
13
METADATA AND MEDIA ASSET MANAGEMENT
Since the advent of videotape, broadcasters and enterprise class media organizations using audio, video, and rich-media have employed Media Asset Management (MAM) systems to aid in the storage, cataloging, and retrieval of static and moving media assets. Those MAM systems have typically remained a comparatively separate function from the production, playout, and distribution sides of operations. More often than not, only individual tasks such as simple cataloging have been integrated into the many OEM systems that include some degree of MAM. Serving devices, such as videoservers or library management systems (LMS), like Sony Broadcast’s LMS product line, needed these features to manage the videotape or digital files contained on them. Given the uniqueness of these early requirements for MAM, the OEMs would typically write their own software and integrate it directly into their products. This practice changed once videoserver systems emerged.
Broadcast television automation systems have also carried MAM components in their program and commercial playout platform, up through and including the current evolution of videoservers. Newer “digital broadcasting” platforms that run on commercial IT-type hardware (e.g., the Omnibus iTX platform) would also manage these assets with their own flavor of MAM.
Until recent times, with the proliferation of file-based workflows and the growing scale of storage systems, what has been missing in a MAM infrastructure is the ability to fully integrate media asset management across the entire production workflow from planning, to scheduling and acquisition, through broadcast release, packaging, distribution, and archiving. New dimensions in information technology now make it possible to gain a much richer degree of integration, one that marries media and management into a harmonious operating environment across the enterprise.
This chapter will look at the fundamentals of media asset management as it applies to moving media platforms and digital storage systems utilized in the production, play to air, library, and archive processes.
KEY CHAPTER POINTS
- Identifying the terminologies associated with the management of various forms of moving media
- Defining how systems control or process information about assets that are media centric (i.e., contain audio or video), and describing their differences
- Metadata—what they are, the types of metadata, and why metadata are an essential element in media asset management systems
- How collaboration, workflow, and interoperability are affected by media asset management systems and their implementation
- Overview of Web-based and other media-based asset management services, for example, Dublin Core, PBCore, SOAP, REST
- Intelligent integrated media asset management, gluing the entire ecosystem together
- Assessing how storage systems for media asset management are deploying, including archive
Media Management Systems
Exploring the topics related to managing media centric assets, one finds there have been a number of similar terms applied to essentially a common category of topics. The terminologies have emerged from various segments of cataloging, searching, and retrieval-related activities, such as libraries, print-based publishing, and the Web:
Media Asset Management (MAM)
Content Management Systems (CM or CMS)
Production Asset Management (PAM)
Digital Asset Management (DAM)
Asset Management Systems (ASM)
For clarity, this chapter will focus mainly on media file types, which generally include audio, video, and images; in other words “media” asset management (MAM) in a digital environment. We will touch upon the parallels found in Web systems, but that topic is a much broader one that will not be addressed in depth.
Media Assets and Content
In its most fundamental form, a media asset is a form of content. Content can be information that is found in unstructured, weakly structured, and highly structured forms. These forms of information, as content or media assets, are made available to users through the physical components of electronic storage, networking, and serving systems. These assets may be used by both humans and machine-based entities.
Media assets consist of multimedia-based unstructured information objects such as pictures, diagrams, presentations, and other rich-media such as those comprised of audio and video essence. Before information becomes an asset, it may be referred to as a media information object, a component that only presents information, and that becomes more valuable when structured metadata are linked with that object (see Fig. 13.1). Once metadata are included, the media asset becomes more available, is searchable, able to be repackaged, and can be associated with databases that allow integration of the metadata records for secondary, extensible purposes.
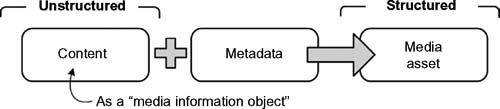
Figure 13.1 Content plus metadata creates a media asset.
Content Management System
The content management system (CMS) is a collection of procedures that will be used to manage workflow in a collaborative environment. While CMS is not necessarily specific to any particular environment, in recent times, CMS has gained more use in Web-based applications than in enterprise database-like systems. This set of procedures could be manual or computerbased, and will allow accessibility for the purpose of contributing to and sharing stored data across the enterprise or across the Internet.
In a CMS, data may be defined as documents, rich-media, movies, images, graphics, phone numbers, scientific data, etc. CMSs are frequently employed in the processes of storing, controlling, revising, enriching, and publishing that data or documentation. For closed environments (such as a corporate intranet), the CMS controls access to stored data based on user roles and permissions, aimed at defining what information each user may be permitted to view, copy, download, or edit. The CMS further supports the processes of storing and retrieving data so as to reduce repetitive or duplicative inputs.
Web-Based CMS
With the prolific use of the Web for information search and retrieval, the terms content management and content management system have in recent years become much more focused on Web-based information management. When viewed from this perspective, a content management system is designed so that it becomes the control element for Web-based content. The CMS in turn is the support conduit for the Web master or website’s content contributors.
Digital Asset Management
The management tasks, decisions, and processes surrounding the ingest, annotation, cataloguing, storing, retrieval, and distribution of digital assets is referred to as digital asset management (DAM). Media asset management (MAM), which works primarily with digital images (photographs), animations, audio (music or speech), and video, is a subcategory of DAM (see Fig. 13.2). The term DAM also references those protocols used for the downloading, renaming, backing up, rating, grouping, archiving, optimizing, maintaining, thinning, and exporting of digital files.
