
18
STORAGE MANAGEMENT
Simply having storage available and in sufficient capacity with adequate bandwidth is only part of an overall system reliability and performance equation. If one assumes, wrongly, that the system would never grow, that users would never increase, that every rule in the book would be followed, and that all users would cooperate equally, then there would be no requirements for “storage management.” With that kind of criteria not on your agenda, then this chapter could be passed over completely.
However, this is never the case for a network or a computer system. Nor is this the case in dealing with unstructured, digital media storage. Storage management is a requirement regardless of the scale of the system, the size of the storage array, or the number of users.
There are obvious elements of storage management, and there are others not so obvious. In a system, we find there are applications that handle certain functions of storage management routinely and sufficiently, and there are other elements or subsystems that must be routinely administered.
Storage management is becoming a segment of the security and auditing processes that ensure copyrighted intellectual property (IP) is not compromised. When services such as digital color timing, online assembly, digital opticals (fades, dissolves, etc.), titles, digital cinema, as well as film and video output, depend upon advanced, highly intelligent active storage platforms for continued business activities, the ability to manage the stores that support those activities becomes a routine and indispensible activity.
This chapter now takes a look into the topics associated with the management of storage systems from background-related tasks to the more complex processes that involve NAS and SAN consolidation, monitoring, and performance tuning.
KEY CHAPTER POINTS
•Computers and networks—an overview and review of the fundamental elements that comprise the services and applications now generally accepted as routine in digital media infrastructures
•An introduction to what storage management is, and why it is important to control at the early stages of implementing a storage platform
•Life expectancy, including the caring for physical media assets, storage, protection, and preventative measures that will aid in extending the life and value of the media
•Managing file-based assets, and the impacts and effects of disk and file fragmentation
•Practical monitoring and management of a SAN environment using tools that capture traffic flow and other metrics continuously and in real time for the purpose of tuning the SAN or observing the impacts that applications have on performance
•Using root cause analysis to ascertain performance values in a storage system
•NAS consolidation methodologies that include NAS gateways and other nontraditional approaches such as file system clustering, parallel file systems, and NAS aggregators
•Snapshots of data volumes and how they are used to protect, audit, and provide an avenue for user restoration in real time
•Backup and data replication technologies aimed at reducing or managing storage capacity that include data deduplication, compression, and delta differencing
•Storage capacity management for media-centric operations; there is a time and place for everything—are the techniques for structured data the same as for unstructured data?
Storage System Dependencies
Two elements that depend upon storage systems, whether large or small, are computers and servers. We will begin the introduction to storage management with a review of these two fundamental elements in computing and networking.
Computers
Computers and servers depend upon storage, and thus they become important elements in the storage management chain. From a definition perspective, we will represent a computer as an electronic machine used in making calculations, which supports storing and analyzing information it receives from peripheral sources including storage systems (i.e., disk drives, optical media, etc); networks (i.e., local and Internet); and other devices such as displays, sound reproduction devices, and image processors.
Computers do not think, they merely process data and control (directly or indirectly) a seemingly endless set of input and output parameters through applications (software), sending that information to and from devices including storage systems.
Servers
A sometimes misunderstood or misrepresented term, a server (when referred to in computer networking) is a program that operates as a socket listener. We tend to associate servers with physical hardware, for example, a videoserver. We further associated server(s) with prefixes, such as a Web server or file server.
The term server is also generalized to describe a host that is deployed to execute one or more programs. These terms are all relative to each other and to computers, but they are generally not directly associated with physical hardware such as the computer/CPU, and its memory, peripherals, or storage components. The server, thus, remains simply a program that can be installed on application-specific hardware, embedded into a silicon-based programmable device, or in a virtual space such as in the “cloud.”
Server Applications
To provide a contrast to how a particular server may be deployed, we look at some examples of what server applications are and where they might be routinely applied.
One server application will use what is called a server socket listener, an app that is created in software and monitors the traffic on a particular port. This process, called polling, involves an application that looks for a form of service, for example, one that is trying to make a TCP connection to the server program. Extensions to this type of socket application may be created to see if the server actually responds to a request with some form of valid data (i.e., the TCP connection is up and the application is running). This may further extend the protocol to allow the server to return detailed status information about the system in response to a “status” type of message.
Media Servers
A media server may be either a dedicated computer appliance or a specialized application in software. This device simply stores and shares media. Media servers may range from enterprise-class machines providing video-on-demand or broadcast transmission services to small personal computers that utilize network-attached storage (NAS) for the home that is dedicated to storing digital video clips, long-form movies, music, and picture files.
In the world of telephony, the computing component that processes audio and/or video streams associated with telephone calls or connections is also called a media server. When used in conference services, a special “engine” is necessary that can mix audio streams together, so that participants can hear from all the other participants.
Streaming Servers
Media streamed over a network to a receiver that buffers and decodes the media for display or viewing on a constantly received basis requires a serving platform that can manage either the incoming signal (for live, linear video and audio) or the pulling of media files (from storage, cache or a library) through its server and on to distribution/transmission to one or more network addresses and users. Media is generally presented in a linear fashion and without interruption, as though it were a television broadcast signal emanating from a local television station. Additional network requirements, such as a multicasting-enabled network, require special considerations tailored to streamed media.
The following section contrasts the two main methods of delivering media over the Internet. The first method using a standard Web server to transmit the file is sometimes called “progressive download.” The other method is a streaming media server. As you will see, the server and network transportation method is the substantial differentiator between the two methodologies.
Web Servers
A computer with high-speed access to the Internet that is customized for sending Web pages and images to a Web browser is called a Web server. The computer will often run Web server software, such as Microsoft Internet Information Services (IIS) or the Apache Foundation’s Apache HTTP Server (“Apache”). The same technologies will often be used to host computer files and executable programs or to distribute media files containing video and audio.
Player software installed on the client or user’s computer is used to access media files from a Web server. Player applications, such as Windows Media Player or RealPlayer, will utilize a technology called “progressive download” to receive and play out those files. Addresses would be like those found in your browser window:
http:// (for general, open communications)
or
https:// (for secure communications)
For streaming media applications, the server (like the Web server) is connected to a high speed Internet connection. However in this case, the computer would be running streaming media server software such as Windows Media Services (WMS from Microsoft) or Helix Server (from RealNetworks).
To contrast the two, streaming media versus progressive download, the differences are the server software and corresponding network protocol used to transmit the media file.
Streaming media files would have an address something like the following:
mms://x.x.x.x/streaming_media_file_directory/media_file_ name.wmv
or
rtsp://x.x.x.x/directory/filename.rm
Sometimes streaming media addresses are embedded inside a text file that is downloaded from a Web server and then opened by the media player. Such a file might end in the .asx (Windows Media) or .rm (Real) file extensions.
Files downloaded over the Web generally cannot be viewed until the entire file is downloaded. Files delivered to the server using streaming media technology are buffered and playable shortly after they are received by the computer they are being viewed on.
The streaming server works in concert with the client to send audio and/or video over the Internet or intranet for nearly immediate playback. Features include real-time broadcasting of live events, plus the ability to control the playback of on-demand content. Viewers are able to skip to a point part way through a clip without needing to download the beginning. When the download speeds are inadequate to deliver the data in time for real-time playout, the streamed Web cast sacrifices image quality, so that the viewing can remain synchronized as close to real time as possible.
Storage Management Concepts
As previously mentioned, storage systems are the platforms that support the processors and processes associated with computers and servers. Storage may appear as RAM (memory on silicon, including flash) and as mechanical or optical storage media (CDs, DVDs, hard disk drives).
