
Chapter 16. Security Process
In the Laundry we pride ourselves on our procedures. We’ve got procedures for breaking and entering offices, procedures for reporting a shortage of paper clips, procedures for summoning demons from the vasty deeps, and procedures for writing procedures. We may actually be on track to be the world’s first ISO-9000 total-quality-certified intelligence agency.
The Atrocity Archives
—CHARLES STROSS
16.1 Planning
Security doesn’t just happen. It takes organized effort, planning ahead, and process. If you’re a geek like me—and you probably are one (or at least a geek at heart) if you’ve made it to page 279 of a rather technical book—those words probably strike horror into your heart. Nevertheless, and very reluctantly, I’ve concluded that process is a very necessary component of secure operation. Sigh. . .
The first issue is very simple: who makes which decisions about security? Even in a tiny organization, it requires some thought: the sole sysadmin may be the one to implement a policy, but it’s management that has to set the shape of the policy. Larger organizations, of course, have more complex management structures, and hence more complex arrangements for creating policies. Actually setting policy is, as outlined in Chapter 15, an interactive process. There are at least four different players: the manager who sets the overall flavor, the manager whose bailiwick will be affected by a policy or policy change, the security person who knows the threats, and the sysadmin who handles the actual technical aspects.
In some situations, such as the aftermath of a penetration, many more people have to get dragged in, up to and including the Legal and Personnel departments. In smaller organizations, these distinct jobs may not exist; that said, the roles are always there.
A second important issue is the resources—money—to be devoted to security. Security is always an expense; it is never a profit center. Worse yet, and unlike expenditures on, say, machinery, security doesn’t help productivity. In fact, the necessary mechanisms often hurt. You need to spend money on security, just as you need to spend money on other parasitic expenses such as insurance, audits, employee background checks, and more. The problem with security, though, is twofold: as noted, it can hinder and annoy employees, and you never really know whether the money you’ve spent on it has done you any good. This is a crucial negotiation: as a security person, you’re the one who best understands the threat model, but again, security is a parasitic expense.
There are many other aspects of security where advance planning and process can help. One is the role of employee training—it’s often boring and frequently ignored, but you can’t do without it. If nothing else, it can be a legal necessity: part of the US Federal Trade Commission’s settlement with Twitter included several requirements for employee training.1 Procurement strategy can matter: is it worth paying more for hardware and software that you think is more secure, or that your sysadmin staff can handle better? And of course, creating an ongoing mechanism for tracking changes in the threat model will clearly help, even if the intelligence group does end up annoying the sysadmins by insisting on constant reevaluation of security mechanisms.
1. “Twitter Settles Charges . . .,” http://www.ftc.gov/opa/2010/06/twitter.shtm.
Finally, there’s bookkeeping—keeping track of all the little things that can make or break security in the real world: what systems have or haven’t been updated, when certificates are due to expire, where all the external links go, and more. None but the smallest of sites can do without that, even if it does require more pixelwork by everyone else.
16.2 Security Policies
Where do security policies come from? More precisely, what factors should go into creating them? I’ll start by showing how to create firewall rules, but the concepts generalize.
It’s an empty truism to say, “Derive them from overall corporate policy” or “Negotiate with all stakeholders.” Apart from the fact that the overall mechanism should have been established earlier, per Section 16.1, it begs the questions: how are those policies established, or how are the stakeholders identified? Ultimately, it boils down to balancing opportunities, risks, and the threat model—but that’s almost as empty a truism. A more structured process is needed.
Most organizations will have a “deny by default” basic policy. Thus, we start by identifying the desired functionality. Note carefully: “allow inbound connections to TCP port X” is not “functionality”; rather, it’s a way to achieve it. We’re not up to that decision yet. Per Section 11.3, there are often several possible mechanisms to achieve the desired results; at this point, all of them should be on the table.
