
Provenance for cloud data accountability
Alan Y.S. Tan; Ryan K.L. Ko; Geoff Holmes; Bill Rogers Cyber Security Lab, Department of Computer Science, University of Waikato, Hamilton, New Zealand
Abstract
Although cloud adoption has increased in recent years, it is still hampered by the lack of means for data accountability. Data provenance, the information that describes the historical events surrounding the datum, can potentially address the data accountability issue in the cloud. While provenance research has produced tools that can actively collect data provenance in a cloud environment, these tools incur a substantial amount of overhead in terms of time and storage. This overhead, along with other disadvantages, render these tools untenable as a long-term solution.
In this chapter, we introduce the notion of provenance reconstruction as an alternative solution for active provenance collection. The idea is to mine pieces of information from readily available information sources in the relevant cloud environment and piece them together to form data provenance chains. However, to be able to piece the extracted information together, we need to know how each of these information pieces can be fitted together. We present a data provenance model that defines a list of provenance elements a data provenance for cloud data accountability should have, and a set of rules that defines the behavior of these elements. Through the data provenance model, we can then categorize the extracted information pieces into the different elements. Using the set of rules defined in the model, we have a rough idea of how these individual provenance elements can be fitted together to form provenance chains that describe the historical events related to data. We briefly discuss how the model can be used in our architecture and identify a list of challenges that needs to be addressed at the end.
1 Introduction
1.1 Background
While cloud computing has been proposed for some years, surveys (Attunity, 2013; Linthicum, 2013) have shown that the adoption of cloud by businesses is only starting to increase in recent years.
Issues related to data accountability and cloud security such as the vulnerabilities identified in the cloud, the confidentiality, integrity, privacy, and control of data have been the inhibitors of cloud adoption by businesses (North Bridge, 2013). Even with security losing its position as the primary inhibitor for cloud adoption (North Bridge, 2013), accountability-related issues such as data regulatory compliance and privacy of data are still concerns for businesses when considering moving their businesses to cloud services. These issues are primarily made difficult due to the lack of transparency in cloud environments (Chow et al., 2009).
Government regulations which safeguard sensitive data, such as the Health Insurance Portability and Accountability Act (HIPAA) in the United States (U.S. Department of Health and Human Services, 1996) and the Data Protection Act (DPA) in the United Kingdom (Directorate General Health and Consumers, 2010), mandate companies dealing with sensitive data to comply with regulations laid out in the policies. These regulations often require companies to place measures to assure the confidentiality and accountability of data. However, none of the current cloud providers provide tools or features that guarantee customers accountability and control over their data in the cloud. This lack of means to enable data accountability in the cloud needs to be addressed.
Data Provenance—the information about actions performed on data and related entities involved (Tan et al., 2013), directly addresses the data accountability issue. Recent data provenance research has resulted in various tools that can be deployed into the cloud. Provenance collection tools such as Progger (Ko and Will, 2014), S2Logger (Suen et al., 2013), Flogger (Ko et al., 2011a), SPADE (Gehani and Tariq, 2012), Lipstick (Amsterdamer et al., 2011), and Burrito (Guo and Seltzer, 2012) serve to capture and record provenance at various levels of granularity within cloud environments. The resulting provenance logs, a collection of captured data provenance, can then be analyzed in data audits to find out whether a data breach or policy violation has taken place.
However, as with any data-generating tools, these provenance collecting tools incur time and storage overheads (Carata et al., 2014). In input/output (I/O) intensive environments, the cost can be exceptionally high. For example, Muniswamy-Reddy et al. (2006) reports PASS, their implementation of an active provenance collector, incurred a time overhead ranging from 230% to 10% under different I/O loads and a storage overhead of around 33%. While 33% may seem a small figure, provenance logs will only continue to grow over time. Hence, overheads incurred through active provenance collection should not be overlooked.
Another disadvantage of provenance collecting tools is the need to deploy them on the target infrastructure and before any data are processed. Should the data be moved from a system with the tools deployed to another system without the collection tools, or data were accessed before the tool was deployed, the problem of missing data provenance arises. This is analogous to crime scenes which could have benefited from closed-circuit television (CCTV) cameras installed.
These gaps show that we should not solely rely on the use of active provenance collection tools to generate the data provenance required for cloud data accountability. The associated overhead costs also imply the use of these tools may not be a long-term solution. For a more robust and efficient solution, we look at the notion of reconstructing the required data provenance.
