
11
OBJECT-BASED STORAGE
The concepts of “objects” and how storage devices associate with objects are unique in that they depart from the architectures of traditional file and storage systems. Getting a grasp on objects can help to paint a better picture of what the promoters of MXF and metadata for moving media had in mind when they set out to formalize those standards over 15 years ago.
Object-based storage, unlike block-based storage, encapsulates user data, its attributes, and the information associated with describing that user data together, as opposed to having them linked externally by a separate organizing mechanism. This combination enables object storage to determine data layout and quality of service on a per-object basis, improving flexibility and manageability.
The natural evolution of the block storage interface, objectbased storage, is aimed at efficiently and effectively meeting the performance, reliability, security, and service requirements demanded by current and future applications. The storage interface provides an organizational container, the object, into which user data, attributes, permissions, and intelligence about each of them can be kept in a secure manner.
KEY CHAPTER POINTS
•A thorough discussion of objects and relationships that storage systems have in terms of containers, object-based storage (OBS), object-based storage systems (OSS), and object-based storage devices (OSD)
•Block-based versus object-based disk and storage structures
•The OSD command set and its derivation that came from the research at Carnegie Mellon University in the early 1990s on Network-Attached Secure Disks (NASD)
•NFS Version 4.1 and the Parallel Network File System (pNFS), which originated from the research on NASD and is implementing OSD functionality
•Security mechanisms that add data integrity to OSD implementation
• An application case for OSD, the eXensible Access Method (XAM) storage interface, along with the future of the standards and other related topics
Introduction: Objects
An “object” is a container for data and attributes. Typically, large data files are broken down and stored in one or more objects. The protocol, object-based storage (OBS), specifies the several operations that are performed on objects, and it is based on what is known as an object-based storage device (OSD). Objects can be employed in smaller single computer/server applications or in massively parallel server/processor systems.
Object-based storage offers another improvement in security, accessibility control, and prevention of malicious damage.
Data Access Models
The technology is known as the Object-Based Data Access Model and is similar to the established data access methods like those of parallel SCSI, serial attached SCSI (SAS), Fibre Channel Protocol (FCP) and other block-based methods. The model also relates to file-based methods found in NFS and CIFS.
Analogous to a logical unit, but unlike a traditional blockoriented device providing access to data organized as an array of unrelated blocks, OSD as an object store allows access to data by means of a virtual entity that groups data together as “storage objects,” according to needs that are determined by the user.
Objects are typically composed of the following:
•Object identifier (OID)
•Attributes (inferred and user supplied)
•User metadata (structural or descriptive metadata, e.g., date, time or file type)
•Actual data
In this model, unlike that of a host-based file system, storage space is allocated internally by the OSD itself. The OSD will manage all the required low-level storage, the space management, and all necessary security functions. Given there is now no host-based metadata for an object, an application can only retrieve an object by using its object identifier (OID). Figure 11.1 depicts the differences in the traditional block-based disk structure versus the object-based disk storage structure.
In an OSD, a collection of objects forms a flat space of unique OIDs. By rearranging pointers to objects, sets of virtual file hierarchies can be emulated (see Fig. 11.2).

Figure 11.1 Block-based versus object-based disk structures.
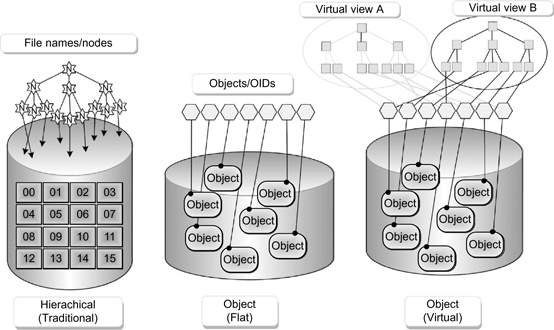
Figure 11.2 Access models for objects and OIDs versus traditional file names and nodes with “virtual” and “flat” structures.
Object-Based Storage Device
An OSD is a computer storage device, similar to disk storage, but it is intended to work at a higher level. An OSD provides the mechanisms to organize data into flexible-sized data containers, called objects, as opposed to a traditional block- oriented (disk) interface that reads and writes fixed- sized blocks of data. The object is the fundamental unit of data storage in an OSD, which contains the elements shown on the right side of Fig. 11.1.
The OSD has the responsibility for managing the storage of objects as a set of data, attributes, OIDs, and associated user metadata.
Object Types
Each object is a self-contained unit, which provides the users with the flexibility they need to encapsulate data and then share it under their complete control. Host-based data management applications and file systems are able to store both user data and metadata. The object attributes in OSD enable associations of applications with any OSD object. Such attributes are contained in the association hierarchy (shown in Fig. 11.3), and they include the following: root objects, partition objects, collection objects, or user objects. Attributes may be used to describe specific characteristics of an OSD object. These attributes are similar in concept to the structural metadata found in the SMPTE metadata definitions, so they fit well into this OSD architecture. The attributes include information such as the OSD object’s total amount of bytes occupied, the logical size of the OSD object, or when the OSD object was last modified.

