
Detecting correlations among data
Abstract
Detecting Correlations among Data, develops techniques for quantifying correlations within data sets, and especially within and among time series. Several different manifestations of correlation are explored and linked together: from probability theory, covariance; from time series analysis, cross-correlation; and from spectral analysis, coherence. The effect of smoothing and band-pass filtering on the statistical properties of the data and their spectra is also discussed.
9.1 Correlation is covariance
When we create a scatter plot of observations, we are treating the data as random variables. The underlying idea is that two data types (or elements), say di and dj, are scattering about their typical values. Sometimes the scatter is due to measurement noise. Sometimes it is due to an unmodeled natural process that we can only treat probabilistically. But in either case, we are viewing the cloud of data points as being drawn from a joint probability density function, p(di, dj). The data are correlated if the covariance of this function is nonzero. Thus, the covariance matrix, C, is extremely useful in quantifying the degree to which different elements correlate. Recall that the covariance matrix associated with p(di, dj) are defined as:

Here ![]() and
and ![]() are the means of di and dj, respectively. We can estimate Cij from a data set by approximating the probability density function with a histogram constructed from the observed data. We first divide the (di, dj) plane into many small bins, numbered by the index s. Each bin has area ΔdiΔdj and is centered at (di(s), dj(s)) (Figure 9.1). We now denote the number of data pairs in bin s by Ns. The probability, p(di, dj) ΔdiΔdj ≈ Ns/N, where N is the total number of data pairs, so
are the means of di and dj, respectively. We can estimate Cij from a data set by approximating the probability density function with a histogram constructed from the observed data. We first divide the (di, dj) plane into many small bins, numbered by the index s. Each bin has area ΔdiΔdj and is centered at (di(s), dj(s)) (Figure 9.1). We now denote the number of data pairs in bin s by Ns. The probability, p(di, dj) ΔdiΔdj ≈ Ns/N, where N is the total number of data pairs, so


We now shrink the size of the patches so that at most one data pair is in each bin. Then, Ns equals either zero or unity. Summation over the patches is equal to summation over the (di, dj) pairs themselves:

The covariance is nonzero when the data exhibit some degree of correlation, but its actual numerical value depends on the overall range of the data. The range can be normalized to ±1 by scaling by the square root of the product of variances:

The quantity R is called the matrix of correlation coefficients, and its elements are called correlation coefficients and are denoted by the lower-case letter, r. When, as above, they are estimated from the data (as contrasted to being computed from the probability density function), they are referred to as sample correlation coefficients. See Table 9.1 for a list of important quantities, such as R, that are introduced in this chapter. The covariance, C, and correlation coefficient matrix, R, can be estimated from a set of data, D, as follows:
Table 9.1
Important Quantities Used in Chapter 9.
| Symbol | Name | Created from | Significance |
| Cd | Covariance matrix of the data, d | Probability density function of the data, p(d) | Diagonal elements, [Cd]ij with i = j: variance of the data, di; squared width of the univariate probability density function, p(di) off-diagonal elements, [Cd]ij with i ≠ j: degree of correlation between the pair of observations, di and dj |
| R | Matrix of correlation coefficients | Probability density function of the data, p(d) | Normalized version of Cd with elements that vary between ±1 elements of R given the symbol, r |
| Autocorrelaton function | Time series, d | Element ak: degree of correlation between two elements of d separated by a time lag, τ = (k − 1)Δt | |
| Cross-correlation function | Two time series, d(1) and d(2) | Element ck: degree of correlation between an element of d(1) and an element of d(2) separated by a time lag, τ = (k − 1)Δt | |
| Convolution | Filter, f, and time series, d | Filters the times series, d, with the filter, f | |
| Fourier transform | Time series, d(t) | Amplitude of sines and cosines of frequency, ω, in the time series | |
| C2(ω0, Δω) | Coherence | Two time series, d(1) and d(2) | Similarity between d(1) and d(2) at frequencies in the range, ω0 ± Δω varies between 0 and 1 |

C = cov(D); % covariance R = corrcoef(D); % correlation coefficient
(MatLab eda09_01)
Here, D, is an N × M matrix organized so that Dij is the amount of element, j, in sample i (the same arrangement as in Equation 8.1). The matrix, R, is M × M, so that Rij expresses the degree of correlation of elements i and j. Figure 9.2A depicts the matrix of correlation coefficients for the Atlantic rock dataset, in which the elements are literal chemical elements. The diagonal elements are all unity, as a data type correlates perfectly with itself. Some pairs of chemical components, such as TiO2 and NaO2, strongly correlate with each other (Figure 9.2B). Other pairs, such as TiO2 and Al2O3, are nearly uncorrelated.

