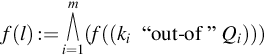Computational trust methods for security quantification in the cloud ecosystem
Sheikh Mahbub Habib; Florian Volk; Sascha Hauke; Max Mühlhäuser Telecooperation Lab, Technische Universität Darmstadt/CASED, Darmstadt, Germany
Abstract
In this chapter, we provide an in-depth insight into computational trust methods that are able to reliably quantify the security level of service providers and transparently communicate that level to the users. The methods particularly consider business as well as end user requirements along with a complex specification of security assurances during security quantification. Novel trust methods are validated using formal proofs, industry-accepted security assurance datasets, and user studies.
1 Introduction
According to the 2014 Gartner hype cycle for emerging technologies report (LeHong et al., 2014), cloud computing technology is moving toward maturity. However, the main barrier for business users’ adoption of cloud services is still the lack of security assurance from cloud providers. Another barrier for users is the growing number of cloud outages (Tsidulko, 2014) either due to the network failures, software updates, or security breaches. These barriers along with users’ inability to measure the security services erode their confidence in cloud providers’ overall security capabilities (Intel, 2012).
Security assurance in the cloud computing ecosystem has gone some promising steps forward since the introduction of the Security, Assurance and Trust Registry (STAR) (CSA, 2012) by the Cloud Security Alliance (CSA) in 2011. A growing number of cloud providers are sharing their service-specific security capabilities in a public repository, e.g., the CSA STAR. Potential users are able to browse this public repository in order to reason about the capabilities of different cloud providers. In order to provide users with security assurance, technical methods are required to quantify the security capabilities of cloud providers. The methods for quantification, aggregation as well as visual communication in an automated manner are necessary to achieve the goal of effective security assurance.
In this chapter, computational trust methods are leveraged to quantitatively assess the security capabilities of cloud providers. As underlying information of those capabilities is based on the cloud providers’ self-assessments, such information might contain inconsistencies. Moreover, when several sources such as experts or auditors assess that inconsistent information in different manner, conflicting assessment results might appear. The trust methods described in this chapter are able to quantify the level of security capabilities in presence of inconsistent and conflicting information. These methods also provide means to visually communicate the quantitative assessment to users based on their requirements.
2 Computational trust: preliminaries
Computational trust provides means to support entities to make informed decisions in electronic environments, where decisions are often subject to risk and uncertainty. Research in computational trust addresses the formal modeling, assessment, and management of the social notion of trust for use in risky electronic environments. Examples of such risky environments span from social networks over e-marketplaces to cloud computing service ecosystems. In theory, trust is usually reasoned in terms of the relationship within a specific context between a trustor and a trustee, where the trustor is a subject that trusts a target entity, which is referred to as trustee. Mathematically, trust is an estimate by the trustor of the inherent trustworthiness of the trustee, i.e., the quality of another party to act beneficially or at least nondetrimentally to the relying party.
In order to estimate trustworthiness of a trustee, a trustor requires evidence about the trustee’s behavior in the past. Evidence about a trustee can be derived from direct experience or asking other trustor about their own experiences, i.e., indirect experience. This is termed as social concept of trust and has been widely used in the field of computer science (Jøsang et al., 2007). For detailed discussion on the definitions in the field of philosophy, sociology, psychology, and economics, we refer the readers to McKnight and Chervany (1996) and Grandison (2007).
Although researchers agree on the social concept of trust, it is not easy to get a single definition of trust based on the universal consensus. A definition that is adopted by many researchers in the field of computer science is the definition provided by the sociologist Gambetta (1990, 2000):
In the context of this chapter, an agent or a group of agents refers to service providers, who provide the requested service by contemporaneously meeting a service-specific requirement r, e.g., confidentiality, availability, etc. In another setting, a service provider may publish r by means of service capabilities, e.g., compliance, information security (IS), data governance. The assurance of r corresponds to what is referred to as perform a particular action.
3 State-of-the-art approaches tackling cloud security
In this section, we provide a number of approaches that aim to tackle the cloud security issues from the perspective of computational trust, trusted computing, security transparency, and security quantification.
3.1 Computational trust models and mechanisms
Computational trust mechanisms are useful for trustworthiness evaluation in various service environments (Jøsang et al., 2007) such as in e-commerce and P2P networks. These mechanisms have also been adapted in grid computing by Lin et al. (2004) and Haq et al. (2010), in cloud computing by Pawar et al. (2012), as well as in the context of web service selection by Wang et al. (2010). Haq et al. proposed a trust model based on certificates (i.e., PKI-based) and a reputation-based trust system as a part of an Service Level Agreement (SLA) validation framework. Wang et al. proposed a trust model, which takes multiple factors (reputation, trustworthiness, and risk) into account when evaluating web services. Both approaches consider SLA validation as the main factor for establishing trust on the grid service and web service providers. An SLA validation framework can help to identify the compliance of SLA parameters agreed between a user and a cloud provider. Pawar et al. (2012) proposed a trust model to evaluate trustworthiness of cloud infrastructure providers based on SLA compliance.
In order to serve the customers best, a trust mechanism should take multiple available sources of information into account, such as past experience of the users as well as third-party certificates. The past experience about the capabilities and competency of the service providers might be based on the insufficient information or extracted from unreliable sources. Moreover, certificates issued by incompetent and unreliable certificate authorities (CAs) might render the trust evaluation process useless. Thus, trust mechanisms in Habib et al. (2013) considered these issues important and trust is modeled under uncertain conditions such as insufficient information and unreliable CAs or trust sources. Furthermore, trust mechanisms also need to consider service-specific capabilities that are relevant when selecting service providers in cloud marketplaces.
Trust operators. Non application-specific computational trust models usually provide mathematical operators for trustworthiness assessment. One of such operators is consensus, which combines evidence from different sources about the same target. Another operator is discounting, which weights recommendation based on the trustworthiness of the sources. These two operators are important when deriving trustworthiness based on direct experience and recommendation. In the cloud computing ecosystem, services are hosted in complex distributed systems. In order to assess the trustworthiness of cloud providers regarding different capabilities such as security and compliance, we additionally need operators; logic-based approaches that can provide such operators are Subjective Logic (SL) (Jøsang, 2001), CertainLogic (Ries et al., 2011), and CertainTrust (Ries, 2009a).
3.2 Trusted computing technologies
Apart from the field of computational trust mechanisms, a number of approaches from the field of trusted computing are proposed to ensure trustworthy cloud infrastructures. Krautheim (2009) proposed a private virtual infrastructure; this is a security architecture for cloud computing and uses a trust model to share the responsibility of security between the service provider and client. Schiffman et al. (2010) proposed a hardware-based attestation mechanism to provide assurance of data processing protection in the cloud for customers. There are further approaches like property-based Trusted Platform Module (TPM) virtualization (Sadeghi et al., 2008), which can be used in the cloud scenario to assure users about the fulfillment of security properties or attributes in cloud platforms using attestation concepts. However, in general, attestation concepts based on trusted computing (e.g., Sadeghi and Stüble, 2004) focus on the evaluation of single platforms. while services in the web are often hosted in composite platforms. Moreover, uncertainty arises due to the nature of the property-based attestation mechanism, which requires dynamic trust-based models such as the one addressed in Nagarajan (2010). This approach also considered composite service platforms while designing the trust model.
3.3 Cloud security transparency mechanisms
The CSA launched the STAR in order to promote transparency in cloud ecosystems. Cloud providers answer the Consensus Assessment Initiative Questionnaire (CAIQ) (CSA, 2011) and make the completed CAIQ available through the CSA STAR. The CAIQ profiles of cloud providers are useful for potential cloud users in order to assess the security capabilities, e.g., compliance, IS, governance, of cloud services before signing up contracts. Although the CAIQ profiles are based on the cloud providers’ self-assessments, the CSA make sure that cloud providers publish their information truthfully and update them regularly in the STAR. One of the major drawbacks of the completed CAIQ profiles is that the information underlying the profiles is informally formatted, e.g., by means of free form text spreadsheets. This drawback limits human users to quantify security capabilities based on the information provided in those profiles.
3.4 Cloud security quantification methods
Security quantification is essential and useful for cloud users in order to compare the cloud providers based on the level of their security capabilities. In order to address the STAR’s drawback, Luna Garcia et al. (2012) proposed an approach to quantify Security Level Agreements, i.e., the CAIQ profiles. The proposed approach leverages Quantitative Policy Trees (QPTs) to model security capabilities underlying the CAIQ. Related AND/OR-based aggregation methods are used to aggregate the qualitative or quantitative values (i.e., answers provided in the CAIQ profiles) associated with different nodes of QPTs. Aggregated values represent the security capability level of cloud providers. However, those security quantification and aggregation methods are not able to deal with uncertainty and inconsistencies associated with answers provided by cloud providers.
4 Computational trust methods for quantifying security capabilities
In cloud computing ecosystems, computing resources such as computing power, data storage, and software are modeled as services. A number of cloud providers offer those services with similar functionality. However, there can be huge differences regarding the published security capabilities of those service providers. Therefore, security capabilities need to be quantified in order to support users to compare the cloud providers.
Computational trust methods are useful tools to assess the quality of a trustee based on the available evidence that is subject to uncertainty. When evidence is derived from multiple sources, there might be conflicting evidence due to the nature of information sources. Those trust methods are able to deal with conflicting evidence while assessing the quality of that trustee. Such methods can be used to assess and quantify security capabilities as underlying evidence of those capabilities is often conflicting and uncertain. Furthermore, trust methods provide visual aids to communicate the quality of a trustee (e.g., cloud provider) to the trustor. This can be a useful technique to communicate the security levels of cloud providers to users in order to support them in making informed decisions.
4.1 Formal analysis of security capabilities
In a cloud ecosystem, service providers may publish service-specific security capabilities using a self-assessment framework such as the CSA CAIQ. Users can make use of these capabilities, publicly available from the STAR, to get a better handle on the security attributes that cloud providers claimed to have. In the CAIQ, fulfillment of capabilities can be reasoned in a composite manner, for instance, a cloud provider is considered to fulfill the IS capability given that the constituent attributes (IS-01–IS-34) are also fulfilled. However, the CAIQ framework as it stands does not provide a solution on analyzing such a composition in the context of security quantification.
Each of the security capabilities has underlying attributes that are, again, composed of several other attributes. If capabilities are associated with attributes that cannot be split further, they are denoted as “atomic attributes.” If capabilities are associated with attributes that are composed of further attributes, these are denoted as “nonatomic attributes.” In the context of service-specific capabilities, a consumer’s requirement(s) is denoted as R, where consumers might prefer to personalize a set of requirements.
4.1.1 Transforming security attributes into formal security terms
The definition of formal “security terms” in the context of published security attributes follows a similar syntax and semantics of the definitions presented in Schryen et al. (2011). Therefore, formal definitions were proposed to analyze composite distributed services. Here, similar definitions are formulated to analyze composite service attributes, i.e., a service attribute may consist of subattributes. Regarding service-specific composite attributes, the definitions are as follows.
Let S be a service with atomic attributes, P={Pi}ni=1![]() . Assume that the user requirements, R={R1,…,Rn}
. Assume that the user requirements, R={R1,…,Rn}![]() , are a subset of published attributes, R⊆P
, are a subset of published attributes, R⊆P![]() . A single requirement is denoted by r⊆P
. A single requirement is denoted by r⊆P![]() . Every attribute Pi is assumed to have subattributes, |N|.
. Every attribute Pi is assumed to have subattributes, |N|.
Definition 2
An atomic attribute Pi of a service S can be described by the security term (k“out-of”N)![]() , k∈{1,…,|N|},N⊆Pi
, k∈{1,…,|N|},N⊆Pi![]() , wrt r
, wrt r
:⇔{Atleastksubattributes“out-of”NneedtobesatisfiedsothatSmeetsrequirementr.
