
The past influences the present
Abstract
The Past Influences the Present focuses on the use of past behavior to predict the future. The key concept is the filter, a type of linear model that connects the past and present states of a system. Filters can be used to both quantify the physical processes that connect two related sets of measurements and predict their future behavior. We develop the prediction error filter and apply it to hydrographic data in order to explore the degree to which stream flow can be predicted. We show that the filter has many uses in addition to prediction; for instance, it can be used to explore the underlying processes that connect two related types of data.
7.1 Behavior sensitive to past conditions
Consider a scenario in which a thermometer is placed on the flame emitted by a burner (Figure 7.1A). The gas supplied to the burner varies with time, causing the heat, h(t), of the flame, measured in Watts (W), to fluctuate. An ideal thermometer would respond instantaneously to changes in heat, so the temperature, θ(t), measured in Kelvin (K), would track heat exactly, that is, θ(t) ∝ h(t). In this case, the past history of the heat has no effect on the temperature. The temperature now depends only on the heat at this moment. If, however, a metal plate is inserted into the flame between the burner and the thermometer (Figure 7.1B), the situation changes radically. The plate takes time to warm up or cool down. The thermometer does not immediately detect a change in heat; it now takes time to respond to changes. Even if the flame were turned off, the thermometer would not immediately detect the event. For a while, it would continue to register high temperatures that reflected the heat supplied by the flame in the past. In this case, θ(t) would not be proportional to h(t), although the two would still be related in some fashion.

The relationship between θ(t) and h(t) might be linear. Suppose that the time history of heat, h(t), caused temperature, θ(t). If the heat were doubled to 2h(t), we might find that the temperature also doubled, to 2θ(t). Moreover, if two flames were operated individually, with h1(t) causing θ1(t) and h2(t) causing θ2(t), we might find that the combined heat of the two flames, h1(t) + h2(t), caused temperature, θ1(t) + θ2(t).
Another aspect of this scenario is that only relative time matters. If we turn on the burner at 9 AM today, varying its heat, h(t), and recording temperature, θ(t), we might expect that the same experiment, if started at 9 AM tomorrow with the same h(t), would lead to exactly the same θ(t) (as long as we measured time from the start of each experiment). The underlying notion is that the physics of heat transport through the plate does not depend on day of the week.
This linear behavior can be quantified by assuming that both the heat, h(t), and temperature, θ(t), are time series; then writing the temperature, θi, at time, ti, as a linear function of past and present heat, hj, with j ≤ I,

Note that each formula involves only current and past values of the heat. This is an expression of causality—the future cannot affect the present. The relationship embodied in Equation (7.1) is called a convolution, and is denoted by the asterisk, * (which does not mean multiplication when used in this context).
The gs in Equation (7.1) are coefficients that express the linear proportionality between heat and temperature. Note that exactly the same coefficients, g1, g2, g3, g4 … are used in all the formulas in Equation (7.1). This pattern implements the time-shift invariance that we discussed earlier—only the relative time between the application of the heat and the measurement of the temperature matters. Of course, this is only an idealization. If, for instance, the plate were oxidizing during the experiment, then its thermal properties would change with time and the set of coefficients that linked θ(t) to h(t) at one time would be different from that at another.
For Equation (7.1) to be of any practical use, we need to assume that only the recent past affects the present, that is, the coefficients, g1, g2, g3, g4, …, eventually diminish in magnitude, sufficiently for the sequence to be approximated as having a finite length. This notion implies that the underlying physics has a characteristic time scale over which equilibration occurs. Heat that was supplied prior to this characteristic response time has negligible effect on the current temperature. In the case of the flame in the laboratory, we would not expect that yesterday’s experiment would affect today’s experiment. The temperature of the plate has adequate time to equilibrate overnight.
As Equation (7.1) is linear, it can be arranged into a matrix equation of the form d = Gm:

Note, however, that a problem arises because of the lack of observation before time, t1. Here, we have simply ignored those values (or equivalently, assumed that they are zero). At time t1, the best that we can write is θ1 = g1h1, as we have no information about heating at earlier times.
When grouped together in a column vector, g, the coefficients are called a filter. A filter has a simple and important interpretation as the temperature time series that one would observe if a unit impulse (spike) of heat were applied: inserting h = [1, 0, 0, 0, …, 0]T into Equation (7.2) yields θ = [g1, g2, g3, …, gN]T. Thus, the time series, g, is often called the impulse response of the system (Figure 7.2). The equation, θ = g * h, can then be understood to mean that the output—the data, θ—equals the input—the heat, h—convolved with the impulse response of the system.

