
CHAPTER
18
Social Accessibility
A collaborative approach to improving
Web accessibility
Yevgen Borodin,1 Shinya Kawanaka,2 Hironobu Takagi,2 Masatomo Kobayashi,2 Daisuke Sato,2 Chieko Asakawa2
1Department of Computer Science, Stony Brook University
2IBM Research – Tokyo
ABSTRACT
This chapter challenges the assumption that Web site owners are the ones who are responsible for the accessibility of Web content. Web designers and Web developers have been notorious for not following official accessibility guidelines. At the same time, the amount of user-generated Web content made it practically impossible for site owners to ensure content accessibility in a centralized fashion. However, the dawn of social computing promises that collaborative approaches will overcome these problems. This chapter overviews the applications of social computing to Web accessibility and introduces Social Accessibility – a collaborative framework, which brings together end users and volunteers for the purpose of creating external accessibility metadata. In making the Web accessible, the Social Accessibility approach bypasses content owners, considerably reducing the time for accessibility renovations. In addition, the centralized metadata can be used to educate Web designers and developers about creating accessible content, while providing a central point for collaborative accessibility verification.
INTRODUCTION
The Web is playing an increasingly important role in our lives and has turned into an infrastructure vital to our society. However, in its evolution from single-author text-based Web pages to interactive Web applications with user-generated content, the Web has become less accessible to people with vision impairments, because content providers often fail to follow the accessibility guidelines while using a wide variety of inaccessible Web technologies with the primary focus on improving visual interaction.
Web content has traditionally been under the control of site owners, which is why, according to the present view on Web accessibility, site owners should be the ones who bear the responsibility for making their content accessible. Nowadays, however, the content is frequently generated by end users, who are posting information on content-sharing services, such as forums, blogs, etc., in the volume that can hardly be controlled by the site owners.
Highly interactive interfaces built with technologies such as AJAX and Flash exacerbate the accessibility problems even further. Though interactive Web sites can enhance the user experience by offering rich interactivity and responsiveness of the Web application, they simultaneously pose serious challenges not only to assistive software, such as screen readers used by blind people, but also to spiders crawling and indexing the Web, software tools that help users aggregate and filter information, automate repetitive tasks (Borodin, 2008; Leshed et al., 2008) (Chapter 5), provide custom views (Nichols & Lau, 2008) (Chapter 6), etc.
From a compliance perspective, Web designers and developers have to embed sufficient accessibility metadata into their content; for example, screen reader users need structural metadata (e.g., headings and lists) and alternative text for images to be able to efficiently navigate Web pages. Unfortunately, the accessibility metadata are often inadequate in both quality and quantity. Site owners are not able to give higher priority to their Web sites’ accessibility compared to their business and technology needs, with the result that visual attractiveness of Web sites remains their primary focus.
Even those site owners who are willing to make their sites compliant with accessibility guidelines are not always able to do so, because of the need for specialized knowledge. On the other hand, only end users can reliably assess the usability and accessibility of Web sites. However, until now, the user involvement in improving Web accessibility has been very limited. There is general consensus among users that sending reports about accessibility problems to site owners is of little or no use, and that no effective feedback loop exists to correct accessibility problems. This leads us to believe that there is a clear need for a new framework that could engage the end users in making the Web more accessible and, thus, accelerate the accessibility renovations of Web sites.
Recent years have seen a surge in social networks (e.g., Facebook, MySpace, LinkedIn, etc.), which have proven effective in bringing together users with common interests, which in turn made possible a variety of collaborative approaches, such as ManyEyes (Viégas et al., 2007), ESP game (von Ahn & Dabbish, 2004), reCAPTCHA (von Ahn et al., 2008), Mechanical Turk (Kittur, 2008), and Phetch (von Ahn et al., 2007), to name a few.
The Social Accessibility Project (Takagi et al., 2008) featured in this chapter is taking a similar approach – it applies social computing strategies to accessibility metadata authoring. The collaboration through the Social Accessibility network allows persons experiencing accessibility problems to submit service requests, and it encourages other participants to respond to the requests by creating accessibility metadata, which can be generated both manually and automatically. This in turn provides various options for participation and volunteering. While shortening the creation time for accessible Web content, a collaborative approach can also drastically reduce the burden on content providers. And finally, the social networking infrastructure facilitates discussions and brings together people from around the world for the purpose of improving Web accessibility.
RELATED WORK
The work related to the Social Accessibility project includes collaborative authoring, transcoding, metadata authoring approaches, accessibility of Rich Internet Applications, and database integration.
Collaborative authoring
The Social Accessibility (SA) network enables collaborative authoring of accessibility metadata, which are additional information about the original Web documents to make them more accessible. The use of metadata in improving Web accessibility is wide-ranging and is covered by several W3C guidelines1 and standards. Some representative examples include alternative text metadata describing images, labels for form elements, and ARIA2 markup indicating the semantic roles of dynamic content. An important feature of accessibility metadata is that they can be used by a wide variety of software tools – from screen readers to search engines.
Collaborative document authoring is an area with a long history (e.g., Leland, Fish, & Kraut, 1988). A prime example of the largest success in this area is the wiki (Leuf & Cunningham, 2001), with the above-mentioned technology having yielded such fruits of global collaboration as the Wikipedia. In spite of the successes of collaborative authoring, it has rarely been applied to the accessibility area. One of the recent projects involving the technology is its use for collaborative “caption” authoring of multimedia content. The We-LCoME project is aimed at building accessible multimedia e-learning content through collaborative work on a wiki system (Ferretti et al., 2007; Ferretti et al., 2008). We-LCoME and Social Accessibility run in similar directions, using collaborative authoring for accessibility. Google Image Labeler3 is a system used to build accurate textual descriptions of images through a game. The goal of the project is to improve the accuracy of Google Image search; nonetheless, the generated metadata could potentially be used for accessibility. Another system, which collects image labels through a game, is Phetch (von Ahn et al., 2007). The Social Accessibility approach learns from the existing research on collaborative document authoring and uses it to improve Web accessibility.