Regardless of how or where that storage exists, the management or handling of the media before, during, and after is an important and sometimes overlooked process.
Caring for Media
It comes as no surprise that preventative care for your media assets is something that should happen, but is often overlooked. Understanding what the media can tolerate and still produce reliable data requires a commitment to processes not generally viewed as important to many organizations, both large and small.
Life Expectancy
For most users, the length of time for which the disc remains usable is considered its “life expectancy” (LE). The media’s LE assumes some implied or acceptable amount of degradation. What type and how much degradation is acceptable?
Some physical media can tolerate certain levels of abuse and still reproduce some or all of the digital or image content contained on the media. Others, for a multitude of reasons, may not reproduce any information when subjected to abuse due to storage, handling, or uncontrollable environmental impacts. Data, when recorded to physical media (such as a removable disc), has been captured with certain additional bits of information that are used to properly reconstruct the data should it be incorrectly recovered by the read mechanisms employed by the storage platform.
The classes of error correction can be divided between electronic data correction and physical data correction. The latter, referred to as “end-of-life,” is far more complicated to address than the former.
Correcting Data Errors
Most systems that playback media (audio and/or video) have correction capabilities built in that correct a certain number of errors. Referred to as “error detection and correction,” the playback systems will adjust or augment data errors up to the point when the error correction coding is unable to fully correct those errors. At this point, many differing anomalies will develop depending upon how the media was coded and the sophistication of the playback systems that reproduce the data.
When determining whether data correction is achievable, one of the classifications that hopefully can be avoided is the media’s “end-of-life” (EOL). One means of determining EOL for a disc is based on a count of the number of errors on the disc ahead of or before error correction occurs. Disc failure chances increase with the number of errors. It is impossible to specify that number in relation to a performance problem, that is, either a “minor glitch” or a “catastrophic failure.” Failure modes depend on the number of errors remaining after error correction and where those errors are distributed within the data. Once the number of errors (prior to error correction) increases to a certain level, the likelihood of any form of disc failure, even if small, might indeed be unacceptable, at which time the disc is considered EOL.
CD and DVD Life Expectancy
The consensus among manufacturers that have done extensive testing is that under recommended storage conditions, CD-R, DVD-R, and DVD+R discs should have a life expectancy of 100 to 200 years or more; CD-RW, DVD-RW, DVD+RW, and DVD-RAM discs should have a life expectancy of 25 years or more.
The information available about life expectancy for CD-ROM and DVD-ROM discs (including audio and video) is sparse, resulting in an increased level of uncertainty for their LE. Still, expectations vary from 20 to 100 years for these disc types. Through an accelerated aging study conducted by at the National Institute of Standards and Technology (NIST), the estimated life expectancy of one type of DVD-R disc used for authoring is 30 years if stored at 25 °C (77 °F) and 50% relative humidity.
Blu-Ray Life Expectancy Testing
Experiments by Panasonic engineers with regard to life expectancy and durability examined the symbol error rates (SER) rather than the jitter during data recovery mainly because jitter is more affected by environmental conditions such as dust or erosion. Using 50-Gbyte Blu-ray (BD-R), both the high (36 Mbits/second, 4.92 m/s at 1X) and low (72 Mbits/second, 9.84 m/second at 2X) recording rates were employed in the evaluation. SER is more directly connected with the playability, so it is the “write power” (in the recording process) that is judged during the first practical use of the recording.
To confirm the stability of the recorded data, dependencies on SER read cycles with high-frequency modulation were measured and recorded. Lastly, an acceleration test confirmed the reliability of the disc from an archival stability perspective using a number of prescribed stress tests. The data sets were compared against the Blu-ray Disc specifications when each sample disc was exposed under each condition.
From the inorganic tests conducted by engineers at Matsushita (Panasonic) and reported in the IEEE report (see Further Readings at the end of this chapter), it was concluded that the lifetime of the dual-layer Blu-ray Disc using Te-O-Pd inorganic recording material would exceed 500 years.
Preserving Digital Media
When it comes to the preservation of digital media, particularly physical media (including tape or film-based materials, plastic CD/DVD/BD media, and when portable, media such as XDCAM discs), there are three general categories of environmentally induced deterioration that impact the life expectancy and performance of the media: biological, chemical, and physical (or mechanical).
Biological Decay
This factor includes living organisms that may harm the media. Mold, insects, rodents, bacteria, and algae all have a strong dependence on temperature and relative humidity (RH). Mold and mildew are serious threats to media collections. Any sustained high RH at or above 70% for more than a few days should be avoided.
Chemical Decay
Chemical decay is a result of a spontaneous chemical change to the storage or operational environment. Fading of color dyes in photographs and degradation of binder layers in magnetic tape are examples of decay caused by chemical reactions occurring within the materials themselves. The rate of deterioration depends primarily on temperature; however, moisture will also impact the rate as well. As the temperature of the storage area increases, and as the RH rises, chemical decay will occur at a more exaggerated rate. Chemical decay is a major threat to media that have color dyes and/or nitrate or acetate plastic supports. Cold storage is recommended for film-based materials, and a frozen storage environment is recommended when there are signs of deterioration.
Solid and Gaseous Contaminants
For the successful storage of media collections, users should include a means to control solid and gaseous contaminants that are present in the atmosphere.
Particulates
Particulates are very small-diameter solids that settle on surfaces in storage spaces, which come from outside, when no filtration is provided, or may be produced inside from the debris that results from deteriorating materials or even human activity. Any particulates that come in the form of dust or grit will cause surface abrasion. For tape, images, or plastic media (DVD, Blu-ray), the negative impact from particulates can be quite reactive toward images or data.
Gaseous Pollutants
Such pollutants will arise mostly from outside sources, with the media hampered by air quality, automotive exhaust, and other industrial processes. However, gaseous pollutants can also be produced inside, as a consequence of deteriorating materials or poorquality enclosures. When pollutants are released by a degrading material, they may affect adjacent materials contained in the same storage area. Many routine activities such as photocopying, general maintenance, or construction can introduce ozone, formaldehydes, ammonia, or other pollutants.
Ozone and nitrogen dioxide are high-level oxidizing pollutants that can be damaging to organic dyes, silver images, and image binders. Plastic-based media that utilize organic dyes in some of their processes are equally vulnerable to gaseous pollutants.
Protecting against Pollutants
Large commercial buildings often used cloth (or “bag”) filters to capture particulates as they enter the building. Internally produced particulates are further reduced by filters as the air is recirculated inside the building. Filters aimed at removing gaseous pollutants that enter from the outside are far less common in conventional building environments. Although charcoal filters can remove ozone and some other gaseous pollutants fairly efficiently, they are less effective with nitrogen dioxide (NO2). Although potassium permanganate media can remove NO2, this method is rarely found to be used in conventional buildings, except in more highly controlled environments such as clean rooms.
Generally as a precaution, when bag filters are employed, they should be cleaned and/or changed regularly. Gaseous pollutant filters should be handled by trained, experienced professionals.
Electronic Media Management
There is a lot more to managing and handling of these precious digital media assets than meets the eye. Quite often, the extent of the physical handling of the storage mediums (discs, hard drives, tapes) is limited to the occasional dusting or cleaning of the filtration systems that draw air into or through the chassis. In the case of tapes (videotape or data tape), in general, there is more care given to the operational environment than the storage environment that contains these assets.
There are many ways to protect and/or handle the physical environments in which the media is stored or used. We have covered some of the impacts on the physical handling of the media in previous sections, and any further deliberation would be outside the scope of this book. What we will look at now is how the digital assets (the files and such) are managed by both automated and manual methods.