Figure 11.3 Object types with associated attributes.
Object-Based Storage
OBS is a protocol layer that is independent of the underlying storage hardware. OBS can take advantage of commodity hardware economics. As a standard, OBS claims to avoid the high cost of specialized storage servers.
OSDs, coupled with data-aware storage and attribute interpretation, can manipulate objects, thus aiding in search, data mining, and data manipulation applications.
OSD Command Set
The original work began in 1994 at Carnegie Mellon University (Pittsburgh, PA) as a government funded project that essentially developed the concepts of what would be called Network- Attached Secure Disks (NASD). The support continued through an advisory group, the National Storage Industry Consortium, who helped in the drafting of the interface specification that would later be submitted to the International Committee for Information Technology Standards (INCITS) T10, who develops standards and technical reports on I/O interfaces, particularly the series of Small Computer System Interface (SCSI) standards. This work was ratified as the ANSI T10 SCSI OSD V1 command set and subsequently released as INCITS 400-2004. The efforts gained the support of the Storage Networking Industry Association (SNIA), a body that works closely with standards body organizations (SBOs) to promote technical objectives from user- and vendor- supported groups. Work has continued on further extensions to the interface under the heading of a “V2” version.
Like the effects that object-based programming (OBP) has already had on the industry, the movement toward OSD implementation promises to have as an important and similar impact on enterprise wide storage as OBP did on programming well over a decade ago.
Command Interface
The command interface, which became the initial OSD standard, “Object-based Storage Device Commands” (approved for SCSI in 2004), includes the commands to create and delete an object, write and read bytes to and from the individual objects, and set and retrieve the attributes of the object.
By definition, each object has both data (as an uninterpreted sequence of bytes) and metadata (an extensible set of attributes describing the object). The OSD command interface includes commands to do the following:
•Create and delete objects.
•Write and read bytes to and from individual objects.
•Set and get attributes of objects.
The OSD is responsible for managing the storage of objects and their metadata. The OSD standard further implements a security mechanism that provides per-object and per-command access control.
Attributes
A key component of the OSD standard relates to the flexibility and connections of attributes to objects. An enormous number of attribute pages are available, per the ANSI T10 SCSI OSD V1 standard, which defines 232 (4.295 × 109 = 4,294,967,296) attribute pages per object, 232 attributes per attribute page.
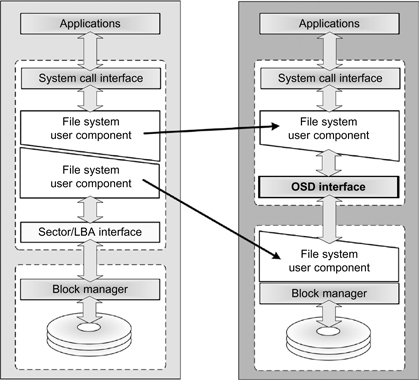
Figure 11.4 Traditional model versus object-based model for access as per the T10 OSD-3 working group of INCITS.
A comparatively minute range of this attribute name space is predefined by the standard. The application can use (or define) the predominant part of the space, allowing for superior data services and an improved quality of service (QoS).
Attribute Categories
The categories of attributes used in object-based storage systems are as follows:
•Storage attributes that are similar to inodes, that is, data structures on a traditional Unix-style file system (such as UFS), which store basic information about a regular file, directory, or other file system object. These storage attributes are used by the OSD to manage block allocations for data. They include such items as the capacity used, the OID, the logical length, or block pointers.
•User attributes that are used by applications and metadata managers to store higher level information about the object. This information includes capacity, density, performance, cost, manageability, reliability, availability, serviceability, interoperability, security, power usage, adaptability, capability, and quotas.
System Layers and Devices
Attributes and metadata will be stored directly with the data object. They are automatically passed between layers and across devices. When objects pass through a designated system layer or device, that layer may then react based on the values in the attributes that it interprets. Any other attributes that are not recognized (i.e., not understood) are passed along unmodified and unacted upon. This concept is ideal for media systems where workflows consistently handle data that needs some form of action taken based upon what that data actually is (e.g., transcoding from SD to HD based upon a flag setting in the workflow management).
Another application handles the objects that are marked either as temporary or as high reliability. Because attributes are stored with user data, a service level can be attached to that data, which would manage secondary activities, such as better caching, prefetching, or migration.