External metadata and transcoding
In general, there are two types of metadata: internal metadata that are embedded into documents (Web pages) and external (standoff) metadata that are stored separately, but are associated with the original documents. The important distinction is that the internal metadata can only be changed with the appropriate permissions from content owners, whereas the external metadata can be created by anyone. The SA approach utilizes the external metadata, in this way, enabling the collaborative approach to metadata authoring.
The main challenge in using the external metadata is in the on-the-fly association of specific metadata with the content they describe. Anchoring metadata to a specific part of a document is, therefore, key to the effective use of external metadata. Various research projects have been focusing on the automatic or semiautomatic creation and adaptation of external metadata to improve accessibility through transcoding original documents.
Transcoding is often used to modify the presentation of content without modifying the originals. Transcoding for Web accessibility is a category of approaches that make existing Web pages accessible on the fly. Currently, the technology is not widely used, in spite of its huge potential to improve the accessibility of Web content. The primary reason for not using transcoding has been the heavy workload of metadata authoring, which has not been manageable until the introduction of collaborative approaches.
Transcoding of Web pages was originally developed to adapt Web pages to mobile devices (Bickmore & Schilit, 1997b) and to personalize pages (Maglio & Barrett, 2000). Then the technique was applied to transform inaccessible Web content into accessible on the fly. This technique has formed a new category of approaches – “transcoding for Web accessibility.” More on transcoding, including history and methods, can be found in (Asakawa & Takagi, 2008a).
A recent research challenge in the transcoding area is dynamic Web applications, including AJAX techniques that use JavaScript to change the content of an already-loaded Web page. The AJAX (Asynchronous JavaScript and XML) techniques allow Web pages to download data on demand; for instance, while typing search keywords on a search engine Web site, the underlying JavaScript can transparently retrieve keyword suggestions from the server. The aiBrowser has a metadata mechanism to dynamically convert AJAX and Flash-based dynamic content into accessible formats (Miyashita et al., 2007). AxsJAX (Chen & Raman, 2008) is a technology used to make AJAX applications accessible while using JavaScript descriptions as a kind of metadata. Another technique, Access Monkey (Bigham & Ladner, 2007), also uses JavaScript to transcode content.
Metadata authoring approaches
Transcoding with external metadata has great potential as a new approach to creating a more accessible Web environment by supplementing the insufficient internal metadata. However, the workload of authoring has prevented it from providing major real-world benefits to users. We classify the approaches by the reduction of the authoring time and effort.
Fully automated generation. Automatic transcoding techniques can transform content without any additional information by using various inference techniques, such as content analysis (Ramakrishnan, Stent, & Yang, 2004), differential analysis (Takagi & Asakawa, 2000), and so on. These automatic methods have an advantage in coverage since they can deal with any content on the Web; however, the accuracy of their inferences can be problematic. Besides, mechanisms to add supplementary manual metadata are needed for practical deployments. One example of such an approach is WebInsight (Bigham et al., 2006). The system infers alternative texts for images by automatically combining the results of OCR with the text-based content analysis and humanauthored metadata. In addition, the system is characterized by its use of manual metadata as a last resort after exhaustive automatic processing.
Semi automated authoring. Some types of annotations are difficult to create by using fully automated approaches, such as states of Rich Internet Applications (RIAs). In the traditional static-Web paradigm, each page represents a state reachable through static links easily identifiable in the HTML source code. On the other hand, in RIAs, the states are implicit and are determined by the user actions and the ensuing changes that occur in Web pages as a result of those actions. The discovery of the states, transitions, and the information hidden in those states can improve RIA accessibility to Web spiders, screen readers, and other tools (Borodin, 2008; Leshed et al., 2008; Nichols & Lau, 2008) that need to retrieve the information. Fully automated approaches for discovering such states are not feasible (Mesbah, Bozdag, & Deursen, 2008); conversely, a semiautomated approach guided by users (even if they do not realize it) can be used to create and share external metadata describing dynamic content and its behavior. The collaborative crawling (Aggarwal, 2002) approach can be used to automate the discovery of dynamic content and metadata authoring, as described further in this chapter.
Manual annotations. Users exploring Web content can also be a source of metadata. For example, blind users can find the starting position of the main content in a page by exploring the page and marking this position for other users. Some commercial screen readers have functions to register alternative texts for images (e.g., JAWS4). HearSay (Ramakrishnan, Stent, & Yang, 2004; Borodin et al., 2007) has more advanced functions to allow users to add metadata (labels) in combination with an automatic analysis function. Users can easily select an appropriate label from the candidates. Although more accurate than automated annotation, manual authoring of metadata can be time-consuming.
Improvement of centralized authoring (template matching). Site-wide Annotation (Takagi et al., 2002) is aimed at reducing workload by combining template matching algorithms with a metadata management tool, Site Pattern Analyzer (SPA). A snapshot of a target site is crawled by the tool in advance, and then the tool visualizes the correspondences of each item of metadata to each page on the screen. In spite of the improvements, the workload for metadata maintenance is still excessive, which prevents it from being adopted by site owners as a practical way of making their rapidly evolving content accessible.
Improvement of centralized authoring (styling information). SADIe (Harper, Bechhofer, & Lunn, 2006) is characterized by its annotation mechanism based on CSS5 information. One of the well-established approaches in Web design is CSS-based styling, because it provides flexibility in design, reduces the cost of managing visual layouts, and even improves accessibility by separating the logical structure of the content from the page design. SADIe takes advantage of this approach to reduce the workload of metadata authoring by associating semantics with the styling components. The main limitation of this approach is that it only works for sites with well-organized CSS styling, meaning that CSS styles have to follow the logical structure of Web pages.
