
CHAPTER
16
Going beyond PBD
A play-by-play and mixed-initiative approach
Hyuckchul Jung,1 James Allen,1 William de Beaumont,1 Nate Blaylock,1 Lucian Galescu,1
George Ferguson,2 Mary Swift2
1‘institute for Human and Machine Cognition
2Computer Science Department, University of Rochester
ABSTRACT
An innovative task learning system called PLOW (Procedure Learning On the Web) lets end users teach procedural tasks to automate their various Web activities. Deep natural language understanding and mixed-initiative interaction in PLOW make the teaching process very natural and intuitive while producing efficient and workable procedures.
INTRODUCTION
The Web has become the main medium for providing services and information for our daily activities at home and work. Many Web activities require the execution of a series of procedural steps involving Web browser actions. Programmatically automating such tasks to increase productivity is feasible but out of reach for many end users. Programming by demonstration (PBD) is an innovative paradigm that can enable novice users to build a program by just showing a computer what users do (Cypher, 1993). However, in this approach, numerous examples are often needed for the system to infer a workable task.
We aim to build a system with which a novice user can teach tasks by using a single example, without requiring too much or too specialized work from the user. This goal poses significant challenges because the observed sequence of actions is only one instance of a task to teach, and the user’s decision-making process that drives his or her actions is not revealed in the demonstration.
To achieve this challenging goal, we have developed a novel approach in which a user not only demonstrates a task but also explains the task with a play-by-play description. In the PLOW system, demonstration is accompanied by natural language (NL) explanation, which makes it possible for PLOW to infer a task structure that is not easily inferable from observations alone but represents a user’s intentions. Furthermore, the semantic information encoded in NL enables PLOW to reliably identify objects in nonstatic Web pages.
Another key aspect that makes PLOW more efficient is the mixed-initiative interaction that dramatically reduces the complexity of teaching a task by having the computer (1) proactively initiate execution so that the user can verify that it has correctly learned the task, and (2) ask timely questions to solicit information required to complete a task (e.g., asking for a termination condition when it learns an iterative task). This chapter presents the challenges, innovations, and lessons in developing the PLOW system.
MOTIVATING EXAMPLE
Information extraction from the Web is a routine action for many users, and travel arrangement (e.g., booking hotels, flights, and rental cars) is one of many time-consuming activities that require collecting information from multiple sources. Figure 16.1 shows a sample dialogue in which a user teaches PLOW how to find hotels near an address at a travel Web site such as mapquest.com.
In Figure 16.1, user actions (italic texts) are accompanied by a user’s natural language description (normal texts labeled with “User”). Although most of the actions in Figure 16.1 are normal browsing actions, with PLOW, a user may need to perform some easy special actions, such as highlighting a text or an area of the screen by clicking and dragging to directly tell PLOW which information the user is interested in (underlined texts in Figure 16.1).
While user actions on a browser provides useful information, it is very difficult for a system to identify key high-level task information from the demonstration alone, such as:
• Identifying a task goal: What is the final goal of the current task? What is the input and the output?
• Identifying correct parameterization: What values are required to perform the task? Is a value a constant or a variable? For variables, what is the relation among them?
• Identifying iteration control structure: What is the boundary of iteration? Which actions should be repeated? When should iterations be stopped?
• Identifying task hierarchy: When does a new (sub) task start or end?
With PBD based on conventional machine learning approaches, such as (Angros et al., 2002; Lau & Weld, 1999; van Lent & Laird, 2001), to identify the previously mentioned key aspects of a task, multiple examples will be required to generalize learned knowledge. However, PLOW is able to build a task from a single demonstration by inferring the key task information described earlier from the natural language description provided by a user in the play-by-play demonstration.
Another major point is PLOW’s proactive interaction with a user in a natural and unobtrusive manner. In Figure 16.1, the utterances and the actions of PLOW are presented in bold texts and the texts between angled brackets, respectively. For instance, PLOW asks questions (#12 and #20), reports its status (#23), proactively performs learned actions, and presents the action results for verification (#14, #16, #18, and #22).
Furthermore, the contextual information for an action enables PLOW to identify Web objects (e.g., text field, link, etc.) that can change over time. For instance, the user utterance in #8 (“Put the city here”) explains the action of typing a city name into a field labeled with “City”. The NL description is used to find the city field in future execution with a new page format (e.g., new ads inserted at the top, reordering input fields in the search box, etc.).
With this play-by-play and mixed-initiative approach, PLOW is able to build a robust and flexible task from a single demonstration. Learned tasks can be easily improved and modified with new examples, and they can be also reused to build a larger task and shared with other users.

FIGURE 16.1
A dialogue to find hotels near an address.
