
Chapter 8. Operations Security
This chapter covers the following topics:
• Operations security concepts: Discusses concepts concerning maintaining security operations such as need-to-know/least privilege, separation of duties, job rotation, sensitive information procedures, record retention and monitoring special privileges.
• Resource protection: Describes procedures used to protect tangible and intangible assets. Topics include redundancy and fault tolerance, backup and recovery systems, identity and access management, media management, and network and resource management.
• Operations processes: Focuses on managing ongoing security measures. Topics include incident response management, change management, configuration management, patch management, and audit and review.
• Operations security threats and preventative measures: Covers preventative measures to security threats. Topics include clipping levels, deviations from standards, unusual or unexplained events, unscheduled reboots, trusted recovery, trusted paths, input/output controls, system hardening, vulnerability management systems, IDS/IPS, monitoring and reporting, and antimalware/antivirus.
After an enterprise has implemented a secure network, the job is not complete. Numerous policies, procedures, and processes must be developed and followed faithfully to maintain a secure posture. Operations security comprises the activities that support continual maintenance of the security of the system on a daily basis. This chapter covers those concepts and their application to an ever-changing environment.
Foundation Topics
Operations Security Concepts
Throughout this book you’ve seen references made to policies and principals that can guide all security operations. In this section we review some concepts more completely that have already been touched on and introduce some new issues concerned with maintaining security operations.

Need-to-Know/Least Privilege
In regard to allowing access to resources and assigning rights to perform operations, always apply the concept of least privilege (also called need-to-know). In the context of resource access that means that the default level of access should be no access. Give users access only to resources required to do their job, and that access should require manual implementation after the requirement is verified by a supervisor.
Discretionary access control (DAC) and role-based access control (RBAC) are examples of systems based on a user’s need to know. To ensure least privilege requires that the user’s job be identified and each user be granted the lowest clearance required for their tasks. Another example is the implementation of views in a database. Need-to-know requires that the operator have the minimum knowledge of the system necessary to perform his task.
Separation of Duties
The concept of separation of duties prescribes that sensitive operations be divided among multiple users so that no one user has the rights and access to carry out the operation alone. Separation of duties is valuable in deterring fraud by ensuring that no single individual can compromise a system. It is considered a preventive administrative control. An example would be one person initiating a request for a payment and another authorizing that same payment. This is also sometimes referred to as dual control.
Job Rotation
From a security perspective job rotation refers to the training of multiple users to perform the duties of a position to help prevent fraud by any individual employee. The idea is that by making multiple people familiar with the legitimate functions of the position, the higher the likelihood that unusual activities by any one person will be noticed. This is often used in conjunction with mandatory vacations, in which all users are required to take time off, allowing another to fill their position while gone, which enhances the opportunity to discover unusual activity. Beyond the security aspects of job rotation, additional benefits include:
• Trained backup in case of emergencies
• Protection against fraud
• Cross training of employees
Rotation of duties, separation of duties, and mandatory vacations are all administrative controls.
Sensitive Information Procedures
With an entire section of the CISSP exam blueprint (and a chapter of this book) devoted to access control and its use in preventing unauthorized access to sensitive data, it is obvious that the secure handling of sensitive information is critical. Although we tend to think in terms of the company’s information, it is also critical that the company protect the private information of its customers and employees as well. A leak of users’ and customers’ personal information causes at a minimum embarrassment for the company and possibly fines and lawsuits.
Regardless of whether the aim is to protect company data or personal data, the key is to apply the access control principles described in Chapter 2, “Access Control,” to both sets of data. When examining accessing access control procedures and policies, the following questions need to be answered.
• Is data available to the user that is not required for his job?
• Do too many users have access to sensitive data?
Record Retention
Proper access control is not possible without auditing. This allows us to track activities and discover problems before they are fully realized. Because this can sometimes lead to a mountain of data to analyze, only monitor the most sensitive of activities, and retain and review all records. Moreover, in many cases companies are required by law or regulation to maintain records of certain data.
Most auditing systems allow for the configuration of data retention options. In some cases the default operation is to start writing over the older records in the log when the maximum log size is full. Regular clearing and saving of the log can prevent this from happening and avoid the loss of important events. In cases of extremely sensitive data, having a server shut off access when a security log is full and cannot record any more events is even advisable.
Monitor Special Privileges
Inevitably some users, especially supervisors or those in the IT support department, will require special rights and privileges that other users do not possess. For example, it might be required that a set of users who work the Help Desk might need to be able to reset passwords or perhaps make changes to user accounts. These types of rights carry with them a responsibility to exercise the rights responsibly and ethically.