OSD Versions
Several research projects have explored object storage and implemented prototype systems with various semantics. The initial OSD standard, Object-based Storage Device Commands (OSD), for SCSI was approved in 2004. A second version of the command set (OSD-2) was finalized in late 2008 yet remains stalled in the standardization process. OSD-3, the latest version, is under development with its current draft T10/2128-D revision 02 published on July 10, 2010.
Storage Categories
Storage technologies can be classified into three major categories as follows: direct-attached storage (DAS), network-attached storage (NAS), and storage area networks (SAN). A brief introduction follows, with much greater detail found in Chapter 15.
Direct-Attached Storage
DAS is computer storage, usually magnetic drives or solid-state drives that are directly attached to a computer workstation or server. DAS is the simplest and easiest to implement form of disk storage.
Network-Attached Storage
NAS is a file-based storage architecture for hosts connected to an IP network or a LAN. Typically, the functionality of a NAS requires that the file servers manage the metadata, which describes how those files are stored on the devices. The advantages to a NAS implementation are in terms of their data sharing and secure access through a server or workstation.
NAS Advantages
Network-attached storage became popular because it uses inexpensive, reliable, and reasonably fast Ethernet topologies and associated protocols. NAS offsets the impacts of a fussy, costly, yet very fast Fibre Channel alternative. The Network Files System (NFS) is highly utilized on NAS as a storage protocol for compute clusters. Unfortunately, as data sets and file sizes have grown exponentially, the relative speed of Ethernet has not quite kept up with that growth, especially when adding in the growth in bandwidth requirements. With 10-Gbit Ethernet (10 GigE) acceptance rising, many of these Ethernet problems are now being solved. Nonetheless, NFS has had a hard time scaling to gigabit Ethernet, which is reason in part why TCP Offload Engines (TOEs), custom hardware pipelines, and other implementations have emerged for gigabit Ethernet storage subsystems.
Further development in a parallel NFS (pNFS), which is sanctioned by the IETF, has helped this situation. pNFS is discussed later in this chapter.
Storage Area Networks
A SAN is a block-based architecture where the client has direct access to disks on a switched fabric network, which is usually Fibre Channel based (although that model has been changing). The SAN’s main advantage is in its capability to transfer large amounts of data in units of blocks. The SAN may also be constructed with several sets of parallel data and control paths providing for multiple machine access and data processing, including metadata handling. With this degree of activity, the need for security and access control is essential.
Unfortunately, blocks on a SAN have a poor security model that relies on coarse grain techniques involving zoning and logical unit number (LUN) masking. Object-based storage helps in resolving the security issues, as discussed later in this chapter.
The SAN technology’s intent is to replace bus-based architecture with a high-speed, higher bandwidth switched fabric.
Combining SAN and NAS Advantages
An object-based system, when implemented as a SAN technology, combines the advantages of high-speed, direct-access SANs and the data sharing and secure access capabilities of NAS.
Earlier trends (ca. 2006) saw the emergence of NAS head—based file servers that were placed in front of SAN storage. This practice continues today, but the development of parallel NAS (pNAS) at the client side is a change that is expected in the current NAS had/SAN combination.
Network-Attached Secure Disks
In the 1990s, research on NASD examined the opportunities to move additional processing power closer to the actual disk drive when in a NAS environment. As distributed file systems have increased in popularity as a means to access data across LANs, there have been a number of approaches to improve them. The scalability and storage management associated with these exposed file systems has raised security concerns for at least the last two decades. NASD and object-based storage have helped to control this exposure.
Traditionally, a server-attached disk (SAD) storage configuration would transfer data via the server’s memory. At the time of the transfer, the server synchronously oversees rights and privileges assigned per the structure of the security scheme set by the administrator. SAD systems would typically have two independent networks: the local area network (LAN) and the storage bus. In this system, all data travels over both networks. Storage subsystems used by SAD generally will implement some level of self-management and extensibility, with both being limited by the SAD file system design. Part of the concept of NASD was to overcome those limitations and in turn provide for greater flexibility and higher performance.
Access Control and Security in OSD
An important aspect of this NASD work related to access control is how data and its associated attributes can be securely accessed by systems and users. NASD researchers from Carnegie Mellon described a security protocol for object storage that allowed a security manager to provide fine-grained access control to a shared storage device on a network. In turn, this work linked into a higher level building block that could be aggregated together to provide large-scale, secure storage.
NASD efficiently supports asynchronous oversight (access control) and secure communications using capabilities that have been cryptographically sealed by the appropriate authority, for example, the file system manager or partition manager. The approach is dependent upon the shared secret between a NASD drive and the authority in order to maintain this long-term relationship. A four-level key hierarchy is used as follows:
•Master key—also called the “top key” that is off-line and only accessible by the drive owner (i.e., the system administrator).