PLOW ARCHITECTURE
PLOW is an extension to TRIPS (Ferguson & Allen, 1998), a dialogue-based collaborative problem solving system that has been applied to many real-world applications.
The TRIPS system
The TRIPS system provides the architecture and the domain-independent capabilities for supporting mixed-initiative dialogues in various applications and domains. Its central components are based on a domain-independent representation, including a linguistically based semantic form, illocutionary acts, and a collaborative problem solving model. The system can be tailored to individual domains through an ontology mapping system that maps domain-independent representations into domainspecific representations (Dzikovska, Allen, & Swift, 2008).
Figure 16.2 shows the core components of TRIPS: (1) a toolkit for rapid development of language models for the Sphinx-III speech recognition system; (2) a robust parsing system that uses a broad coverage grammar and lexicon of spoken language; (3) an interpretation manager (IM) that provides contextual interpretation based on the current discourse context, including reference resolution, ellipsis processing, and the generation of intended speech act hypotheses; (4) an ontology manager (OM) that translates between representations; and (5) a generation manager (GM) and surface generator that generate system utterances from the domain-independent logical form.
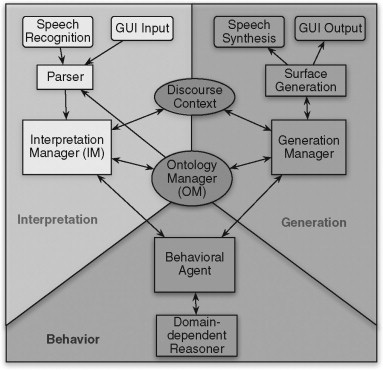
FIGURE 16.2
TRIPS architecture.
The IM coordinates the interpretation of utterances and observed cyber actions. IM draws from the Discourse Context module as well to help resolve ambiguities in the input, and coordinates the synchronization of the user’s utterances and observed actions. Then IM interacts with a behavioral agent (BA) to identify the most likely intended interpretations in terms of collaborative problem solving acts (e.g., propose an action, accept a problem solving act or ignore it, work on something more pressing, etc.). BA gets support from additional reasoning modules specialized for each application domain and reports its status to a GM that plans a linguistic act to communicate the BA’s intentions to the user.
TRIPS components interact with each other by exchanging messages through a communication facilitator. Therefore, they can be distributed among networked computers. The rest of this chapter will focus on the PLOW components. For further information about TRIPS, refer to (Allen, Blaylock, & Ferguson, 2002; Ferguson & Allen, 1998).
PLOW interface
PLOW inherits most of its core reasoning modules for language interpretation and generation from TRIPS. New capabilities for task learning are added to the behavioral agent that interacts with additional reasoners specialized for building task representation, maintaining a task repository, and executing learned tasks. Though these modules are designed to learn tasks in various domains (e.g., office applications, robots, etc.), PLOW focuses on tasks that can be performed within a Web browser, and its ontology is extended to cover Web browsing actions.
Figure 16.3 shows PLOW’s user interface. The main window on the left is the Firefox browser instrumented so that PLOW can monitor user actions and execute actions for learned tasks. Through the instrumentation, PLOW accesses and manipulates a tree-structured logical model of Web pages, called DOM (Document Object Model). On the right is a GUI that summarizes a task under construction, highlights steps in execution for verification, and provides tools to manage learned tasks. A chat window at the bottom shows speech interaction, and the user can switch between speech and keyboard anytime.
The domain-independent aspect of PLOW was recently demonstrated in the project for appointment booking with the Composite Health Care System (CHCS) that is widely used at U.S. military hospitals. CHCS is a terminal-based legacy system and most of the PLOW codes were reused for the system. The major work involved instrumenting the terminal environment (e.g., observing key strokes, checking screen update, etc.) as well as extending the ontology for the health care domain. From a user’s point of view, the only noticeable major change to adapt to was the replacement of a browser with a terminal.
Collaborative problem solving in PLOW
Figure 16.4 shows a high-level view of the information flow in PLOW. At the center lies a CPS (Collaborative Problem Solving) agent that acts as a behavioral agent in the TRIPS architecture. The CPS agent (henceforth called CPSA) computes the most likely intention in the given problem solving context (based on the interaction with IM). CPSA also coordinates and drives other parts of the system to learn what a user intends to build as a task and invokes execution when needed.
