
Cloud as infrastructure for managing complex scalable business networks, privacy perspective
Abdussalam Ali; Igor Hawryszkiewycz Faculty of Engineering and IT, School of Systems, Management and Leadership, University of Technology, Sydney, Australia
Abstract
This chapter presents a model that can be used to define strategies for designing and implementing a knowledge management on the cloud. The focus of the chapter is on ways to share knowledge while preserving privacy and security in scalable business networks. The model is particularly relevant to cloud technology so that businesses can effectively use features provided by this technology including scalability or availability and its low cost. That includes the businesses of different sizes, from small to medium, and enterprises. Knowledge management discipline is not an exception to benefit from this technology and its advantages. In this study, we have presented some strategies that may help when implementing knowledge management systems by considering cloud computing as infrastructure.
1 Introduction
In this chapter, we present strategies for designing and implementing a model to support KM as considering the privacy issue. These strategies are based on a current research that deals with implementing a model to support KM in complex business networks. Cloud computing infrastructure technology has been suggested as the infrastructure to implement this model. Also, we show the requirements of privacy and how it can be supported in the model. That is based on the fact that knowledge is a private asset in nature either it is owned by individuals, groups, or firms.
The advantages of cloud technology include scalability, availability, and its low cost. That extends its use in small and medium businesses in addition to enterprises. The scalability feature in cloud allows businesses to scale their activities without concern with hardware and storage. On the other hand, this technology has its concerns and risks which businesses should take into consideration when they use it. The top of that, of course, is the security and privacy issue.
To present our approach of modeling, we have structured this chapter as following:
In Section 1, we define knowledge and knowledge management (KM) based on a number of literatures. KM processes and systems are highlighted as well. In this section, the privacy and security have been presented in context of KM. We also investigate technology as a main success factor for supporting KM processes.
In Section 2, we present the cloud technology and declare why we have chosen this technology as infrastructure to implement our model. The concept of cloud computing has been presented in terms of its definition, types, and components. In this section, the scalability feature is explored and privacy issue is investigated as well. Concepts and approaches of knowledge and KM as a service (KaaS and KMaaS) are explored and explained in this section as well.
In Section 3, we present our principal ideas toward designing a model to support KM. In this section, we present how to model KM activities. Also, we present how people and social networks have been modeled in terms of groups and organizations based on living systems theory (LST) concepts. The privacy and how it can be supported is considered in the model. A scenario is presented to show how these strategies may be applied in reality.
2 Knowledge management
2.1 Definitions and concepts
KM in this chapter refers to processes and mechanisms of creating and sharing knowledge. KM can be defined as “the systematic and organizationally specified process for acquiring, organising and communicating knowledge of employees so that other employees may make use of it to be more effective and productive in their work” (Hahn and Subramani, 2000). There is extensive literature on KM processes including Fernandez and Sabherwal (2010), Awad and Ghaziri (2004), Dakilir (2011). Based on those literatures, these processes as shown in Figure 1 include:

• Discovering: The process of finding where the knowledge resides.
• Gathering: Knowledge gathering is alternatively used to explain the capturing. Fernandez and Sabherwal (2010) define capturing as the process of obtaining knowledge from the tacit (individuals) and explicit (such as manuals) sources.
• Filtering: The process of minimizing the knowledge gathered by rejecting the redundancy. That can be done by individuals or software agents (Dakilir, 2011).
• Organizing: The process of rearranging and composing the knowledge so that it can be easily retrieved and used to take decisions (Awad and Ghaziri, 2004).
• Sharing: It is the way of transferring knowledge between individuals and groups (Awad and Ghaziri, 2004). Fernandez and Sabherwal (2010) define knowledge sharing as “the process through which explicit or tacit knowledge is communicated to other individuals.”
In our model, we consider these processes as the functions to be implemented by people to create and share knowledge. Later in section 4, we show how we model what is called knowledge activities according to these functions.
2.2 Social networks in business environment
Social interaction has been mentioned by many authors as one of the factors for successful KM systems.