Accessibility of Rich Internet Applications
Most Rich Internet Applications (RIAs) are currently accessible only to users visually interacting with the dynamic content. If Web developers properly exposed states and transitions of their Web sites, screen readers, crawlers, and tools for information filtering (Kawanaka et al., 2008) and automation (Borodin, 2008; Leshed et al., 2008) (Chapter 5) would be able to interact with the rich content. Unfortunately, Web applications are built with a variety of technologies and toolkits, many of which make RIA Web sites partially or completely inaccessible. Until recently, there have been two disjointed efforts to improve the accessibility of dynamic content by either manual or automatic authoring of metadata.
Manual approaches. The use of W3C standard for Accessible Rich Internet Applications (ARIA)6 was one of the first attempts to make RIAs accessible. ARIA markup is intended to be used by screen readers to improve accessibility of Web applications to blind people. ARIA metadata can be embedded into Web pages and can be used to describe live areas, roles, and states of dynamic content. Regrettably, most of the dynamic content available today does not implement the ARIA standard. Nor are Web developers likely to follow ARIA consistently, for they have not followed other accessibility guidelines.
ARIA can also be supplied as part of reusable components or widgets; for example, Dojo Dijit7 provides ARIA-enabled widgets and a toolkit to build custom accessible widgets. However, Dijit is only one of many available toolkits, and Web developers continue creating inaccessible custom widgets of their own. Another application of ARIA is through transcoding. To illustrate, Google’s Axs-JAX (Chen & Raman, 2008) allows Web developers to use JavaScript to inject ARIA metadata into existing applications. However, AxsJAX scripts have to be created manually so far.
Fully automated approaches. To date, the only known approaches to fully automated collection of information from Web applications have been crawling RIA Web sites statically or crawling RIAs by opening them in a Web browser (Mesbah et al., 2008). It is lamentable that both of these approaches have a number of limitations and cannot be used to make RIAs fully accessible in practice.
The majority of search engines index RIAs by statically crawling Web sites and extracting text from the HTML source code. With such crawling, one cannot effectively infer the implicit state model of the Web site. The results of indexing can be enhanced by content providers explicitly exposing textual data to Web spiders, such as through meta tags. However, content providers are not always aware of how to properly use meta tags to make content accessible to Web crawlers.
An alternative to the static crawling can be opening RIAs in a Web browser and simulating various user events on all objects to expose the resulting system events and hidden content. For instance, AJAX application crawling is described in (Mesbah, Bozdag, & Deursen, 2008; Frey, 2007), where diff algorithms are used to detect the changes. Dynamic changes can also be identified by combining a diff algorithm with HTML DOM mutation event listeners, as described in (Borodin et al., 2008a). Hypothetically, such AJAX crawling could automate metadata authoring. In reality, though, a crawler cannot often access all content, and it consumes substantial machine time, while suffering from: state explosion (Mesbah, Bozdag, & Deursen, 2008), irreversibility of actions (which requires that transitions be retraced from the start state), latency between actions and reactions (especially in AJAX applications), and inability to access password-protected Web sites.
The collaborative crawling approach described later in this chapter combines the manual and automated approaches to semiautomated generation of ARIA metadata.
Database integration
The Web domain and the Life Science domain are two of the most active domains among those integrating databases. Because these domains have many resources to handle (such as Web pages or genomes), and because those resources are often stored separately for each project, there exists a strong demand for data integration and data exchange.
The Semantic Web8 is a W3C initiative for integrating and exchanging Web resources. Web developers can use metadata, which are described in a Resource Description Framework (RDF)9 or the Web Ontology Language (OWL)10 to specify titles, publishers, meanings, and other semantic roles. By adding such metadata, applications handling RDF or OWL can interpret the meaning of Web resources, and handle resources with similar meanings as well. For example, if two online banking Web sites have the same semantic metadata, an application using such metadata can provide the same interface to both Web sites, even though they may use different visual layouts. Since metadata are written in one format, it is not necessary to convert the data format, which makes data exchange relatively easy. SA is also striving for standardization of formats; however, it does not require the complexity of the Semantic Web, and is currently using a database with a custom schema (Kawanaka et al., 2008).
In the Life Science domain, integrating databases is an active area of research. YeastHub (Cheung et al., 2005) is a project aiming to integrate many databases of yeast genomes stored separately in the past. Users can now search for yeast genome data in the YeastHub and obtain database tables or RDF that combine the data stored in separate databases. However, because the genome data formats are relatively fixed, and because the genome data is easy to convert, data integration is relatively uncomplicated. Social Accessibility schema try to accommodate a mixture of metadata that may be useful to a wide variety of systems.
SOCIAL ACCESSIBILITY11
Architecture and workflow of the SA framework
Social Accessibility (SA) (Takagi et al., 2008) is a collaborative framework that uses the power of the open community to improve the accessibility of existing Web content. SA unites end users and supporters who can collaboratively create accessibility metadata.
Until very recently, the general presumption has been that Web developers have primary responsibility for making Web pages accessible by embedding accessibility metadata such as alternative text, headings, ARIA, etc., into their content. Nevertheless, with the escalating amount of user-generated content, it has become clear that developers cannot be held solely responsible for content accessibility. At the same time, even though only end users have the ability to assess the real accessibility and usability of Web pages, there has been no systematic feedback loop from users to content providers. In our view, the Social Accessibility approach challenges this presumption.