The idea of correlation can also be applied to the elements of a time series. Neighboring samples in a time series are often highly correlated (and hence predictable), even though the time series as a whole may be random. Consider, for example, the stream flow of the Neuse River. On the one hand, a hydrologist, working a year ago, would not have been able to predict whether today’s discharge is unusually high or low. It is just not possible to predict individual storms—the source of the river’s water—a year in advance; they are best considered random phenomena. On the other hand, if today’s discharge is high, the chances are excellent that tomorrow’s discharge will be high as well. Stream flow persists for a few days, because the rain water takes time to drain away.
The notion of short term correlation within the stream flow time series can also be described by a joint probability density function. If we denote the river’s discharge at time ti as di, and discharge at time tj as dj, then we can speak of the joint probability density function p(di, dj). In the case of stream flow, we expect that di and dj will have a strong positive correlation when the time difference or lag, τ = ti − tj, is small (Figure 9.3A). When the measurements are more widely separated in time, then we expect the correlation to be weaker (Figure 9.3B). We expect discharge to be uncorrelated at separations of, say, a month or so (Figure 9.3C). On the other hand, discharge will again be positively correlated, although maybe only weakly so, at separations of about a year, because patterns of stream flow have an annual cycle. Note that we must assume that the time series is stationary, meaning that its statistical properties do not change with time, or else the degree of correlation would depend on the measurement times, as well as the time difference between them.

We already have the methodology to quantify the degree of correlation of a joint probability density function: its covariance matrix, Cij. In this case, we manipulate the formula to bring out the means, because in many cases we will be dealing with time series that fluctuate around zero:

Here, the mean, ![]() , of the time series is assumed to be independent of time (so it has no index). The matrix, A, is called the autocorrelation matrix of the time series. It is equal to the covariance matrix when the mean of the time series is zero.
, of the time series is assumed to be independent of time (so it has no index). The matrix, A, is called the autocorrelation matrix of the time series. It is equal to the covariance matrix when the mean of the time series is zero.
Just as in the case of the covariance, the autocorrelation can be estimated from observations. The data are pairs of samples drawn from the time series, where one member of the pair is lagged by a fixed time interval, τ = (k − 1)Δt, with respect to the other (with k an integer; note that k = 1 corresponds to τ = 0). A time series of length N has N − |k − 1| such pairs. We then form a histogram of the pairs, as we did in the case of covariance, so that the integral in Equation (9.5) can be approximated by a summation:

Once again, we shrink the size of the bins so that at most one pair is in each bin and Ns equals either zero or unity, so summation over the bin is equal to summation over the data pairs themselves. For the k > 0 case, we have

The column vector, a, is called the autocorrelation of the time series. An element, ak, is called the autocorrelation at time lag, τ = k − 1. The autocorrelation at negative lags equals the autocorrelation at positive lags, as A is a symmetric matrix, that is, Aij = ak, with k = |i − j| + 1. As we have defined it above, ak is unnormalized, in the sense that it omits the factor of 1/(N − |k − 1|).
In MatLab, the autocorrelation is calculated as follows:
(MatLab Script eda09_03)
Here, d is a time series of length N. The xcorr() function returns a vector of length 2N − 1 that includes both negative and positive lags so that the zero lag element is a(N).
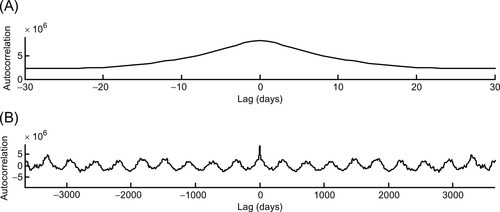
The autocorrelation of the Neuse River hydrograph is shown in Figure 9.4. For small lags, say of less than a month, the autocorrelation falls off rapidly with lag, with a time scale that reflects the time that rain water needs to drain away after a storm. For larger lags, say of a few years, the autocorrelation oscillates around zero with a period of one year. This behavior reflects the seasonal cycle. Summer and winter discharges are negatively correlated, as one tends to be high when the other is low.
9.2 Computing autocorrelation by hand
The autocorrelation at zero lag (k = 1) can be calculated by hand by writing down two copies of the time series, one above the other, multiplying adjacent terms, and adding:

Note that a1 is proportional to the power in the time series. Subsequent elements of ak are calculated by progressively offsetting one copy of the time series with respect to the other, prior to multiplying and adding (and ignoring the elements with no overlap). The lag Δt (k = 2) element is as follows:

and the lag 2Δt (k = 3) element is as follows:

9.3 Relationship to convolution and power spectral density
The formula for the autocorrelation is very similar to the formula for the convolution (Equation 7.1):

Note that a five pointed star, ![]() , is used to indicate autocorrelation, in the same sense that an asterisk, *, is used to indicate convolution. The two formulas are very similar, except that in the case of the convolution, one of the two time series is backward in time, in contrast to the autocorrelation, where both are forward in time. The relationship between the two can be found by transforming the autocorrelation integral to a new variable, τ′ = −τ,
, is used to indicate autocorrelation, in the same sense that an asterisk, *, is used to indicate convolution. The two formulas are very similar, except that in the case of the convolution, one of the two time series is backward in time, in contrast to the autocorrelation, where both are forward in time. The relationship between the two can be found by transforming the autocorrelation integral to a new variable, τ′ = −τ,

