
14
CLUSTERING
Traditionally, storage systems were designed for structured data where the file sizes were small, and the systems, such as databases or email servers, could be optimized for high levels of transactional processes. With the growth in unstructured content, certainly for motion imaging, motion picture production, and multimedia applications, traditional storage systems can no longer address the demanding issues arising as media files have exploded in size, volume, and complexity.
Storing unstructured media data requires some fundamental changes to storage systems due to larger file sizes and data volumes, higher throughput requirements, high concurrent file access, and read-intensive access patterns. Solutions developed to address these differences grew out of the concepts of clustered servers.
Clustered architectures, including storage and servers, have changed the rules of how data is stored, accessed, and processed. This chapter is about those changes and how the requirements for the storage of unstructured data, especially media files, might be met through clustering.
KEY CHAPTER POINTS
•Defining distinctions between grids and clusters from the storage perspective and the computer/server perspective
•Looking at the various “sharing” architectures such as shared nothing, shared everything, and mirroring
•Qualifying, selecting, and managing grids and/or clusters
•Common scaling characteristics for clusters and grids
Why Use Clusters?
The enterprise has continually been driven to address the growing needs for increased compute power and enhanced storage capacity. During this evolution, it was not uncommon for the IT managers to employ multiple sets of discrete workstations or servers to address the ever increasing scaling of processes. Managing the proliferation of individual devices and dedicated storage increased the time and risk associated with data and information services.
IT system administrators began to adopt clustered server architectures as a means to handle these requirements without having to displace an already hefty investment in existing servers, workstations, and other storage components. By aggregating standard industry grade servers, systems would achieve higher levels of performance, reliability, and scalability. Concurrently, overall workload management also improved. Through the employment of clustering, systems could be expanded and the performance of the systems increased at a fraction of the cost of the traditional “big iron” single-box solutions with their complex multiprocessor subsystems and file management architectures.
Clustering may be looked at as a solution to protection against failures. It can also provide an avenue for load distribution. It can be used as a means to extend the useful life of legacy servers or storage components. Regardless of how and under what kind of architecture it is implemented, clustering seems like a valuable direction to go in when existing solutions and components fall short.
However, clustering of servers brought on new issues for storage management. Administrators would have to respond to the islands of storage that were now dedicated to each of the server/ cluster functions. Virtualization was certainly one possibility; cloud storage seems to be becoming another. Nonetheless, seeming to solve one problem unfortunately created an entirely new one. Industries, even before the growth in unstructured data, were in search of a different solution that could handle the integration of SAN, NAS, and DAS storage systems.
Defining clustered storage can be difficult, because although it is similar in concept to clustered servers, it can have several different meanings and implementations. Depending upon the application and business requirements in which clustered storage is applied, the sharing and consolidation of storage-centric activities can yield significant cost reductions, performance increases, and manageability of both growth and obsolescence.
Clustering is, in fact, one of the oldest types of storage because of its appealing abilities to scale out (horizontally) in terms of capacity well beyond the limits of a stand-alone storage implementation. Clustering is not bound by geographic regions and can be implemented over great distances adding to versatility, performance, and resilience.
Clustering may be tightly coupled or loosely coupled. Solutions from vendors are available in either method. Clustering can be applied in file, block, or object based configurations; with the latter being the most distinctive. Clustering offers the advantage of managing a single namespace instead of multiple servers, each with their own.
Clustering aids in mitigating single points of failure (SPOF) by providing multiple paths and components that can keep the system working even if one of the segments or elements is unavailable.
Physical Components
Traditionally, storage systems are bound by the physical components of their respective configurations. Some of those elements include the following:
•Number of disk drives
•Number of attached servers
•Cache size
•Disk and/or storage controller performance
It is given that storage systems never seem to be static. The dynamic nature of the applications, users, and implementations forces varying changes in storage architectures, capacities, performance, addressability, and redundancy. When expanding these storage systems, administrators must address both functional and logical constraints. A portion of these issues may include items such as the number of file systems supported, the number of snapshots or replications of the data sets, and others, which are outlined in this book.