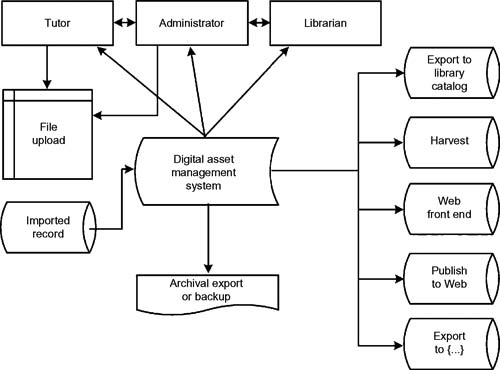
Figure 13.2 The digital asset management (DAM) system workflow for assets that reach beyond just video and audio have touch points to publishing, catalogs, librarians, tutors, and archive or export.
The makeup of a DAM system will consist of the computer hardware and software applications that support the process of managing the digital assets. With certain exceptions, such as specific video or audio codecs, and the abilities to process at other than real time, the physical components of a MAM can be quite similar to those used in a DAM system.
Asset Management System
This term is sometimes used in conjunction with MAM or DAM, but should generally be thought of as pertaining to physical assets (such as property or goods). Asset management is the process of maintaining, upgrading, and operating physical assets. An asset management system is a framework that provides a measure of organization performance, which is tied to short-term and long-term planning. Figure 13.3 shows a sample workflow for an asset management system that might be used in document management for static images and information in a library or non-moving media content application.
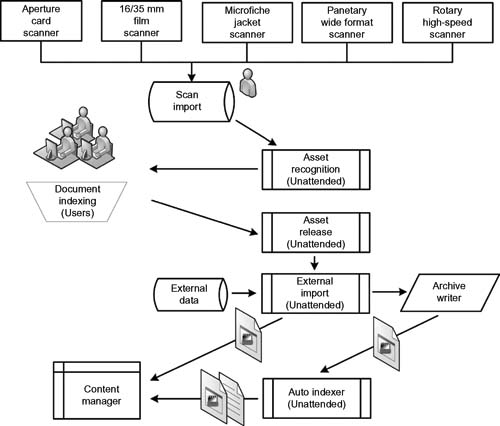
Figure 13.3 A sample workflow for static media and document (asset) recognition including processing, with scanning, indexing, and content management.
This chapter does not delve into the topic of asset management from the perspective of digital or media assets.
Media Asset Management
As the first word implies, this is the management of assets specific to media. The media may be digital or analog; however, for the purposes of refining what is a huge territory, this book will relate media asset management to only digital assets that would more traditionally be stored on a digital file server tailored for video, audio, and images.
Historically, MAM systems have focused more on providing storage management and were not involved with workflow or operations. The MAM would be that instrument that connected the files on a storage platform with a database-driven application that looked up certain tags, i.e., information provided by the user at the time the media was ingested to the storage system. The simple MAM allowed for the rudimentary searching of the media based upon that user generated information. The extremely simplistic approach was at best the electronic equivalent of a label placed on a videotape cassette or the 3 × 5 card stuck in the container that housed that tape.
Two of the more traditional approaches to MAM implementation employed early on were in tape-based systems and digital videoserver systems.
Tape-Based MAM
MAM solutions for videotape typically involved media assets stored in a robotic library with supporting information about those tapes kept in a data library housed on a dedicated computer system. Software cataloged the library based upon the tags (records) that were entered into that application by the user, usually at the time of ingesting the material into the tape library.
Solutions like these have been around since the mid-1980s. At the most basic level, at least for broadcast applications, the library catalog data would contain a house number that was paired against information contained in the broadcast traffic system that described that asset. This house number was the database key link between what was in the videotape library’s database and what was contained in the traffic system’s database. Traffic systems held the contractual information about the content, but had no network or other connection to the robotic library. It essentially knew nothing about what actually resided on the physical tape media.
In the early days prior to automated or robotic tape-based play-to-air systems (see the workflow example in Figure 13.4), the tapes (or films) on the broadcast library shelf would be manually collected according to instructions from the traffic department, moved to the dubbing/transfer area where an operator would load the tape (or film) and cue it, then either electronically dub each tape to a master commercial reel or ready videotape transports (or film projectors) for playback by an operator or other triggering mechanism associated with the station’s master control play-to-air operations.
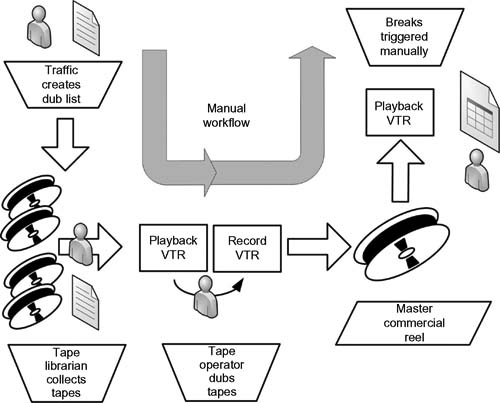
Figure 13.4 Legacy, manual workflow in a broadcast or content play-to-air environment.
Once automated tape-based play-to-air libraries were put into use by broadcasters, an operator would load the tapes into the play-to-air robotic library and enable applications that were built into this robotic system’s control system (referred to as a library management system or LMS), which would be triggered by the station’s external automation interfaces at the appropriate point in time based upon the station’s program schedule. This was essentially the entire sum and substance of the “media asset management” process prior to the era of videoservers.
Drawbacks to Tape-Based Systems
The principle drawbacks to this type of MAM was that there was no integration or interaction between the asset management, in general, and operations. Tape was a one-function/one-action-at-atime instrument of physical media. Tape offered no collaboration, that is, when a tape is in use, no one else could have access to that material except as linear video on a routable video transport system (a coaxial cable with BNCs on the ends). Work would be limited to just one individual, working on one specific task and only with that specific tape.
To use that asset for any other task (play-to-air, editing, or copying), a person would have to physically retrieve the tape from a shelf or library, take that tape to a location with equipment (a VTR) capable of playing that tape, load the tape, and then play the tape. No integration between the media asset management system and the playout equipment was possible.