The next step is to evaluate the different options for both cost and security risks (Section 11.7). For large-enough projects, it may pay to bring in Legal: can some of the risks be ameliorated by a contract with some external party? Should you impose some security requirements on that party? Remember that the goal is not security at any cost, it’s security commensurate with the cost/benefit trade-off. If you never lose your bet—that is, if you never suffer a breach—perhaps you’re being too conservative.
On the other hand, don’t neglect worst-case analyses. Estimates of penetration probability have a very high degree of uncertainty, and systems are often far more porous than anyone would like [Perlroth 2014]. Ask yourself this: what if there is a serious penetration because of this new hole? Can you contain the resultant damage?
Your threat model comes in here, in a non-obvious way. A sophisticated adversary (and we’re well into the upper-right quadrant now, though not quite to the level of the Andromedans) will seek out and exploit indirect paths in. Your security may be top-notch, but what of your partners? Target was reportedly hacked via a link to the contractor that ran its HVAC systems [Krebs 2014].
At this point, you can select and start to deploy a solution, but we’re not done with process yet. You need a process for logging the original request, including requester, justification, alternatives considered, relevant threat model aspects, and what exceptions to your normal rules you made to fulfill the request. Why should all this be written down? At some point, things will change and you’ll need to revisit the exception. Maybe the project is over and you can remove it all. Alternately, perhaps the threat model or your own internal topology (and hence defenses) have changed; this may dictate a change in which solution you should prefer. Yes, changing a deployed system isn’t easy, but that’s the sort of thing software people do all the time. If there’s a security case for changing it, compatible with the business case, it can be done.
If your policy is “default accept”—many, though not all, universities are that way—you need a somewhat different process. Start with the assets to be protected and the threats to them, then lay out the defensive options. “Install a firewall” isn’t an answer; a firewall is a way to enforce a certain policy, not a policy in and of itself.
Organizations with a mostly open net generally have a culture to match. That in turn means that there’s an organizational cost to tightening security: people will resent it, and in particular will resent the loss of ability to do things they had been accustomed to doing. This suggests looking for options that cause minimal disruption: protecting only a few servers, blocking the most-abused TCP ports, and so on. Unfortunately, one critical asset isn’t easily isolated: staff time to clean up intrusions. There are no simple answers, but the basic question and the basic trade-offs are the same as always: is the increase in security worth the cost? Here, some of the cost is in morale, which is harder to quantify; it is a cost nevertheless.
The morale issue can easily arise when considering non-firewall security policies, too, such as software installation and BYOD. The analysis probably starts with the benefits of the technology. We proceed more or less as above: what does the technology do for the organization, which can include both increasing productivity and improving morale? Against that, there are the risks and costs, especially whether this will hurt security. Manageability and staff time are crucial cost factors, too. Suppose someone wants some non-standard software installed. The benefits to that staffer may be obvious, but is it secure enough to use? That evaluation, which may be time-consuming, has to be done by the sysadmins and/or the security group. Is it worth their while to even start the process?
The security issues and cost trade-offs surrounding BYOD are somewhat different. Apart from the security question, an employee-owned device is just that: employee owned. This raises difficult questions about manageability: not just who has what rights on the device (though that’s a difficult question), but also on the ability of the sysadmin group to carry out its usual management processes. The classic case, of course, is Blackberries versus iPhones and later Android phones. Blackberries were designed from the start for centralized administration: the corporate IT group configures them, decides what apps users can or cannot use, and so on. (Blackberries have other features intended for corporate use and centralized management, such as integration with calendar, address book, and voice mail systems. These are not security issues [though they profoundly affect the sysadmins], so I won’t discuss them further, save to note that their lack may affect the benefit side of the cost/benefit equation.) By contrast, iPhones and Android phones were designed for personal use; the central management features, especially initially, simply weren’t as good. Does this lack affect security? Assuredly. Is this a fatal flaw? That’s a harder question; there are advantages that have to be considered as well. Morale is one factor, of course, but many people feel that they are more productive with the newer devices. And of course, if employees are using their own toys the company does not have to spend the money buying the devices—though prices have dropped so far that the expense is not a particularly significant increase to the fully loaded cost of a professional-grade employee.