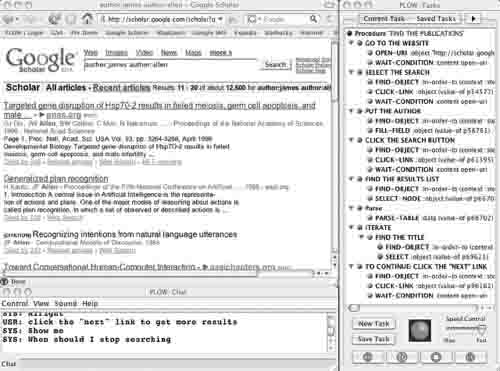
FIGURE 16.3
PLOW interface.
CPSA understands the interaction as a dialogue between itself and a user. The dialogue provides the context for interpreting human utterances and actions, and provides the structure for deciding what to do in response. In this approach, from a user’s perspective, PLOW appears to be a competent collaborative partner, working together towards the shared goal of one-shot learning.
To give an overview of the collaborative problem solving, assume that a user introduced a new step. CPSA first checks if it knows how to perform the step and, if so, initiates a dialogue to find out if the user wants to use a known task for the step in the current task. If the user says so, CPSA invokes another dialogue to check if the user wants to execute the reused task or not. Depending on the user’s responses, CPSA shows different behavior. In the case of execution, CPSA enters into an execution mode and presents results when successful. If execution failed, PLOW invokes a debugging dialogue, showing where it failed.
In some cases, the system takes proactive execution mixed with learning, following an explicit model of problem solving. In particular, this type of collaborative execution during learning is very critical in learning iteration without requiring a user to tediously demonstrate each loop over a significant period. Refer to (Allen et al., 2002) for the background and the formal model of collaborative problem solving in TRIPS.
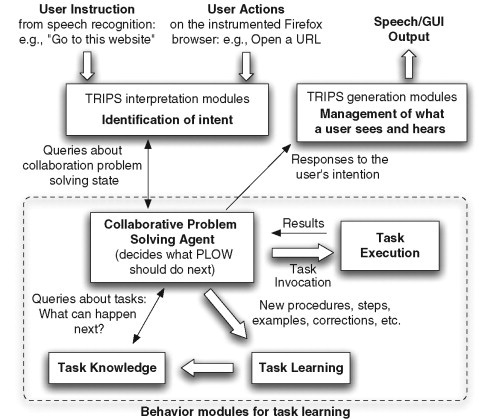
FIGURE 16.4
PLOW information flow.
TEACHING WEB TASKS WITH PLAY-BY-PLAY
Task representation
A task is built as a series of steps and each step may be primitive (i.e., a self-contained terminal action) or correspond to another task (i.e., calling a subtask). However, a task model is more than a collection of steps. A task model needs to contain information such as an overall task goal, preconditions, postconditions, the relationship between steps, and the hierarchical structure of a task, among others.
Figure 16.5 shows an abstract task model in PLOW that is designed to be easily executable by the system as well as applicable to further reasoning. The model includes a task goal, various conditions (pre/post/triggering/completion-condition), step description, and supplemental records, such as documentation. Each step consists of the name, preconditions, parameters, and primitive actions. An action definition includes its name and parameters.

FIGURE 16.5
Abstract task model.
Following sections will show how a task model is constructed through collaboration between a user and PLOW that involves multiple communicative acts and highly sophisticated reasoning in PLOW. They will also provide more detailed description for each element in the task model presented in Figure 16.5. Refer to (Allen et al., 2007; Jung et al., 2008) for additional technical detail including the internal abstract knowledge representation language. The task model examples below are simplified for illustrative purpose by replacing a frame-like representation based on domain-specific ontology with plain English.
Task goal definition
The task model is incrementally built as a user performs play-by-play demonstration. Figure 16.6 shows a part of the task model built from the dialogue in Figure 16.1. Given the user utterance “Let me teach you to find hotels near an address” (#1 in Figure 16.1), TRIPS natural language understanding modules parse and interpret it. IM computes multiple hypotheses, selects the best candidate, and sends it to CPSA for evaluation.
Here, the selected hypothesis is that the user has proposed to teach PLOW a task for finding a set of hotels with an attribute of being near an address. CPSA reasons about the validity of the user’s proposal and makes a decision, to accept or refuse. When it is accepted, IM requests CPSA to commit to the proposal. Then CPSA requests a task-learning module, henceforth called TL, to initiate the learning process for a new task. Receiving this request that includes the description of the task to learn, TL creates an initial task model with the goal part based on the given task description (Figure 16.6-a) and notifies CPSA of its ready status. Then, CPSA updates its collaborative problem solving state and waits for the user to define a step.

FIGURE 16.6
A task model example.
