
19
RESILIENCE, FAULT TOLERANCE, AND VIRTUALIZATION
Resilience and fault tolerance are subjective terms from any perspective, just like virtualization. As in most technologies, the terms can take on many different meanings, especially when used in varying contexts and for diverse applications. The technologies used in attaining high degrees of resilience, fault tolerance, and virtualization may be applied to disk drives, clusters, storage area networks (SANs), tape libraries, computers, etc.
This chapter explores regions of storage management that lacked the technology and that needed to be addressed until shortly after the beginning of the new millennium. Ironically, as we have seen the desktop computer just about peak in performance with the laptop not far behind, we now find that manufacturers of chips and operating systems are focusing on mobility. This means transportability and virtualization of nonlocation- based computing through the deployment of processors, displays, and applications at a level not seen, nor probably expected, until recently.
As such, many new issues ranging from collaboration through security are surfacing. This is challenging for IT managers at corporate levels and in turn has seen the launch (and the roots of acceptance) of storage in the cloud and software as a service. However, we are only scratching the surface of the future for the media and entertainment industry when it comes to storing the assets associated with moving media.
KEY CHAPTER POINTS
•Techniques and practices for achieving high levels of resiliency for storage platforms and their associated systems
•Storage tiering, the layers, and levels of how storage can be managed using automated policy-based storage tiering, hierarchical storage management (HSM), and virtualization
• Defining operational objectives and applying storage performance metrics, such as recovery time objective (RTO) and recovery point objective (RPO), to classify storage systems and service level agreements (SLAs)
•Working with legacy or existing storage components in a heterogeneous environment
•Proactive techniques to prevent corruption of data at the disk level employing RAID scrubs, checksums, checkpoints, snapshots, lost write protection, and early detection technologies
•Virtual file systems, virtual server, and virtual storage
•Approaches to obtaining high accessibility (HA) and fault tolerance for simple or complex storage and server systems
Resilience
Data can have varying degrees of value based upon the user’s perspective. Information, the meaningful part of data, can have even greater value not only to those that are directly affected by it but also to those who have no idea of whether the information exists. This means that data, once it becomes meaningful information, needs to be both accessible and resilient to the many influences it may come in contact with.
The value and importance of data may not be uniform across the domain of information technologies. However, most information will generally be treated equally in the way it is managed and in the way it may be stored. Nonetheless, there will be conditions where the information (as data) can be at risk. It is the task of designers, engineers, system architects, and IT professionals to reduce the risks associated with data/information storage and management by carefully weighing and analyzing the many options and paths available in storage technologies.
The Merriam-Webster online dictionary defines “resilient” to mean “capable of withstanding shock without permanent deformation or rupture” and “tending to recover from or adjust easily to misfortune or change.” With this context, we will explore how storage can be designed to protect and to correct for anomalies that often occur when moving, replicating, or manipulating data, which is a routine part of operations and workflow.
The challenges of building storage networks and systems that are resilient is a science that continues to be developed. If you place yourself in the perspective of a few of the high profile, highly active online environments, you might have a better understanding of the degree of resilience that a system must have in order to be highly accessible and “ready to action” at anytime.
If you look at six-year-old Facebook, now with some 500 million active users, 50% of them log on everyday and they collectively spend over 700 billion minutes/month online (per the statistics from the Press Room at Facebook.com on November 23, 2010); you can see that this platform must be one of, if not the most, active information systems on the planet.
The network and storage systems that support this global endeavor must continue to be resilient to attacks, responsive to all its users, and fault tolerant to all potential thwarts at all levels and at all times. Furthermore, these systems must be flexible and scalable so as to adapt to changes and demands without warning.
Storage Tiering
Assigning data to an appropriate type of storage is just one of the methods for achieving system resiliency. Where data is placed and onto what type of storage it is contained is a management process that is generally supported by specific applications such as automation, production asset management (PAM), or enterprise- wide media asset management (MAM). Such applications may be enough to control where the data resides and for how long it is at a particular storage location based upon workflow, needs for accessibility, and usage policies.
Storage tiering is the process of introducing data onto appropriate levels or types of storage inside an overall enterprise-wide storage pool. The general rule of thumb for employing tiered storage is that only active and dynamic data is kept on primary storage. Fixed or static data, known as persistent (i.e., nontransactional or posttransactional) data, does not belong to primary storage. Users will gain increased accessibility to active or dynamic data when persistent data is moved away from primary to secondary storage.
In its most elemental form, storage tiering is the segregating of a storage environment into two or more different types of storage. Each type of storage is optimized for specific characteristics, for example, performance, availability, or cost. Storage tiering matches files with the most appropriate type of storage, depending on the needs or requirements of a user.
There are no “standardized” industry schemes used in segmenting, restricting, classifying, or numerically assigning tiers. Organizations are not restricted on establishing how they structure or into what segments they introduce their data, but there are some guidelines to storage tiering that an organization can employ.
Most organizations can meet their goals for storage management by employing two storage tiers. A typical two-tiered storage environment (as shown in Fig. 19.1) adds data into an environment that is optimized as primary storage for performance and availability, with a secondary tier aimed at storage capacity and cost.

Figure 19.1 The two-tier storage approach is suitable for most organizations.
However, a two-tier storage approach may not be sufficient for some organizations. Certain business requirements and diversification may make it necessary to expand beyond the simple “primary” and “secondary” storage analogies, so intermediary or tertiary platforms may need to be implemented that fulfill these additional requirements. By dividing storage into multiple tiers, other advantages are realized, such as options, configurations, and feature sets that can be provisioned and managed more easily.
Assigning your data to an appropriate type of storage is just one of the methods for achieving overall system resiliency. We will first look at a twotier approach to managing storage, given that this is the most common and convenient method.
Two-Tier Approach
When business activities do not command more aggressive multitier approaches to storage, alternatives are available to mediate the dynamics of the storage requirements. A two-tiered approach has the opportunity to use all or some of the applications, approaches, and technologies that will be discussed throughout this chapter and aggregate them to one of the two tiers: one for high production and high availability and the other for long-term preservation, archive, or business continuity.
One of the solutions that storage professionals may employ, regardless of the tier level, is automation. Higher end multitier solutions will use automation and data traffic flow analysis to ensure that their assets are placed on the right tier and can be accessible for the needs of the operation when demanded. These systems monitor various data activities and may utilize technologies such as snapshots and deduplication to support the storage systems’ performance and requirements on an ongoing basis. Long-standing technologies, like hierarchical storage management (HSM), are solutions that automatically move data from high cost storage to less cost storage based upon usage or demand for those assets and historical trends or policies set by the users or administrators.
Hierarchical Storage Management
HSM provides an automatic way of managing and distributing data between the different storage tiers (or layers) to meet user needs for accessing data, while minimizing the overall cost. The concept of hierarchical storage management involves the placement of data items in such a way as to minimize the cost of data storage, while maximizing the accessibility.
The principal features that hierarchical storage management provides include the following:
•A reduced total cost of storage—data that is accessed less frequently will be moved to and reside on lower cost storage.
•Performance benefits—freeing up costly, high-performance storage when less frequently utilized data resides on a lower tier, less costly, level of storage. This strategy has the potential to increase overall system performance.
•Utilizing tape automation—when an automated tape library is employed, there are further opportunities to reduce operating costs. For backup recovery and media services, automated tape systems reduce operational costs by mitigating manual intervention. Because most tape operations are unattended, the chances for human errors are substantially reduced. Using a hands-off approach assures that all the proper data is moved to backup or archive without prompting.
•Improved system availability—historical data is not repeatedly saved. The number of instances of the same data are reduced. Active data stays on high-performance online storage, whereas inactive data is moved to near line or archive under a rules- or policy-based model.