The most difficult issue, though, is the fact that the organization cannot set or enforce its normal policies. Some insist on company-supplied software that verifies that patches and antivirus software is up to date; this is largely unobjectionable. Other corporate policies might be seen as more intrusive, such as a ban on visiting adult web sites. As noted [Wondracek et al. 2010], even from a purely security perspective this isn’t unreasonable—but it’s also a fact that lots of people visit such sites despite that. There are more problematic issues with personally owned machines. Some games include anti-cheating modules that appear to spy on other activities on the user’s computer [Ward 2005]:
But Mr Hoglund found that The Warden also scans the text in the title bars of any Window for any other program.
Writing in his blog about what he found Mr Hoglund said: “I watched The Warden sniff down the e-mail addresses of people I was communicating with on MSN, the URL of several websites that I had open at the time, and the names of all my running programs.”
It’s easy to see why corporations might find that troubling, but it’s also easy to see why some employees might want to own computer games.
There are other difficult policy questions that can arise even today, and more will certainly show up in the future. What’s important is to have a structured methodology for dealing with them. A reflexive “no” answer can be just as bad as a reflexive “yes,” and business pressures will make the latter strategy far more plausible than would have seemed likely even a few years ago.
16.3 Logging and Reporting
Few automated systems work well without feedback, and computer security systems are no exception. You need to know what’s going on on your systems; the way to learn is your log files. There are three fundamental questions: what do you log, how do you log it, and what do you do with your logs?
The two obvious answers to the first question are “security-sensitive events” and “everything.” Neither is quite correct, though the latter is closer to the mark. The problem with trying to restrict what you log to security-sensitive information is that you don’t always know in advance what will be relevant. The limits, then, on collection are primarily load based, though care should be taken to avoid logging or retaining privacy-sensitive information without strong operational reasons.
Once upon a time, disk space was the primary bottleneck; obviously, that’s a lot less true today. CPU time is more of an issue, at least when it comes to fine-grained logging (e.g., every “open file” operation) on busy hosts. The biggest issue, though, is how much data you can actually make sense of: do you have enough CPU power, RAM, and so on, to do the necessary correlations?
Given all that, the proper strategy is twofold. First, set logging to “high” on all of your boxes; back off if and as necessary. Second, and equally important, set up your system administration databases (Section 15.3) to be able to turn things back to “high” in an emergency. This sort of prepositioning (which I’ll return to in the next section) is essential for rapid response.
How to log is conceptually more straightforward, though the engineering issues may require a fair amount of attention. There are two primary requirements: that an attacker who has penetrated a system be unable to wipe its logs, and that the logs be available in one place for analysis. Both of these point in the same direction: a centralized logging machine. Of course, for a large site you can’t do that all in one place; the link and disk bandwidths are probably inadequate. The trick—that is, the engineering effort—goes into figuring out the right way to divide things up.
As explained below, log information is best stored in a database, not a flat file. This suggests that at a minimum, a federated database [Josifovski et al. 2002] be used to permit access to all records if necessary. More often, you’ll want to limit your queries to single databases if possible; this in turn means grouping together related records, ones that might be needed in a single query. An obvious starting point is your service replicas: logs from all web servers, or all VPN servers, or all authentication servers should go to the same log database, especially if the replicas are providing identical services.
A diagram is shown in Figure 16.1. Various system elements create log file entries; these are sent to a parser/demultiplexer. The parser is, I fear, an ugly piece of code: it has to take text strings—all the myriad types of messages produced by every version of every box you have—and convert them into useful database entries. Once that’s done, a configuration file specifies which databases should receive which entries—and it’s perfectly reasonable to replicate some entries to help performance during queries.