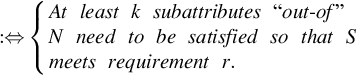
In order to describe atomic attributes of a service that satisfies more than one requirement, we define the following security terms:
Definition 3
Different atomic attributes P of a service S can be described by the security term ((k1 ![]()
![]()
![]() km) “out-of” (N1,
km) “out-of” (N1, ![]() , Nm)); ∀iki∈{1,…,|Ni|},Ni⊆P
, Nm)); ∀iki∈{1,…,|Ni|},Ni⊆P![]() , wrt R
, wrt R
:⇔{Foreachi∈{1,…,m}atleastkisubattributes“out-of”NineedtobesatisfiedsothatSmeetsrequirementsR.
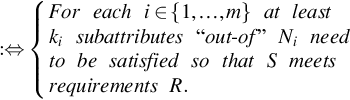
In order to represent nonatomic security attributes of a service by means of security terms we define the following two definitions. Let {Pi}ni=1![]() be subattributes of a system S, and let property Pi of the system be described by the following security term li,∀i∈{1,…,n}
be subattributes of a system S, and let property Pi of the system be described by the following security term li,∀i∈{1,…,n}![]() . Assuming that user requirements, R={R1,…,Rn}
. Assuming that user requirements, R={R1,…,Rn}![]() , are a subset of published attributes, R⊆Pi
, are a subset of published attributes, R⊆Pi![]() . In the case of a single requirement, r⊆Pi
. In the case of a single requirement, r⊆Pi![]() .
.
Definition 4
A nonatomic attribute Pi of a service S can be described by the security term (k“out-of”{li1,…,lim})![]() , k ∈{1,…,m}, {i1,…,im}⊆{1,…,n}
, k ∈{1,…,m}, {i1,…,im}⊆{1,…,n}![]() , wrt r
, wrt r
:⇔{Atleastkattributes“out-of”{Pi1,…,Pim}needtobesatisfiedsothatSmeetsrequirementr.
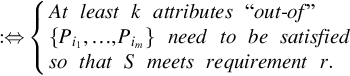
Definition 5
Different nonatomic attributes P of a system S can be described by the security term ((k1 ![]()
![]()
![]() km) “out-of” (Q1,
km) “out-of” (Q1, ![]() , Qm));∀iki∈{1,…,|Qi|},Qi⊆{l1,…,ln}
, Qm));∀iki∈{1,…,|Qi|},Qi⊆{l1,…,ln}![]() , wrt R
, wrt R
:⇔{Foreachi∈{1,…,m}atleastkiattributes“out-of”thesetofattributesforwhichQicontainssecuritytermsneedtobesatisfiedsothatSmeetsrequirementsR.

We demonstrate the analysis and determination of security terms with the following example.
4.1.1.1 Example
Assume that a cloud provider publishes service-specific capabilities regarding a set of attributes like security, compliance, data governance, etc. Those capabilities and attributes are published through a public repository named STAR following the CSA CAIQ framework. A user wants to assess the security level of a cloud provider wrt. the following requirements: security and compliance. We assume that a static mapping between the user requirements and published capabilities of cloud providers is already available. In order to satisfy the user’s security requirement, a cloud provider has to possess capabilities regarding following three attributes: Facility Security (FS), Human Resources Security (HS), and IS. Additionally, in order to satisfy user’s compliance requirement, a cloud provider has to possess capabilities regarding following two attributes: technical compliance (CO) and legal compliance (LG). The above definitions are used to convert the service-specific attributes into security terms. Applying Definitions 2 and 4, the following security terms are obtained according to the given requirements of the user, i.e., security and compliance.
• Security: (3“out-of”{FS,HS,IS})︸=:l1![]() (Definition 2)
(Definition 2)
• Compliance: (2“out-of”{CO, LG})︸=:l2![]() (Definition 2)
(Definition 2)
• {Security, Compliance}: (2“out-of”({l1,l2}))![]() (Definition 4)
(Definition 4)
4.1.2 Mapping security terms to PLTs
The example shows that the representation of composite service attributes by means of security terms can become complex even for a simple set of attributes. In order to represent security terms in a simple format to allow easy interpretation and evaluation, security terms are transformed into Propositional Logic Terms (PLTs). The following theorem is required for this purpose.
Theorem 1
Let the attributes P of system S consist of subattributes P = {P1,…, Pn} and let {XP1,…,XPn}![]() be literals with ∀i: XPi=
be literals with ∀i: XPi=![]() true, if R⊆P
true, if R⊆P![]() and r⊆Pi
and r⊆Pi![]() . Then, the security term l can be mapped to a propositional logic formula f(l) such that S is trustworthy wrt r or R if and only if f(l) is satisfied.
. Then, the security term l can be mapped to a propositional logic formula f(l) such that S is trustworthy wrt r or R if and only if f(l) is satisfied.
The proof regarding Theorem 1 is provided in Appendix.
We use the above-mentioned example to illustrate how to determine the propositional logic formula of particular security terms, namely l1, l2, and l.
4.1.2.1 Example
• l1=(3“out-of”({FS, HS, IS}))![]()
⇒f(l1)(A.1)=(FS)∧(HS)∧(IS)=FS∧HS∧IS=:fsecurity

• l2=2“out-of”({CO, LG})![]()
⇒f(l2)(A.1)=(CO)∧(LG)=CO∧LG=:fcompliance
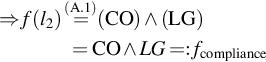
• l=2“out-of”({l1,l2})![]()
⇒f(l)(A.3)=(f(l1))∧(f(l2))=(fsecurity)∧(fcompliance)=(FS∧HS∧IS)∧(CO∧LG)
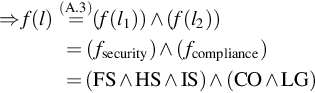
4.2 Evaluating security capablities
The framework discussed in the previous section provides means to model the security capabilities of cloud providers considering different security attributes. Particularly, the framework formally analyzes the dependencies underlying those attributes and represents the dependencies by means of PLTs. However, PLTs do not serve the purpose of quantifying the security capabilities of service providers. Security quantification is essential to compare cloud services as well as cloud providers that have similar capabilities. In order to quantify security levels of cloud providers, there is a need to associate values with the PLTs. This means that capabilities of a service should be associated with a value that represents the existence of underlying attributes and subattributes. The values should be aggregated according to the derived attribute specification, i.e., PLTs.
According to Ries et al. (2011), such a value can appear in the form of an opinion, which is based on the available pieces of evidence. Derived pieces of evidence can be incomplete, unreliable, or indeterminable due to the type of measuring methods. Thus, opinions derived from this evidence are subject to uncertainty. Moreover, the opinions derived from different sources might be conflicting either due to the method they use for assessing evidence, or simply because the sources are unreliable. The mechanism should also be able to aggregate opinions in compositions as represented in PLTs. The propositions in the PLTs are combined with a logical AND (∧) operator and this operator should be able to combine opinions derived from uncertain and conflicting evidence. Therefore, novel CertainLogic logical operators and nonstandard operators (i.e., FUSION) are leveraged to quantify the security capabilities of cloud providers. The CertainLogic operators are defined to deal with uncertain and conflicting opinions associated with propositions.
In the following section, the CertainLogic AND (∧) and FUSION operators are defined. The definitions are based on an established model, CertainTrust, which serves as a representational model to represent opinions under uncertain probabilities.
4.2.1 CertainLogic operators
As CertainLogic operators are based on the CertainTrust representational model, we start this section with a brief overview on that model.
4.2.1.1 CertainTrust
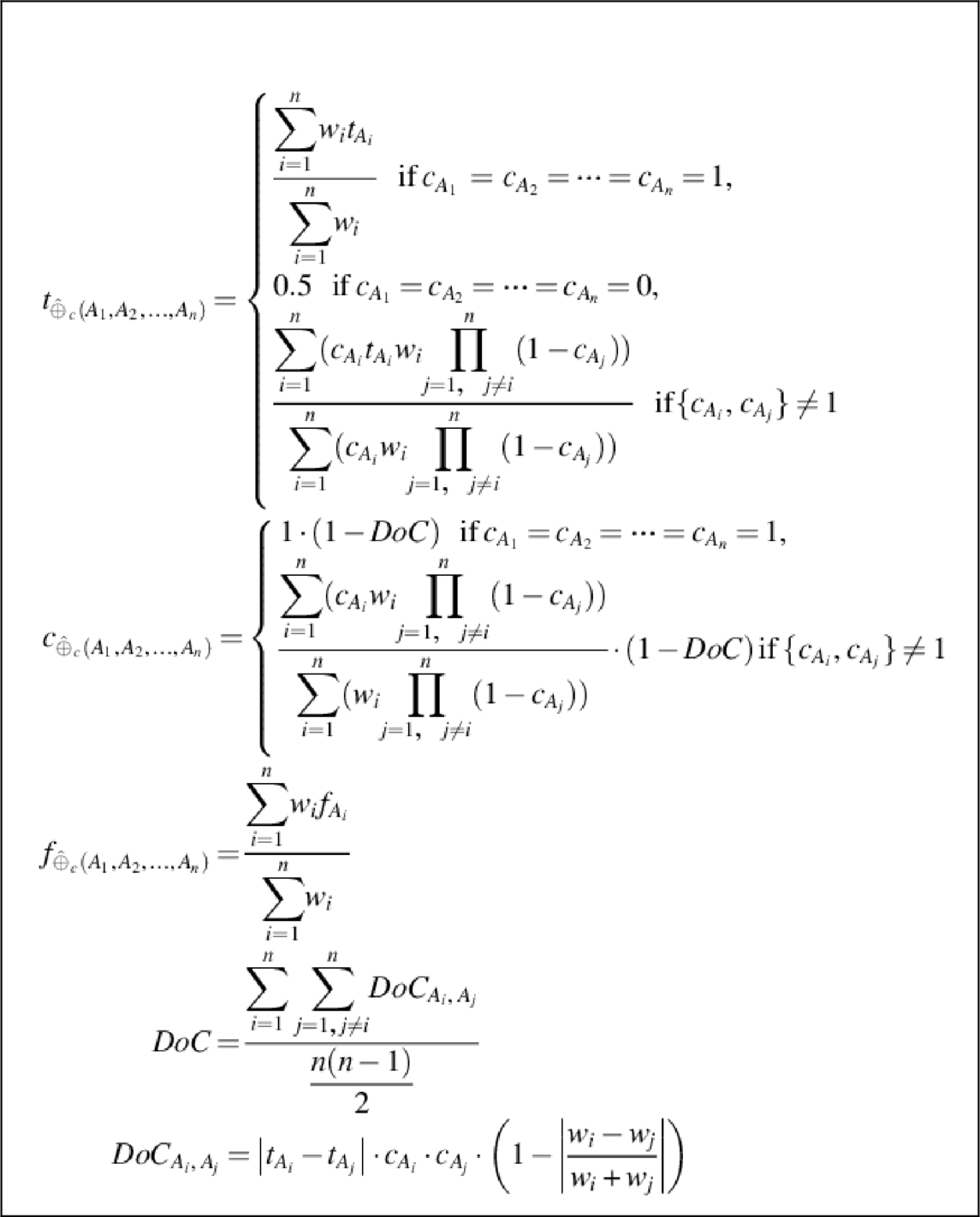
Ries proposed the CertainTrust model (Ries, 2009b) in order to represent trust under uncertain probabilities. With this model, the truth of a statement or proposition can also be expressed by a construct called opinion. By design, this opinion construction addresses evidence under uncertainty and a user’s initial expectation about the truth of a proposition. The definition of CertainTrust is as follows.
Here, the average rating t indicates the degree to which past pieces of evidence support the truth of a proposition. It depends on the relative frequency of observations or pieces of evidence supporting the truth of a proposition. The certainty c indicates the degree to which the average rating is assumed to be representative for the future. It depends on the number of past observations (or collected pieces of evidence). The higher the certainty of an opinion is, the higher is the influence of the average rating on the expectation value (cf. Definition 7) in relation to the initial expectation. When the maximum level of certainty (c = 1) is reached, the average rating is assumed to be representative for future outcomes. The initial expectation f expresses the assumption about the truth of a proposition in absence of evidence.
