
Chapter 11. Building Secure Systems
“All through that century, the human race was drawing slowly nearer to the abyss—never even suspecting its existence. Across that abyss, there is only one bridge. Few races, unaided, have ever found it. Some have turned back while there was still time, avoiding both the danger and the achievement. Their worlds have become Elysian islands of effortless content, playing no further part in the story of the universe. That would never have been your fate—or your fortune. Your race was too vital for that. It would have plunged into ruin and taken others with it, for you would never have found the bridge.”
Karellen in Childhood’s End
—ARTHUR C. CLARKE
Basic technologies are all well and good, but what we really want are systems—and, if you’re reading this book, secure systems. Systems security comprises four very different aspects: good basic technologies (the subject of Part II), correct coding, proper design, and secure operation. All of these are necessary; a weakness in any can spell disaster. I’ve already covered the most important basic technologies. Entire books can be and have been written about correct coding; accordingly, I’ll just touch on it. I’ll spend more time on system building and its close cousin evaluation—how do you put the various pieces together?—though that’s really a topic big enough to merit its own book. Finally, I’ll discuss secure operation, a vital topic usually lumped under the headings of “simple system administration” or those “!@#$%![]() [l]users.” There’s more to both of those topics; I’ll cover those, too, in subsequent chapters. As always, the stress is on how to think about the problem; other than the fundamental limitations of human beings, the specifics will vary over time but the basic problems remain.
[l]users.” There’s more to both of those topics; I’ll cover those, too, in subsequent chapters. As always, the stress is on how to think about the problem; other than the fundamental limitations of human beings, the specifics will vary over time but the basic problems remain.
It is important to remember, of course, that there are no foolproof recipes for security. No matter how good you are nor how carefully you follow my advice, you can still experience a failure. In other words, a good design includes consideration of how to limit the damage from any single breach.
11.1 Correct Coding
There are many books and papers on how to write correct, secure code; I don’t propose to recap them or replace them here. Let it suffice to say that the usual advice—avoid buffer overflows, sanitize your inputs, watch out for cross-site scripting errors, the usual seemingly endless list—is sound. A few points are worth stressing, however.
The first is that the threat model—the kinds of bugs that can be exploited, or defenses bypassed—is not static. Once upon a time, if you’d offered defenders “canaries” to protect against stack-based buffer overflows [Cowan et al. 2003] and made data space non-executable, everyone would have exclaimed, “Problem solved!” Of course, it wasn’t. Heap overflows are exploitable, too, and things like return-oriented programming (ROP) [Pappas 2014; Shacham 2007] showed that there are other attack techniques possible. No one in the security field is betting that there aren’t more that no one has bothered to discover yet.
The “solution” sounds simple: write correct code. Of course, it’s neither simple nor even feasible, which is why I put the word in quotes. Nevertheless, it’s a goal to aim for, which in turn means that anything that improves correctness improves security. This includes the whole panoply of software engineering processes, with all that implies: design documents, design and code reviews, unit and system tests, regression tests, and so on.
Those techniques alone won’t solve the problem, though, because many security requirements are quite different than the usual. Take “tainting”: the concept that input from an untrusted source must not be used to do certain things without certain context-specific checks. It certainly makes sense, but how this should be done is heavily context-dependent. Let’s consider the differences between web servers and mailers.
Both have to watch out for problems, but the problems can differ, even when they’re addressing the same underlying issue. One favorite example—favorite because programmers still get it wrong, even though it’s been recognized as a problem for decades, is the “..” problem: filenames that contain enough ‘/../’ strings to move up the tree beyond the nominal base for that activity. How you achieve this, though, is very different; accordingly, the specific rules programmers must follow (and hence the specifications for the application) will vary.
For web servers, all files must be under a directory known as the document root. Avoiding too many instances of /../ sounds simple, but it isn’t. For one thing, some instances are correct practice in setting up web sites, which means that they must be accepted and processed correctly; something like html/../art/pic.jpg should be rewritten as art/pic.jpg; however, html/../../docroot/art/pic.jpg is invalid, even if it would ultimately point to the same file. There are also the myriad ways to represent /, such as %25 and —to say nothing of all of the Unicode characters that look like a /, such as ߼, which is technically the “fraction slash” rather than the more usual “solidus.” (If that’s not bad enough, imagine a Unicode-encoded URL that includes something like iana.org<fractionslash>othernastystuff.com, which can easily be mistaken for something really on the iana.org web site rather than on othernastystuff.com.)
The problem with mail is more subtle. It’s not so much people sending email directly to files, since that’s easy to handle simply by checking inbound messages against the list of legal recipients (few computers will accept messages for /etc/[email protected] or even smb/../../etc/[email protected]) as it is the ability on some systems for users to specify a filename to receive their own email. That is, I can (sometimes) say that mail for me should be written to /home/smb/funky-mail. That sounds simple, too; the mailer should simply permit writing to files that I have write permission for. It isn’t; I’ll skip the details (again, this isn’t a book on secure coding), but in a very similar situation the Apache web server does about 20 different checks.1 A useful simplification, then, might be to allow delivery to any files below /home/smb, but that in turn brings in the .. problem. (Bonus points to all readers who spotted the other very serious security problem inherent in that very bad idea. Don’t do this without a lot more care; it doesn’t do what you want.) There’s a lot of security complexity here no matter how you slice it, but given that /../ adds to the conceptual workload and that there aren’t strong reasons to permit it, it’s not at all unreasonable to bar it in this situation.
1. “suEXEC Support,” http://httpd.apache.org/docs/2.4/suexec.html.
There’s one more variant worth mentioning: an FTP server. Those typically log users in, and then rely solely on the access controls of the underlying OS. Because of the way in which the login takes place, it’s more similar to an ordinary user login than a mailer is, which simplifies things; accordingly, FTP servers don’t even have to consider the issue—unless the server supports pattern-based access control (some do), in which case the situation is similar to but simpler than for web servers.
