
2. Lexical Conventions and Syntax
This chapter describes the syntactic and lexical conventions of a Python program. Topics include line structure, grouping of statements, reserved words, literals, operators, tokens, and source code encoding.
Line Structure and Indentation
Each statement in a program is terminated with a newline. Long statements can span multiple lines by using the line-continuation character (), as shown in the following example:
![]()
You don’t need the line-continuation character when the definition of a triple-quoted string, list, tuple, or dictionary spans multiple lines. More generally, any part of a program enclosed in parentheses (...), brackets [...], braces {...}, or triple quotes can span multiple lines without use of the line-continuation character because they clearly denote the start and end of a definition.
Indentation is used to denote different blocks of code, such as the bodies of functions, conditionals, loops, and classes. The amount of indentation used for the first statement of a block is arbitrary, but the indentation of the entire block must be consistent. Here’s an example:

If the body of a function, conditional, loop, or class is short and contains only a single statement, it can be placed on the same line, like this:
![]()
To denote an empty body or block, use the pass statement. Here’s an example:

Although tabs can be used for indentation, this practice is discouraged. The use of spaces is universally preferred (and encouraged) by the Python programming community. When tab characters are encountered, they’re converted into the number of spaces required to move to the next column that’s a multiple of 8 (for example, a tab appearing in column 11 inserts enough spaces to move to column 16). Running Python with the -t option prints warning messages when tabs and spaces are mixed inconsistently within the same program block. The -tt option turns these warning messages into TabError exceptions.
To place more than one statement on a line, separate the statements with a semicolon (;). A line containing a single statement can also be terminated by a semicolon, although this is unnecessary.
The # character denotes a comment that extends to the end of the line. A # appearing inside a quoted string doesn’t start a comment, however.
Finally, the interpreter ignores all blank lines except when running in interactive mode. In this case, a blank line signals the end of input when typing a statement that spans multiple lines.
Identifiers and Reserved Words
An identifier is a name used to identify variables, functions, classes, modules, and other objects. Identifiers can include letters, numbers, and the underscore character (_) but must always start with a nonnumeric character. Letters are currently confined to the characters A–Z and a–z in the ISO–Latin character set. Because identifiers are case-sensitive, FOO is different from foo. Special symbols such as $, %, and @ are not allowed in identifiers. In addition, words such as if, else, and for are reserved and cannot be used as identifier names. The following list shows all the reserved words:

Identifiers starting or ending with underscores often have special meanings. For example, identifiers starting with a single underscore such as _foo are not imported by the from module import * statement. Identifiers with leading and trailing double underscores such as _ _init_ _ are reserved for special methods, and identifiers with leading double underscores such as _ _bar are used to implement private class members, as described in Chapter 7, “Classes and Object-Oriented Programming.” General-purpose use of similar identifiers should be avoided.
Numeric Literals
There are four types of built-in numeric literals:
• Booleans
• Integers
• Complex numbers
The identifiers True and False are interpreted as Boolean values with the integer values of 1 and 0, respectively. A number such as 1234 is interpreted as a decimal integer. To specify an integer using octal, hexadecimal, or binary notation, precede the value with 0, 0x, or 0b, respectively (for example, 0644, 0x100fea8, or 0b11101010).
Integers in Python can have an arbitrary number of digits, so if you want to specify a really large integer, just write out all of the digits, as in 12345678901234567890. However, when inspecting values and looking at old Python code, you might see large numbers written with a trailing l (lowercase L) or L character, as in 12345678901234567890L. This trailing L is related to the fact that Python internally represents integers as either a fixed-precision machine integer or an arbitrary precision long integer type depending on the magnitude of the value. In older versions of Python, you could explicitly choose to use either type and would add the trailing L to explicitly indicate the long type. Today, this distinction is unnecessary and is actively discouraged. So, if you want a large integer value, just write it without the L.
Numbers such as 123.34 and 1.2334e+02 are interpreted as floating-point numbers. An integer or floating-point number with a trailing j or J, such as 12.34J, is an imaginary number. You can create complex numbers with real and imaginary parts by adding a real number and an imaginary number, as in 1.2 + 12.34J.
String Literals
String literals are used to specify a sequence of characters and are defined by enclosing text in single ('), double ("), or triple (''' or """) quotes. There is no semantic difference between quoting styles other than the requirement that you use the same type of quote to start and terminate a string. Single- and double-quoted strings must be defined on a single line, whereas triple-quoted strings can span multiple lines and include all of the enclosed formatting (that is, newlines, tabs, spaces, and so on). Adjacent strings (separated by white space, newline, or a line-continuation character) such as "hello" 'world' are concatenated to form a single string "helloworld".
Within string literals, the backslash () character is used to escape special characters such as newlines, the backslash itself, quotes, and nonprinting characters. Table 2.1 shows the accepted escape codes. Unrecognized escape sequences are left in the string unmodified and include the leading backslash.
Table 2.1 Standard Character Escape Codes