It expresses the expectation about the truth of a proposition taking into account the initial expectation, the average rating and the certainty. In other words, the expectation value shifts from the initial expectation value (f) to the average rating (t) with increasing certainty (c). The expectation value, E, expresses trustworthiness of the trustor on the trustee and is referred to as trustworthiness value in CertainTrust model.
4.2.1.2 CertainLogic AND (∧) Operator
The operator ∧ is applicable when opinions about two-independent propositions need to be combined in order to produce a new opinion reflecting the degree of truth of both propositions simultaneously. Note that the opinions (cf. Definition 6) are represented using the CertainTrust model. The rationale behind the definitions of the logical operators of CertainTrust (e.g., AND (∧)) demands an analytical discussion.
In standard binary logic, logical operators operate on propositions that only consider the values “TRUE” or “FALSE” (i.e., 1 or 0, respectively) as input arguments. In standard probabilistic logic, the logical operators operates on propositions that consider values in the range of [0,1] (i.e., probabilities) as input arguments. However, logical operators in the standard probabilistic approach are not able to consider uncertainty about the probability values. SL’s logical operators are able to operate on opinions that consider uncertain probabilities as input arguments. Additionally, SL’s logical operators are a generalized version of standard logic operators and probabilistic logic operators.
CertainLogic’s logical operators operate on CertainTrust’s opinions, which represent uncertain probabilities in a more flexible and simpler manner than the opinion representation in SL. Note that both CertainTrust’s representation and SL’s representation of opinions are isomorphic with the mapping provided in Ries (2009b). For a detailed discussion on the representational model of SL’s opinions and CertainTrust’s opinions, we refer the readers to Chapter 2 of Habib (2014). The definitions of CertainLogic’s logical operators are formulated in a way so that they are equivalent to the definitions of logical operators in SL. This equivalence serves as an argument for the justification and mathematical validity of CertainLogic logical operators’ definitions. Moreover, these operators are generalization of binary logic and probabilistic logic operators.
Definition 8
(Operator AND). Let A and B be two independent propositions and the opinions about the truth of these propositions be given as oA = (tA, cA, fA) and oB = (tB,cB,fB), respectively. Then, the resulting opinion is denoted as oA∧B = (tA∧B, cA∧B, fA∧B) where tA∧B, cA∧B, and fA∧B are defined in Table 1 (AND). We use the symbol “ ∧″ to designate the operator AND and we define oA∧B ≡ oA ∧ oB.
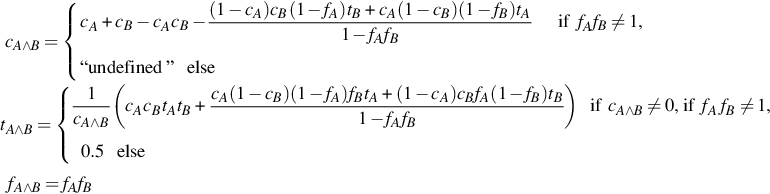
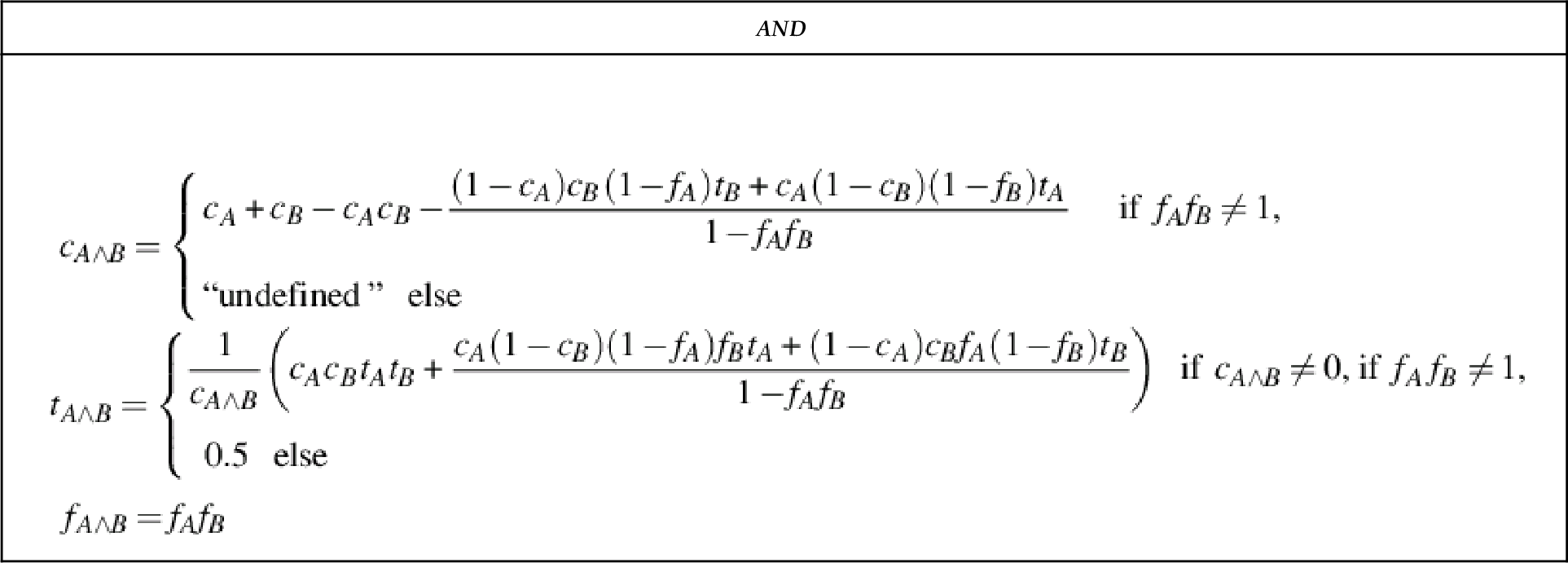
The aggregation (using the AND operator) of opinions about independent propositions A and B are formulated in a way that the resulting initial expectation (f) is dependent on the initial expectation values, fA and fB assigned to A and B, respectively. Following the equivalent definitions of SL’s normal conjunction operator and basic characteristics of the same operator (∧) in standard probabilistic logic, we define fA∧B = fAfB. The definitions for cA∧B and tA∧B are formulated in similar manner and the corresponding adjustments in the definitions are made to maintain the equivalence between the operators of SL and CertainLogic. The AND (∧) operator of CertainLogic is associative and commutative; both properties are desirable for the evaluation of PLTs.
4.2.1.3 CertainLogic FUSION operator
Assume that one wants to fuse conflicting opinions (about a proposition) derived from multiple sources. In this case, one should use the conflict-aware fusion (C.FUSION) operator as defined in Habib (2014). This operator operates on dependent conflicting opinions and reflects the calculated degree of conflict (DoC) in the resulting fused opinion. Note that the C.FUSION operator is also able to deal with preferential weights associated with opinions.
Definition 9
(C.FUSION). Let A be a proposition and let oA1=(tA1,cA1,fA1)![]() , oA2=(tA2,cA2,fA2),…,oAn=(tAn,cAn,fAn
, oA2=(tA2,cA2,fA2),…,oAn=(tAn,cAn,fAn![]() ) be n opinions associated to A. Furthermore, the weights w1, w2,…, wn (with w1,w2,…,wn∈ℝ+0
) be n opinions associated to A. Furthermore, the weights w1, w2,…, wn (with w1,w2,…,wn∈ℝ+0![]() and w1 + w2 +
and w1 + w2 + ![]() + wn≠0) are assigned to the opinions oA1
+ wn≠0) are assigned to the opinions oA1![]() , oA2
, oA2![]() ,…, oAn
,…, oAn![]() , respectively. The C.FUSION is denoted as
, respectively. The C.FUSION is denoted as
oˆ⊕c(A1,A2,…,An)=((tˆ⊕c(A1,A2,…,An),cˆ⊕c(A1,A2,…,An),fˆ⊕c(A1,A2,…,An)),DoC)
where tˆ⊕c(A1,A2,…,An)![]() , cˆ⊕c(A1,A2,…,An)
, cˆ⊕c(A1,A2,…,An)![]() , fˆ⊕c(A1,A2,…,An)
, fˆ⊕c(A1,A2,…,An)![]() , the DoC are defined in Table 2. We use the symbol (ˆ⊕c
, the DoC are defined in Table 2. We use the symbol (ˆ⊕c![]() ) to designate the operator C.FUSION and we define oˆ⊕c(A1,A2,…,An)≡ˆ⊕c((oA1,w1),(oA2,w2),…,(oAn,wn))
) to designate the operator C.FUSION and we define oˆ⊕c(A1,A2,…,An)≡ˆ⊕c((oA1,w1),(oA2,w2),…,(oAn,wn))![]() .
.
Table 2
Definition of the C.FUSION Operator
|
tˆ⊕c(A1,A2,…,An)={∑ni=1witAi∑ni=1wiifcA1=cA2=⋯=cAn=1,0.5ifcA1=cA2=⋯=cAn=0,∑ni=1(cAitAiwi∏nj=1,j≠i(1−cAj))∑ni=1(cAiwi∏nj=1,j≠i(1−cAj))if{cAi,cAj}≠1cˆ⊕c(A1,A2,…,An)={1·(1−DoC)ifcA1=cA2=⋯=cAn=1,∑ni=1(cAiwi∏nj=1,j≠i(1−cAj))∑ni=1(wi∏nj=1,j≠i(1−cAj))·(1−DoC)if{cAi,cAj}≠1fˆ⊕c(A1,A2,…,An)=∑ni=1wifAi∑ni=1wiDoC=∑ni=1∑nj=1,j≠iDoCAi,Ajn(n−1)2DoCAi,Aj=|tAi−tAj|·cAi·cAj·(1−|wi−wjwi+wj|) |
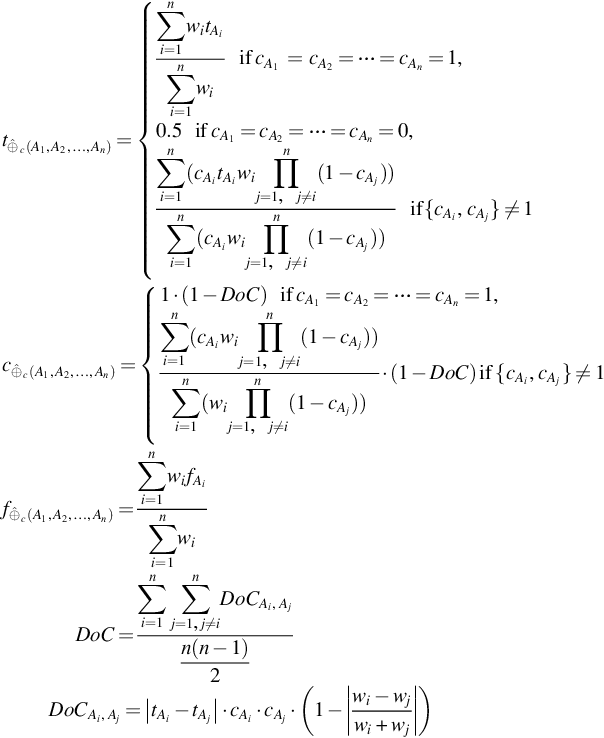
The C.FUSION operator is commutative and idempotent, but not associative.
The rationale behind the definition of the C.FUSION demands an extensive discussion. The basic concept of this operator is that the operator extends the CertainLogic’s Weighted fusion (Habib et al., 2012) operator by calculating the DoC between a pair of opinions. Then, the value of (1−DoC) is multiplied with the certainty (c) that would be calculated by the weighted fusion (the parameters for t and f are the same as in the weighted fusion).