•Transparent to applications—no application changes are required as data is moved to a different storage technology.
•New applications are enabled—printed information, information in file drawers, and information that is not presently managed can be stored inexpensively when enabled on an HSM.
When asset management, content management, or other forms of media management are integrated with hierarchical storage management applications, the features embedded in each of these data management systems collectively give rise to significant cost savings and revenue opportunities throughout the business. Users will find a reduction in the total costs of disk and tape hardware derived from the more effective use of expensive “high-performance” disk storage as opposed to less expensive tape storage.
Benefits are further realized by reducing the costs of labor derived from those skills that were previously required to manage the assets. A one-time savings area is that those previously allocated tasks involved in the management and cleanup of system disk space, as maximum storage capacities were reached, are now transformed because automation can carry those services. Another cost reduction is that the systems now respond faster to requests for archive data, and the deliveries are more error free.
HSM can be integrated with any of the subtiers associated with the storage solution, including near line and archive. HSM may be deployed in a disk-to-disk (D2D), a disk-to-tape (D2T), or a disk-to-disk-to-tape (D2D2T) environment, providing efficiency and rapid response to user requests.
Either in a two-tiered or in a multitiered approach, the principles of HSM can be applied to migration, archive, and storage management systems as part of the asset management system or as an application layer in an overall storage management architecture.
Policy-Based Automated Storage Tiering
Attempting to manually manage data between two (or more) tiers of storage is an ill-advised practice; hence, the practice known as “policy-based management” was created. Some vendors and systems will utilize an “over-the-top” approach to automate policybased storage management. This practice may be used when the storage management system needs to touch several vendors’ hardware or software, such as in the case of an asset management system. Another approach is to employ an “in-line” solution that works across all the storage tiers.
Utilizing an in-line, policy-based solution to automate storage management practices is a much more practical approach. One of the architectures employed by those systems with only two tiers is an in-line device that is logically situated between clients and file storage. This device acts as a proxy for all file accesses. By employing an in-line technology, the system can respond dynamically to changes in storage system requirements.
When taking a two-layer approach, the data management on two tiers of storage is simplified and requires little human intervention. Companies that provide this form of two-layer management may offer a stand-alone “box” solution and applications set between the client and the storage platforms, or they may provide a similar set of services bundled into a larger set of services including HSM, deduplication, snapshotting, accelerators, and the like.
We will first look at the two-layer management approach and examine the multitier alternatives. Later, we will diversify the discussion into the associated services and technologies that may be applied in either a two-tier or a multitier storage management implementation.
File Virtualization Layer
The first of the two layers, referred to as “file virtualization,” allows enterprises to build storage environments that are comprised of different storage devices, platforms, vendors, and technologies. This process decouples the logical access to a file from its physical location on back-end storage.
Through these principles of file virtualization, the system federates multiple physical storage resources into a single virtual pool. In this simplified model, a virtual share is comprised of the total capacity that is found on two separate storage resources, a primary storage unit and a secondary storage unit. The first storage unit provides the online, mission-critical file storage. The second storage unit is used for less often accessed storage and may provide other services, such as deduplication, to keep storage capacities maximized. Using this approach, user/clients see a logical view of a single virtual share instead of two physical shares. The user/clients obtain “logical access” to files through the virtual share, and administrators (or third party applications) can move files between the two physical shares without impacting user/client access.
As the logical file mapping does not change, the file migrations never require any user/client reconfiguration.
Automation Layer
The second of the two layers, the automation layer, provides the necessary intelligence to ensure that all files are located on the appropriate storage tier. Data management policies are configured so that the system determines not only when and where to move existing files but also where to place newly created files. Policies are based on a number of considerations, including a file’s age, type, location, access rights, project status, etc. The automation engine consists of several components, the filesets, and placement rules. Figure 19.2 shows how the two tiers of storage are migrated using automation and file-virtualization layer technologies.
A fileset informs the storage management controller to which collection of data it should apply a policy. It defines a group of files based on a shared attribute or collection of attributes. Filesets can be created based on any portion of a file’s name, including its path or extension, size, or age based on last accessed or last modified date. Filesets can also be combined in unions or intersections to create more sophisticated policies.
For example, an aging policy can target MP3 files that have not been modified in the last 30 days, or all MP3 files that have not been accessed in the last 30 days. A “placement rule” then instructs the storage management system where to place a file that was matched by a fileset. Placement rules can be set up to target a specific share or, on a broader basis, a collection of shares as either the source or the target for data migration.
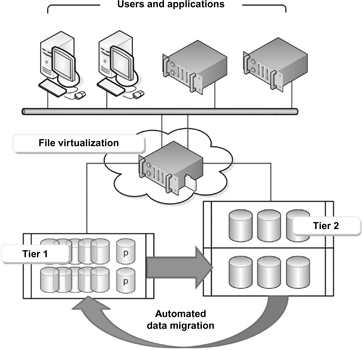
Figure 19.2 Two-tier automated storage using file virtualization.
To ascertain the scale of the storage management platform, one must consider the flow of data through the system at average and peak times. Configured in part like a Gigabit Ethernet switch with channelized control to manage throughput, the storage management system is built around both hardware and software. The hardware components are basically Gigabit Ethernet ports that are sized to the maximum throughput requirements of the data flows. Dedicated policy-based file virtualization systems (consisting of both hardware and software) take the place of the traditional multiport Ethernet switches that cross connect each user or server to a large pool of individual storage subsystems.
In summary, file virtualization systems simplify many of the traditional storage management tasks that would normally have been addressed individually on a platform by platform basis.
Multitiered Storage
Some organizations, especially larger enterprises and businesses that provide for several kinds of service, may wish to depart from the simpler two-tiered storage approach, even with the several value-added capabilities the more confined architecture may provide. When this is the objective, the storage solution moves into a multitiered configuration, often through the means of a “highly resilient storage environment.”
In this alternative, enterprise-wide storage data is then shifted so as to map the many elements of storage management into different tiers, also called “service levels,” depending upon the value of the data (information) to the enterprise as a whole. With this perspective, the easiest method to ascertain which data is assigned to which service level (tier) is to consider the value of that data to the enterprise relative to each working environment and each workflow. This will obviously vary with the business and the structure of the organization, so, for example, we will segment the storage tier architectures into the following four tiers:
Tier 1—where mission-critical, online data are maintained
Tier 2—where business critical information is kept
Tier 3—where workgroup and distributed enterprise data are placed
Tier 4—where reference, archival, and business compliance data are kept
The highest tier will be assigned the highest level of resiliency. As the service levels move to the lower tiers, the resiliency options can be selected appropriately. Regardless of the tier level, even for the lowest tiers (where archive, reference, or business compliance data is stored), there are inherent cost-effective and value-driven features available to increase storage resiliency for those purposes.
Before looking into what options and practices could be applied to which tier or service level, it might be advisable to understand how the industry looks at ascertaining or measuring recovery when an event, small or large, occurs that disrupts operations. An event could be anything from an outage on the network, to a loss of data accessibility, to a complete disaster when multiple systems or the entire site fails.
Recovery Parameters
Reducing the impact to the business in the event of failures and recovery times is a prime objective that is essential to establishing the degree of resiliency that a system must have. Every consideration will add to the overall cost of the storage system, so establishing the business value of each data class will more than likely involve certain trade-offs.
The industry uses two metrics to associate the performance of a storage tier and for setting a range of boundaries for acceptability: they are “recovery point objective” (RPO) and “recovery time objective” (RTO). Also note that these two metrics are used in establishing parameters for a disaster recovery (DR) solution.