We can see, then, that the proper handling of this string is very much context and specification dependent. A simple set of rules is in fact simplistic.
What programming language you use probably matters, too. C is notorious for its susceptibility to buffer overflows, uncontrolled pointers, and more; using a more modern language would eliminate whole classes of problems. Clearly, this is the right thing to do.
Or is it? It turns out that scientific evidence for this proposition is remarkably hard to come by. A 1999 National Academies study noted [Schneider 1999]:
There is much anecdotal and little hard, experimental evidence concerning whether the choice of programming language can enhance trustworthiness. One report [Computer Science and Telecommunications Board 1997] looked for hard evidence but found essentially none. Further study is needed and, if undertaken, could be used to inform research directions in the programming language community.
The cited report discussed many studies, but there were always confounding factors that called the results into question.
There’s another factor to consider: are these modern languages too complex? Remember Hoare’s warning about Ada, which was being adopted as the standard programming language for US Department of Defense projects [1981]:
The next rocket to go astray as a result of a programming language error may not be an exploratory space rocket on a harmless trip to Venus: It may be a nuclear warhead exploding over one of our own cities. An unreliable programming language generating unreliable programs constitutes a far greater risk to our environment and to our society than unsafe cars, toxic pesticides, or accidents at nuclear power stations. Be vigilant to reduce that risk, not to increase it.
On balance, most security people feel that moving away from C and C++ is probably the right answer, but the answer is less clear-cut than I’d like.
Ultimately, perhaps Brooks’ analysis was the most accurate [1987]:
I predict that a decade from now, when the effectiveness of Ada is assessed, it will be seen to have made a substantial difference, but not because of any particular language feature, nor indeed of all of them combined. Neither will the new Ada environments prove to be the cause of the improvements. Ada’s greatest contribution will be that switching to it occasioned training programmers in modern software design techniques.
Training, though, is an important part of process as well: programmers do need to be taught how to write correct, secure code.
Virtually everything I’ve just described, with the exception of some of the requirements, applies to all large-scale software development projects. Security, though, is different; there are malicious adversaries. In ordinary code, one can say “no records are longer than 1,024 bytes” and not worry. In security-sensitive code, though, that’s a recipe for disaster; attackers will happily construct longer records for the precise purpose of overflowing your buffers if you’re not careful. How do you know if you’ve been careful enough?
C, of course, is part of the problem. Since strings do not have explicit length fields, many string functions—copying, comparison, and more—come in two forms, such as strcpy() and strncpy(); one uses the conventional zero byte delimiter and one takes an explicit length as well. Passing lengths around everywhere isn’t always convenient, especially in old code that’s been updated over the years; is it ever safe to use functions like strcpy()?
It is perhaps unfortunate that the answer is “yes”: sometimes, they are safe as well as convenient. If the answer were “no,” they could be deleted or flagged with bloodthirsty warnings by the compiler, much as gets() is. If the program has already verified that the string lengths are safe, or if the input comes only from trustworthy sources like a sysadmin-specified file, there’s no strong reason not to use these functions. The problem is how to tell the difference, and in particular how to audit your code.
I took a very quick look at the source to a recent version of the Firefox web browser. By actual count of the lines emitted by fgrep -wR I found 303 instances of strncpy() and 735 instances of strcpy(). Does that imply that Firefox is terminally insecure? Probably not; most of those instances will be false positives—but that’s an awful lot of code to review by hand.
Beyond that, there are many common errors that cannot be detected that way. The simplest example is a type mismatch between modules, which is especially easy to do in C. Another example is the difficulty of taint analysis: given how a variable can be referred to directly or via a pointer, determining where something came from is very difficult.
The answer is to use a specialized static analyzer, a program that looks at programs and finds certain classes of mistakes. Static analyzers are old—lint dates back to the 1970s [S. C. Johnson 1978]—but newer ones are much more comprehensive. If nothing else, they’ve been tuned to detect security-sensitive misbehavior.
This book is not the place for a comprehensive discussion of such programs. (If you’re interested, I recommend [Chess and West 2007; McGraw 2006]. Microsoft has developed many tools that can cope with systems as large as Windows or Office [Ball et al. 2004; Larus et al. 2004].) I will note three caveats about using them:
• Static analyzers aren’t panaceas. Bad code is bad code, and creatively bad programmers can outwit the best tools. (Chess and West’s book also gives a lot of very sage advice on mistakes to avoid.)
• Vulnerabilities—in this context, that means programming errors—increase all the time. Newly discovered attacks, new operating environments, and new languages will all have their quirks; code that was once effectively safe can become unsafe. Consider format string attacks, which were completely unknown before around 1999. Old code has to be revisited with newly updated tools.
• Static analysis is just one more part of the development process, along with code reviews, testing, and so on. Simply having a tool, or using it casually, will not suffice. Again, process matters.
There’s a reason, then, that this section is named “Correct Coding” rather than “Correct Programming”: the problem is far deeper than just writing the programs.
11.2 Design Issues
Let’s start our discussion of security design principles by considering a typical—but simplified—example: a modern web server. Major sites’ web servers today don’t serve static files; rather, they’re controlled by content management systems, which in turn are database driven. That is, a reference to a page will generally invoke a script that processes a template for the page; the template, in turn, will contain database references and/or invocations of other scripts. The database will contain structured files for all of the content: the title and actual text of the requested page, information about other links to show on that page (“most e-mailed,” “trending,” video or audio adjuncts, and so on), related content, and more. For that matter, the database will likely contain information about users, the kinds of ads they should receive, and more.
Figure 11.1 shows the layout of a typical high-end web server. There are several points about it worth noting. First and foremost, all of the major components are replicated; this is done for reliability and load sharing. There are two border routers, each perhaps homed to a different ISP. There are multiple web servers, each fed by load balancers. There are multiple databases; here, some of the separation is likely because of different roles and access characteristics. Even the networks are replicated; no single failure should be able to take this site off the air.
