
Protection through isolation
Virtues and pitfalls
Johanna Ullrich; Edgar R. Weippl SBA Research, Vienna, Austria
Abstract
Multitenancy is a key feature of cloud computing which has become a major concept recently. Nevertheless, sharing resources among a number of customers who are unknown to each other implies certain risks. While isolation is a strong means of mitigation, it also challenges a number of the main principles of cloud computing. Cloud computing looks to maximize resource use and isolation comes always at a cost, leaving few resources for the actual desired computation. In this chapter, we discuss the topic of hypervisor isolation by the example of networking. This includes the discussion of hypervisor architectures and mechanisms of isolation considering networking. Identifying the attack surface, an inventory of network-based attacks exploiting hypervisor isolation and possible countermeasures are presented.
1 Introduction
Cloud computing has emerged from a combination of various technologies (primarily virtualization, increased networking capabilities, and large storage devices) and has led to significant cost reductions based on economy-of-scale effects. Beyond hardware, noncomputational resources such as maintenance staff or air conditioning are also shared, leading to multitenancy being a key feature of cloud computing. However, sharing’s negative impacts on security among coresiding parties are often glossed over in discussions of cloud computing. This is of particular interest on public clouds because your neighbor is unknown to you. As it is generally easy to subscribe to cloud services, malicious parties are also able to settle within the cloud. Once there, they may seek to exploit other users from their privileged starting position, targeting the collection of private information using covert channels or taking over their neighbors via hypervisor exploits. The main mitigation strategy against these hazards is distinct isolation between instances, provided by the hypervisor, although the quality of isolation is far from being absolutely reliable and varies significantly. Although it is the cloud provider’s responsibility to protect its customers from each other, it is also highly important for the latter to know of the drawbacks of isolation across various hypervisors in order to deal accordingly with the given environment.
In the case of cloud computing, networking capabilities will inevitably provide access to nodes with the appropriate basics for most hosted applications. Sharing usually one network interface card among a number of virtual hosts causes distinct limitations, e.g., the inability to send at the same time, delays due to the intermediate hypervisor or interference with inherent protocol features. While this may play only a minor role in inferring the existence of virtualization, it becomes a serious issue in case certain parameters can be influenced by other parties to determine coresidency of virtual instances, deanonymize internal addresses or gain secret information. The latter case unquestionably raises serious security and privacy risks. As the prohibition of network access is impractical due to its importance, network isolation plays a major role in instance isolation generally.
This chapter investigates the topic of instance isolation in clouds and illustrates the matter in detail through the example of networking. In a first step, we investigate the mechanisms which are intended to provide proper isolation among coresiding instances and familiarize ourselves with the overview and specifics of general hypervisor architecture through the example of the open-source implementations Xen and KVM.
We focus on how hypervisors handle sharing of the networking resources among a number of virtual instances and discuss inherent challenges such as network scheduling to determine which node’s packets are allowed to send at a certain point in time, or traffic shaping to restrict an instance to a certain bandwidth. Then, we identify potential attack surfaces and emphasize a discussion on how shared networking can be exploited. This is accompanied by an inventory of currently known attacks analyzing the exploited attack vectors.
Although full isolation seems to be utterly impossible considering the vast attack surface and the need for networking, we develop strategies for mitigation of isolation-based threats and discuss their limitations. Finally, we draw conclusions on the most important aspects of cloud computing and highlight inevitable challenges for cloud security research.
2 Hypervisors
Hypervisors, or also virtual machine monitors (VMMs), are pieces of software that enable multiple operating systems to run on a single physical machine. Although a key enabler for today’s success of cloud computing, virtualization has been an issue in computer science for at least four decades (e.g., Goldberg, 1974). Here, we discuss different hypervisor architectures and present the architecture of common implementations before focusing on their networking behavior.
2.1 General architectures
A hypervisor provides an efficient, isolated duplicate of the physical machines for virtual machines. Popek and Goldberg (1974) claimed that all sensitive instructions, i.e., those changing resource availability or configuration, must be privileged instructions in order to build an effective hypervisor for a certain system. In such an environment, all sensitive instructions cross the hypervisor, which is able to control the virtual machines appropriately.
This concept is today known as full virtualization and has the advantage that the host-operating system does not have to be adapted to work with the hypervisor, i.e., it is unaware of its virtualized environment. Obviously, a number of systems are far from perfect and require a number of additional actions in order to be virtualizable, leading to the technologies of paravirtualization, binary translation, and hardware-assisted virtualization (Pearce et al., 2013).