Screen reader users with a variety of accessibility needs can participate in the Social Accessibility initiative by installing SA plug-ins for Firefox or Internet Explorer (IE) browsers. The plug-ins connect to the SA server, as shown in Figure 18.1, and every time the user visits a new Web page with Firefox or IE Web browsers, the plug-in retrieves the accessibility metadata from the Open Repository and transcodes the Web page by applying the metadata to the browser’s HTML DOM representation of the Web page. The users can then read the Web page using the assistive technology of their choice and enjoy the improved accessibility of the content. By using the End-User Tool, which is a standalone Windows application, users can report any remaining accessibility problems by creating service requests that are also stored in the Open Repository. The SA Web portal12 facilitates collaboration between supporters and end users and provides a forum for discussing problems and solutions.
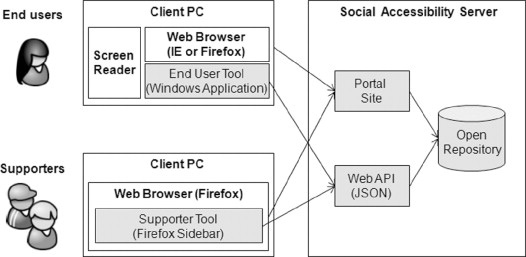
FIGURE 18.1
Basic architecture of the Social Accessibility service.
SA supporters are notified of incoming service requests through the Supporter Tool, which is a Firefox sidebar plug-in. The plug-in helps visualize user requests as well as any other accessibility problems. By using the plug-in, the supporters can act upon the requests and fix the accessibility problems. With every fix, the Supporter Plug-in submits the accessibility metadata to the SA Open Repository hosted on the Social Accessibility Server. Figure 18.2 shows the entire workflow: (1) a person with vision impairment reports an inaccessible image; (2) a supporter fixes the problem by adding alternative text; and (3) the end user listens to the alternative text of the image.
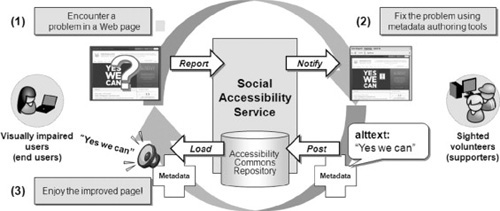
FIGURE 18.2
Workflow of Social Accessibility.
Accessibility assessment and visualization13
The Supporter Plug-in provides volunteers with the tools necessary for accessibility assessment of Web pages and visualization of user reports, including the User Request, Pagemap, and Quick Fix views.
The User Request view (Figure 18.3) shows recent problem reports and provides an easy interface for fixing the problems. Many reports are accompanied by a thumb-view snapshot of the Web page with the approximate position of the accessibility problem circled. This view also allows supporters to start a discussion and change the status of the request.
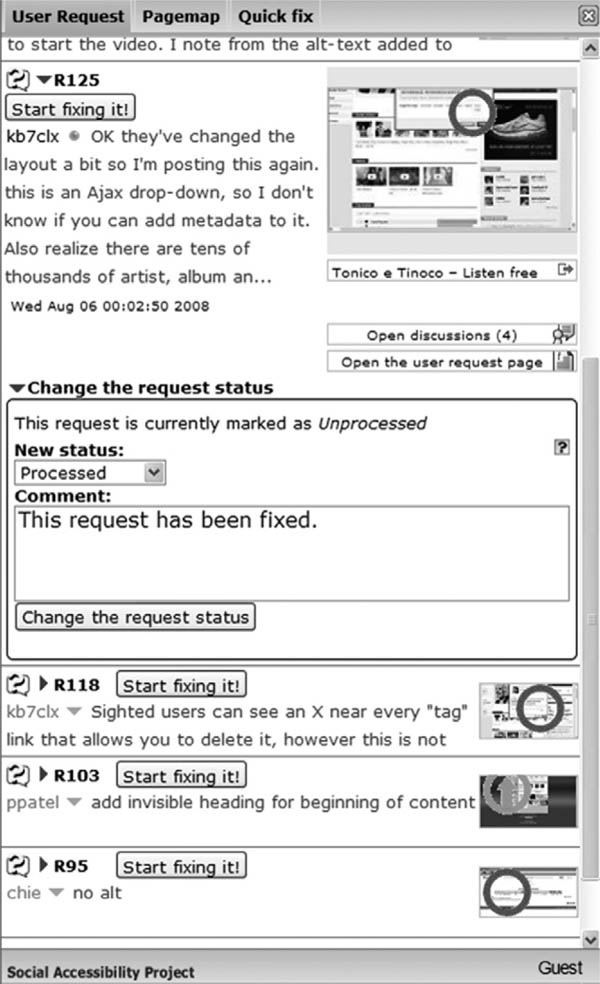
FIGURE 18.3
User Request view.
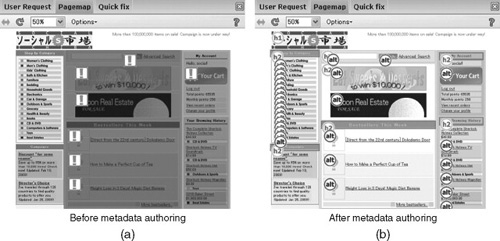
FIGURE 18.4
Pagemap editing tool.
Pagemap is a WYSIWYG-style editor for metadata authoring (Figure 18.4). The editor uses a brightness-gradation technique (Takagi et al., 2004) to visualize how long it would take a screen reader user to reach a certain part of the page, using darker colors for less accessible content. The editor uses exclamation marks to indicate inaccessible images without alternative text or with meaningless default alternative text such as “banner” or “spacer.” With the help of the editor, supporters can easily label elements as headings, provide text descriptions, or do both, by clicking on the exclamation marks. Figure 18.4a shows an inaccessible page before it was edited and Figure 18.4b – after it was renovated with Social Accessibility tools. Headings allow screen reader users to “jump” from one section of the page to another quickly, while alternative text ensures that users can read the labels of all images and image-links.