The task model built at this stage also includes other useful information such as a task description (Figure 16.6-b) and documentation (Figure 16.6-c). Note that the task description is not the text directly from speech recognition. Instead, it is text that the TRIPS surface generator produced from the internal representation of the task goal, which clearly shows that the system understands what a user said. The same goes for the step description in the task model. These reverse-generated NL descriptions are used to describe the current task in the PLOW interface (the right side window in Figure 16.3). PLOW automatically generates the documentation part, but a user can edit it later for a note.
A task may also have a trigger: e.g., when a user says, “Let me teach you how to book hotels near an airport when a flight is canceled”, the event of flight cancellation (that can be notified in various forms) is captured as a trigger and recorded in the task model. While PLOW is running, if PLOW is notified of such an event, it finds a task with a matching triggering condition and, if any, executes the task.
Task step definition
High-level step description in play-by-play
When a user describes a step by saying, “Go to this Website” (#2 in Figure 16.1), IM and CPSA collaboratively interpret and reason about the utterance. Then, CPSA requests TL to identify a step by sending a message that contains the user’s step description. Given this request, TL creates a step with an incomplete action part (since no action has been taken yet) and inserts the step definition (Figure 16.7) into the current task model.

FIGURE 16.7
An example of step definition.
Primitive actions of a step
Following the step description, a user performs a normal navigation action in the browser and the action is detected by the Firefox instrumentation. IM receives the action and checks with CPSA. Then, after checking the validity of the action, CPSA requests TL to learn the action of opening the URL observed in the browser. Using the information in this request, TL extends the action part of the step definition as shown in Figure 16.8.
Note that TL inserts additional information into the action definition based on its domain knowledge. To handle multiple windows, a browser window to perform the current action is specified. In addition, an action to wait for “complete Web page loading” is inserted (Figure 16.8-b). Without such synchronization, subsequent actions could fail, particularly on a slow network (e.g., trying to select a menu when the target menu does not appear yet). In navigating to a link, there can be multiple page loading events (e.g., some travel Web sites show intermediate Web pages while waiting for search results). PLOW observes how many page loading events have occurred and inserts waiting actions accordingly.
Figure 16.9 shows the PLOW interface after this step demonstration. The right side window for the current task under construction has a traffic signal light at the bottom portion. The signal changes colors (green/red/yellow) based on PLOW’s internal processing state and its expectation of the application environment, telling if it is deemed OK for a user to provide inputs to PLOW (green) or not (red). Yellow implies that PLOW is not sure, because, in this case, there can be multiple page loading events controlled by the Web site server.
Web objects in primitive actions
In Figure 16.1, there is a step created by saying, “Put the city here” and typing a city name into a text field labeled with “City”. Here, the observed action from the browser instrumentation is an action that puts some text (e.g., “Pensacola”) into a text field. However, the semantic description helps PLOW to find the text field in a Web page, the layout of which may change in a future visit.
Figure 16.10 is a screenshot of the Firefox DOM Inspector that shows DOM nodes and their attributes/structure accessed by PLOW for its learning how to identify objects in nonstatic Web pages (e.g., redesigned or dynamic Web pages).1 For simplicity, such objects will be called “Web objects” hereafter. For the step to put in a city, PLOW finds a match for “city” in one of the attributes of the INPUT node (i.e., id=“startCity”). PLOW learns the relation between the semantic concept and the node attribute as a rule for future execution. Linguistic variation (e.g., cities) or similar ontological concepts (e.g., town, municipality) are also considered for the match. Right after learning this new rule, PLOW verifies it by applying the rule in the current page and checking if the object (i.e., a text field) found by the rule is the same as the object observed in demonstration.

FIGURE 16.8
Step definition with extended action part.
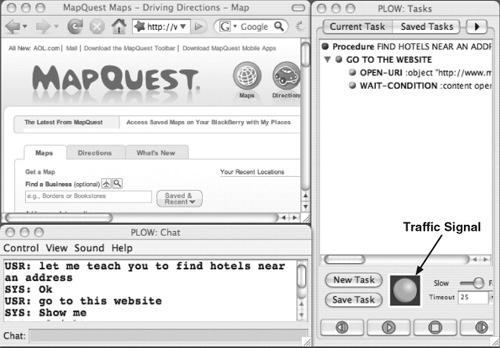
FIGURE 16.9
PLOW interface after step demonstration.
PLOW also uses other heuristics to learn rules. For instance, when the node identified in the demonstration does not have any semantic relation, it finds another reference node traversing the DOM tree and, if found, computes the relation between the node observed in demonstration and the reference node found elsewhere. With this sophisticated approach, even when there is a Web page format change, PLOW is able to find a node as long as there are no significant local changes around the node in focus. For further information on PLOW’s Web object identification, refer to (Chambers et al., 2006).