•Drive key—an online key available to the drive administrator used for manipulating partitions, setting partition keys, or for any object-based operation (optional).
•Partition key—an online key used by the file system manager to set working keys or for object-based operations (optional).
•Current working key—used online by the file system manager as a basis for capacity generation, and optionally for objectbased operations.
•Previous working key—used online by the file system manager as a basis for capabilities that were generated under the previous working key.
The top key, that is, the master key, is the longest-lived secret. For highly secure models, the master key once set remains unchallengeable. It is not recorded online outside of the NASD drive. This key is used only to establish a new drive key in the event of failures or desynchronization.
Fast Forward
By employing more powerful processors with features such as block allocation (also called space management), a more abstract interface of reading and writing bytes to flexible data containers could then be enabled.
The most active work (ca. 2002) was at the Parallel Data Lab at Carnegie Mellon University (http://www.pdl.cmu.edu) originally under the direction of Garth Gibson. Development was related to the work associated with NASD and Active Disks. Additional work during this time period was done at the University of California at Berkeley, the University of California, Santa Barbara, and the University of Maryland, as well as Hewlett Packard Labs, Seagate Technology, and Intel Labs.
Storage Interface Progression
Change is inevitable, especially in the area of storage. Earlier in this book, we introduced you to the infancy of storage and discussed how it progressed in the early days of the original Shugart Technologies model ST-506. These technologies then lead to the “data separator” era outlined by the Enhanced Small Disk Interface (ESDI) and the Storage Module Device (SMD) developments of the 1980s.
The physical sector interface utilizing sector buffering (e.g., IPI-2) led to the logical block interface with error correcting code (ECC) and geometry mapping (e.g., in SCSI). This evolution has moved on to the byte string interface, where space management is one of the primary objectives and is governed by the development found in OSD.
Intelligent Storage Interface
OSD is the interface to intelligent storage. In SCSI hard drive implementation, each 512-byte sector is equivalent. In the OSD basic objects implementation, the system is “structure-aware.” OSD will take control of space management, determine where to put the file data, and become completely aware of where the free space is, and if continued, can move the file data around based upon its needs and control.
As the types of data become more varied, the system control can become even more complicated. In the case of ordered sequential files, such as motion video (e.g., MPEG, JPEG, etc.), the internal structure becomes more complete. The additional functionality of “structure-aware” and “data-aware” storage (see Fig. 11.5) found in object-based storage thus aids in enabling improved sharing, security, and reliability. QoS, indexing, and searching are all improved as well.
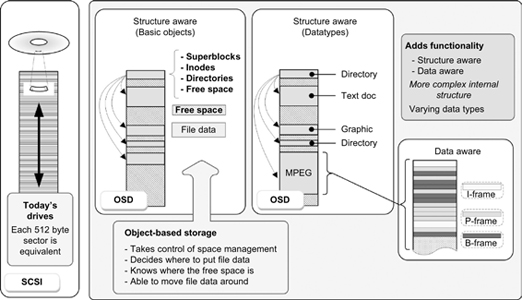
Figure 11.5 OSD as an interface to intelligent storage enables sharing, security, reliability, QoS, performance, and structure awareness as basic objects and as datatypes.
Data Objects
Data objects will have both data and metadata. An object’s data is an uninterpreted sequence of bytes. The metadata associated with that object is the extensible set of attributes that describes the object.
Contained in OSDs, there will be one or more logical units that are comprised of the following types of stored data objects:
•Root object—each OSD logical unit contains one and only one root object. The root object attributes contain global characteristics for the OSD logical unit. These may include the total capacity of the logical unit, the number of partitions that it contains, and a list of Partition_IDs for the partitions in the logical unit. The root object is the starting point for navigation of the structure on an OSD logical unit. It does not contain a read/write data area.
•Partition—an OSD object created by specific commands from an application client that contains a set of collections and user objects that share common security requirements and attributes. These attributes could include, at least, the prescribed default security method and other information such as a capacity quota. User objects are collected into partitions that are represented by partition OSD objects. There may be any number of partitions, up to a specified quota or the capacity of the OSD logical unit. A partition does not contain a read/write data area.
•Collection—an OSD object created by commands from an application client, which is used for the fast indexing of user objects. A collection is contained within one partition, and a partition may contain zero or more collections. The support for collections is optional.
•User object—an OSD object containing end-user data such as a file or a database. Attributes associated with the user object may include the logical size of the user data and the time stamps for creation, access, or modification of any end-user data. A user object may be a member of zero or more collections concurrently.
Object-Based Data Access
The object-based data access model is analogous to a logical unit, which is usually addressed as a LUN. In current SCSI protocol, the LUN is a 64-bit identifier generally divided into four 16-bit pieces used to reflect a multilevel addressing scheme.