Although in a perfect world we would like to assume that we can expect this from all users, in the real world we know this is not always true. Therefore, one of the things to monitor is the use of these privileges. Although we should be concerned with the amount of monitoring performed and the amount of data produced by this monitoring, recording the exercise of special privileges should not be sacrificed, even if it means regularly saving the data as a log file and clearing the event gathering system.
Resource Protection
Enterprise resources include both assets we can see and touch (tangible), such as computers and printers, and assets we cannot see and touch (intangible), such as trade secrets and processes. Although typically we think of resource protection as preventing the corruption of digital resources and as the prevention of damage to physical resources, this concept also includes maintaining the availability of those resources. In this section, we discuss both aspects of resource protection.
Protecting Tangible and Intangible Assets
In some cases among the most valuable assets of a company are intangible ones such as secret recipes, formulas, and trade secrets. In other cases the value of the company is derived from its physical assets such as facilities, equipment, and the talents of its people. All are considered resources and should be included in a comprehensive resource protection plan. In this section some specific concerns with these various types of resources are explored.
Facilities
Usually the largest tangible asset the organization has is the building in which it operates and the surrounding land. Physical security is covered extensively in Chapter 11, “Physical (Environmental) Security,” but it bears emphasizing that vulnerability testing (discussed more fully later in this chapter) ought to include the security controls of the facility itself. Some examples of vulnerability testing as it relates to facilities include:
• Do doors close automatically, and does an alarm sound if they are held open too long?
• Are the protection mechanisms of sensitive areas, such as server rooms and wiring closets, sufficient and operational?
• Does the fire suppression system work?
• Are sensitive documents shredded as opposed to being thrown in the dumpster?
Beyond the access issues, the main systems that are needed to ensure operations are not disrupted include fire detection/suppression, HVAC (including temperature and humidity controls), water and sewage systems, power/backup power, communications equipment, and intrusion detection. For more detailed information on these issues, see Chapter 9, “Business Continuity and Disaster Recovery.”
Hardware
Another of the more tangible assets that must be protected is all the hardware that makes the network operate. This includes not only the computers and printers with which the users directly come in contact, but also the infrastructure devices that they never see such as routers, switches, and firewall appliances. Maintaining access to these critical devices from an availability standpoint is covered later in the sections “Redundancy and Fault Tolerance” and “Backup and Recovery Systems.”
From a management standpoint these devices are typically managed remotely. Special care must be taken to safeguard access to these management features as well as protect the data and commands passing across the network to these devices. Some specific guidelines include:
• Change all default administrator passwords on the devices.
• Limit the number of users that have remote access to these devices.
• Rather than Telnet (which send commands in clear text) use an encrypted command-line tool such as Secure Shell (SSH).
• Manage critical systems locally.
• Limit physical access to these devices.
Software
Software assets include any propriety application, scripts, or batch files that have been developed in house that are critical to the operation of the organization. As discussed in Chapter 5, “Software Development Security,” secure coding and development practices can help to prevent weaknesses in these systems. Attention must also be paid to preventing theft of these assets as well.
Moreover, closely monitoring the use of commercial applications and systems in the enterprise can prevent unintentional breach of licensing agreements. One of the benefits of only giving users the applications they require to do their job is that it limits the number of users that have an application, helping to prevent exhaustion of licenses for software.
Information Assets
Information assets are the last asset type that needs to be discussed but by no means are they the least important. The primary purpose of operations security is to safeguard information assets that are resident in the system. These assets include recipes, processes, trade secrets, product plans, and any other type of information that enables the enterprise to maintain competitiveness within its industry. The principles of data classification and access control discussed in Chapters 4 and 2, respectively, apply most critically to these assets. In some cases the dollar value of these assets might be difficult to determine although it might be clear to all involved that the asset is critical. For example, the secret formula for Coca-Cola has been closely guarded for many years due to its value to the company.
Asset Management
In the process of managing these assets several issues must be addressed. Certainly access to the asset must be closely controlled to prevent its deletion, theft, or corruption (in the case of digital assets) and from physical damage (in the case of physical assets). Moreover, the asset must remain available when needed. This section covers methods of ensuring availability, authorization, and integrity.
Redundancy and Fault Tolerance
One of the ways to provide uninterrupted access to information assets is through redundancy and fault tolerance. Redundancy refers to providing multiple instances of either a physical or logical component such that a second component is available if the first fails. Fault tolerance is a broader concept that includes redundancy but refers to any process that allows a system to continue making information assets available in the case of a failure.