Let us start first with a foundation definition of the file.
What’s a File
Any collection of data that is treated as a single unit on a storage medium (such as a disk) is referred to as a computer file or simply a “file.” The analogy, in fact the actual term, came from the precomputer office model associated with the filing cabinet. In similar fashion to the manila folder (the file) that holds sheets of paper (the elements of the file) in a filing cabinet, a computer stores files in a disk, with the disk acting as a filing cabinet.
A file can be found and retrieved (accessed), changed in some way (modified), and stored again back on the disk. Multiple hundreds of thousands of pieces of information can be stored on a physically small hard disk drive, far more than can be stored in any regular office filing cabinet.
Files accumulate extremely rapidly when looking at computer systems, laptops, workstations, and servers. They often plague the storage platforms at levels of indescribable proportions, especially when large storage arrays are employed.
One of the management areas that greatly concerns users and affects performance of any storage system is fragmentation.
Fragmentation
Fragmentation is the process of splitting up elements into smaller segments (fragments) and having them scattered randomly all over the storage medium. Files are ideally recorded contiguously, that is, each element is sequentially adjacent to each other.
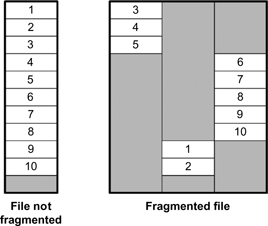
Figure 18.1 File fragmentation.
Disk fragmentation has affected every operating system (OS) throughout history. The root cause of this is based upon several factors, and for the OS, it may reach a magnitude that can severely curtail performance. The OS is often a dynamic instrument, which is constantly updated to protect against viruses, to correct software interdependency issues, to improve performance, and to patch previous versions when anomalies are discovered by the developer. With the propensity to engage a fallback mechanism such as restore points that enable the OS to return to a previous state should it be corrupted, the number of files that get scattered all over the drive increases in untold proportions.
In computer workstations, PCs, or other similar devices, the continual changes that are made when applications are added, updated, or removed will often augment the negative impacts that occur during those processes, resulting in what is commonly referred to as “fragmentation.”
Types of Fragmentation
There are two types of fragmentation that affect storage and computer system performance: file fragmentation and free space fragmentation.
File fragmentation (see Fig. 18.1) refers to computer files that are no longer contiguously spaced in a sequential matter. This creates problems with file access.
Free space fragmentation (see Fig. 18.2) refers to when the empty space on a disk is broken into small sets of scattered segments that are randomly distributed over the medium. Writing to this space is inhibited because this empty space scattering forces the drive electronics and mechanical components to randomly place each of the new file elements into various noncontiguous tracks and blocks that are no longer sequentially accessible.
Figure 18.2 Fragmented free space.

Ideally, free space would all be located in sets of big open spaces on the disk drive; and files should ideally be contiguously recorded onto the disk surface, so they can be sequentially and rapidly accessed and read without having the mechanical latencies of the head arm and rotational wait times of the spinning platters detract from access and read functions.
File fragmentation will cause problems when accessing data stored in computer disk files. Free space fragmentation causes problems when creating new data files or extending (i.e., adding to) old ones. Together, these two types of fragmentation are generally referred to as “disk fragmentation.”
One point that is important to understand when speaking about fragmentation is we are referring to the file as a “container” for data. This is not about the contents (i.e., the “data”) of the file itself. Sometimes the term fragmentation is also used to describe a condition whereby a file has its records (i.e., its “contents”) scattered about within the file, which may be separated by numerous small gaps. Fragmentation of this type may be the results of a problem with an application that maintains the file, but it is not something that is inherent in the operating system or disk file structure itself.
File Fragmentation
When the data associated with a single file is not contiguously located in the same location, that is, it is scattered around on the drive or array, then file fragmentation occurs. File fragmentation can become a real problem as the capacity limits are reached on a single disk, for example, direct-attached storage (DAS).
Temporary files are constantly being created by applications. Every time an application calls upon a file to be opened or created, additional information is created and stored somewhere on the disk drive. Most notable are the files that a word processor creates for backup protection should the app freeze or the user (or some external force) inadvertently force the improper closure of the file or the application, which would also include a crash. These files are usually purged by the application, except in the case of an abnormal or improper closing, as in a crash or write hiccup.
Graphics, CAD programs, and various multimedia or editing programs also create temporary files that allow for repetitive “undo” operations to occur. And of course, the Internet is renowned for creating an incorrigible number of temporary files that are often never cleaned up unless through the conscious management of all the directories, folders, and applications (both internal and external) of the programs resident on the workstation or server.
The proliferation of temp files can sometimes be controlled by the user, and at other times, the user has no control. Third party or integral operating system housekeeping programs can be configured to clean up these leftovers, but they will seldom take the next needed step in storage management, that is, defragmentation.

Figure 18.3 Fragmented record space.
Record Space Fragmentation
In the case of recording, fragmentation may occur at the time an application directs the I/O system to write to the disk. In the example of Figure 18.3, three records are arranged first contiguously and then again with the records separated by empty record space. In the first arrangement, the record space is not fragmented and the files are consolidated into one large area. This provides for good read access and mitigates latencies when the drive heads are instructed to recover the data.
In the second arrangement, the record space is fragmented. This can occur because of improperly synchronized write activities, interruptions in the write processes, or other factors.
Since record space fragmentation is the concern of how the applications are written and not necessarily of the operating or file system(s), this section need not address the topic any further.
Master File Table Fragmentation
The Master File Table (MFT) is a fundamental component of the NT file system (NTFS). The MFT is the master index or lookup point for all the files on an NTFS volume. The MFT maintains a reference to all file names, file attributes, and pointers to the files themselves. In other words, the MFT is that element that keeps track of all the files on a disk.
When the file system needs access to a file, it first must go through the MFT to obtain the file’s location. When the file has been scattered (i.e., fragmented) all over the disk, the MFT must then provide the direction to each file fragment and to all those attributes associated with those fragments. Under a high percentage of fragmentation, tracking this data can be an enormous task. MFT fragmentation is complicated and time consuming to manage; and when uncontrolled, it leads to disk performance degradation during read activities.
There will be one MFT for every NTFS disk. Because the operating system has to go through the MFT to retrieve any file on the disk, fragmentation of the MFT can seriously impact performance. In the Microsoft Windows 7 operating system, the size of the MFT can be reallocated to prevent fragmentation and in turn preserve performance. These topics and work-around remedies should be left to the IT professional, especially when working with media applications from third parties.
Note that in Microsoft’s Windows 7 operating system, the term “MFT” is used in another context. In this domain, the term then means “Media Foundation Transform,” and it refers to a processing model for streaming media and other media-related activities.
System Fragmentation
System fragmentation is another extension of file fragmentation. In this perspective, one would consider the entire system, including a file-level perspective, a disk-level perspective, a volume setlevel perspective, and a complete system-level perspective.
Disk-Level Fragmentation
Many of the previously discussed defragmentation level activities are nonintrusive, that is, they will not (usually) cause harm to the data and do not necessarily require backing up the HDD data prior to execution; however, this is not the case for activities that are designed to “condense” a disk drive.
When it is necessary to perform disk-level defragmentation, this is considered an activity that is “intrusive” in nature. It could be harmful to the data if the application aborts or fails mid-process. The disk-level defragmentation process may be issued on a disk-by-disk basis or on a system-wide basis. You should always have a backup before you perform data intrusive activities such as a disk-level defragmentation command.