A Quick Fix view in Figures 18.3 and 18.4 displays a list of all images on the currently opened Web page and allows supporters to enter alternative text quickly.
Collaborative crawling
The current SA tools package enables manual metadata authoring. However, there is work under way to enable semiautomated and fully automated approaches to metadata authoring. The automated approaches can assist in creating metadata faster, while reducing both the expensive human effort and the minimum required accessibility knowledge on the part of the supporters.
The SA tools can provide an interface for manual authoring of ARIA-style metadata, such as live areas, relations between Web objects, object roles, etc. The ARIA-style markup will allow applications such as Web crawlers and screen readers to identify and correctly handle dynamic content, as well as identify states and transitions in Rich Internet Applications (RIA). However, creating ARIA-style annotations manually requires that supporters understand what dynamic content is and have more than basic knowledge of Web accessibility. Therefore, the process of authoring metadata could be greatly facilitated by semiautomated approaches such as collaborative crawling (Aggarwal, 2002) and could offer significant help to both Social Accessibility users and volunteers.
The collaborative crawling technique enables the discovery of the underlying structure of the Web by mining the browsing traces of a multitude of users. Although the original approach was employed for standard Web crawling between Web pages (Aggarwal, 2002), the SA tool for collaborative crawling (CCrawl14) mines user browsing behavior within Web pages to identify dynamic content. The approach delegates the discovery of dynamic content to regular computer users, with the expectation that, eventually, the users will try all allowable actions (transitions) and experience all possible system reactions. This approach will allow the SA volunteers to create ARIA-style metadata while performing their regular browsing activities. In the process, the volunteers act, in a way, as “distributed spiders” crawling the Web and discovering dynamic content.
By analyzing user actions and system reactions on a given Web page, it is possible to automatically infer ARIA metadata for live areas (e.g., dynamic stock ticker) and actionable objects (e.g., dragable), identify relations between objects (e.g., hover the mouse to open the menu), and even infer element roles (e.g., slider). Observing multiple users performing the same action will only improve inference confidence. The derived metadata can then be shared through the SA network and used by SA clients, such as screen readers with ARIA support or Web spiders for intelligent crawling of RIA sites.
Figure 18.5 illustrates a simple inference example on Amazon.com. When the user hovers the mouse over the dynamic menu (A), a “mousemove” event is triggered in the browser’s DOM. The event is then caught by the underlying JavaScript, which displays a hidden submenu (B), which in turn triggers a “DOMAttrModified” event. By analyzing the sequence of user—system events and the resulting system reactions, it is possible to infer that (B) is a live area and (A) controls (B). This information can then be stored in the SA open repository. When a blind person visits the Amazon Web site, its Web pages can be transcoded to incorporate the correct ARIA markup. Then, with any screen reader that supports ARIA, the user will be able to expand the “Books” submenu and will have a usable interface to locate and review the submenu.
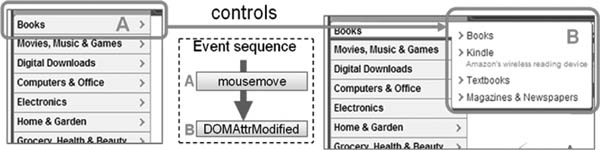
FIGURE 18.5
Discovering live areas and inferring relations on Amazon.com.
Metadata representation and Accessibility Commons15
The metadata generated by the Social Accessibility framework are stored in the Accessibility Commons (AC) database (Kawanaka et al., 2008). The metadata schema was defined in a collaborative effort of several research projects described in the next subsection, with the goal of unifying disparate schemas used by the projects and providing for future needs of these and other projects.
The AC schema includes three main components: Semantics, URI Addressing, and Element Addressing. The Semantics component describes the meaning of the metadata (e.g., level-1 heading, “news”); the URI Addressing specifies the target URI of the documents, for which the metadata were generated; and the Element Addressing is the reference to the HTML elements where the metadata have to be applied (e.g., XPath16 address). Table 18.1 illustrates a sample metadata record suggesting that the HTML DIV element with the specified XPath be marked as a level-1 heading on all root-level HTML pages of the example.com Web site.
Because the metadata does not specify how exactly Web pages need to be transcoded, each Social Accessibility client application can interpret the metadata in its own way. Each metadata record also contains other information such as author, creation date, etc. The full schema definition can be found in (Kawanaka et al., 2008).
Client-side applications, such as metadata authoring tools (Takagi et al., 2002; Harper et al., 2006), and assistive technologies (Borodin et al., 2007) can access the AC Open Repository (Figure 18.1) using the Hyper-Text Transfer Protocol (HTTP). A client can submit metadata by posting it in JSON format (Kawanaka et al., 2008) and can retrieve metadata by sending a request with the URIs of the Web page and the images of that page. Figure 18.6 outlines the process of metadata retrieval from the AC repository.
First, the client application sends the query with URI of the current Web page to the AC server via the HTTP. Upon its arrival to the AC server, the URI is processed using an automaton-based index, which returns the metadata IDs matching the queried URIs. The metadata records are then retrieved from the database using the metadata IDs. Finally, the metadata records are sent back to the client computer and are used to transcode the Web page.
Type |
Volue |
Data Type |
H1 |
Data Descr |
news |
URI Type |
wildcard |
URI Pattern |
|
Address Type |
xpath |
Address |
/HTML[1]/BODY[1]/DIV[1]/DIV[2] |
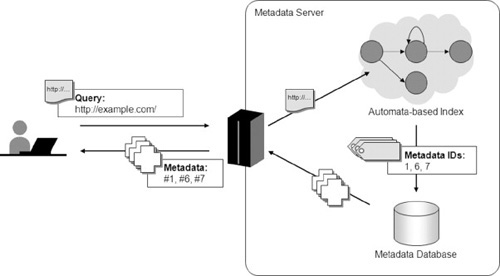
FIGURE 18.6
Retrieving AC metadata.