In some cases redundancy is applied at the physical layer, such as network redundancy provided by a dual backbone in a local network environment or by using multiple network cards in a critical server. In other cases redundancy is applied logically such as when a router knows multiple paths to a destination in case one fails.
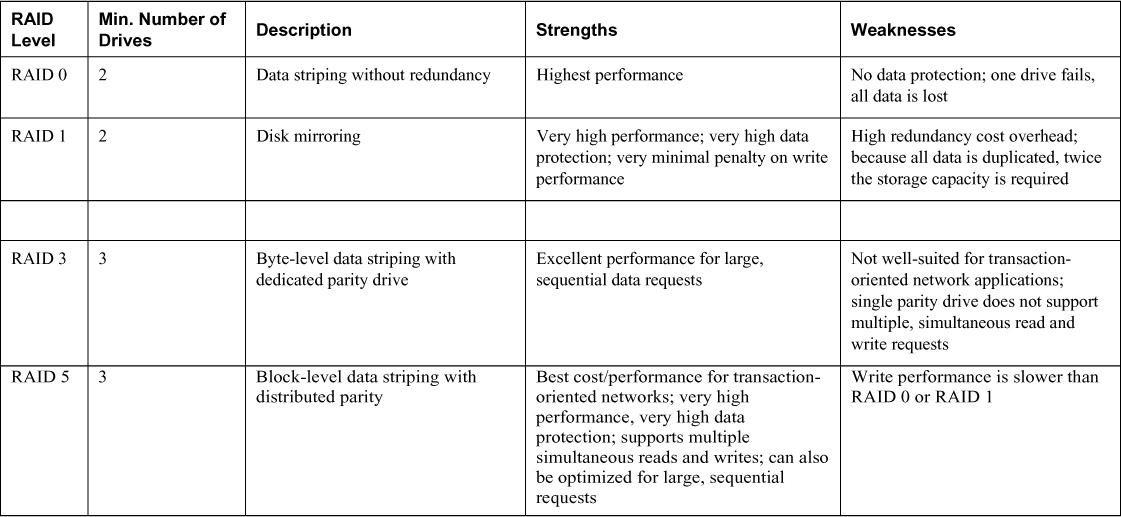
Fault tolerance countermeasures are designed to combat threats to design reliability. Although fault tolerance can include redundancy it also refers to systems such as Redundant Array of Independent Disks (RAID) in which data is written across multiple disks in such a way that a disk can fail and the data can be quickly made available from the remaining disks in the array without resorting to a backup tape. Be familiar with a number of RAID types because not all provide fault tolerance. RAID is covered in Chapter 9, “Business Continuity and Disaster Recovery.” Regardless of the technique employed for fault tolerance to operate, a system must be capable of detecting and correcting the fault.
Backup and Recovery Systems
Although a comprehensive coverage of backup and recovery systems is found in Chapter 9, it is important to emphasize here the role of operations in carrying out those activities. After the backup schedule has been designed, there will be daily tasks associated with carrying out the plan. One of the most important parts of this system is an ongoing testing process to ensure that all backups are usable in case a recovery is required. The time to discover that a backup did not succeed is during testing and not during a live recovery.
Identity and Access Management
Identity and access management are covered thoroughly in Chapter 2. From an operations perspective it is important to realize that managing these things is an ongoing process that might require creating accounts, deleting accounts, creating and populating groups, and managing the permissions associated with all of these concepts. Ensuring that the rights to perform these actions are tightly controlled and that a formal process is established for removing permissions when they are no longer required and disabling accounts that are no longer needed is essential.
Another area to focus on is the control of the use of privileged accounts or accounts that have rights and permissions that exceed those of a regular user account. Although this obviously applies to built-in administrator or supervisor accounts (in some operating systems called root accounts) that have vast permissions, it also applies to accounts such as the Windows Power User account, which also confers some special privileges to the user.
Moreover, maintain the same tight control over the numerous built-in groups that exist in Windows to grant special rights to the group members. When using these groups, make note of any privileges held by the default groups that are not required for your purposes. You might want to remove some of the privileges from the default groups to support the concept of least privilege.
Media Management
Although media management was briefly discussed in Chapter 7, “Security Architecture and Design,” a more detailed coverage is appropriate here. Be familiar with the following concepts and issues surrounding media management.
RAID
Redundant Array of Independent Disks (RAID) refers to a system whereby multiple hard drives are used to provide either a performance boost or fault tolerance for the data. When we speak of fault tolerance in RAID we mean maintaining access to the data even in a drive failure without restoring the data from a backup media. The following are the types of RAID with which you should be familiar.