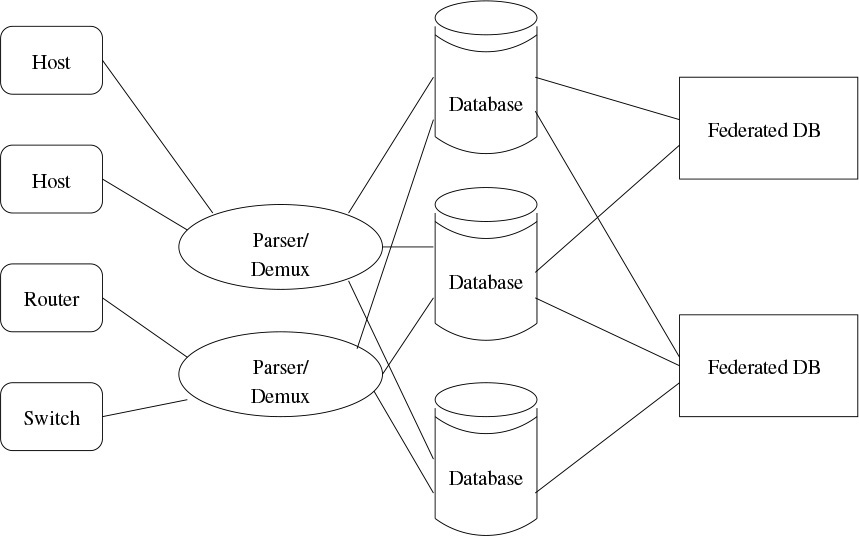
Figure 16.1: Putting log file entries into a database.
Both the parser and the databases need to be replicated. One reason, of course, is reliability; a second, as we shall see, is to aid in forensic analysis.
How you implement log file queries and polling is very OS dependent. On Unix-like systems—Linux, Solaris, Mac OS X—the built-in utilities make it easy to do data reduction on each end system; on Windows, you may find it easier to pull the files back to your monitoring server and crunch them there. Alternately, you could install a script language (e.g., Python or Perl) on each machine. The existence of portable application packages such as Apache makes that an attractive idea.
It’s time for an example. Here’s a (lightly edited) log file entry from a colleague’s small hosting center:
Jul 23 19:45:17 r0/r0 32773: Jul 23 19:45:16.206:
%SEC-6-IPACCESSLOGP: list serial-out4 denied
tcp 10.13.0.22(65276) -> 69.16.175.10(80)
His routers are configured to block all packets to or from network 10/8, since that address block is reserved for intrasite use [Rekhter et al. 1996]; this message was produced by a Cisco router. Suppose we wanted to investigate the real origin of that packet. What database queries might we want to issue?
One path would be to try to figure out on which computer the offending packet originated. To do that, we’d want a query asking all switches if they saw 10.13.0.22 as the source IP address on any ports. (Some Ethernet switches log that information; others do not.) If there are other routers in the data center, check their traffic matrices to see whether they saw any such traffic. Note that these queries presume that other, non-logging information has been added to the databases: a network management server should periodically use SNMP to dump the traffic data from assorted network elements.
We could also check which users were logged in at the time. This is a straightforward query—whose login times span the period of interest?—but it requires login data from every machine. Another way the packets could have entered the network is via a VPN: which VPN sessions were active at that time? It’s generally not reasonable to do full-packet logging (and a privacy risk besides) and few sites do full process accounting these days, but those are good options to be able to turn on quickly if weird things are happening. Again, these records need to be added to databases to ease the job of the investigator.
Let’s consider another example. Suppose, for example, that you believe that a particular machine’s SQL database has been probed by someone at 192.0.2.42. If you have the right infrastructure, you can easily check the SQL log files for queries from 192.0.2.42 on only the machines with SQL servers. (Your SQL servers don’t have such logs? Clearly, the vendor’s developers haven’t read this book yet. Tell them they need to. In fact, they should buy several copies of it. Your database system provides logging but you haven’t enabled it yet on your internal SQL servers? That’s a simple configuration change you can push out via your sysadmin database; the same database entry will, of course, automatically enable monitoring of that newly created log file.)