1.2 Provenance reconstruction
Provenance reconstruction looks at piecing back the provenance by mining readily available information sources from the relevant environment (Groth et al., 2012). In our context, we are interested in reconstructing the provenance of data stored in the cloud using information that is readily available in the cloud environment.
The following are some advantages of using provenance reconstruction as opposed to active provenance collection.
• Reduced reliance on active provenance collection tools: With the data provenance being reconstructed, we can reduce or remove the need for using active provenance collection tools to actively track data. This reduces the storage overhead significantly. However, a certain degree of computational overhead is still required for reconstructing the provenance.
• Increase system portability of tools: Active provenance collection tools such as Progger (Ko and Will, 2014) and PASS (Muniswamy-Reddy et al., 2006) usually require modifying the target system (e.g., the operating system hosting the cloud environment). Such modifications are considered intrusive and reduce the portability of the tools across different systems due to architecture and implementation differences. By contrast, provenance reconstruction usually only requires interacting with data files that already exist on the system. Since no modifications to the system are required, it results in a tool that is more portable compared to active provenance collection tools.
• Reduced complexity in analysis: Active provenance collection tools usually collect data provenance indistinguishably. As a result, analysts have to shuffle through large amounts of data (Ko and Will, 2014; Chen et al., 2012a), making the analysis laborious and complex. Even with the aid of graph manipulation (Jankun-Kelly, 2008; Chen et al., 2012b) and provenance querying tools (Biton et al., 2008), it takes time and effort for the analyst to identify which portion of the provenance to focus on due to the amount of noise (e.g., provenance of other unrelated data or activities). In contrast, provenance reconstruction rebuilds only the provenance of the data of interest. This removes the need for analysts to determine which part of the provenance graph to prune, hence reducing the complexity of provenance analysis.
As we can see, some of the listed advantages address directly the gaps identified in active provenance collection tools (e.g., overhead costs). Due to these advantages, we see provenance reconstruction as a complementary or replacement solution for active provenance collection tools.
In this chapter, we discuss the notion of using provenance reconstruction for generating the required data provenance for enabling cloud data accountability and how it can be achieved. Our assumption is that pieces of information that can form the data provenance when pieced together, can be mined from information sources found within the cloud environment. Some examples of such information sources are metadata of the data files or system log files.
However, simply extracting the pieces of information from information sources is insufficient for cloud data accountability. We need to be able to piece them together in a manner such that the result can describe what has happened to the data. As such, a data model is required to facilitate the identification or categorization of the role of each extracted piece of information and how these pieces can be fitted together. This is much like solving a jigsaw puzzle where we have to identify the image and shape of each piece in order for us to know how they can be fitted together to form the final picture.
We will discuss the types of role the data model should describe in Section 3 and the list of rules that govern the behavior of the role in the model in Section 3.3. We can think of the role as the image on the jigsaw puzzle piece and the rules as the shape of that puzzle piece. We then show how the list of roles and the list of rules defined in the two sections can aid the reconstruction of provenance in a cloud environment in Section 4. We then identify a list of challenges and future work in Sections 5 and 6, respectively.
However, before discussing the data model, we first look at applications of provenance reconstruction and understand how they differ with the situation in our context, in Section 2.
2 Related work
In this section, we look at some past applications of provenance reconstruction and discuss whether the methods used are applicable in the context of reconstructing data provenance in a cloud environment. We also take a look at some of the attributes that were used in those proposed methodologies. Our aim is to understand what type of attributes would help in enabling cloud data accountability.
Paraphrasing Weitzner et al. (2008), accountability refers to being able to hold individuals or institutes accountable for misuse under a given set of rules. In this case, our focus is cloud data accountability. The attributes should allow us to attribute actions to individuals or entities and understand when, if any, did a violation occur.
Content similarity analysis is probably one of the most common methodologies used for provenance reconstruction. To understand how content of files changes over time (e.g., evolution of files) (Deolalikar and Laffitte, 2009; Magliacane, 2012; Nies et al., 2012) the analysis attempts to relate files by measuring the similarity distance between content of files. The files are then linked based on the computed similarity scores and ordered based on timestamps (e.g., date of creation or date of last modification). The assumption is that files that are derived from another file would bear a high similarity in terms of content.
Content similarity analysis would not be applicable in our context simply because file relationship is not our primary focus. We are interested in information such as what actions were executed, by whom and when was the action executed, with respect to the data. In terms of attributes, Deolalikar and Laffitte (2009), Magliacane (2012), and Nies et al. (2012) focused on inter-file similarity and timestamp. While timestamp enables us to determine the time period of an event, looking at file similarity may not necessarily tell us whether a violation has occurred or who is liable in the event of a rule violation.