Now, we discuss the calculation of the DoC for two opinions. For the parameter, it holds DoC ∈ [0,1]. This parameter depends on the average ratings (t), the certainty values (c), and the weights (w). The weights are assumed to be selected by the trustors (consumers) and the purpose of the weights is to model the preferences of the trustor when aggregating opinions from different sources. We assume that the compliance of their preferences are ensured under a policy negotiation phase. For example, users might be given three choices: high (2), low (1), and no preference (0, i.e., opinion from a particular source is not considered), to express their preferences on selecting the sources that provide the opinions. Note that the weights are not introduced to model the reliability of sources. In this case, it would be appropriate to use the discounting operator (Ries, 2009b; Jøsang, 2001) to explicitly consider reliability of sources and apply the fusion operator on the results to influence users’ preferences. The values of DoC can be interpreted as follows:
• No conflict (DoC=0): For DoC=0, it holds that there is no conflict between the two opinions. This is true if both opinions agree on the average rating, i.e., tA1=tA2![]() or in case that at least one opinion has a certainty c = 0 (for completeness we have to state that it is also true if one of the weights is equal to 0, which means the opinion is not considered).
or in case that at least one opinion has a certainty c = 0 (for completeness we have to state that it is also true if one of the weights is equal to 0, which means the opinion is not considered).
• Total conflict (DoC=1): For DoC=1, it holds that the two opinions are weighted equally (w1 = w2) and contradicts each other to a maximum. This means, that both opinions have a maximum certainty (cA1=cA2=1![]() ) and maximum divergence in the average ratings, i.e., tA1 = 0 and tA2 = 1 (or tA1 = 1 and tA2 = 0).
) and maximum divergence in the average ratings, i.e., tA1 = 0 and tA2 = 1 (or tA1 = 1 and tA2 = 0).
• Conflict (DoC∈]0,1[): For DoC∈]0,1[, it holds that there are two opinions contradict each other to a certain degree. This means that the both opinions does not agree on the average ratings, i.e., tA1≠tA2![]() , having certainty values other than 0 and 1. The weights can be any real number other than 0.
, having certainty values other than 0 and 1. The weights can be any real number other than 0.
Next, we argue for integrating the DoC into the resulting opinion by multiplying the certainty with (1−DoC). The argument is, in case that there are two (equally weighted) conflicting opinions, then this indicates that the information which these opinions are based on is not representative for the outcome of the assessment or experiment. Thus, for the sake of representativeness, in the case of total conflict (i.e., DoC=1), we reduce the certainty (c(oA1,w1)ˆ⊕(oA2,w2)![]() ) of the resulting opinion by a multiplicative factor, (1−DoC). The certainty value is 0 in this case.
) of the resulting opinion by a multiplicative factor, (1−DoC). The certainty value is 0 in this case.
For n opinions, (i.e., DoCAi,Aj![]() ) in Table 2 is calculated for each opinion pairs. For instance, if there are n opinions there can be at most n(n−1)2
) in Table 2 is calculated for each opinion pairs. For instance, if there are n opinions there can be at most n(n−1)2![]() pairs and is calculated for each of those pairs individually. Then, all the pairwise DoC values are averaged, i.e., averaging n(n−1)2
pairs and is calculated for each of those pairs individually. Then, all the pairwise DoC values are averaged, i.e., averaging n(n−1)2![]() pairs of DoCAi,Aj
pairs of DoCAi,Aj![]() . Finally, the certainty (i.e., cˆ⊕c(A1,A2,…,An)
. Finally, the certainty (i.e., cˆ⊕c(A1,A2,…,An)![]() ) parameter of the resulting opinion (cf. Table 2) is adjusted with the resulting DoC value.
) parameter of the resulting opinion (cf. Table 2) is adjusted with the resulting DoC value.
In Table 2, for all opinions if it holds cAi=0![]() (complete uncertainty), the expectation values (cf. Definition 7) depends only on f. However, for soundness we define tAi=0.5
(complete uncertainty), the expectation values (cf. Definition 7) depends only on f. However, for soundness we define tAi=0.5![]() in this case.
in this case.
4.2.2 Security capability assessment using certainLogic operators
We consider the CSA STAR as an information repository of security capabilities that are published by cloud providers. In the CSA STAR, cloud providers publish one set of valid answers in response to the CAIQ regarding each of the services they offer. The answers are evidence of corresponding capabilities that cloud providers claimed to have. Here, the CSA is assumed responsible for checking the authenticity and the basic accuracy of the answered questionnaires as mentioned in CSA (2013).
In order to assess security capabilities as published in the CSA STAR, we follow a two-step approach:
1. First, PLTs are constructed from the given CAIQ domains by means of formal analysis (cf. Section 4.1). The CAIQ domains are termed as security capabilities in this chapter. In the context of the CAIQ, a PLT configuration consists of 11 operands (i.e., capabilities) combined with 10 AND (∧) operators. Conceptually, a PLT configuration is constructed as follows:
CO∧DG∧FS∧HR∧IS∧LG∧OP∧RI∧RM∧RS∧SA
where, CO, DG, FS, HR, IS, LG, OP, RI, RM, RS, and SA are the acronyms for Compliance, Data Governance, Facility Security, Human Resources Security, Information Security, Legal, Operations Management, Risk Management, Release Management, Resiliency and Security Architecture, respectively.
2. Second, for each of the propositions (security capabilities), an associated opinion (t, c, f) is required to evaluate the PLTs. The opinions need to be extracted from cloud providers’ answers to the CAIQ domains. The answers are usually in the form of “yes” or “no”, which upon analysis can be classified to positive and negative pieces of evidence. These evidence units demonstrate the level of security capabilities a cloud provider has regarding the services it offers in cloud ecosystems. In Ries (2009b), a mapping is proposed to map the collected pieces of evidence to the opinion space. The mapping (cf. Equation 2) has been proposed in the context of ubiquitous computing environments, where evidence units are collected based on a trustor’s interaction experience with a trustee. In this context, positive (r) and negative (s) pieces of evidence are mapped to the CertainTrust opinion space. In the context of CAIQ, evidence units are based on the cloud providers’ self-assessment of security capabilities regarding each of the services they offer. As the existence of the capabilities are reasoned based on the given assertions, the same mapping function is used to derive opinions from those assertions, i.e., positive and negative pieces of evidence, under each of the capabilities. The mapping between the evidence space and the CertainTrust opinion space is as follows:
t={0ifr+s=0,rr+selse.c=N⋅(r+s)2⋅(N−(r+s))+N⋅(r+s)f=0.99
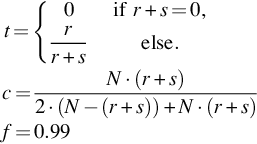
The definitions regarding the parameters are as follows:
• Average rating, t, is calculated based on the number of positive assertions (r) and the number of negative assertions (s) under each domain. If there are no questions answered, t is 0. Otherwise, t is the relative frequency of positive and negative assertions.
• Certainty, c, is calculated based on the total number of questions, N and the number of positive (r) and negative (s) assertions under each domain. c is 1 when all questions under each domain are answered with positive or negative assertions and 0 if none are answered.
The definition of N is adjusted according to the context of CAIQ assessment. The total number of questions, N, not only considers positive and negative assertions but also the unanswered questions under each domain. The unanswered questions can be of two types:
(a) Questions that cloud providers left out for unknown reasons or an answer to a question is indeterminable to classify as “yes” or “no”.
(b) Questions that do not fit the scope of the services (i.e., Not Applicable) offered by the respective cloud providers.
In order to deal with the above-mentioned types of questions, we define N as following:
• For type (a), the unknown (to which we refer as “u”) marked answer(s) to the corresponding question(s) under each domain are taken into account. That means, N = r + s + u.
• For type (b), the Not Applicable (to which we refer as “NA”) marked answers under each domain are not included in the calculation of N. That means, N = (r + s + u) − NA.
• Initial expectation, f, is set very high (i.e., 0.99) for every single domain assuming that cloud providers publish information regarding their capabilities in the STAR repository truthfully and that the accuracy of this information is validated using the CloudAudit (CSA, 2012a) framework.
In the CertainTrust model, the expectation value (E) is calculated based on Definition 7. E is computed based on t, c, and f. Herein, with increasing certainty (which means that a large amount of evidence is available), the influence of the f ceases. In the context of security capability assessment, the E represents the level of security capability that a cloud provider possess.
4.3 Visually communicating multiple security capabilities
When communicating the results of a security capability evaluation to human users, a set of numerical expectation values or opinion tuples is usually inferior to a visual representation. The latter one is intended to be understood easier and faster by humans in comparison with textual descriptions that include numerical values only.
The Human Trust Interface (cf. Figure 1 (c)) in Ries and Schreiber (2008) is used to visualize a single CertainTrust opinion. It can be used to display the overall result of trust assessments of cloud providers. However, it is often more suitable to convey detailed information to potential customers.
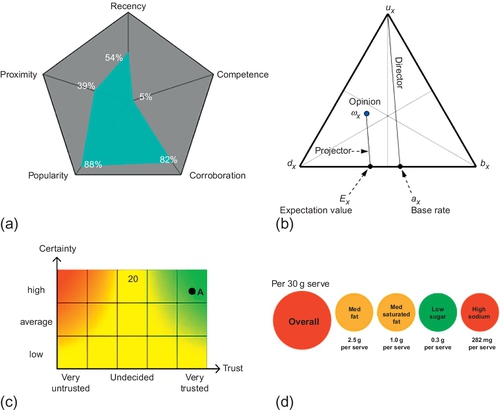
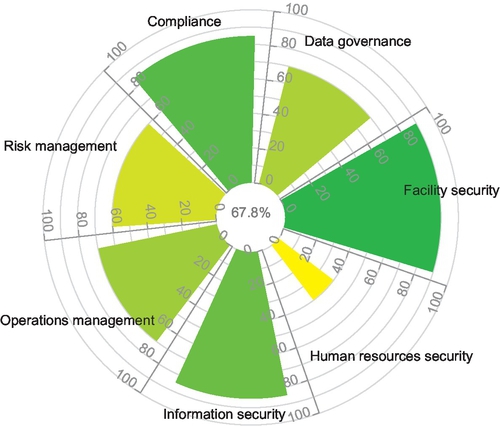
The Star-Interface is one of the most popular visualizations for trustworthiness. The more stars a product is given, the higher its rating and thus, its trustworthiness. However, the Star-Interface lacks two important features to be used in communicating multicriterial trust: (i) it lacks a certainty measure, i.e., how much evidence a rating is based on and (ii) only one rating is shown at a time. Nurse et al. present a multicriterial trust visualization using radar charts in Nurse et al. (2013) (cf. Figure 1 (a)). Five trust factors—namely recency, competence, corroboration, popularity, and proximity—are shown within one graph. The score for each trust factor is ploted on one of the axis of the pentagon-shaped graph. Aside being limited to these five fixed trust factors, the graph does not denote certainty at all. The Opinion Triangle by Jøsang et al. (2012) (cf. Figure 1 (b)) enriches the display of a trust value with an uncertainty measure. Similar to the Star-Interface, the Opinion Triangle displays only one opinion at a time. The Opinion Triangle is very well suited for analysis done by experts. However, it is not readily accessible on an intuitive level. The expressive power of Ries et al.’s Human Trust Interface (Ries and Schreiber, 2008) (cf. Figure 1 (c)) is similar to the Opinion Triangle. The introduction of a color-gradient trades off quantitative-analytical capabilities for a more intuitive display of the given trust value. Kelly et al. (2009) evaluate the expressive power of a Traffic Light scheme, enriched with an overall rating, to communicate food trustworthiness (cf. Figure 1 (d)). On the one hand, this visualization combines an intuitive color-coded interface and the display of multiple criteria. On the other hand, this visualization lacks the display of certainty values.