RAID 0, also called disk striping, writes the data across multiple drives. Although it improves performance its does not provide fault tolerance. Figure 8-1 depicts RAID 0.
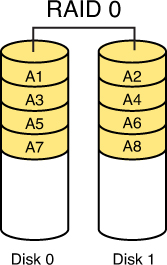
RAID 1, also called disk mirroring, uses two disks and writes a copy of the data to both disks, providing fault tolerance in the case of a single drive failure. Figure 8-2 depicts RAID 1.
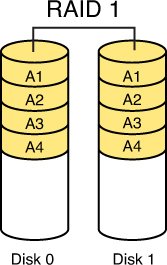
RAID 3, requiring at least three drives, also requires that the data is written across all drives like striping and then parity information is written to a single dedicated drive. The parity information is used to regenerate the data in the case of a single drive failure. The downfall is that the parity drive is a single point of failure if it goes bad. Figure 8-3 depicts RAID 3.
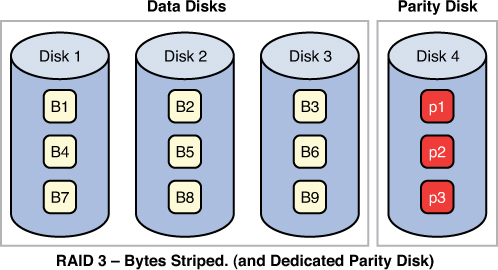
RAID 5, requiring at least three drives, also requires that the data is written across all drives like striping and then parity information is written across all drives as well. The parity information is used in the same way as in RAID 3, but it is not stored on a single drive so there is no single point of failure for the parity data. With hardware RAID Level 5 the spare drives that replace the failed drives are usually hot swappable, meaning they can be replaced on the server while it is running. Figure 8-4 depicts RAID 5.
RAID 7, though not a standard but a proprietary implementation, incorporates the same principles as RAID 5 but enables the drive array to continue to operate if any disk or any path to any disk fails. The multiple disks in the array operate as a single virtual disk.
Although RAID can be implemented with software or with hardware, certain types of RAID are faster when implemented with hardware. When software RAID is used, it is a function of the operating system. Both RAID 3 and 5 are examples of RAID types that are faster when implemented with hardware. Simple striping or mirroring (RAID 0 and 1), however, tend to perform well in software because they do not use the hardware-level parity drives. Table 8-1 summarizes the RAID types.
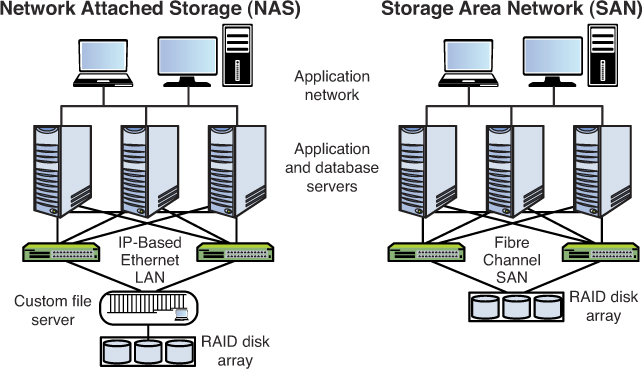
SAN
Storage area networks (SAN) are comprised of high-capacity storage devices that are connected by a high-speed private network (separate from the LAN) using storage-specific switches. This storage information architecture addresses the collection of data, management of data, and use of data.
NAS
Network-attached storage (NAS) serves the same function as SAN, but clients access the storage in a different way. In a NAS, almost any machine that can connect to the LAN (or is interconnected to the LAN through a WAN) can use protocols such as NFS, CIFS, or HTTP to connect to a NAS and share files. In a SAN, only devices that can use the Fibre channel SCSI network can access the data so it is typically done though a server with this capability. Figure 8-5 shows a comparison of the two systems.
HSM
A Hierarchical Storage Management (HSM) system is a type of backup management system that provides a continuous online backup by using optical or tape “jukeboxes.” It operates by automatically moving data between high-cost and low-cost storage media as the data ages. When continuous availability (24 hours-a-day processing) is required, HSM provides a good alternative to tape backups. It also strives to use the proper media for the scenario. For example, rewritable and erasable (CDR/W) optical disk is sometimes used for backups that require short time storage for changeable data, but require faster file access than tape.
Media History
Accurately maintain media library logs to keep track of the history of the media. This is important in that all media types have a maximum number of times they can safely be used. A log should be kept by a media librarian. This log should track all media (backup and other types such as OS installation discs). With respect to the backup media use the following guidelines:
• Track all instances of access to the media.