Free Space Fragmentation
Free space fragmentation can become a problem when you approach a low capacity level on the hard drive. When there is a small percentage of disk available (free), and one frequently uses this space and follows it up with the deletion of temporary files, then one would be likely to have a high free space fragmentation percentage. What this means is that any remaining free space is scattered all over the hard drive in tiny amounts and in noncontiguous segments.
Ultimately, this impacts any OS’s ability to control file fragmentation. The system then loses the ability to rewrite large growing files into contiguous empty space because there is none. New, large files that are written are now fragmented because of the same issues.
When space is fragmented, any system or application caching files also get spread around all over the disk drive. Many operating systems (even Apple’s OS X) will use file caching heavily. The drawback to having only a minor amount of cache free space is latency, that is, I/O access times are increased as the files and cache spaces are continually exercised at every read or write command. The ability to write and access caches from the same physical area produces a very noticeable increase in speed. Rebuilding the caches after defragmenting can be highly advantageous.
Apple’s HFS + Approach to Fragmentation
The Apple Mac operating system OS X manages file fragmentation by rewriting files into a contiguous space when a file is opened. The triggers for this are when the file is under 20 Mbytes and when it contains more than eight fragments. This preventative, background task is a standard measure aimed at preventing any heavy file fragmentation, but it does not prevent free space fragmentation.
OS X implements Hot File “Adaptive” Clustering in its HFS+ file system (originally introduced with Mac OS Version 8.1 in 1998), which monitors frequently accessed files that are essentially read only and are not changed. The OS then moves these often accessed files to a special hot zone on the hard drive. When the files are moved, OS X automatically defragments them and then places them into an area of the hard drive that allows for the fastest access.
Hot File Clustering is a multistaged clustering scheme that records “hot” files (except journal files, and ideally quota files) on a volume and moves them to the “hot space” on the volume. The hot space on a volume is a small percentage of the file system and is located at the end of the default metadata zone (which is located at the start of the volume).
Defragmenting Solid State Drives
Defragmentation is not recommended for solid state drives (SSDs) of flash memory-based construction. To review, the main reasons for defragging a disk are the following: (1) to limit the amount of times the drive heads must move to a different section of the disk to read the data and (2) to place the majority of your data on the outer edge of the disk where read and write speeds are fastest.
SSDs eliminate both of these reasons. The SSD’s seek times are almost immeasurable compared with mechanical drives, thus moving data to a different section of the flash memory disk is of no value. On an SSD, files need not be placed sequentially on the disk, as there is no degradation in performance over the entire size of the flash memory disk. Defragmentation on an SSD will actually decrease the life expectancy on the drive, as there are a finite number of writes per cell before failure.
SAN Management
The management and administration of storage area networks (SANs) include the configuration of the RAID systems, drive capacity management, and SAN optimization, performance, and troubleshooting. Many of the SANs used in both structured and unstructured data environments are deployed in a virtual machine environment. Figure 18.4 compares a traditional application/operating system to a virtual machine implementation. Note that multiple operating systems (OS) may be integrated through the concepts of the virtual machine layer between physical hardware and applications.

Figure 18.4 Traditional versus virtual architecture.
Complete tool sets that are essential to the management of SANs are available, which can provide real-time, continuous SAN monitoring through the gathering of detailed virtual machine (VM) to logical unit number (LUN) statistics that transact among hightraffic fabric links. Management systems should be able to visualize all the host-VM-LUN conversations and allow for the accurate measurement of application transaction times within the virtualized environment. System monitoring allows for the highlighting of SAN-induced latency issues that can impact service level agreements (SLA) in a commercial activity.
Caution should be raised when looking into system managers, particularly when addressing the multiple elements that the SAN is composed of. Often, these tools are “manager of managers.” They simply collect information from other monitoring tools and then provide a “topology view” that aids in provisioning or capacity planning.
Enterprise-class tool sets, known as Storage Resource Management (SRM) tools, support to a limited extent a heterogeneous SAN environment. SRM tools promote a “single pane of glass” view for most of the administrative functions of SAN management. As information is collected from SAN switch fabric managers, and storage array monitoring tools and hosts, the SRM tools typically may not provide any additional SAN performance or health information beyond what the component element managers themselves may provide. However, they may provide more complete and aggregated reporting, including topology rendering.
When applied to the area of SAN troubleshooting, SRM tools will usually identify those failed components or the data paths that are affected by the failed component, up to and even including the application itself. However, this is just the first step in optimizing how specific applications perform in a virtualized storage or shared environment.
SRM tool products will support a number of services or aids across several dimensions. The broader services will define the degree of heterogeneous device support, how agents are being used on the system, application awareness, recording and reporting on change management, provisioning and configuration, and others.
Using Agents
Software agents are often employed into the systems so as to enable storage resource management, switch management, and monitoring. These tools may utilize software APIs that poll the system and then collect metrics at specified intervals. These prescribed “out-of-band” agents are used to minimize the actual effect of performance measurement on the SAN being measured. They observe and report on the data path and unfortunately may not look at nonperformance-oriented functions like capacity management. Thus, the out-of-band process does not affect capacity reporting, but it does affect performance reporting in an inaccurate way.
By design and function, SANs are optimized for two primary tasks: one is to move the data through a system to its destination at the fastest possible interval and the other is to ensure the integrity of the data as it traverses the systems. When the traffic load on the network is at its highest, this software agent’s priority will adjust (i.e., fall) in an effort to allow for the SAN primary functionality, that is, rapid data movement, data integrity, and maintainability.
Some agents will take inquiry cycles no matter what the current application or transaction load may be. This invokes impertinent data that then skews the actual meaning of the information obtained. The agent may then either ignore the cycle or provide a reading at a time that is irrelevant to the performance of the SAN at that instant when the readings were taken. What is needed most is a 24 × 7 monitoring process that ignores nothing and invokes triggers based on real-time events that can be used to affect the overall performance of the system at the application and the storage level.
Application and Virtual Machine Monitoring
These monitoring tools are used for optimizing the server environment. Most are inadequate for network monitoring and analysis or are incapable of finding root cause performance bottlenecks. Knowing that the biggest cause of application latency is in I/O, some tools in this category lack the ability to tune the overall environment so as to obtain a higher application performance and higher server consolidation ratio.
SAN Switch Fabric Management
SAN switch fabric managers (switch monitoring tools) are primarily designed to enable proper switch provisioning, zoning, and capacity management. These tools manage and secure the flow of data across single-vendor supplied multiple fabrics at the level of a central view. The management tool set is used to measure, monitor, and achieve the goals related to SLAs, and aid in promoting security and compliance while containing operating expenses.
Storage Virtualization Monitors
The aim of storage virtualization is to manage storage as a single resource. Virtualization combines storage capacity from multiple, often heterogeneous disk systems into a single reservoir of sufficient capacity, which can be managed as a business resource. The components of a virtual storage platform will include the host, switches, appliances, and array-based storage. In order to increase storage utilization, the storage virtualization monitor will provide the host applications with more efficient access to capacity through flexible provisioning.
Today’s practices include the configuration of storage solutions into tiers, which are comprised of varying forms of storage components, such as Fibre Channel drives, SATA or SAS drives, and associated switches. This process mandates the processes of data migration in order to balance capacity against the required bandwidths per the applications that they address. The managers then match the application to the SLA and migrate the data to the proper storage tier.
These tools may further support advanced copy or snapshot services to enhance data protection and further provide varying levels of management reports. However, many of the tools, like the others described previously, make little attempt to specialize in performance measurement or analysis.