Paravirtualization encompasses changes to the system in order to redirect these nonprivileged, but sensitive, instructions over the hypervisor to regain full control on the resources. Therefore, the host-operating system has to undergo various modifications to work with the hypervisor, and the host is aware that it is virtualized. Applications running atop the altered OS do not have to be changed. Undoubtedly, these modifications require more work to implement, but on the other hand may provide better performance than full virtualization which often intervenes (Rose, 2004; Crosby and Brown, 2006). The best-known hypervisor of this type is Xen (Xen Project, n.d.).
Hardware-assisted virtualization is achieved by means of additional functionality included into the CPU, specifically an additional execution mode called guest mode, which is dedicated to the virtual instances (Drepper, 2008; Adams and Agesen, 2006). However, this type of virtualization requires certain hardware, in contrast to paravirtualization, which is in general able to run on any system. The latter also eases migration of paravirtualized machines. A popular representative for this virtualization type is the Kernel-based Virtual Machine (KVM) infrastructure (KVM, n.d.). Combinations of the two techniques are commonly referred to as hybrid virtualization.
Binary translation is a software virtualization and includes the use of an interpreter. It translates binary code to another binary, but excluding nontrapping instructions. This means that the input contains a full instruction set, but the output is a subset thereof and contains the innocuous instructions only (Adams and Agesen, 2006). This technology is also the closest to emulation, where the functionality of a device is simulated and all instructions are intercepted. The performance is dependent on the instructions to translate. VMware is an example of virtualization using binary translation (VMware, n.d.).
Hypervisors can also be distinguished by their relation to the host-operating system. In the case where the hypervisor fully replaces the operating system, it is called a bare-metal or Type I hypervisor, and where a host-operating system is still necessary, the hypervisor is hosted, or of Type II. Classifying the aforementioned hypervisors: Xen and KVM are both bare-metal—VMware ESX also, but its Workstation equivalent is hosted. Most workstation hypervisors are hosted as they are typically used for testing or training purposes.
2.2 Practical realization
Table 1 provides an overview on leading public cloud providers and their preferred hypervisor. Three specific hypervisors are frequently used: KVM, Xen, and VMware vCloud, and so we will focus on these when discussing implemented architectures. KVM and Xen are both open-source products and full insight into their behavior is provided; due to this, they have been extensively studied in the scientific literature, especially Xen. Their counterpart vCloud is a proprietary product. We would have to rely on its documentation, and therefore, exclude it from in-depth investigation.
Table 1
Leading cloud providers and hypervisors
| Hypervisor | Cloud providers |
| Azure Hypervisor | Microsoft Azure |
| KVM | Google Compute Engine, IBM SmartCloud, Digital Ocean |
| vCloud | Bluelock, Terremark, Savvis, EarthLinkCloud, CSC |
| Xen | Rackspace Open Cloud, Amazon EC2, GoGrid |
Xen is the market’s old bull. Although being the typical representative for paravirtualization, it is nowadays also capable of hardware-assisted virtualization. Being a bare-metal hypervisor it resides directly above the hardware as depicted in Figure 1. The hypervisor itself performs only basic operations, such as CPU scheduling or memory management. More complex decisions are transferred to Domain0, a privileged virtual machine with rights to access physical I/O and interact with the other virtual instances. Domain0 runs a Linux kernel running the physical drivers and provides their virtual representations. The guests run in their own domains, DomainN, and access I/O devices like disk by means of Domain0’s abstractions. This approach has the advantage that physical drivers have to be available only for the OS used in Domain0. (Barharm et al., 2003; Pratt et al., 2005)
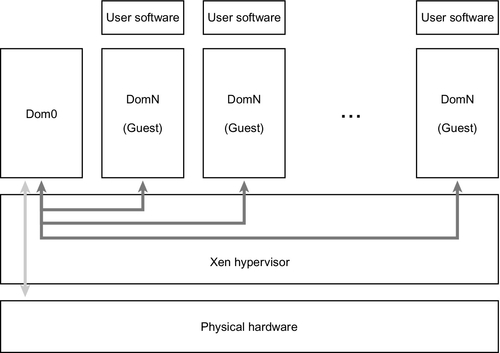
The host and guest notify each other by means of hypercalls and events. Hypercalls are comparable to system calls and allow the domain to perform privileged instructions by trapping into the hypervisor. Communication in the opposite direction is done by asynchronous events: Pending events are indicated in bit masks before calling the host via callback. Data transfer is performed with descriptor rings which refer to data buffers. These kinds of ring buffers are filled by domains and the hypervisor in a producer-consumer manner. (Barharm et al., 2003)
As mentioned in the previous chapter, paravirtualization requires modification of the guest-operating system. A variety of Linux and BSD distributions are supported as they require few changes; however, for Windows, it is recommended to use hardware-assisted mode (DomU Support, 2014).