Solution sets may be predefined with real and/or artificial boundaries that force the users into decisions that can involve upgrades to a larger storage system and/or the necessity for an increased storage management tool set as the storage system limits are approached.
For the traditional storage systems deployed throughout the enterprise, there have been typically three principle storage architectures, which are as follows:
•Direct-attached storage (DAS)
•Storage area networks (SANs)
•Network-attached storage (NAS)
These architectures are described in detail in various chapters of this book.
Clustered storage is the fourth principle of storage architecture. Clustering enables the pulling together of two or more storage systems, which then behave as a single entity.
Capabilities and Types of Clustering
The capabilities of clustered storage vary in terms of their ability to scale capacity, performance, and accessibility at the block or file level, including availability and ease of use. Clustered storage is categorized in types, each with different characteristics or “architectures”:
•Two-way simple failover
•Namespace aggregation
•Clustered storage with a distributed file system (DFS)
Two-Way Simple Failover
Protected storage systems have traditionally employed both a primary and a redundant node-based architecture. In this model, each node, defined as a combination of server or controller head and a hard disk drive or disk drive array, can be configured to stand on its own. This protected node concept, when design is appropriated, provides for more than just a means to mitigate the risks of having all your (storage) eggs in one basket. Adding multiple nodes can provide for increased bandwidth (throughput), but this configuration was not typically managed for this purpose.
When configured to operate in only a simple protection mode, if one of the nodes failed, the system entered into a process called “failing over” whereby the redundant node would take over the entire responsibilities of storage system until the failed node could be repaired. This simple failover concept should not be defined as a true clustering technique but more properly described as a redundancy technique.
The NAS community would refer to this as “two-way clustering,” which evolved out of the need to improve both fault tolerance and redundancy for those legacy or traditional single-head storage architectures (see Fig. 14.1). This mode enables one controller head to assume the identity of the failing controller head, allowing the failed controller’s data volumes to continue to be accessed or written to by the new controller head. The main limiting factor of this approach was its inherent limited performance and scalability. This model worked best on small file system sizes, but it increased management complexity and had a relative high cost to achieve the high availability of the file data.
As the growth of unstructured data exploded, it became evident that this type of solution would not meet the future needs of the enterprise.

Figure 14.1 Two-way failover protected by clustering.
Namespace Aggregation
This form of clustered storage solution essentially presents a single pane of glass, a veneer that pulls the elements of storage management together. Such solutions can be purely software-based (i.e., software virtualization) or can be a combination of software and hardware (i.e., appliance and switch). It creates a single namespace and cluster of storage resources that appear as one large pool of data management (see Fig. 14.2). Typically, these solutions enable “synthetic trees” that encompass a cluster of NAS servers or storage devices, present the silos to a network user as one (unified) namespace, and store the data on any given silo. In other words, they create gateways through which data from several different files and heterogeneous systems is redirected to be accessed from a common point.
Solutions in this class control laying out a file (i.e., striping data) across disk volumes to a specific silo—but not across the silos that make up the cluster—and they still allow data movement between tiers of storage with limited client interruption. Although this approach can be attractive on the surface from an initial cost standpoint, the IT administrator is still managing, growing, and configuring these islands of storage (i.e., heterogeneous silos of storage), but now with an additional virtualization layer. This approach creates more complexity, higher management burden, and greater long-term operational costs.
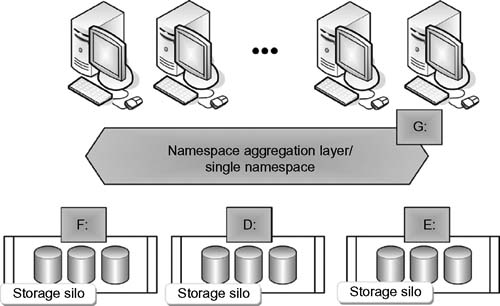
Figure 14.2 Namespace aggregation as a type of clustered
Clustered Storage with a Distributed File System
Evolution extended the two previously described types of clustering, “two-way simple clustering” and “namespace aggregation,” into distributed clustered storage as a network storage system that allows users to combine and add storage nodes, which all access the same data pool. This solution resides on the storage layer and utilizes one or more distributed file systems that span across any number of nodes or storage controllers.