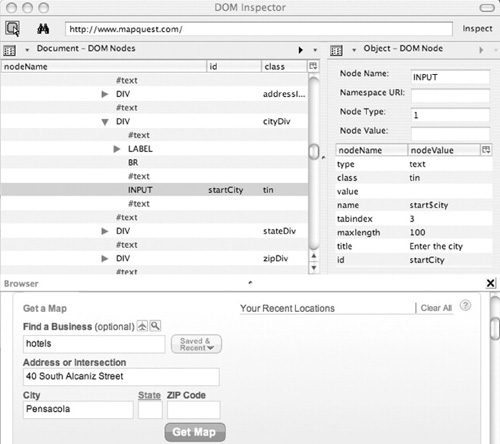
FIGURE 16.10
DOM structure of a Web page.
Parameter identification
Identifying parameters is challenging even for a simple task and, without special domain knowledge, it is almost impossible with only a single observation. When an object is used in a task, the system should determine if it is a constant or a variable. In the case of a variable, it also has to figure out the relation between variables. Figure 16.11 shows how natural language plays a critical role in PLOW’s parameter identification, enabling it to identify parameters from a play-by-play single demonstration.
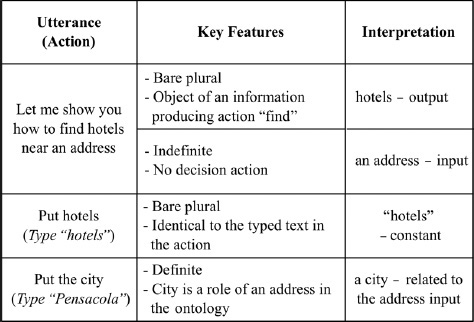
FIGURE 16.11
Interpretation of noun phrases.
Furthermore, TRIPS’s reference resolution capability also identifies the relation between parameters. For instance, in Figure 16.1, the city instance in one step (#8) is related to the address mentioned earlier (#1 and #5). The semantic concept CITY is a role of another concept, ADDRESS, in the TRIPS ontology. A special address parser helps to reason that the typed city name “Pensacola” in the demonstrated action (#8) matches the city part of the given full address provided by a user (#6). Without this dependency relation from language understanding and the verification by the address parser, PLOW will add the city as a separate input parameter. Note that, in the final task model, there is only a single input parameter, an address (Figure 16.6-d).
NL description also helps to identify output parameters. From the utterances that specify which information to extract (#13, #15, and #17 in Figure 16.1), PLOW figures out that the objects to find in those steps are related to the task output defined in the task definition (i.e., “hotels” in #1). Therefore, they are added as output parameters (Figure 16.6-e).
Task hierarchy
PLOW uses simple heuristics to identify the beginning and end of a subtask. Any statement that explicitly identifies a goal (e.g., “Let me show you how …”) is seen as the beginning of a new (sub) task. A user’s explicit statement, such as “I’m done”, or another goal statement indicates the end of the current (sub) task. Our anecdotal experience is that users easily get familiar with this intuitive teaching style through a few guided training sessions.
Control constructs
Conditionals
Conditionals have a basic structure of “if X, then do Y”, optionally followed by “otherwise do Z”. However, the action trace for conditionals includes only one action, either Y or Z, based on the truth value of the condition X. In general, identifying X is very difficult, because the entire context of demonstration should be checked and reasoned about. However, in the play-by-play demonstration, when a user specifies a condition, PLOW can correctly interpret the condition from language.
Iteration
The main difficulty in identifying iterative procedures from a single example is that the action trace (a sequence of actions) alone does not fully reveal the iterative structure. For iteration, a system needs to identify these key aspects: (1) the list to iterate over; (2) what actions to take for each element; (3) how to add more list elements; and (4) when to stop.
For a system to reason about these aspects on its own, in addition to repetitive examples, full understanding of the action context (beyond observed actions) and special domain knowledge will be required (e.g., what and how many list items were potentially available, which ones were included in the observed actions, how and when Web page transition works, etc.). Furthermore, a user would not want to demonstrate lengthy iterations. In PLOW, natural language again plays a key role. As shown below, we designed the system GUI and dialogue to guide a user through the demonstration for iteration: mixed-initiative interaction with proactive execution and simple queries make the process much easier and intuitive.
In Figure 16.12, a user is teaching PLOW how to find hotels near an address. When the user highlights a list of results (Figure 16.12-a) and says, “Here is a list of results”, PLOW infers that an iteration over elements in the list will follow. Then, PLOW enters into an iteration-learning mode with the goal of identifying the key aspects stated earlier. First, by analyzing the DOM structure for the list object, PLOW identifies individual elements of the list and then presents the parsed list in a dedicated GUI window with each element (essentially a portion of the original Web page) contained in a separate cell (Figure 16.12-b).