• Track the number and location of backups.
• Track age of media to prevent loss of data through media degeneration.
• Inventory the media regularly.
Media Labeling and Storage
Plainly label all forms of storage media (tapes, optical, and so on) and store them safely. Some guidelines in the area of media control are to
• Accurately and promptly mark all data storage media.
• Ensure proper environmental storage of the media.
• Ensure the safe and clean handling of the media.
• Log data media to provide a physical inventory control.
The environment where the media will be stored is also important. For example, damage starts occurring to magnetic media above 100 degrees. The Forest Green Book is a Rainbow Series book that defines the secure handling of sensitive or classified automated information system memory and secondary storage media, such as degaussers, magnetic tapes, hard disks, floppy disks, and cards. The Rainbow Series is discussed in more detail in Chapter 4, “Information Security Governance and Risk Management.”
Sanitizing and Disposing of Media
During media disposal, you must ensure no data remains on the media. The most reliable, secure means of removing data from magnetic storage media, such as a magnetic tape cassette, is through degaussing, which exposes the media to a powerful, alternating magnetic field. It removes any previously written data, leaving the media in a magnetically randomized (blank) state. Some other disposal terms and concepts with which you should be familiar are
• Data purging: Using a method such as degaussing to make the old data unavailable even with forensics. Purging renders information unrecoverable against laboratory attacks (forensics).
• Data clearing: Renders information unrecoverable by a keyboard. This attack extracts information from data storage media by executing software utilities, keystrokes, or other system resources executed from a keyboard.
• Remanence: Any data left after the media has been erased.
Network and Resource Management
Although security operations seems to focus its attention on providing confidentiality and integrity of data, availability of the data is also one of its goals. This means designing and maintaining processes and systems that maintain availability to resources despite hardware or software failures in the environment. Although this topic is covered more completely in Chapter 9, the following principles and concepts are available to assist in maintaining access to resources:
Redundant Hardware: Failures of physical components, such as hard drives and network cards, can interrupt access to resources. Providing redundant instances of these components can help to ensure a faster return to access. In some cases changing out a component might require manual intervention, but in many cases these items are hot swappable (they can be changed with the device up and running) in which case a momentary reduction in performance might occur rather than a complete disruption of access.
Fault-Tolerant Technologies: Taking the idea of redundancy to the next level are technologies that are based on multiple computing systems working together to provide uninterrupted access even in the event of a failure of one of the systems. Clustering of servers and grid computing are both great examples of this approach.
Service Level Agreements (SLAs): SLAs are agreements about the ability of the support system to respond to problems within a certain timeframe while providing an agreed level of service. They can be internal between departments or external to a service provider. By agreeing on the quickness with which various problems are addressed, some predictability is introduced to the response to problems, which ultimately supports the maintenance of access to resources.
MTBF and MTTR: Although service-level agreements are appropriate for services that are provided, a slightly different approach to introducing predictability can be used with regard to physical components that are purchased. Vendors typically publish values for a product’s Mean Time Between Failure (MTBF), which describes how often a component fails on average. Another valuable metric typically provided is the Mean Time to Repair (MTTR), which describes the average amount of time it will take to get the device fixed and back online.
Single Point of Failure (SPOF): Though not actually a strategy, it is worth mentioning that the ultimate goal of any of these approaches is to avoid a single point of failure in a system. All components and group of components and devices should be examined to discover any single element that could interrupt access to resources if a failure occurs. Each SPOF should then be mitigated in some way.
Operations Processes
While technology can help us to prevent many problems and maintain access to critical resources, in many cases problems are created by the human beings managing the systems. Well-designed and tested policies and processes, exercised faithfully, can go a long way in preventing loss of data and loss of access to data. This section covers a number of critical procedures.
Incident Response Management
Inevitably security events will occur and the response to these events says much about how damaging the events will be to the organization. Incident response policies should be formally designed, well communicated, and followed. They should specifically address cyber-attacks against an organization’s IT systems. Steps in the incident response system can include the following:
1. Detect. The first step is to detect the incident. All detective controls, such as auditing, discussed in Chapter 2, “Access Control,” are designed to provide this capability. The worst sort of incident is the one that goes unnoticed.
2. Respond. The response to the incident should be appropriate for the type of incident. Denial of service attacks against the web server would require a quicker and different response than a missing mouse in the server room. Establish standard responses and response times ahead of time.
3. Report. All incidents should be reported within a timeframe that reflects the seriousness of the incident. In many cases establishing a list of incident types and the person to contact when that type of incident occurs is helpful. Exercising attention to detail at this early stage while time-sensitive information is still available is critical.