Each column, c(i), of the matrix, G, in Equation (7.2) is the time series, g, which is shifted so that g1 aligns with row i; that is, it is the response of an impulse at time ti. If we read the matrix equation as θ = h1c(1) + h2c(2) + h3c(3) +, …, then we can see that the temperature, θ, is built up by adding together many time-shifted versions of the impulse response, each with an amplitude governed by the amount of heat. In this view, the time series of heat is composed of a sequence of spikes and the time series for temperature is constructed by mixing together scaled versions of the impulse responses of each of those spikes (Figure 7.3).

So far, we have been examining a scenario in which the data vary with time. The same sort of behavior occurs in spatial contexts as well. Consider a scenario in which a spatially variable mass, h(x), of a pollutant is accidentally spilled on a highway. If, a year later, its concentration, θ(x), on the road surface is measured, it will not obey θ(x) ∝ h(x), because weather and traffic will have spread out the deposit. This type of scenario can also be represented with filters, but in this case they are noncausal, that is, the concentration at position x0 is affected by deposition at both x ≤ x0 and x > x0:

We need to assume that the filter coefficients (the gs) die away at both the left and the right so that the filter can be approximated by one of finite length.
Crib Sheet 7.1
Filter basics
A filter is a time series f (of length L) that expresses a linear relationship between an output time series d (of length N) and an input time series m (of length ![]() ) through an operation called a convolution.
) through an operation called a convolution.
(Here * denotes the convolution operation, not multiplication).
Use a filter when d depends on the past history of m.
L expresses the duration of the past that influences the present. Filters can be of any length, but short filters (![]() ) usually behave better than long filters.
) usually behave better than long filters.
Matrix forms of the convolution

d = toeplitz([f',zeros(1,N-L)]',[f(1),zeros(1,N-1)]) * m;

d = toeplitz(m,[m(1),zeros(1,L-1)]) * f;
d = conv(f,m); % perform convolution
d = d[1:N]; % truncate result to length N (optional)
7.2 Filtering as convolution
Equations (7.1) and (7.2) involve the discrete time series θ, h, and g. They can readily be generalized to the corresponding continuous case, for functions θ(t), h(t), and g(t), by viewing Equation (7.1) as the Riemann sum approximation of an integral. Then the heat, h(t), is related to the temperature, θ(t), by the convolution integral introduced in Section 6.11:

Note that the function, g(t) (as in Equation 7.3), and the time series, g (as in Equation 7.1) differ by a scaling factor: gi = Δtg(ti), which arises from the Δt in the Riemann summation.
The integral formulation is useful because it will allow us to deduce properties of filters that might not be so obvious from the matrix equation (Equation 7.2) that describes the discrete case. As an example, we note that an alternative form of the convolution can be derived from Equation (7.3) by the transformation of variables, t′ = (t−τ):
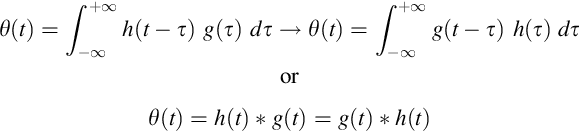
For causal filters, the function, g(t), is zero for times t < 0. In the first integral, g(t) is forward in time and h(t) is backward in time, and in the second integral, it is vice-versa. Just as with the discrete version of the convolution, the integral version is denoted by the asterisk: θ(t) = h(t) * g(t). The integral convolution is symmetric, in the sense that h(t) * g(t) = g(t) * h(t).
In Section 7.1, we interpreted the discrete convolution, θ = g * h, to mean that the output, θ, is the input, h, convolved with the impulse response of the system, g. We interpreted the column vector, g, as the impulse response because θ = g when the input is a spike, h = [1, 0, 0, 0, …, 0]T. The same rationale carries over to the integral convolution. The equation θ(t) = g(t) * h(t) means that the output, θ(t), is the input, h(t), convolved with the impulse response of the system, g(t). We represent the spike with the Dirac function, δ(t) (see Section 6.6). Then θ(t) = g(t) when h(t) = δ(t) (as can be verified by inserting h(t) = δ(t) into Equation 7.4).
The alternative form of the integral convolution (Equation 7.4), when converted to a Riemann summation, yields the following matrix equation:

In Equation (7.2), the heat plays the role of the model parameters. If solved by least squares, this equation allows the reconstruction of the heat, using observations of temperature (with the impulse response assumed known, perhaps by deriving it from the fundamental physics). In Equation (7.4), the impulse response plays the role of the model parameters. If solved by least squares, this equation allows the reconstruction of the impulse response, using observations of temperature. In this case, the heat is assumed to be known, perhaps by measuring it, too. (Note, however, that the data kernel would then contain potentially noisy observations, which violates one of the underlying assumptions of least-squares methodology.)
As another example of the utility of the integral formulation of the convolution, note that we had previously derived a relation pertaining to the Fourier transform of a convolution (see Section 6.11). In this context, the Fourier transform of temperature, ![]() , is equal to the product of the transforms of the heat and the impulse response,
, is equal to the product of the transforms of the heat and the impulse response, ![]() . As we will see later in the chapter, this relationship will prove useful in some computational scenarios.
. As we will see later in the chapter, this relationship will prove useful in some computational scenarios.
7.3 Solving problems with filters
Here, we consider a more environmentally relevant temperature scenario, which, however, shares a structural similarity with the burner example. Suppose a thin underground layer generates heat (for example, because of a chemical reaction) and the temperature of the surrounding soil or sediment is measured. As with the burner example, the heat production, h(t), of the layer is unknown and the temperature, θ(t), of the soil at a distance, z = 1 meter, away from the layer is the observation. (Perhaps direct observation of the layer is contraindicated owing to concerns about release of hazardous chemicals). The impulse response, g(t), of such a layer is predicted on the basis of the physics of heat flow (Menke and Abbott, 1990, their Equation 6.3.4):