The object store in OSD allows access to data by means of storage objects. Again, the object is a virtual entity that groups data together in a means determined by the user and whose grouping is generally logically related. OSD is usually deployed as a deviceoriented system that is based on data objects that encapsulate user data, including user attributes and user metadata.
As mentioned previously, the OSD then manages all the essential low-level storage, drive space management, and security functions.
Data Layout with QoS
An underlying principle in object-based storage is that it allows for the combination of data, attributes, and metadata to set up and, in turn, determines the data layout and the quality of service (QoS) for the system on a per-object basis. Thus, OSD improves manageability and flexibility for all of the data sets in a system. To place OSD into perspective, we need to look at the differences in block-based versus file-based methods of traditional storage system architectures.
Block-Based Methods
Storage area networks (SANs) will use the SCSI block I/O command set that provides high random I/O and data throughput performance using direct access to the data at the level of the disk drive or Fibre Channel. Block-based methods of storage include parallel-SCSI, SAS, FCP, PATA/ATA, and SATA.
File-Based Methods
Network-attached storage (NAS) systems use Network File System (NFS) or Common Internet File System (CIFS) command sets for accessing data. Multiple nodes can access the data because the metadata on the media is shared.
Parallel Heading
The principles of a NFS were developed by Sun Microsystems (Sun) in the 1980s, where it later became an open standard that allowed files on the network to be available anywhere. Today, the Internet Engineering Task Force (IETF) is the body responsible for NFS standards and revisions. As higher speeds for data transfers and networks placed new demands on systems, work began (ca. 2002–2003) on the development of a parallel version of NFS, which would enable much higher speeds. This work would become pNFS.
Typical NFS Servers
Standard NFS file servers function much like a conventional PC workstation does. Files that land on local disks are tracked by the computer’s file system through processes that manage the location, name, creation and modification dates, attributes, permissions, size, etc. Metadata, the data about the data, is used to track these parameters, such as the location, size, and date. The metadata can be contained locally through the file system or separately.
When a file is requested, the file server receives the request, looks up the metadata, and converts that information into disk input/output (I/O) requests, where the process then collects the data and sends it over the network to the requested destination. Much of the time in this process is spent simply collecting the data. The time adds up quickly when a number of small file requests continually recur, as in database or transactional applications.
In the case where the files are quite large, as in media clips or large contiguous segments, it is the data transmission time that becomes the limiting factor. If you could segment a large file into smaller pieces and send those pieces in parallel to a compute server, ideally it would be faster than sending a single file to a single location. With several parallel connections, that time is reduced substantially.
These concepts and desires promoted the development of the parallel file system and multi-threaded computing and would be an enabling factor for accessing the storage subsystems through more efficient means and without taxing the CPU management processes attached to the file system.
Parallel NFS
Parallel NFS (pNFS) is a standards-based parallel file system serving the NFS protocol. pNFS divides the NFS file server into two types: the first is the metadata and control server and the second is one to as many storage servers as the budget (and physical space) can tolerate (see Fig. 11.6). When aligned together, the control server and the storage servers form a single logical NFS server with a plethora of network connections. The compute server, likely to be a multinode cluster, will employ a large number of Ethernet ports that provision the network transfers. Large parallel, high-performance clusters have been built out of inexpensive PC-like hardware and are sometimes known as a Beowulf cluster, which might run a Free and Open Source Software (FOSS) operating system, such as Solaris, GNU/Linux, or the BSD (Berkeley Software Distribution) descendents, which form a Unix-like OS family.

Figure 11.6 Parallel NFS using the storage access protocols from the pNFS standard from the IETF work. Note that the control protocol is outside of the pNFS standard.
Operationally, the compute server requests a file using the NFSv4.1 client (final draft produced ca. 2007–2008). The NFS control server then receives the request and then searches the location of the file chunks on the various storage servers. The information, called a layout, is sent back to the NFSv4.1 client, which tells its cluster members where to retrieve the data. Cluster members will use the layout information and request the data directly from the storage servers. Security components further provide for data integrity (explained later) through a series of secret keys and messaging. The processing, transfer, and handling speeds increase proportionately to the number of storage servers in the cluster.
Version Compatibility
pNFS is backwards-compatible with existing NFS implementations. When a previous client (e.g., NFS v3 client) wishes to access data from a pNFS-enabled cluster, it will mount the pNFS cluster like another ordinary NFS filer. Migration to pNFS v4.1 is designed to be straightforward and easy.
Applications
Parallel path processing and cluster computing is being applied to applications such as finite analysis and financial risk analysis, and it is extensively applied in 3D animation and rendering space for motion picture production. Video editing, collaborative workflows, and high-performance streaming video all could take good advantage of the features in pNFS, especially the improved data transfer times.
