
Filling in missing data
Abstract
Chapter 10, Filling in Missing Data, discusses the interpolation of one- and two-dimensional data. Interpolation is shown to be yet another special case of the linear model. The relationship between interpolation and the gap-filling techniques developed in Chapter 5 is shown to be related to different approaches to implementing prior information about the properties of the data. Linear and spline interpolation, as well as kriging, are developed. Two-dimensional interpolation and Delaunay triangulation, a critical technique for organizing two-dimensional data, are explained. Two-dimensional Fourier transforms, which are also important in many two-dimensional data analysis scenarios, are also discussed.
10.1 Interpolation requires prior information
Two situations in which data points need to be filled in are common:
The data are collected at irregularly spaced times or positions, but the data analysis method requires that they be evenly spaced. Spectral analysis is one such example, because it requires time to increase with constant increments, Δt.
Two sets of data need to be compared with each other, but they have not been observed at common values of time or position. The making of scatter plots is one such example, because the pairs of data that are plotted need to have been made at the same time or position.
In both cases, the times or positions at which the data have been observed are inconvenient. A solution to this dilemma is to interpolate the data; that is, to use the available data to estimate the data values at a more useful set of times or positions. We encountered the interpolation problem previously, in Chapter 5 (see Figure 10.1). Prior information about how the data behaved between the data points was a key factor in achieving the result.
The generalized least-squares methodology that we developed in Chapter 5 utilized both observations and the prior information to create an estimate of the data at all times or positions. Observations and prior information are both treated probabilistically. The solution is dependent on the observations and prior information, but does not satisfy either, anywhere. This is not seen as a problem, because both observations and prior information are viewed as subject to uncertainty. There is really no need to satisfy either of them exactly; we only need to find a solution for which the level of error is acceptable.
An alternative, deterministic approach is to find a solution that passes exactly through the observations and that exactly satisfies the prior information between them. Superficially, this approach seems superior—both observations and prior information are being satisfied exactly. However, this approach singles out the observation points as special. The solution will inevitably behave somewhat differently at the observation points than between them, which is not a desirable property.
Whether or not this approach is tractable—or even possible—depends on the type of prior information involved. Information about smoothness turns out to be especially easy to implement and leads to a set of techniques that might be called the traditional approach to interpolation. As we will see, these techniques are a straightforward extension of the linear model techniques that we have been developing in this book.
A purist might argue that interpolation of any kind is never the best approach to data analysis, because it will invariably introduce features not present in the original data, leading to wrong conclusions. A better approach is to generalize the analysis technique so that it can handle irregularly spaced data. This argument has merit, because interpolation adds additional—and often unquantifiable—error to the data. Nevertheless, if used sensibly, it is a valid data analysis tool that can simplify many data processing projects.
The basic idea behind interpolation is to construct an interpolant, a function, d(t), that goes through all the data points, di, and does something sensible in between them. We can then evaluate the interpolant, d(t), at whatever values of time, t, that we want—evenly spaced times, or times that match those of another dataset, to name two examples. Finding functions that go through a set of data points is easy. Finding functions that do something sensible in between the data points is more difficult as well as more problematical, because our notion of what is sensible will depend on prior knowledge, which varies from dataset to dataset.
Some obvious ideas do not work at all. A polynomial of degree N − 1, for instance, can easily be constructed to go through N data points (Figure 10.2). Unfortunately, the polynomial often takes wilds swings between the points. A high-degree polynomial does not embody the prior information that the function, d(t), does not stray too far above or below the values of nearby data points.

10.2 Linear interpolation
A low-order polynomial is less wiggly than a high-order one and is better able to capture the prior information of smoothness. Unfortunately, a low-order polynomial can pass exactly through only a few data. The solution is to construct the function, d(t), out of a sequence of polynomials, each valid for a short time interval. Such functions are called splines.
The simplest splines are line segments connecting the data points. The second derivative of a line is zero, so it embodies the prior information that the function is very smooth between the data points. The estimated datum at time, t, depends only on the values of the two bracketing observations, the one made immediately before time, t, and the one immediately after time, t. The interpolation formula is as follows:

Here, the time, t, is bracketed by the two observation times, ti and ti+1. Note the use of the local quantities, ti+1 − t and t − ti; that is, time measured with respect to a nearby sample. In MatLab, linear interpolation is performed as follows:
(MatLab eda10_02)
Here, d is a column vector of the original data, measured at time, t, and dp is the interpolated data at time, tp.
Linear interpolation has the virtue of being simple. The interpolated data always lie between the observed data; they never deviate above or below them (Figure 10.3). Its major defect is that the function, d(t), has kinks (discontinuities in slope) at the data points. The kinks are undesirable because they are an artifact not present in the original data; they arise from the prior information. Kinks will, for instance, add high frequencies to the power spectral density of the time series.