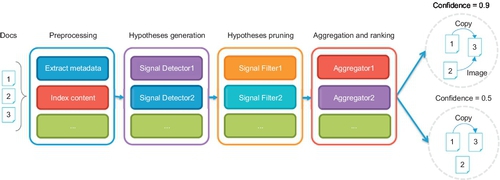
Having said that, the workflow proposed by Magliacane (2012) is very much applicable to our case. Her proposed workflow splits the reconstruction process into preprocessing, hypothesis generation, hypothesis pruning and aggregation and ranking, as shown in Figure 1. Algorithms that calculate similarity scores (Lux and Chatzichristofis, 2008; Bendersky and Croft, 2009) were used in the hypothesis generation phase to determine how each file can be linked together to form potential provenance chains. Non-relevant and inconsistent provenance chains were then pruned away based on a set of defined domain-specific rules in the hypothesis pruning phase. Finally, the remaining provenance chains were aggregated and assigned a confidence value based on the semantic type of data in the aggregation and ranking phase. This workflow can be adapted to match our objectives. The extraction of information from various information sources can be done in the preprocessing phase. In the hypothesis generation phase, the pieces of extracted information can be pieced together in a logical manner to form potential provenance chains that describe the history of the relevant data. We discuss this in more detail in Section 4.
Zhao et al. (2011) showed how missing provenance of a dataset can be inferred from other similar datasets that has a complete provenance. This was based on their observation that data items linked by special semantic “connections” (i.e., datasets that would be treated by the same process) would have similar provenance. In a workflow or process driven environment, such observations would be valid as one would expect to apply the same workflow on datasets with the similar property (e.g., in a biology experimental lab, gene data would be analyzed using similar workflows). However, in a cloud environment, even the same dataset can undergo different “treatment” from different users. For example, a clerk can be entering data and updating an excel sheet in the cloud, which would then be read by the clerk’s manager. Actions that will be executed on the data are purely based on the intent of each individual. As such, we cannot expect a user to perform the same action on every file of the same type. Hence, inferring data provenance from other datasets is not likely to produce favorable results in our context.
Much like the content similarity methodology, Zhao et al.’s proposed system relies on semantic similarity between datasets to determine which dataset’s provenance can be used for inference. However, as discussed earlier, attributes that look at similarity scoring may not be useful for determining who should be liable in the event of a violation of rules that governs the data.
Huq et al. tries to infer the data provenance from the scripting grammar used in a given script (Huq et al., 2013). By analyzing the syntax used in a given script (e.g., a Python script), the proposed system can extract out the control-flow, data-flow and executed operations from the script. A workflow provenance is then built based on the analyzed grammar. However, the proposed system requires the script to be available for analysis. Intuitively, such a system would not be applicable on a dataset as datasets usually do not contain information on actions that were executed on it.
Provenance reconstruction is also used to help reduce the need for human involvement in the provenance capturing process. Active monitoring strategies such as source code annotation and process execution monitoring, were used to monitor a process’s interaction with its environment in the Earth System Science Server (ES3) project (Frew et al., 2008). The captured interactions were decomposed into object references and linkages between objects before being used to reconstruct the provenance graphs. In doing so, scientists using the ES3 platform are free to use their own software and libraries and need not have to adhere to the use of specially modified libraries for provenance capture. However, because of the need to actively monitor each process during execution, the ES3 platform possesses the disadvantages of active provenance collection tools mentioned in Section 1.1. This is in contrast to our goal of using information that is readily available in the cloud environment (e.g., system logs that are gathered by the system or file’s metadata).
Information such as the universally unique identifier (UUID) for provenance-relevant objects (files or processes) and operations executed (e.g., file accesses) were captured during the monitoring of processes in ES3. This information allows analysts of the resulting provenance graph to trace back which files were used and the actions that were executed on them. An analyst would be able to determine whether a process has accessed a file it should not and as such this information is desirable in our context.
Our discussion on related work has thus far shown that methods used to reconstruct provenance are not applicable in our context. This is because our focus is on deriving the historical events of the data rather than its relationship with other files. It is more likely that information sources such as system log files or the file’s metadata contain events that are related to the data of interest. However, using the jigsaw puzzle analogy, we need a data model to systematically determine how each piece of information can be fitted together. Performing an exhaustive matching (e.g., permutation of n pieces of information) would result in a huge search space. Interestingly, the use of a data model to aid provenance reconstruction has been absent in the methodologies reviewed thus far. We shall look at describing such a data model in detail in the following sections.