Concurrent user support is ideal for pNFS where multiple sets of disks can respond, thus spreading the workload across many storage servers. This improves scaling of storage requirements easily and consistently. pNFS may be implemented using Fibre Channel or block-based iSCSI on GigE file storage or object-based storage (OBS).
pNFS with OSD Protocols
When employed with object-based storage, the files are broken into smaller chunks, referred to as objects, which are uniquely identified by numbers as opposed to the traditional path names in block file storage methods. Objects use extensible metadata that enables a more refined, lower overhead security technique.
Object servers will not accept data or commands unless so authorized by the metadata server. This capability-based security scheme prevents malicious, accidental, or unauthorized access or changes to be made.
Operations that are part of the OSD protocols include the following:
READ, WRITE, FLUSH,
GET ATTRIBUTES, SET ATTRIBUTES,
CREATE, and DELETE.
When using the object-based layout, a client may only use the READ, WRITE, GET ATTRIBUTES, and FLUSH commands. All other commands are only allowed to be used by the pNFS server. An object-based layout for pNFS includes object identifiers, capabilities that allow clients to READ or WRITE those objects, and various parameters that control how file data is striped across their component objects.
Linux pNFS
Although there is a tight integration of control and data protocols for parallel file systems, the control and data flows are separate. By using pNFS as a universal metadata protocol, applications can fulfill a consistent set of file system semantics across data repositories. By providing a framework for the coexistence of the NFSv4.1 control protocol, the Linux pNFS implementation facilitates interoperability with all storage protocols. This is seen as a major departure from current file systems, which support only a single storage protocol such as OSD.
Figure 11.7 depicts the architecture of pNFS on the Linux OS. Through the added layout and transport drivers, the standard NFS v4 architecture interprets and utilizes opaque layout information that is returned from the pNFS server. The layout contains the information required to access any byte range of a file, and it may contain file system—specific access information. In the case of OSD, the object-based layout driver requires the use of OSD’s access control capabilities.
To perform direct and parallel I/O, a pNFS client first requests layout information from the pNFS server, which the layout driver uses to translate read and write requests from the pNFS client into I/O requests directed to storage devices. The NFSv4.1 filebased storage protocol stripes files across NFSv4.1 data servers (storage devices). In this mode, only READ, WRITE, COMMIT, and session operations are used on the data path. The pNFS server is able to generate layout information by itself or requests assistance from the underlying file system.

Figure 11.7 The pNFS implementation on a Linux operating system.
Layout drivers use a standard set of interfaces for all storage protocols and are pluggable. A “policy interface” is used to inform pNFS clients of the policies that are specific to the file system and the storage system. To facilitate the management of the layout information and in performing I/O with storage, an “I/O interface” is used. Layout driver functionality can depend on the application, the supported storage protocol, and the core of the parallel file system.
The last layer between the client and storage is the transport driver, which is used to perform those input and output functions, such as iSCSI or Open Network Computing Remote Procedure Calls (ONC RPC), on the storage nodes, through the instructions and policies control described.
IETF Standards for NFSv4.1/pNFS
The IETF working groups that lead the standardization of the parallel implementation of NFS, what is now NFSv4.1, published several RFC documents related to the standardization of a suite of capabilities. At the time, the OSD standard was only at Version 1.0, but work continued with the anticipation of Version 2.0 as SNIA T10/1729-D would be forthcoming.
This second-generation OSD protocol has additional proposed features that will support more robust error recovery, snapshots, and byte-range capabilities. Therefore, the OSD version must be explicitly called out in the information returned in the layout. The IETF documents related mostly to parallel NFS are shown in Table 11.1.
OSD Management Structure
In OSD, there is a differing management structure than that of the traditional SCSI-3 Block Commands (SBC) structure defined in the references under development as ISO/IEC 14776-323, SCSI Block Commands-3 (SBC-3) [T10/1799-D]. The principle differences are at the file system storage management level, which is replaced by the OSD interface and OSD storage management (refer back to Fig. 11.4). Subsequently, the traditional sector or logical block addressing scheme is transformed and is now located just ahead of the block I/O manager for the storage (drive or tape) device itself.

SCSI Architecture Model
The original third-generation SCSI standards used the name SCSI-3 to distinguish them from SCSI-2. To lessen confusion, succeeding SCSI standards dropped the “-3” from their names. When the SCSI-3 architecture model (SAM) was revised, the nomenclature was simply shorted to “SAM-2” (SCSI Architecture Model - 2).
Although the individual components of the SCSI family continue to evolve, there was no SCSI-4 project envisioned. The fifth generation and current SCSI Architectural Model - 5 (SAM-5) has a INCITS T10 committee status date of May 2011 listed as T10 Project Number 2104-D, Revision 05.
As of December 2010, OSD-3 (T10 Project Number 2128-D, Revision 02) is still in development with a target date of November 2011.