KVM is short for Kernel-based Virtual Machine Monitor. Being developed later than Xen, it relies heavily on CPU virtualization features. Beyond kernel and execution mode, these CPUs provide an additional mode—guest mode. In this mode, system software is able to trap certain sensitive instructions guaranteeing the fulfillment of Popek’s requirements.
As depicted in Figure 2, the hypervisor itself is a Linux kernel module and provides a device node (/dev/kvm). It enables the creation of new virtual machines, running and interrupting virtual CPUs, as well as memory allocation and register access. During the hypervisor’s development, reusability of existing Linux technology was important, e.g., CPU scheduling, networking or memory management. This way, KVM is able to profit from the collective experience included in the operating systems and benefit from future improvements. Virtual machines are ordinary Linux processes having their own memory and are scheduled onto the CPU as is every other process. (Kivity et al., 2007; Redhat, 2008)
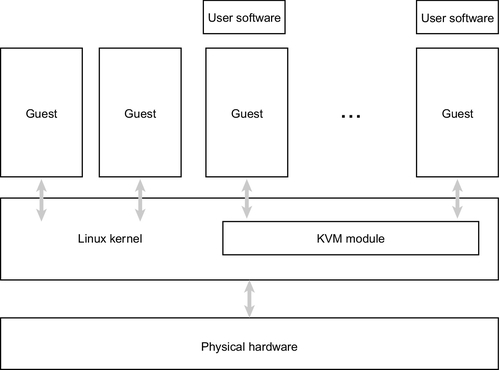
For I/O, two mechanisms are available: programmed I/O (PIO) traps privileged CPU instructions for I/O of the virtualization extension, whereas memory-mapped I/O (MMIO) means using the same instruction for device access as for memory access. All accesses lead to a switch from guest to kernel mode, but finally I/O processing is executed in guest mode by means of a device model. Communication from the guest to the host is possible via virtual interrupts, trigged by the hypervisor after an ordinary hardware interrupt from a device (Kivity et al., 2007).
KVM has been included into the 2.6 kernel and is thus available in practically all Linux distributions. Unlike Xen, the plain hardware-assisted alternative does not require changes to guest-operating systems. However, today there are also paravirtualized device drivers available for I/O interfaces for performance improvement as the PIO and MMIO require mode switching (Kivity et al., 2007).
3 Shared networking architecture
A virtual network interface on its own is not enough. Successful communication requires also a network—plugging a virtual cable into the virtual interface. Numerous possibilities exist: an internal virtual connection only, a virtual network equipment on the data layer (virtual bridge or switch) or the transport layer (virtual router), as well as Network Address Translation. The first is unusual for cloud services as the nodes are required to be accessible from the outside. In public clouds, it would not even be possible to access your instances for management issues despite paying for them. However, it is more commonly used on workstation hypervisors.
Despite the variety of options, the majority of tutorials recommend bridging. In this case, the hypervisor forwards all packets unaltered and puts them on the physical network. From the guest’s point of view, they seem to be directly connected to the network.
Irrespective of the specific architecture, network traffic from a number of virtual instances has to be multiplexed before reaching the physical network, and this raises the question of adequate sharing. On one hand, an instance’s share of bandwidth should be more or less constant over time. On the other hand, interactive tasks, e.g., a Web server, are less affected by a reduced bandwidth than scarce responsiveness due to latencies. While private clouds might be able to adapt to certain needs, public cloud providers targeting a diverse mass of customers cannot. Thus, hypervisors in general target a balance between throughput and responsiveness by means of an adequate packet-scheduling policy. Beyond ordering packets ready to be sent onto the physical wire, traffic shaping is a second important aspect regarding cloud networking. A physical node is shared among instances which do not necessarily have to be of the same performance, which may, for example, vary based on purpose or the owner’s financial investment, and instances’ bandwidth is limited by means of traffic shaping. We will discuss the two issues network scheduling and traffic shaping in-depth.
3.1 Packet scheduling
A scheduling algorithm decides in which order packets of various guests are processed and is thus an important part of hypervisor performance. A number of different CPU scheduling algorithms exist to support a variety of applications. Some hypervisors additionally implement specific packet schedulers. As a consequence, the hypervisor architectures may lead to varying packet sequences.
With KVM which aims to minimize changes to ordinary Linux, virtual instances are scheduled on the CPU like is any other process, e.g., a server daemon or your text processor. Irrespectively, the kernel is asked to run these instances in guest mode—the certain kernel mode that has been added for virtualization support.