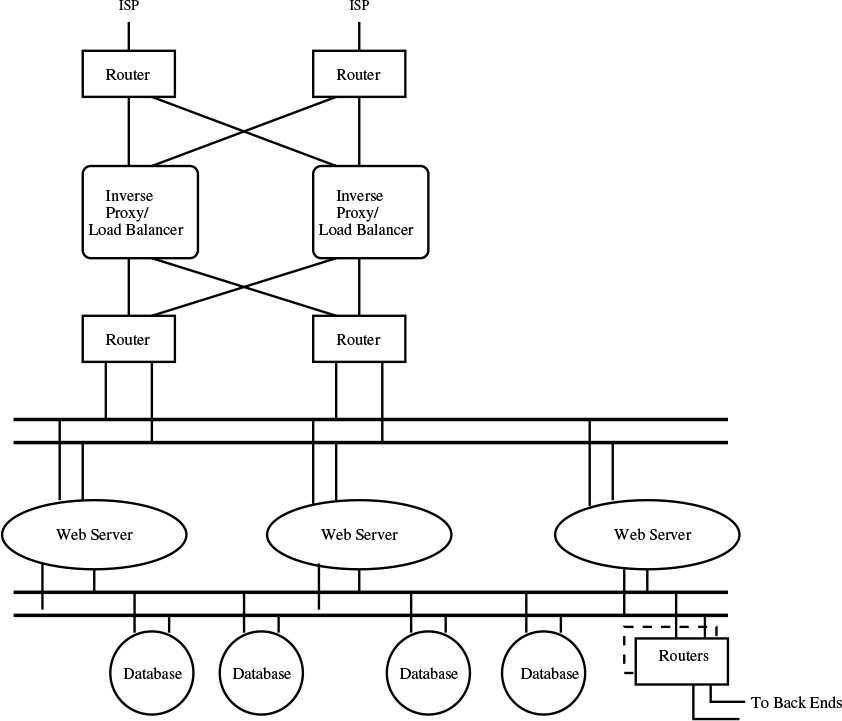
Figure 11.1: The layout of a typical web server and its associated databases.
The second point worth noting is the inherent security in the design. The load balancers, which are also inverse proxies, feed only ports 80 and 443 through to the web servers. They’re not intended as firewalls per se; nevertheless, they function as such. Similarly, an attacker who has somehow compromised the load balancers or the routers on either side of them still can’t get to the databases; the web servers are just that, web servers, and they don’t route IP packets between their “north” and their “south” Ethernets.
The third thing we notice is that “minor” link in the southeast to “back ends.” That’s probably the most dangerous part of the system as shown, unless there are strong security protections between the web servers and databases and these undescribed back-end systems.
The fourth item is that the diagram is seriously flawed; there are many more vital functions that can’t be integrated into this scheme without breaking the nice security properties I just outlined. Note carefully what I’m saying: it’s not that I’ve omitted details (that’s inevitable in such a high-level view); rather, it’s that when you add in some of these details, a lot of their security properties are inherently compromised.
The most obvious problem is the network operations center (NOC): how does it talk to the various pieces? It has to be able to talk to the north routers, the load balancers, and the routers in the middle; there are also the switches on either side of the web servers. Where do you connect the NOC? There are no locations on the diagram capable of talking to all of those network elements; if we introduce one, we’ve bypassed one of the protection layers. A NOC station that can talk to the two pairs of LANs provides a path to the database servers that bypasses the web servers; something that can talk to the outside routers and the inside ones is a path around the load balancers.
Access by network, system, and web administrators poses similar issues. It’s easy enough to see how the database and web server machines can be contacted via the back-end routers, but someone has to be able to maintain and reconfigure the network elements in the north half of this diagram. Perhaps that’s done via a separate management LAN (a solution that might also help the NOC)—but again, that bypasses the protection of the proxy servers.
There are many more machines missing from this diagram; connecting them poses its own challenges. Where do the customer care systems connect? They need pervasive access to the databases, so presumably they should be on the south LANs—but customer care is often outsourced or done by teleworkers. In fact, there may be many other external links to just this complex: suppliers, banks, shipping companies, external web designers, content suppliers, and more. I’ll deal more with external links in Section 11.3; for now, let it suffice to say that such links raise another issue that needs to be considered.
Customer email presents a fascinating challenge. All email to and from customers—including delivery status and failures of outbound email—needs to be logged in a database for the use of customer care. The mail servers need not be in the same data center, but they either need to access the same databases, with all the security challenges that implies, or the separate databases they do use must be accessible to customer care and somehow linked to what is done via the web servers.
There are many more types of access needed: (tape?) backup machines, along with the interfaces needed to restore files; the backup data center, which may be on the other side of the planet but needs up-to-the-minute databases; the console servers; the environmental sensing and control networks (if your machine room gets too hot, you really want to shut things down); your authentication server, which in turn should probably be linked to your personnel machines so that they know whether an employee has left the company—the list goes ever on. A few years ago, I looked at the high-level schematic for a large company’s billing system. It had four different databases and 18 other processing elements. One of those databases held the sales tax rates for every relevant jurisdiction; that, of course, implies a real-time link to some vendor who is responsible for tracking changes in rates and rules, and updating the database as needed. Real-world systems are infinitely complex—and if someone shows you a diagram without such complexity, the proper response is “what aren’t you showing me?”
Security people don’t get to pick what functions exist, nor do they decide which are handled in house and which are outsourced. We do, however, have the responsibility of securing it all, even when the rest of the organization decides to change things around.
11.3 External Links
Out of all design issues, the most difficult is external connectivity: the many, many links to other companies. Make no mistake about it: there are very many links. I once asked a top network security person at a major American corporation how many authorized links there were to other companies: “at least a thousand.” And how many unauthorized links did he think existed? “At least that many more.” These links exist not because of carelessness or lack of security awareness; rather, they’re there because they’re necessary for the business. As such, the security question is not whether they should exist, but how to secure them. You’ll occasionally win a fight on that issue; more often, you’ll not just lose, you’ll be shunted aside as someone who doesn’t understand the business.