Note that the impulse response is proportional to a Normal curve with variance, 2κt, centered about z = 0. The equation involves three material constants, the density, ρ, of the soil, its heat capacity, cp, and its thermal diffusivity, κ. Typical values for soil are ρ ≈ 1500 kg/m3, cp ≈ 800 J/kg K, and κ ≈ 1.25 × 10−6 m2/s. Note that time is divided by the quantity (2κ)−1 ≈ 4 × 105 s, which defines a time scale of about 4.6 days for the heat transport process. Thus, observations made every few hours are sufficient to adequately measure variations of temperature. The quantity, ρcp ≈ 1.2 × 106 J/kg K, is the amount of heat, 1.2 million Joules in this case, that needs to be supplied to raise the temperature of a cubic meter of rock by 1 K. Thus, for example, a chemical reaction supplying heat at a rate of 1 W/m2 will warm up a cubic meter of soil by 0.08 K in 1 day.
The impulse response (Figure 7.4A) is problematical in two respects: (1) Although it rapidly rises to its maximum value, it then decays only slowly, so a large number of samples are needed to describe it accurately. (2) It contains a factor of t−1/2 that is singular at time, t = 0 although the function itself is zero, as the exponential factor tends to zero faster than the t−1/2 factor blows up. Thus, the t = 0 value must be coded separately in MatLab:

M=1024; N=M; Dtdays = 0.5; tdays = Dtdays*[0:N−1]’; Dtseconds = Dtdays*3600*24; tseconds = Dtseconds*tdays; ––– g = zeros(M,1); g(1)=0.0; % manually set first value g(2:M) = (1/(rho*cp)) * (Dtseconds/sqrt(2*pi)) .* … (1./sqrt(2*kappa*tseconds(2:M))) .* … exp(−0.5*(zˆ2)./ (2*kappa*tseconds(2:M)));
(MatLab eda07_01)
Note that two column vectors of time are being maintained: tdays, with units of days and sampling of ½ day, which is used for plotting, and tseconds, with units of seconds, which is used in formulas that require SI units. Note also that the formula for the impulse response contains a factor of Δt not present in Equation (7.6), the scaling factor between the continuous and discrete forms of the convolution.
Given a heat production function, h(t) (Figure 7.4B), the temperature can be predicted by performing the convolution θ(t) = g(t) * h(t). In MatLab, one can build the matrix, G (Equation 7.2) and then perform the matrix multiplication:
G = toeplitz([g‘, zeros(N−M,1)’]’, [g(1), zeros(1,M−1)]); qtrue2 = G*htrue;
(MatLab eda07_01)
Here we use the character, q, instead of θ, as MatLab variables need to have Latin names. An alternative (and preferable) way to perform the convolution is to use MatLab’s conv() (for convolve) function, which performs the convolution summation (Equation 7.1) directly:
tmp = conv(g, htrue); qtrue=tmp(1:N);
The conv() function returns a column vector that is N + M − 1 samples long, which we truncate here to N samples.
When we attempt to solve this problem with least squares, MatLab reports that the solution,
is ill-behaved. Apparently, more than one heat production, hest, predicts the same—or nearly the same—observations. A quick fixup is to use the damped least squares solution, which adds prior information that hest is small. The damped least squares solution is easy to implement. We merely add a factor of ε2I to GTG:
GTG=G’*G; GTGmax = max(max(abs(GTG))); e2=1e−4*GTGmax; hest1=(GTG+e2*ye(M,M))(G’*qobs);
(MatLab eda07_01)
The function eye() returns the identity matrix, I. In principle, the size of ε2 should be governed by the ratio of the variance of the data to the variance of the prior information. However, we make no pretense here of knowing what this ratio might be. Instead, we take a more pragmatic approach, choosing a value for ε2 (e2 in the script) by trial-and-error. In order to expedite the trial-and-error tuning, we write ε2 as proportional to the largest element in GTG, so that a small damping factor (10−4, in this case) corresponds to the case where ε2I is smaller than GTG.
The damped least squares solution returns a heat production, hest, that closely resembles the true heat production, htrue, when run on synthetic data with a low (0.1%) noise level (Figure 7.5). The situation is less favorable as the noise level is increased to 1% (Figure 7.6). Although the two peaks in heat production, htrue, can still be discerned in hest, they are superimposed on a background of high amplitude, high-frequency fluctuations. The problem is that the impulse response, g(t), is a slowly varying function that tends to smooth out high-frequency variations in heat production. Thus, while the low-frequency components of the heat production are well constrained by the data, θobs, the high-frequency components are not. The damped least squares implements the prior information of smallness, but smallness does not discriminate between frequencies and, so, does little to correct this problem. As an alternative, we try prior information of smoothness, implemented with generalized least squares. As a smooth solution is one lacking high-frequency fluctuations, this method does much better (Figure 7.7). The MatLab code that created and solved the generalized least squares equation, Fm = f, is as follows:



e=10*max(max(abs(G))); F=zeros(N + M,M); f=zeros(N + M,1); F(1:N,1:M)=G; f(1:N)= qobs2; H=toeplitz(e*[−2, 1, zeros(1,M−2)]′,… e*[−2, 1, zeros(1,M−2)]); F(N+1:N+M,:)=H; f(N+1:N+M)=0; hest3 = (F′*F)(F′*f);
(MatLab eda07_02)
Here the matrix equation, f = Fm, is built up from its two component parts, the data equation, d = Gm and the prior information equation, h = Hm. As before, the quantity ε is in principle controlled by the square-root of the ratio of the variances of the data and the prior information. However, we again take a pragmatic approach and tune it by trial-and-error.
The above code makes rather inefficient use of computer memory. The matrix, G, is constructed from exactly one column-vector, g, so that almost all of the elements of the matrix are redundant. Similarly, the matrix, H, has only three nonzero diagonals, so most of its elements are zero. This wastefulness is not a problem for short filters, but the storage requirements and computation time quickly becomes unmanageable for long ones. The solution can be computed much more efficiently using MatLab’s bicg() function. As was described in Section 5.8, this function requires a user-supplied function that efficiently computes FT(Fv) = GT(Gv) + HT(Hv), where v is an arbitrary vector. This function, which we call filterfun(), is analogous to (but more complicated than) the afun() function discussed in Section 5.8:
function y = filterfun(v,transp_flag) global g H; % get dimensions N = length(g); M = length(v); [K, M2] = size(H); temp1 = conv(g,v); % G v is of length N a=temp1(1:N); b=H*v; % H v is of length K temp2=conv(flipud(g),a); % GT (G v) is of length M a2 = temp2(N:N+M−1); b2 = H′*b; % HT (H v) is of length M % FT F v = GT G v+HT H v y = a2 + b2; return
(MatLab filterfun)
The quantities, g and H, are defined as global variables, in both this function and the main script, so MatLab recognizes these variables as referring to the same quantities in both scripts. The required vector, GT(Gv) + HT(Hv), is built up in five steps: (1) The quantity a = Gv is just the convolution of g and v, and is computed using the conv() function. (2) The quantity b = Hv is performed with a simple matrix multiplication and presumes that H is a sparse matrix. (3) The quantity a2 = GTa is a convolution, but the matrix GT differs from the normal convolution matrix G in three respects. First, the ordering of g in the columns of GT is reversed (‘flipped’) with respect to its ordering in G. Second, GT is upper-triangular, while G is lower-triangular. Third, GT is M × N whereas G is N × M. Thus, modifications in procedure are required to compute a2 = GTa using the conv() function. The order of the elements of g must be flipped before computing its convolution with a. Moreover, the results must be extracted from the last M elements of the column vector returned by conv() (not, as with Gv, from the first N elements). (4) The quantity b2 = HTb is computed via normal matrix multiplication, again presuming that H is sparse. (5) The quantity a2 + b2 is computed by normal vector addition. In the main script, the quantities H, h, and f are created as follows:
clear g H; global g H; ––– e=10*max(abs(g)); K=M; L=N + K; H=spalloc(K,M,3*K); for j = [2:K] H(j,j−1)=e; end for j = [1:K] H(j,j)=−2*e; end for j = [1:K−1] H(j,j+1)=e; end h=zeros(K,1); f(1:N)=qobs2; f(N+1:N+K)=h;
(MatLab eda07_03)
The spalloc() function creates a K × M sparse matrix H, capable of holding 3 K nonzero elements. Its three nonzero diagonals are set by the three for loops. The column vector h is zero. The column vector f is built up from θest and h. The quantity FTf is computed using the same methodology as in filterfun() and then both filterfun() and FTf are passed to the biconjugate gradient function, bicg():
temp=conv(flipud(g),qobs2); FTfa = temp(N:N+M−1); FTfb = H′*h; FTf=FTfa+FTfb; hest3=bicg(@filterfun,FTf,1e−10,3*L);
(MatLab eda07_03)
The solution provided by eda07_03 is the same as that provided by eda07_02, but the memory requirements are much less and the execution speed is much faster.
7.4 An example of an empirically-derived filter
At least during the summer when precipitation occurs as rain, we might expect that the discharge of a river is proportional to the amount of rain that falls on its watershed. However, rain does not instantaneously cause discharge but rather is delayed behind it because the rainwater needs time to work its way through soils and tributaries before it can register on a hydrographic station. This scenario is well suited to being described by a filter. River discharge d(t) is related to precipitation g(t) through the convolution relationship ![]() , where the filter r(t) respresents the response of the river’s drainage network to a pulse of rain.
, where the filter r(t) respresents the response of the river’s drainage network to a pulse of rain.
We apply this idea to the Hudson River, using a dataset with daily measurements of river discharge and precipitation, both measured in the Albany, New York area:
The file precip_discharge_data.txt contains three columns of data, time in days starting January 1, 2002, Hudson River discharge in cubic feet per second measured at the Green Island hydrographic station near Albany, New York and precipitation in inches per day measured at the Albany Airport. I download the discharge data from the USGS’s Surface-Water Daily Data for the Nation database and the precipitation data from NOAA’s lobal Surface Summary of Day database and merged the two together. A few of the precipitation values were listed as 99.99; I reset them to zero.
We focus on a 101 day long time period in Summer 2004, which contains four signifcant storms and about a dozen days with more moderate precipitation (Figure 7.8 A). As expected, the observed river discharge (Figure 7.8 B, sold curve) rises after each storm and varies more smoothly than does precipitation.