Real-Time Reporting and Monitoring
When optimizing SAN performance, whether for a VM or when the SAN is the principal platform for media-centric file interchanges, a tool set that allows for real-time monitoring and filtering and will calculate statistics based on checking all of the Fibre Channel frames traveling through the VM infrastructure and the Fibre Channel SAN is important.
Traditionally, most of the SRM and switch monitoring solutions will take SAN statistics only at a set of preset intervals. In this case, the metrics are only sampled or averaged and do not provide a sense of how the SAN is performing on an instantaneous or a continuous basis. Detailed performance information is usually not captured especially when there is a burst of data or when a large amount of traffic passes through the system between the sample intervals. Once these statistics are aggregated, important instantaneous data such as the total capacity on a particular port is no longer visible. Furthermore, this practice of interval monitoring cannot convey how the individual application transactions or traffic flow is handled on any particular port at any particular time.
This is analogous to what happens when watching a video stream where there are thousands of frames being presented to the storage system or the decoder. Most of the video is seen as unimpaired, but the one or two frames that get skipped or dropped are not noticed, and the system does not report any problems because from an “average” perspective, nothing was “visibly” lost.
Application L atency
SANs are often blamed for problems that occur as a result of an application hiccup. With today’s SAN management tools, any root cause analysis could take weeks of time to analyze or diagnose. By having a tool set that utilizes advanced filtering or alerting mechanisms, the number of false positives is reduced and the administrator is allowed to concentrate on real issues affecting SAN performance.
Through historical trending, the administrator can use the tool sets to help identify when a problem manifested itself and then employ various metrics that can capture in precise time what happened. Such tools often can automatically trigger a protocol analyzer that can capture the relevant data and speed up the process of root cause analysis.
The best performance metric is knowing what effect the SAN has on an application’s response time when it is captured or recorded at every transaction. This diagnostic then determines what is referred to as “application latency.” To get a perspective on this encumbrance, many analysis tools will be looking only at I/O operations per second (IOPS) or data throughput in Mbytes/second to come up with an overall performance number. This is akin to watching a speedometer and then equating that observation to predict how long it takes to go to a location on a highway that might be congested due to an unforeseen automobile accident. If you extend that analogy and look at a number of trips along this corridor and then equate that to confirm your average speed, you would never know (i.e., when statistically averaged) if one of the excursions took longer than another or if you were diverted or stalled because of that unforeseen complication.
Finding what the effects of application latency are is like using a stopwatch to report just exactly how long each trip took down a highway during a certain road condition and at a known traffic volume. With this type of latency measurement diagnostics, one will know in real time if any one of those trips might have taken longer than it might otherwise normally have taken.
Data movement when in a storage environment must overcome many obstacles as it moves through servers, switches, physical interfaces (cabling, converters, etc.) and onto or away from the storage medium. The proper management of these systems during peak load times (e.g., rendering or collaborative editing) and the ability to reconfigure the SAN for specific workflows can be accomplished with the appropriate tool sets in place.
Furthermore, when changing configurations such as when adding more storage or consolidating SAN islands, performance metrics can be captured and compared so as to apply the right functions and applications to satisfy demands from the users or associated other systems.
NAS Management
Like the SAN, a NAS environment can provide needed storage solutions with respect to capacity while controlling costs within the parameters defined by the organization’s workflows or activities. There are numerous configurations and solutions that can aid in handling issues that affect capacity, growth, consolidation, control, and cost.
Integrated NAS Boxes
Traditionally, NAS boxes have come as either gateways or integrated boxed solutions. The NAS gateway will use a front-end file server with external back-end storage attached via Fibre Channel (FC). The integrated NAS box will use a front-end file server with back-end storage integrated into a single storage subsystem. The number of options available in an integrated box solution is limited from the back-end storage side, whereas a NAS gateway can potentially provide support for storage from many manufacturers.
NAS Consolidation
The need for consolidation of NAS storage components arises when the overall system performance can no longer be effectively scaled or when the limits on capacity are reached beyond which another resolution is necessary. It may also be used when organizations already have a SAN solution in place and want to mitigate the number of discrete NAS implementations (i.e., curb “NAS sprawl”) throughout the enterprise.
There are at least four basic ways to consolidate NAS data:
•Acquiring more, larger, or better versions of those NAS gateways or integrated NAS filers that are already in use
•Clustering of the file systems (where large computer clusters already exist) to provide high-performance access to file system data
•Employing parallel file systems, similar to those of clustered file systems, which can provide concurrent access to a single file across a number of nodes that are operating in parallel
•Using a set of NAS aggregators that consolidate data across a number of distinct NAS filers, both as gateways and integrated NASs.
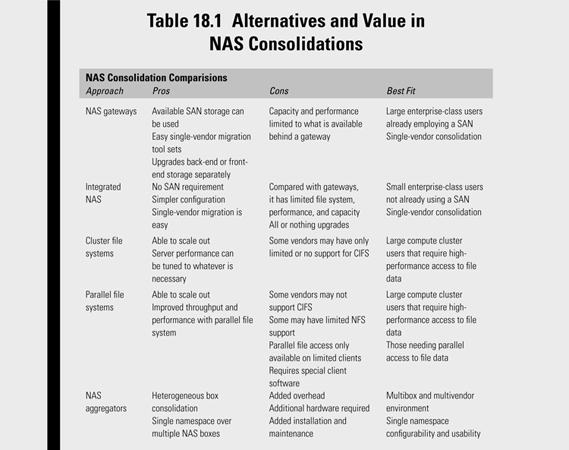
Table 18.1 summarizes many of the differences associated with NAS consolidation.
NAS Gateways
When organizations are significantly vested with NAS storage, and they already utilize a SAN infrastructure independently, the NAS gateway is a means for consolidating their NAS data onto SAN storage. The major NAS vendors all provide tools for data migration from their NAS storage to their representative gateway products. Support is also available for all the NAS protocols and most of the operating system environments.
Although gateway performance and capacity are quite good, the NAS gateway approach falls short when compared with other available nontraditional alternatives. Gateways tend to provide for more flexibility and scalability when compared with integrated NAS boxes. If the requirement is only to upgrade backend storage performance, the NAS gateway allows you to do that separately from the NAS front end.
NAS gateways are often configured as blades in a high-performance storage subsystem. Blades are available that include local storage. These types of blade sets may be combined into a single chassis, up to the limits of the slots in the blade chassis.
Users should understand the constraints of this kind of blade architecture. Blades may support one or more file systems; however, be sure to understand if files can or cannot be shared across blades.
The operating environment needs to be determined to complete interoperability. The gateway may also include high-end capabilities such as sophisticated file replication and mirroring, or automatic volume management, which lets administrators increase file-system space without client intervention. Consider whether the blade or NAS gateway will support alternative backend storage.
NAS storage providers offer NAS gateway products based on Windows Storage Server (WSS) software. Most WSS products are configured as gateways that provide similar base functionality. Client support on Windows platforms using WSS is very tight and allows for easy deployment. When using CIFS or NFS and Windows Distributed File System (DFS), WSS in turn provides for a clustered file system that is accessible across all active nodes and configures nodes as active for servicing data or as passive for cluster failover.
Some NAS gateways may offer both file and block access through one system. Others may employ block access that goes directly to back-end storage and bypasses the filer altogether. In this application, both the filer front-end and back-end storage can be expanded transparently to client access, making storage provisioning easier. This concept lets the nodes act as a cluster, providing file access to the shared back-end storage. File systems should be capable of being updated a node at a time and be able to be read by multiple nodes.