Businesses and organizations in the era of globalization become more dependent on each other. That is interpreted into collaboration where exchange of knowledge is a key factor to participate and collaborate. This collaboration is an interaction between individuals either within the business itself or between businesses. This interaction happens through what is called social networks. In the context of business, these networks are the business networks (Qureshi, 2006).
Networks support the organization to access knowledge, resources, technologies, and markets. Researchers argue that the most important benefit of social networks is approaching new sources of knowledge (Chatti, 2012). These social interactions should be supported in these environments (Fischer and Ostwald, 2001).
In our research, we propose a model to manage gathering, creating, organizing, and sharing the knowledge between business networks within the complex business networks environment. The research sees knowledge sharing as predominantly a socio-technical issue. From the point view of privacy, we show what strategies for controlling privacy between these networks.
2.3 Technology as KM enabler
Technology in KM should be considered as a tool to support people to implement knowledge processes and activities. However, technology should not be a replacement to human factor.
Many literatures and researches consider technology as a critical success factor in supporting KM systems. These papers include Wong (2005), Moffett et al. (2003), Luo and Lee (2013), Alazmi and Zairi (2003), Davenport et al. (1998), and Rasmussen and Nielsen (2011).
Many authors also report that the approaches followed to use technology as KM driver is not adequate. That is because KM systems are treated in the same way as information systems in terms of design and implementation. Nunes et al. (2006) observe from the interviews that ICT presence and implementation does not mean that knowledge is shared effectively throughout the firm. Fischer and Ostwald (2001) report that technology alone is not adequate to solve the issue of KM.
Limitations of the technology in supporting KM can be summarized as following:
1. Technology does not serve more than the storage of information (Currie and Maire, 2004; Nunes et al., 2006; Birkinshaw, 2001).
2. Limitation to knowledge types. IT systems operate as storages for explicit knowledge more than tacit type (Nunes et al., 2006; Birkinshaw, 2001)
3. Overlooking the “social interaction” phenomena when introducing IT for KM. Considering this sort of limitation is crucial as the social interaction is a main mechanism in knowledge sharing and transferring activities (Birkinshaw, 2001).
Our approach in designing the model is considering technology as a supporter and enabler to the KM. Technology is to be employed to manage and support the social interaction between individuals and groups in business networks rather than substitute them.
2.4 Security and privacy in KM context
Knowledge as an intellectual asset must be protected. Business secrets should be highly protected for not to be captured by the other competitors. In this case, an access control mechanisms should be implemented to provide this sort of protection (Bertino et al., 2006). These mechanisms suppose to control the access of knowledge when sharing and transferring processes take place. Knowledge creator or owner specifies who should be permitted to access this knowledge (Bertino et al., 2006; Muniraman et al., 2007).
Control access procedures should be easy and user friendly. As mentioned by Muniraman et al. (2007) that the system should not have much restrictions so users do not refuse to use the system. In other words, there should be a balance between privacy and accessibility. Knowledge is to be accessed only by authorized people, and those authorized are supposed to access knowledge easily when they need it.
It is known that knowledge is either in explicit or tacit form. Also, and as mentioned previously, that tacit knowledge presents the most of knowledge. In context of information systems, usually security and privacy techniques and procedures focus on how to control accessing the information storage artifacts. Tacit component of knowledge should be considered in designing privacy and security procedures and policies. Policies in organization must be implemented to control accessing knowledge and experts, and what kind of knowledge should be transferred and to whom.
As our choice for the infrastructure in implementing our model is the cloud technology, in Section 3 we present cloud computing overview and explain the issue of privacy and security. Then, we present the idea of our model and what are the strategies to be followed to implement privacy procedures and policies.
3 Cloud computing overview
3.1 Cloud computing concepts
The idea behind cloud computing is that the local computer does not deal with running the applications. Instead, the powerful remotely accessed computers and servers are dealing with this job (Strickland, 2008).
Marston et al. (2011) define cloud computing as “an information technology service model where computing services, both hardware and software, are delivered on-demand to customers over a network in a self-service fashion, independent of device and location.”