The escape codes OOO and x are used to embed characters into a string literal that can’t be easily typed (that is, control codes, nonprinting characters, symbols, international characters, and so on). For these escape codes, you have to specify an integer value corresponding to a character value. For example, if you wanted to write a string literal for the word “Jalapeño”, you might write it as "Jalapexf1o" where xf1 is the character code for ñ.
In Python 2 string literals correspond to 8-bit character or byte-oriented data. A serious limitation of these strings is that they do not fully support international character sets and Unicode. To address this limitation, Python 2 uses a separate string type for Unicode data. To write a Unicode string literal, you prefix the first quote with the letter “u”. For example:
s = u"Jalapeu00f1o"
In Python 3, this prefix character is unnecessary (and is actually a syntax error) as all strings are already Unicode. Python 2 will emulate this behavior if you run the interpreter with the -U option (in which case all string literals will be treated as Unicode and the u prefix can be omitted).
Regardless of which Python version you are using, the escape codes of u, U, and N in Table 2.1 are used to insert arbitrary characters into a Unicode literal. Every Unicode character has an assigned code point, which is typically denoted in Unicode charts as U+XXXX where XXXX is a sequence of four or more hexadecimal digits. (Note that this notation is not Python syntax but is often used by authors when describing Unicode characters.) For example, the character ñ has a code point of U+00F1. The u escape code is used to insert Unicode characters with code points in the range U+0000 to U+FFFF (for example, u00f1). The U escape code is used to insert characters in the range U+10000 and above (for example, U00012345). One subtle caution concerning the U escape code is that Unicode characters with code points above U+10000 usually get decomposed into a pair of characters known as a surrogate pair. This has to do with the internal representation of Unicode strings and is covered in more detail in Chapter 3, “Types and Objects.”
Unicode characters also have a descriptive name. If you know the name, you can use the N{character name} escape sequence. For example:
s = u"JalapeN{LATIN SMALL LETTER N WITH TILDE}o"
For an authoritative reference on code points and character names, consult http://www.unicode.org/charts.
Optionally, you can precede a string literal with an r or R, such as in r'd'. These strings are known as raw strings because all their backslash characters are left intact—that is, the string literally contains the enclosed text, including the backslashes. The main use of raw strings is to specify literals where the backslash character has some significance. Examples might include the specification of regular expression patterns with the re module or specifying a filename on a Windows machine (for example, r'c:
ewdata ests').
Raw strings cannot end in a single backslash, such as r"". Within raw strings, uXXXX escape sequences are still interpreted as Unicode characters, provided that the number of preceding characters is odd. For instance, ur"u1234" defines a raw Unicode string with the single character U+1234, whereas ur"\u1234" defines a seven-character string in which the first two characters are slashes and the remaining five characters are the literal "u1234". Also, in Python 2.2, the r must appear after the u in raw Unicode strings as shown. In Python 3.0, the u prefix is unnecessary.
String literals should not be defined using a sequence of raw bytes that correspond to a data encoding such as UTF-8 or UTF-16. For example, directly writing a raw UTF-8 encoded string such as 'Jalapexc3xb1o' simply produces a nine-character string U+004A, U+0061, U+006C, U+0061, U+0070, U+0065, U+00C3, U+00B1, U+006F, which is probably not what you intended. This is because in UTF-8, the multibyte sequence xc3xb1 is supposed to represent the single character U+00F1, not the two characters U+00C3 and U+00B1. To specify an encoded byte string as a literal, prefix the first quote with a "b" as in b"Jalapexc3xb1o". When defined, this literally creates a string of single bytes. From this representation, it is possible to create a normal string by decoding the value of the byte literal with its decode() method. More details about this are covered in Chapter 3 and Chapter 4, “Operators and Expressions.”
The use of byte literals is quite rare in most programs because this syntax did not appear until Python 2.6, and in that version there is no difference between a byte literal and a normal string. In Python 3, however, byte literals are mapped to a new bytes datatype that behaves differently than a normal string (see Appendix A, “Python 3”).
Containers
Values enclosed in square brackets [...], parentheses (...), and braces {...} denote a collection of objects contained in a list, tuple, and dictionary, respectively, as in the following example:
![]()
List, tuple, and dictionary literals can span multiple lines without using the line-continuation character (). In addition, a trailing comma is allowed on the last item. For example:
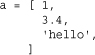
Operators, Delimiters, and Special Symbols
The following operators are recognized:
![]()
The following tokens serve as delimiters for expressions, lists, dictionaries, and various parts of a statement:
![]()
For example, the equal (=) character serves as a delimiter between the name and value of an assignment, whereas the comma (,) character is used to delimit arguments to a function, elements in lists and tuples, and so on. The period (.) is also used in floating-point numbers and in the ellipsis (...) used in extended slicing operations.
Finally, the following special symbols are also used:
![]()
The characters $ and ? have no meaning in Python and cannot appear in a program except inside a quoted string literal.
Documentation Strings
If the first statement of a module, class, or function definition is a string, that string becomes a documentation string for the associated object, as in the following example:

Code-browsing and documentation-generation tools sometimes use documentation strings. The strings are accessible in the _ _doc_ _ attribute of an object, as shown here:
![]()
The indentation of the documentation string must be consistent with all the other statements in a definition. In addition, a documentation string cannot be computed or assigned from a variable as an expression. The documentation string always has to be a string literal enclosed in quotes.
Decorators
Function, method, or class definitions may be preceded by a special symbol known as a decorator, the purpose of which is to modify the behavior of the definition that follows. Decorators are denoted with the @ symbol and must be placed on a separate line immediately before the corresponding function, method, or class. Here’s an example:

More than one decorator can be used, but each one must be on a separate line. Here’s an example:
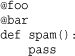
More information about decorators can be found in Chapter 6, “Functions and Functional Programming,” and Chapter 7, “Classes and Object-Oriented Programming.”
Source Code Encoding
Python source programs are normally written in standard 7-bit ASCII. However, users working in Unicode environments may find this awkward—especially if they must write a lot of string literals with international characters.
It is possible to write Python source code in a different encoding by including a special encoding comment in the first or second line of a Python program:

When the special coding: comment is supplied, string literals may be typed in directly using a Unicode-aware editor. However, other elements of Python, including identifier names and reserved words, should still be restricted to ASCII characters.