Thus, the autocorrelation is the convolution of a time-reversed time series with the original time series.
Two neighboring points on a time series will correlate strongly with each other if the time series varies slowly between them. A time series with an autocorrelation that declines slowly with lag is necessarily richer in low frequency energy than one that declines quickly with lag. This relationship can be explored by computing the Fourier transform of the autocorrelation. The calculation is simplified by recalling that the Fourier transform of a convolution is the product of the transforms. Thus,
where ![]() {−d(t)} stands for the Fourier transform of d(−t). We compute it as follows:
{−d(t)} stands for the Fourier transform of d(−t). We compute it as follows:

Here, we have used the transformation of variables, t′ = −t, together with the fact that, for real time series, ![]() and
and ![]() are complex conjugates of each other. Thus,
are complex conjugates of each other. Thus,
The Fourier transform of the autocorrelation is proportional to the power spectral density of the time series. As we have seen in Section 6.5, functions that are broad in time have Fourier transforms that are narrow in frequency. Hence, a time series with a broad autocorrelation function has most of its power at low frequencies.
9.4 Cross-correlation
The underlying idea behind the autocorrelation is that pairs of samples drawn from the same time series, and separated by a fixed time lag, τ, are correlated. This idea can be generalized to pairs of samples drawn from two different time series. As an example, consider time series of precipitation, u, and stream flow, v. At times when precipitation is high, we expect stream flow to be high, too. However, the time of peak stream flow will be delayed with respect to the time of maximum precipitation, as water takes time to drain from the land. Thus, the precipitation and stream flow time series will be most correlated when the former is lagged by a specific amount of time with respect to the latter.
We quantify this idea by defining the probability density function, p(ui, vj), the joint probability for the i-th sample of time series, u, and the j-th sample of time series, v. The autocorrelation then generalizes to the cross-correlation, ck (written side-by-size with the convolution, for comparison):

Note that the five pointed star is used to indicate cross-correlation, as well as autocorrelation, as the autocorrelation of a time series is its cross-correlation with itself. Here, u(ti) and v(ti) are two time series, each of length, N. The cross-correlation is related to the convolution by
In MatLab, the cross-correlation is calculated with the function
(MatLab Script eda09_04)
Here, u and v are time series of length, N. The xcorr() function returns both negative and positive lags and is of length, 2N−1. The zero-lag element is c(N). Unlike the autocorrelation, the cross-correlation is not symmetric in lag. Instead, the cross-correlation of v and u is the time-reversed version of the cross-correlation of u and v. Mistakes in ordering the arguments of the xcorr() function will lead to a result that is backwards in time; that is, if u(t) ![]() v(t) = c(t), then v(t)
v(t) = c(t), then v(t) ![]() u(t) = c(−t).
u(t) = c(−t).
We note here that the Fourier Transform of the cross-correlation is called the cross-spectral density:
However, we will put off discussion of its uses until Section 9.9.
9.5 Using the cross-correlation to align time series
The cross-correlation is useful in aligning two time series, one of which is delayed with respect to the other, as its peak occurs at the lag at which the two time series are best correlated, that is, the lag at which they best line up. In MatLab,
c = xcorr(u,v); [cmax, icmax] = max(c); tlag = −Dt * (icmax−N);
(MatLab eda09_04)
Here, Dt is the sampling interval of the time series and tlag is the time lag between the two time series. The lag is positive when features in v occur at later times than corresponding features in u. This technique is illustrated in Figure 9.5.

We apply this technique to an air quality dataset, in which the objective is to understand the diurnal fluctuations of ozone (O3). Ozone is a highly reactive gas that occurs in small (parts per billion) concentrations in the earth’s atmosphere. Ozone in the stratosphere plays an important role in shielding the earth’s surface from ultraviolet (UV) light from the sun, for it is a strong UV absorber. But its presence in the troposphere at ground level is problematical. It is a major ingredient in smog and a health risk, increasing susceptibility to respiratory diseases. Tropospheric ozone has several sources, including chemical reactions between oxides of nitrogen and volatile organic compounds in the presence of sunlight and high temperatures. We thus focus on the relationship between ozone concentration and the intensity of sunlight (that is, of solar radiation). Bill Menke provides the following information about the dataset:
A colleague gave me a text file of ozone data from the Weather Center at the United States Military Academy at West Point, NY. It contains tropospheric (ground level) ozone data for 15 days starting on August 1, 1993. Also included in the file are solar radiation, air temperature and several other environmental parameters. The original file is named ozone_orig.txt and has about a dozen columns of data. I used it to create a file ozone_nohead.txt that contains just 4 columns of data, time in days after 00:00 08/01/1993, ozone in parts per billion, solar radiation in W/m2, and air temperature in °C.
The solar radiation and ozone concentration data are shown in Figure 9.6. Both show a pronounced diurnal periodicity, but the peaks in ozone are delayed several hours behind the peaks in sunlight. The lag, determined by cross-correlating the two time series, is 3 h (Figure 9.7). Notice that excellent results are achieved, even though the two dataset do not exactly match.