Automaton-based indexing
The AC database is queried on the URI addresses, which can be represented with wildcards and regular expressions. As this kind of indexing is not implemented by typical database systems, AC employs a custom-made automaton-based index similar to that described in (Chan, Garofalakis, & Rastogi, 2002), which can identify all matching URI patterns using a nondeterministic finite state automaton. The index is created by converting a URI pattern to an automaton and then merging the automaton with the index automaton. The final states of the index automaton are associated with metadata IDs, which are accepted in those states, so that all of the metadata matching a URI can be retrieved by running the automaton once. The index automaton technique has greatly reduced the search times for metadata; with the current database containing around 100,000 records, the requested metadata can be found in microseconds.
Uniting disparate accessibility metadata
A number of existing accessibility research projects and products are using disparate metadata, a thorough understanding of which informed the design of the Accessibility Commons (AC) database schema, which hopefully ensured that the schema could be used by these projects and remain relevant as new projects and products are developed.
aiBrowser. The aiBrowser (Miyashita et al., 2007) is a multimedia browser for visually impaired people. The browser transcodes HTML documents and Adobe Flash17 on the client side to provide alternate content that is more accessible for visually impaired people. The transcoding is done using metadata described in XML. The metadata describe how to combine HTML elements and Flash objects to generate more accessible alternate content. In the metadata, XPath expressions are used to specify HTML elements, and Flash queries are used to specify Flash objects. In addition, the aiBrowser allows users to add manual annotations for headings and alternative text. If the aiBrowser were to use a common repository, it could share its metadata and user annotations to provide alternative text and heading tags to people using other technologies.
HearSay. The HearSay nonvisual Web browser (Ramakrishnan, Stent, & Yang, 2004; Borodin et al., 2007; Mahmud, Borodin, & Ramakrishnan, 2007; Borodin et al., 2008b; Mahmud, Borodin, & Ramakrishnan, 2008) uses various content analysis techniques to improve Web accessibility, among which are context-directed browsing for identification of relevant information in Web pages (Mahmud, Borodin, & Ramakrishnan, 2007), language detection (Borodin et al., 2008b), concept detection (Mahmud, Borodin, & Ramakrishnan, 2008), etc. HearSay uses the results of the automated analyses to annotate Web content. For example, the context-directed browsing algorithm inserts a “start” label, instructing the browser to begin reading the page from a specific position. The HearSay browser has a VoiceXML-based dialog interface, which interprets the labels and provides facilities for navigating, editing, and creating manual labels, which can be stored in personal or shared repositories. The use of uniform metadata and a shared repository allows other applications to benefit from the labels created in HearSay. At the same time, future HearSay users will have access to metadata created by a wider pool of blind Web users.
WebInSight for Images. WebInSight for Images (Bigham et al., 2006) provides alternative text for many Web images to improve their accessibility. To make this alternative text, WebInSight uses contextual analysis of linked Web pages, enhanced Optical Character Recognition (OCR), and human labeling. The alternative text strings are stored in a shared database referenced by an MD5 hash of the image and the URL of the image. The stored alternative text is supplied as users browse the Web. When a user visits a Web page for the first time, WebInSight attempts to create alternative texts by doing contextual analysis and OCR. If these options fail, the user can request human labeling. By combining the alternative text into a common database, users will be more likely to experience the benefits.
Site-wide Annotation. Site-wide Annotation (Takagi et al., 2002) is a research project to transcode entire Web sites by annotating them. The metadata of the Site-wide Annotation use XPath expressions. The system checks for elements matching the expressions and transcodes the Web pages based on the metadata. This enables transcoding of an entire Web site with a small set of metadata. If this metadata could be created and shared by users, a larger number of Web sites would be transcoded for better Web accessibility.
AxsJAX. AxsJAX (Chen & Raman, 2008) is an accessibility framework to inject accessibility support into Web 2.0 applications. At present, the main targets of AxsJAX are Google applications such as Gmail and Google Docs. AxsJAX scripts use Greasemonkey or a bookmarklet, or run directly in Fire Vox,18 a nonvisual Web browser implemented as a Firefox browser extension. AxsJAX uses XPath to connect ARIA markup to the corresponding Web page elements. Currently, these associations are distributed to users in the form of scripts. More tools could benefit from the semantic knowledge encoded in these scripts if they were stored in a more flexible and semantically accessible common repository.
Accessmonkey. Accessmonkey (Bigham & Ladner, 2007) is another common scripting framework that Web users and developers can use to improve Web accessibility collaboratively. The goal is to enable both Web users and developers to write scripts that can then be used to improve the accessibility of Web pages for blind Web users.
Structural semantics for Accessibility and Device Independence (SADIe). SADIe (Harper, Bechhofer & Lunn, 2006) is a proxy-based tool for transcoding entire Web sites as opposed to individual pages. It relies on ontological annotations of the Cascading Style Sheet (CSS) to apply accurate and scalable transcoding algorithms broadly. Only by explicitly enunciating the implicit semantics of the visual page structure (groups, components, typographic cues, etc.) can we enable machine understanding of the designers’ original intentions. These intentions are important if we wish to provide a similar experience to visually impaired users as we do to fully sighted users. SADIe can be regarded as a tool for the site-wide reverse engineering of Web pages to achieve design rediscovery (Chikofsky & Cross, 1990).
JAWS. JAWS is one of the most popular screen readers, which has a labeling feature and allows users to provide alternative text for images or flash objects. The latest version of JAWS can make use of WAI-ARIA, a World Wide Web Consortium (W3C) internal metadata standard, to improve the accessibility of dynamic content.