Generally, a software system resides at the storage layer, providing the ability to completely control the layout of data (through “data striping”) across all the storage nodes that make up the cluster. Access goes all the way down to the error correction and concealment (ECC) level at every element of the data pool. This is in contrast to namespace aggregation (such as in virtualization products) that only directs the specific storage silo to which data is written.
This system has the intelligence to make the nodes both symmetric and distributed. The cluster in turn works as an intelligent and unified system, allowing each node the capability of running on its own and communicating with the other nodes to deliver files in response to the needs of the hosts and users. In this way, each node knows everything about the other nodes. Thus, each node in the cluster is a “coherent peer” to the other.

Distributed clustered storage in turn provides the highest levels of availability, scalability, aggregate throughput, reliability, and ease of management when compared to the solutions of “two-way failover” and “namespace aggregation” described (see Table 14.1).
Cluster Scaling Characteristics
As mentioned, clustering allows systems to scale more easily. The complicated or cumbersome issues related to increasing performance, availability, and accessibility can now be more easily and effectively improved as the storage capacity requirements increase and unstructured storage architectures expand. These improvements include the following:
•Performance—optimization and increases in bandwidth, IOPs, or a combination of both are tuned for large, sequential read or write operations such as those found in moving media applications or time-sensitive, random reads and writes such as those in transaction-oriented operations.
•Availability—including the elimination of single points of failure, the capability to implement transparent failover, and the ability to achieve self-healing processes.
•Capacity and connectivity—the implementation of Fibre Channel, Ethernet, or InfiniBand ports that can support significantly larger storage capacities, increased server access, and extended connectivity.
•Accessibility—enabling block access like that used in iSCSI, Fibre Channel, or InfiniBand; or for network-attached storage (NAS) file systems such as NFS, CIFS, or proprietary; or for data sharing.
•Recoverability—the ability for the system to return to normal operations after some level of failure.
•Sharing—including shared-nothing, shared-something, or shared-everything architectures; may be based upon open or proprietary hardware and software using tightly or loosely coupled interconnects.
Shared Structures
The sharing of data (as information) among machines, users, and environments is a key element that allows effective collaboration, distribution, and aggregation of content; whether that content is multimedia, moving images, linked metadata, or transactional databases. Much has been written about the various methodologies that surround sharing. Sharing can mean shared storage, shared projects, and/or shared resources. Regardless of whether the architecture is clustered, the structures of these sharing architectures become the secret sauce of the systems in which they are deployed.
Sharing structures include (but are not necessarily limited to) the following:
•Shared-nothing (SN) clusters
•Shared-disk clusters
•Mirrored-disk clusters
•Shared something
•Shared-partial model
•Shared everything (SE)
Each of these has different, sometimes overlapping, meanings. Some of the terms were created for marketing or coined to convey a slightly different perspective on a quite similar alternative. Where possible, these systems will be described in the context of what the industry has accepted the terms to mean.
Shared-Nothing Clusters
A shared-nothing architecture (SN) was initially employed in a distributed computing architecture, characterized by each node being independent and self-sufficient. Michale Stonebraker (UC Berkeley) identified shared nothing in the context, “neither memory nor peripheral storage is shared among processors,” in his paper (1986) that describes the three dominant themes in building high transaction rate multiprocessor systems. A shared-nothing cluster is sometimes referred to as a “federated system.”
In distributed data storage, such as in a clustered environment, shared nothing means there is no single point of contention across any portion of the system. Data in a SN-computing system is partitioned in some manner and then spreads across a set of machines with each machine having sole access, and hence sole responsibility, for the data it holds.