9.6 Least squares estimation of filters
In Section 7.1, we showed that the convolution equation, g(t)*m(t) = d(t), can be written as a matrix equation of the form, Gm = d, where m and d are the time series versions of m(t) and d(t), respectively, and G is the matrix:

The least squares solution involves the matrix products, GTG and GTd:

Thus, the elements of GTd are the cross-correlation, c, of the time series d and g and the elements of GTG are approximately the autocorrelation matrix, A, of the time series, g. The matrix, GTG, is approximately Toeplitz, with elements [GTG]ij = ak, where k = |i − j| + 1. This result is only approximate, because on close examination, elements that appear to refer to the same autocorrelation are actually different from one another. Thus, for example, [GTG]11 is exactly a1, but [GTG]22 is not, as it is the autocorrelation of the first N − 1 elements of g, not of all of g. The difference grows towards the bottom-right of the matrix.
This technique is sometimes used to solve the filter estimation problem, that is, solve θ = g * h for an estimate of h. We examined this problem previously in Section 7.3, using MatLab script eda07_03. We provide here an alternate version of this script. A major modification is made to the function called by the biconjugate gradient solver, bicg(). It now uses the autocorrelation to perform the multiplication FTFv. The function was previously called filterfun() but is renamed here to autofun():
function y = autofun(v,transp_flag) global a H; N = length(v); % FT F v = GT G v + HT H v GTGv=zeros(N,1); for i = [1:N] GTGv(i) = [fliplr(a(1:i)′), a(2:N−i+1)′] * v; end Hv = H*v; HTHv = H′*Hv; y = GTGv + HTHv; return
(MatLab autofun)
The global variable, a, contains the autocorrelation of g. It is computed only once, in the main script. The main script also performs the cross-correlation prior to the call to bicg():
clear a H; global a H; ––– al = xcorr(g); Na = length(al); a = al((Na+1)/2: Na); ––– cl = xcorr(qobs2, g); Nc = length(cl); c = cl((Nc+1)/2: Nc); ––– % set up F′f = GT qobs + HT h % GT qobs is c=qobs2*g HTh = H′* h; FTf = c + HTh; % solve hest3 = bicg(@autofun, FTf, 1e−10, 3*L);
(MatLab eda09_06)
The results, shown in Figure 9.8, can be compared to those in Figure 7.7. The method does a good job recovering the two peaks in h, but suffers from “edge effects,” that is, putting spurious oscillations at the beginning and end of the time series.

9.7 The effect of smoothing on time series
As was discussed in Section 4.5, the smoothing of data is a linear process of the form, dsmooth = Gdobs. Smoothing is also a type of filtering, as can be seen by examining the form of data kernel, G (Equation 4.16), which is Toeplitz. The columns of G define a smoothing filter, s. Usually, we will want the smoothing to be symmetric, so that the smoothed data, dismooth, is calculated through a weighted average of the observed data, djobs, both to its left and right of i (where j > i corresponds to the future and j < i corresponds to the past). The filter, si, is, therefore, noncausal with coefficients that are symmetric about the present value (i = 1). The coefficients need to sum to unity, to preserve the overall amplitude of the data. These traits are exemplified in the three-point smoothing filter (see Equation 4.15):
It uses the present (element, i), the past (element, i − 1) and the future (element, i + 1) of dobs to calculate dismooth:

As long as the filter is of finite length, L, we can view the output as delayed with respect to the input, and the filtering operation itself to be causal:
In this case, the delay is one sample. In general, the delay is (L − 1)/2 samples. The length, L, controls the smoothness of the filter, with large Ls corresponding to large degrees of smoothing (Figure 9.9).

The above filter is triangular in shape, as it ramps up linearly to its central value and then linearly ramps down. It weights the central datum more than its neighbors. This is in contrast to the uniform filter, which has L constant coefficients, each of amplitude, L−1. It weights all L data equally. Many other shapes are possible, too. An important issue is the best shape for the smoothing filter, s.
One way of understanding the choice of the filter is to examine its effect on the autocorrelation function of the smoothed time series. Intuitively, we expect that smoothing broadens the autocorrelation, because it makes the time series vary less between samples. This behavior can be verified by computing the autocorrelation of the smoothed time series
Thus, the autocorrelation of the smoothed time series is the autocorrelation of the original time series convolved with the autocorrelation of the smoothing filter. The autocorrelation function of the smoothing filter is a broad function. When convolved with the autocorrelation function of the data, it smoothes and broadens it. Filters of different shapes have autocorrelation functions with different degrees of broadness. Each results in the smoothed data having a somewhat differently shaped autocorrelation function.
Another way of understanding the effect of the filter is to examine its effect on the power spectral density of the smoothed time series. The idea behind smoothing is to suppress high frequency fluctuations in the data while leaving the low frequencies unchanged. One measure of the quality of a filter is the evenness by which the suppression occurs. From this perspective, filters that evenly damp out high frequencies are better than filters that suppress them unevenly.
The behavior of the filter can be understood via the convolution theorem (Section 6.11), which states that the Fourier transform of a convolution is the product of the transforms. Thus, the Fourier transform of the smoothed data is just
That is, the transform of the smoothed data is the transform of the observed data multiplied by the transform of the filter. Thus, the effect of the filter can be understood by examining its amplitude spectral density, ![]() .
.
The uniform, or boxcar, filter with width, T, and amplitude, T−1 is the easiest to analyze:

Here, we have used the rule, exp(−iωt) = cos(ωt) + isin(ωt) and the definition, sinc(x) = sin(πx)/(πx). The cosine function is symmetric about the origin, so its integral on the (−½T, +½T) interval is twice that on (0, +½T) interval. The sine function is anti-symmetric, so its integral on the (−½T, 0) interval cancels its integral on the (0, +½T) interval. While the sinc function (Figure 9.10) declines with frequency, it does so unevenly, with many sidelobes along the frequency axis. It does not smoothly damp out high frequencies and so is a poor filter, from this perspective.