4. Recover. Recovery involves a reaction designed to make the network or system that is affected functional again. Exactly what that means depend on the circumstances and the recovery measures that are available. For example, if fault-tolerance measures are in place, the recovery might consist of simply allowing one server in a cluster to fail over to another. In other cases it could mean restoring the server from a recent backup. The main goal of this step is to make all resources available again.
5. Remediate. This step involves eliminating any residual danger or damage to the network that still might exist. For example, in the case of a virus outbreak, it could mean scanning all systems to root out any additional effected machines. These measures are designed to make a more detailed mitigation when time allows.
6. Review. Finally, review each incident to discover what could be learned from it. Changes to procedures might be called for. Share lessons learned with all personnel who might encounter this type of incident again. Complete documentation and analysis is the goal of this step.
Change Management
All networks evolve, grow, and change over time. Companies and their processes also evolve and change, which is a good thing. But manage change in a structured way so as to maintain a common sense of purpose about the changes. By following recommended steps in a formal process, change can be prevented from becoming the tail that wags the dog. The following are guidelines to include as a part of any change control policy:
• All changes should be formally requested.
• Each request should be analyzed to ensure it supports all goals and polices.
• Prior to formal approval, all costs and effects of the methods of implementation should be reviewed.
• After they’re approved, the change steps should be developed.
• During implementation, incremental testing should occur, relying on a predetermined fallback strategy if necessary.
• Complete documentation should be produced and submitted with a formal report to management.
One of the key benefits of following this method is the ability to make use of the documentation in future planning. Lessons learned can be applied and even the process itself can be improved through analysis.
Configuration Management
Although it’s really a subset of change management, configuration management specifically focuses itself on bringing order out of the chaos that can occur when multiple engineers and technicians have administrative access to the computers and devices that make the network function. It follows the same basic process as that discussed under “Change Management,” but perhaps takes on even greater importance considering the impact that conflicting changes can have (and in some immediately) on the network.
The functions of configuration management are:
• Report the status of change processing.
• Document the functional and physical characteristics of each configuration item.
• Perform information capture and version control.
• Control changes to the configuration items, and issue versions of configuration items from the software library
Note
In the context of configuration management, a software library is a controlled area accessible only to approved users who are restricted to the use of an approved procedure. A configuration item (CI) is a uniquely identifiable subset of the system that represents the smallest portion to be subject to an independent configuration control procedure. When an operation is broken into individual CIs the process is called configuration identification.
Examples of these types of changes are:
• Operating system configuration
• Software configuration
• Hardware configuration
From a CISSP perspective, the biggest contribution of configuration management controls is ensuring that changes to the system do not unintentionally diminish security. Because of this, all changes must be documented, and all network diagrams, both logical and physical must be updated constantly and consistently to accurately reflect the state of each configuration now and not as it was two years ago. Verifying that all configuration management policies are being followed should be an ongoing process.
In many cases it is beneficial to form a configuration control board. The tasks of the configuration control board can include
• Ensuring that changes made are approved, tested, documented, and implemented correctly.
• Meeting periodically to discuss configuration status accounting reports.
• Maintaining responsibility for ensuring that changes made do not jeopardize the soundness of the verification system.
In summary, the components of configuration management are:
• Configuration control
• Configuration status accounting
• Configuration audit
Patch Management
As configuration management is a subset of change management, patch management might be seen as a subset of configuration management. Software patches are updates released by vendors that either fix functional issues with or close security loopholes in operating systems, applications, and versions of firmware that run on the network devices.
To ensure that all devices have the latest patches installed, deploy a formal system to ensure that all systems receive the latest updates after thorough testing in a non-production environment. It is impossible for the vendor to anticipate every possible impact a change might have on business critical systems in the network. The enterprise is responsible for ensuring that patches do not adversely impact operations.
Audit and Review
Accountability is impossible without a record of activities and review of those activities. Capturing and monitoring audit logs provide the digital proof when someone who is performing certain activities needs to be identified. This goes for both the good guys and the bad guys. In many cases it is required to determine who misconfigured something rather than who stole something. Audit trails based upon access and identification codes establish individual accountability. The questions to address when reviewing audit logs include the following:
• Are users accessing information or performing tasks that are unnecessary for their job?
• Are repetitive mistakes (such as deletions) being made?
• Do too many users have special rights and privileges?