10.3 Cubic interpolation
A relatively simple modification is to use cubic polynomials in each of the intervals between the data points, instead of linear ones. A cubic polynomial has four coefficients and can satisfy four constraints. The requirement that the function must pass through the observed data at the ends of the interval places two constraints on these coefficients, leaving two constraints that can represent prior information. We can require that the first and second derivatives are continuous across intervals, creating a smooth function, d(t), that has no kinks across intervals. (Its first derivative has no kinks either, but its second derivative does).
The trick behind working out simple formula for cubic splines is properly organizing the knowns and the unknowns. We start by defining the i-th interval as the one between time, ti, and time, ti+1. Within this interval, the spline function is a cubic polynomial, Si(t). As the second derivative of a cubic is linear, it can be specified by its values, yi and yi+1, at the ends of the interval:

(Compare with Equation 10.1). We can make the second derivative continuous across adjacent intervals if we equate yi of interval i + 1 with yi+1 of interval i. Thus, only one second derivative, yi, is defined for each time, ti, even though two cubic polynomials touch this point. These ys are the primary unknowns in this problem. The formula for Si(t) can now be found by integrating Equation 10.2 twice:

Here ai and bi are integration constants. We now choose these constants so that the cubic goes through the data points, that is Si(ti) = di and Si(ti+1) = di+1. This requirement leads to

The cubic spline is then

and its first derivative is

Finally, we determine the ys by requiring that two neighboring splines have first derivatives that are continuous across the interval:
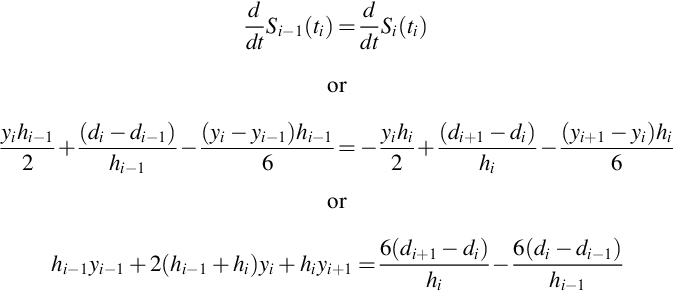
The y's satisfy a linear equation that can be solved by standard matrix methods, which we have discussed in Chapter 1. Note that the i = 1 and i = N equations involve the quantities, y0 and yN+1, which represent the second derivatives at two undefined points, one to the left of the first data point and the other to the right of the last data point. They can be set to any value and moved to the right hand side of the equation. The choice y0 = yN+1 = 0 leads to a solution called natural cubic splines.
Because of its smoothness (Figure 10.4), cubic spline interpolation is usually preferable to linear interpolation.

In MatLab, cubic spline interpolation is performed as follows:
(MatLab eda10_03)
Here, d is a column vector of the original data, measured at time, t, and dp is the interpolated data at time, tp.
10.4 Kriging
The generalized least-squared methodology that we developed in Chapter 5 to fill in data gaps was based on prior information, represented by the linear equation, ![]() . We quantified roughness, say R, of a vector, m, by choosing H to be a matrix of second derivatives and by setting
. We quantified roughness, say R, of a vector, m, by choosing H to be a matrix of second derivatives and by setting ![]() to zero. The minimization of the total roughness,
to zero. The minimization of the total roughness,
in Equation (5.8) leads to a solution that is smooth. Note that we can rewrite Equation (10.8) as
We have encountered the quantity, ![]() , before in Equation (5.1), where we interpreted it as the error, Ep(m), in the prior information. The quantity,
, before in Equation (5.1), where we interpreted it as the error, Ep(m), in the prior information. The quantity, ![]() , can be interpreted as the covariance, Cm, of the prior information. In the case of smoothness, the prior covariance matrix, Cm, has nonzero off-diagonal elements. Neighboring model parameters are highly correlated, as a smooth curve is one for which neighboring points have similar values. Thus, the prior covariance, Cm, of the model is intrinsically linked to the measure of smoothness. Actually we have already encountered this link in the context of time series. The autocorrelation function of a time series is closely related to both its covariance and its smoothness (see Section 9.1). This analysis suggests that prior information about a function's autocorrelation function can be usefully applied to the interpolation problem.
, can be interpreted as the covariance, Cm, of the prior information. In the case of smoothness, the prior covariance matrix, Cm, has nonzero off-diagonal elements. Neighboring model parameters are highly correlated, as a smooth curve is one for which neighboring points have similar values. Thus, the prior covariance, Cm, of the model is intrinsically linked to the measure of smoothness. Actually we have already encountered this link in the context of time series. The autocorrelation function of a time series is closely related to both its covariance and its smoothness (see Section 9.1). This analysis suggests that prior information about a function's autocorrelation function can be usefully applied to the interpolation problem.
Kriging (named after its inventor, Danie G. Krige) is an interpolation method based on this idea. It provides an estimate of a datum, ![]() , at an arbitrary time,
, at an arbitrary time, ![]() , based on a set of N observations, say
, based on a set of N observations, say ![]() , when prior information about its autocorrelation function, a(t), is available. The method assumes a linear model in which
, when prior information about its autocorrelation function, a(t), is available. The method assumes a linear model in which ![]() is a weighted average of all the observed data (as contrasted to just the two bracketing data) (Krige, 1951):
is a weighted average of all the observed data (as contrasted to just the two bracketing data) (Krige, 1951):