We use the same Generalized Least Squares procedure described in Section 7.3 to estimate the filter r(t). Note, however, that in Section 7.3 we assumed that the output and filter were known and solved for the input, whereas here we are assuming that the input and output are known and are solving for the filter. The underlying equations are the same but the interpretation is different. In the current case, the data kernel G in the standard equation ![]() is built from the precipitation g(t), the model parameters m represent the unknown response r(t) and the data d respresent the discharge d(t). We expect that the response of the river to precipitation is relatvely short-lived, since a pulse of rain should drain away over the course of a few weeks, so this is a case where
is built from the precipitation g(t), the model parameters m represent the unknown response r(t) and the data d respresent the discharge d(t). We expect that the response of the river to precipitation is relatvely short-lived, since a pulse of rain should drain away over the course of a few weeks, so this is a case where ![]() . We also implement prior information of the form
. We also implement prior information of the form ![]() . Motivated by the notion that r(t) decays smoothly with time, we use the prior information that
. Motivated by the notion that r(t) decays smoothly with time, we use the prior information that ![]() , so H is a first difference matrix and
, so H is a first difference matrix and ![]() . The results depend on the relative error in the data and prior inforation,
. The results depend on the relative error in the data and prior inforation, ![]() . We tune both M and ε by trial and error until we achieve a filter that is a good compromise between being smooth and fitting the data well.
. We tune both M and ε by trial and error until we achieve a filter that is a good compromise between being smooth and fitting the data well.
As expected, the estimated filter r(t) (Figure 7.8 C) declines with time, reaching half of its starting value after about 10 days. The predicted discharge matches the observations, with two exceptions: the prediction misses the peak at day 707; and the prediction overestimates the peak at day 742. These errors may be due to our use of data from a single meteorological station to represent precipitation in the whole Hudson River watershed. A storm may miss the station or dump a disproportionate amount of rain on it. A more complicated model that allows for several stations might have worked better:
Here g(i)(t) is the precipitation observed at the i-th meterological station and r(i)(t) is the resonse of the river discharge to a pulse of precipitation that falls near that station. This problem can be solved using Generalized Least Squares, but the bookkeeping needed to construct the equations ![]() and
and ![]() is challenging.
is challenging.
The river’s estimated response r(t) can be used to predict river discharge for past time periods in which meterterological data, but no hydrographic data, are available. This process, sometimes referred to as retrodiction, is often used to close gaps in the historical record of a river’s dischage.
7.5 Predicting the future
Suppose we approximate the present value of a time series, d, as a linear function of its past values:

where the p’s are coefficients. If we knew these coefficients, then we could predict the current value di using the past values di−1, di−2, di−3,… Equation (7.8) is just the convolution equation:
Here, the prediction error filter p is the unknown. The convolution equation, p * d = 0, has the same form as the heat production equation, g * h = θ, that we encountered in the previous section, and the same generalized least squared methodology can be used to solve it. The prior information, p1 = (−1), is assumed to be extremely certain and given much smaller variance than p * d = 0. In most practical cases, the future, insofar as it can be predicted, is a function primarily of the recent past. Thus, the prediction error filter is short and MatLab’s standard matrix algebra can be used in the computation of p (although the bicongugate gradient method remains a good alternative).
As an example, we compute the prediction error filter of the Neuse River Hydrograph (Figure 7.9) using both methods, obtaining, as expected, identical results in the two cases. We choose M = 100 as the length of p. The filter has most of its high amplitude in the first 3 of 4 days, suggesting that a shorter filter might produce a similar prediction. The small feature at a time of 42 days is surprising, because it indicates some dependence of the present on times more than a month in the past. However, degree to which this feature actually improves the prediction needs to be investigated before its significance can be understood.