Other than investigations, you should do routine automated analysis of your logs to try to spot anomalies. Again, you’re much better off with a database, for several reasons. One is because it makes it easier to tailor your monitors to a machine’s role [Finke 1994; Finke 1997b]. On web servers, for example, you want to check the web logs. A test web server, though, will have very different contact patterns than a production one; you want to tune and tag your collection efforts accordingly.
Beyond that, correlating different entries is a powerful technique for detecting attacks; see, for example, [Abad, J. Taylor, et al. 2003; Abad, Y. Li, et al. 2004; Kruegel and Vigna 2003]. While the math behind sophisticated intrusion detection systems can be complicated (Section 5.3), the basic concept is straightforward: combinations of various activities can be revealing. Proper log file analysis may be the only way that Manning or Snowden could have been caught. They were authorized to access many and possibly all of the files they downloaded, but the volume of their activities was certainly suspicious [Toxen 2014]:
The NSA should monitor how many documents one accesses and at what rate, and then detect and limit this. It is astonishing, both with the NSA’s breach and similar huge thefts of data such as Target’s late-2013 loss of data for 40 million credit cards (including mine), that nobody noticed and did anything. Decent real-time monitoring and automated response to events would have detected both events early on and could have prevented most of each breach.
The open source Logcheck and Log-watch programs will generate alerts of abnormal events in near real time, and the Fail2Ban program will lock out the attacker. All are free and easily can be customized to detect excessive quantities of downloads of documents. There are many comparable commercial applications, and the NSA certainly has the budget to create its own.
The notion of automated examination of log file entries for security monitoring is not new [S. E. Hansen and Atkins 1992; S. E. Hansen and Atkins 1993]. Too few sites do it, even today; they treat their log files as something to examine after a breach. Of course, if they don’t monitor their logs they probably won’t notice that they’ve been hacked.
16.4 Incident Response
What will you do when your site is hacked? Not “if,” “when.” If you run a decent-sized site, you’ll almost certainly have to face the issue at some point. Planning and preparation can make a huge difference in how things turn out and in how quickly you’re back on the air.
Some of the issues are non-technical. When an attack is detected, who should be notified and when? Note that sometimes, you’re uncertain about whether you’re dealing with an attack—when do you pass the possibly bad news up the ladder?
Obviously, the details will vary depending on the size of the organization. In large companies, the Chief Information Security Officer (CISO) will make the hard calls, but that means looping in the CISO fairly early in the game. In smaller organizations, it will probably be the head of the IT group (or maybe the one and only sysadmin) who handles things. However, penetrations are not just a technical issue; a lot of different people (or roles) have to get involved:
CEO Penetrations can be serious; companies have gone out of business because of them [Butler 2014]. There can also be major impact on your company’s reputation [Ziobro and Yadron 2014] and even on the Board of Directors [Ziobro and Lublin 2014].
Legal Depending on your industry and what happened, breaches may have legal consequences. In most US states, for example, companies are required to notify people if their personal information has been stolen [Stevens 2012]. If the hack is serious enough to affect the share price, the public has to be notified [Michaels 2014].
Some companies prefer to delay any public mention of the breach [Yadron 2014]; in at least one, Urban Outfitters, the legal department calls the shots [Yadron 2014]:
After a hack involving consumer data, her first call isn’t to her boss, who is Urban’s technology chief. Instead, it’s the company’s general counsel, a shift the company made post-Target to cloak the conversations under attorney-client privilege. Then, according to the plan, an outside investigator, whom she declined to name, is due at Urban headquarters within 24 hours, Ms. Hutchinson said.
I’m on record as opposing too much silence [Bellovin 2012], but I’m neither a CEO nor a general counsel.
Public Relations Expect press inquiries once the story gets out. In fact, if you’re unlucky, that’s how you’ll find out: an enterprising journalist has turned up evidence of the hack and will contact your company. (What should you say about the incident? My advice is honesty; as Shakespeare noted, “truth will out” [1596].) That said, initial impressions of the problem will almost certainly be wrong; bear that in mind when crafting your strategy.