How should external links be secured? Many people’s immediate reaction is to say, “Set up an encrypted VPN from the outside company to our network.” It’s not a bad suggestion, and I’d likely include it among my own recommendations, but let’s take a deeper look at it: why should you encrypt this link, and what does it cost? For that matter, we should look more closely at just how the encryption should be deployed.
Encryption protects against eavesdropping; it also provides authentication of received packets. Who, though, is going to engage in such activities? In a business-to-business connection, both ends have dedicated connections to their ISPs. Eavesdropping on either the access links or ISP backbones isn’t easy. The Andromedans can do it; few others are capable of it. Put another way, if your threat model includes surveillance by intelligence agencies, encrypting such links is vital. That’s by no means a preposterous concept, but it’s also not a universal threat model. VPNs are cheap and easy—but if they’re problematic in your environment for some reason, it’s worth thinking hard about who your enemies are. Hold on a moment, though, before you rip out your crypto: there are two more things to consider.
I’ll defer discussing one until the end of the section, but I’ve already alluded to the other: cryptography can authenticate packets without relying on the source IP address. Again, this goes back to threat models: who is capable of forging addresses? Although it’s still a sophisticated attack, it’s much easier than eavesdropping. One mechanism is a routing attack: someone announcing someone else’s IP addresses via BGP. It’s rare but feasible; there have been reports of spammers doing it [Ramachandran and Feamster 2006; Vervier, Thonnard, and Dacier 2015] and an apparent Bitcoin thief [Greenberg 2014; Litke and Stewart 2014], and I’ve heard of other incidents from Reliable Sources. Another way to do it is by attacking the DNS, either directly via a cache contamination attack [Bellovin 1995; Kaminsky 2008] or by hijacking a site’s DNS records via their registrar [Edwards 2000]. Note that these would be targeted, reasonably sophisticated attacks; we’re into the upper right quadrant of our threat matrix, though not all the way to Andromeda.
The more mundane threats demand more of our attention. The real risk is that you’re letting others inside your network: what can they do, and what can you do to protect yourself? The answer is very much context dependent, but there are some standard approaches.
The most obvious, if you can do it, is to apply firewall rules to the interconnection. That is, restrict what hosts and services of yours the external machines can reach. Note that there may be a conflict between your cryptography and the need for firewalling: you can’t filter IPsec-protected traffic based on actual destination addresses and port numbers, so that has to be done after decryption or integrated with it.
A problem, though, is that the resource of yours being accessed is still vulnerable; if it is penetrated, the rest of your network is at risk. Thus, and if the threat model so indicates, a more interesting way to approach the solution is what I call the shared enclave model: walling off the resource behind a firewall, a firewall that protects the rest of the company from the enclave. This is shown in Figure 11.2. The main corporate firewall permits the external traffic into the corporate network, but only to the internal VPN gateway. The traffic then passes through the second firewall to the decryption gateway; from there, the actual resource can be reached.
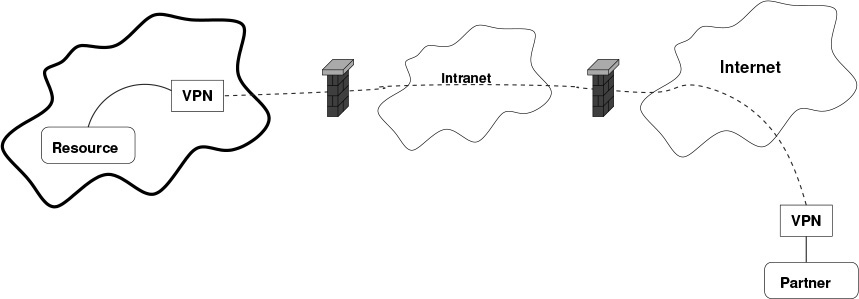
Figure 11.2: A shared enclave: an internal firewall protecting the rest of the organization from externally accessible partners that may have been penetrated.
Note the problem: how does the rest of your organization reach it? The answer, of course, is to have special rules on that internal firewall permitting such access. What are the necessary types of access? Obviously, that’s somewhat situation dependent, but it’s clear that essentially, we’ve more or less replicated the configuration shown in Figure 11.1, and hence all of the problems that go with it. That’s not to say that this is a bad idea; however, it comes at a cost.
There’s another reason to adopt shared enclaves: your partner may insist on it. After all, if you set up a VPN, your partners are vulnerable to attacks from your side. (Yes, I know that your firewall’s strength is as the strength of ten firewalls because your hearts are pure, but your partners may not realize this.) Enclaves limit which of your employees have access to the VPN and hence have the ability to endanger your partner.
Taking this one more step, you may need to insist on an enclave architecture at their end, for the same reason. Even if you trust their honesty, do you trust their competence at network security? After all, it is highly unlikely that your site is the only external connection they have. Unless there are further protections, you’re exposed not just to your partners but to all of the other companies to whom they talk, ad infinitum. There’s a word for this sort of transitive closure of connected networks: the Internet.
Note how we derived the shared enclave architecture. It came from a combination of three factors: the resource to be protected, a threat model that assumed that the computer hosting this resource might be penetrated, and (to some extent) a need to protect the partner organization from other failures within your site. The second factor is the most crucial here: if your shared resource, perhaps a special-purpose web or database server, is strongly enough protected, you don’t need the extra layers of protection. If it may be weak, or if it is very exposed to the outside (perhaps you’re a big wholesaler and it’s handling orders from a very large number of retail outlets), a stronger security posture is indicated.
Sometimes, partners need to access far more than a single cluster of easily segregated servers. I know of one situation where a company was legally compelled to engage an outside auditing firm to check on certain classes of transactions. This firm therefore required access to a fair number of internal databases: the data architecture had of course not been designed without outside auditing in mind, so information was scattered hither and yon. How should this be handled?