A filter based on a Normal curve will have no sidelobes (Figure 9.11), as the Fourier transform of a Normal curve with variance, σt2, in time is a Normal curve with variance, σω2 = σt−2, in frequency (Equation 6.27). It is a better filter, from the perspective of smoothly and evenly damping high frequencies. However, a Normal filter is infinite in length and must, in practice, be truncated, a process which introduces small sidelobes. Note that the effective width of a filter depends not only on its length, L, but also on its shape. The quantity, 2σt, is a good measure of its effective width, where σt2 is its variance in time. Thus, for example, a Normal filter with σt = 6.05 samples has approximately the same effective width as a uniform filter with L = 21, which has a variance of about 62 (compare Figures 9.10 and 9.11).

9.8 Band-pass filters
A smoothing filter passes low frequencies and attenuates high frequencies. A natural extension of this idea is a filter that passes frequencies in a specified range, or pass-band, and that attenuates frequencies outside of this range. A filter that passes low frequencies is called a low-pass filter, high frequencies, a high-pass filter, and an intermediate band, a band-pass filter. A filter that passes all frequencies except a given range is called a notch filter.
In order to design such filters, we need to know how to assess the effect of a given set of filter coefficients on the power spectral density of the filter. We start with the definition of an Infinite Impulse Response (IIR) filter (Equation 7.21), f = vinv*u, where u and v are short filters of lengths, Nu and Nv, respectively, and vinv is the inverse filter of v. The z-transform of the filter, f, is

Here, z ju and zkv are the roots of u(z) and v(z), respectively and c is a normalization constant. As our goal involves spectral properties, we need to understand the connection between the z-transform and the Fourier transform. The Discrete Fourier Transform is defined as

as ωk=(k − 1)Δω and tn=(n − 1)Δt. Note that the factor of (n − 1) within the exponential can be interpreted as raising the exponential to the (n − 1) power. Thus,

Here, we have used the relationship, ΔωΔt = 2π/N. Thus, the Fourier transform is just the z-transform evaluated at a specific set of z's. There are N of these z's and they are equally spaced on the unit circle (that is, the circle |z|2 = 1 in the complex z-plane, Figure 9.12). A point on the unit circle can be represented as, z = exp(−iθ), where θ is angle with respect to the real axis. Frequency, ω, is proportional to angle, θ, via θ = ωΔt = (k − 1)ΔωΔt = 2π(k − 1)/N. As the points in a Fourier transform are evenly spaced in frequency, they are evenly spaced in angle around the unit circle. Zero frequency corresponds to θ = 0 and the Nyquist frequency corresponds to θ = π; that is, 180°).

Now we are in a position to analyze the effect of the filters, u and v on the spectrum of the composite filter, f = vinv*u. The polynomial, u(z), has Nu − 1 roots (or “zeros”), each of which creates a region of low amplitude in a patch of the z-plane near that zero. If the unit circle intersects this patch, then frequencies on that segment of the unit circle are attenuated. Thus, for example, zeros near θ = 0 attenuate low frequencies (Figure 9.13A) and zeros near θ = π (the Nyquist frequency) attenuate high frequencies (Figure 9.13B).

The polynomial, v(z), has Nu − 1 roots, so that its reciprocal, 1/v(z), has Nu − 1 singularities (or poles), each of which creates a region of high amplitude in a patch of the z-plane near that pole. If the unit circle intersects this patch, then frequencies on that segment of the unit circle are amplified (Figure 9.14A). Thus, for example, poles near θ = 0 amplify low frequencies and zeros near θ = π (the Nyquist frequency) amplify high frequencies. As was discussed in Section 7.6, the poles must lie outside the unit circle for the inverse filter, vinv, to exist. In order for the filter to be real, the poles and zeros either must be on the real z-axis or occur in complex-conjugate pairs (that is, at angles, θ and −θ).

Filter design then becomes a problem of cleverly placing poles and zeros in the complex z-plane to achieve whatever attenuation or amplification of frequencies is desired. Often, just a few poles and zeros are needed to achieve the desired effect. For instance, two poles nearly collocated with two zeros suffice to create a notch filter (Figure 9.14B), that is, one that attenuates just a narrow range of frequencies. With just a handful of poles and zeros—corresponding to filters u and v with just a handful of coefficients—one can create extremely effective and efficient filters.
As an example, we provide a MatLab function for a Chebyshev band-pass filter, chebyshevfilt.m. It passes frequencies in a specific frequency interval and attenuates frequencies outside that interval. It uses u and v each of length 5, corresponding to four zeros and four poles. The zeros are paired up, two at θ = 0 and two at θ = π, so that frequencies near zero and near the Nyquist frequency are strongly attenuated. The two conjugate pairs of poles are near θs corresponding to the ends of the pass-band interval (Figure 9.15). The function is called as follows:

[dout, u, v] = chebyshevfilt(din, Dt, flow, fhigh);
(MatLab eda09_14)
Here, din is the input time series, Dt is the sampling interval and flow, and fhigh the pass-band. The function returns the filtered time series, dout, along with the filters, u and v. The input response of the filter (that is, its influence on a spike) is illustrated in Figure 9.16.