3 Data provenance model for data accountability
In this section, we discuss what information should the data provenance contain for it to be useful for data accountability. This would help us identify what role should the model be able to categorize.
In Section 2, we identified time and attributes that would allow us to reference an object (e.g., UUID) and operations as desirable attributes. However, these three classes of attributes only tell us the when, what, and how of a violation. More information is required for us to find out who should be held responsible (Ko et al., 2011b; Ko, 2014). To further understand what is required for data accountability, we look at a privacy breach incident case study.
3.1 A case for provenance
In 2010, David Barksdale, Google’s ex-Site Reliability Engineer (SRE), was fired for breaching Google service users’ privacy (Protalinski, 2010). Barksdale abused the data access rights given to him for performing his role as an SRE. He tapped into call logs, extracted information such as names and phone numbers of users and used this information for stalking and spying on teenagers. Barksdale’s activities went unnoticed by the company until complaints were filed. If not for the complaints, the extent of violation that Barksdale had undertaken might not have been uncovered.
We have to ask ourselves two questions: “Why did Barksdale’s activities go unnoticed by the company?” and “Were there any other victims that were not discovered?.” One likely possibility is that Google does not monitor or maintain data access records of their SREs. One can imagine with such records, a review process would easily uncover the answers to both questions. Such data access records should at least contain the following information:
• Entities—Users or processes that have come into contact with the dataset. Information of entities involved can help investigators narrow down the investigation scope to only datasets which Barksdale looked at.
• Time—Timestamps that indicate the time period and duration in which Barksdale accessed the dataset can help correlate incidents to data accesses or vice versa.
• Operations performed—When correlated with entity and timestamp, knowing the type of operation performed on the dataset (e.g., read, write, transfer of data from a file) by Barksdale allows investigators to trace how Barksdale was able to obtain information required to commit the said offences.
• Context—Contextual information such as the owner of the dataset and whether this dataset has a phone record between two individuals is useful for investigators in attempting to understand what kind of information or the likely victims that can result through unauthorized access of the said dataset.
With this list of information, investigators would be able to trace and find out who are the violators and determine the extent of damage caused by such malicious insiders. With reference to our discussion of attributes in Section 2, the addition of entities would enable us to trace back to the individual responsible for a violation. While the above list is not an exhaustive one, we argue this is the minimal information required for any investigator to find out when did a violation happen, who did it, what objects are involved and how did the violation occur (operations executed).
Barksdale’s case is only one example of how data provenance can aid forensic investigations in the cloud. Investigators or auditors can easily assess whether the data stored in the cloud has violated any regulations governing the data (e.g., the data have to stay within the country’s jurisdiction) by analyzing the provenance of the dataset. Should a violation be identified, other information such as timestamps and entities can help attribute the violation to individual user accounts.
In the following sections, we look at a model for data provenance. The model defines the types of information data provenance should contain such that it can be used for enabling cloud data accountability.
3.2 Elements of the data provenance model
In Section 1.2, we used the term role as a unit for information types. However, we see the list of information types discussed in this section as the basic building blocks of any data provenance chain for cloud data accountability. Hence, we shall use the term element in place of role.
With reference to our discussion on the case study of David Barksdale, we formulate our data provenance model to consist of the following elements, Artifact, Entity, Actions, Time, and Context. These elements are used to represent various components within a computer system. The rationale for having this list of elements is so that we can categorize different information mined from log files or other types of information sources found within a computer system. We then discuss how these elements can be pieced together in Section 3.3.
3.2.1 Artifact
Artifact generally refers to objects that are immutable on their own. An example of an artifact within a computer system is a data file. While artifacts cannot change state on their own, other elements can change the state of an artifact. One such scenario is when a user writes to a file through a program. The artifact element helps to identify which data file is involved within the data provenance. This piece of information is useful when the provenance record contains more than one affected artifact (e.g., copying of content from one file to another).
3.2.2 Entity
An entity refers to user, process, or even an application within a computer system. Entities are generally what starts an action within the system. We classify process and application under entity, even though they have to be started by a user, because both of them are capable of running other actions once started (e.g., background process). In terms of data accountability, entity is the element to look for when determining the ones responsible for a malicious action.
3.2.3 Actions
Actions can range from atomic operations such as system calls executed by the kernel to compound operations like functions within system libraries or user application programming interfaces (APIs). Knowing the action that was executed helps in understanding the relationship between two artifacts and how an artifact reaches its current state.