This GUI-based approach lets the user quickly verify the list parsing result and easily teach what to do for each element. Note that list and table HTML objects that contain the desired list may also be used for other purposes (e.g., formatting, inserting ads, etc.), so it is fairly common that some irrelevant information may appear to be part of the list. PLOW uses clustering and similarity-based techniques to weed out such information.
After presenting the parsed list, PLOW waits for the user’s identification of an element. For instance, the user says, “This is the hotel name”, and highlights the hotel name in one of the small cells in the GUI (Figure 16.12-c). Given this information, PLOW learns the extraction pattern and proactively applies the rule to the rest of elements (Figure 16.12-d). While the extracted data from this iterative step are stored in a knowledge base for further reasoning, a user cannot manipulate the data except for referring to them. In contrast, a mashup system, Potluck (Huynh, Miller, & Karger, 2007), provides a user with intuitive GUIs for clustering and editing the information from extracted lists.
Note that a composite action can be also defined for each list element. For instance, a user may navigate to a page from a link (e.g., in Figure 16.12-b, the “Directions To” link), extract data from the new page, and so on. Dontcheva’s Web summary system (Chapter 12) can also extract information from linked pages, the content of which may trigger information extraction from other Web sites based on user-defined relations. Though her system can be applied to a given collection of items, PLOW can identify an arbitrary number of items (in multiple Web pages) and iterate over them with termination conditions as described later.

FIGURE 16.12
Learning iteration.
If there is an error, the user can notify PLOW about the problem by saying, “This is wrong”, and show a new example. Then, PLOW learns a new extraction pattern and reapplies it to all list elements for further verification. This correction interaction may continue until a comprehensive pattern is learned.
Next, the user teaches PLOW how to iterate over multiple lists by introducing a special action (e.g., “Click the next link for more results” – see Figure 16.12-e). This helps PLOW to recognize the user’s intention to repeat what he or she demonstrated in the first list on other lists. Here, to identify the duration of the iteration, PLOW asks for a termination condition by saying, “When should I stop searching’/” For this query, it can understand a range of user responses, such as “Get two pages”, “Twenty items”, and “Get all”.
The conditions can depend on the information extracted for each element, as in “Until the distance is greater than 2 miles”. In the case of getting all results, the system also asks how to recognize the ending, and the user can tell and show what to check (e.g., “When you don’t see the next link” or “When you see the end sign”). For verification, PLOW executes the learned iterative procedure until the termination condition is satisfied and presents the results to the user using the special GUI. The user can sort and/or filter the results with certain conditions (e.g., “sort the results by distance”, “keep the first three results”, etc.).
UTILIZING AND IMPROVING TAUGHT WEB TASKS
Persistent and sharable tasks
After teaching a task, a user can save it in a persistent repository. Figure 16.13 shows the “Saved Tasks” panel in the PLOW interface that shows a list of a user’s private tasks. A pop-up menu is provided for task management, and one of its capabilities is exporting a task to a public repository for sharing the task with others. A user can import shared tasks from the “Public Tasks” panel.
Task invocation
Tasks in the private repository can be invoked through the GUI (Figure 16.13) or in natural language (e.g., “Find me hotels near an airport”). If the selected task requires input parameters, PLOW asks for their values (e.g., “What is the airport?”), and the user can provide parameter values using the GUI or natural language.
Users can invoke a task and provide input parameters in a single utterance, such as, “Find me hotels near LAX”or”Find me hotels near an airport. The airport is LAX.” Results can also be presented via the GUI or in natural language. This NL-based invocation capability allows users to use indirect channels as well. For example, we built an email agent that interprets an email subject and body so that a user can invoke a task by sending an email and receive the execution results as a reply.
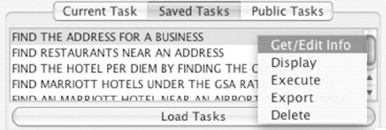
FIGURE 16.13
Task management.
Here, given a user request, PLOW finds a matching task with its natural language understanding and ontological reasoning capabilities. A user does not necessarily have to use the same task description used in teaching. “Get me restaurants in a city” or “Look for eateries in a town” would select a task to find restaurants in a city.
Reusing tasks
In teaching a task, existing tasks can be included as subtasks. When a user gives the description of a new step, PLOW checks if the step matches one of the known tasks; if a matching task is found, it is inserted as a subtask with parameter binding between the current task and the reused task. For instance, in one teaching session, a user has taught how to book a flight and wants to reserve a hotel. For a step introduced by saying, “Book a hotel for the arrival date”, PLOW will check for a matching task for the step.