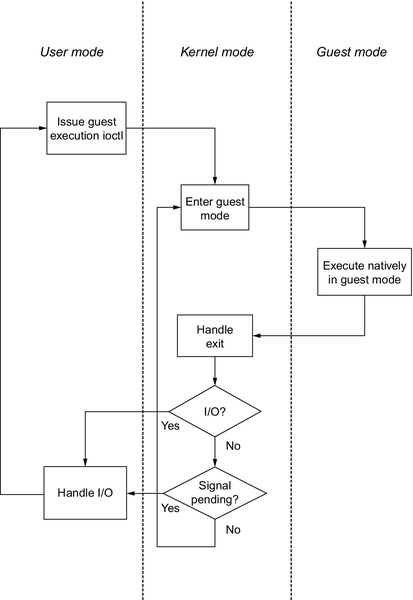
Guest mode is exited and kernel mode entered if an I/O instruction or external signals occurs. The I/O itself is then handled in user mode. Afterwards, user mode again asks the kernel mode for further execution in guest mode. This is also depicted in Figure 3. Frequent mode switches, however, are time consuming and lead to negative impacts on performance. (Kivity et al., 2007) In conclusion, the chosen CPU scheduler directly impacts the order of packets being sent in KVM.
In contrast, Xen hypervisor uses dedicated packet scheduling in addition to CPU scheduling due to its standalone architecture (Figure 4). Every virtual instance contains a netfront device which represents its virtualized network interface and is further connected to its counterpart in privileged Domain0. Interfaces with pending packets to be sent are registered in netback’s TX queue. At a regular interval, a kernel thread handles these packets in round-robbing style. It takes the first pending device, processes a single pending packet, and then inserts the device again at the queue’s end if further packets are available. The number of processed packets per round is limited in dependence of the page size. The processed packets are forwarded to a single queue and are processed for the time of two jiffies.
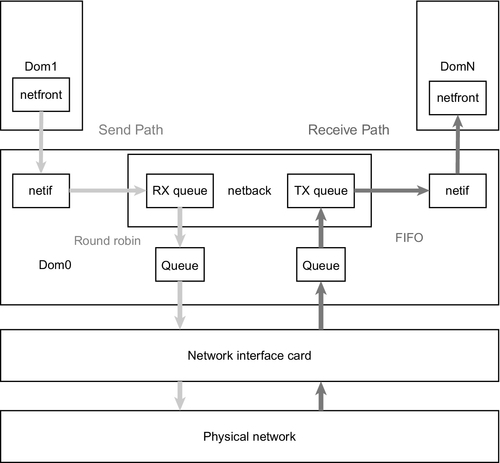
Receiving packets is less complex: The netback driver holds an RX queue containing all packets addressed to virtual instances. They are processed according to the first-input-first-output principle and delivered to the adequate device. The number of maximum processed packet per round is limited to the same page-size-related number as for sending. Forwarding is handled by the same kernel thread mentioned above. Per round, the thread handles packet receiving prior sending (Xi et al., 2013; Fraser, 2005).
The XEN scheduler is simple and vastly fair among instances, but does not allow to prioritize traffic over others due to its single queue ton the packets’ way to the physical network. The packet-wise quantum for round-robin, however, targets to maintain high bandwidth for large data transmission and short latency for responsive tasks. CPU scheduling still affects packet ordering, e.g., due to inserting interfaces into the netback RX queue, but effects are minor in comparison to the dedicated packet scheduler.
3.2 Traffic shaping
Traffic shaping throttles an instance’s throughput, potentially even in the case of idling resources. Hypervisors use various schedulers; however, credit-based token-bucket schedulers appear to dominate. Thereby, every instance receives a certain amount of tokens which can be spent for traffic at a regular interval. The implementations vary in details, e.g., regarding bucket size or the time interval.
Xen allows the definition of a maximum bandwidth which allows a burst of adequate size, bandwidth multiplied by time interval, per time interval. Traffic shaping is part of the netback driver’s net_tx_action function. For netfront interfaces with a pending packet, credit-based scheduling is applied. If enough credits are available anyway, the packet’s size is subtracted, processed, and sent. Alternatively, if credits are not sufficient, it is checked whether enough time has passed to add further credits. If it is time for further credits to be added, the replenish timeout is set to the current time and the packet is passed on as above. The provided credits are equivalent to the above-mentioned burst size. Otherwise, a callback for replenish after timeout is set, and the packet has to wait. Token-bucket-based traffic shaping is, however, applied only to outgoing traffic; incoming traffic is unlimited (Fraser, 2005).