The industry contrasts shared nothing with systems that maintain a large amount of centrally-stored state information, whether in a database, an application server, or any other similar single point of contention.
The value of shared nothing is in its scalability, making SN popular for Web development. Google has demonstrated that a pure SN system can scale almost infinitely simply by adding nodes in the form of inexpensive computers, and hence calls this “sharding.”
Shared-nothing architectures are prevalent in data warehousing, despite the debate as to whether a shared-nothing approach is superior to a shared-disk application. Shared nothing does not involve concurrent disk accesses from multiple nodes; that is, the clusters do not require a distributed lock manager (explained shortly). Shared-nothing cluster solutions are found in Microsoft Cluster Server (MSCS), a suite of software applications that allow servers to work together as a computer cluster, providing failover, network, and component load balancing; and increased availability of applications or parallel computational power as in the case of supercomputing or high-performance computing (HPC) clusters.
Shared-Disk Clusters
A shared-disk (SD) architecture is a comparable architecture popular in clustered data systems, where the disk itself is accessible from all cluster nodes. In shared disk, any node can access any data element, and any single data element has no dedicated owner.
Shared-disk clusters rely on a common I/O bus for disk access; however, they do not require shared memory. In SD, all nodes may concurrently write to or cache data from the central disks by way of a synchronization mechanism that is used to preserve coherence of data within the system. Cluster software, called the “distributed lock manager,” takes on the role of managing this synchronization.
An SD cluster will support much higher levels of system availability; that is, if one node fails, the other nodes should not be affected. Nonetheless, high availability comes at the cost of a modest amount of reduced performance that occurs due to the overhead of using the distributed lock manager, as well as the potential bottlenecks that occur whenever hardware is shared. The SD cluster makes up for this with relatively good scaling properties, such as those cluster technologies employed in Oracle Parallel Server (OPS), a version of the Oracle database system designed for massively parallel processors (MPPs) that allows multiple CPUs to access a single database, or in IBM High Availability Cluster Multiprocessing (HACMP).
The shared file system is available with shared-disk clustering. Multiple systems are also attached to the same disk. All nodes in the cluster must then have access to the shared disk, but only one node has ownership of the disk; that is, there is only one database instance. In this application, if one node fails, the other takes over.
Mirrored-Disk Clusters
Mirroring is the replication of all application data from the primary storage components to a secondary or backup storage system. Often, the backup system resides at a remote location or for availability purposes may be immediately adjacent to the primary system. The replication function generally occurs while the primary system is active. A mirrored backup system, as in a software mirroring application, may not typically perform any work outside of its role as a passive standby.
Should a failure occur in the primary storage system, the failover process transfers control to the secondary (backup) system. Depending upon the scale of failure, this process can take some time. During this critical period, applications may lose some state information when they are reset; however, mirroring does enable a reasonably fast recovery scheme, requiring little administrative or human intervention.
Mirrored-disk clusters will typically include only two nodes. The configurations will usually self-monitor those applications, networks, servers, and storage components on the system.
These combined processes automate application restarts on an alternate (local or remote) server should there be a planned or unplanned service outage. Additional functionality includes the failback of services, applications, and data in a rapid and efficient method to ensure business continuity with a minimal amount of interruption.
Shared-Something Clusters
Worth mentioning, but rather vague in meaning and rarely publicized, the Oracle Real Application Cluster (RAC) database might be defined as a shared-something (SS) cluster. Oracle RAC uses multiple computers to run the Oracle Relational Database Management System (RDBMS). In their configuration, there is shared data access plus some application-level memory sharing. This definition gets fuzzy once you get into RDMAbased architectures like those found in InfiniBand, where nodes are actually granting direct memory access to other nodes within a cluster.
With all these shared architecture terminologies, it is not a surprise to find a “shared kind-of-something-but-not-really” (SKS-BNR) concept because it had not been thought of quite yet.