If the user already has a task to reserve a hotel with a check-in date and a number of nights, PLOW will mark the step as reusing another task so that, in execution, the reused task can be called. PLOW will also infer that the arrival date should be bound to the check-in date and consider the number of nights as a new input parameter if there is no related object in the current task.
Editing tasks
To fix obsolete tasks (e.g., to update them after Web site changes) or to improve or simplify a task, PLOW lets a user add or delete steps. To reach a step to edit, PLOW supports (1) step-by-step execution (the default mode for verification) and (2) partial execution up to a certain step. One can invoke the two modes by saying, “Let’s practice step by step” and “Execute the task up to this step” (after selecting a step in the current task window), respectively.
Setting up the action context (i.e., browser setting, extracted objects, available parameter values, etc.) with real execution is critical because the context is used in PLOW’s reasoning for the action to edit. Figure 16.14 shows the interaction between a user (USR) and PLOW (SYS) for task editing that was to add a new step to select a checkbox for a special military rate in booking a hotel. Note that, before the dialogue in the chat window, the user selected the step described as “Put the check out date” in the current task window (marked with a stop sign).
Improving tasks from execution failure
Execution failure from unnecessary or missing steps can be corrected by task editing. Major Web site redesigns will sometimes trigger Web object identification failures. When PLOW detects an execution error, it stops at the failed action, notifies the user, and initiates a debugging process by asking for a new example from which it learns an additional extraction pattern.
In Figure 16.15, the task is to find hotel per diem rates for a city and a state. In testing for a city in Nebraska, PLOW failed at the step to find a per diem list because the list observed in demonstration had a significantly different structure from the list to find in testing. PLOW notified a user of the failure with speech and GUI (red text with a bug icon) outputs. The dialogue in the chat window shows how PLOW and a user interacted with each other to address the problem. As shown in the browser window, the user gave a new example by highlighting the per diem rate list for the failed step. Now, the constructed task has become more robust with the knowledge about different list structures.
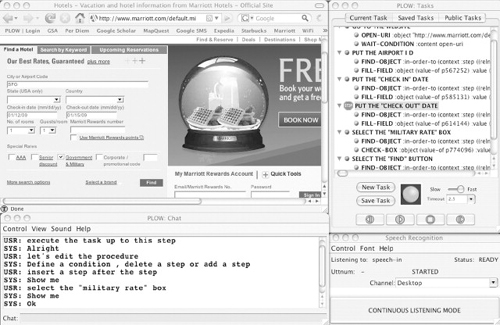
FIGURE 16.14
Task editing.
EVALUATION
In 2006 and 2007, PLOW was evaluated along with three other task-learning systems by an independent agency as a part of the U.S. DARPA (Defense Advanced Research Projects Agency) CALO (Cognitive Assistant that Learns and Organizes) project. Sixteen human subjects received training on each system and they were given ten problems that can be performed on various Web sites:
1. To whom should a travel itinerary be emailed?
2. List all publications from the work funded by a project.
3. List top N candidates for given product specifications.
4. Retrieve N product reviews for a product.
5. List restaurants within a certain distance from an address.
6. In what conference was an article published?
7. What articles are cited in a given article?
8. What articles cite a given article?
9. Who else is traveling to a location on the same day with a person of interest?
10. What roles does a person play in an institution?
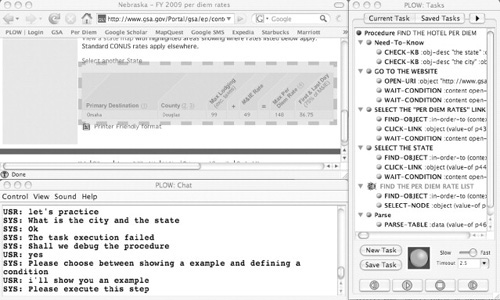
FIGURE 16.15
Failure correction with a new example.
PLOW did very well in both tests, receiving a grade of 2.82 (2006) and 3.47 (2007) out of 4 (exceeding the project goals in both cases). The test score was given by human evaluators based on a complex scheme that took into account the completeness and the correctness of the results.
In a separate test in 2006, test subjects were given a set of 10 new surprise problems, some of which were substantially different from the original 10 problems. They were free to choose from different systems. However, PLOW was the system of choice among the subjects. In the testing, 55 task models out of the possible 160 individual models were constructed by 16 users. PLOW was used to create 30 out of the 55 completed task models, and 13 out of 16 users used PLOW at least once (the next most used system was used by 8 users). PLOW also received the highest average score (2.2 out of 4) in the test.