In a node failover mode, any active node should be capable of picking up the file services of the failing node. Additional services such as snapshot, asynchronous local data mirroring, virtual servers, and full Network Data Management Protocol (NDMP) support may also be desired.
NAS gateways should seamlessly integrate into missioncritical enterprise-class SAN infrastructures. They should allow users to deliver NAS and block solutions, while also dramatically increasing utilization of the current infrastructure. Organizations can gain the advantages of enterprise-class Fibre Channel storage connectivity without incurring the costs of physically connecting each host to the SAN infrastructure. This optimizes storage usage and preserves future scalability.
Nontraditional Approaches
Of the many secret sauces employed in NAS gateways, vendors often tout their products as a means to achieve independent performance scaling for both the back-end and front-end storage.
Alternative, nontraditional implementations go a step further by not only allowing a scale-up (vertical growth) of performance in the front end achieved by increasing node horsepower but also providing a scale-out (horizontal growth) of the front end by adding multiple independent nodes that can access the same single namespace.
The following sections discuss three nontraditional approaches to NAS consolidation.
Clustered File Systems
For operating across multiple nodes, usually at least eight or more, clustered file systems can be deployed using commercial off-the-shelf (COTS) hardware and standard operating system software. Nodes may be metadata nodes, storage nodes, or hybrid (supporting both metadata and storage services).
The performance of a cluster file system can be throttled up to mostly any degree desired by adding additional nodes to the cluster.
NAS box clusters make a claim of high availability; however, the box cluster implementations are not quite up to the performance available from a clustered or parallel file system product. True clustered (or parallel) file systems will scale performance linearly in proportion to the number of nodes and still provide access to the same data across all the added nodes.
Clustered file systems are used when large compute clusters need high-performance access to file system data. The downside is that clustered file system products may not be as useful for Windows users, as some systems offer little to no support for CIFS, noting further that this may be a vendor-specific condition that warrants closer examination.
Parallel File Systems
Similar in construct to clustered file systems, a parallel file system implementation provides concurrent access to a single file across a number of nodes that operate in parallel. Parallel file systems require that the file data be striped across multiple nodes, as well as any client-specific software needed to process all the file parts simultaneously.
Those that employ large compute clusters are offered the advantage of massive performance scalability, which is inherent in parallel file system products. Nonetheless, it is always important to check if a parallel file system will support the intended operating systems, as there may be some limitations, for example, outside of Linux.
A common feature of the nontraditional approaches to NAS consolidation is a global namespace (GNS). A GNS enables a singlemount point or share for a number of file systems. By providing a single share for a number of file systems, GNS presents a central management point for the files under its domain. WSS along with other products may use Windows DFS to provide a GNS across several CIFS servers.
NAS Aggregators
A tool or system that provides support to NAS architectures is called a NAS aggregator. In appearance, the NAS aggregator acts as a gateway for a series of NAS devices or NAS head gateways. The aggregator allows you to consolidate those files stored on NAS devices into a single domain, enabling the user to add more NAS storage and to then manage those files that are stored on the NAS.
Installation of a NAS aggregator is really no more complicated than adding a NAS gateway. However, the user needs to make some decisions about the structure of the new NAS storage environment, including how it will function before beginning the installation. The following sections are aids to determining how, why, and what to do when selecting and installing a NAS aggregator.
Need for NAS Aggregators
When looking to storage system consolidation, particularly when there are multiple NAS systems from differing vendors, users may want to consider a NAS aggregator. In such cases, a NAS aggregator can be very useful and may actually result in saving costs, as well as being an aid to mitigating management headaches. A word of caution is urged; the more one departs from the consolidation picture, the more the problems inherent in NAS aggregators are likely to affect the operation.
NAS aggregators are not inexpensive. They may be found in hardware and some in software. Regardless, they will all have to be managed. Whether in hardware or software, aggregators will add another layer of complexity to the storage system; and depending upon the configuration, they may limit the NAS bandwidth (especially in-band versions).
A stand-alone aggregator, especially one of the hardwarebased versions, will introduce a sin6/29/2012 10:23:50 AMle point of failure into the NAS system. Most aggregators will be employed in pairs at which time they may also be used to provide failover.
Before deciding on an aggregator, one should consider other options. If the consolidation needs are moderate, one might be better off simply moving up to a larger NAS appliance or gateway.
NAS Aggregator Planning
NAS aggregators will introduce major changes into the storage architecture. At the virtual level, by combining the view of files stored on various NAS file systems, the aggregator then requires the storage administrator to reexamine how this new storage platform will be organized. This is beyond the physical changing of the locations of the files in storage; the aggregator now reorganizes the storage architecture so that there is a new view of the file system that both administrators and users can work with.
Making optimal use of this capability requires careful and precise planning. The administrator should map out any new structure before selecting an NAS aggregator and then choose one that will best support the file views that he or she wants to use in the environment where it is applied.
Remote Mirroring of NAS Aggregators
Support for remote mirroring, which is the duplication of data between sites, is yet another consideration for NAS aggregators. If remote mirroring is part of your organization’s data protection scheme, you should take this into account prior to committing to any hardware selections.
Remote site replication across heterogeneous NAS boxes is a protection scheme that provides for quick access to remote data if the primary site’s data services should failover. High-availability capabilities will include the option of two boxes configured as an active/active or active/passive pair.
There are three different levels of performance available in varying product lines. Bandwidth requirements, as with any in- band appliance, are important considerations that must be analyzed for any deployment. Some remote mirroring applications will provide for policy-based migration of files between the primary and remote sites. Policy scripts are used to migrate files from an active box to a less active one to level performance and free up the high-performance storage assets. In provisioning filelevel migration and so as to retain quick global name access to both systems, some vendors will duplicate all the file directory information at its appliance.
Other software-only implementations may use out-of-band scenarios such as those employed using Windows Active Directory, which fulfill the GNS requirement. Such an out-of-band appliance should not hinder file read-write operations, but users may find it inhibits fully transparent migration of data from one NAS box to another. In these models, much of the manual work required to migrate data from one share to another is eliminated through automation.
Migration Policy Planning
Most aggregators will allow the users to automatically migrate files between aggregators. Through the use of sophisticated policy management, load balancing is achieved and those heretofore manual file migration tasks can become almost fully automated. Such policybased migration requires that a thorough plan be developed for data migration, something that users need to explore before selecting the support hardware for any proposed configuration.
NAS Aggregator: In-Band versus Out-of-Band
Aggregators may be in-band, out-of-band, or even hybrid in nature. With an in-band aggregator, reads and writes flow through the appliance on the way to and from the storage. This form of aggregator is likely to create a bandwidth problem, as well as adding overhead to current storage operations.
Out-of-band aggregators need not require reads and writes to go through the aggregator. They instead rely on a file system service (such as Windows Active Directory) to provide the GNS necessary to consolidate files. This mode prevents bandwidth limitations for storage operations. However, these out-of-band products do not see as deeply into the data and typically are incapable of automatically migrating files from one NAS system to another. In this model, a “system” may be either a stand-alone NAS appliance or a NAS gateway.
Hybrid products are thought of as out-of-band appliances, but in fact, they will use in-band techniques to migrate files. It is more complicated to automate file migration with a true hybrid implementation, so users should thoroughly investigate the plans and techniques for hybrid systems.
Snapshots
Functionally, a “snapshot” is a point-in-time copy that enables users to protect their data without any performance impact and through a minimal expenditure of storage space. The technology enables a point-in-time replication of the file systems ranging from a single file to a complete data capture for disaster recovery purposes. Vendors providing snapshot capabilities state they can make copies in less than one second, regardless of volume size or level of activity on the system; with as many as 255 snapshot copies per volume, which instantly creates online backups for user- driven file or system recovery.