The level and amount of auditing should reflect the security policy of the company. Audits can be either self-audits or be performed by a third party. Self-audits always introduce the danger of subjectivity to the process. Logs can be generated on a wide variety of devices including IDS, servers, routers, and switches. In fact, host-based IDS makes use of the operating system logs of the host machine.
When assessing controls over audit trails or logs, address the following questions:
• Does the audit trail provide a trace of user actions?
• Is access to online logs strictly controlled?
• Is there separation of duties between security personnel who administer the access control function and those who administer the audit trail?
Keep and store logs in accordance with the retention policy defined in the organization’s security policy. They must be secured to prevent modification, deletion, and destruction. When auditing is functioning in a monitoring role it supports the detection security function in the technical category. When formal review of the audit logs takes place it is a form of detective administrative control. Reviewing audit data should be a function separate from the day-to-day administration of the system.
Operations Security Threats and Preventative Measures
As you have probably gathered by now a wide variety of security threats face those charged with protecting the assets of an organization. Luckily, a wide variety of tools are available to use to accomplish this task. This section covers some common threats and mitigation approaches.
Clipping Levels
Clipping levels set a baseline for normal user errors, and violations exceeding that threshold will be recorded for analysis of why the violations occurred. When clipping levels are used a certain number of occurrences of an activity might generate no information whereas recording of activities begins when a certain level is exceeded.
Clipping levels are used to
• Reduce the amount of data to be evaluated in audit logs
• Provide a baseline of user errors above which violations will be recorded
Deviations from Standards
One of the methods that you can use to identify performance problems that arise is by developing standards or baselines for the performance of certain systems. After these benchmarks have been established deviations for the standards can be identified. This is especially helpful in identifying certain types of DoS attacks as they occur. Beyond the security benefit it also aids in identifying systems that might need upgrading before the situation effects productivity.
Unusual or Unexplained Events
In some cases events occur that appear to have no logical cause. That should never be accepted as an answer when problems occur. Although the focus is typically on getting systems up and running again, the root causes of issues must be identified. Avoid the temptation to implement a quick workaround (often at the expense of security). When time permits, using a methodical approach to find exactly why the event happened is best, because inevitably the problem will come back if the root cause has not been addressed.
Unscheduled Reboots
When systems reboot on their own, it is typically a sign of hardware problems of some sort. Reboots should be recorded and addressed. Overheating is the cause of many reboots. Often reboots can also be the result of a DoS attack. Have a system monitoring in place to record all system reboots, and investigate any that are not initiated by a human or have occurred as a result of an automatic upgrade.
Trusted Recovery
When an application or operating system suffers a failure (crash, freeze, and so on) it is important that the system respond in a way that leaves the system in a secure state or that it makes a trusted recovery. A trusted recovery ensures that security is not breached when a system crash or other system failure occurs. You might recall that the Orange Book requires a system be capable of a trusted recovery for all systems rated B3 or A1.
Trusted Paths
A trusted path is a communication channel between the user or the program through which he is working and the trusted computer base. (Chapter 7, “Security Architecture and Design” covers TCB.) The TCB provides the resources to protect the channel and prevent it from being compromised. Conversely a communication path that is not protected by the system’s normal security mechanisms is called a covert channel. Taking this a step further, if the interface offered to the user is secured in this way it is referred to as a trusted shell.
Input/Output Controls
The main thrust of input/output control is to apply controls or checks to the input that is allowed to be submitted to the system. Performing input validation on all information accepted into the system can ensure that it is of the right data type and format and that it does not leave the system in an insecure state.
Also secure output of the system (printouts, reports, and so on). All sensitive output information should require a receipt before release and have proper access controls applied regardless of its format.
System Hardening
Another of the ongoing goals of operations security is to ensure that all systems have been hardened to the extent that is possible and still provide functionality. The hardening can be accomplished both on a physical and logical basis. Chapter 11, “Physical (Environmental) Security,” covers physical security of systems in detail. From a logical perspective
• Remove unnecessary applications.
• Disable unnecessary services.
• Block unrequired ports.
• Tightly control the connecting of external storage devices and media if it’s allowed at all.
Vulnerability Management Systems
The importance of performing vulnerability and penetration testing has been emphasized throughout this book. A vulnerability management system is software that centralizes and to a certain extent automates the process of continually monitoring and testing the network for vulnerabilities. These systems can scan the network for vulnerabilities, report them, and in many cases remediate the problem without human intervention. Although they’re a valuable tool in the toolbox, these systems, regardless of how sophisticated they might be, cannot take the place of vulnerability and penetration testing performed by trained professionals.