Again, we go back to our threat model: how much do you trust the outside firm? If they’re honest and competent, a simple set of firewall rules will suffice. That is, create an access control list that allows this outside company to reach some set of database servers within your network. (See the box on page 218.) Use standard database facilities, such as GRANT and VIEW, to limit what parts of the database they can see. If they’re honest but perhaps not competent enough, the right solution might be an enclave on their side, not yours. How do you enforce that? You enforce it the same way you enforce many other things in the real world: by a contract with suitable penalty clauses, rather than just by technology.
If that isn’t sufficient protection, the best approach is often an application gateway. The obvious starting point is an SQL proxy that filters out dangerous things, per Figure 2.1. It then implements a federated database [Josifovski et al. 2002], which treats multiple independent databases as a single one. Again, the standard SQL restriction mechanisms can and should be used. More specifically, use them to restrict what this proxy can reach; this provides some protection against database access control implementation flaws since the outside party can’t even reach the actual databases.
Again, note that the proper design is driven by resource and threat models. If the resource is extremely valuable or the threat is great, stronger protections are indicated. Often, though, ordinary commercial practices will suffice.
11.4 Trust Patterns
As noted, the criteria used to select different protection schemes are resource value and threat model. What, though, makes the different schemes more or less secure? Why does a shared enclave give more protection than a set of firewall rules? Why do all of the necessary but missing connectivity requirements in our model web server complex hurt security? The answer to these questions—trust patterns—is at the heart of how one designs secure systems.
What do I mean by trust patterns? Who talks to whom? Who can talk to whom? What might they do? What do you trust them to do and to which other machines, all modulated by the strength of any security controls that are applied?
Let’s consider a simple case and a variant: two hosts, A and B, on a network, and the same two hosts separated by a firewall that permits only port 80 to pass from A to B. What is the difference? If B trusts that A will only try to connect to port 80 on B—and not to any other port, nor to any port on host C—there is no difference, and the firewall is irrelevant. If B does not have that much trust in A, whether because A has nasty tendencies or because B thinks that A might be penetrated by nasty outsiders, the firewall enforces B’s trust assumption: that the only connections that A will make will be to B:80.
We see here two essential design and analysis principles: that a system design can make certain assumptions about what will happen, and that external components can be used to enforce those assumptions. We can see this in some of the design alternatives discussed earlier. Let’s revisit Figure 11.1 from this perspective; in particular, let’s consider the effects of the existence of a NOC that has to be able to speak directly to each network. There are two essential security assumptions here: that the web servers will only be contacted on ports 80 and 443, and that there’s no way to reach the database servers without going through the web servers. The former property is enforced by the reverse proxies, and the latter by the topology of the configuration.
The existence of the NOC invalidates both assumptions: there is now a path to the web servers that does not pass through the proxy servers, and there is a path to the database servers that does not go through the web servers. These violations do not inherently render the configuration insecure; however, they force us to take a deeper look. The original design required that the web servers trust the proxy servers and did not require any trust assumptions by the database servers. Now, we require an additional two assumptions: that the NOC itself will not attempt improper connections (and “improper” may have a more complex meaning), and that the NOC is itself sufficiently secure that it does not create a bypass path for attackers.
The former assumption is probably safe. If your NOC engineers can’t be trusted, you probably have bigger security problems. (Can they be trusted? See Section 16.3, on logging, for precautions you can take.) The more interesting questions are whether the NOC machines are secure enough, and what to do if they’re not.
Roughly speaking, a computer can be penetrated in one of two ways: either there’s a flaw in something that’s listening to (i.e., reachable via) a network port, or the user of the computer has inadvertently downloaded something dubious. Standard Windows and Mac OS X boxes tend to be listening to too many ports out of the box to be high assurance. They may very well be secure, but you don’t know that; some form of remediation is indicated. (How to prevent external connections to those ports can be a bit tricky, since the operational needs of a NOC tend to conflict with standard firewalls, but the details of what to do are out of scope for this book. For now, let it suffice to say that it can be done.) Inadvertent downloads can be dealt with both by policy—“Thou shalt not browse the web from thy NOC console”—or by technology: delete all browsers from those boxes. If you can’t delete the browsers because they’re needed to configure or monitor certain things, force all browsing to go through a proxy that enforces your rules and logs exceptions.
To sum up: analysis of the more realistic server complex configuration shows that there are additional nodes and paths that have to be trusted. These may not be not fully trustable; however, with a bit of extra work we can achieve high-enough levels of security.
What did we do here? The essence of the analysis was looking at who could talk to whom, and deciding whether a simple connection was secure enough. Depending on the situation—the resources being protected, the threats, the topology, and the inherent properties of the systems and configurations—we may need to take actions and/or add components to ensure security.
Let’s make another change to the topology and to the threat model and see what happens. Suppose that one of the databases is at a remote location. That is, instead of the database server being connected to the two south LANs, we instead have a router with a direct link to another router at some other site; at that site, we have another LAN with our database server. (For simplicity, I’ll omit the reliability aspects of this variant, but of course there would be lots of replication.) How does this change our security analysis?
To a first approximation, it doesn’t; we only have to assume that the new routers and links are secure. However, there are two potential issues. First, we need high assurance that the other site is indeed secure and that there is no way for other machines at this site to gain access to the distant database. Second, I noted the need to assume that the links are secure—but if your enemy is a major government, that may not be a valid assumption [Timberg 2013].
Encryption is the solution to both issues, but how we deploy it may differ. If the only risk is from the Andromedans, a link encryptor will suffice. On the other hand, if you’re worried about what’s going on at your remote site (and you probably should be, since it’s distant and you have to rely on the sysadmins there), you probably want something like the enclave strategy discussed above, with a VPN link to it. (Fairly obviously, if you’re not worried about governments but are worried about remote configurations, an unencrypted tunnel to the enclave will suffice—but using encryption won’t hurt, and it will protect you if you’ve gotten the threat model wrong.)