Social Accessibility pilot service19
The Social Accessibility pilot service was launched in the summer of 2008. In the 10 months of the service being in use, its supporters resolved 275 service requests, creating over 18,000 metadata records for 2930 Web pages. Table 18.2 shows the frequencies of metadata types created by the users. The majority of annotations were alternative text and headings (levels 1-6). Users and supporters together labeled 122 “landmarks” (new destinations added for navigation within a page), removed 119 headings, and created 17 metadata records about ARIA and specialized script metadata for DHTML.
Metadata Type |
Count |
Alternative text |
11,969 (65%) |
h+ (h1-6) |
6069 (33%) |
Landmark |
122 (1%) |
h- |
119 (1%) |
Others |
17 (0%) |
Total |
18,296 (100%) |
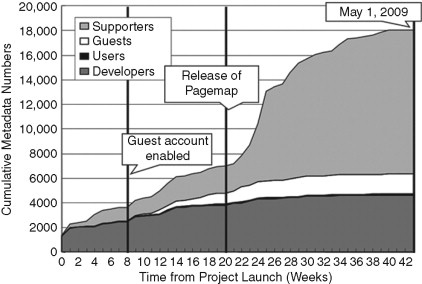
FIGURE 18.7
Historical activity of SA participants.
Figure 18.7 shows the activity of authoring the accessibility metadata over the 42 weeks since the SA service was launched. The horizontal axis shows the time, and the vertical axis shows the cumulative number of metadata records created by each category of participants. The SA development team members were initial supporters who reduced their activities over time to encourage other participants. Some of the activities were the addition of landmarks and alternative text by the end users. Some of the contributions were made by SA guests, with the majority of activities being metadata authoring by the registered supporters after the Pagemap visualization release (Figure 18.3).
The majority of requests were for alternative text (124), headings (80), and questions about content (43). The remaining requests included forms, landmarks, Flash, color, CAPTCHA, DHTML, etc. Almost half (45%) of the requests were resolved within a single day. The supporters were not able to resolve 19 requests (5.9%), primarily because SA was not yet handling DHTML and Flash at that time.
CHALLENGES AND FUTURE WORK
A number of challenges will have to be eventually overcome to ensure continued effectiveness and value of the Social Accessibility network. The problems involve breakages of metadata due to site changes, conflicts between different metadata records, database performance, possibility of spam metadata, security and privacy of SA users, interface complexity, incentive systems, collaboration with content providers, etc.
Conflicts and broken metadata
The metadata accumulated in the AC database may eventually accrue conflicts; for example, two different versions of alternative text may be supplied for the same image. Also, the repository may contain broken metadata, such as that due to changes in the target Web pages. Currently, the SA infrastructure does not detect any conflicts or broken metadata and returns all metadata fetched by the query, leaving the metadata filtering task to the client application. It is our hope that, with a large number of participants, metadata errors may be quickly identified, reported, and fixed. However, techniques need to be developed for discarding or fixing broken metadata, as well as for metadata ranking and filtering. For instance, the user’s own metadata can be given the highest priority, followed by human-authored and then machine-generated metadata. A ranking system can be employed to resolve conflicts based on supporters’ reputations. Further, metadata filtering can be based on the user’s locale, preferences, context, etc.
Database performance
It is expected that millions of metadata records will be accumulated in the AC repository; therefore, low-latency database performance is crucial to the SA infrastructure. Automaton-based indexing, briefly discussed in this chapter, is the first step to improving the response time of the SA service. With the growing number of metadata records, another source of latency will be the amount of data sent back to clients for every query. One way to reduce the amount of SA traffic is to filter the metadata on the AC server side before sending it to the client. For example, metadata conflicts can be resolved on the server side.
Security, privacy, and spam
Any successful system is eventually attacked by spammers, hackers, or both. For example, spammers may try to insert a large number of ads instead of the useful metadata. It may be possible to reduce the damage by introducing some protection mechanisms, such as a limited number of queries per second, limited size of labels, etc. A reputation system can further help identify and remove offending accounts and records.
Privacy protection, in part, always depends on the common sense of the users. For example, for reasons of safety, users should not knowingly submit any personal information as part of the metadata. For the same reason, in order to protect personal information, SA should not use textual content as a method of addressing HTML elements on the page. Nonetheless, when the user reports an error, a snapshot of the browser’s content and the reading position are automatically captured and sent to the SA server. This functionality enables the supporters to understand the problems faced by the user; however, it may inadvertently violate user privacy by capturing such personal information as bank account numbers. To address this concern, screenshots have to be blurred or blacked out, to make them illegible yet preserve the visual structure of the page, before being submitted to the server. It may also be necessary to block screen capture of secure pages that use the HTTPS protocol.
Metadata authoring skills
A successful collaborative system should require minimal technical skills and contribution from its users, while providing maximum benefits. The current pilot system20 requires that supporters have minimal knowledge about Web accessibility, such as the appropriateness of headings and alternative text. Both SA novice supporters and users can easily learn about the SA tools and services. However, the inclusion of more types of metadata will invariably increase the complexity of the interface. For example, the inclusion of the simplest ARIA metadata will require that supporters know about dynamic content and understand relationships between objects, thus complicating the interface required for selecting objects. Therefore, it is important to continue developing semiautomated and fully automated approaches to metadata authoring. Collaborative crawling is one of such promising approaches that would require no work whatsoever on the part of the user.
Effectiveness of incentives
SA employs a simple scheme for ranking supporters based, primarily, on the number of metadata records contributed to the system. The informal feedback from both users and supporters confirmed the importance of the incentive system. Supporters also remarked that the most effective rewards are the appreciative comments from end users. Ranking supporters on the SA portal Web site also motivated them to remain active on the system. As noted earlier, ranking can also help with metadata conflict resolutions. It is important to further develop the ranking mechanism to consider more parameters, such as end user appreciation, and measure the supporter’s reactions.