•Recovery time objective (RTO)—The length of time it takes to return to normal or near normal operations in the event of an outage where accessibility to data is lost.
•Recovery point objective (RPO)—The amount of data, measured in time, that you can lose from the outage event.
These two primary considerations should be used in establishing the appropriate storage tier level for your data. These metrics are business-driven and set the stage for the following: whether you recover from disk or tape; where you recover to; and the size of the recovery infrastructure and staff needed to manage your systems. The RTO metric is relatively straightforward to understand, but RPO is a little more complex as it includes describing an “acceptable level of data loss”; that is, the tolerance level when data is inaccessible. RPO can vary, for example, from hours for reference data to zero data loss for compliance data.
Once in a situation where data is unavailable to those applications that expect the data to be present in order to function, the nonproductivity clock begins to run. As a result, when the recovered data is made available again to the application and what time it is available may be especially important, as only the end users and owners of the critical applications affected by any outage can understand (and pay for) the RPO and RTO specific to the “usability of the application.” The additional indicators that you may want to implement and/or account for are called “RPOData” and “RTO-Data” and may apply to situations where service contracts or internal financial accountability metrics influence the scale of the resiliency and how that scale affects budgets.
Operational Objectives
It is important to understand, especially when trying to design a solution that fits all the possible instances or implications, that RTO and RPO both by name infer that they are “objectives,” which by definition is effectively a target. If an RPO is eight hours, then the design solution architecture must ensure data loss of eight hours or less. Thus, when testing performance, or actually recovering from an event (i.e., a “disaster”), be sure to track and document the actual thresholds that are achieved, which will include recovery “point” and recovery “time.”
From the operational perspective, all too often, the time to recover does not meet the objective due to unconsidered “overhead” time. Overhead time needs to be accounted for when the organization needs to make considerations for items such as the selection of DR teams and if they can be fulfilled with the “available staff” as opposed to outsourcing the services as in a vendorprovided service contract or other outside entity. When disaster strikes, you need to understand when the actual declaration is made and mark the time for getting to the recovery site from that point. Finally, it is important to know and accept that this could be a massive undertaking and that the overall bedlam involved in initiating a recovery from a disaster is not something that occurs in everyday operations and is difficult to replicate, just as a fire drill does not exactly replicate the actual fire “event” or its aftermath.
Through the efforts of tracking and documenting actual versus objective (especially during acceptance, compliance, or routine testing), the organization will understand what is being accomplished in a given period of time. The value being that you will ultimately defend future investments by honing the recovery methodologies and processes to better meet or exceed those objectives.
When Disaster Strikes
In any form of disaster recovery, whether short term with minimal intervention or long term with deeper impacts, the recovery teams will be looking at all elements of the production and storage chain: servers, networks, and storage. Each of these areas have both interrelated and isolated roles that pertain to getting the system back online from a disaster. For this reason, organizations must routinely test the procedures and document the findings.
Depending upon the scale of the disaster, once the infrastructure is recovered and the associated application data is again available to users, there will typically be several other tasks that are necessary to make the application usable and presentable to end users. For example, if there is a suspicion that databases were corrupted, the analysts will need to evaluate what impact the outage had on lost data or unrecoverable information. These people need to do to the databases what the application and software teams needed to do to validate system functionality.
Having the metrics of your system available, because they were documented against actual test runs, will aid in assessing the short- and long-term impacts of how well the resiliency factors, which were designed into the system originally, performed. Briefly, it may not be fully possible to assess how well the design worked until it failed over and recovered back.
With these perspectives in mind, the context of tiers begins to make better sense.
Tier Classification R anges
Whether in an enterprise-class data center or in the central nerve centers of a broadcast program distributor, mission-critical data (your product in the case of a broadcaster) typically demands no unplanned outages and a zero tolerance for data loss (i.e., no “off-air or black time” for the broadcaster). These requirements place this level of data and the systems that support it into the tier 1 service classes for storage.
The requirements of other departments (such as news production or postproduction) typically have lower service levels and for the most part may be able to withstand longer unplanned downtime and minutes of lost data. This does not mean their data is anymore or less important; it is that the costs involved in supporting the equipments and values that these services have to the organization or product are not like those associated with mission-critical operations.
For other operations, such as long-term promotional services, Web design, or for smaller remote offices without shared storage, these workgroups could withstand as much as a day’s worth of data loss or inaccessibility, with outages resolved in hours instead of minutes.
As discussed earlier in this chapter, data storage can be segmented into different tiers or service levels for activities that occur and influence the productivity and performance of the enterprise. We will now look at some of the components and rationale for the multitier classifications outlined earlier.
Tier 1: Mission-Critical, Online Data
Mission-critical data has the highest value to the organization and by necessity requires the highest tier of storage resiliency. Data segmented to this tier is intolerable to any amount of lost data. Rarely, an occasional few moments of unplanned downtime will be withstood without directly impacting the front-facing product or the top line of revenue generation. In order to meet this level of storage resiliency, the enterprise needs to implement a set of features and guidelines and a set of options that result in a resiliency target with the following metrics:
•Recovery point objective (RPO)—zero data loss
•Recovery time objective (RTO)—zero downtime to recovery in minutes
Not only online applications will need sufficient protection but a scheme to migrate critical data to and from secondary storage (tier 2 or tier 3) should also be planned for. For broadcast on-air operations, the videoserver platform will generally have RAID drives, often RAID 6 or RAID 60, and occasionally RAID 5 for budget conscious operations. High profile program channels will usually use two identical server and storage platforms, called main and protect, with the protect being a 100% mirror of the main system.
For a production environment that works with digital intermediates (DIs) and visual effects for digital film production (i.e., “digital cinema”), tier 1 storage implementation could span the range from modest to high-end storage management. This workflow does not have the equivalent constraints of commercial on-theair or program content distribution broadcasting, so a different approach is taken. However, the deadlines imposed on these activities are every bit as crucial to the organization as is getting a broadcaster’s program and its commercials on the air and on time.
For motion picture or high-end national advertising productions, seldom is the original material exposed to the risks of the postproduction processes and storage platforms until the rendering or final assembly process. For this working environment, the original material is often transferred to an uncompressed data library with a high-resolution (high definition or equivalent) digital proxy created. Once the proxy is created, the production community only works with these proxy-based assets.
One of the differences in motion picture production is that the size of the data sets and the number of elements involved in a production (especially with effects) can be orders of magnitude larger in size compared with broadcast or program playback. With that in mind, the complications of handling these data sets or with migrating them to secondary storage or to backup protection present an entirely different set of issues.
For a data center or business operations’ environment, storage should be protected from any local storage-related issues through mirroring, the replicating of high value data to remote locations, and the use of nonsynchronized snapshots to mirror sites or vaults using a high-speed, long-distance interconnection. For reconstruction, to speed the process and to reduce the risks during reconstruction, the number of loops should be maximized. The size of the RAID groups should be smaller to support faster reconstruction, and also because of the reduced risks in the event of a smaller RAID set failure versus a large set with significantly larger single- drive capacities.
Tier 2: Business Critical Data
Here the target is minimization of disruptive activities. At this level, a business will typically be processing high value data. The loss of data or its unavailability for more than a few minutes is to be avoided. Higher value data classes are generally placed on storage systems with a resiliency level not unlike that of missioncritical systems but potentially with a reduction in the number of mirrored servers and storage set combinations.
Storage clustering may be employed when the organization is geographically dispersed or when several smaller offices are routinely connected into another set of regional offices. Clustering does not necessarily require that the drive components be physically adjacent to each other, and in some cases for data protection, they are allocated across more than one location.