Because assets were stored on tape and the metadata about those assets would be stored separately in a computer, users could perform searches on that metadata, but the physical retrieval process would be manual. It would take considerable time to locate and transport the assets, resulting in a risk that those assets could be lost or unavailable because they were already being used by others. The simplest functions of browsing could be quite time consuming, requiring handling the physical asset, usually in its original form.
Physical media is subject to use degradation each time the tape is played or handled. When the asset was stored on analog videotape, duplications would always be of poorer quality than the original. Even with digital videotape, the cloning process would have to be manually managed, had to occur in real time, and should any updates to the metadata be necessary, the accuracy of that update could be compromised by the user improperly recording that updated information or forgetting to make the update all together. Seldom would these systems account for usage counts or changes in media quality.
All of these disadvantages would directly translate into poor productivity. Mistakes would occur due to inefficient collaboration, introducing significant delays into the production and broadcast processes.
MAM for Videoserver Implementations
The introduction of videoservers as a buffer between tape-based libraries and play-to-air operations helped alleviate a portion of the manual processes of asset management—but not many of them. With a videoserver implementation, each videotape would be physically transferred from the tape media to the digital storage platform, where certain data about that asset would be entered and communicated to a basic media asset management program resident on the videoserver. If the transfer was part of the broadcast station’s play-to-air automation, that information was collected in that platform as well as the automation program. Due to the proprietary nature of each of these variant platforms, the information on one system was seldom replicated in its entirety on another. Certain systems needed certain information while other systems might need that same information or would require a different set of data.
Videoservers with their associated storage platforms would maintain their own database populated with information that the user would enter during the ingest process. Such information, or metadata, would basically instruct the videoserver on where to begin the playout through metadata called the start of message (SOM), and when to stop the playout of that media, which in turn would trigger the next clip in a sequence of files to be played back during a commercial station break. This later metadata element, called the end of message (EOM), would set the point where playout of active video would cease. The EOM would sometimes trigger the next SOM to roll if the clip was not the last event in the sequence of a station break.
Other videoserver specific information would be more structural in nature, such as the location of the clip on the actual hard disk or storage platform, the codec, the time vcode or frame count of the clip, the number of audio channels, and other technical information. The videoserver’s internal database would be application specific to that videoserver. The videoserver would tie the data to a clip identification number, which the videoserver would associate with an external database contained on the station play-to-air automation system, or, if the playout program was self contained on the videoserver, with its resident application.
For the most part, the videoserver’s storage, search, and retrieval functions had several disadvantages stemming from the fact that there was no integration between asset management and operations. Any outside interaction would be contained to the station automation system, or depending upon the videoserver, possibly a simple clip playback program resident to the videoserver.
Lack of Media Asset Integration
Digital storage systems might include tool sets integrated into nonlinear editors or the traffic or scheduling programs, or as a part of the media ingest or acquisition applications that provided some level of MAM. When these tool sets were integrated with a storage platform, they could offer the advantage of having immediate access to those media assets contained on that specific storage platform. These tools would usually be incompatible with other platforms and would be unable to access them without special customization for the MAM.
Metadata that was entered into one system would only reside within that system, and would not be capable of exchange throughout the MAM. This interoperability issue leaves each of the systems isolated from one another, requiring users to open specific applications on each platform that would be unable to be cross-linked into the principle MAM system.
Collaboration Issues
Carrying on work among multiple users would be complicated under these scenarios. Although tool set integration might make it possible for multiple users to employ the same tools for simultaneous access to the same material, it might not be possible for users of different tool sets to gain a comparable level of access. Since most of these early MAM systems were designed just for storage management, they would neither typically facilitate collaboration nor directly handle any rights access. Without active collaboration, these storage solutions could then have no involvement with workflow.
Metadata
Metadata are used to describe information about specific data. Often referred to as “the bits about the bits,” metadata (whose genealogy is believed to begin circa 1982) provide information about a certain item’s content. Another name for metadata is “metalanguage.”
When a document, image, or other type of data are created, certain parameters should be added with the item as part of the complete file. Such elements, otherwise called attributes, include items such as a file name, the size or type of file, the date it was created, etc. These metadata are called structural—and generally will not change.
Additional forms of metadata may also describe the location or ownership of the file among other information considered “necessary” to be noted about the contents of the data. These are called descriptive metadata. These metadata types are explained in more detail later in the chapter.
For picture-based assets, the image may include metadata describing the pixel dimensions (how large the picture is), the color depth (e.g., 24-bit), the image resolution (e.g., 300 pixels per inch), when the image was created, and other data. A text-based asset would likely include metadata containing information about the number of words or characters in the document, who the author is, when the document was created, and potentially a short summary of the document.
Web pages often include metadata in the form of meta tags. Description and keyword meta tags are commonly used to describe the Web page’s content, which enables third-party search engines to use this metadata when adding those Web pages to their search index.
This metalanguage or metadata aid in speeding up searches, allow for the creation of catalogs, can be created automatically by the encoding platform, and can be added to by the user, author, or owner.
Media-Centric Metadata
Metadata, in a digital media environment, are used to manage the file system information. They describe, at their highest level of importance, where the files are kept so that other subsystems may search for them, retrieve them, update or process them, and the like.
There are two general categories of metadata for media systems, called structural metadata and descriptive metadata. The example of Figure 13.5 shows a typical set of metadata screen shots where users or machines enter or display the respective forms of metadata fields.