Here, dobs is a column vector of the observed data and w is an unknown column-vector of weights. As we shall see, the weights can be determined using prior knowledge of the autocorrelation function. The approach is to minimize the variance of ![]() , the difference between the estimated and true value of the time series. As we will see, we will not actually need to know the true value of the time series, but only its true autocorrelation function. The formula for variance is
, the difference between the estimated and true value of the time series. As we will see, we will not actually need to know the true value of the time series, but only its true autocorrelation function. The formula for variance is

Here, p(d) is the probability density function of the data. We have assumed that the estimated and true data have the same mean, that is, ![]() . We now set
. We now set ![]() so that
so that

Note that we have used the definition of the autocorrelation function, a(t) (see Equation 9.6) and that we have ignored a normalization factor (hence the ∝ sign), which appears in all three terms of the equation. Finally, we differentiate the variance with respect to wk and set the result to zero:

which yields the matrix equation
Thus,
Note that the matrix, M, and the column-vector, v, depend only on the autocorrelation of the data. Normally, data needs to be interpolated at many different times, not just one as in the equation above. In such case, we define a column vector, t0est, of all the times at which it needs to be evaluated, along with a corresponding vector of interpolated data, d0est. The solution becomes
Note that the results are insensitive to the overall amplitude of the autocorrelation function, which cancels from the equation; only its shape matters. Prior notions of smoothness are implemented by specifying a particular autocorrelation function. A wide autocorrelation function will lead to a smooth estimate of d(t) and a narrow function to a rough one. For instance, if we use a Normal function,

then its variance, L, will control the degree of smoothness of the estimate.
In MatLab, this approach is very simply implemented:
A = exp(−abs(tobs*ones(N,1)’−ones(N,1)*tobs’).^2/(2*L2)); V = exp(−abs(tobs*ones(M,1)’−ones(N,1)*test’).^2/(2*L2)); dest=dobs′*((A+1e−6*eye(N))V);
(MatLab eda10_04)
Note that we have damped the matrix, A, by addition of a small amount of the identity matrix. This modification guards against the possibility that the matrix, A, is near-singular. It has little effect on the solution when it is not near-singular, but drives the solution towards zero when it is. An example is shown in Figure 10.5.