The prediction error, e = p * d, is an extremely interesting quantity (Figure 7.10), because it contains the part of the present that cannot be predicted from the past; that is, the new information. In this case, we expect that the unpredictable part of the Neuse hydrograph is the pattern of storms, while the predictable part is response of the river to those storms. The narrow spikes in the error, e, which correlate to peaks in the discharge, seem to bear this out.

Crib Sheet 7.2
Least squares estimation of a filter
Step 1: Indentify the time series and their lengths
The filter equation ![]() relates input g to output d (both of length N) via convolution with a filter m (of length M).
relates input g to output d (both of length N) via convolution with a filter m (of length M).
Step 2: Choose the length M of the filter
In general, ![]() . Filters are most useful (and best behaved) when
. Filters are most useful (and best behaved) when ![]()
Step 3: Choose the form of the prior information (if any)
Prior information ![]() (where h has K rows and
(where h has K rows and ![]() ) can improve the performance of the estimation process. For instance, smoothness (with
) can improve the performance of the estimation process. For instance, smoothness (with ![]() ,
, ![]() and H the second derivative matrix) can reduce short-period fluctuations caused by noise in the data. In practice, the value of ε is set by trial and error.
and H the second derivative matrix) can reduce short-period fluctuations caused by noise in the data. In practice, the value of ε is set by trial and error.
Step 4: Build the prior information equation
Declare globals at top of the script:
clear all;
global g H;
Make H a sparse matrix:
e = epsilon*ones(M,1)/(Dtˆ2);
H = spdiags([e,-2*e,e],[-1:1],M-2,M);
h = zeros(M-2,1);
Step 5: Build the r.h.s. of the least squares equations
L=N+K;
f(1:N)=d;
f(N+1:N+K)=h;
temp=conv(flipud(g),d);
FTfa = temp(N:N+M-1);
FTfb = H’*h;
FTf=FTfa+FTfb;
Step 6: Solve the least squares equation for the estimated filter
mest=bicg(@filterfun,FTf,1e-10,3*L);
Step 7: Calculate (and plot) the predicted data and error
dpre = conv(g,mest);
dpre = dpre(1:N);
e = d-dpre;
E=e’*e;
MatLab eda07_06
7.6 A parallel between filters and polynomials
Being able to perform convolutions of short time series by hand is very useful, so we describe here a simple method of organizing the calculation in the convolution formula (Equation 7.1). Suppose we want to calculate c = a * b, where both a and b are of length 3. We start by writing down a and b as row vectors, with a written backward and time and b written forward in time, with one sample of overlap. We obtain c1 by multiplying column-wise, treating blanks as zeros:

To obtain c2, we shift the top time series one sample to the right, multiply column-wise, and add the results:

To obtain c3, we shift, multiply, and add again.

And so forth. The last nonzero element is c5:

An astute reader might have noticed that this is exactly the same pattern of coefficients that one would obtain if one multiplied the polynomials:

We can perform a convolution by converting the time series to polynomials, as above, multiplying the polynomials, and forming a time series from the coefficients of the product. The process of forming the polynomial from a time series is trivial: multiply the first element by z0, the second by z1, the third by z2, and so forth, and add. The process of forming a time series from a polynomial is equally trivial: the first element is the coefficient of the z0 term, the second of the z1 term, the third of the z2 term, and so forth. Yet, while it is trivial to perform, this process turns out to be extremely important, because it allows us to apply a very large body of knowledge about polynomials to issues associated with filters and convolutions. Because of its importance, the process of forming a polynomial from a time series is given a special name, the z-transform.
7.7 Filter cascades and inverse filters
Consider a polynomial g(z) of order N − 1 that represents a filter, g, of length, N. According to the Fundamental Theorem of Algebra, the polynomial can be written as the product of its N − 1 factors:
where the rs are the roots of the polynomial (that is, the zs for which the polynomial is zero) and the factor of gN acts as an overall normalization. Thus the filter, g, can be written as a cascade of convolutions of N − 1 length-two filters:
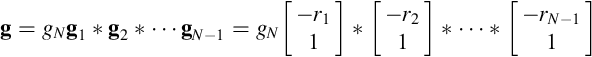
Thus, any long filtering operation can be broken down into a sequence of many small ones. (Note, however, that some of the length-two time series may be complex, as the roots of a polynomial are, in general, complex).
The goal of the temperature scenario in Section 7.3 was to solve an equation of the form g * m = dobs for m. In that section, we used generalized least squares to solve the equivalent matrix equation Gm = d. Another way to solve the problem is to construct an inverse filter ginv such that ginv * g = [1, 0, 0, …, 0]T. Then g * m = dobs can be solved by convolving each side of the equation by the inverse filter: mest = ginv * dobs.
The z-transform of the inverse filter is evidently ginv(z) = 1/g(z), because then g(z)ginv(z) = 1. Note, however, that the function 1/g(z) is not a polynomial, so the method of inverting the z-transform and thereby converting the function, 1/g(z), back to the time series, ginv, is unclear. Suppose, however, that g(z) was written as a product of its factors (z − ri), as in Equation (7.15). Then, the inverse filter is the product of the reciprocal of each of these binomials:

Each of these reciprocals can now be expanded using the binomial theorem:

Writing the same result in terms of time series

Thus, the inverse of a length-two filter is infinite in length. This is not a problem, as long as the elements of the inverse filter die away quickly, which happens when ![]() or, equivalently,
or, equivalently, ![]() .
.
Each length-two filter in the cascade for g turns into an infinite length filter in the cascade for the inverse filter, ginv. Therefore, while g is a length-N filter, ginv is an infinite length filter. Any attempt (as in Section 7.3) to find a finite-length version of ginv is at best approximate, and can really succeed only when all the roots of g(z) satisfy ![]() . Nevertheless, the approximation is quite good in some cases. In the lingo of filter theory, the roots, ri, must all lie outside the unit circle,
. Nevertheless, the approximation is quite good in some cases. In the lingo of filter theory, the roots, ri, must all lie outside the unit circle, ![]() , for the inverse filter to exist. In this case, the filter, g, is said to be minimum phase.
, for the inverse filter to exist. In this case, the filter, g, is said to be minimum phase.
This method can be used to construct inverse filters of short filters (Figure 7.11). The first step is to find the roots of the polynomial associated with the filter, g:
% find roots of g r = roots(flipud(g));
(MatLab eda07_07)
Here, the filter, g, is of length N. Note that the order of elements in g are flipped, because MatLab’s root() function expects the highest order coefficient first. Then a length, Ni, approximation of the inverse filter is computed:
% construct inverse filter, gi, of length Ni Ni = 50; gi = zeros(Ni,1); gi(1)=1/gN; % filter cascade, one filter per loop for j = [1:N−1] % construct inverse filter of a length−2 filter tmp = zeros(Ni,1); tmp(1) = 1; for k = [2:Ni] tmp(k) = tmp(k−1)/r(j); end tmp = −tmp/r(j); gi = conv(gi,tmp); gi=gi(1:Ni); end % delete imaginary part (which should be zero) gi = real(gi);
(MatLab eda07_07)
First, the inverse filter is initialized to a spike of amplitude 1/gN. Then, each component filter (Equation 7.18) of the cascade (Equation 7.17) is constructed and convolved into gi. After each convolution, the results are truncated to length Ni. Finally, the imaginary part of the inverse filter, which is zero up to round-off error, is deleted.
As an aside, we mention that Fourier transforms can also be used to solve the equation g * m = d and to understand the inverse filter. As the Fourier transform of a convolution is the product of the Fourier transforms, we have
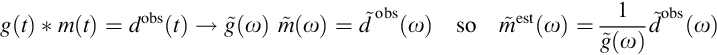
This equation elucidates the problem of the nonuniqueness of the solution, mest(t). If the Fourier transform of the impulse response, ![]() , is zero for any value of frequency, ω0, then this spectral hole hides the corresponding value of
, is zero for any value of frequency, ω0, then this spectral hole hides the corresponding value of ![]() , in the sense that the data,
, in the sense that the data, ![]() , does not depend on it. Thus,
, does not depend on it. Thus, ![]() is nonunique; its value at frequency ω0 is arbitrary. In practice, even nonzero but small values of
is nonunique; its value at frequency ω0 is arbitrary. In practice, even nonzero but small values of ![]() are problematical, as corresponding large values of
are problematical, as corresponding large values of ![]() amplify noise in the data,
amplify noise in the data, ![]() , and lead to a noisy solution, mest(t). We encountered this problem in the heat production scenario of Section 7.3. As the impulse response (Figure 7.4A) is a very smooth function, its Fourier transform has low amplitude at high frequencies. This leads to high-frequency noise present in the data being amplified during the solution process.
, and lead to a noisy solution, mest(t). We encountered this problem in the heat production scenario of Section 7.3. As the impulse response (Figure 7.4A) is a very smooth function, its Fourier transform has low amplitude at high frequencies. This leads to high-frequency noise present in the data being amplified during the solution process.
Equation (7.20) also implies that the Fourier transform of the inverse filter is ![]() ; that is, the Fourier transform of the inverse filter is the reciprocal of the Fourier transform of the filter. A problem arises, however, with spectral holes, as
; that is, the Fourier transform of the inverse filter is the reciprocal of the Fourier transform of the filter. A problem arises, however, with spectral holes, as ![]() is singular at those frequencies. Because of problems associated with spectral holes, the spectral division method defined by Equation (7.20) is not usually a satisfactory method for computing the solution to g * m = d or for constructing the inverse filter. The generalized least squares method, based on solving the matrix form of the equation g * ginv = [1, 0, 0, …, 0]T, usually performs much better, as prior information can be used to select a well-behaved solution.
is singular at those frequencies. Because of problems associated with spectral holes, the spectral division method defined by Equation (7.20) is not usually a satisfactory method for computing the solution to g * m = d or for constructing the inverse filter. The generalized least squares method, based on solving the matrix form of the equation g * ginv = [1, 0, 0, …, 0]T, usually performs much better, as prior information can be used to select a well-behaved solution.
7.8 Making use of what you know
In the standard way of evaluating a convolution equation (e.g., θ = g * h, as in Equation 7.1), we compute the elements of θ in sequence, θ1, θ2, θ3, … but independently of one another, even though we know the value of θ1 before we start to calculate θ2, know the values of θ1 and θ2 before we start to calculate θ3, and so forth. The known but unused values of θ are a source of information that can be put to work.
Suppose that the convolution equation (Equation 7.1) is modified by adding a second summation:

Here, u and v are filters of length N and M, respectively, whose relationships to g are yet to be determined. Note that the last summation starts at j = 2, so that only previously calculated elements of θ are employed. The introduction of past values of θ into the convolution equation is called recursion and filters that include recursion (i.e., include the last term in Equation 7.21) are called Infinite Impulse Response (IIR) filters. Filters that omit recursion (i.e., omit the last term in Equation 7.21) are called Finite Impulse Response (FIR) filters. If we define v1 = 1, then we can rewrite Equation (7.21) as:

Recall that we began this discussion by seeking an efficient way to evaluate θ = g * h. Equation (7.22) implies θ = vinv * u * h and so, if we could find filters u and v so that g = vinv * u, then Equation (7.21) would be equivalent to θ = g * h. However, it will only improve efficiency if the two filters, u and v, are shorter than g. What makes this possible is the fact that even a very short filter, v, has an infinitely long inverse filter, vinv.
In order to illustrate how an IIR filter can be designed, we examine the following simple case:

Here, g is a causal smoothing filter. It has only positive coefficients that rapidly decrease with time and the sum of its elements is unity. Each element of θ is dependent on just the current value and recent past of h. The choices
work in this case, as vinv = [1, v2, v22, …]T = [1, ½, ¼, …]T (see Equation 7.19). The generalized convolution equation (Equation 7.21) then reduces to
which involves very little computation, indeed! This filter is implemented in MatLab as follows Figure 7.11):
q1=zeros(N,1); q1(1)=0.5*h1(1); for j=[2:N] q1(j)=0.5*(h1(j) + q1(j−1)); end

(MatLab eda07_08)
Here, h1 is the original time series and q1 is the smoothed version. Both are of length N. MatLab provides a function, filter(), that implements Equation (7.20) and can be used as an alternative to the for loop (Figure 7.12):

u=[0.5,0]′; v=[1.0,−0.5]; q1 = filter(u, v, h1);
(MatLab eda07_09)
We will return to the issue of IIT filter design in Chapter 9.
Problems
7.1 Calculate by hand the convolution of a = [1, 1, 1, 1]T and b = [1, 1, 1, 1]T. Comment on the shape of the function c = a * b.
7.2 Plot the prediction error, E, of the prediction of the Neuse River hydrograph as a function of the length, N, of the prediction error filter. Is a point of diminishing returns reached?
7.3 What is the z-transform of a filter that delays a time series by one sample?
7.4 Note that any filter, g, with g1 = 0 is a nonstationary phase, as its z-transform is exactly divisible by z and so has a root at z = 0 that is not outside the unit circle. A simple way to change a stationary phase filter into one that is nonstationary phase filter is to decrease the size of its first element towards zero. Modify script eda07_07 to examine what happens to the inverse filter when you decrease the size of g1 towards zero in a series of steps. Increasing Ni might make the behavior clearer.
7.5 Generalize the recursive filter developed at the end of Section 7.8 for the case g(t) ∝ exp(−t/τ), that is, a smoothing filter of unit area and arbitrary width, τ. Start by writing gj ∝ [1, c, c2, …]T with c = exp(−Δt/τ).
7.6 Use your result from the previous problem to smooth the Neuse River hydrograph by with a sequence of filters, g(t) ∝ exp(−t/τ), with τ = 5, 15 and 40 days. Plot your results and comment on the effect of filtering on the appearance of the hydrograph.