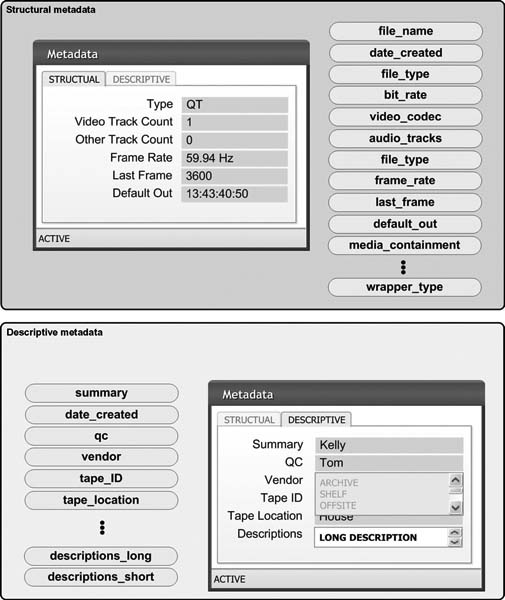
Figure 13.5 Sample elements of structural and descriptive metadata, with sample input screen for manually entering data into the database.
Structural Metadata
These are the data used to describe the physical attributes of a file. For video assets (video essence), they will include such information as the format of the video file, their bit rate, the resolution, and the container (i.e., wrapper) type.
The overall media asset management system, and its peripheral components, depends upon the integrity of the structural metadata associated with each independent file. It is for this reason that users should never forcefully change the attributes or tags in this important set of data. The result of modifying structural metadata would be the disastrous equivalent of changing the file extension on a computer file. In a more global sense, structural metadata are as important to the MAM as the file allocation table (FAT) is to the hard disk drive.
The Society of Motion Picture and Television Engineers (SMPTE) has standardized the Structural Metadata of the MXF file format as SMPTE 380M, which contains the technical parameters of the stored material, defines how the material is played out, and provides a plug-in mechanism for a Descriptive Metadata scheme (DMS-1).
Descriptive Metadata
This information may be generated either by the system or by the operator/user. Descriptive metadata examples include shot logging, track naming, availability (allowed dates of usage), and rights or permissions. Depending upon the organization, descriptive metadata may very simple (10–20 fixed terms) or very complex (hundreds of elements or fields).
Descriptive metadata may be very selective so as to limit the number of variances that a user might enter. For example, in a baseball game, some of these entries might be limited to the number of possible play combinations, the number of batters, the players names, and what occurred with each batter at the plate (strike out, walk, fouled out, run, hit, error). These incidents may be logged using a specific application that is constructed from a tool set by the user or administrator. It is important tagging information that supports search and retrieval of media from the MAM system.
SMPTE, as part of their standards and practices documents, provides a Recommended Practice (as of this writing, version RP210-11-2008) that includes the framework for a deep set of terminologies contained in a user addressable online instrument built on a node and leaf structure (see Fig. 13.6). The SMPTE Data Element Dictionary (formerly called the Metadata Dictionary) is a data element register that defines data elements, including their names, descriptions, and identifiers, for association with essence or other metadata. A full explanation is contained in SMPTE 335M. The spreadsheet form details can be found at www.smpte-ra.org/ under the file RP210.11.XLS. One can see the depth that such metadata can take, as it begins at the administrative levels and goes well beyond the coding levels for mediarelated files and essence descriptions.
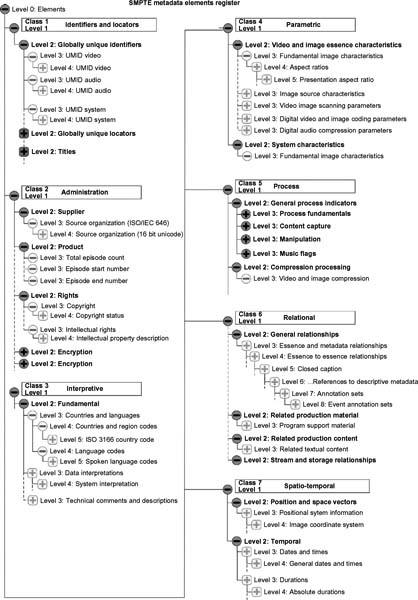
Figure 13.6 Partial segment of the node and leaf structure used in the metadata dictionary [extracted in part from the SMPTE RP210 online registry].
Interoperability
Interoperability is a key component of any metadata strategy. Elaborate systems that are independently devised for only one archival repository will be a recipe for low productivity and high costs, and will have minimal impact. Richard Gabriel’s maxim “Worse is better,” which originated from when he was comparing two programming languages, one elegant but complex, the other awkward but simple, correctly predicted that the simpler language would spread faster, and thus more people would come to care about improving the simple language than otherwise improving the complex one.
Gabriel’s prediction was found to be correct, as is demonstrated by the widespread adoption and success of Dublin Core (DC), which was initially regarded as an unlikely solution by the professionals on account of its rigorous simplicity.
Dublin Core
Now one of the more recognized initiatives related to metadata, this work dates back to 2000 when, at that time, the Dublin Core community focused on “application profiles” as a type of metadata schema. Application profiles, as schemas, consist of data elements that are drawn from one or more namespaces, combined together by implementers, and then optimized for a particular local application. In the application profile concept, metadata records would use Dublin Core together with other specialized vocabularies to meet particular implementation requirements.
The motivation for the work on the Dublin Core was to develop a set of 15 simple data elements (see Table 13.1) that could be used to describe document-like networked information objects in support of discovery (i.e., searching) activities. The Dublin Core data elements consist of the following: title; creator (author); subject and keywords; description; publisher; other contributor; date; resource type; format; resource identifier; source; language; relation; coverage; and rights management.