When analyzing trust patterns, what is a node? There is no simple answer; it can be a process, a computer, or some combination of the two. Ideally, it is just a process; however, the analysis has to include the risks of privilege escalation attacks by that process should it be subverted, other active processes on the machine that may be penetrated via network activity, and so on. Similarly, defenses include file access permissions, sandboxes, virtual machines, and other host-centric concepts. Security and especially insecurity are systems properties; looking too narrowly is a classic mistake.
11.5 Legacy Systems
For all my fine words about design, I’ve been quite silent about one very ugly subject: legacy systems. There are very few greenfield designs in this business, ones where you get to build everything from scratch. We rarely have that luxury. There’s often some Paleolithic mainframe off in a corner somewhere, one that contains a database vital to the project, but you can’t talk to it securely because there are no COBOL implementations of TLS. What then? As it turns out, our analytic tools still work, but there will generally be more need for additional components.
Again, we start by assessing trust patterns. Do we trust the legacy systems or the path to them? Not infrequently, the answer to both questions is “no”; however, you will have neither the budget nor the time nor the authority to touch the systems. (Even if you had unlimited budget and authority, “do not touch” is probably the right answer. If you tried to rewrite every legacy system your project relied upon, the resulting disaster would make a lovely case study for a software engineering class. The system would end up far too large and far too complex to even work.) The best you can do is treat the legacy systems the way you would other unpleasant but necessary components (such as the NOC): they exist, you have to talk to them, and they have certain immutable properties. Your job is to engineer around the potential insecurity.
The best answer, in general, is a front end or proxy that you control. This box, which has known and acceptable properties, is the only one allowed to talk or listen to the legacy system. In essence, it’s a proxy firewall that provides protection in both directions. It’s not unreasonable to add some extra functionality, such as syntactic transformations like converting from XML to a punch card-oriented format, but that should be done with care: adding too much extra complexity to a security box always weakens it. Bear in mind, though, that this sort of conversion still has to be done somewhere. This is a difficult architectural decision: is this a legacy system interface box, a security gateway, or both? There are sound reasons for saying “both,” but that in turn implies a need for care in just how this box is implemented. Should technologies like sandboxing be used?
There is one important disadvantage to this proxy strategy: information is lost. Specifically, the legacy system no longer has authoritative information on who initiated particular transactions; this affects both access control and logging. It is tempting, in some instances, to let the proxy impersonate individual users, but that may be infeasible or have other bad side effects. For one thing, how does the proxy server get the credentials to impersonate users? For another, the legacy system may not be designed for that many logins; O(n2) algorithms are perfectly acceptable when n is small but not when it’s far larger than anyone had ever anticipated. Consider, say, a payroll system. Back when the world was young and punch cards walked the earth, employees probably filled out paper time sheets; these were sent to the keypunch pool and the resulting card decks were fed into the system. No logins were necessary. A tech generation later, departmental administrative folk would have something like an IBM 3270 terminal for interactive entry; at this point, logins and passwords would have been added, but only one per department. In today’s world, of course, every employee would do it, via a web browser or a special smart phone app. That’s at least an order of magnitude more users; can the system handle it?
From an access control perspective, the answer is to give the proxy full permissions on the mainframe’s database. This, though, hurts logging (Section 16.3): the mainframe no longer knows and hence can no longer record the actual userid that initiated a particular transaction. This isn’t good, but it is an inevitable consequence of what is often an unavoidable course of action. The only solution is to do copious logging at the proxy, with—if possible—enough information to permit automated correlation of the proxy’s log file entries with the legacy system’s.
11.6 Structural Defenses
There is a remarkable but subtle theme running through the last three sections: the designs we encounter are driven much more by application logic than by threat model. That is, the interconnection of web servers, database machines, service hosts, and so on is largely independent of what enemies might try to do. A high-end web site has a database because that’s the best way to build the web site; it has nothing to do with the desire to separate a more critical resource from the highly exposed web server. The threat model comes into play when we decide what defenses to put in different spots: encryption, packet filters, hardened hosts, and more. Can we do better? We can, if we divide the logic differently and build the databases in a fashion that reflects the threats.
Let’s consider an e-commerce site where the primary threat is high-end, targeted criminal activity. That is, the design is not intended to counter the Andromedans; rather, it’s dealing with folks who just want money. There are three primary threats: theft of credit card numbers, fake orders to be delivered to a hacker-controlled address, and the financial and PR loss to the company if customer personal data is stolen. A common response to a data breach is for the affected company to pay for credit monitoring for the affected people. It’s hard to say how much that costs per person, but it seems to be about $5 [Burke 2015]. That is not a trivial amount of money for most companies. Let’s take the threats one at a time.
From this analysis, it is clear that the biggest threat is to the databases and in particular to their contents. That is, our protections should focus on certain fields; other components, such as the web server itself, are of much lower importance.
Credit card number theft is probably the biggest threat. If we can believe the estimates for Target’s loss [Abrams 2014; Riley et al. 2014], it cost them about $50 per card number compromised. In other words, it’s worth a considerable amount of effort to ensure that this failure never happens, no matter what else is compromised.
The first approach is to use database access controls, as outlined above, to make sure that the web server can never read the credit card number. The web server is the likely point of entry for a direct attack. If the database server itself is compromised, though, its access control mechanisms may not stand up—and the data on it is so central to business operations that it’s likely very exposed to someone who has already gained access to the corporate network. Only one computer really needs to read the credit card number, though, and that’s the one that actually sends the billing information to the bank. Accordingly, let’s use public key cryptography to encrypt the credit card numbers; only the billing computer will have the decryption key. This computer is extremely specialized, and hence can be locked down a lot more than most other machines. If it’s still too vulnerable, or if you can’t afford the public key decryptions, have a specialized encrypt/decrypt computer: the web server or the database machine can ask it to encrypt credit card numbers using, say, AES; only the billing computer can request decryptions.