•Recovery point objective (RPO)—from zero lost data up to minutes of lost data
•Recovery time objective (RTO)—recovery can take minutes (but not hours)
Tier 3: Distributed Environments and Workgroups
Some segments of the organization’s structure, which might include localized workgroups and workgroups that are geographically distributed across an enterprise environment, are often able to tolerate longer unplanned outages and some level of data loss. These types of deployments, at these lower service levels, can employ lower cost storage solutions that leverage the reduced costs associated with these lower tiers of functionality or performance.
Storage resiliency options are available when this class of storage is utilized in an active-active configuration.
•Recovery point objective (RPO)—data loss of minutes to hours for local workgroups, possibly up to a day for remote offices
•Recovery time objective (RTO)—recovery can take minutes to hours
Tier 4: Reference, Archive, and Compliance Data
This tier of storage is typically implemented as near-line storage using lower cost media, such as SATA disks in “just a bunch of disks” (JBOD) or simple array configurations. The data stored on this tier is seldom active and infrequently accessed for reads; so this environment is tolerable of longer downtime. For write activities, most archival applications will buffer the write data for hours, but are capable of queuing up the data for much longer should the tape or disk library be temporarily unavailable, out of operation for maintenance or for other uncontrollable reasons.
Tier 4 storage may include disk-to-disk (D2D), disk-to-tape (D2T), or even disk-to-disk-to-tape (D2D2T) methods for archive or data compliance applications. Which of these profiles are selected depends upon the need for accessibility, the volume of data, and the degree of protection required by the organization.
•Recovery point objective (RPO)—ranging from a few minutes up to a day of lost data acceptability, with no acceptable loss of data for compliance archiving (business data compliance is now critical in terms of legal protection and corporate records associated with Sarbanes-Oxley regulations).
•Recovery time objective (RTO)—recovery can take minutes to hours. If the data is stored in a protected vault off-site, the RTO could become a day or more.
From the loss of data perspective, a high degree of resiliency is still expected. Reference data accessibility can usually tolerate hours of inaccessibility, whereas any business compliance data loss is totally unacceptable.
Protecting Data and Storage
Data can be protected in various ways and by differing configurations. Based upon the needs, performance, and values that the storage contributes to the organization, a storage device hierarchy can potentially incorporate many layers of both physical (drives, controllers, and other hardware) and logical (software, virtualization, and replication) subsystems. The architecture of the storage solution affects the levels of protection and performance that can be achieved. Looking from a global perspective, the concept of a “storage triangle” (shown in Fig. 19.3), reveals three axes of storage that could be employed from one to many regions of the organization. The triangle graphically describes three differing configurations based upon capacity, bandwidth, or resiliency.
Capacity
If the goal is to achieve maximum capacity without worrying too much about bandwidth or resiliency, then the upper point of the triangle is one of the more straightforward approaches. In the “capacity” model, a massive number of inexpensive (e.g., SATA) drives could be strung together to form a JBOD configuration that holds oodles of gigabytes of data. The drawback of this course is that there is no protection, no integrated backup, and no resiliency in the case of having any one single drive in the JBOD group fail.
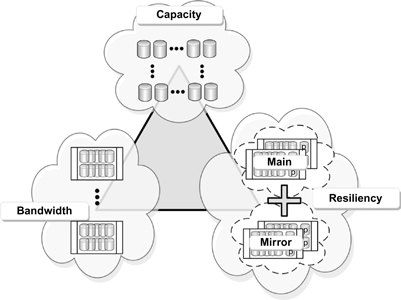
Figure 19.3 The “storage triangle” where three storage structures are described, which could be applied in different ways across multiple storage tiers.
This JBOD approach is not the recommended solution for a wide-scale, single-only storage implementation. However, this solution is not without amendments, as it could involve a mirrored (RAID 1) set of JBOD, or utilize a tape storage system for backup (not shown in the figure). This solution also has finite performance limitations and will only suffice as a second tier (or higher) solution without much online performance. Nonetheless, this is how the majority of PC workstations are configured, and reliance on other means of protection is becoming the norm (e.g., online Internet-connected storage backup in the cloud).
Bandwidth
The left lower corner of the triangle is where sets of striped RAID arrays (usually RAID 3 or RAID 5) could be used to provide both protection and bandwidth. Such a solution could be augmented with extensions using, for example, RAID 6 or RAID 53, RAID 10, etc. The significance here is that the data is protected at the block level, the drives are protected at the RAID-array level, and the system gets an additional benefit in that throughput (bandwidth) performance specs increase exponentially as more RAID sets are added. However, one of the today’s drawbacks is with drive capacities increasing through the 1-TB boundary and headed toward 2-TB boundary, and beyond in short order, the number of drives needed in an array to achieve needed capacity goes down, but the time to rebuild a drive during a failover increases horribly. This is why many storage vendors are finding that for bandwidth and RAID-striped protection, it is almost better to use more of the subterabyte- sized drives and gain the performance by other means.
Resiliency
The ultimate in storage protection and resiliency is achieved when there is a MAIN storage subsystem and MIRROR backup, as depicted in the “storage triangle” of Figure 19.3. Here, one finds an exotic array of RAID 6 protected LUNs grouped into primary (or primary plus backup) and then a complete mirror of the same set of storage arrays is placed either adjacent to the main array or in a remote location for added protection. RAID 6 provides two levels of parity protection, often with another “hot spare” included. In this model, the data is striped across additional RAID 6 arrays (or LUNs), all of which collectively provide bandwidth and protection. Mirrored drives provide resiliency by allowing for a 100% failover to the other system without a loss of productivity or performance.
Dynamic Capacity Balancing
Balancing policies help enable the enterprise to create a larger pool of “virtual file servers” composed of existing file storage devices. When coupled with “file virtualization,” a process that makes the physical location of the file immaterial, it is possible to aggregate various storage resources into a single pool. Completely utilizing a pool of storage resources falls on the shoulders of what is referred to as “dynamic capacity balancing.”
Beyond getting the best economic value out of any existing storage resources, the capacity, bandwidth, (throughput), and processing power for these physical devices can be optimized for application performance using virtualization techniques. Grouping all the storage resources together under a common set of storage management policies allows administrators to perform data management tasks, such as load balancing and provisioning without disrupting users or applications, and it can be accomplished in real time.
Additional value is obtained because backups can be optimized by splitting the virtual file system into multiple physical ones and then by performing smaller backups in parallel to mitigate the complications and the time involved with a single, large backup. Restoration activities are then shortened as well. And with a single virtual file server, performance hot spots are eliminated because those individual devices are now aggregated and controlled by a single server instead of individually managed.

Figure 19.4 Dynamic capacity balancing.
Figure 19.4 depicts how minimally used resources are aggregated through the virtualization process to obtain more usability than when the individual resources are discretely addressed. The aggregation process, consisting of intelligent file virtualization, improves bandwidth and system-wide efficiency.
The depths and topics of overall load balancing at a system level involve several areas, not the least of which are networkbased, and must certainly include all the elements of hosts, nodes, members of groups, servers, and the like. Load balancing, in theory, allows the distribution of inbound traffic across multiple back-end destinations, thus forcing the concept of a collection of back-end destinations. Clusters (also called pools or farms) are collections of similar “services” that are available on any number of hosts.
In moving media applications, services that provide for the transcoding of all video and audio streams throughout the organization would be housed onto what might be called the “transcode farm.” Quality control and file-syntax compliance checking are a processing service that might be clustered to the “QC pool” and so on. The fundamental concept here is that all these systems have a collective object that refers to “all similar services.” The task then becomes to make the best use of each of the services, without having to know (and independently control) the physical devices that provide the services.