Table 3.1 Dublin Core Data Elements
| Title | Format |
| Creator (Author) | Resource identifier |
| Subject and Keywords | Source |
| Description | Language |
| Publisher | Relation |
| Other contributor | Coverage |
| Data | Rights management |
| Resource type |
The Dublin Core achieved wide dissemination as part of the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) and was ratified as IETF RFC 5013, ANSI/NISO Standard Z39.85–2007, and ISO Standard 15836:2009. Since 1997, the Dublin Core data model has evolved alongside the World Wide Web Consortium’s (www.w3c.org) work on a generic data model for metadata, known as the Resource Description Framework (RDF). As part of an extended set of DCMI Metadata Terms, Dublin Core ultimately became one of most popular vocabularies for use with RDF, most recently in the context of the Linked Data movement.
PBCore
Developed by the Public Broadcasting Service (PBS) with development funding from the Corporation for Public Broadcasting (CPB), the project, which was initially published in 2005, provides a common set of terms and capabilities that address metadata and associated media asset management activities for use specifically by many public broadcasting stations, organizations, and information systems (see Fig. 13.7). These entities use this 48-element core document to describe the intellectual content, property rights, and instantiations/formats of their media items.
The PBCore project has been finalizing its XML Schema Definition (XSD) as the main framework upon which all the PBCore elements, their relationships, vocabulary pick-lists, and data types are organized and defined. PBS is building an accurate and meticulous XSD to ensure that when PBCore compliant metadata descriptions are shared between data systems, the contributing system and the receiving system are both able to “machine read” and faultlessly interpret and display these descriptions.
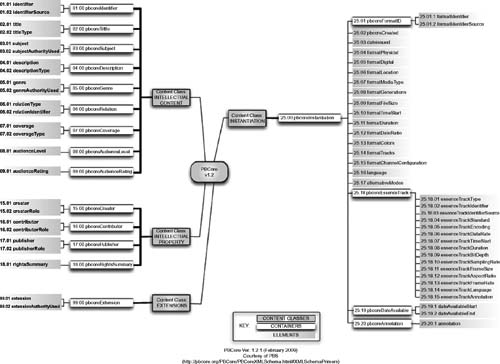
Figure 13.7 The PBCore and XML schema, and XSD (XML Schema Definition) layout utilized by PBS for metadata.
Formally known as the Public Broadcasting Metadata Dictionary Project, PBCore is designed to provide, for television, radio, and Web activities, a standard way of describing and using this data, allowing content to be more easily retrieved and shared among colleagues, software systems, institutions, community and production partners, private citizens, and educators. PBCore can also be used as a guide for the onset of an archival or asset management process at an individual broadcast station or institution.
PBS sees this as a standard pivotal to applying the power of digital technology to meet the mission of public broadcasting. In the process of creating the PBCore XSD, they determined enhancements to the underlying structure of PBCore were necessary. These enhancements aid in the binding together of related metadata elements (for example “Title” and “TitleType”) into new element containers. The original 48 PBCore elements are now becoming a more structured hierarchical model consisting of 53 elements arranged in 15 containers and 3 sub-containers, all organized under 4 content classes.
Usage Metadata
Usage metadata is yet another form of descriptive metadata. Typically a subset of descriptive metadata, usage metadata describes life-cycle information about a video clip or file such as when the camcorder actually first captured the content. Depending upon how the metadata schema is implemented, this might include the time of day, the shooter (if the camcorder logs that information), and the MAC address of the recording equipment or the name associated with the physical recording media.
Schemas
Defined basically as a protocol that describes how one collects all these data sets together, schemas have different meanings depending upon the systems they are associated with. For example, in computer science, an XML (extensible markup language) schema is a way to define the structure, content and, to some extent, the semantics of XML documents. Since XML has becoming the de facto standard of writing code for media asset systems, particularly one that is human understandable, many of the metadata systems are being written (or translated into) XML.
Standards, Practices, and Policies for Metadata
Much of the work published on metadata, in general, comes out of the professional library (librarian) space. Setting policies that cover the endless possibilities for metadata applications is beyond comprehension, but there are still several efforts (as previously described) that continue in that domain.
Diane Hillman’s (Cornell University) infamous statement, “There are no metadata police,” elevated awareness of standards, practices, and policies. There are indeed prescribed standards and practices that can be observed and followed when designing a usable and extensible metadata platform. Some of these have emerged from the work in MPEG-7, and in various other global activities by standards committees and their study groups. It would be nearly impossible to present all of these, but the “Further Readings” section at the conclusion of this chapter will provide some links to current and previous activities.
Storing Metadata
There are two principle philosophies associated with where metadata are stored for media-centric applications. One belief is to associate metadata to the file in an external database housed on a separate server platform. The alternative is to embed the metadata with the actual file. Both have their pros and cons.
Metadata, particularly descriptive metadata, are quite dynamic. The size of the metadata file, that is, the byte count of the XMLbased information, continues to grow as the file (content) moves through the production, distribution, and archiving processes. It is for this reason, and the risks associated with the loss of the metadata embedded in a file, that many MAM systems will employ a discrete server platform that isolates the actual essence of the file from the descriptive metadata.
Structural metadata are almost always carried with the file itself. These metadata do not necessarily follow XML formats as structural metadata are most useful to devices, such as decoders and videoservers, when the file is first presented to the playback system of root level server platforms.
Descriptive metadata would not necessarily be carried or contained (wrapped) within the essence portions of a media file. Given the dynamic nature of descriptive metadata during production and other workflows, this would potentially require that a new version of each file would be created every time that a new element is added to the metadata. This would require a continual growth in storage systems for what would be highly duplicative information.
Organizations like the Advanced Media Workflow Association (AMWA) are working on schemas that can link the metadata with the essence elements through versioning methods. It is beyond the scope of this book to delve into this topic, but expect to see continued adoption of these methods through the advancements in the MXF standards and practices.
Metadata Services
Any complete media asset management system must be able to communicate with several different elements and components when utilized in an enterprise-wide implementation. We use the term “services” to describe “code that can be called by other code,” and extend that to include metadata services that can easily be handed off from one subsystem to another.