There is an alternative design that merits analysis: store credit card numbers in a separate databases, one that could perhaps be locked down more tightly. While better than storing card numbers in the primary database, it’s not as good as this design. First, if the billing computer does the decryption itself, the card numbers are never exposed except at the single point where they are actually needed. Regardless of anything else, there must be exposure at this point; more or less by definition, any other scheme must be strictly weaker. Second, database servers are inherently more complex than the encryption/decryption server in the alternate scheme; probabilistically, this makes them considerably less secure. (There’s another wrinkle I won’t analyze in detail: many merchants use credit card numbers as customer identifiers; this lets them link online and offline purchases by the same person. There are a number of ways to deal with this, including using salted hashes as the identifier.)
We can use a similar strategy against the second threat: delivery to false addresses because of a database penetration. (Takeover of a user account is a separate issue.) Shipping addresses are not particularly sensitive, so they don’t necessarily need to be encrypted (but see below); however, they do need to be authenticated. The crucial point here is the encryption the key that should be used: one derived from the user’s password. More specifically, the user’s password is used as a private key for the Digital Signature Algorithm (DSA) or its elliptic curve equivalent. From it, a public key is derived and is sent to a certificate authority (CA) server. The private key is used to sign all shipping addresses; the certificate, which is stored in the user profile database, authenticates them.
Note how this works. An attacker with control of the web server or even the database server cannot create a valid shipping address. Doing that can only be done for an account that is actively shopping on the site at that time. In fact, a user would be prompted for a password any time a new shipping address is entered; this is already routinely done by some sites for high-value purchases. The crucial machine is the CA server; as with the card number decryption server in the first scenario, it is a specialized machine that can be locked down far more tightly than a database server can be.
We deal with the third problem, theft of other personal information, by encryption: we encrypt all such information with the user’s password. It is thus fully exposed to the web server when the user is logged in, but is protected otherwise. Certainly, information can be captured while a web server is compromised, but most accounts are not active most of the time.
This scheme poses a few interesting trade-offs; in particular, password reset and “big data” analysis become tricky. Let’s take these one at a time.
If user profile data is encrypted with the user’s password and that password is lost, the data is lost. There are at least two approaches to dealing with this. The first is to treat it as an advantage: one common cause of password reset is a compromise of the customer’s email account, in which case the attacker can use that account to reset passwords on other interesting accounts and thus gain access to them. Forcing the user to reenter important data, such as credit card numbers, can actually be an advantage. A second approach is to keep a backup copy of the data, encrypted with a different key. This works if the password reset server—which cannot be the web server—is the only one that can decrypt this copy. It’s a riskier approach, in that this is not nearly as simple a process as, say, the credit card number decryption server postulated earlier; still, it’s at least somewhat stronger than keeping the data in the clear all along. Is this worth it? That’s a business decision; this scheme is more costly (and not super-strong); is it worth it to avoid the customer annoyance of reentering profile data? How costly would the loss of the data you store be? (Not storing too much data can be a cost-saving measure as well as privacy-preserving.) If you don’t use separate protection for credit numbers, as outlined earlier, it would seem prudent to use this variant for them at least.
There are other business costs as well. Another sensitive item is the user’s email address; if a list of email addresses is stolen, it’s valuable to the spammers. (Email addresses were the goal of some people allegedly linked to a penetration of JPMorgan Chase [Goldstein 2015].) That suggests that it should be encrypted. On the other hand, many companies like to send email to their customers, especially those who haven’t been active lately. This may or may not be spam from the perspective of the recipient; nevertheless, very many companies perceive this as a useful (i.e., profitable) thing to do. This is a classic trade-off of security costs versus business opportunities and has to be evaluated as such, for each company’s needs.
Big data analysis is easier to deal with. The analyses of interest generally deal with a set of categories, rather than raw personal data; user data can be categorized appropriately before encryption. Consider, for example, a company that wants to match its customers against the vast stores of information accumulated by data brokers [FTC 2014]. The desired information can be extracted (and perhaps hashed) when the user is logged in; later analyses can be done against this secondary information, without reference to the cleartext identity. The problem, of course, arises when you conceive of new analyses to do, ones for which you have not previously extracted the necessary data from the plaintext record.
I call these defenses “structural” because they’re a reflection of the inherent structure of what needs to be protected. If your assets can be made to fit such a model, and if you can find ways to isolate the sensitive information while still fulfilling the primary organizational purposes, you can achieve very strong security against certain threats. However, these two “ifs” are very big ones indeed; except for passwords (which, as discussed in Chapter 7, are generally salted and hashed), this is not a common defensive approach. Often, though, that’s because it hasn’t been thought about. It should be.
11.7 Security Evaluations
For now I’m a judge
And a good judge, too
Yes, now I’m a judge
And a good judge, too
Though all my law be fudge
Yet I’ll never, never budge
And I’ll live and die a judge
And a good Judge too
Trial by Jury
—W. S. GILBERT AND ARTHUR SULLIVAN
The converse of design is analysis: given a system, is it secure? If it isn’t, where are the problems and how can they be fixed or at least remediated?
Organizations can conduct security reviews at many different points. They may be done at various points during implementation, shortly before initial customer release, during periodic audits of the IT infrastructure, or even after a breach in some other system has awakened management.
Reviews have a lot in common with initial design. There’s a business need; there are also likely some very necessary security risks. As before, while you must be honest, it’s still sometimes necessary and always difficult to say “no.” The advice on page 214 applies here, too: instead of saying, “I have a bad feeling about this,” show precisely what the problem is and how to fix things.
There is one very important difference between design and review, though. A designer has a free hand to choose different components, including for reasons as mundane as “we’ll get a better discount from vendor K if we buy more of their gear this year,” or for important but non-security reasons such as the ability to run on the −48V DC that the backup battery plant provides. (Why −48V DC? That’s an old telephone company central office standard; even today, gear intended to run in telco central offices will support that voltage. This is especially true for generic hardware such as routers and network switches.) The analyst has to work with the design as it exists, and not as he or she thinks it should have been built. The best analogy here is an architect versus the controlled demolition experts who bring us those really cool building implosion videos. Both need to understand the strength of materials, how many columns must fail to bring down a wall, and so on. The architect, though, will worry about aesthetics, the client’s budget, how the space will be used, and more; the demolition expert takes all that as a given and figures out how many explosive charges detonated in what sequence will cause the proper collapse. The exterior wall cladding, carefully selected for its color, reflectivity, and thermal efficiency, is utterly irrelevant unless its strength or other physical properties affect the amount of plastique to use.