Shared-Partial Model
These instances of data and storage sets share some resources and cooperate in a limited way. In this configuration, a portion of the system memory is designated as shared memory in which each instance can then be accessed. Both the code and the data for each instance are stored in private memory. Data that is shared by applications in several instances is stored in the shared memory.
In this shared-partial model the instances are not clustered.
Shared-Everything Clusters
Commercially available in some databases, the idea of a sharedeverything (SE) cluster is that it behaves like a single big box built from multiple smaller boxes.
To give an abbreviated perspective of an application, a systems complex or “Sysplex” is a single logical system that runs on one or more physical systems. This design drives the requirements of a shared-everything storage concept. In IBM mainframes, Sysplex joins multiple processors into a single unit, sharing the same logical devices often isolated within a single system. Parallel Sysplex technology allows multiple mainframes to perform as one.
In the shared-everything cluster, parts of applications may be spread among different cluster nodes in order to take advantage of additional CPUs, memory, and I/O when available on other nodes. In terms of workload processing, multiple instances of applications in a hierarchy of dependent resources per cluster running will handle each of the particular duties and resources that come from the hierarchy of dependent resources, but would be running on different nodes.
Although shared nothing (SN) is considered to be the most scalable, it is sensitive to the problems of data skew, which is the difference in the arrival time of a data set at two different registers. Conversely, SE allows the collaborating processors to share the workload more efficiently; however, SE suffers from the limitation of memory and disk I/O bandwidth. A potentially better approach would be a hybrid architecture in which SE clusters are interconnected through a communication network to form a SN structure at the inter-cluster level. In such a hybrid approach, the processing elements are clustered into SE systems to minimize any skew effect. Each cluster would be kept small within the limitation of the memory and I/O technology in order to avoid the data access bottleneck.
Managing Storage Clusters for Scalability
The management of the cluster itself is yet another element in the overall storage clustering system. Tool sets can provide for management of the many elements of the cluster components, but they may not necessarily manage the scalability or performance of the cluster.
The goal of cluster management is to simplify the management of the overall system, which is certainly useful. However, usually these tools would not provide the linear scalable performance of a true cluster.
Approaches to scaling a cluster include the combining of two controller nodes that are actually an active—active cluster and then connecting this controller node pair to other pairs. There is no aggregation of performance with the other pairs.
In managing scalability, one should look at complete node protection for high availability, which aims at eliminating all single points of failure, including the failure of an entire distributed controller node. The RAID architecture should be distributed RAID, which allows for capacity efficiency. A clustered storage system that uses distributed RAID protects the distributed controller nodes and can provide up to double the usable capacity of a clustered system that only copies (or mirrors) data between nodes.
To obtain a maximized bandwidth to performance ratio, clustered systems should eliminate a master controller and aggregate the network ports to provide the highest bandwidth. For media installations, this allows for the support of more workstations without necessarily requiring expensive proprietary Fibre Channel or even 10 Gbit Ethernet.
Deployment
Prior to the deployment of a clustered solution, engineers should look for potential SPOFs, as well as additional design features including N + 1 redundancy, and systems incorporating hot- swappable component design with self-healing capabilities that can identify, isolate, and contain faults before they can turn into problems. Although there is plenty of opportunity to prevent failures because of the multiplicity of the systems in a cluster, there are always points in a system that, if they should fault, may bring down a system completely.
Tight or Loose
Tightly coupled clustered storage divides the data between nodes in the cluster at a level of granularity smaller than a file and typically at the block or subblock level. In a typical dual-controller architecture, performance will peak at around 50% of drive capacity, after which it actually declines. In tightly coupled clusters, users should see an improvement in performance as drives and nodes are added to the environment.
Tightly coupled storage clusters tend to be focused on primary storage. You may find archives and some disk-to-disk backup systems that may employ tightly coupled storage. The downside to tight coupling is that the components of the cluster are stricter, seldom will use heterogeneous subsystems, will most always come from a single supplier, and are weaker on flexibility.