The same applies to storage utilization, with the best use approach then being managed through the concepts of dynamic (load) capacity balancing.
Heterogeneous Environments
Influenced by an emphasis on cost control, much has been made on the value of heterogeneous storage architectures where storage elements from different vendors can be installed that are able to interoperate and still meet organizations’ storage demands. Common to any “best-of-breed” IT purchase argument, the benefits cited in this philosophy are lower product acquisition costs due to price competition, potential decreases in total storage costs, and avoidance of proprietary solutions provided only with vendor lock-in.
Coupled with the slow progress perceived by the storage industry toward a more unified storage management environment, the lack of emerging storage management standards, or the consolidation of storage management tools, external third party solutions are coming of age as a centerpiece in resolving such issues as NAS sprawl, variances in performance across the overall enterprise-wide storage solutions’ package, and a preponderance of individuals aimed at using departmental budgets to solve their own problems with little concern for the overall longterm enterprise storage management objectives.
Island Management
The time and effort it takes to manage islands of storage across a large enterprise are growing in proportion to the amount of storage added, which we all know is continuous. The complexity of employing storage components from diverse numbers of vendors necessitates developing compatibility matrices that must be matched and adhered to retain peak operational performance. This alone can grow exponentially with the increasing number of vendors that all too often provide a low-bid solution to an enterprise-level problem. So, these services must be outsourced, which also adds to the cost of operations and induces risk if or when failures occur.
Managing the different versions of embedded code, software, and driver interfaces can be even more complex, usually outside the expertise of most IT departments, especially those who have “help desk” oversaturation at much lower levels.
Storage management solutions that integrate multiple sets of heterogenic storage products need to provide user-transparent functionality through the employment of hidden, almost sideline, tool sets that effectively manage data tranformation from a virtual storage pool to the user/client platforms, and vice versa, regardless of whether the assets are stored on primary and secondary storage components. Storage management needs to enable flexibility and compatibility with network-attached storage (NAS) and storage area network (SAN) devices and servers in order to enjoy the benefits of virtualization across a heterogeneous infrastructure. By employing an intelligent in-line storage management solution that virtualizes the individual storage components, one can prevent the need for forklift upgrades of hardware, the replacement of existing file systems, or the installation of software agents across the enterprise.
Storage management solutions should use industry-standard file access protocols to communicate with clients and servers; for example, CIFS for Windows devices and NFS for Unix or Linux devices. The solution should not need to introduce a new file system and instead should only act as a proxy to those file systems that are already in place.
Employing RAID
The predominant method for data and storage protection comes from the multiple choices available when employing RAID technologies for resiliency and bandwidth. Using RAID to protect data on the hard disks reduces the risk that data will be lost should a drive fail, while at the same time improving data throughput and the bandwidth of the overall storage picture. In Chapter 6, the depths and dimensions of the various RAID levels are covered in much greater detail.
In platforms that require all three elements of the storage triangle, that is, capacity, bandwidth, and resiliency, it is important to select a RAID level that supports redundant parity and hot spares as an aid to maintain the responsiveness of the storage system. In the unfortunate event that a drive in an array (or LUN) fails, having the additional readiness of an extra parity drive will help maintain the operation of that segment of storage.
Yet RAID protection, mirroring, and remote extensions for disaster protection are only a part of the resiliency equation. We have explored storage tiering and other elements aimed at assuring “nondrive related” anomalies will not affect operations. Even with automation or storage management subsystems, we need to be even more certain that the storage platforms can address the answers to the resiliency questions with instruments that also focus directly on the physical disk media used in the storage subsystems.
Lost Write Protection
Other than during a complete disk failure, a write operation disk malfunction will rarely occur where a block of data is silently dropped or lost, but the disk is unable to detect the write failure, and it still signals a successful write action status (a false positive reporting). If no detection and correction mechanism are in place, this “lost write” event causes silent data corruption.
Checksums, used for data integrity (explained below) will not protect against a lost write event. By employing a “write signature” feature implemented in storage virtualization technology that aligns closely with RAID integration, this type of failure can be identified and will be detected upon the next read, and the data is then re-created using RAID. Such an implementation is available on systems from vendors, in particular NetApp, in conjunction with their Write Anywhere File Layout (WAFL) storage virtualization technology, where even block-oriented, SAN installations can have this level of protection.
Note that this is not the same as a “lost delayed-write data” error message that might have been received under extremely heavy file system stress activities (an occurrence in Windows 2000).
RAID Checksums for Data Integrity
High-performance, resilient storage solutions will frequently offer additional drive data protection schemes beyond those already implemented in the RAID controller. One of these methods generates a checksum for each block of data that is stored as part of that block’s metadata. To ensure data accuracy, when that block is later read back, a new checksum is calculated from that read data and is then compared against the metadata originally stored for that block. Should the metadata differ, the data read back is presumed invalid; therefore, the requested data is then recreated from the parity information on the RAID set, and the data is rewritten to the original block. The entire check is re-created to validate the second (replaced) data set that can be properly recovered with valid data.
For active data sets, where reads and/or writes occur frequently, the checksum provides another avenue to data integrity. This form of resiliency is referred to as a “self-healing” storage activity and is used to proactively protect data path and other disk drive errors. In systems that employ this degree of self-preservation, the functions are usually turned on and remain on at all times.
RAID Scrubs
Ensuring drive reliability improves accessibility and in turn increases system resiliency. Enterprise drives, which are bound by compliance requirements, normally develop fewer errors than standard drives (e.g., SATA) found in home computers and PC workstations or used in secondary storage arrays. However, any drive may develop errors for a variety of reasons that can be both age- and usage-related. The unsuspected damage may occur from microscopic particles that have become lodged in the media, or frequently accessed areas of a drive may simply wear out and become corrupted. This kind of damage is called a “latent sector error” (LSE), because there is no routine way to detect the error until a request to read the data is made.
Another anomaly that can occur is from those files that are located in home directories, which tend not to be accessed nearly as often as active data, mainly because of the age of those files. While RAID checksums ensure that data read from the drive is accurate before it is offered out to the user (i.e., application) as “requested data,” it may not be the full answer to ensuring disk drive integrity.
A process referred to as “scrubbing” improves data availability by finding and correcting media and checksum errors while a drive or RAID group is in its normal state. The activities may be run manually or assigned to a schedule, usually once a week for high-performance, high-availability systems.
Many current systems will perform sequential disk scrubbing, which is checking disk sectors sequentially at a constant rate, and is employed to detect LSEs in a timely fashion. Some storage system providers (such as EMC Corporation in cooperation with RSA) are looking at a different approach where rather than using the sequential method of scrubbing they will vary the scrubbing rate over a number of sectors in a given time period. Utilizing the fact that LSEs tend to arise in clusters, a repeated sampling of a region will identify LSEs faster than when scanned using a sequential process; this staggered adaptive strategy in theory makes sense.
Determining an optimal scrubbing strategy for a given disk configuration may in turn lead to a way to automatically engage a recovery operation when errors are detected. The results of the scrub could be transformed into the solid state/flash memory domain (as in SSDs) to predict errors in memory before they affect other cache implementations.
Ideally, both the scrubbing and checksum methods will help improve the reliability of storage systems and the availability of the information contained on those storage systems. While adaptive scrubbing algorithm technologies are still in their infancy, researchers further feel that these technologies will lead to better- designed algorithms that will significantly improve existing storage and data integrity technologies.
Predicted Errors
Enterprise disk systems and high-performance, intelligent storage platforms all employ levels of predictive diagnostics that aid in supporting advanced notifications of eminent drive failures. Some of these systems use the reporting features of the drives, plus their own data collection routines and algorithms, to signal that a drive may be failing or is about to fail. These systems will then jump into a routine that tries to read and then write as much as possible from the affected disk into a cache or hot standby disk, with the balance of the corrupted or missing data generated from parity.