PLOW performed relatively well for the problems, the solution of which can be provided by a single Web site with minimal manipulation of the extracted information (e.g., simple data filtering such as selecting N items). As for the user-friendliness, though PLOW received favorable anecdotal comments for its natural interaction, users were often unable to undo incorrect steps (forcing them to restart), and they also got confused when PLOW entered into an error state without proper feedback, causing additional errors.
RELATED WORK
A major technique in task learning is an observation-based approach in which agents learn task models through observation of the actions performed by an expert (Angros et al., 2002; Lau & Weld, 1999; van Lent & Laird, 2001). However, a significant drawback of these approaches is that they require multiple examples, making them infeasible for one-shot learning in most cases without very special domain knowledge.
Researchers also investigated techniques that do not require observation by enabling experts to encode their knowledge with annotation (Garland, Ryall, & Rich, 2001; Lee & Anderson, 1997). To make a knowledge encoding process more efficient, a specialized GUI system, called Tailor, was developed as part of the DARPA CALO project (Blythe, 2005). Pseudo-NL-based scripts, such as CoScripter, fit very well for end users to automate and share Web-based processes (Chapter 5). Although these annotation and NL-based scripting technologies are very useful, it would be difficult for a system to learn how to identify Web objects in nonstatic Web pages.
Chickenfoot (Chapter 3), with a UNIX shell script style language, and AtomSmasher (Chapter 7), with rules to control multiple scripts, are good alternatives to automate Web-based processes that include complex control structures. However, they still have many features in conventional programming languages and are less suitable for novice end users.
Creo is a PBD system that can learn a task from a single example (Chapter 4). The generalization of observed actions is supported by knowledge bases of semantic information, MIT’s ConceptNet and Stanford’s TAP. Although the semantic information provides the basis for parameter generalization, it is limited to support reasoning about control structures from a single example.
Mashup systems are also efficient tools to extract and integrate information from multiple Web sites (see Chapters 9 and 12) (Huynh et al., 2007). While they are powerful tools, their capability and complexity are positively correlated (i.e., complex interfaces are provided for advanced functionalities). Furthermore, they have limitations on handling nonstatic Web objects and understanding extracted information for further reasoning.
SUMMARY
PLOW demonstrates that NL is a powerful intuitive tool for end users to build Web tasks with significant complexity using only a single demonstration. The natural play-by-play demonstration that would occur in human–human teaching provides enough information for the system to generalize demonstrated actions. Mixed-initiative interaction also makes the task building process much more convenient and intuitive. Without the system’s proactive involvement in learning, the human instructor’s job could become very tedious, difficult, and complex. Semantic information in NL description also makes the system more robust by letting it handle the dynamic nature of the Web.
Though PLOW sheds more light on NL’s roles and the collaborative problem solving aspects in the end user programming on the Web, significant challenges still exist and new ones will emerge as application domains are expanded. Better reasoning about tasks, broader coverage of language understanding, and more robust Web object handling will be needed to address the challenges.
Acknowledgments
This work was supported in part by DARPA grant NBCHD-03-0010 under a subcontract from SRI International, and ONR grant N000140510314.
Intended users: |
All users |
Domain: |
All Web sites |
Description: |
PLOW learns a task from explicit demonstration of the task together with natural language instruction. The natural language “play by play” provides key information that allows rapid and robust learning of complex tasks including conditionals and iterations in one session. |
Example: |
Look for hotels near an airport based on their distance and price. When a user’s flight is cancelled at midnight, the user invokes a task built by his/her colleague to get a list of hotels. |
Automation: |
Yes, it automates tasks that can be done by normal Web browsing actions but do not require visual understanding of Web pages. |
Mashups: |
It can combine information from multiple Web sources. However, its capability is limited by the difficulty in understanding complex instruction for how to present and manipulate combined information. |
Scripting: |
No. |
Natural language: |
Natural language processing is the key to understanding the user’s intention and Web page content. |
Recordability: |
Yes, user actions are observed by the system. |
Inferencing: |
Heuristics are used in interpreting the user’s intention, which may be vague or ambiguous, and learning how to identify objects in a Web page. |
Sharing: |
Yes, users can share tasks using a specialized GUI. |
Comparison to other |
PLOW exploits the rich information encoded in the user’s natural language |
systems: |
description for demonstrated actions, which makes the teaching process efficient and natural. |
Platform: |
Implemented as a desktop application combined with an instrumented Mozilla Firefox browser. A Web-based version with a server was also developed. |
Availability: |
Not currently available. |
1PLOW has limitations in handling objects in rich interfaced pages that dynamically change while they are viewed, often in response to mouse actions or at specified timing events (e.g., Web pages with technologies such as Dynamic HTML and Flash).