IDS/IPS
Setup, configuration, and monitoring of any intrusion detection and intrusion prevention systems are also ongoing responsibilities of operations security. Many of these systems must be updated on a regular basis with the attack signatures that enable them to detect new attack types. The analysis engines that they use also sometimes have updates that need to be applied.
Moreover, the log files of systems that are set to log certain events rather than take specific actions when they occur need to have those logs archived and analyzed on a regular basis. Spending large sums of money on software that gathers information and then disregarding that information makes no sense whatsoever.
Chapter 2, “Access Control,” discusses IDS and IPS in detail.
Monitoring and Reporting
Hopefully by now it is obvious that monitoring and reporting on the findings is another of the day-to-day responsibilities of operations security. Some key issues to keep in mind are:
• Reduce the data collected when monitoring as much as possible and still satisfy requirements.
• Ensure that report formats reflect the technical level and needs of the audience.
Antimalware/Antivirus
Finally, all updates of antivirus and antimalware software are the responsibility of operations security. For more detailed coverage of these procedures see Chapter 5.
Exam Preparation Tasks
Key Topics
Review the most important topics in this chapter, noted with the Key Topics icon in the outer margin of the page. Table 8-2 lists a reference of these key topics and the page numbers on which each is found.
Complete the Tables and Lists from Memory
Print a copy of the CD Appendix A, “Memory Tables,” or at least the section for this chapter, and complete the tables and lists from memory. The CD Appendix B, “Memory Tables Answer Key,” includes completed tables and lists to check your work.
Define Key Terms
Define the following key terms from this chapter and check your answers in the glossary:
operations security
need-to-know/least privilege
separation of duties
job rotation
information assets
redundancy
fault tolerance
RAID 2
Storage Area Networks (SAN)
Hierarchical Storage Management (HSM) system
data purging
remanence
Mean Time Between Failure (MTBF)
NAS
trusted path
Review Questions
1. Which of the following refers to allowing users access only to resources required to do their job?
a. job rotation
b. separation of duties
c. need-to-know/least privilege
d. mandatory vacation
2. Which of the following is an example of an intangible asset?
a. disc drive
b. recipes
c. people
d. server
3. Which of the following is not a guideline for securing hardware?
a. Change all default administrator passwords on the devices
b. Use Telnet rather than SSH
c. Limit physical access to these devices
d. Manage critical system locally
4. Which of the following is also called disk striping?
a. RAID 0
b. RAID 1
c. RAID 2
d. RAID 5
5. Which of the following is also called disk mirroring?
a. RAID 0
b. RAID 1
c. RAID 2
d. RAID 5
6. Which of the following is comprised of high-capacity storage devices that are connected by a high-speed private (separate from the LAN) network using storage specific switches?
a. HSM
b. SAN
c. NAS
d. RAID
7. Which of the following uses a method such as degaussing to make the old data unavailable even with forensics?
a. data clearing
b. data purging
c. remanence
d. data duplication
8. A backup power supply is an example of ____________.
a. SLAs
b. MTBR
c. redundancy
d. cardinality
9. Which of the following describes the average amount of time it will take to get the device fixed and back online?
a. MTBF
b. MTTR
c. HSM
d. SLA
10. Which of the following is not a step in incident response management?
a. detect
b. respond
c. monitor
d. report
Answers and Explanations
1. c. When allowing access to resources and assigning rights to perform operations, the concept of least privilege (also called need-to-know) should always be applied. In the context of resource access that means that the default level of access should be no access. Give users only access to resources required to do their job, and that access should require manual implementation after the requirement is verified by a supervisor.
2. b. In some cases among the most valuable assets of a company are intangible ones such as secret recipes, formulas, and trade secrets.
3. b. Rather than Telnet (which sends commands in clear text) use an encrypted command line tool such as Secure Shell (SSH).
4. a. RAID 0, also called disk striping, writes the data across multiple drives but although it improves performance its does not provide fault tolerance.
5. b. RAID 1, also called disk mirroring, uses two disks and writes a copy of the data to both disks, providing fault tolerance in the case of a single drive failure.
6. b. Storage area networks (SAN) are comprised of high-capacity storage devices that are connected by a high-speed private (separate from the LAN) network using storage specific switches.
7. b. Purging renders information unrecoverable against laboratory attacks (forensics).
8. c. Failures of physical components such as hard drives and network cards can interrupt access to resources. Providing redundant instances of these components can help to ensure a faster return to access.
9. b. The Mean Time to Repair (MTTR) describes the average amount of time it will take to get the device fixed and back online.
10. c. The steps in incident response management are
1. Detect
2. Respond
3. Report
4. Recover
5. Remediate
6. Review