When doing the analysis itself, the most important thing to remember is that attackers don’t follow the rules (Chapter 2). More specifically, they don’t follow your notion of what can happen; they’ll attack where they can. Always look more broadly. Consider, for example, a single node that the diagram labels “web server.” The naive approach is to look at the HTTP server itself: Apache or IIS, which version, what configuration options are supported, and so on. Those questions are necessary but are by no means sufficient. The attacker would be just as happy to use an ssh port that was left unprotected, or to penetrate the firm to which you’ve outsourced your web site design; they’ll then upload backdoored scripts using the authorized connection, which may involve FTP or something else unusual. You have to consider the computer as a whole—and if it’s a virtual machine, you have to consider the hypervisor as well.
For that reason, I’m not fond of using attack trees or other top-down methodologies for security analysis. Those start by saying “to attack X, one must first penetrate Y or Z.” Certainly, penetrating Y or Z will suffice, but that approach tends to favor known paths. Instead, go bottom-up: look at each computer, assume that it’s been compromised, and see what can happen.
I approach system security analysis by boxes and arrows—a directed graph (not a tree!)—that shows input dependencies. (This approach is similar, though not identical, to Rescorla’s “protocol models” [Rescorla and IAB 2005]. Also, see the “data flow diagrams” in [Shostack 2014].) A module with many arrows pointing to it is harder to secure because there are many avenues from which an attack can be launched; by extension, input from such modules should be treated with suspicion because it’s much more likely to have been corrupted.
The process is iterative; neither boxes nor arrows are indivisible. If, notionally, an arrow represents a TCP connection, you need to ask how that TCP connection is protected and what other TCP connections can be created. Similarly, a box labeled “web server” on a high-level diagram may in fact run a content management system based on several SQL databases.
Resist the temptation to reify such a diagram by attaching weights and penetration probabilities. There are no reliable numbers on just how trustworthy a given component is; indeed, given how heavily dependent vulnerability is to the type of attacker and the assets being protected, it’s far from clear that reliable numbers would be useful if used in a different context.
Here is where defenses come into play. First, we look at what nasty things are being prevented. Let’s go back to Figure 11.1 and assume that the web server has somehow fallen. In that diagram, the database servers are now very much at risk. What mechanisms are in place to protect them? Are there access control lists or other firewall-like mechanisms on the LANs to keep the web servers from any ports other than SQL itself? Is the database configured to restrict access appropriately? To give one trivial example, there is no reason whatsoever that a web server should be able to read a customer’s stored credit card numbers; it should only be able to write them. (If your user interface design includes the display of the last four digits of a card number, that should be a separate column, written by the web server at the same time as it writes the actual card number. How to ensure that the two fields are always consistent requires annoying but not overly hairy programming.)
It is, of course, fair to ask the chances of a particular computer being compromised. An analysis that simply says, “Very bad things will happen if Q is compromised,” but does not explain how that could happen is fatally flawed. A statement like that is at most a caution—Q must be strongly protected—but says nothing about the actual risk. This part of the analysis, assessing the strength or weakness of any given computer, is the one most dependent on the experience and judgment of the analyst; it is also the one most dependent on the abilities of the adversary. Is Linux more secure than Windows? Is Debian Linux 5.0 more secure than Windows 8.1? Does the answer change depending on the patch installation strategy, or on external protections such as packet filters? What is the reputation of installed third-party software, such as Apache or MySQL? What can a realistic attacker do with physical access to some component? There are no easy or obvious answers to even simple questions like these, let alone more difficult ones about MI-31’s stash of 0-day exploits or about attacks involving combinations of software weaknesses.
One approach to subsystem security analysis is the Relative Attack Surface Quotient (RASQ) [Howard, Pincus, and Wing 2005]. RASQ does not try to assign an absolute security value to a component; rather, it compares different designs for a subsystem to evaluate which is more secure. The evaluation is done by looking for attack opportunities along a set of different dimensions, such as open communications channels or access rights. RASQ is not a perfect solution, and it does require two or more versions of a subsystem to evaluate; still, it is useful when assessing design alternatives or changes to an existing system architecture.
Operational considerations matter, too. Recall the story from Chapter 2 about the guest login on a gateway. One can’t anticipate a chain of failures quite like that, but it’s entirely fair to ask what provisions are present for emergency access. Are they secure? I once reviewed a design that stated, “No console access except from the computer room.” That’s a lovely thought, and in the 1980s it might have been a sensible precaution. Today, though, servers live in lights-out data centers, often with no one on-site. Indeed, the actual code may run on some cloud provider’s infrastructure. What, then, is “the” computer room? And if there really is no other access, what will happen in an emergency? The system I was reviewing would have been more secure in real life if they planned ahead for secure, available console access.
You may find, if you push, that there are actually more components than are shown on the diagram you’ve been given, just as we saw when analyzing Figure 11.1. Drill down! Ask questions about such things! (But do it tactfully: don’t say, “What else are you hiding from me?” after some extra component is disclosed. . . .) It’s quite normal for system architects to show a design with only their components; the boring operational pieces are left to the data center folk who are accustomed to dealing with console servers, NOCs, and so on. Attackers, of course, don’t care about this organizational boundary.
Understanding and evaluating a system is not a simple task. Indeed, just understanding the threats is difficult; whole books (like the excellent [Shostack 2014]) have been written on the subject. The essence is to approach the questions systematically. A very high percentage of failures occur because designers or evaluators completely overlooked some aspect of the architecture, or because they underestimated the skills and resources of potential enemies. If you look at every component and every link, asking yourself who could compromise it and what the effects would be, you’re much more likely to get the right answer.