A snapshot is a locally retained point-in-time image of the data presented on a system at the time of capture. Several companies employ snapshots as part of their data security, protection, or recovery schemes. NetApp uses their snapshot technology as a feature of their Write Anywhere File Layout (WAFL®) storage virtualization technology, which is a part of the microkernel that ships with each NetApp storage system.
Snapshots are used by system administrators to enable frequent, low-impact, user-recoverable backups that are “frozen-intime,” usually read-only views, of a volume that provide an easy access point for older versions of directory hierarchies, files, or LUNs. A snapshot will greatly improve the reliability of a backup and will generally incur only a minimal hit to performance overhead. Snapshots can be safely created on a running system, providing near-instantaneous, secure, user-managed restores of data should a write failure occur or a storage system become temporarily disabled.
Users should be able to directly access replication copies that allow them to recover from accidental deletions, corruptions, or modifications of their data. The security of each file is retained in the snapshot copy, and the restoration is both secure and simple. Snapshots further aid in meeting MPAA usage audits, security, and forensic analysis.
Virtual Snapshots
When used in conjunction with a virtual machine infrastructure, storage array-based snapshots are touted for business continuity, disaster recovery, and backups because of their ability to create these “point-in-time” images of virtual machines (VMs). It is important to understand how virtualization affects storage array snapshot use, as incorrect usage could render storage array snapshots unreliable or valueless.
In this case, the snapshots to which we refer are not VMware-like virtual machine snapshots; rather, they are the snapshots provided by the storage array directly. These snapshots are, by default, not integrated in any way with VMware serving platforms, so a few extra steps are necessary to ensure reliability, consistency, and usability.
VM-level file system consistency is the key to ensuring consistent and usable snapshots. Users need to understand that there are multiple levels of operations that will continually occur simultaneously.
There are three types of snapshots that can be created in a VMware environment:
Hot Snapshots
These will require no downtime, yet they run the risk of proliferating inconsistent data. In a hot snapshot, the virtual machine is live at the time when the snapshot is taken. The guest operating system will be given no warning or direction to flush the I/O buffers, nor is the host given time to commit writes to the storage array. This results in a high risk level in file system inconsistency for the guest OS, which will then force a file system check upon reboot. Although the file system may recover, applications running in the guest OS (such as databases and e-mail systems) may not recover. This is where there is a risk that data loss may result should the storage array snapshot not be restored. The use of hot snapshots should be avoided in order to alleviate potential problems with VM-level file system inconsistency.
Cold Snapshots
They require the most downtime yet provide the greatest guarantee of VM-level file system consistency. To obtain a cold snapshot, one must shut down the virtual machine, take a snapshot, and then restart the virtual machine. Although this can be scripted, it still requires downtime that operations must take into consideration.
Warm Snapshots
This snapshot mode will require less downtime but will require a virtual machine—level file system check (i.e., “chkdsk” or “fsck”), once the virtual machine has recovered from the warm snapshot capture. In most cases, the NTFS or EXT3 file system journaling will prevent data corruption, but because the VM is paused or suspended while the snapshot is taken and resumed after the snapshot is complete, file system recovery techniques are required to ensure that no data corruption has taken place.
Scripts are generally used in these instances, and they will generally invoke the use of the sync driver that helps to flush the virtual machine file system buffers to the disk as a support method to ensure file system consistency.
In general, the use of cold and warm snapshots introduces varying degrees of downtime and service interruption for virtual machine applications. These interruptions may be intolerable to the organization.
Combining Snapshots
One way to mitigate the data inconsistency risks associated with snapshots is to combine storage array snapshots with virtual machine snapshots. Products from VMware, which are initiated through and managed with the VirtualCenter application, employ a differencing disk where all the changes to the virtual machine’s file system are cached. Storage array snapshots taken in conjunction with a VMware snapshot will behave much like the warm snapshots described in this section. Under this operation, the virtual machine initiates a file system check, but in this implementation, there should be no service interruption or downtime incurred.
When these solutions are used in conjunction with the published best practices from the SAN supplier, they can help to ensure that the storage array-based snapshots of the virtual machines remain usable in the event they are called upon.
Data Deduplication
With the global extension of collaborative workflows, data is routinely and continuously replicated to multiple locations that are geographically separated from one another. The result is an enormous amount of redundant data creation, much of which is unnecessary once the principle activities associated with those files are complete.
Data deduplication is a method for mitigating storage capacity limitations by eliminating all redundant data in a storage system. In this practice, there becomes only a single unique instance of the data that is actually retained on storage media. The storage platform may be either disk or tape based.
Any instances in the applications that will access the redundant data will be replaced with a pointer that targets the location of the unique data instance. In e-mail, for example, a typical system could contain multiple instances of the same 1-Mbyte file attachment. When the e-mail platform is archived or backed up, all of these instances are saved, which, if there are a hundred instances of each attachment, could end up consuming 100 Mbytes of storage space.
Through the application of data deduplication, only a single instance of the attachment is actually stored. Then, for each subsequent instance, a reference is made back to that single saved copy. Thus, the 100 Mbytes of storage consumed would be reduced to only a single 1-Mbyte instance, saving 99 Mbytes of storage space.
Data deduplication is often called “intelligent compression” or “single-instance storage.” It offers other benefits, including the more efficient use of disk space, an allowance for longer disk retention periods, and an easier approach to better recovery time objectives (RTO) for a longer time. Data deduplication further reduces the need for extensive overburdening tape backups.
The data deduplication process can occur at any point in the backup path, including at the client (the source system), the backup media server, or at the backup target. When employed for remote site mirroring, replication, or off-site archiving/disaster recovery applications, data deduplication can further reduce the amount of data that is sent across a WAN.
File- or Block-Level Deduplication
Data deduplication operates at either the file or the block level. Block deduplication looks within a file and saves unique iterations of each block. File deduplication eliminates duplicate files, but this is not a very efficient means of deduplication.
Each chunk of data is processed using a hash algorithm such as MD5 or SHA-1 (or later). These two commonly used hash algorithms are described next.
Message Digest 5 (MD5)
Message digest functions, also called “hash functions” are used to produce digital summaries of information called “message digests” (MD), which are also known as “hashes.” The MDs are commonly 128 bits to 160 bits in length and provide a digital identifier for each digital file or document. MD functions are mathematical functions that process information so as to produce a different message digest for each unique document. Identical documents should have the same message digest; however, if even one of the bits for the document changes (called “bit flipping”), the message digest changes.
Cryptographic hash functions are deterministic procedures or algorithms that take an arbitrary block of data and return a fixedsize bit string that is known as the “hash value.” This “message digest” serves as a means of reliably identifying a file.
MD5 is the most recent of the message digests in use today. MD5 is a widely used 128-bit cryptographic hash function, which is specified in RFC 1321, and it is typically expressed as a 32-digit hexadecimal number. MD5 is employed in a variety of security applications but is commonly used to check the integrity of files. However, MD5 has been shown not to be particularly collision resistant, making MD5 unsuitable for applications such as SSL certificates or digital signatures (which rely on this property). In applications where security and reliability of the data is extremely important, use of alternative cryptographic methods should be considered.
Secure Hash Algorithm
SHA-1 (for Secure Hash Algorithm), is a hash function developed by the National Security Agency (NSA) and published by the National Institute of Standards and Technology (NIST), Information Technology Laboratory, as a U.S. Federal Information Processing Standard (FIPS).