Personnel If an all-employee advisory is needed, it’s probably up to the Personnel folks to handle it. If it’s an inside job, they’ll certainly need to be involved.
Physical Security I’ve seen hacks where every employee’s password had to be reset and patches installed on their computers. The security guards at the doors were the ones who handled the logistics of this.
Production Department Heads It may become necessary to shut down certain production systems, even ones that are customer facing. That’s probably a joint decision, but even if it’s strictly up to the CISO, the production folks need to know.
It is instructive to read how complicated the logistics were even in the 1980s [Eichin and Rochlis 1989; Stoll 1988]. They’re more complicated now.
Both of those papers make another point: it’s important to be able to communicate when you can’t use email. It may be unavailable (Is your mail server still up? Still reachable?), or you may need to refrain from using email to avoid alerting the attackers. Translation: everyone relevant needs to have a list of phone numbers—printed on paper. The list should include home and mobile phone numbers, especially if your office phones use VoIP. Naturally, there needs to be a known, well-defined policy on when this list should be used—but when it’s needed, it’s really needed.
The larger the company, the more need there is for a notification and reaction flow-chart, and perhaps even rehearsals. Even small organizations need to think about the problem in advance; at a minimum, anyone who might be called should be aware of the possibility.
There are purely technical precautions to take, too. Specifically, you need to know what to do to monitor an ongoing problem, assess the damage, and restore full, uninfected functionality. The latter is largely up to your own group; the former two items may be outsourced, in which case you need to know whom to call. To do it yourself, you’ll likely need special software and perhaps hardware. Monitoring a network? What computer will you hook up to the monitoring ports on the relevant switches or routers? How will you reconfigure that node to start feeding the right stuff to the monitoring port? How will you distribute that data or its analyses to all of the right people, when you don’t want to email it? How will you preserve the data in a form that may be useful in a prosecution?
Find out in advance who the proper legal authorities are for your industry and jurisdiction. Talk to them; find out what they’d want you to do in case of an incident. Your lawyers should talk to prosecutors about what logging should be like to best preserve useful evidence. Your local police department may be the wrong choice; many don’t have the expertise to handle computer intrusions originating from a foreign country. Similarly, there are often industry-specific information-sharing organizations; these can keep you apprised of ongoing threats and probably know who the proper law enforcement agencies are.
Even if you have no interest in prosecution, a full forensic analysis is mandatory: you need to know what the damage was, how the attackers got in, and whether you’ve cleaned them out. The canonical advice on disinfecting a system—reformat the disk and reinstall—is inadequate; if you don’t change something, you’ll end up reinstalling the vulnerability. To quote the old folk definition, insanity is doing the same thing over and over again and hoping for a different result. You probably do need to reinstall, but that’s not sufficient. Reinstallation, though, means that you need access to installation media and your backups, and you need some way of knowing which backups are clean and which contain attacker-installed back doors.
This is where your logs will earn their keep: they’re your only way of knowing when and how the initial penetration took place. A dose of humility is need, as well as confirmation by inspecting the systems suggested by the log. Don’t act too hastily, though; take time to think it through. Recovery is never a fast process. At a minimum, you’re installing a lot of systems and applications (and possibly using this as an opportunity to upgrade to new versions), and testing your new setup. If you don’t move to new versions, you’ll certainly want to install pending patches. You won’t have the usual luxury of time in a test lab, but you’re also not doing yourself any favors if you don’t take some time to test. You’ll need spare machines and disks, so you can continue operations while the rebuilds take place; that, too, requires advance procurement. Recovery is an all-hands-on-deck event, with plenty of overtime for everyone. (Maybe the CFO should also be on the notification list?)
Dealing with an intrusion is never easy and is rarely fun. (Bill Cheswick, Avi Rubin, and I described our experiences in Chapter 17 of [Cheswick, Bellovin, and Rubin 2003]. We were lucky; it was a largely unused experimental machine.) Knowing what to do and having the necessary hardware and software on hand makes life a lot easier.