Inspired by the four visualizations from Figure 1, the T-Viz chart was designed with three features in mind: intuitive readability, presentation of multiple trust values, and conveying certainty values alongside the trust values (Volk et al., 2014). An exemplary T-Viz is shown in Figure 2. In order to visualize multiple levels of security capabilities, the circular T-Viz chart is divided into multiple segments, one per criterion. Within each segment, a colored slice’s height denotes average rating (t) while its width denotes certainty (c). Moreover, the color of the slice denotes the expectation value (E) calculated based on trust, certainty, and initial expectation value. Thereby, the selection of colors is the same as in the Human Trust Interface. In the middle of the T-Viz graph, an overall score is shown.
The T-Viz visualization was evaluated in a user study with 229 participants. Thereby, two hypothesis have been tested based on the product ratings. We believe that the study results also apply to cloud service provider ratings.
H1: Decisions regarding quality made using the T-Viz chart are at least as good as decisions made using multiple Star-Interfaces (one per criterion).
H2: Decisions made using T-Viz are faster than decisions made using multiple Star-Interfaces.
The results of the study show a nonsignificant advantage of T-Viz over the Star-Interface regarding H1: when using multiple Star-Interfaces, participants decide correctly in 89.2% of the cases. When using T-Viz, 92% correct decisions are made. Therefore, H1 cannot be rejected. Regarding H2, a Wilcoxon-Mann-Whitney test confirms (p < 0.001) that decisions made using T-Viz are significantly faster than those made by using multiple Star-Interfaces.
Moreover, the study yielded two noteworthy qualitative results. Participants generally favor T-Viz over multiple Star-Interfaces when there are more than four categories taken into account. Several participants reported an “unexpected ease-of-use” regarding T-Viz, although they considered T-Viz to be less intuitive on first sight.
5 Case studies
In this section, we demonstrate the practicality of computational trust methods, described in Section 4, in quantifying security capabilities of cloud providers. A Java-based automated tool, Cloud Computing Assessment (CCA), was used to conduct the experiments in this section.
5.1 Case study 1: quantifying and visually communicating security capabilities
In the first case study, we demonstrate how to quantify the level of security capabilities that are published by the cloud providers in the CSA STAR. In order to do so, the CertainLogic AND (∧) operator is applied into the CSA CAIQ datasets published in the STAR. For brevity, only two CAIQ datasets of cloud storage providers are considered for experimental analysis. Our experiments are centered around two cases:
Practical
In this case, all relevant assertions derived from the STAR datasets are considered for the experiments. The idea is to demonstrate the result of security quantification when all security capabilities are considered by a cloud user. Naturally, the CertainLogic AND (∧) operator is applied in this case.
Customized
This case considers personal preferences of a user on selecting capabilities, e.g., CO, DG, FS, and IS in the context of CAIQ. This particular case demonstrates the result of security quantification when a subset of security capabilities is specified by a user.
In order to visually communicate the level of security capabilities to potential cloud service users, T-Viz (cf. Section 4.3) is used for representing multicriterial values regarding those capabilities.
5.1.1 Experiments: practical case
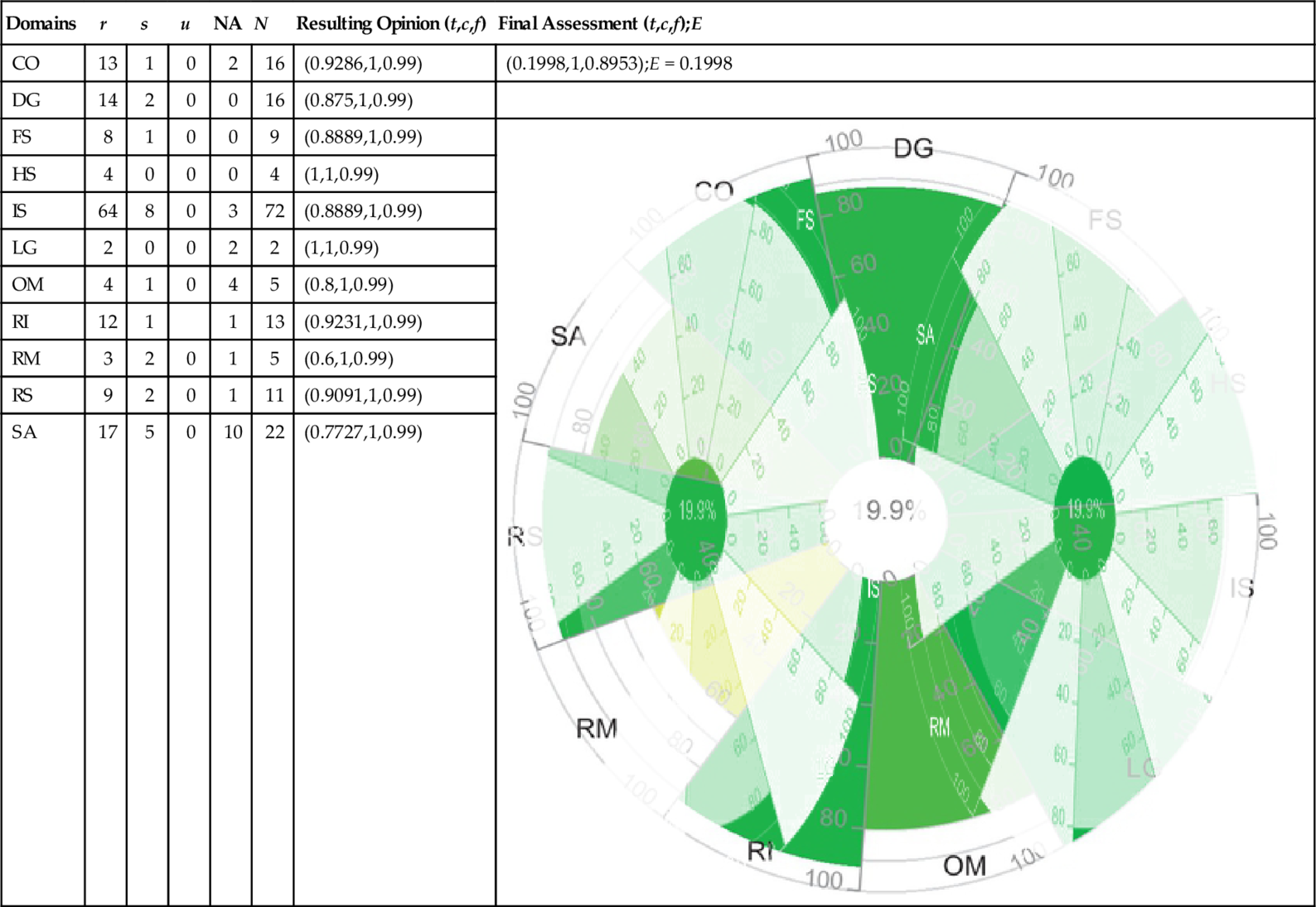
We choose two CAIQ profiles of Cloud storage providers, “D” and “M.” The identities of the cloud providers are anonymized due to usage restrictions of the STAR.
Tables 3 and 4 present a summary of the assertions. Corresponding resulting opinions are calculated using Equation 2 to map the given assertions to opinions. According to the final assessment, given in Tables 3 and 4, cloud consumers are able to identify a potential cloud provider based on the computed expectation value, i.e., the quantified security level. The security level of Cloud provider “D” is higher than that of Cloud provider “M.” It means that the level of security capabilities claimed by provider “D” is better than that of provider “M” based on the detailed assessment of underlying attributes of those capabilities. Hence, the expectation value is a reasonable indicator for users to compare cloud providers. Note that in addition to the expectation value, the certainty (c) value is a good indicator of whether the aggregated rating (t) is representative or further analysis is required.