Again this is a practice that is widely deployed by storage management systems and can routinely be found in professional broadcast videoserver systems, news-editing platforms, and purpose- built storage systems used in mission-critical applications.
Historical File Tracking
When automated storage tiering is employed, physical media consumption should theoretically be reduced. The added benefit in reduced storage consumption management is that the time required to support both backup and recovery periods is also decreased. These objectives are beneficial to controlling the physical costs of the media that include not only the capital costs of the hardware but also the operational costs of power, cooling, and data center or central equipment room real estate. In addition, automated tiering storage should offset the lost productivity time during the recovery periods. However, automation can also make it more difficult to locate and restore individual files from the backup media, unless other levels of system management are included.
Given that storage management is now more virtual in nature, a means to simplify file recovery is necessary. One of those methods is “historical file tracking,” a method by which administrators can use elements of the storage management solution to identify the physical location of the individual files at any point in time. With file versioning, coupled with virtualization, it is now all the more important to know not only the name of the file but also the version of the file (usually chronologically categorized) so that time is not lost having to analyze the file content after the file or files have been located, restored, and prepared for usage.
Checkpoints and Snapshots
When integrating or combining heterogeneous storage environments into a virtual environment, for example, in the concepts described earlier, the potential for data corruption as a result of moving data between the storage tiers is always possible. The risks associated with data interchanges between disparate storage platforms, such as false writes or reporting of false writes, require an alternate means for ensuring data accuracy. One of the concepts developed to aid in validating that write actions to drives indeed occurred and that the data was properly recorded is referred to as “snapshotting.”
Snapshots
Snapshots are used to capture an instance in time where all the states of the most recent read or write activities are recorded to a secondary protective storage subsystem. This procedure is a cache-based activity that quickly captures the changes in a data set, stores it into another location, and then uses it to match the present datasets to the data that was properly written to or read from main storage memory. The technology is used in support of coordinating physical snapshots across multiple NAS devices and file systems, even those from different vendors within the same virtual namespace. The snapshot is navigable in the same manner as the virtual file system from which it was created, giving users the ability to recover their files in a virtual environment.
Snapshots are useful for storing the state of the system so that an administrator could return to that state repeatedly. A virtual machine snapshot is a file-based representation of the state of a virtual machine at a given time. The snapshot will generally include both configuration and disk data.
In these highly active environments, snapshots will consume significant amounts of storage space over time, unless they are purged after backups or file audit/reconciliation. Snapshots are often contained to solid state (ram-disk like) devices, or similar short-term storage caches that are based on technology that can rapidly write data to the store, then hold it there while checks are made, and then purge it quickly in preparation for the next capture.
Checkpoint
A checkpoint, in a virtualization context, is a snapshot of the state of a virtual machine. Like a restore point in the Windows operating system, a checkpoint allows the administrator to return the virtual machine to a previous state.
Checkpoints are most commonly used to create backups before conducting updates. Should an update fail or cause problems, the administrator can return the virtual machine to its state prior to the update. The recover action is used to return the system to the checkpoint state.
Virtualization in File-Based Storage
Virtualization is not new to most computing environments. Parenthetically, any technology that is camouflaged behind an interface that masks the details of how that technology is actually implemented could be called virtual.
Virtualization, from the perspective of a server needing to address the storage systems, is used to abstract a view of the storage, its locations, and its resources.
Needs and Wants for Next Generation Storage
Driven by the enormous growth in file-based information and the critical needs to more reliably and cost-effectively manage these information assets, organizations from small offices through production boutiques to enterprise-size IT-centric corporations and motion picture production studios are implementing new strategies for building and managing file-based storage solutions. These appropriately called next generation (“NextGen”) solutions must now meet prescribed business and technical requirements to be successful and to provide value to the organization. Corporations and businesses are now compelled to retain significantly more information, electronic and otherwise, than in the past.
These NextGen solutions now allow enterprises to deploy and consistently manage services across a wide range of disk- and tape-based storage tiers with different performances, capacities, availabilities, and cost characteristics. The challenge is that they must attempt to do this without having to make a forklift level, wholesale displacement of their existing assets. NextGen systems now enable a common set of scalable and highly available global namespaces that support data migration, data life-cycle management, and data protection services across multiple storage tiers.
Virtualization, in concert with cloud-based storage technology, is a widely discussed trend throughout the IT industry. For traditional workstation and certain server implementations, the IT managers may be consolidating many x86-based applications onto a single server.
Storage Virtualization
Virtualization has become an equally important trend in the storage market. Yet, the focus is almost exactly the opposite. Rather than consolidating multiple servers onto one piece of hardware (as in the traditional virtualization sense), network-based storage virtualization is frequently about allowing storage professionals to manage multiple storage systems (e.g., NAS- and SANattached arrays) into a centralized pool of storage capacity. These next generation storage systems will allow IT managers to more straightforwardly and nondisruptively migrate data between storage platforms, heighten the utilization of installed capacity, scale data protection and security processes, and implement tiered storage policies to control costs.
The following sections will explore the elements of file virtualization, and the techniques and technologies that once lived entirely in the data center but are now migrating to the cloud as we search for improvements in storage and data management.
File Virtualization at a Network Level
Determining objectives and considering what elements to address when looking at network-based file virtualization can be approached by examining some general cases and practices that IT administrators are faced with when looking for solutions to this global explosion of data. Three of those areas will be looked at in the following sections:
•File migration and consolidation
•Dynamic storage tiering
•File sharing on a global dimension
File Migration and Consolidation
In order to boost utilization of NAS systems, consider the consolidation of dispersed file servers or legacy NAS systems onto a smaller number of NAS systems. This opportunity enables greater data sharing and improves both backup and data retention processes. The challenge to this is that the migration time for even a small set of file servers can take upwards of a year to plan, implement, and complete. It can take a huge number of resources away from the IT-management side and be quite disruptive to users, limiting productivity and forcing continual incremental workflow adjustments.
Of course, these numbers grow continually, especially when organizations of any scale might be adding a terabyte or more of data per week to their NAS systems. By changing to a file virtualization approach, organizations are able to reduce all the elements that would have been involved with migration, including the time associated with planning and mostly if not all of the downtime. In some cases, this implementation methodology dropped from 1 year to less than 1 month and radically reduced the amount of disruption to users and productivity.
Dynamic Storage Tiering
Optimizing capacity of NAS systems so as to control cost and NAS sprawl can be resolved by deploying a solution that moves old, stale, and infrequently accessed data and the associated backup copies of that data to a storage tier that focuses on capacity and low cost (refer again to the “storage triangle” of Fig. 19.3). End users will typically refuse to eliminate old files from networked drives, dispersed production editing platforms, e-mail systems, and other departmentally isolated storage platforms. These islanders further refuse to manually move data to separate archival drives, elevating the risk factor to enormous proportions. Most use cases will find that as much as 60–80% of this stored data is infrequently accessed. So, the time and capacity management issue becomes even greater because backing up all this infrequently used data now increases the backup times, makes data more complicated to locate when or if it must be restored, and leads to massive duplication of data on tapes. Given that most tape backup libraries charge by the volume of tape being administered, the cost impacts to the bottom line are massive.
By employing the techniques of network-based file virtualization, case studies in as recent as the 2007 time frame (about the time when file virtualization emerged to the forefront) showed that organizations were able to reduce spending on disk storage hardware by around 40–60%. In IT-based organizations, some found that they reduced the recovery times for files and e-mail from days to hours and further reduced the time and costs of backup to tape by 50–80%.