Finally, we note that the power spectral density of a time series is uniquely determined by its autocorrelation function, as the former is the Fourier transform of the latter (see Section 9.3). Thus, while we have focused here on prior information in the form of the autocorrelation function of the time series, we could alternatively have used prior information about its power spectral density.
Crib Sheet 10.1
When and how to interpolate
If you can’t already guess what the interpolated values should be, don’t interpolate; limit your analysis to the uninterpolated data.
To convert an irregularly-sampled independent variable into an evenly-sampled one, in order to use an algorithm that requires the latter.
To align the independent variable of two different data sets, so that they can be compared.
To increase the number N of data and to fill in large data gaps.
(You are just fooling yourself when you do this).
Linear interpolation, advantages
The results are local (depend only upon bracketing values)
The overall range of the data is preserved.
The interpolated data may contain sharp kinks
(Don’t use when computing derivatives or power spectra)
Cubic interpolation, advantage
Extremely smooth
(Use when computing derivatives and power spectra)
The overall range of the data is not preserved.
The results are non-local (an outlier can lead to ringing).
Caveats when computing power spectra of interpolated data
While decreasing ![]() appears to increase fmax, the results are bogus.
appears to increase fmax, the results are bogus.
Interpolating large data gaps creates strong correlations between spectral peaks that complicate tests of significance.
10.5 Interpolation in two-dimensions
Interpolation is not limited to one dimension. Equally common is the case where data are collected on an irregular two-dimensional grid but need to be interpolated onto a regular, two-dimensional grid. The basic idea behind two-dimensional interpolation is the same as in one dimension: construct a function, d(x1, x2), that goes through all the data points and does something sensible in between them, and use it to estimate the data at whatever points, (x1, x2), are of interest.
A key part of spline interpolation is defining intervals over which the spline functions are valid. In one-dimensional interpolation, the intervals are both conceptually and computationally simple. They are just the segments of the time axis bracketed by neighboring observations. As long as the data are in the order of increasing time, each interval is between a data point and its successor. In two dimensions, intervals become two-dimensional patches (or tiles) in (x1, x2). Creating and manipulating these tiles is complicated.
One commonly used tiling is based on connecting the observation points together with straight lines, to form a mesh of triangles. The idea is to ensure that the vertices of every triangle coincide with the data points and that the (x1, x2) plane is completely covered by triangles with no holes or overlap. A spline function is then defined within each triangle. Such triangular meshes are nonunique as the data points can be connected in many alternative ways. Delaunay triangulation is a method for constructing a mesh that favors equilateral triangles over elongated ones. This is a desirable property as then the maximum distance over which a spline function acts is small. MatLab provides two-dimensional spline functions that rely on Delaunay triangulation, but perform it behind-the-scenes, so that normally you do not need to be concerned with it. Linear interpolation is performed using
dp=griddata(xobs,yobs,dobs,xp,yp,’linear’);
(MatLab eda09_05)
and cubic spline interpolation by
dp=griddata(xobs,yobs,dobs,xp,yp,’cubic’);
(MatLab eda10_05)
In both cases, xobs and yobs are column vectors of the (x1, x2) coordinates of the data, dobs is a column vector of the data, xp and yp are column vectors of the (x1, x2) coordinates at which interpolated data are desired, and dp is a column vector of the corresponding interpolated data. An example is given in Figure 10.6.

The MatLab documentation indicates that the griddata() function is being depreciated in favor of another, similar function, TriScatteredInterp(), meaning that it may not be supported in future releases of the software. The use of this new function is illustrated in MatLab script eda10_06. As of the time of publication, TriScatteredInterp() does not perform cubic interpolation.
Occasionally, the need arises to examine the triangular mesh that underpins the interpolation (Figure 10.6B). Furthermore, triangular meshes have many useful applications in addition to interpolation. In MatLab, a triangular grid is created as follows:
mytri = DelaunayTri(xobs,yobs); XY=mytri.X; [NXY, i] = size(XY); TRI = mytri.Triangulation; [NTRI, i] = size(TRI);
(MatLab eda10_05)
The DelaunayTri() function takes column-vectors of the (x1, x2) coordinates of the data (called xobs and yobs in the script) and returns information about the triangles in the object, mytri. Until now, we have not encountered MatLab objects. They are a type of variable that shares some similarity with a vector, as can be understood by the following comparison:
A vector, v, contains elements, that are referred to using a numerical index, for example, v(1), v(2), and so forth. The parentheses are used to separate the index from the name of the vector, so that there is no confusion between the two. Each element is a variable that can hold a scalar value. Thus, for example, v(1)=10.5.
An object, o, contains properties, that are referred to using symbolic names, for example, o.a, o.b, and so forth. The period is used to separate the name of the property from the name of the object so that there is no confusion between the two. Each property is a variable that can hold anything. Thus, for instance, the o.a property could hold a scalar value, o.a=10.5, but the o.b property could hold a 3000 × 100 matrix, o.b=zeros(3000,100).
The DelaunayTri() function returns an object, mytri, with two properties, mytri.X and mytri.Triangulation. The property, mytri.X, is a two-column wide array of the (x1, x2) coordinates of the vertices of the triangles. The property, mytri.Triangulation, is a three-column wide array of the indices, (t1, t2, t3), in the mytri.X vertex array, of the three vertices of each triangle.
In the script above, the mytri.X property is copied to a normal array, XY, of size NXY×2, and the mytri.Triangulation property is copied to a normal array, TRI, of size NTRI×3. Thus, the i-th triangle has one vertex at XY(v1,1), XY(v1,2), another at XY(v2,1), XY(v2,2), and a third at XY(v3,1), XY(v3,2), where
v1=TRI(i,1); v2=TRI(i,2); v3=TRI(i,3);
(MatLab eda10_05)
A commonly encountered problem is to determine within which triangle a given point, x0, is. MatLab provides a function that performs this calculation (see Figure 10.7 for a description of the theory behind this calculation):