Table 3
Practical Case: Quantified Security Capabilities of Cloud “D” (Anonymized)
| Domains | r | s | u | NA | N | Resulting Opinion (t,c,f) | Final Assessment (t,c,f);E |
| CO | 16 | 0 | 0 | 0 | 16 | (1,1,0.99) | (0.3085,0.9978,0.8953);E = 0.3098 |
| DG | 13 | 2 | 1 | 0 | 16 | (0.8667,0.9917,0.99) | |
| FS | 8 | 1 | 0 | 0 | 9 | (0.8889,1,0.99) | 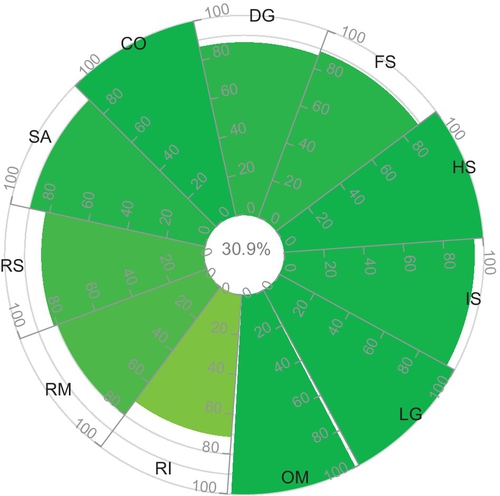 |
| HS | 4 | 0 | 0 | 0 | 4 | (1,1,0.99) | |
| IS | 64 | 3 | 5 | 3 | 72 | (0.9552,0.9979,0.99) | |
| LG | 2 | 0 | 0 | 2 | 2 | (1,1,0.99) | |
| OM | 5 | 0 | 1 | 3 | 6 | (1,0.9375,0.99) | |
| RI | 10 | 4 | 0 | 0 | 14 | (0.7143,1,0.99) | |
| RM | 4 | 1 | 0 | 1 | 5 | (0.8,1,0.99) | |
| RS | 10 | 1 | 0 | 1 | 11 | (0.8182,1,0.99) | |
| SA | 27 | 3 | 0 | 2 | 30 | (0.9,1,0.99) |
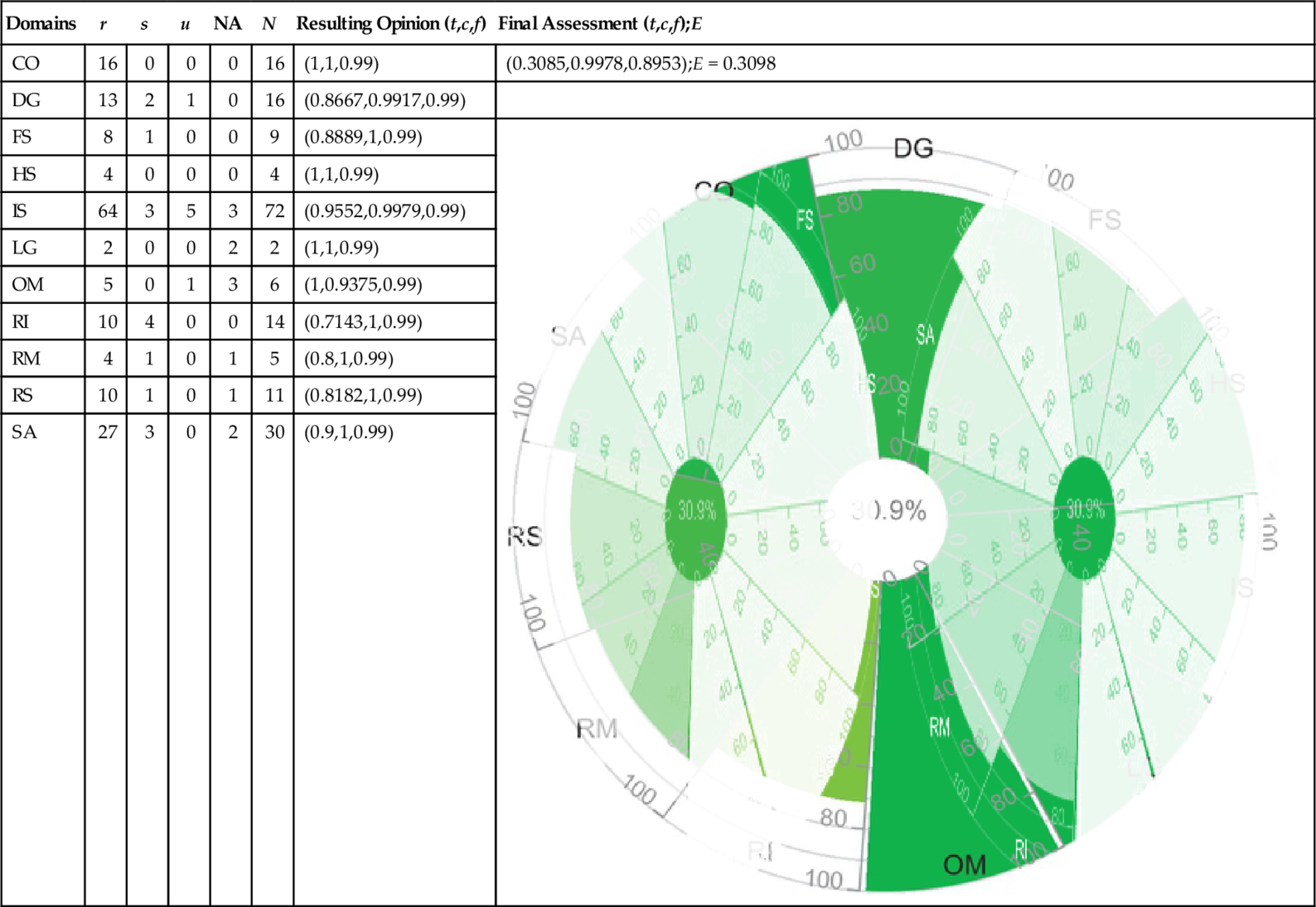
Table 4
Practical Case: Quantified Security Capabilities of Cloud “M” (Anonymized)
| Domains | r | s | u | NA | N | Resulting Opinion (t,c,f) | Final Assessment (t,c,f);E |
| CO | 13 | 1 | 0 | 2 | 16 | (0.9286,1,0.99) | (0.1998,1,0.8953);E = 0.1998 |
| DG | 14 | 2 | 0 | 0 | 16 | (0.875,1,0.99) | |
| FS | 8 | 1 | 0 | 0 | 9 | (0.8889,1,0.99) | 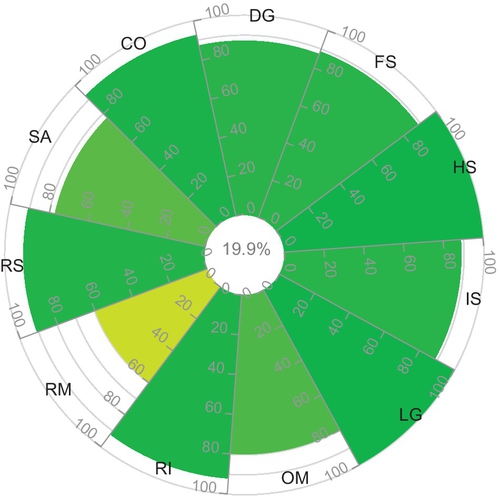 |
| HS | 4 | 0 | 0 | 0 | 4 | (1,1,0.99) | |
| IS | 64 | 8 | 0 | 3 | 72 | (0.8889,1,0.99) | |
| LG | 2 | 0 | 0 | 2 | 2 | (1,1,0.99) | |
| OM | 4 | 1 | 0 | 4 | 5 | (0.8,1,0.99) | |
| RI | 12 | 1 | 1 | 13 | (0.9231,1,0.99) | ||
| RM | 3 | 2 | 0 | 1 | 5 | (0.6,1,0.99) | |
| RS | 9 | 2 | 0 | 1 | 11 | (0.9091,1,0.99) | |
| SA | 17 | 5 | 0 | 10 | 22 | (0.7727,1,0.99) |
5.1.2 Experiments: customized case
Tables 5 and 6 reflect a user’s preference while quantifying security levels of cloud providers. A user might require cloud providers to possess security capabilities regarding CO, DG, FS, and IS as a part of their service provisioning policy. We demonstrate experiments on the CAIQs submitted by Cloud “D” and Cloud “M” in the STAR. By enabling the customization feature of the CCA tool on the completed CAIQs, we observe notable changes in opinion values as well as in expectation values (security levels) calculated for both providers in comparison to the results given in Tables 3 and 4. Moreover, the customization feature enables the customers to get a personalized assessment of a cloud providers’ security capabilities in contrast to the fixed Excel-based CAIQ assessment available in the CSA website. In our case study, we mimicked user preferences by randomly selecting security capabilities from the given list using our tool.
Table 5
Customized Case: Quantified Security Capabilities of Cloud “D” (Anonymized)
| Domains | r | s | u | NA | N | Resulting Opinion (t,c,f) | Final Assessment (t,c,f);E |
| CO | 16 | 0 | 0 | 0 | 16 | (1,1,0.99) | (0.7363,0.9978,0.9606);E = 0.7368 |
| DG | 13 | 2 | 1 | 0 | 16 | (0.8667,0.9917,0.99) | 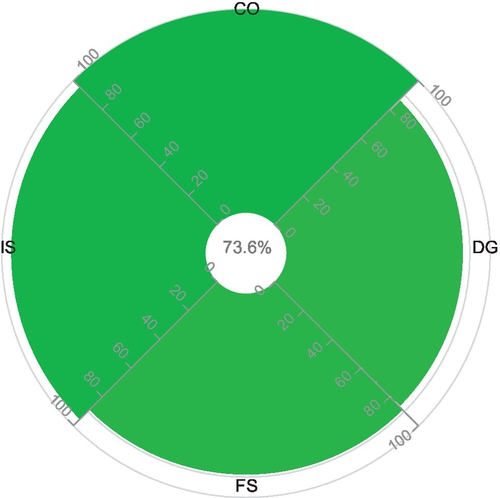 |
| FS | 8 | 1 | 0 | 0 | 9 | (0.8889,1,0.99) | |
| IS | 64 | 3 | 5 | 3 | 72 | (0.9552,0.9979,0.99) |
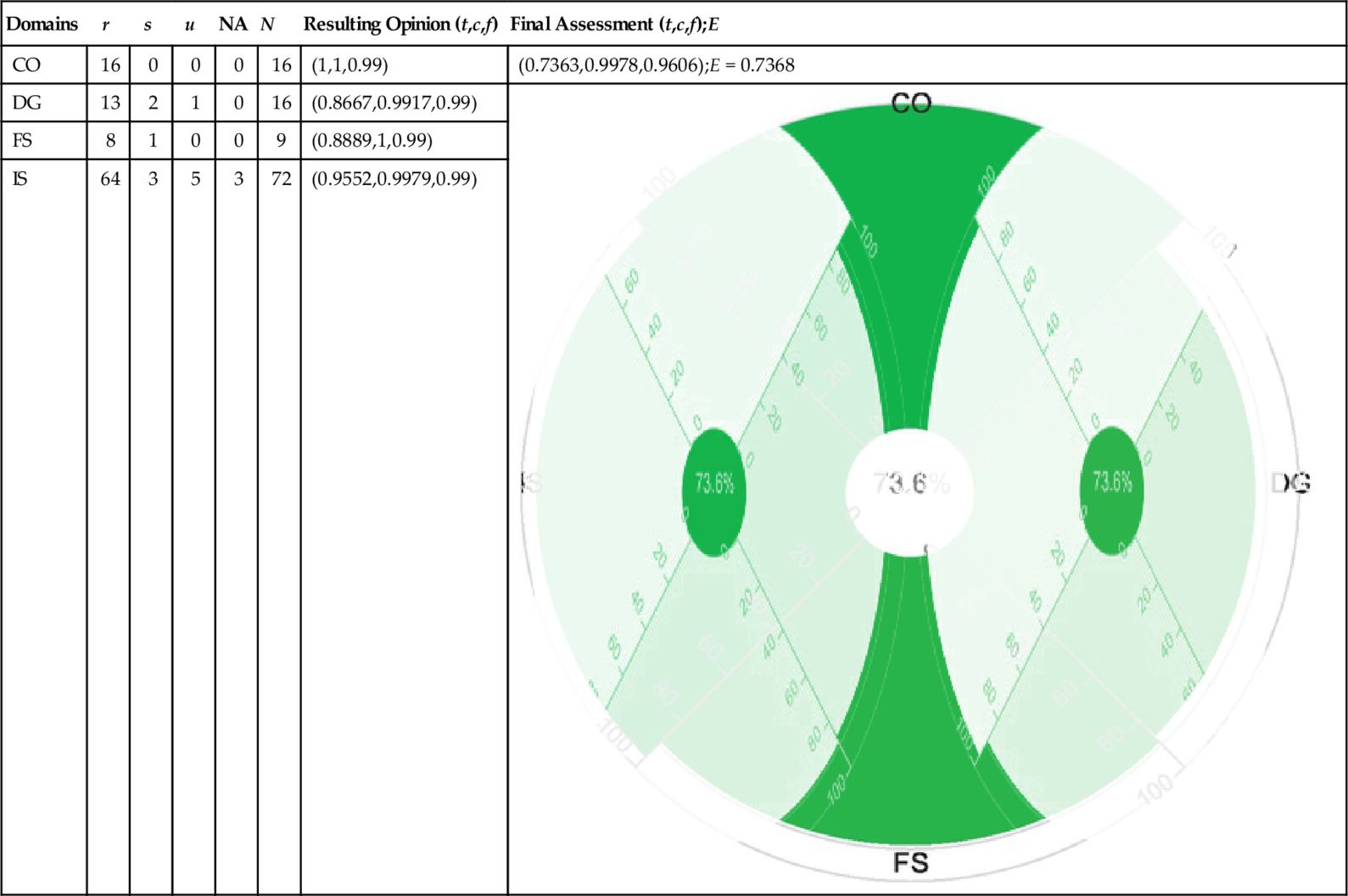
Table 6
Customized Case: Quantified Security Capabilities of Cloud “M” (Anonymized)
| Domains | r | s | u | NA | N | Resulting Opinion (t,c,f) | Final Assessment (t,c,f);E |
| CO | 13 | 1 | 0 | 2 | 14 | (0.9286,1,0.99) | (0.642,1,0.9606);E = 0.642 |
| DG | 14 | 2 | 0 | 0 | 16 | (0.875,1,0.99) | 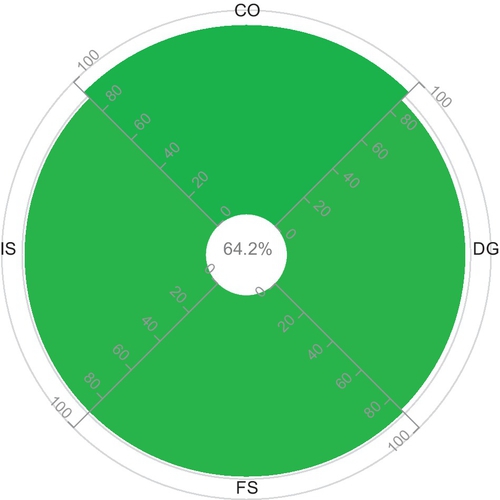 |
| FS | 8 | 1 | 0 | 0 | 9 | (0.8889,1,0.99) | |
| IS | 64 | 8 | 0 | 3 | 72 | (0.8889,1,0.99) |
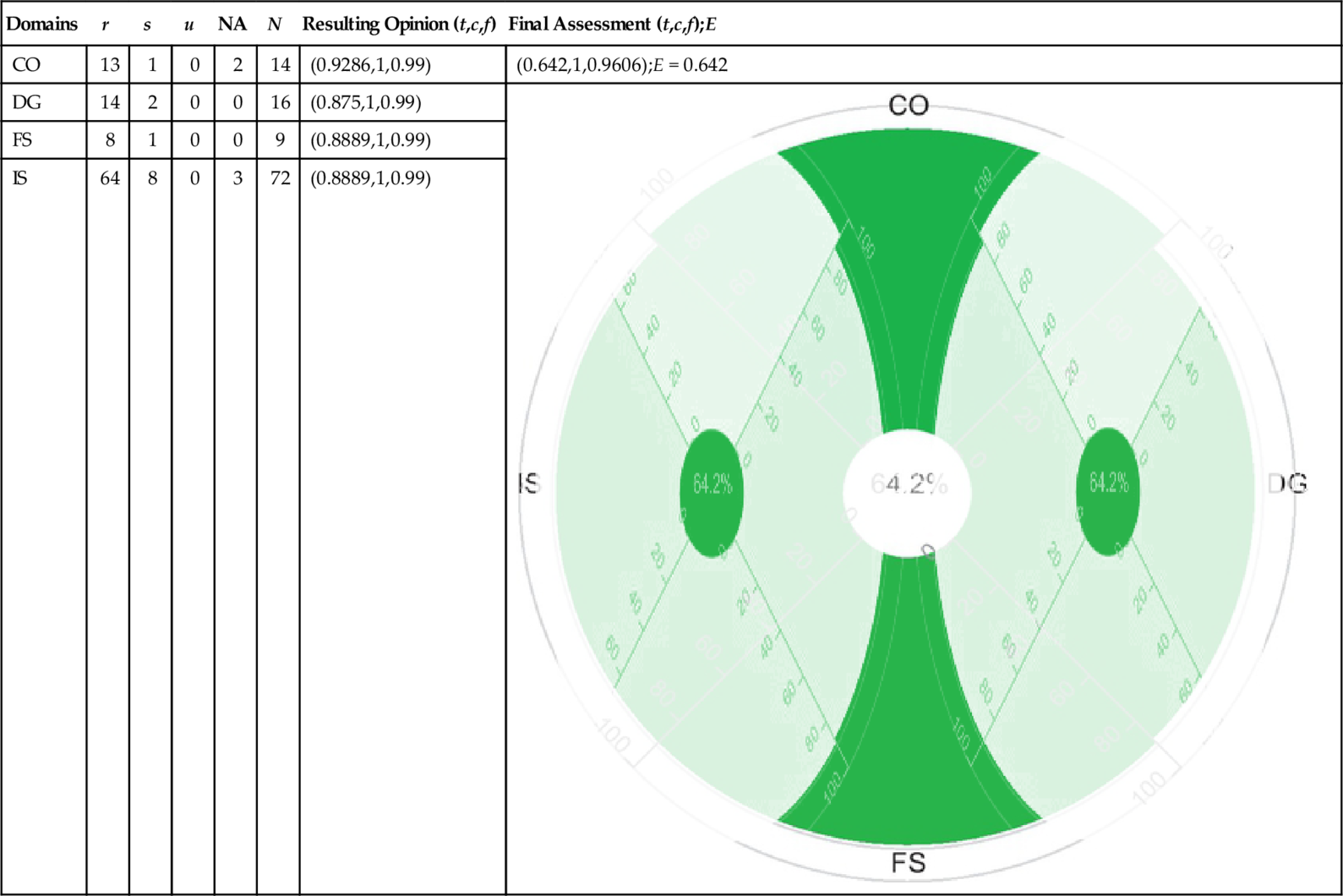
In continuation, now we analyze the documented results in Tables 5 and 6. The security levels, calculated based on the customization of the capabilities, are significantly higher than the values calculated in Tables 3 and 4. The reason behind the deviation of the security levels is that the underlying assertions of required capabilities are more “positive” than those of Tables 3 and 4. It means that the cloud providers in Table 5 and 6 have a higher security level in the customized case than in the practical case. Based on the results of the final assessment in the customized case, we conclude that cloud provider “D” has a better security level than cloud provider “M.” The reason here is that “D” posseses all the attributes under CO capability as well as a lower number of missing attributes under IS capability compare to “M.”