Collaborating with content providers
Accessibility renovation work is too often reduced to the task of fixing the errors reported by automatic accessibility checkers. The SA approach may reduce the burden placed on site owners through the power of the community, which does not mean, however, that content providers can now ignore accessibility issues. Instead, the centralization of the metadata should encourage site owners to pay more attention to accessibility and, hopefully, renovate their sites to be more accessible. The SA system can change that by automatically summarizing, organizing, and delivering accessibility information to content providers with suggestions on how to incorporate metadata into Web sites.
In addition to resolving immediate accessibility problems, the reported issues can be regarded as the results of volunteer-based Web site usability testing by real users. The created metadata can also be regarded as volunteer-based consulting for accessibility improvements. In other words, the SA network is a system of collective intelligence for end users, volunteers, site owners, and everyone who has an interest in the accessibility of the Web. The Social Accessibility network will soon provide a portal for content providers, where site owners will be able to obtain a summary of accessibility problems on their Web site and a set of objective instructions on how to fix these problems. The products of the collaborative authoring process – metadata, discussions, and site-specific rules for metadata – will present invaluable information for effective renovations by site owners.
Another possible scenario is to enable content providers to transcode their Web pages on the fly for every Web page fetched from the Web server, in which case users may not even be aware of the mechanism improving Web accessibility. This approach would also improve the compliance of the Web site, since the improvement is taking place on the server side. A similar approach to dynamic transcoding of Web pages using a JavaScript library is already employed by Google’s AxsJAX technology (Chen & Raman, 2008).
SUMMARY
This chapter discussed several collaborative approaches to improving Web accessibility and overviewed the challenges in Web accessibility. To reduce the burden on site owners and shorten the time to improved accessibility, we introduced Social Accessibility – a framework that can make the Web more accessible by gathering the power of the open community. The approach is characterized by collaborative metadata authoring based on user requests. Any Web user with a disability can report Web accessibility problems to the Social Accessibility service, and any Web user can volunteer to fix the accessibility problems without modifying the original content. We also discussed the collaborative crawling approach that can improve accessibility of Rich Internet Applications for screen readers, Web crawlers, and other software tools that need to interact with dynamic Web content.
With the growing popularity of social computing, the Social Accessibility approach has the potential to grow into a worldwide collective intelligence for Web accessibility, and contribute to changing the access environments of users with disabilities worldwide.
This work is based on earlier work: (Kawanaka et al., 2008; Takagi, et al., 2008; Takagi, et al., 2009).
Intended users: |
All users, but specifically assistive technology users |
Domain: |
All Web sites |
Description: |
Social Accessibility (SA) is a collaborative framework that uses the power of the open community to improve the accessibility of existing Web content. SA brings together end users and supporters who can collaboratively create and utilize the accessibility metadata. |
Example: |
John, a blind screen reader user, tries to make a purchase on a Web site, but encounters some accessibility problems, which he reports to the Social Accessibility network. In response to John’s request, supporters create accessibility metadata by providing labels for inaccessible content, such as image buttons without alternative text, form elements without labels, etc. The next time John or any other screen reader user visits the Web page they will find the Web page fully accessible. The administrator of the inaccessible Web site can get an overview of the accessibility problems found on the Web site and incorporate the metadata directly into the Web site source code. Software tools such as crawlers and wrappers can also use the metadata to perform their tasks more efficiently. |
Automation: |
No, but the metadata can be used by automation tools. |
Mashups: |
No, but the metadata can be used by mashup tools. |
Scripting: |
No, but there is a user interface for authoring metadata. |
Natural language: |
No. |
Recordability: |
No. |
Inferencing: |
No. |
Sharing: |
The system facilitates collaborative authoring and usage of accessibility metadata for Web sites. |
Comparison to other |
No clear similarities to other systems. |
systems: |
|
Platform: |
Mozilla Firefox and Internet Explorer browsers |
Availability: |
The browser plug-ins may be downloaded from: http://sa.watson.ibm.com/. |
1Web Content Accessibility Guidelines (WCAG) Specifications: http://www.w3.org/TR/WCAG10/.
2Accessible Rich Internet Applications (ARIA) Specifications: http://www.w3.org/TR/wai-aria/.
3Google Image Labeler: http://images.google.com/imagelabeler/.
4JAWS, Freedom Scientific Inc.: http://www.freedomscientific.com/.
5Cascading Style Sheet (CSS): http://www.w3.org/TR/CSS2/.
6Accessible Rich Internet Applications (WAI-ARIA): http://www.w3.org/TR/wai-aria/.
7Dojo Dijit: http://dojotoolkit.org/projects/dijit.
8OWL Web Ontology Language: http://www.w3.org/TR/owl-features.
9Resource Description Framework (RDF): http://www.w3.org/RDF.
10OWL Web Ontology Language: http://www.w3.org/TR/owl-features.
11For further details about the SA approach, please see (Takagi et al., 2008).
12Social Accessibility Project: http://sa.watson.ibm.com.
13The readers are invited to read the user guide and try the tools: http://sa.watson.ibm.com/getting_started/using_the_pagemap.
14The CCrawl tool is currently a concept prototype and is piloted separately from the main SA tools.
15More details on the Accessibility Commons database can be found in (Kawanaka et al., 2008).
16XML Path Language (XPath): http://www.w3.org/TR/xpath.
17Adobe Flash: http://www.adobe.com/products/flash.
18Fire Vox: A Screen Reading Extension for Firefox: http://firevox.clcworld.net/.
19More details on the pilot service can be found in (Takagi et al., 2009).
20Social Accessibility Project: http://sa.watson.ibm.com.