Metadata services are an object-oriented repository technology that may be integrated with enterprise-class information systems or with other “third party” applications that process metadata.
In the past, managing metadata has been as much an operational hazard as a realistic feature. In an enterprise-wide media management environment that has many sets of content collection points, editorial work stations, storage platforms (local and shared), and content databases, providing a unified set of metadata is essential to a successful implementation.
MAM products are migrating to, or are being written as, Webbased applications and technologies, using what are referred to as “messaging technologies.” These messaging services transfer and interchange metadata and metadata services among the supporting hardware and software platforms.
Media Application Services
Media application services are those elements that perform tasks related to the content presented to them throughout the life cycle of that content. A content life cycle begins at the capture point, moves through ingest and interim storage, and then on through the production, distribution, and archive phases.
Table 13.2 Media Application Services Categorized by Functionality and Service Tiers
| Fundamental Services | Secondary Services | Optional/Other Services |
| Search service | Browse service | Captioning service |
| Organize service | Transcode service | Quality control service |
| Transfer service | Distribution service | Archive service |
| Media service | Future service(s) | Other third-party service |
| Rules service |
A MAM system needs to employ various services that will allow the user to intelligently and efficiently manipulate the media files using the associated metadata collected throughout the MAM system. These services call code from other subsystems in the enterprise system and then react accordingly based upon the service functions.
Certain services (see Table 13.2) are essential to any MAM implementation and may be referred to as “fundamental services.” Companies that manufacturer media server systems, such as in the case of Omneon, may offer a product specific server (Omneon calls theirs a “Media Application Server” or MAS), which is a foundation for the development and deployment of media-centric applications. The Omneon MAS enables a single virtualized view of the content across managed systems and fundamental media processing services, thus minimizing the complexities of media management.
Sophisticated MAM systems generally build in similar functions to their products, which are then configured (or customized) to the third-party serving products they integrate with. Regardless of where these services are placed in the product portfolio, these fundamental services will most likely consist of the following.
Search Services
Using both structural and descriptive metadata, these services will provide the capability to search across multiple file systems. Information may be retrieved from records of previously saved searches and can be used to populate folders dynamically.
Organizational Services
Content relationships may be created and maintained irrespective of the data types. These services will allow other services to treat these collections of relationships as single objects.
Transfer Services
Transfer services are involved with managing content movement per user requests or rule-sets defined by those users. The transfer service may be configured to automatically sense growing or static files, and then prescribe the most appropriate transfer method to move those files to locations either local to the server/ storage platform or to other third-party applications.
Media Services
Media services are those services specifically related to the media essence. Such services could be the purging of that data, the segmentation of the data, the duplication of the essence, etc.
Rules Services
Rules service allow users to develop workflow and processing rules to perform tasks or call other services based on system state, time, or manual parameters.
Additional services may be added to the pool to further support MAM functionality. A browse service will enable the generation of proxies either internally or through the calling of services from an external transcoding engine. Distribution services create the channel for distributing media files either as completed clips of media to the end user (sometimes through a content distribution network or content delivery network (CDN)), or sometimes to third-party products that prepare them for the application or service that will receive them.
Services including quality control, archive, captioning, and transcoding all become segments of the MAM system in its totality. Such services often become the “options” that are added to the base MAM system to fulfill business or operational needs. Services can be quite automated, taking those tasks away from error prone humans, while providing a justifiable validation that the proper quality control has been put into the delivery of the final product packages.
Messaging Services for MAM
Any use of proprietary messaging services in an enterprise-wide MAM implementation should be discouraged if there is to be continued flexibility in the system. Having to supply translators that remap or exchange and recode metadata between the variant other subsystems in the overall media production, storage, or operations environment spells certain disaster. When any one of the other subsystems changes their platform architecture or schemas, it will most certainly require new configurations or re-customization of the principle MAM system just to regain the previous ability to interchange your metadata.
Today, stemming from the tremendous developments in Webbased technologies, there is no reason not to develop messaging services using industry standard, open source practices for the exchange of information among platforms. These may include Web service standards such as SOAP or REST.
REpresentational State Transfer (REST) is an architectural style and not a toolkit. In REST, resources are identified by uniform resource identifiers (URIs). These resources are manipulated through their representations, with messages that are self-descriptive and stateless. REST permits multiple representations to be accepted or sent. REST has gained widespread acceptance across the Web as a simpler alternative to Simple Object Access Protocol (SOAP) and Web Services Description Language (WSDL)-based services.
SOAP was created to accomplish a better way to communicate between applications. At the time of SOAP development, it used hyper-text transfer protocol (HTTP), which was being supported by all Internet browsers and servers. SOAP provides a means to communicate between applications running on different operating systems, with different technologies and programming languages. SOAP became a W3C Recommendation on June 24, 2003.
Intelligent Integrated MAM
The current thinking in managing media assets is that systems must now be “media aware,” that is, there must be intelligence integrated into the MAM that understands what the particular media is, what can be done with or done to that media, and how that media should be handled during ingest, processing, storage, distribution, and archive. This intelligence goes beyond just the elements of digital storage. The concept of the intelligent integrated MAM binds the entire production chain and multi-platform delivery into a single complete solution.
Intelligent integrated MAM pulls together the elements of business goals with the operational needs, the functionality of the systems, and the technical requirements necessary to fulfill those target goals. A system would include workflow management, tool set integration, metadata and metadata services, and collaboration among multiple users. Furthermore, the elements of centralized databases and a multi-tiered architecture are necessary to achieve a fully integrated MAM system.