9.9 Frequency-dependent coherence
Time series that track one another, that is, exhibit coherence, need not do so at every period. Consider, for instance, a geographic location where air temperature and wind speed both have annual cycles. Summer days are, on average, both hotter and windier than winter days. But this correlation, which is due to large scale processes in the climate system, does not hold for shorter periods of a few days. A summer heat wave is not, on average, any windier than in times of moderate summer weather. In this case, temperature and wind are correlated at long periods, but not at short ones. In another example, plant growth in a given biome might correlate with precipitation over periods of a few weeks, but this does not necessarily imply that plant growth is faster in winter than in summer, even when winter tends to be wetter, on average, than summer. In this case, growth and precipitation are correlated at short periods, but not at long ones.
We introduce here a new dataset that illustrates this behavior, water quality data from the Reynolds Channel, part of the Middle Bay estuary on the south shore of Long Island, NY. Bill Menke, who provided the data, says the following about it:
I downloaded this Reynolds Channel Water Quality dataset from the US Geological Survey’s National Water Information System. It consists of daily average values of a variety of environmental parameters for a period of about five years, starting on January 1, 2006. The original data was in one long text file, but I broke it into two pieces, the header (reynolds_header.txt) and the data (reynolds_data.txt). The data file has very many columns, and has time in a year-month-day format. In order to make the data more manageable, I created another file, reynolds_uninterpolated.txt, that has time reformatted into days starting on January 1, 2006 and that retains only six of the original data columns: precipitation in inches, air temperature in °C, water temperature in°C, salinity in practical salinity units, turbidity in formazin nephelometric units and chlorophyll in micrograms per liter. Not every parameter had a data value for every time, so I set the missing values to the placeholder, −999. Finally I created a file, reynolds_interpolated.txt, in which missing data are filled in using linear interpolation. The MatLab script that I used is called interpolate_reynolds.m.
Note that the original data had missing data that were filled in using interpolation. We will discuss this process in the next chapter. A plot of the data (Figure 9.17) reveals that the general appearance of the different data types is quite variable. Precipitation is very spiky, reflecting individual storms. Air and water temperature, and to a lesser degree, salinity, are dominated by the annual cycle. Moreover, turbidity (cloudiness of the water) and chlorophyll (a proxy for the concentration of algae and other photosynthetic plankton) have both long period oscillations and short intense spikes.

We can look for correlations at different periods by band-pass filtering the data using different pass bands, for example periods of about 1 year and periods of about 5 days (Figure 9.18). All six time series appear to have some coherence at periods of 1 year, with air and water temperature tracking each other the best and turbidity tracking nothing very well. The situation at periods of about 5 days is more complicated. The most coherent pair seems to be salinity and precipitation, which are anti-correlated (as one might expect, as rain dilutes the salt in the bay). Air and water temperature do not track each other nearly as well in this period band than at periods of 1 year, but they do seem to show some coherence. Chlorophyll does not seem correlated with any of the other parameters at these shorter periods.

Our goal is to quantify the degree of similarity between two time series, u(t) and v(t), at frequencies near a specified frequency, ω0. We start by band-pass filtering the time series to produce filtered versions, f(t) * u(t) and f(t) * v(t). The band-pass filter, f(t, ω0, Δω), is chosen to have a center frequency, ω0, and a bandwidth, 2Δω (meaning that it passes frequencies in the range ω0 ± Δω). We now compare these two filtered time series by cross-correlating them:

If the two time series are similar in shape (and if they are aligned in time), then the zero-lag value of the cross-correlation, ![]() will have a large absolute value. Its value will be large and positive when the time series are nearly the same, and large and negative if they have nearly the same shape but are flipped in sign with respect to each other. It will be near-zero when the two time series are dissimilar.
will have a large absolute value. Its value will be large and positive when the time series are nearly the same, and large and negative if they have nearly the same shape but are flipped in sign with respect to each other. It will be near-zero when the two time series are dissimilar.
Two undesirable aspects of Equation (9.30) are that a different band-pass filtered version of the time series is required for every frequency at which we want to evaluate similarity and the whole cross-correlation is calculated, whereas only its zero-lag value is needed. As we show below, these time-consuming calculations are unnecessary. We can substantially improve on Equation (9.30) by utilizing the fact that the value of a function, c(t), at time, t = 0, is proportional to the integral of its Fourier transform over frequency:

Applying this relationship to the cross-correlation at zero lag, c(t = 0), and using the rule that the Fourier transform of a convolution is the product of the transforms, yields