Loosely coupled clusters are essentially dual-controller standalone systems that use a global namespace to reduce management requirements over the entire environment. Although this achieves greater flexibility in the members of the cluster and the cluster can start with just one member, the entirety of the file must be on a single node. This is the opposite of a tightly coupled cluster where the data is stored across nodes in the cluster.
However, the data can be mirrored to other nodes for redundancy, with some software solutions providing the capability to use the secondary copy as a backup, automatically. The downside of loosely coupled clusters comes from the fact that the node housing the data limits the maximum performance and capacity of the cluster. Performance will not scale-up as nodes are added, a feature reserved for a tightly coupled cluster environment. Therefore, loosely coupled clusters tend to be deployed where performance is still important, but the costs for increasing the storage capacity have more impact.
Tightly coupled and loosely coupled clustered storage can both address the issues of expandability, capacity and performance scale, and I/O. Caution is urged because the differences between the two can be camouflaged by driving up the performance side of the dual controller and then driving down the impacts of storage costs.
Support and Growth
If selecting a solution from a storage vendor, look to how they intend to support and manage the growth over the next 5 years. Understand what the costs, service requirements, and extensibility of the solution will be over both the financial lifetime and the practical lifetime of the solution. Look for barriers to expansion. And then, before making the choice, check if there is still another alternative, such as grid storage, that might be an equally good or a potentially better implementation.
Grid Computing
Grids are usually computer clusters that are focused more on throughput like a computing utility, rather than running fewer, tightly coupled jobs. Often, grids will incorporate heterogeneous collections of computers. The sets may be distributed geographically, and they may be administered by unrelated organizations.
Grid computing is optimized for workloads that consist of multiple independent jobs. These jobs are sometimes referred to as “packets of work” or just packets. Packets do not need to share data between the other independent jobs during the computation process. Grids are not essentially an entity, but they are designed to serve and manage the allocation of other jobs to computers that will perform the work independently of the rest of the grid cluster.
Resources such as storage may be shared by all the nodes on the grid. Intermediate results of one job do not affect other jobs in progress on other nodes of the grid. Grid computing is excellent for handling applications that have large bandwidth requirements.
Grids and clusters are frequently lumped together into the same category, but there are differences in the two architectures.
Grids and Nodes
A grid is an approach to storing data that employs multiple self-contained storage nodes that are interconnected such that any node is able to communicate with any other node through means that do not require the data to pass through a centralized switch.
Storage nodes each contain their own storage medium, a microprocessor, a management layer, and a means to index the storage. In more typical applications, multiple nodes may share a common switch; however, each node must also be connected to at least one other node in the cluster. Grid topologies are found to have many layouts, including the interconnection of nodes in an n-dimensional hypercube configuration, similar to how nodes are interconnected in a mesh network.
Grid storage provides advantages over older storage methods. Grid storage also introduces another level of redundancy and fault tolerance. Should one storage node fail, or the pathway between nodes be interrupted, the grid can automatically reroute access to a secondary path or to a redundant node. The obvious impact is that online maintenance is reduced and downtime is alleviated, potentially all together. Furthermore, using multiple paths between each node pair ensures that the storage grid will maintain optimum performance even under conditions of fluctuating or unbalanced loads.
Grid storage is easily scalable and reduces the need for expensive hardware upgrades that require significant downtime. When a new storage node is added, software will automatically recognize it and configure it so that it integrates with the rest of the grid as a normal, essentially background task.
Grid or Cluster
So the question looms: “Is a cluster a grid?” The answer depends in part on what the user (or the vendor) sees in the definition of a grid. One might consider a grid to be a service or an architecture, which could be both hardware and/or software based. The solution may be spanning distance, or it could be providing some other set of capabilities. As a consequence of the variety of applications or definitions, there exist many different vendor, industry, and technological definitions and opinions as to what constitutes either a grid or a cluster for the server or the storage environments where they will play a role.