In this section, we have demonstrated the applicability of the formal framework (cf. Section 4.1) and the CertainLogic AND (∧) operator for combining opinions on independent propositions. The propositions are constructed according to the independent domains given in the CSA CAIQ. Opinions on the propositions are derived from the assertions given by the cloud providers in the STAR. Considering the CertainLogic AND (∧) operator for quantifying security capabilities in this context demonstrates the operator’s applicability in real world settings.
5.2 Case study 2: quantifying and communicating security capabilities in presence of multiple sources
In this section, we assume that the security capabilities of Cloud “D” and Cloud “M” are assessed by multiple sources. Along with the default CAIQ assessment, discussed in the previous section, two other sources are considered for our case study. In the following, we provide a brief overview of those sources and their opinion generation process.
The resulting three opinions are extracted in the following manner:
1. CAIQ assessment: The resulting opinion (oQ) on the trustworthiness of Cloud “D” and “M” is generated from their completed CAIQ published by the CSA STAR.
2. Accreditors: Accreditors use the CCA tool to assess the capabilities of Cloud “D” and “M.” The resulting opinion (oA) is then extracted based on the assessment. The opinion is represented using the CertainTrust model.
3. Expert assessment: The capabilities of Cloud “D” and “M” are assessed by experts using our CCA tool. The resulting opinion (oE) is then derived by the experts using the CCA tool. The opinion is represented using the CertainTrust model.
5.2.1 Experiments
In order to derive the opinion oQ, the published CAIQs in the STAR are considered. Hence, we use the resulting opinions (derived from CAIQs) documented in Tables 5 and 6 for the experiments conducted in this section. The accreditors and experts may analyze the assertions of CAIQs in a different manner which results in four different outcomes: Tables 7–10. Thus, the resulting opinions (oA and oE), derived from the CAIQ profiles of Cloud provider “D” and “M,” are different than the opinion oQ in Tables 5 and 6.
In a real world setting, one would assume that a user can choose between a couple of cloud providers, e.g., Cloud provider “D” and “M.” In this case, we propose to sort the cloud providers based on their expectation value E and using the DoC as a second criteria if necessary. The opinions considered to calculate the fused opinions of Cloud provider “D” and Cloud provider “M” are given in Tables 5, 7, 8 and Tables 6, 9, and 10 respectively.
Table 7
Quantified Security Capabilities of Cloud “D” (Anonymized): Accreditor Perspective (oA)
| Domains | r | s | u | NA | N | Resulting Opinion (t,c,f) | Final Assessment oA;E |
| CO | 16 | 0 | 0 | 0 | 16 | (1,1,0.99) | (0.8994,0.9938,0.9606);E = 0.8998 |
| DG | 15 | 1 | 0 | 0 | 16 | (0.9375,1,0.99) | 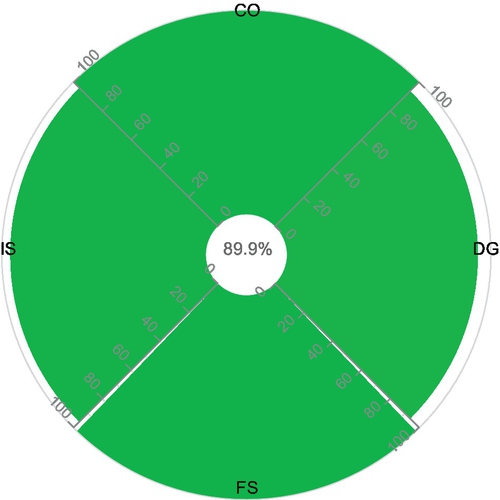 |
| FS | 8 | 0 | 1 | 0 | 9 | (1,0.973,0.99) | |
| IS | 72 | 3 | 0 | 1 | 75 | (0.96,1,0.99) |
Table 8
Quantified Security Capabilities of Cloud “D” (Anonymized): Expert Perspective (oE)
| Domains | r | s | u | NA | N | Resulting Opinion (t,c,f) | Final Assessment oE;E |
| CO | 16 | 0 | 0 | 0 | 16 | (1,1,0.99) | (0.8003,0.9937,0.9606);E = 0.8013 |
| DG | 15 | 1 | 0 | 0 | 16 | (0.9375,1,0.99) | 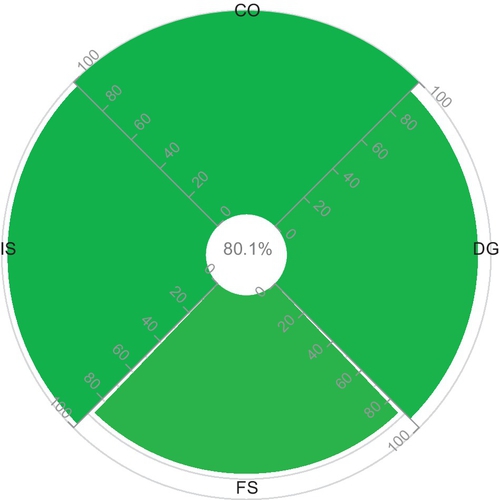 |
| FS | 7 | 1 | 1 | 0 | 9 | (0.875,0.973,0.99) | |
| IS | 73 | 2 | 0 | 0 | 75 | (0.9733,1,0.99) |
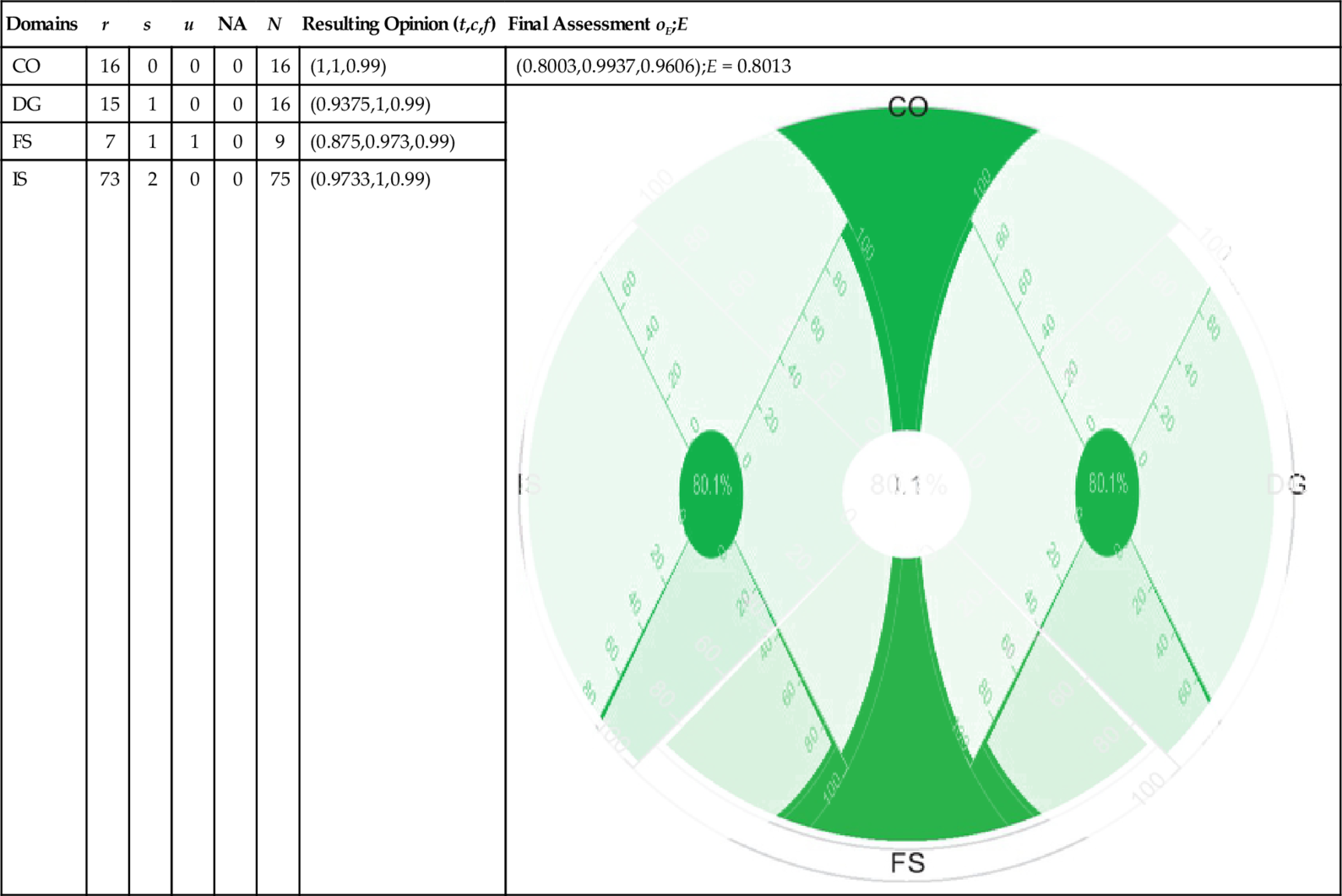
Table 9
Quantified Security Capabilities of Cloud “M” (Anonymized): Accreditor Perspective (oA)
| Domains | r | s | u | NA | N | Resulting Opinion (t,c,f) | Final Assessment oA;E |
| CO | 11 | 1 | 2 | 2 | 14 | (0.9167,0.9767,0.99) | (0.6277,0.9957,0.9606);E = 0.6291 |
| DG | 15 | 1 | 0 | 0 | 16 | (0.9375,1,0.99) | 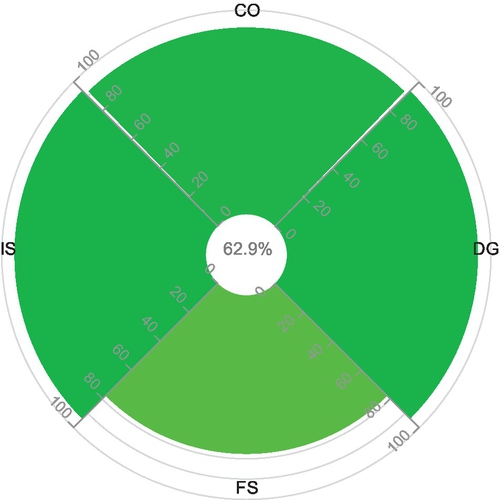 |
| FS | 7 | 2 | 0 | 0 | 9 | (0.7778,1,0.99) | |
| IS | 62 | 4 | 4 | 5 | 70 | (0.9394,0.9983,0.99) |

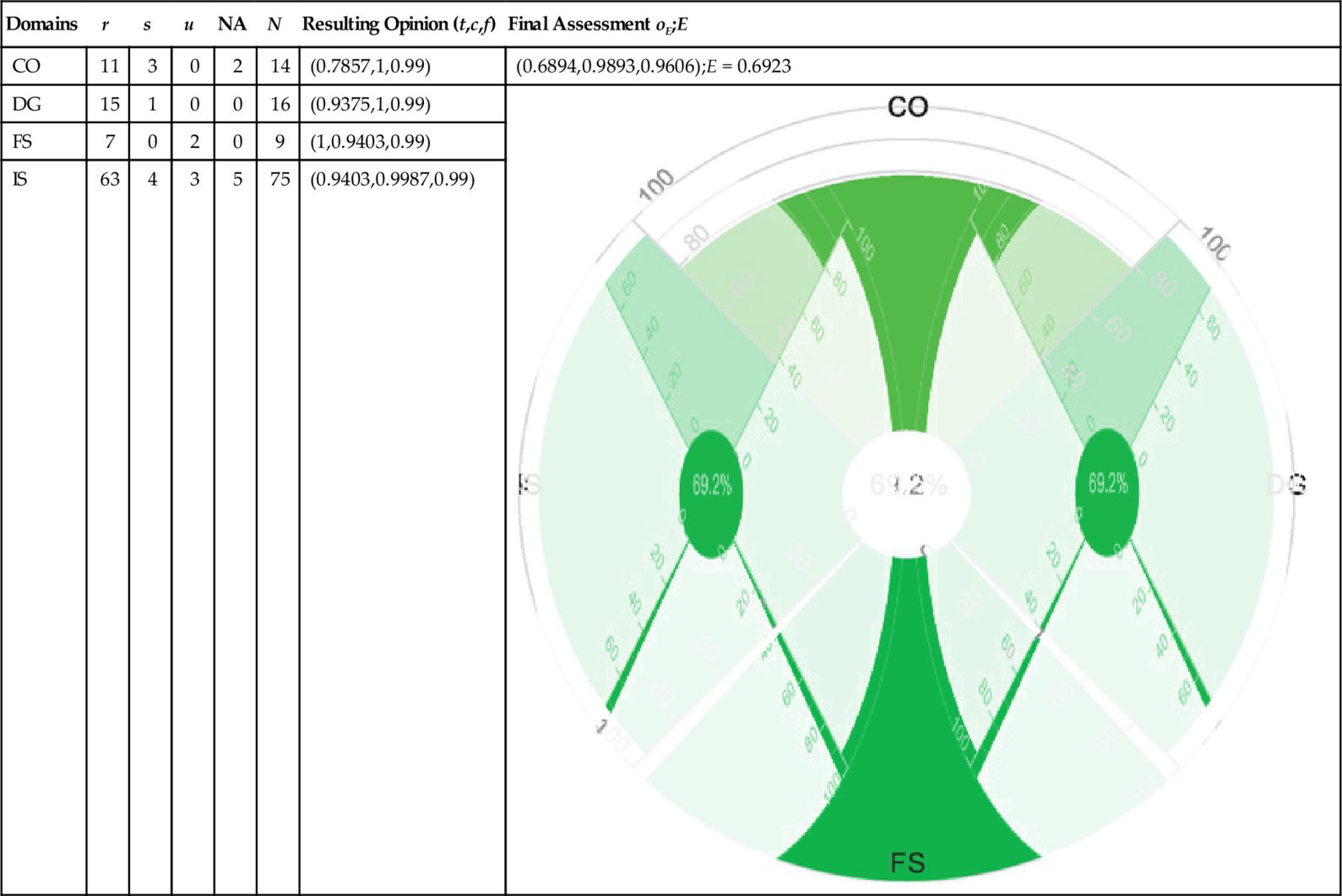
Table 10
Quantified Security Capabilities of Cloud “M” (Anonymized): Expert Perspective (oE)
| Domains | r | s | u | NA | N | Resulting Opinion (t,c,f) | Final Assessment oE;E |
| CO | 11 | 3 | 0 | 2 | 14 | (0.7857,1,0.99) | (0.6894,0.9893,0.9606);E = 0.6923 |
| DG | 15 | 1 | 0 | 0 | 16 | (0.9375,1,0.99) | 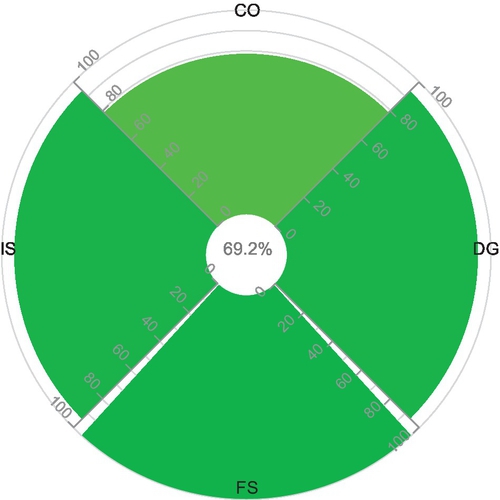 |
| FS | 7 | 0 | 2 | 0 | 9 | (1,0.9403,0.99) | |
| IS | 63 | 4 | 3 | 5 | 75 | (0.9403,0.9987,0.99) |
In Table 11, C.FUSION (cf. Table 2) is applied to aggregate the opinions, derived from multiple sources, on security capabilities of Cloud provider “D” and “M.” Here, we found a special case while fusing the opinions regarding security capabilities of Cloud provider “M.” The default opinion (oQ) regarding the security capabilities of Cloud provider “M” has absolute certainty (i.e., c = 1); according to the definition of C.FUSION, fusion is only possible if and only if none of the opinions have absolute certainty. Therefore, for comparing security capability levels between Cloud “D” and “M,” users might either choose the resulting opinion that calculates the highest expectation value or choose the opinion that has absolute certainty regarding the security capabilities of Cloud “M.”
Table 11
Cloud “D” vs. Cloud “M”
| Cloud provider “D”: oˆ⊕c(Q,A,E,F) | Cloud provider “M”: oQ; oE |
| (0.7832,0.8888,0.9606) | (0.642,1,0.9606); (0.6894,0.9893,0.9606) |
| E = 0.8029 | E = 0.642; E = 0.6923 |
| DoC= 0.1076 | DoC=N/A |
According to the calculated expectation values, Cloud provider “D” has a better security level than Cloud provider “M” considering either of the two potential opinions. This comes from the fact that the given assertions by provider “D” are more positive (t = 0.7832) than those of provider “M” (t = 0.6894 or t = 0.642) regarding the required capabilities, CO, DG, FS, and IS. Even though the certainty values (0.9604 and 1) indicate better representativeness of the average rating of Cloud “M,” it is not enough for provider “M” to receive a better expectation value E than provider “D.” In this special case, the DoC value is not a deciding factor because of the special case of Cloud “M.”
6 Conclusion
Computational trust methods support cloud users to quantitatively reason the security capabilities of cloud providers in presence of uncertain and conflicting information. This is a significant step forward in the research context of security quantification. Automated security quantification techniques (formal framework along with CertainLogic operators and multicriterial visualization), as described in this chapter, remove the burden of the users in assessing the security capabilities manually using the STAR platform. By using the automated techniques, users in cloud ecosystems will be able to assess the overall security capabilities of cloud providers. Hence, they will feel more confident in adopting cloud services for their business.
In this chapter, the computational trust methods provide means to compare cloud providers in a qualitative manner. It would be interesting to investigate quantitative benchmarking methods to rank cloud providers based on their security capabilities. These methods should not only consider user requirements but also consider the correlation of underlying attribute assertions of security capabilities under specific service types.
Acknowledgment
This work has been (co)funded by the DFG as part of project S1 (Scalable Trust Infrastructures) within the CRC 1119 CROSSING.
Appendix. proof for theorem 1
We prove the theorem along the inductive definition of security terms, and we provide the corresponding propositional logic formula for each definition of security terms. The principal idea of the proof is that we reformulate the expression “k out of a set L" by explicitly considering all combinations of elements of L, where L can be either a set of properties or of trustworthiness terms of sub-properties. The provision of such a mapping f (of trustworthiness terms on propositional logic terms) proves the theorem.
Proof 1
• If l = (k “out-of” N), k∈{1,…,|N|},N⊆A![]() (Definition 2), then
(Definition 2), then
f(l):=∨{Ai1,…,Aik}⊆A|{Ai1,…,Aik}|=k(ik∧j=i1Aj)
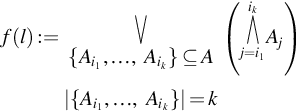
• If l = ((k1 ![]()
![]()
![]() km) “out-of” (N1,
km) “out-of” (N1, ![]() , Nm)), Ni⊆A∀i
, Nm)), Ni⊆A∀i![]() (Definition 3), then
(Definition 3), then
f(l):=m∧i=1(f((ki“out-of”Ni)))
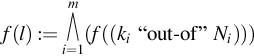
• If l=(k“out-of”{li1,…,lim}),lijtrustworthinessterms,{i1,…,im}⊆{1,…,n}![]() (Definition 4), then
(Definition 4), then
f(l):=∨{j1,…,jk}⊆{i1,…,im}|{j1,…,jk}|=k(jk∧j=j1(f(lj)))
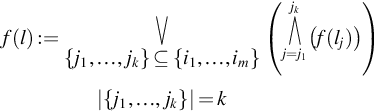
• If l = ((k1 ![]()
![]()
![]() km) “out-of” (Q1,
km) “out-of” (Q1, ![]() , Qm)), Qiset oftrustworthiness terms
, Qm)), Qiset oftrustworthiness terms![]() (Definition 5), then
(Definition 5), then
f(l):=m∧i=1(f((ki“out-of”Qi)))