3.2.4 Context
Context within a computer system covers details that ranges from metadata of a file that includes file names, description of a file; to file descriptors that are used by the kernel in system calls. The context element can help in establishing the importance of the artifact the investigator is looking at (e.g., a description that indicates the file contains classified information) or even help determine how different system calls should be linked together (e.g., how different read system calls should be linked to different write system calls at the kernel level).
3.2.5 Time
The coverage of the time element is intuitive. Other elements such as artifact and actions should have a timestamp value associated to it. These timestamps can indicate varying pieces of information crucial for investigators in piecing the provenance back together in the correct order. Some examples of timestamps are time of creation, time of access, and time of execution.
Once information mined from log files and other information sources are categorized, we can start piecing the various elements together to form the complete provenance picture of the data. To aid the reconstruction process, we define a set of rules that would help guide the reconstruction process, based on certain assumptions.
3.3 Rules for data provenance model
In this section, we list the assumptions made on how elements in the model should behave and define a set of actions that governs the behavior of these elements. The objective is to be able to piece together elements mined from different information sources to form logical chains of provenance that can possibly describe how the data reaches its current state. These chains of provenance form the search space for the original provenance of the target dataset.
In the context of a computer system, a function cannot start execution by itself and a system call cannot be executed without invocation by the kernel or a process. The command to execute has to originate either from a user or a process that is already executing. Hence, when there is an action element, it should always have an accompanying entity that is responsible for its execution.
The result of this assumption is that entities can be said to start another entity in the model. One possible scenario would be a user (with valid user ID) is able to start processes (with process ID) within its privilege. As such, entities can be linked directly to another entity. Once a process is started, it is considered as an entity by itself with attribution to a valid user.
Artifacts such as files within a computer system are assumed to be unable to change their own state. This includes modifying its own content or other file’s content. State transition on an artifact is only possible through a direct action being executed on the artifact itself. Together with Assumption 1, we say that there will always be a relative action and its associated user that can be attributed for the artifact’s arrival at its current state. One example of such a scenario is when a file is created by a user using an editor. The user and the action of creating the file will be the cause of how the file came into existence on the file system.
While we explicitly listed three assumptions here, we did not include other more intuitive assumptions. Some of these assumptions include actions should be ordered based on the timestamp tagged to them and actions with timestamp older than an artifact’s creation timestamp (if any) should not be associated with the artifact.
While there exists other provenance models such as the Open Provenance Model (OPM) (Moreau et al., 2011) and the PROV Data Model (PROV-DM) (Moreau et al., 2013), the objectives of those models differ from our presented model. OPM and PROV-DM seek to define a common format to describe provenance from different sources for inter-operability between tools that produce and consume provenance. These models also aim to describe provenance used in fields of research such as databases and the semantic Web. This resulted in an extensive set of vocabulary being developed for describing various components of those models (Zhao, 2010; Hartig and Zhao, 2012). While this helps in cross domain applications of provenance, it causes the vocabulary to become complex and heavy-weight as concepts from different fields have to be incorporated into the model.
OPM and PROV-DM models also assume that the provenance being described is of the same granularity (e.g., components of a workflow provenance of an application are all generated at the application level). In our case, we are looking to use information extracted from different information sources to piece together the data provenance. It is likely that these information sources (e.g., system log file generated by the system or a file’s metadata or network log files) are generated by different logging mechanisms residing at different granularity levels in a cloud system. Hence the model must be aware that each information piece may be of different granularity and be still able to relate them together. We discuss this in more detail in Section 5.
4 Reconstructing the data provenance
Having described the model and the rules governing the elements’ behavior in Sections 3 and 3.3, we show how the model can be used in the provenance reconstruction process. Figure 2 illustrates the overview of our provenance reconstruction workflow.
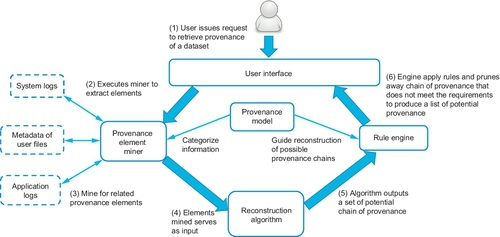
The whole process starts when a user (e.g., investigator) issues a query to retrieve the data provenance of a certain file. The element miner then crawls relevant information based on user’s inputs and categorizes the information according to the defined elements in the model.
The elements mined are then passed on to the reconstruction algorithm. Here, AI planning techniques, such as those described in Groth et al. (2012) or other forms of heuristics can be applied on the elements to reconstruct potential provenance chains that represents how the data can possibly reach its current state.