By default, this time interval is 50 ms but can be modified (Redhat, n.d.), although this is unlikely to be done in the wild. In general, the smaller the chunks, the smaller the latencies are and the smoother the traffic is. However, smaller chunks can increase the required computing effort due to more frequent callbacks. Furthermore, the netback driver ensures that bursts are able to transmit jumbo packets of up to 128 kB because the interface may seize up due to lacking credits (Fraser, 2005). This leads to a dependence of the factual minimum bandwidth and the time interval. For example, the default interval of 50 ms leads to a minimum bandwidth of 2.5 kB/s.
KVM-virtualized instance traffic is shaped using the kernel’s Traffic Control, e.g., via (libvirt, n.d.). Although the kernel module provides various shaping algorithms, only hierarchical token bucket is common, which is emphasized by configuration tools solely supporting this option. In general, this algorithm provides each instance the requested service limited to the rate assigned to it (Devera, 2002). In comparison to Xen, inbound as well as outbound bandwidth is adjustable per virtual interface. Both traffic directions are defined by the three parameters average, peak and burst. Outgoing traffic can further be parameterized through floor.
It is unlikely that all coresident instances utilize all their resources at the same time and send data packets on the network as fast as they can. Idle bandwidth is lent out to neighbors, which are now able to send at higher rates, though the resource is of course returned to the borrower as soon as required. Borrowing in this way improves resource utilization while maintaining fairness. The peak parameter defines the maximum borrowed amount by ceiling the maximum data rate.
Many network connections are bursty, i.e., short periods of heavy traffic stagger with idleness. If guaranteed bandwidth is shifted to times of demand, the instance is able to send at the maximum rate, response time decreases and more interactivity is provided. Burst parameter limits the data being transferred at peak rate. Floor has been introduced later and guarantees minimal throughput.
4 Isolation-based attack surface
All network traffics of coresiding instances have to cross the underlying hypervisor before reaching the network interface card and being released to the network. As a result sharing a single network interface card among a number of hosts inevitably means distinct limitations. First, packets of different hosts will never appear on the network at the same point in time because the physical network interface is only able to put one packet at once onto the network. Second, routing packets through the hypervisor means time delays and lengthens the round-trip time in comparison to interacting with plain physical nodes. The additional time for outgoing as well as incoming packets is spent passing data to the hypervisor, queuing or delays caused by traffic shaping due to lacking credits. Finally, there is an additional chance for packets to be lost. Buffers in hypervisors, like everywhere else, are limited to a certain size. Packets beyond the capacity will be dropped, causing an increased need for packet retransmission or other measures of robustness.
As fair use of physical bandwidth among strangers seems unlikely, certain bandwidth per instance is guaranteed. The latter is limited to a certain value and controlled by means of traffic shaping. Being a part of the hypervisor and, thus, the responsibility of the cloud provider, the customer is not able to choose an appropriate technology, e.g., fitting best to his/her application.
Increased round-trip times and packet loss as well as limited bandwidth seem unremarkable at first. They may indicate that the respective host is virtualized but they become a more apparent issue if these parameters can be influenced from the outside. For example, if a coresident host is able to increase the neighbor’s round-trip time, or the number of retransmissions due to packet loss, the latter’s throughput is negatively affected. Isolation should prevent this.
However, isolation performance is not perfect, as shown in various publications, for example, Adamczyk and Chydzinski (2011) investigated the Xen hypervisor networking isolation. Measuring the impact of two virtual instances on each other has shown various interdependencies. In general, the higher the rate limits and thus assigned bandwidth to the instances, the more the actual achieved rate fluctuates, being on average slightly below the parameterized value. It is even possible that one instance is assigned the total bandwidth for a short period of time despite the neighbor also wanting to transmit. The authors further have shown that a chatty neighbor seizes more bandwidth than its calm counterpart.
Pu et al. (2010) measure the interference of CPU- and I/O-intensive instances on the same physical node, also on a Xen hypervisor. The results show that a certain workload combination allows the highest combined throughput, while others lead to significantly worse performance. While the authors target to optimize performance, an adversary might also utilize this to decrease performance.
Similarly, Hwang et al. (2013) combined networking with other resource-intensive instances on four hypervisors, including KVM and the Xen. Claiming that a Web server is a popular setup on a cloud instance, they measure the HTTP response time while stressing the components CPU, memory, or disk, respectively, by coresident instances. The decline in responsiveness for KVM is comparably small, Xen especially suffers from coresident memory use and network access.