Often missing in the “what constitutes a grid” discussion is what few exploit as an essential component. This element is one that on the surface seems straightforward, but in context is just as hard to define. Supervisory control and data acquisition (SCADA) is the term applied to the command and control functionality of a system. The concept is applicable to all forms of industry. A facility that has a lights-out work environment still requires some form of SCADA. A computer system and a storage system both need this kind of management to provide efficiency and predictability as the system is used in normal and abnormal workflows.
To add just one more tangent to the discussion, another variable in the grid versus cluster determination is what kind of SCADA functionality is available for “transparent” command and control of a storage system. By this, we mean self-monitoring, self—healing, and self-reporting subsystems that intelligently perform multiple threads of background tasks that help to optimize the systems for bandwidth, resiliency, and other provisions. The further chapters on storage networking, high performance, and shared storage cover several elements of what can be—and often is—provided for in a clustered storage environment.
Mitigating SPOF
Eliminating single points of failure (SPOF) is central to enhancing data availability, accessibility, and reliability. When looking at cluster solutions, candidates should be evaluated for potential areas where if one component failed it would bring the entire system down. Features that include N + 1 redundancy, multiple pathing, and hot-swappable component design with self-healing capabilities are aids to identifying, isolating, and containing faults before they can turn into problems.
N + 1 Architecture
Another class of storage solution that is present in the grey area as to whether it is a cluster is the proverbial “N + 1 architecture.” This class of storage is intended to provide the faithful level of redundancy that most seem to feel they require. An N + 1 model uses two or more (N) primary I/O nodes or controllers, generally configured as NAS heads. A secondary onstandby or failover node, in either an active or inactive mode, provides the “+ 1” component.
What can make an N + 1 model most confusing is how the vendor views the architecture for the components they supply. Some find that by positioning dual-controller RAID arrays or dual NAS head solutions as clusters for availability, they have achieved this “N + 1” redundancy.
Differentiators
Items that separate one form of clustered storage solution from another include the following:
•How nodes of the cluster are interconnected: loosely or tightly coupled, open, or proprietary
•Input/output affinity
•Performance load balancing across nodes
•Hardware choices—open propriety, commercial off-the-shelf (COTS), or heterogeneous (different sets of third-party components) versus homogeneous (provided by a single source/ vendor) servers and storage
•File sharing capabilities and methods—clustered file system software, host-based agents, or drivers
•Duplication, replication, and mirroring: local and/or remote mirroring, degrees or levels of replication, point-in-time (PIT) copy, and snapshotting
•Growth of the storage—modular storage with virtualization, automated load balancing, chassis/array or crate additions, and knowing the limitations of each form or level of expansion
•Performance tuning—capabilities for adjusting sequential read and write parameters and random updates
•Security and protection—concepts of distributed lock management and cluster coherency
Clustered storage can be a good fit for diverse environments of all sizes. When the need to grow demands that the user enable a “just-in-time storage acquisition” mentality, they do not need the complexity of disruptive upgrades or added management complexities. Clustered storage can provide those solutions.
Single Logical Storage System
A cluster will provide a single logical storage system regardless of the number of nodes in the system. This means that any application can access any element of data stored on it through any storage controller in the cluster. A cluster thus provides for the aggregation of all the hardware resources as a single system.
A clustered storage system will greatly improve performance while providing a single level of management when additional storage controllers are added to the cluster, regardless of how big the cluster might become. An inherent property of the cluster is that when a new node is added, the data is then automatically redistributed to that new node. This process is referred to as “load balancing”, a function which is then applied across the entire cluster.
Input/Output Operations Per Second (IOPS)
IOPS is a common benchmark for hard disk drives and computer storage media. A numerical benchmark is often published by SAN and drive manufacturers. These numbers can be misleading and may not actually guarantee a real-world performance metric.
Performance benchmarks for clustered storage systems are metrics that have relevance to the overall system. Metrics, such as random IOPS numbers, are primarily dependent upon the storage device’s random seek time. Sequential IOPS numbers, especially when considered for large block sizes, typically indicate the maximum bandwidth that a storage device can handle. You may find that sequential IOPS numbers are often replaced by a simpler specification that describes bandwidth in terms of a Mbytes/second metric.