Once the algorithm generates the output list of provenances, the next step is to prune away those that are logically incorrect. This is achieved through the rule engine. The rule engine will apply a set of rules on each of the generated provenance chains from the previous step to ensure that the provenance elements are joined in a manner that satisfy all rules. Those provenance chains that are joined in a manner that does not satisfy the set of rules are considered as non-logical provenance chains and pruned away. The set of rules can be divided into two sets, model specific and domain specific. Model-specific rules dictate the behavior of the provenance elements. Examples of model-specific rules are those mentioned in Section 3.3. Domain-specific rules are rules inserted by users (e.g., system forensic analysts) for reasons such as to narrow down the provenance chains to look at. Examples of domain-specific rules could be, “remove provenance chains that involve network communications.” Domain specific-rules should be specified with care as over-strict rules may result in pruning away relevant provenance chains from the search space.
From Figure 2, we can see that the model plays two crucial roles in the reconstruction process. The first is in the mining of elements from the various information sources. Without the model to help categorize the information mined, the reconstruction algorithm would have no clue on what these information represent. By knowing the nature of the mined information, the reconstruction algorithm would be able to have a basic knowledge on how each of these separate information can be pieced together to form the provenance chain.
The second role of the model is to help reduce the provenance chain search space generated by the reconstruction algorithm. The reduction is achieved by pruning away provenance chains that are consider non-logical. This is done in conjunction with the rule engine and is explained in the previous paragraphs above.
5 Challenges
Guiding the provenance reconstruction process is just one of the many challenges that need to be addressed. The following issues have to be addressed before the concept is ready for use in a production cloud environment:
• Parsing of information sources—Although logging formats such as the common event format (Arcsight, 2009; iWebDev, 2011) and the extended log format Hallam-Baker and Behlendorf exist to standardize the format of logs produced by logging mechanisms, we cannot assume that all log files will adhere to these logging standards. Third party developed applications such as user web applications or programs are unlikely to adopt such logging standards due to reasons such as being unaware of such logging standards. This is on top of the possibility of having semi or unstructured log files or even wide variety of information sources that range from database logs to file meta-data to image files. Therefore, the miner has to be designed in a modular and robust manner such that users can easily incorporate in new heuristics for the mining to be done. Having a modular miner also allows incorporating new logging standards or adapting to different types of information sources with minimal changes.
• Difference in granularity—The granularity of logs produced by different applications or logging mechanisms can differ. One simple example is the comparison between a user application’s log and a system log such as dmesg (Linux system log). In the user application’s log, one can expect information such as functions called, input and output parameters and even program errors caused by user inputs. In a system log, information such as the devices that were invoked or system calls resulting from the function call by a user’s application are being logged instead. The challenge here is given the difference in granularity, how can one link elements together such that they form the provenance chain that describes the history of the data.
6 Future work and concluding remarks
In this chapter, we introduced the concept of provenance reconstruction as an alternative solution for active provenance collection tools in generating the data provenance for enabling cloud data provenance. We then focused our discussion on the data provenance model, a crucial component in our provenance reconstruction workflow. The data model consists of a list of provenance elements (Section 3.2) for categorizing information extracted from various information sources and a set of rules (Section 3.3) which define the behavior of these elements. We explained how the rules could be used for pruning away non-logical provenance chains generated by the provenance reconstruction algorithm in Section 4. We also illustrated and briefly explained how the model is incorporated into the provenance reconstruction workflow.
We are currently working on implementing the data model discussed in this chapter. This is but the first step toward having a working prototype for generating data provenance using provenance reconstruction in a cloud environment. However, the challenges mentioned in Section 5 have to be addressed first in order for the model to be robust and agnostic to the range of information sources within a cloud environment.
After the extracted information are modeled into provenance elements, the next step is to piece them together to form possible provenance chains that describe the historical events of the data. We plan to look into the area of artificial intelligence planning (AI planning) for deriving an algorithm for construction of provenance chains. By modeling each element as a service, AI planning used in automatic web service composition (Oh et al., 2006) could be adapted for generating the required provenance chains.
Our vision is to create a robust and platform independent tool that can generate the required provenance for cloud data accountability. Provenance reconstruction techniques provide the means for creating such a tool. Provenance reconstruction-based tools would not only help cloud providers provide the necessary guarantees to businesses looking to move their services and infrastructure to the cloud, but also increase users’ confidence in cloud technologies and services.