In fact, Xen contains a boost mechanism to support latency-critical applications. It preempts other virtual machines and schedules latency-critical ones; however, it works only in the case where the neighbor runs full CPU usage and increases latency for networking. Xu et al. (2013) presented a solution to mitigate these increased round-trip times experienced in presence of neighbors with high CPU load. Up to now, this mitigation strategies deployment is scarce and the inert hypervisor issue might be exploited by malicious coresidents.
The discussed measurement setups all represent highly idealized clouds. In production cloud environments, the number of instances per physical node tends to be higher and the network is shared among a cluster of servers. As a consequence, the question arises whether it is feasible to exploit these issues in the wild, since attackers have to deal with a noisy environment and adjust their measurements accordingly. Anticipating the answer given in the following chapter, attacks are also feasible in production environments. Various works have shown that the isolation can be circumvented for address deanonymization, coresidence checking, communication via covert channels, load measuring, and increase of instance performance without paying. In conclusion, attacks exploiting improper isolation are feasible.
5 Inventory of known attacks
Here, we present attacker models applicable to the cloud and describe currently known attack techniques. We address the five network-based cloud vulnerabilities of address deanonymization, coresidence detection, covert channels and side channels, and performance attacks (Table 2).
Table 2
Inventory of network-based attacks in clouds
| References | Description | Vulnerability type |
| Herzberg et al. (2013) | Additional latencies by packet flooding | Address deanonymization |
| Ristenpart et al. (2009) | Request to DNS from internal network | Address deanonymization |
| Bates et al. (2012) | Additional latencies by packet flooding | Coresidence detection |
| Herzberg et al. (2013) | Additional latencies by packet flooding | Coresidence detection |
| Ristenpart et al. (2009) | Investigate provider’s placement strategy | Coresidence detection |
| Bates et al. (2012) | Additional latencies by packet flooding | Covert channel |
| Bates et al. (2012) | Load measurement based on connection’s throughput | Side channel |
| Farley et al. (2012) and Ou et al. (2012) | Performance differences due to heterogeneous hardware | Performance attack |
| Varadarajan et al. (2012) | Tricking neighbor into another resource’s limit | Performance attack |
Cloud instances in a data center are internally connected to each other by means of a local network using private addresses, whereas access from outside the cloud uses public addresses. From an adversary's point of view, launching an attack inside the cloud is definitely of more interest, e.g., due to higher available bandwidth and decreased latency, and is easily achieved by renting an instance, especially in public clouds. However, to target a certain victim the adversary must infer the other's internal address from their public one, commonly referred to as address deanonymization. Herzberg et al. (2013) propose the use of two instances, a prober and a malicious client, controlled by the adversary. The prober sweeps through the publicly announced address range and sends packet bursts to each instance. The benign client connects to a legitimate service on the victim. In case the prober hits the same instance as the client is connected to, the time to download a certain file increases and allows the correlation of private to public addresses. Some clouds allow even simpler address deanonymization by DNS querying the same autogenerated domain name from inside and outside the cloud. However, a number of similar simple attack vectors have been closed in reaction to publications like presented by Ristenpart et al. (2009) in the past and it is likely that the same will happen to DNS querying.
Multitenancy is, as already stated a few times, one of the major aspects of cloud computing and thus the main reason to introduce isolation among neighbors. Nevertheless, hypervisor exploits are still found every now and again (e. g., US-CERT, 2007; US-CERT, 2010), and these require prior coresidence of the victim and the attacker on the same physical machine. The process of checking the coresidence of an instance to another owned by oneself is referred to as coresidence detection.
Early works relied on measuring round-trip times, number of hops en route or matching Domain0 addresses (Ristenpart et al., 2009). Assuming that these native timing channels are disabled, a better representation of contemporary cloud computing, Bates et al. (2012) propose a means of detection again using a flooder and a malicious client. The first floods the network, while the second is connected to victim via a benign service, e.g., a Web server. If the flooder is coresident with the victim, its large amount of sent packets negatively impacts the neighbor's access to the resource. This is measured by the packet arrival rate on the client.
Herzberg et al. (2013) propose a reversed approach but one that requires at least three nodes under the attacker's controls. The flooder again saturates the network but targets another of the attacker's instances, while another client maintains a benign connection to the victim. If the flooded instance is coresident with the victim, the mass of packets again impacts the benign connection. In this work, the additional latency of a file download is measured.
Beyond network-based coresidency detection, a variety of alternatives exists which target the exploitation of other shared resources (e.g., Ristenpart et al., 2009; Zhang et al., 2011; Wu et al., 2012). Gaining insight into a cloud provider’s placement strategy to assign virtual instances to physical nodes, the attacker is able to improve their own strategy to place an instance next to a targeted node (e.g., Ristenpart et al., 2009).
Covert channels are communication channels which are not permitted for information exchange as they contain the risk of revealing secret information, e.g., private keys. Coresidency of virtual instances, therefore, adds new alternatives for attackers. In this case, the sender is coresident with another instance which provides a publicly available service, e.g., a Web server. The receiver connects to this server and measures the packet rate. The sender modulates this packet rates by flooding the network (Bates et al., 2012).
Besides extracting the key, attackers may also be interested in the victim’s load, e.g., to infer economic background. Therefore, a client maintains a connection to the victim as well as to the coresiding host under its control. Network congestion or other coresident nodes impact both connections the same way. Only additional loads for the victim change the ratio of the connections’ throughput. Obviously, the load on the coresiding attacker instance also changes the ratio, but since it is under the control of the attacker they can take steps to prevent this (Bates et al., 2012).
In general, the more a cloud customers pays, the more performance is provided. Instances of the same size and thus of the same cost can differ in their performance caused by hardware differences through data center expansion, contention, and coresiding instances. Customers may seek to maximize their performance for free and therefore choose the best performing from a number of launched instances, or decide based on a stochastic model (Farley et al., 2012; Ou et al., 2012). While this approach is legal considering cloud computing, malicious customers might aim to maximize their performance at their neighbors’ expense. Applications frequently face a single bottleneck resource. While waiting for this specific resource, the calls for other resources also decrease making it more accessible to other instances. By leading a neighbor into another’s resource limit, an attacker is able to free the required resource, increase its own performance and perform resource-freeing attacks (Varadarajan et al., 2012). These attacks however require that the victim provides a publicly available service, providing a means to influence resource use. Their feasibility has been verified by freeing the cache by tricking the neighbor into its CPU use limits. The victim’s behavior was triggered by accessing dynamic content of its publicly available Web server, which uses CPU more heavily in contrast to processing static content.
All these scenarios, however, are not independent of each other, as a cloud-based attack typically requires a sequence of steps as depicted in Figure 5. Once a victim is spotted, address deanonymization allows shifting the attack to being launched from within the cloud. Afterwards, targeted placement of a malicious instance next to a victim can be checked by means of coresidency detection technologies before the final attack, e.g., a covert channel or load measuring, is started.

6 Protection strategies
Malicious cloud users are able to cause serious harm to cloud providers and other customers. The described attacks exploit the fact that sharing a physical node’s networking capability means one instance’s performance is dependent on its neighbor’s behavior. Outgoing packets from instances have to be multiplexed before being sent onto the physical network, because a network interface card is only able to send one packet at a certain point in time. Likewise, only one packet at a time can be received, and these packets have to be demultiplexed to the respective guest instance.
Tackling the root cause of the issue and providing each virtual instance its own path to the physical network, i.e., its own physical network interface, would sufficiently mitigate the presented attacks. However, this approach contradicts the cloud-computing principles of resource sharing and flexibility, and so alternative mitigation methods are highly important. Nevertheless, the majority of mitigation strategies aim to tackle the problem in the hypervisor as the single guest instances are not aware of this issue.
Specifically, three types of mitigations are feasible. First, randomization prohibits deterministically inferring neighbor behavior. Second, adjusting bandwidth assignment hinders the influence of neighbor demands. Third, add-on mitigation as changes or supplements to today’s infrastructure (Table 3).
Table 3
Inventory of potential countermeasures
| Randomization | Bandwidth assignment | Add-on mitigation |
| Random scheduling (Keller et al., 2011; Bates et al., 2012) | Prevention on overprovisioning (Bates et al., 2012) | Rate limiting (Herzberg et al., 2013) |
| Reduction of timer resolution (Hu, 1992; Vattikonda et al., 2011) | Stringent time-division multiplexing | Blocking of internal traffic (Herzberg et al., 2013) |
Regarding randomization, two alternatives are available: Keller et al. (2011) propose random scheduling to prevent cache side channels. Instead of randomizing the scheduler, it is also possible to prevent accurate measurement. Vattikonda et al. (2011) claim that cache side channels require a timer resolution of tens of nanoseconds. The elimination of this resolution does not disrupt applications whilst preventing the side channels attacks, and adopts a solution already known from the VAX security kernel to the Xen hypervisor (Hu, 1992). However, randomization has up to now only been investigated for cache side channels. Nevertheless, Bates et al. (2012) advise randomly scheduling outgoing packets in order to hinder attacks. Fuzzy timing is infeasible for network side channels as a lower time resolution is sufficient. Eliminating this coarse solution would presumably also break ordinary benign applications. In general, the impact of randomizing solutions must be investigated carefully, because dependent on their time resolution they are able to seriously interfere with networking, e.g., TCP retransmission. Furthermore, they require a change of sensitive hypervisor code.
A reasoned parameterization of bandwidth limits per instance prevents heavy dependence on each other (Bates et al., 2012). By preventing overprovision, i.e., assigning in total less bandwidth to virtual instances than physical bandwidth available, it is guaranteed that every guest gets its quota. Further, borrowing bandwidth from other, currently idle nodes should be prevented, which removes an attacker’s motivation to influence others to gain resources. However, this means less efficient resource use and less revenue for the provider who aims to minimize idle resources.
The radical opposite to randomized scheduling is stringent time-division multiplexing, which also enables mitigating isolation-based vulnerabilities. Time slices are assigned to virtual instances and its packets are only sent within these slices. This prevents the instances influencing each other and includes rate limiting and a maximum bandwidth automatically. While the implementation seems straightforward, questions arise when considering handling incoming packets as well as global synchronization.
Herzberg et al. (2013) additionally propose add-on mitigation strategies which do not involve changes in the hypervisor algorithms. Although they have the advantage of being easily applicable, they nevertheless bear the risk of not fully mitigating the issue. First, a number of attacks, such as address deanonymization and coresidency checking, require flooding. Sending a high number of packets can be prevented by the implementation of rate limiting, but must be careful not to negatively impact benign traffic. Some cloud providers already have a process for spam prevention which could be adopted: Only a limited number of mails are allowed to be sent from a cloud instance unless an unlimited quota is manually requested via a Web form. This request includes an explanatory statement which is checked by the provider. This approach could be adopted for benign applications which conflict with rate limiting. A further alternative is blocking internal communication between nodes of different accounts, a means of indirect rate limiting. The attacker has to use public addresses, the traffic is routed outside and back inside to the cloud network. Additionally, this way address deanonymization becomes futile.
The above-mentioned mitigation strategies help to prevent attacks where multiplexing one resource among various virtual instances plays a role, i.e., address deanonymization, coresidency checking, covert channels and load measuring. In contrast, resource-freeing attacks aim to redirect the neighbor to another resource, and so changing the networking scheduler would not mitigate the issue. Therefore, Varadarajan et al. (2012) propose smarter scheduling. The hypervisor could monitor the virtual instances and schedule them in order to prevent conflicts.
7 Conclusion
We have seen that isolation is one of the main mitigation strategies to protect instances against each other on single physical hosts. Looking at today’s best-known open-source hypervisors provides an insight of how isolation is achieved: Xen is representative of paravirtulization, providing abstractions of devices to its instances using Domain0, while KVM is a full-virtualized hypervisor requiring specific hardware support and heavily reusing Linux code. Looking at networking in more detail, has revealed that scheduling and traffic shaping contribute to isolation.
However, today’s hypervisors are still vulnerable to a number of attacks which exploit improper isolation, e. g., address deanonymization, coresidency detection, covert channels and resource-freeing attacks. These attacks exploit the fact that, in order to maintain performance, virtual instances share physical resources and are thus not fully independent of each other.
This leads to a general conclusion that there is a tradeoff between security and performance. Security aims to uncouple instances through isolation, but isolation comes at a cost. To guarantee a certain amount of resources to every instance, scheduling cannot be as seamless as it could be and has to dedicate quotas to certain instances. Idle resources cannot be lent out to others. Overprovision is frowned upon as the guarantees cannot be fulfilled in the worst-case scenario.
While isolation is a strong means of mitigation, it also challenges a number of the main principles of cloud computing. Cloud computing looks to maximize resource use and isolation comes always at a cost, leaving fewer resources for the actual desired computation. This leads to the conclusion that the scope of isolation is also dependent on its operational use. Low security applications might be satisfied with today’s state-of-the-art and prefer cheaper prices. Those with high security needs will have to accept the costs to maintain their standards.
After years of increased attention, it is unlikely that cloud computing is just a passing trend and it seems certain to become a standard technology in the future. Nevertheless, challenges for the future remain and research is ever more necessary in contributing to hypervisor security. Besides analyzing hypervisors for further vulnerabilities, security in clouds has to be tackled with a holistic approach. Further, it has to be determined which amount of isolation is adequate for certain security levels. Last but not least, cloud customers still only have limited options to verify their cloud security. It is neither possible to verify easily whether a cloud provider acts compliantly, nor test an infrastructure’s security in a comprehensive manner. Up to now, security seems to be taking a back seat to reducing costs.