Security Mechanisms
OSD implements a mechanism that provides per-object and per- command access control as its security feature. The T10 OSD security working group sets the following goals for the OSD security protocol: it would prevent against attacks on individual objects, including intentional and inadvertent nonauthorized access; prevent the illegal use of credentials beyond their original scope and lifespan; protect against the forging or theft of credentials; and preclude the use of malformed and misshapen credentials.
Furthermore, the protocol would enable protection against network attacks, such as the so-called “man-in-the-middle” attacks on the network, network errors, malicious message modifications, and message replay attacks. The OSD security protocol must allow for low-cost implementation of the critical path for commodity devices and should enable efficient implementation on existing network transports.
The security flow follows a series of protocols and processes that allow for the goals mentioned previously to be achieved. When a client wishes to access an object, it requests a capability from the security manager. The request must specify the OSD name, partition ID, and object ID to fully identify the object. Any secondary authentication processes for the client are outside the scope of the OSD security protocol. Once the security manager has determined that the client is authorized to perform the requested operation on the specified object, the security manager generates a cryptographically secured credential that includes the requested capability. The secured credential is validated by a shared secret between the security manager and the OSD.
The credential is then sent to the client. The channel for this credential exchange should provide privacy, through encryption, so as to protect the capability key used by the client to authenticate that it legitimately obtained a capability. The client is required to present a capability on each OSD command; and before processing can continue, the OSD verifies that the capability has not been modified in any way, and that the capability permits the requested operation against the specified object. Once both tests are passed, the OSD permits the specific operation based upon the rights encoded in the capability.
It is possible that a client would request a credential that permits multiple types of operation (e.g., Read + Write + Delete), allowing the client to aggressively cache and reuse credentials. This in turn minimizes the volume of like messages between the security manager and the client.
The OSD is a trusted component, providing integrity for the data while stored. The protocol and the OSD insure that a proper following of the protocols will be controlled and not be controlled by an adversary. The security manager for its part is a component that is trusted to safely store the master/long-lived keys after authentication and follows all protocols so as not to be controlled by an adversary.
The depths of how the credentials, capability arguments, and capability keys are managed and secured are beyond the scope of these OSD discussions.
Applications of OSD
As depicted in Fig. 11.5, OSD enables intelligent, data-aware and structure-aware storage. OSD provides many new opportunities for large-scale archives and high-density storage applications. It enables scalability, increased performance, reliability, and a new, higher level of security. This is why many organizations look to OSD to support their assets at levels heretofore reserved to proprietary asset management systems.
Content Aware Storage
The archive market is already using object storage that may be found in multiple proprietary systems with applicationbased APIs. In an effort to promote a standardized interface with interoperability between object storage devices (OSDs) and applications, SNIA christened (in late 2005) what is called a “contributed specification,” which would be called the eXensible Access Method (XAM). XAM is characterized as a Content Aware Storage (CAS) system. The contributed specification efforts were initiated by EMC and IBM in joint cooperation with HP, Hitachi Data Systems (HDS), and at that time Sun (now Oracle).
The goal for fixed content (which usually has a lengthy shelf life) is to enable self-describing data and standard metadata semantics as a methodology for consistent naming and searching. XAM, as a storage interface at the application layer, can be built on storage objects and can provide those services to or from object-storage devices.
eXensible Access Method
XAM is an open-source application to storage interface for file sharing similar to NFS on Unix-like systems and CIFS on Microsoft platforms. However, unlike file sharing protocols, XAM also provides applications and storage systems with an expanded “metadata container,” giving rise to powerful information and retention management capabilities. The XAM standard promotes an interface specification that defines an access method (API) between Consumers (application and management software) and Providers (storage systems) with its capability to manage fixed content reference information storage services.
XAM includes those metadata definitions needed to accompany data so as to achieve application interoperability, storage transparency, and automation for information life cycle management (ILM) and tiered storage practices, long-term records retention, and information security.
XAM is intended to be expanded over time so as to include other data types and support additional implementations based on the XAM API to XAM conformant storage systems. The XAM specification is published in three parts as follows:
XAM—Part 1: Architecture
This is intended to be used by two broad audiences, that is, those application programmers who wish to use the XAM Application Programmers Interface (API) to create, access, manage, and query reference content through standardized XAM and those storage system vendors who are creating vendor interface modules (VIMs).
XAM—Part 2: C API
The complete reference document for C application development using the XAM API, intended for experienced programmers, for those developing applications that interface with storage systems and support the XAM API, and for those developing components of the XAM Library itself.
XAM—Part 3: JAVA API
A complete reference document for Java application development using the XAM API, intended for experienced programmers, for those developing applications that interface with storage systems that support the XAM API, and for those developing components of the XAM Library itself.
File System Differentials
The key difference between XAM and a file system is that XAM is implemented as an API, similar to block file system APIs, except with a focus on storage interface and access methods.
First, XAM abstracts the access method from the storage, a capability necessary to create location independence, policy-based automation, and portability.
Second, XAM wraps the data into what is called an “XSet” (object wrapper). This is similar to an XML wrapper, from the “physical” perspective. As files or data are written to storage media, they are placed into an information object with rich, extended metadata fields incorporated into the object (see Fig. 11.8).

Figure 11.8 The XAM object wrapper containing content and metadata, with examples of potential metadata fields shown on the right side.
The fields will accommodate other metadata standards and application-specific requirements that are deemed necessary for retention and for information management services in most or any environment.
The 5-year activities associated with XAM (within SNIA) culminated with its release in July 2008. ANSI standardization for the XAM v1.0.1 specification, as a SNIA Architecture, was underway at the time of this publication.
Extensions
Object-based storage devices (under the OSD-2 version) enable “snap-shotting” of storage systems to occur. Snapshots are a point-in-time copy of all the objects in a partition. Each snapshot can be placed into a new partition, moved to a central store or replicated to another site.
By using copy-on-write techniques, a space-efficient duplicate of the data set is created in a way that allows two partitions to share objects that are unchanged between the snapshots. By using OSD, it could in turn physically copy the data to a new partition. However, the OSD standard also has a section that defines clones, a writeable snapshot that is created as a read-only partition and would be used in data protection functions.
A “collection” is yet another application for OSD often used for error reporting. The collection is a specific type of object that contains the identifiers of the other objects. If an object were damaged due to a software error (within the OSD environment) or a media defect, its identifier would be placed into a separate error collection, which is quarantined and then would later be independently queried for further corrective action.
Emerging and evolving technologies continue to produce documented changes to current implementations. The current status level of the standards development for object-based storage devices, at the T10 Working Group in INCITS, is “OSD-3” (a document titled “Object-Based Storage Device Commands-3”). As of July 17, 2010, the work was at revision-02 at the development status as Project 2128-D. OSD-3 will define a third-generation command set for devices that store data as objects instead of blocks of data. This version’s purpose is an abstraction to assign to the storage device more responsibility for managing the location of the data.
Embedding OSD
In the consumer space, storage is becoming embedded in more devices all the time. Consequently, we are seeing “intelligent stand-alone devices” already emerging. Devices from iPods and PDAs to smart phones and iPads use intelligent, marketspecific OSDs. Flash memory cards can already be considered object-based storage and are readily accepted primarily because consumers do not really care or need to know about the file system, sectors, or mount points and they care first and foremost about their pictures or music files.
File attribute changes are quite common, especially at the consumer level. OSD offers a capability to alter or change a file attribute (e.g., the artist name in an MP3 file) without having to rewrite the entire file. Extending that concept to large media files, not having to rewrite the entire file just to replace a single 500- Mbyte video clip in a 100-Gbyte set of clips adds great value to how those files are stored and their subsequent accessibility for future purposes.
Refresh Cycles
Standardized data formats may be made necessary by the continued technological advancements in data storage hardware and applications. Each time this occurs, a plan to migrate the data to the next environment must be assessed. When this need occurs, having an object-based storage system and/or a parallel file system allows the object archive to horizontally scale using thirdparty applications.
Further Readings
OSD: A Tutorial on Object Storage Devices. Thomas M. Ruwart, Advanced Concepts, Ciprico, Inc.
OSD DISC/Industry Collaboration.
http://www.dtc.umn.edu/disc/osd.shtml
SNIA Object-Based Storage Device TWG: OSD Technical Working Group (TWG) enables the creation of self-managed, heterogeneous, shared storage by moving low-level storage functions into the storage device itself and accessing the device through a standard object interface rather than a traditional block-based interface such as SCSI or IDE. The OSD TWG develops models and guidelines, requirement statements, preliminary standards definitions, reference code, and prototype demonstrations for OSD storage subsystems.
Open OSD Development: Includes information on the ratification of OSD-2, open source targets, pNFS over OSD, etc.
http://www.open-osd.org/bin/view
Credit is given to Oracle for a detailed, tutorial-like article regarding object-based storage devices, which provided the depth and direction for this chapter. The full article is available online at
http://developers.sun.com/solaris/articles/osd.html.
Drafts of the various INCITS T10 documents can be found at
http://www.t10.org/drafts.htm.
Credit and contributions to the XAM topics include: SNIA-XAM:
Storage Developers - It is Time to Adopt XAM (February 2010)
The Power of XAM (July 2006)
Additional information and white papers on the SNIA XAM Initiative can be found at:
www.snia.org/forums/xam/resources/publications/