tri0 = pointLocation(mytri, x0);
(MatLab eda10_05)
Here, x0 is a two-column wide array of (x1, x2) coordinates and tri0 is a column vector of indices to triangles enclosing these points (i.e., indices into the TRI array).
10.6 Fourier transforms in two dimensions
Periodicities can occur in two dimensions, as for instance in an aerial photograph of storm waves on the surface of the ocean. In order to analyze for these periodicities, we must Fourier transform over both spatial dimensions. A function, f(x, y), of two spatial variables, x and y, becomes a function of two spatial frequencies, or wavenumbers, kx and ky. The integral transform and its inverse are
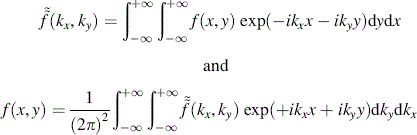
The two-dimensional transform can be thought of as two transforms applied successively. The first one transforms f(x, y) to ![]() and the second transforms
and the second transforms ![]() to
to ![]() . MatLab provides a function, fft2(), that compute the two-dimensional discrete Fourier transform.
. MatLab provides a function, fft2(), that compute the two-dimensional discrete Fourier transform.
In analyzing the discrete case, we will assume that x increases with row number and y increases with column number, so that the data are in a matrix, F, with Fij = f(xi, yj). The transforms are first performed on each row of, F, producing a new matrix, ![]() . As with the one-dimensional transform, the positive kys are in the left-hand side of
. As with the one-dimensional transform, the positive kys are in the left-hand side of ![]() and the negative kys are in its right-hand side. The transform is then performed on each column of
and the negative kys are in its right-hand side. The transform is then performed on each column of ![]() to produce
to produce ![]() . The positive kxs are in the top of
. The positive kxs are in the top of ![]() and the negative kxs are in the bottom of
and the negative kxs are in the bottom of ![]() . The output of the MatLab function, Ftt=fft2(F), in the Nx × Ny = 8 × 8 case, looks like
. The output of the MatLab function, Ftt=fft2(F), in the Nx × Ny = 8 × 8 case, looks like

For real data, ![]() , so that only the left-most Ny/2 + 1 columns are independent. Note, however, that reconstructing a right-hand column from the corresponding left-hand column requires reordering its elements, in addition to complex conjugation:
, so that only the left-most Ny/2 + 1 columns are independent. Note, however, that reconstructing a right-hand column from the corresponding left-hand column requires reordering its elements, in addition to complex conjugation:
for m = [2:Ny/2] mp=Ny−m+2; Ftt2(1,mp) = conj(Ftt(1,m)); Ftt2(2:Nx,mp) = flipud(conj(Ftt(2:Nx,m))); end
(MatLab eda10_07)
Here, Ftt2 is reconstructed from the left-size of Ftt, the two-dimensional Fourier transform of the Nx by Ny matrix, F (calculated, for example, as Ftt=fft2(F)).
We illustrate the two-dimensional Fourier transform with a cosine wave with wavenumber, kr, oriented so that a line perpendicular to its wavefronts makes an angle, θ, with the x-axis (Figure 10.8):

The Fourier transform, ![]() , has two spectral peaks, one at (kx, ky) = (krcosθ, krsinθ) and the other at (kx, ky) = (−krcosθ, −krsinθ). Sidelobes, which appear as vertical and horizontal streaks extending from the spectral peaks in Figure 10.8, are as much of a problem in two dimensions are they are in one.
, has two spectral peaks, one at (kx, ky) = (krcosθ, krsinθ) and the other at (kx, ky) = (−krcosθ, −krsinθ). Sidelobes, which appear as vertical and horizontal streaks extending from the spectral peaks in Figure 10.8, are as much of a problem in two dimensions are they are in one.
Problems
10.1 What is the covariance matrix of the estimated data in linear interpolation? Assume that the observed data have uniform variance, σd2. Do the interpolated data have constant variance? Are they uncorrelated?
10.2 Modify the interpolate_reynolds script of Chapter 9 to interpolate the Reynolds Water Quality dataset with cubic splines. Compare your results to the original linear interpolation.
10.3 Modify the eda10_04 script to computing the kriging estimate for a variety of different widths, L2, of the autocorrelation function. Comment on the results.
10.4 Modify the eda10_07 script to taper the data in both the x and y directions before computing the Fourier transform. Use a two-dimensional taper that is the product of a Hamming window function in x and a Hamming window function in y.
10.5 Estimate the power spectral density in selected monthly images of the CAC Sea Surface Temperature dataset (Chapter 8). Which direction has the longer-wavelength features, latitude or longitude? Explain your results.