Workflow Management
The MAM system must be capable of incorporating the operations side of the organization so as to manage user workflows that include scheduling, acquisition, and production; distribution and repacking; and archiving. A unified MAM system will achieve maximum benefit when it is configured to the many roles and corresponding responsibilities that any user will execute as part of their particular production workflow needs. Workflow designs will include the establishment of permissions, reporting paths for the status of jobs and their approval processes, any points where metadata are entered or altered in the MAM databases, and other essential background operational tasks and requirements.
Collaboration among Multiple Users
Given that the MAM system with its intelligent integrated components will be utilized by the entire enterprise, the elements that make up the MAM must be easily addressable by multiple users who may perform varying tasks simultaneously. These collaborative components allow users to interact and share information (content and metadata) with each other. These activities must extend across the entire organization before an effective MAM solution is realized.
At the same time, the system must include the capabilities to regulate and manage access to certain material, metadata, tool sets, and operations based upon permissions and IT-security policies. The system must also characterize priorities such as multiple or simultaneous requests for the same material so as to manage and restrict unqualified write functions that could destroy or render that material useless. This process is referred to as “access management” and is a key capability in any MAM system.
Tool Set Integration
Each step of the media production workflow will utilize tool sets that integrate operations such as metadata services, business processes, and media exchanges. These tool sets in turn must be able to directly access the storage systems and the asset catalogs (or databases). As previously discussed, these tools should be built around open standards so as to more easily work with the software and hardware in current systems and those that will emerge in the future.
The framework of the MAM system, overall, will be far more extensible when it is built around open standards. Thus, users should be discouraged from building their MAM system around dedicated or proprietary protocols or API components that require detailed or complex customization for functionality.
Centralized Database
When the media database is centralized, it becomes part of a unified depository for all media assets. Users are afforded the ability to quickly share material among each other easily and on a nearly instantaneous basis. Handing off of material from one user to another is simplified, and late breaking changes can be immediately propagated through the system.
Centralized databases are tightly coupled to the centralized storage components, and more loosely coupled to the local disks or storage found on isolated, non-integrated workstations. Proxy browsing and editing is one means to isolate the common connections of the storage and database systems and allow work to proceed without a full-time network connection. Proxy editing may be accomplished on unconnected laptops, but must be fully synchronized with the centralized MAM systems once reconnected or before any actual conforming is started. These are complex tasks that require a deep understanding of system architectures and are generally only successful on full scale media asset management platforms.
Multi-Tier Architecture
From a generalized perspective, a tightly coupled system means that the services, applications, and interfaces are assembled such that they share a common set of information. This is best accomplished with a centralized storage platform for media assets and associated databases. Critics of tightly coupled systems, those that couple workflow and assets with limited flexibility, say this architecture comes with increased risks in the long term.
For these and other reasons, enterprise MAM systems will utilize a multi-tiered architecture (see Fig. 13.8), which incorporates redundancy in both the hardware and software components. Most MAM systems will employ at least a main and a backup database. This upper tier, in the higher class systems, will include at least two database servers each with a protected (RAID) storage system and mirrored databases on separate hardware.
In the middle tier, where the applications are housed, each grouping of applications will be contained on multiple servers. The application servers each perform tasks or provide services as requested by the clients. These services or tasks may include file conversion, ingesting, cataloging, search, etc. By spreading the same applications out across redundant servers, a grid of protection is built such that the applications are protected and the bandwidth accessibility is improved as more and more users gain access to the system. A load balancing application spreads those tasks out among the various servers and aids in managing the replication of the data (metadata and reporting data) across the database servers and the user/client applications.
The lower tier, at the client level, will have multiple workstations for users that are bandwidth allocated across the mid-tier applications. The applications may be called by any user, with access limited only by software licensing.
Architectures of this type mitigate the possibility of a single point of failure. Should discontinuity or failure occur, the client is transferred to another application server. Should the main database fail, the database information is immediately moved to the backup.
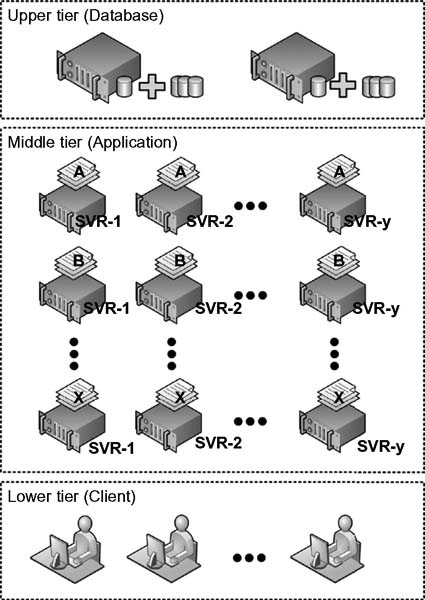
Figure 13.8 The multi-tiered architecture using multiple servers to process and manage the databases for services or tasks (applications) that are requested by clients.
Scalability
Using the multi-tiered architecture approach, growing the MAM system becomes a straightforward process. Should the loads increase, additional servers can be added. Scalability is generally designed into all elements of media asset management and encompasses the storage platforms, database servers, applications servers, and clients.
Storage for MAM
How and where to storing the application databases, media content, and metadata for the components of a media asset management system is no trivial matter. The factors that govern this are driven by the providers of the MAM, and by the manufacturers of the software and hardware platforms that interact with the MAM.
It goes without saying that the important elements of these systems should be contained on protected storage that is either replication based or based on mathematical protection (RAID). Given that many of the MAM software components can be implemented on commercial off the shelf (COTS) server products, the storage elements associated with those servers are generally of a class and service level that can support the kinds of activities and workflows necessary for media asset management.
Specialty platforms, designed for mission critical applications and those that support continuous duty cycles, such as dedicated videoservers for broadcast applications, will suit the playback and/or ingest functions of a MAM. Some integrated, enterpriseclass MAM systems, however, will require that IT-class servers and high-performance storage be augmented by third-party baseband video/audio ingest codecs in order to capture into storage and create those proxies and structural metadata necessary for their functionality.