By shifting the data from high-performance NAS-head configured storage to less costly SATA drives (an average cost reduction of around 75% only for the drives), and by employing an automated data migration system using virtualized files, case studies showed that the frequency of backing up older files (e.g., spread sheets, e-mail, general office documents) decreased from once a week to once a month.
For media organizations, such as content owners that produce their own original programming with hundreds to thousands of “legacy” or archived clips or program segments, which could be located all over the enterprise, these activities could be greatly reduced once a file-virtualization program with automated data migration is set in place. Media asset and content management solutions generally provide some of this functionality, but more is necessary if consolidation and protection of assets are to be achieved.
File Sharing on a Global Dimension
Dedicated content production systems have been wrangling their own data on their own platform for ages. With the trend continuing, whereby isolated companies work on different platforms and with various applications, sharing the content during the program or production development processes is a growing concern. Not only are there connectivity issues to be dealt with but also file versioning, security, and true collaboration are all high on the agenda.
When the organizations are geographically separated, this problem increases geometrically. To facilitate collaboration on projects or program production, all these users need a reliable, easy to manage, and secure means of sharing files across diverse geographically separated locations in order to boost productivity and, more importantly, to minimize version control issues. The challenges are raised when considering that each department, location, or independent contractor has its own file namespace, so sharing either requires opening up access to all potential users (posing major security risks) or necessitates the continual replication of files over long distances.
File virtualization can improve productivity by allowing users in multiple workgroups and remote locations to collaborate more effectively through a common access platform that allows them to share files transparently between them. Using an automated migration and file management platform will aid these processes in a global sense because new workgroups and users no longer need to know what the other workgroups or locations’ particular file naming requirements are. They simply work as usual, and in the background, the file management system handles all the “under the hood” storage, backup, duplication, or replication activities, improving productivity and minimizing risks due to security flaws or lost data.
Storage Resource Virtualization
Virtualized storage resources are becoming part of the new “converged infrastructure” (Fig. 19.5). In order to realize the true benefits of convergence, storage solutions are needed that will easily accommodate data growth and align strongly to business applications. A converged infrastructure will use its storage resources to be virtualized, which then allows for the dynamic provisioning of resources to support applications when capacity (or bandwidth) is needed most. This enables capacity optimized with lower cost components to be used effectively. It will reduce management complexities as the organization reacts to the explosive growth is data.
Figure 19.5 A virtualized storage infrastructure.

One of the principle concepts behind storage virtualization is its ability to address the three dimensions of storage system demands, while maintaining a single environment that is transparent to the user and easily administered throughout the enterprise storage life cycle. For this, all the following elements of scaling are required:
•Scale-up—addresses increased system demands through the dynamic addition of virtual storage directors, ports, caches, and storage capacity. Such scaling activities aid in managing storage growth, while continuing to provide the highest performance for the environment.
•Scale-out—meets the multiple demands by dynamically combining multiple devices into a logical system with shared resources to support the increased demand in virtualized server environments and to ensure the quality of service expected through the partitioning of cache, ports, and access control based on resource groupings.
•Scale-deep—extends the storage value by virtualizing new, existing external storage systems on a dynamic basis, even with storage provided by different vendors. Scale-deep enables the off-loading of less demanding data to lower (external) tiers so as to optimize the high availability (HA) of tier 1 resources.
When and How Much
Even though virtualization is now showing up in all the segments of the storage infrastructure, there still remains some misunderstanding on when to use it and even where to embed it. Administrators see control and visibility of virtualization as key elements in obtaining the maximum benefits possible from this technology. When to use it depends in part on the physical and logical sizes of the storage infrastructure, the locations that will be consolidated, and the type of applications running on the platforms.
Storage managers will need to balance the benefits of virtualization against the complexity it brings. They need to match the intelligence of the existing SAN or NAS components to the levels of (file) server and degree of storage virtualization. Through partitioning, the process of assigning each layer of storage virtualization its own administration, bandwidth, and processing, the storage manager can determine how best to satisfy the requirements at each layer. This prevents applications in one partition from impacting the productive aspects of another.
The degree of virtualization needs to be analyzed and tested. Sometimes it is more appropriate to use less virtualization for performance-intensive applications. For example, a GPU processor component may be better suited to one layer of storage versus a render farm engine that needs a different layer to achieve its throughput targets. This concept can be applied to “edit in place” functionality for nonlinear editorial production versus art-intensive graphics composition. Both need highly available and independently addressable workspaces to accomplish their tasks due in part to the fine-tuning of the applications running on the workstations. However, with file format interchange capabilities, such as in the MXF format, this hurdle is getting lower to cross as time moves on.
Scaling into virtualized storage or servers begin with the low performance services or the less utilized segments of the environment. This is because low performing servers will see the highest performance returns when moved to a virtual environment. High-performance, high-utilization components are already finely tuned to achieve maximum throughput and may only realize a modest gain in performance.
Table 19.1 shows the comparison of legacy solutions with the NextGen storage management solutions.
Fault Tolerance
Designing a system that has no “single point of failure” (SPOF) is a common issue facing most engineering teams when answering Requests for Proposals (RFPs) related to media storage technologies. Improperly judging what has become a mostly generalized “no-SPOF” requirement often leads to over engineering the solution. However, if the system is under engineered the approach leads to potential liabilities should their “low bid” be awarded and the provider is forced to design a system that fails. When confronted with designing or providing for a fault tolerant system, the better statement would be one that the end user sees as livable and more in tune with real-life operations. So the question that needs to be answered becomes “explain how your system will be fault tolerant using the components provided for in your design.” Answering this question correctly requires that the vendor have a true and fundamental understanding of what fault tolerance really means and systems in your design.” To answer that statement, fundamental understanding of what fault tolerance really means is required.

Fault tolerance is the property that enables a system to continue operating properly in the event of the failure of one or more components within the system. Sometimes called “graceful degradation,” the concept to understand is that if the operating quality of a system decreases at all, the decrease is proportional to the severity of the failure of the component. These components could be the network, the transmission protocol, the protection scheme for the disk arrays, the software applications, etc.
Fault tolerance can be achieved by recognizing and anticipating conditions that are well outside the routine expectations and performance of a system (when functioning properly) and then designing the system to handle them. It could be that the systems either will muddle through the fault with transparent but reduced performance or will survive the problem by switching over to a completely redundant parallel system that simply waits in the wings to be called to duty.
Fault-Tolerance Characteristics
Systems that are designed for high availability and high reliability are built so that they are resilient to all conditions related to failover. Fault-tolerant systems are characterized into two classifications: planned service outages and unplanned service outages. The services are measured at the application level because, for the most part, the hardware level (when it fails) will more than likely be realized first at the application level.
Fault tolerance is, in a sense, the opposite of scalability. A system is considered scalable when its ability as an application or a product to continue to function well is changed in size or volume according to a user’s need. With this, it is the ability not only to function well in the rescaled situation but also to actually take full advantage of it. A system’s fault-tolerance factor is considered high when, as the system begins to scale down due to an issue in any one or more of its components (or subsystems), it will continue to work but with elements of performance degradation that do not significantly impact the user’s needs.
There is obviously a point where fault tolerance moves to the stage of failover, but if the system was designed with sufficient protective measures, then it will failover seamlessly and operations will continue undisruptedly.
To meet these objectives, the basic characteristics required are:
•No single point of repair—that is, all components must be either replaceable or repairable without risk to terminating operational services.
•Fault isolation—a failing component can be detected and quarantined (isolated) from the rest of the system to enable diagnostics or repairs to occur.