A hash function takes binary data, called the message, and produces a condensed representation, called the message digest. A cryptographic hash function is a hash function designed to achieve certain security properties. SHA-1 is the most widely used of the existing SHA hash functions and is employed in several widely used security applications and protocols.
According to NIST, research by Professor Xiaoyun Wang in 2005 announced a differential attack on the SHA-1 hash function, which claimed to identify a potential mathematical weakness in SHA-1. The attack primarily affects some digital signature applications, including time stamping and certificate signing operations where one party prepares a message for the generation of a digital signature by a second party, and third parties then verify the signature. There are many applications of hash functions, and many do not require strong collision resistance. Keyed hash applications, such as Hash-based Message Authentication Code (HMAC) or key derivation applications of hash functions, do not seem to be affected.
Nonetheless, this potential attack led to the development of SHA-2, which is algorithmically similar to SHA-1 but includes a family of hash functions, namely SHA-224, SHA-256, SHA-384, and SHA-512, which are used in digital signature applications. As of this writing, there is a yet another new hash algorithm, to be called SHA-3, which will augment the hash algorithms currently specified in FIPS 180-2, the “Secure Hash Standard.” SHA-3 intends to convert a variable length message into a short message digest (MD) that can be used for digital signatures, message authentication, and other applications.
NIST has decided to develop one or more additional hash functions through a public competition, similar to the development process of the Advanced Encryption Standard (AES). The NIST “hash function competition” is scheduled to end with the selection of a winning function in 2012.
Identifying Files
This hashing process generates a unique number for each part which is stored in an index. When any file is updated, only the changed data itself is saved. If only a few bytes of a document or presentation are changed, then only those blocks that were altered are saved. This eliminates the requirement to save the entire file again, plus retain the original, as the changes to just this one segment would not constitute an entirely new file. This behavior makes block deduplication far more efficient. The downsize is that block deduplication takes more processing power and requires a much larger index to track the individual pieces.
Hash Collisions
When a piece of data receives a hash number, that number is compared with the index of other existing hash numbers. If that hash number is already in the index, the piece of data is considered a duplicate and does not need to be stored again. If the hash number is unique, the new hash number is added to the index and the new data is stored.
In rare cases, the hash algorithm could produce the same hash number for two different chunks of data. This is known as a “hash collision” and is the reason that this method causes a potential problem with deduplication. When a hash collision does occur, the system will not store the new data because it checks that its hash number already exists in the index; this is known as a “false positive” and results in a loss of that data.
Some products will use a combination of hash algorithms to reduce the possibility of a hash collision; and others are examining metadata to identify data and prevent collisions.
Delta Differencing
Also known as “delta differential,” this is a technique used to make the backup processes more efficient. Delta differencing involves examining a backup file set and locating the blocks or bytes that have changed since the last backup period. In similar fashion to data deduplication, any changed data is sent to the backup target locally via the local area network (LAN) or to a virtual tape library (VTL), or to even a remote storage location via a wide area network (WAN).
Delta differencing is a time-saving function. Enterprise data sets generally change by only a small percentage each day. The complete backup is essential when it is the initial duplicate of the data set; but to routinely do a full or partial/incremental backup is cumbersome and time consuming. For these reasons, organizations often defer complete backups to the weekends, which lead to an unacceptably large recovery point objective (RPO).
The delta differencing approach gathers and saves only the changed data. With this technique, it is possible to perform faster and more frequent backup cycles without monopolizing the LAN or WAN bandwidth. The smaller backup segments use available storage space far more efficiently and forego the many file duplications that result in wasted space in repeated full backups.
A facility with several hundred terabytes of storage may only change by a few hundred gigabytes each day. A complete backup of the storage could take many hours (or even days), whereas a delta differencing backup can update the complete backup with any “daily changes” in only a few minutes or hours.
Replication
Data replication is yet another practice that protects the stored information by making a complete duplicate copy of the data and storing it in another location. In grid storage, this information is “sliced” into segments and then placed into another location on the storage platform so that it can be either used by others (which increases bandwidth) or used as a redundant set of data in the event the primary set is compromised.
Many different approaches to replication are employed by vendors and by users. Replication is an alternative to RAID, although in some perspectives, replication is a close cousin to mirroring. The differences are that in replication, there is a full 1:1 hit for each duplicated set of data. If the replication factor is 2, then it requires twice as much storage to achieve that level of protection (which is a 50% hit in capacity). The counterpoint to that is in replication, the drives employed usually cost less than for high-performance, mission-critical applications; and the need for RAID controllers is preempted by the software applications that manage the placement and tracking of the data slices.
In the video media domain, Omneon (now a part of Harmonic), has built a series of products around this replication concept, which they call “MediaGrid.” The storage principles employed in Avid Technology’s Unity “ISIS” (Infinitely Scalable Intelligent Storage) platform take a similar approach to replication, but it is referred to as redistribution.
Time and Place
The continued growth of data storage is becoming almost unmanageable. Recently, in a survey of users conducted by Enterprise Storage Group (ESG), users stated that they expected their annual storage growth to be between 11% and 30%. An additional 28% of those respondents are expecting their storage growth to be greater than 30% annually.
The price of storage is not limited to just the hardware. Escalating power and cooling costs and scarce floor space pose a serious challenge to the “just buy more disks” or “we’ll wait for the 2-TB drive” approaches. In practice, data deduplication is often used in conjunction with other forms of data reduction including compression and delta differencing. Collectively, these technologies can enhance a well-designed storage plan, one that is coupled with increasing disk/platter densities, larger disk drives, and faster performing drives such as solid state disks.
Media Production Deduplication
It is unclear, as of this writing, if there is a place for deduplication in the media-centric storage environments, especially on the postproduction side. Compression technologies for video media when the images must be retained in 1K to 4K resolutions are not acceptable, except during the previewing or off-line editing functions where proxies or acceptance dailies are involved. Thus, the storage demands remain quite high throughout the postproduction workflows and processes.
The concept of data deduplication is potentially practical when considering backups; however, when looking at routine daily production operations, it is the individual applications such as editing, compositing, and rendering that manage their data sets independently from the central storage. This brings challenges to identifying what is duplicated data and what is duplicated “scratch” data. Backups, in this environment, are used mainly for protective purposes, whereas the “scratch data” are caches that allow the applications to function rapidly and efficiently.
Many in the media and entertainment space are still debating the value or requirements for data deduplication. The argument is expected to continue and may become the responsibility of those who manage cloud-based storage solutions.
Further Readings
Comer, D. E., & Stevens, D. L. (1993). Vol. III: Client-server programming and applications. Internetworking with TCP/IP. Department of Computer Sciences, Purdue University. (pp. 11. ISBN 0134742222). West Lafayette, IN 47907: Prentice Hall. http://www.diskeeper.com/fragbook/intro.htm
A collaboration between the National Institute of Standards and Technology (NIST) and the Library of Congress (LC) on Optical Media Longevity. http://www.itl.nist.gov/iad/894.05/loc/index.html
Further information about the testing of BD-R life expectancy can be found in the referenced document:
Miyagawa, N., Kitaura, H., Takahashi, K., Doi, Y., Habuta, H., Furumiya, S., Nishiuchi, K., & Yamada, N. (2006). Over 500 years lifetime dual-layer blu-ray disc recordable based on Te-O-Pd recording material. Montreal, Canada: AV Core Technology Center, Matsushita Electronic Industrial Co., Ltd., as it appeared in Optical Data Storage 23–26 April 2006.
Further information on the NIST cryptographic competition for SHA-3 can be found at the following website: http://csrc.nist.gov/groups/ST/hash/index.html