Other MAM systems will provide their own serving and storage platforms, on which they have specifically developed their products. Care should be taken with this form of product line as it infers you must return to this vendor for all future updates when and if more performance-driven servers are available.
Latency
Any delay in obtaining access to material is considered latency. In the serving platforms used for MAM, latency is an important consideration, especially when content is to be shared among multiple users or across many workflows. Most MAM system providers will go through extensive planning to mitigate the impacts of latency on their systems.
Interfacing with Production Storage
Specifying how the MAM system performs with third-party storage components is sometimes called “benchmarking.” This process requires a thorough understanding of the devices that the MAM must interface with.
Many assumptions will be made during the pre-design and proposal stages of defining a complete MAM system. If the MAM is to operate only within the workflow or framework of a post-production facility, that will require a set of specifications that would be different from when the MAM is working in a live or news environment.
The activities expected during ingest are more linear or real time in nature and somewhat easier to navigate versus when a dozen or more nonlinear editing platforms of various formats need access to the same content share. Activities that FTP content directly into servers can be regulated by the engines and software on both the servers and/or the CDN. Streaming media that must be captured upon presentation must have sufficient buffering to ensure no packets or video frames will be lost.
Design development will require a thorough validation of the production storage systems’ capability to sustain a significantly higher number of “read-while-write” operations. IT-centric storage systems may lack this capability, so a complete understanding, and in some cases actual benchmark testing, is necessary.
For example, in applications where live ingest, live playback, streamed playback, and craft editing is required, defined as “peak usage of a system,” there will be a number of read-whilewrite operations that occur simultaneously. These activities may include proxy generations of every image file while those highresolution images are also being recorded, downloaded, or rendered. Further activities might include users that have to browse through these same proxies while they are being generated, and when editors are accessing high resolution while they are also being recorded (or downloaded or rendered).
The previous example is typical of a production environment for live broadcasts including sports and news. In most cases, the MAM system will be managing peripheral activities that migrate files from one platform to another. This requires not only a network architecture that can support the file sizes, bandwidth, and overhead, but it requires that media-aware and high-bandwidth (e.g., fibre channel SAN) storage systems be employed to avoid bottlenecks that will appear to be a MAM control related issue.
When third-party storage systems are employed in a facility, such as in an Avid or Final Cut Pro editing environment, it is important to understand and determine where the active files will reside and what entity controls those activities during the editorial, ingest, cataloging, and release processes. Should all assets be stored on the centralized content store, this will require that the supporting applications be capable of interfacing to and from that store. More often than not, at least in many current operations, users still prefer to work on their local (dedicated) storage. While it is possible to achieve higher local performance in this model, it encumbers the MAM system in its abilities to provide a shared-storage, collaborative workflow environment.
There are no hard-fast or concrete rules for addressing these issues. As manufacturers of editing products develop and release new capabilities (such as improved storage subsystems), the ability to reconfigure or customize the current MAM implementation grows more complex. Often, the race to keep up with all these advancements is one that is not necessarily pleasant for any of the stakeholders—and the user plays a “wait-and-see” game until the design development and update cycles are complete.
Archive
With the understanding that a MAM will be expected to work with all elements of the enterprise’s workflow, its interoperability with an archive is paramount to the continuous availability of the assets under its management and control. Much like what was previously described in the section on “Interfacing with Production Storage,” communicating and sharing media files with the archive requires a very tight integration between both the archive manager and the MAM system.
Archive platforms typically include elements consisting of an archive manager, the “data-mover,” which handles the actual files between storage systems, and the storage system itself (e.g., data tape, optical disk, or spinning disk). Considerable effort is put into managing the handoffs between the MAM and the archive solution. The archive manager must track its assets on its platform much like the disk file system does on a spinning disk platform. The MAM must pass certain metadata elements to the archive manager who then interrogates the source end (the production storage elements) and the target end (the data mover or tape system) to keep the locations properly synchronized in their respective databases. Some of this information is never passed between the MAM and the other systems; yet tracking information such as “who has the file now,” requires that the MAM must be continuously aware of all the file locations in order to support requests from the various users on the system.
Files that move from local or production storage to the archive may remain on both systems until actually purged from one or more of the respective systems. The MAM must become the traffic cop for these processes. Manually overriding the process becomes a violation of the workflow policies that can have severe negative impacts on the system and ultimately may result in the loss of the file, location data, or other pertinent information.
The archive system must therefore work integrally with the MAM system. It is not possible to specify the functionality of one without knowledge of the other.
Further Readings
A complete book on descriptive metadata for television applications is “Descriptive Metadata for Television: An Ennd-to-End Introduction,” Mike Cox, Ellen Mulder, Linda Tadic. Focal Press (1st edition April 10, 2006).
Tutorials on first and second generation Web services technologies can be found at
www.Ws-standards.com or www.soaspecs.com.
Information about PBCore can be found at
http://pbcore.org/PBCore/.
Information about Dublin Core Media Initiative (DCMI) can be found at
http://dublincore.org/.
Information about XML and other Web-services can be found at the World Wide Web Consortium (W3C) at
http://www.w3.org/XML/.
Information on the BBC’s “Standard Media Exchange Framework” (SMEF) can be found at
http://www.bbc.co.uk/guidelines/smef/.
Information on the European Broadcast Union (EBU) project group P/META, whose work is based on an extension of the BBC’s SMEF, can be found at
http://www.ebu.ch/en/technical/trev/trev_290-hopper.pdf.
Information on the Institute fur Rundfunktechnik (IRT) XML mapping of the MXF metadata structures (DMS-1) can be found at
http://mxf.irt.de/activities/2004-02_dms_workshop.php.