Note that this formula involves the cross-spectral density, ![]() . Here, we assume that the band-pass filter can be approximated by two boxcar functions, one centered at +ω0 and the other at −ω0, so the integration limits, ±∞, can be replaced with integration over the positive and negative pass-bands. The cross-correlation is a real function, so the real part of its Fourier transform is symmetric in frequency and the imaginary part is anti-symmetric. Thus, only the real part of the integrand contributes. Except for a scaling factor of 1/(2Δω), the integral is just the average value of the integrand within the pass band, so we replace it with the average, defined as
. Here, we assume that the band-pass filter can be approximated by two boxcar functions, one centered at +ω0 and the other at −ω0, so the integration limits, ±∞, can be replaced with integration over the positive and negative pass-bands. The cross-correlation is a real function, so the real part of its Fourier transform is symmetric in frequency and the imaginary part is anti-symmetric. Thus, only the real part of the integrand contributes. Except for a scaling factor of 1/(2Δω), the integral is just the average value of the integrand within the pass band, so we replace it with the average, defined as

The zero-lag cross-correlation can be normalized into a quantity that varies between ±1 by dividing each time series by the square root of its power. Power is just the autocorrelation, a(t), of the time series at zero lag, and the autocorrelation is just the cross-correlation of a time series with itself, so power satisfies an equation similar to the one above:

Here, Pu and Pv, are the power in the band-passed versions of u(t) and v(t), respectively. Note that we can omit taking the real parts, for they are purely real. The quantity

which varies between +1 and –1, is a measure of the degree of similarity of the time series, u(t) and v(t). However, the quantity

is more commonly encountered in the literature. It is called the coherence of time series u(t) and v(t). It is nearly the square of ![]() , except that it omits the taking of the real part, so that it does not have exactly the interpretation of the normalized zero-lag cross-correlation of the band-passed time series. It does, however, behave similarly (see Note 9.1). It varies between zero and unity, being small when the time series are very dissimilar and large when they are nearly identical. These formulas are demonstrated in MatLab script eda09_17.
, except that it omits the taking of the real part, so that it does not have exactly the interpretation of the normalized zero-lag cross-correlation of the band-passed time series. It does, however, behave similarly (see Note 9.1). It varies between zero and unity, being small when the time series are very dissimilar and large when they are nearly identical. These formulas are demonstrated in MatLab script eda09_17.
The averaging in Equation (9.36)is over neighboring frequencies in a densely-sampled frequency series that is the result of taking the Fourier transform of long time series. However, a very similar result can be obtained by subdividing the long time series into shorter segments, taking the Fourier transform of each, and averaging the results. This correspondence follows from the frequency-spacing of the Fourier transform depending upon on the length of the time series. When a long time series is subdivided into K shorter segments of equal length, the number of frequencies decreases by a factor of K and the number of estimates at a given frequency increases by the same factor. Averaging the K estimates, all for the same frequency, from the short time series gives a result similar to averaging K adjacent values from the long one. This result, due to Welch (1967) is the basis for the MatLab coherence function mscohere() (see MatLab script eda09_18 for an example).
We return now to the Reynolds Channel water quality dataset, and compute the coherence of each pair of time series (several of which are shown in Figure 9.19). Air temperature and water temperature are the most highly coherent time series. They are coherent both at low frequencies (periods of a year or more) and high frequencies (periods of a few days). Precipitation and salinity are also coherent over most of frequency range, although less strongly than air and water temperature. Chlorophyll correlates with the other time series only at the longest periods, indicating that, while it is sensitive to the seasonal cycle, it is not sensitive to short time scale fluctuations in these parameters.

9.10 Windowing before computing Fourier transforms
When computing the power spectral density of continuous time series, we are faced with a decision of how long a segment of the time series to use. Longer is better, of course, both because a long segment is more likely to have properties representative of the time series as a whole, and because long segments provide greater resolution (recall that frequency sampling, Δω, scales with N−1). Actually, as data are often scarce, more often the question is how to make do with a short segment.
A short segment of a time series can be created by multiplying an indefinitely long time series, d(t), by a window function, W(t); that is, a function that is zero everywhere outside the segment. The simplest window function is the boxcar function, which is unity within the interval and zero outside it. The key question is what effect windowing has on the Fourier transform of a time series; that is, how the Fourier transform of W(t)d(t) differs from the Fourier transform of d(t). This question can be analyzed using the convolution theorem. As discussed in Section 6.11, the convolution of two time series has a Fourier transform that is the product of the two individual Fourier transforms. But time and frequency play symmetric roles in the Fourier transform. Thus, the product of two time series has a Fourier transform that is the convolution of the two individual transforms. Windowing has the effect of convolving the Fourier transform of the time series with the Fourier transform of the window function.
From this perspective, a window function with a spiky Fourier transform is the best, because convolving a function with a spike leaves the function unchanged. As we have seen in Section 9.7, the Fourier transform of a boxcar is a sinc function. It has a central spike, which is good, but it also has sidelobes, which are bad. The sidelobes create peaks in the spectrum of the windowed time series, W(t)d(t), that are not present in the spectrum of the original time series, d(t) (Figure 9.20). These artifacts can easily be mistaken for real periodicities in the data.

The solution is a better window function, one that does not have a Fourier transform with such strong sidelobes. It must be zero outside the interval, but we have complete flexibility in choosing its shape within the interval. Many such functions (or tapers) have been proposed. A popular one is the Hamming window function (or Hamming taper)

where Nw is the length of the window. Its Fourier transform (Figure 9.21) has significantly lower-amplitude sidelobes than the boxcar window function. Its central spike is wider, however (compare Figure 9.20E with Figure 9.21E), implying that it smoothes the spectrum of d(t) more than does a boxcar. Smoothing is bad in this context, because it blurs features in the spectrum that might be important. Two narrow and closely-spaced spectral peaks, for instance, will appear as a single broad peak. Unfortunately, the width of the central peak and the amplitude of sidelobes trade off in window functions. The end result is always a compromise between the two.

Notwithstanding this fact, one can nevertheless do substantially better than the Hamming taper, as we will see in the next section.
9.11 Optimal window functions
A good window function is one that has a spiky power spectral density. It should have large amplitudes in a narrow range of frequencies, say ±ω0, straddling the origin and have small amplitudes at higher frequencies. One way to quantify spikiness is through the ratio

Here, ![]() is the Fourier transform of the window function and ωny is the Nyquist frequency. From this point of view, the best window function is the one that maximizes the ratio, R.
is the Fourier transform of the window function and ωny is the Nyquist frequency. From this point of view, the best window function is the one that maximizes the ratio, R.
The denominator of Equation (9.38) is proportional to the power in the window function (see Equation 6.41). If we restrict ourselves to window functions that all have unit power, then the maximization becomes as follows:

The discrete Fourier transform, ![]() , of the window function and its complex conjugate,
, of the window function and its complex conjugate, ![]() , are
, are
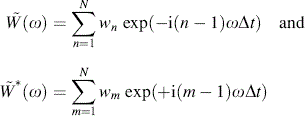
Inserting ![]() into F in Equation (9.39) yields
into F in Equation (9.39) yields

The integration can be performed analytically:

Note that M is a symmetric N × N matrix. The window function, w, satisfies

The Method of Lagrange Multipliers (see Note 9.2) says that maximizing a function, F, with a constraint, C = 0, is equivalent to maximizing F − λC without a constraint, where λ is a new parameter that needs to be determined. Differentiating wTMw − λ(wTw − 1) with respect to w and setting the result to zero leads to the equation
This is just the algebraic eigenvalue problem (see Equation 8.6). Recall that this equation has N solutions, each with an eigenvalue, λi, and a corresponding eigenvector, w(i). The eigenvalues, λi, satisfy λi = w(i)TMw(i), as can be seen by pre-multiplying Equation (9.44) by wT and recalling that the eigenvectors have unit length, wTw = 1. But wTMw is the quantity, F, being maximized in Equation (9.43). Thus, the eigenvalues are a direct measure of the spikiness of the window functions. The best window function is equal to the eigenvector with the largest eigenvalue.
We illustrate the case of a 64-point window function with a width of ω0 = 2Δω (Figures 9.22, 9.23 and 9.24). The six largest eigenvalues are 6.28, 6.27, 6.03, 4.54, 1.72, and 0.2. The first three eigenvalues are approximately equal in size, indicating that three different tapers come close to achieving the design goal of maximizing the spectral power in the ±ω0 frequency range. The first of these, W1(t), is similar in shape to a Normal curve, with high amplitudes in the center of the interval that taper off towards its ends. One possibility is to consider W1(t) the best window function and to use it to compute power spectral density.



However, W2(t) and W3(t) are potentially useful, because they weight the data differently than does W1(t). In particular, they leave intact data near the ends of the interval that W1(t) strongly attenuates. Instead of using just the single window, W1(t), in the computation of power spectral density, alternatively we could use several to compute several different estimates of power spectral density, and then average the results (Figure 9.24). This idea was put forward by Thomson (1982) and is called the multitaper method.
Problems
9.1 The ozone dataset also contains atmospheric temperature, a parameter, which like ozone, might be expected to lag solar radiation. Modify the eda09_05 script to estimate its lag. Does it have the same lag as ozone?
9.2 Suppose that the time series f and h are related by the convolution with the filter, s; that is, f = s*h. As the autocorrelation represents the covariance of a probability density function, the autocorrelation of f should be related to the autocorrelation of h by the normal rules of error propagation. Verify that this is the case by writing the convolution in matrix form, f = Sh, and using the rule Cf = SChST, where the Cs are covariance matrices.
9.3 Modify MatLab script eda09_03 to estimate the autocorrelation of the Reynolds Channel chlorophyll dataset. How quickly does the autocorrelation fall off with lag (for small lags)?
9.4 Taper the Neuse River Hydrograph data using a Hamming window function before computing its power spectral density. Compare your results to the untapered results, commenting on whether any conclusions about periodicities might change. (Note: before tapering, you should subtract the mean from the time series, so that it oscillates around zero).
9.5 Band-pass filter the Black Rock Forest temperature dataset to highlight diurnal variations of temperature. Provide a new answer to Question 2.3 that uses these results.