Third-party software vendors can supply tool sets that are used to measure IOPS. Some of the recognized applications include Iometer (originally developed by Intel), IOzone, and FIO. These tools are used primarily with servers in support of finding the best storage configuration for the given server applications.
The achievable IOPS numbers for a given server configuration may vary greatly depending upon the variables utilized when the analyst enters those numbers into the applications. Such values may include the balance of read and write operations, the mix of random or sequential access patterns, the number of worker threads and queue depth, and the data block sizes.
In large systems, the tools available for monitoring performance metrics are particularly useful in tuning the systems for applications that change during workflows. For example, toward the end of a production, when editorial elements are combined with special effects, a significant amount of computer- intensive rendering will be necessary. These are usually pure number-crunching activities, which have little interaction with users, and can occur during “lights-out” operations. If the storage system had been tuned mostly for collaborative editing and the interaction with humans making choices with less intense activity, the system may not perform well for rendering if it remains in that configuration.
Tool sets that watch IOPS also monitor trends that occur during normal activities. The watchdog monitors network traffic, access and response times, and general bandwidth utilization. The tools may also probe the storage system resources and track the individual drive or RAID controller performance and carry that data into their own tracking systems. Benchmarking the system performance allows you see if that level of performance is degraded because of a particular drive that has too many readrepeats or write errors. Storage technicians can find and replace those degraded elements so as to improve performance and to head off an unexpected failure before it occurs.
Provisioning
Storage systems of today usually support some degree of clustering solution. Leading suppliers will support dual-controller node configurations with active—active or active—passive architectures. Storage systems that support N-way active architectures will scale far beyond dual-controller/dual-node systems. Theoretically, there is no real limit to how far a storage system can scale. Some systems have 80 or more controller nodes in just a single cluster.
In summary, storage clustering offers the following features and capabilities which, to some degree, are configurable and selectable on a varying set of levels:
•Single-level management—when adding more physical resources to a cluster, there is still only one logical system to manage. The cluster remains a single system regardless of its scale or geographic location.
•Just-in-time scalability—where nodes are added to achieve additional processing capacity, cache memory, and bandwidth as needed. It has the ability to add those resources when demand requires it, and it has the ability to avoid making those choices up front.
•Performance protection—the capability to add nodes levels the protection equation but also heightens performance. Storage systems that are only in a dual-node mode are at risk if one of the nodes fails. Failure of one node decreases performance and will slow it down by at least 50%. With a threenode controller cluster, the performance hit drops to 33%, with four nodes, it is 25%, and so on.
•Lower cost—for those already possessing a system, the addition of another controller node is significantly less costly than buying a completely new storage system. Some updates may be only for hardware, with software charges already covered.
•Easy to add on—additional node extensions to existing storage clusters is far less complicated than implementing and transitioning to a whole new storage system. Certainly, this depends on the particular product (or the vendor), but usually the addition of a new node to a storage cluster is an online and often transparent process to the user, which requires a minimum level of planning.
Summary
Grids and clusters have concepts that overlap and principles that are differentiating. Throughout this book, many of the storage concepts, approaches, and technologies are found in stand-alone configurations. Most of these technologies can become elements in a grid or cluster topology. Some of the media technology vendors, providing videoservers, storage systems, and content management solutions, provide elements of grid computing, grid storage, and clustering within their product lines.
These products and others are application-specific implementations; they may or may not actually utilize the grid or clustering storage technologies as described in this chapter. However, when you see vendors claim these implementations make up a heterogeneous storage solution, make sure that you understand all of the underlying implications of that solution, whether or not they use the terms “grid” or “cluster” outright.
Further Readings
An example of test results, which also depict configurations and benchmarks of various intelligent storage system providers, that covers the period from 2001 through 2008 can be found at:
http://www.spec.org/sfs97r1/results/sfs97r1.html.