Accessing of cloud computers, network, and services is done through interface software that runs in the local computer. The simple example of that is the Web browser. Cloud computing is not a new idea as it has been implemented through remotely accessed applications such as Yahoo, Gmail, and Hotmail. Simply the cloud computing architecture can be defined through two parts, the front end and the back end. The front end represents the client that accesses the cloud via interface software, and the back end represents the cloud where the servers, data centers, and powerful computing machines reside. Here, the virtualization can be implemented to reduce the need of hardware machines (Strickland, 2008).
Features of cloud computing (Strickland, 2008) can be summarized as follows:
1. Accessibility: accessing applications anytime from any place.
2. On demand self-service: refers to the availability of service along time.
3. Scalability: it is the ability to quickly and automatically to scale out or to scale in.
4. Cost reduction: reducing hardware needs in client side, either for computing or storage. That reduces onsite infrastructure costs.
Three main layers of services represent cloud computing technology. These layers are (Furht, 2010) as follows:
1. Infrastructure as a Service (IaaS): This refers to the hardware component of cloud. It includes the virtualized computers and the storage accessed by them. These computers should have a guaranteed processing power.
2. Platform as a Service (PaaS): This layer is considered as development environment for developers. It contains the operating system and may contain Integrated Development Environment.
3. Software as a Service (SaaS): It is shown as the top layer. It represents those services accessed remotely by the users to utilize and to make use of the platform and infrastructure.
The aim of our model is to implement services on cloud to support KM activities between business networks. These services are supposed to use cloud as infrastructure and to be implemented as SaaS on this infrastructure.
There are three types of cloud computing that can be described as follows (Furht, 2010):
1. Public cloud: Cloud computing resources are accessed through the Internet. It is called an external cloud as well.
2. Private cloud: It is also called internal cloud. It is the cloud computing on private network. In this type, the customer is provided with the full control on data and security.
3. Hybrid cloud: This type combines the public and private clouds.
Figure 2 illustrates the three types of cloud computing as derived from Furht (2010).
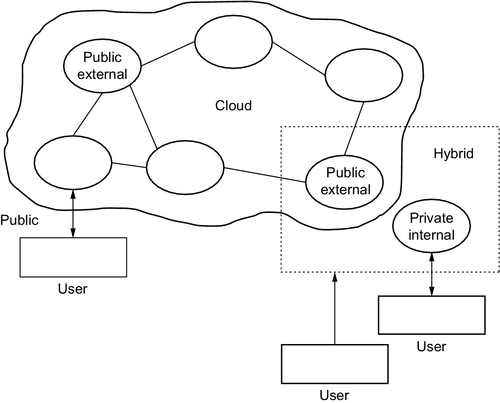
In terms of privacy and security, businesses have the choice to run their services either on public cloud, private cloud, or using both. That depends on the nature of business and the level of knowledge and information sensitivity within the firm.
3.2 Knowledge as a service
Based on the concept of services layers, KaaS and KMaaS have been emerged. The research about these concepts addresses how to benefit from the cloud technology to support KM.
Shouhuai and Weining (2005) present their framework to illustrate the KaaS paradigm as in Figure 3. The framework shows the main participants in KaaS. They are the data owners, service providers, and knowledge consumers. Data owners are provided with data produced through their transactions. Knowledge consumers extract knowledge from these datasets through services provided by the service provider. These services are provided by implemented algorithms to support knowledge extraction. In this framework, the Kaas can be described as the knowledge extracted from the owner's datasets by consumers through services upon the request of the consumer.

Lai et al. (2012) describe KaaS as the service provided by cloud to support the interprocess among the members in the collaborative knowledge network. In this research, authors derived another definition for KaaS. This definition states that KaaS is “the process in which a knowledge service provider, via a knowledge server, answers information requests submitted by some knowledge consumers.”
The study of Lai et al. (2012) introduces a KaaS model that supports medical services in China. The model is to build services via cloud to facilitate knowledge flow between the hospitals and Bio-ART center. Bio-ART center is an advanced radiology center that forward the treatments and reports to the hospitals. Hospitals may forward these tests and results to external consultants to give their opinions about these tests and treatments back to hospitals and Bio-ART. This knowledge flow is provided through cloud services to share the knowledge among the network.
Although these models have been suggested for KaaS, but it is still information storage oriented. These models treat knowledge from the aspect of query and retrieve as in information systems and databases.
3.3 Privacy and security issue in cloud computing
Privacy is one of the human rights. Controlling information owned by people is one type of privacy (Muniraman et al., 2007). Types of information need to be protected as mentioned by Muniraman et al. (2007) include:
• Personal identifiable information: Refers to the personal information used to identify people such as their names, addresses, and birth dates.
• Sensitive information: Any information considered as private. Example of that includes information about religion, race, and surveillance camera videos and images.
• Usage data: The information about habits and devices used through a computer. That includes the information about habits and interests observed through the history of Internet usage, for example.
Privacy and security is one of the main challenges in cloud computing environment. Understanding this issue is an important step to implement privacy and security solutions for cloud services and applications when needed (Chatti, 2012; Muniraman et al., 2007).
Pearson (2009) list the key privacy requirements for privacy solutions in cloud. These requirements are:
1. Transparency: Anyone who wants to collect information about users should tell what he wants to collect. Also, users should be told about what this information is to be used for. At the same time, they should be given the choice if they want this information to be used by others or not.
2. Minimization: Only the needed information is collected and shared.
3. Accessibility: Users or clients must be given access to their information to check its accuracy.
4. Security provision: Security should be implemented to safeguard unauthorized access of users from accessing the private information.
5. Limitation of usage: Information should only be limited to the purpose of use.
From the aspect of KM and KM systems, one of the main private assets is the knowledge itself, either if it is tacit or explicit, is owned by an individual, business, or organization. That is in addition to the other information about users, groups, and relationships between them.
In designing such systems, privacy and security mechanisms and policy should be well defined and implemented. In the last section, we provide more explanation about how to support privacy and security in our model based on a real scenario.
4 Strategies toward successful KM system
In this section, we present some strategies that support modeling and design toward successful KM systems. These strategies are based on the previous discussions about the KM processes, technology, and privacy issue.
These strategies are part of a research that aims to implement services on cloud to support KM in complex business environments.
Our approach includes strategies to model the following:
1. Knowledge organizations and groups.
2. KM activities and allocations.
3. Scalability and privacy.
While we are going through these strategies, we suggest a scenario to apply these strategies. That is to help understand how these approaches may apply in reality. The scenario is titled as “Children Hospital and Bags Factory Scenario.”
The story of the scenario is as in Box 1.
4.1 Modeling knowledge organizations and groups
One important aspect here is to define groups that manage knowledge activities and take responsibility for assigning them to roles and maintaining privacy.
In our model, we introduce what is called knowledge groups and knowledge organizations based on LST (Miller, 1971; Miller, 1972) concepts. By definition of LST, the group is a set of individuals and organization is a set of groups.
As shown in Figure 4, the member of a group is any individual (user) that is assigned to one role or more within the group. This individual can be assigned to different roles in different groups. The role here is a number of tasks and responsibilities implemented by an individual(s) in the group.
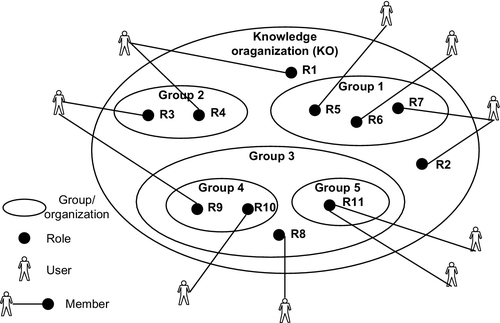
We also here introduce what is called knowledge organization (KO). This organization contains the groups, groups of groups. The boundary of KO is defined by the knowledge requirements related to a specific knowledge project. For example, gathering for the market and subject material to establish a new course subject in a college or faculty. Figure 4 illustrates the concept of organization, group, and member in our model context.
4.2 Modeling knowledge activities and allocations
Based on knowledge functions presented in Section 1, our idea of modeling KM activities is presented in Ali et al. (2014). KM activity by our definition is applying what is called the knowledge function on the knowledge element. Formally, there may be any number of knowledge elements, for example, sales, purchases, proposals, and so on. So we might define a knowledge element as K(sale) or K(purchase).
Knowledge functions are the KM processes defined in Section 1 which include discovery, capturing, filtering, …, etc. Each knowledge element is supposed to go through all the functions by default.
We use the notation discover(K(sale)), capture(K(sale)), discover(K(purchase)). We call these as KM activities.
A KM activity is a knowledge processing function applied to a knowledge element. These activities are allocated to what is called knowledge organizations and groups defined previously.
One of the goals of our model is to provide choices for changing allocations as systems evolve. The goal is to provide the flexibility to reconfigure the requirements as needed.
Allocations are at two levels, allocation of the knowledge activity to the group, followed by the allocation of action tasks to roles in the group. Here, we illustrate two examples of knowledge elements allocation.
Choices of allocating knowledge elements that are possible (Ali et al., 2014):
• Type 1 Allocation (KM function specialists)—Allocate all activities of the same KM function to one group.
• Type 2 Allocation (knowledge element specialists)—Allocate all knowledge processing activities on the same knowledge element to one organization. The organization then distributes the different knowledge processing activities to different groups.
• Type 3—Each functional unit has its own knowledge processing organization or group.
• Type 4—Totally open (hybrid).
In Figure 5, we illustrate an example of the network of Type 2 Allocation.
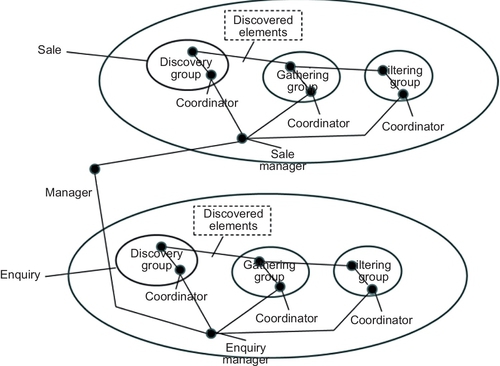
The organization is defined as a number of groups. Each group in the specific organization implements one or more of KM processes.
In the organization level, a coordinator role has been suggested to coordinate between the groups in the same organization for collaboration and knowledge sharing. The other main task of the coordinator is to manage these groups by creating and resigning them.
The services to be implemented on cloud should provide the following functions in terms of allocations:
• Creating and resigning organizations, groups, roles, and user accounts.
• Allocating groups to organizations.
• Allocating roles to groups.
• Allocating KM activities to roles and groups.
Privacy approaches should control who joins these groups and organizations, who accesses knowledge created by specific group or individual, and who can share it with others (Box 2).
Box 2
Children Hospital and Bags Factory Scenario (Organizations, Groups, and Allocations):
The empathy activity in design thinking model (Tschimmel, 2012) is the step where the designer takes the dimensions of the product by investigating the user or even those who somehow have a relation with the user himself. In our scenario, the users of product are mainly are the kids who will use these bags. In empathy activity nurses, doctors, and parents can be involved to get more empathy knowledge. Marketing department in the factory may be involved in this activity as well. In empathy activity, the designer collects as much knowledge as he can about what the user needs in relation to the product to be produced.
To define knowledge activities:
Knowledge elements: bag color, bag weight, health concerns
These are the elements that knowledge is to be gathered about.
Knowledge management functions: discover, create, organize
Knowledge management activities: discover (bag color), discover (bag weight), discover (health concerns), create (bag color), create (bag weight), create (health concerns), organize (bag color), organize (bag weight), organize (health concerns).
These activities are to be assigned to the roles and users within the groups as following:
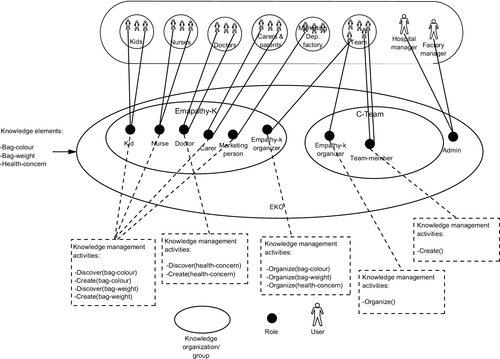
• Empathy Knowledge Organization “EKO” is created.
• This organization contains two groups: empathy knowledge group “Empathy-k” and collaborative team group “C-Team.”
• Roles are to be created into these groups.
• Emapathy-K roles are kid, nurse, carer, doctor, marketing person, Empathy-k-organizer.
• “Emapthy-K-organizer” role in “Emapthy-k” group organizes the knowledge created in this group.
• C-Team group roles: team-member, Empathy-k-organizer
• The “team-member” role task is to make sense about the knowledge created in “Empathy-k” group.
• “Empathy-k-organizer” in C-Team group organizes knowledge created by team members in this group.
• Hospital and factory managers assigned to admin role in the knowledge organization “EKO.” That allows them to manage and modify the organization as needed.
Figure 6 shows how the activities are assigned to groups, roles, and users.
5 Modeling scalability and privacy
1. The ability for flexible growth and shrink (scalability) is one of the main features of our model. Groups and suborganizations can be created within the KO in hierarchical manner. At the same time, any member in the KO can create his own KO.
2. Taking KO inside the business as a reference point, two kinds of scalability can be identified as shown in Figure 7:
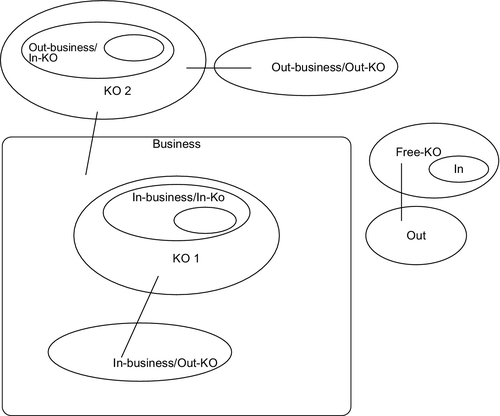
a. In-KO scalability: That means the groups and suborganizations can be created within the KO itself due to organization requirements. Example of that if it is decided to establish new group for new knowledge requirement.
b. Out-KO scalability: That is the ability of the KO members to create other KOs when required. Example of that is when a member in a KO creates his own KO to gather and share knowledge.
3. Taking the business as a reference point, two kinds of scalability can be identified as well:
a. In-Business scaling: That is the business can create as many KOs as required.
b. Out-Business scaling: The business can join/create as many KOs as it needs for collaborating with other businesses, groups, or individuals outside the business itself.
Another kind of KOs is what we call Free-KO which can be created out of the business.
By combining the previous kinds, we get the following options of scalability:
2. In-Business/Out-KO
3. Out-Business/In-KO
4. Out-Business/Out-KO
5. In-Free-KO
6. Out-Free-KO
The model also gives the option for any individual or group to establish their KOs out of business environment. The two options of In-KO and Out-KO scaling can be applied here as well.
The scalability is considered as one of motivations toward designing robust privacy strategies and mechanisms. Adding more knowledge organizations and groups to the business environment requires an effective way to control who access what and manage what.
Recalling the concepts of cloud computing, private and public cloud concepts can be implemented to control privacy of knowledge. For example, knowledge organizations that scaled within the business can be created within a private cloud. Those organizations are accessed by outside users and businesses can be implemented in the public cloud. Figure 8 illustrates this approach.
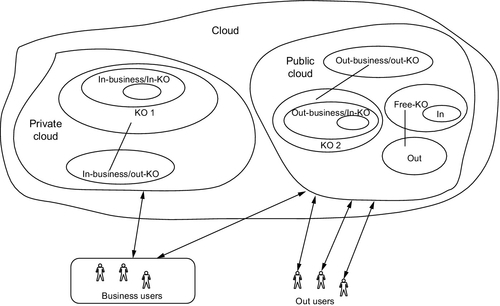
As mentioned previously, implementing privacy mechanisms is an important requirement for effective knowledge supporting systems. The level of importance increases when using cloud computing as an infrastructure.
These mechanisms should manage different levels of security and privacy. These levels include user level, group level, knowledge organization level, and business level. As the cloud stores information about businesses and individuals, there should be clear agreements with cloud providers to protect such information.
Services are accessed by users from their devices (through Web browser for example). As we see cloud stores the data structures of organizations, groups, roles, and users. In addition it stores the knowledge created by users. A control access layer should be implemented to manage accessibility. By this way, users only perform the operations that they are allowed and access only the knowledge permitted.
In Box 3, we explain how cloud concepts have been employed to implement our model by considering scalability and privacy.
Box 3
Hospital and Bags Factory Scenario (Scalability and Privacy)
In Figure 9, the cloud environment has been added.
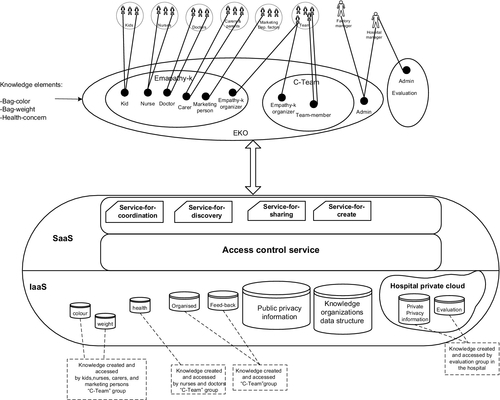
1. Referring to the IaaS and SaaS concepts, cloud should offer the storage and computing capabilities.
2. In the SaaS layer, two types of services are defined, KM services and access control service.
3. IaaS provides the mass storage for knowledge created, privacy information and knowledge organizations, and groups’ data structures.
4. This data structure is created either on public, private cloud, or both depend on business requirements.
5. In the case of public cloud, accessibility will be decided against the public privacy information.
6. In the case of private cloud, accessibility will be decided against the private privacy information.
7. The decision of accessibility is decided by the “Access Control Service” sublayer.
8. Knowledge sets are classified based on the knowledge elements defined. The feedback knowledge set created by C-Team group members is a knowledge created by making sense of knowledge created in the Empathy-k group.
Based on roles created, access control should achieve the following regarding the privacy and security:
1. Users with roles “kid,” “nurse,” “doctor,” “marketing person,” and “carer” access only the knowledge they create.
2. Accessing the knowledge created by each other is only by giving them permission from the “admin.”
3. User with “Empathy-k-organizer” role in “Empathy-k group” organizes knowledge that created within this group.
4. As “Empathy-k-organizer” role is in the C-Team as well, it is not necessary that the user assigned to it accesses the knowledge of the organizer role in the other group. Roles in different groups may have the same name but not necessary that they have the same responsibilities. The user with “Empathy-k-organizer” in C-Team may only organize the knowledge created by other team members.
5. Admin role in the organization has the highest privileges and authorities over the other users.
6. Admins may provide authorities to the other users within the hierarchy.
7. Access control database should store access control information about users and roles to use it for controlling the access of knowledge.
This information can be modified as the system scales.
6 Concluding summary
In this chapter, we have presented some strategies that can be followed for implementing successful KM systems by highlighting the privacy issue. This presentation was in high level. The further research is to define the semantics and services and implementing them on cloud environment. In the chapter, we presented the concepts of KM and cloud computing technology. We have reflected these concepts on our modeling approaches. We have addressed the issue of the KM systems as they have shortcomings in supporting social interactions as a main mechanism to create and share the knowledge. That encouraged us to investigate the business networks as one of the ways to do so. Our approach is to model these networks by what is called knowledge organization and groups. These groups contain roles and responsibilities that assigned to users. The privacy issue and scalability feature have been modeled as well. We have explained these modeling approaches by a scenario to help the reader understand them. However, these ideas may open new doors and research topics for those who are thinking toward implementing such systems.