•Fault containment—the potential for a failing component to continue to affect other components must be alleviated so that propagation of the failure does not escalate to the level of a system failover or disaster.
•Ability and availability of reversion—the ability of a system to return to normal operations once the failed components or issues have been rectified.
Fault tolerance is particularly sought after in high-availability or life-critical systems. However, in the context of storage systems, a precursor to fault tolerance is high availability leading to systems or components that will be in continuous operation for a long duration of time.
Availability is measured relative to a figure of 100% operational; that is, a “never failing” condition. This is a widely held and yet extremely difficult to achieve standard often known by the vernacular of “five 9s” (99.999%) availability. This level of service, often used in statements described in “service level agreements” (SLAs), is equivalent to only 5.26 min/year of outage (6.05 seconds of downtime in a 1-week period). It is also a statement that requires a substantial amount of definition as to just what downtime, failure, or reduced performance mean. In many cases, especially for SLAs, this becomes an answerable and defendable question only by attorneys.
Complex Systems
By nature, systems with a high degree of complexity are generally composed of multiple parts that when properly combined take advantage of their respective strengths to build a value that is much greater than the sum of their individual parts. If there are many parts in the systems, then it makes sense to have some of those “mission-critical” parts far more fault tolerant than others. This brings in the concept of multipathing and how it helps to achieve the effective implementation of complex systems.
Multipathing
Simply stated, when there is more than one means to get to the same physical device, then the system is built with multipathing.
Multipathing can be achieved by using several adapters in a server that is assigned to the same logical unit (LUN) or volume in a storage platform. Multipathing may be implemented through additional ports in an enterprise class switch or storage subsystem (see Fig. 19.6), or by a combination of both. In complex systems (see Fig. 19.7), this happens with multiple NICs, dual redundant switches, two or more media directors, and split storage arrays with sufficient capacity and availability to service the entire system on their own (i.e., stand-alone).
Bottlenecking
The previous examples are more physical in nature than logical, although the processes that manage the path that is in command are essentially software related. Performance in an application depends upon several physical components (e.g., the memory, disk, or CPU), such as the speed of the network and disk I/O and the associated parameters of the application servicing the user.

Figure 19.6 Multipathing by providing more than a single adapter between a server and a storage device.
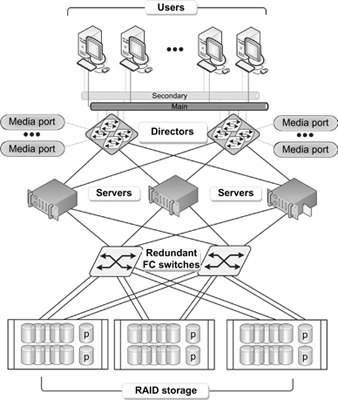
Figure 19.7 A complex server system with redundant Fibre Channel storage switches, media directors, LAN switches, NICs, and media ports.
One means to increase performance, and thus build resiliency and fault tolerance, is to remove bottlenecks in the servers, storage systems, and networks. Multipathing can help alleviate bottlenecks in the following ways:
•Add additional I/O adapters to the server—they increase the I/O rate of the server.
•Use or add additional host adapters on the enterprise storage system—this allows for more throughput (bandwidth) provided the controllers can address the increased I/O cycles.
•Add more CPU horsepower or data flow management capabilities—systems can add more compute power or prioritize data activities on an application-specific basis.
•Add multipathing software—increases the systems’ abilities to handle multiple streams simultaneously, as in render farm engines or content distribution platforms.
Disk mirroring, explained in Chapter 6 as RAID 1, places two copies of all the data on two drives. This is accomplished either in hardware or software by the RAID controller. Software mirroring accomplishes the same function but does not employ an outboard hardware controller, instead one or more applications create the duplicate content and manage its distribution to and from the two (or more) mirrored disk drives. Hardware controllers manage these activities without CPU intervention.
Multipathing is ideal when there is a nonmirrored environment or when mirroring is not an option. Although mirroring protects against data loss by a disk failure, if the mirror ends up with the same errors as the primary, nothing has been resolved.
Clustering
The grouping of servers and/or other resources so as to provide a set of network resources to a client as a single system, which enables high availability (HA), parallel processing, and/or load balancing, is called “clustering.” Chapter 14 discusses clustering in greater depth, so this section will focus more on the fault-tolerance aspects in storage systems.
Clustering groups multiple workstations and servers, multiple storage devices, and redundant interconnections to form what appears to the outside user as a single highly-available system. Clustering may be used to flatten out application or storage hot spots, called “load balancing,” so as to achieve maximum utilization of the resources. Advocates suggest that an enterprise can reach 99.999% availability by employing cluster technologies, yet these numbers must consider all the influences across the entire organization.
Load balancing will divide the amount of work that a compute system is assigned to do among two or more compute platforms (e.g., individual workstations) so that more work is accomplished in the same period of time. Load balancing can be implemented with a combination of hardware and software, similar in function to what modern CPUs with multicore processors might do instead of having multiple fully fledged chassis-like workstations employed. Load balancing is typically the chief reason for computer server clustering.
An alternative to load balancing is parallel processing whereby program execution is accelerated by dividing the instructions and activities among multiple processors (CPUs typically) with the objective of running a program in less time.
Clustering further protects the client from changes to the physical hardware, which brings a number of benefits, especially in terms of high availability. Resources on clustered servers act as highly available versions of heretofore unclustered resources.
Nondisruptive Operations
Administrators have the availability to employ any number of policies that are useful for the tasks of data migration, upgrades, and preserving fault tolerance. Regardless of whether the tasks are quite simple, such as migrating from one RAID set to another or larger, more complex activities that involve moving entire sets of individual files to one file system, all these activities must appear nondisruptive or fault-tolerance sustainability is not achieved.
When performing activities such as data migration or upgrades, especially between heterogeneous storage devices (e.g., both NFS- and CIFS-oriented data),they should be scheduled so as to avoid peak traffic times or system backup windows. Migrations should also be performed without changes to mount points or drive mappings so as to eliminate outages and mitigate business disruption that might have been previously associated with other data migrations.
Upgrades, if at all possible, should be implemented on redundant hardware before committing them to the system full time. Versioning of all software and hardware should be well documented and validated against conflicts with legacy versions of any components in the enterprise system, unless of course those other systems will never interact with each other in any form (something that is highly unlikely in today’s technology wrapped world).
Key sets of considerations should be understood and planned to avoid disrupting business activities that would otherwise impact users or halt applications. High-performance HA systems will usually allow administrators to perform data migrations for any reason at anytime. This class of system will support the completion of data migrations in less time and with no need to schedule downtime with business groups or users. When performed properly under the control of automated policies, data migration will use fewer resources and eliminate the requirements for reconfiguration of individual clients.
Conclusion
Resilient systems, high-availability systems, and fault-tolerance systems, including those using virtualized components, are now all a part of the “expected performance criteria” that we have grown to depend upon for e-commerce, homeland security, banking, and even simple everyday social networking.
The media and entertainment industry has grown into the same mold as it produces more content in shorter time frames, with less people and declining budgets. By providing a service-oriented architecture (SOA) that is composed of resilient HA systems that users can depend upon to accomplish their work—even in times when certain fault-tolerance systems have moved into backup mode or are recovering from a failover—we can obtain a much greater value from both our legacy existing systems and any new systems that we add to the enterprise working environment.
Further Readings
“Fault Tolerant Storage Multipathing and Clustering Solutions for Open Systems for the IBM ESS,” IBM Redbooks, April 2002
White papers, product design literature, and other resources from storage providers including Network Appliance (NetApp), EMC Corporation, F5, Hitachi Data Systems, and IBM are available at the following websites: