
![]()
One of the first things that developers learn about in their career is the benefits of code reuse. Encapsulating and reusing code into separate libraries speeds up the development and testing process and reduces the number of bugs in the system.
Unfortunately, the same approach does not always work well in the case of T-SQL. From a development and testing standpoint, code reuse definitely helps. However, from a performance standpoint, it could introduce unnecessary overhead when implemented incorrectly. One such example is a “one size fits all” approach where developers create a single stored procedure or function and then use it to support different use-cases. For example, consider a system with two tables—Orders and Clients—as shown in Listing 10-1.
Listing 10-1. Code reuse: Tables creation
create table dbo.Clients
(
ClientId int not null,
ClientName varchar(32),
constraint PK_Clients
primary key clustered(ClientId)
);
create table dbo.Orders
(
OrderId int not null identity(1,1),
Clientid int not null,
OrderDate datetime not null,
OrderNumber varchar(32) not null,
Amount smallmoney not null,
IsActive bit not null,
constraint PK_Orders
primary key clustered(OrderId)
);
create index IDX_Orders_OrderNumber
on dbo.Orders(OrderNumber)
include(IsActive, Amount)
where IsActive = 1;
Let’s assume that the system has the data access tier implemented based on stored procedures, and one of these procedures provides information about all of the active orders in the system. The stored procedure code is shown in Listing 10-2.
Listing 10-2. Code reuse: Stored procedure that returns the list of the active orders in the system
create proc dbo.usp_Orders_GetActiveOrders
as
select o.OrderId, o.ClientId, c.ClientName, o.OrderDate, o.OrderNumber, o.Amount
from dbo.Orders o join dbo.Clients c on
o.Clientid = c.ClientId
where IsActive = 1
A client application can call this stored procedure whenever an order list is needed. For example, it can have a page that displays the list with all order attributes as well as a drop-down control that shows only order numbers and amounts. In both cases, the same stored procedure can be used—applications just need to ignore any unnecessary columns in the output while populating the drop-down list.
While this approach helps us reuse the code, it also reuses the execution plan. When we run the stored procedure, we will get the plan, as shown in Figure 10-1.
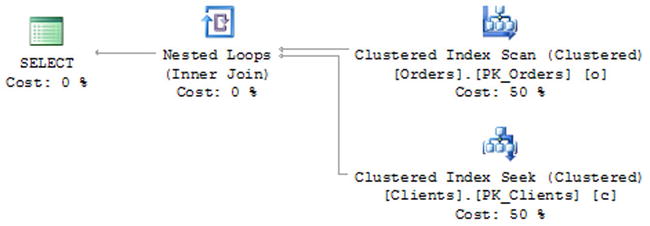
Figure 10-1. Execution plan of dbo.usp_Orders_GetActiveOrders stored procedure
This execution plan would be used in both cases. Nevertheless, the drop-down control does not need all of the order attributes, and it can get the required information with the query shown in Listing 10-3.
Listing 10-3. Code reuse: Select that returns the information required for drop-down control
select OrderId, OrderNumber, Amount
from dbo.Orders
where IsActive = 1
Such a query would have a much more efficient execution plan without the join operator, as shown in Figure 10-2.

Figure 10-2. Execution plan of the query that returns the order numbers and amounts for the drop-down control
As you see, by reusing the same stored procedure, we introduced a suboptimal execution plan with an unnecessary join and clustered index scan versus a filtered non-clustered index scan for one of our use-cases. We could also have very similar problems with user-defined functions.
There are three types of user-defined functions available in SQL Server: scalar, multi-statement table-valued, and inline table-valued. However, I would rather use a different classification based on their execution behavior and impact; that is, multi-statement and inline functions.
The code in a multi-statement function starts with a BEGIN and ends with an END keyword. It does not matter how many statements they have, that is, functions with the single RETURN statement are considered a multi-statement as long as the BEGIN and END keywords are present.
There are two different types of the multi-statement functions. The first is the scalar function, which returns a single scalar value. The second type is the table-valued function, which builds and returns a table resultset that can be used anywhere in the statement.
Unfortunately, multi-statement function calls are expensive and introduce significant CPU overhead. Let’s populate the Orders table that we defined above with 100,000 rows and create a scalar function that truncates the time part of OrderDate column. The function code is shown in Listing 10-4.
Listing 10-4. Multi-statement functions overhead: Scalar function creation
create function dbo.udfDateOnly(@Value datetime)
returns datetime
with schemabinding
as
begin
return (convert(datetime,convert(varchar(10),@Value,121)))
end
This function accepts the datetime parameter and converts it to a varchar in a way that truncates the time part of the value. As a final step, it converts that varchar back to datetime, and it returns that value to the caller. This implementation is terribly inefficient. It introduces the overhead of the function call and type conversions. Although we often see it in various production systems.
Now let’s run the statement shown in Listing 10-5. This query counts the number of orders with OrderDate as of March 1, 2013.
Listing 10-5. Multi-statement functions overhead: Select that uses scalar function
set statistics time on
select count(*)
from dbo.Orders
where dbo.udfDateOnly(OrderDate) = '2013-03-01'
The execution time on my computer is:
SQL Server Execution Times:
CPU time = 468 ms, elapsed time = 509 ms
For the next step, let’s try to perform type conversion without the function, as shown in Listing 10-6.
Listing 10-6. Multi-statement functions overhead:Select without scalar function
select count(*)
from dbo.Orders
where convert(datetime,convert(varchar(10),OrderDate,121))) = '2013-03-01'
The execution time for this query is:
SQL Server Execution Times:
CPU time = 75 ms, elapsed time = 82 ms.
You see that the statement runs almost five times faster without any multi-statement call overhead involved, although there is the better way to write this query. You can check if OrderDate is within the date interval, as shown in Listing 10-7.
Listing 10-7. Multi-statement functions overhead: Select without type conversion
select count(*)
from dbo.Orders
where OrderDate > = '2013-03-01' and OrderDate < '2013-03-02'
This approach cuts execution time to:
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 5 ms.
As you see, user-defined multi-statement function and type conversion operations, which can be considered as system functions, introduce huge overhead, and significantly increase query execution time. However, you would hardly notice it in the execution plans. Figure 10-3 shows the execution plan for the queries that use user-defined functions (Listing 10-5) and date interval (Listing 10-7).

Figure 10-3. Execution plans with and without a scalar user-defined function
A user-defined function adds the Filter operator to the execution plan.Although the costs for both, operator and query, are way off.
If you run SQL Server Profiler and capture SP:Starting event, you would see the screen shown in Figure 10-4.

Figure 10-4. SQL Trace with SP:Starting event
As you see, SQL Server calls the function 100,000 times—once for every row.
Another important factor is that multi-statement functions make the predicates non-SARGable. Let’s add the index on the OrderDate column and check the execution plans of the queries. The index creation statement is shown in Listing 10-8.
Listing 10-8. Multi-statement functions overhead: Index creation
create nonclustered index IDX_Orders_OrderDate on dbo.Orders(OrderDate)
As you see in Figure 10-5, both queries are now using a non-clustered index. However, the first query scans the entire index and calls the function for every row within it while the second query performs the Index Seek operation.
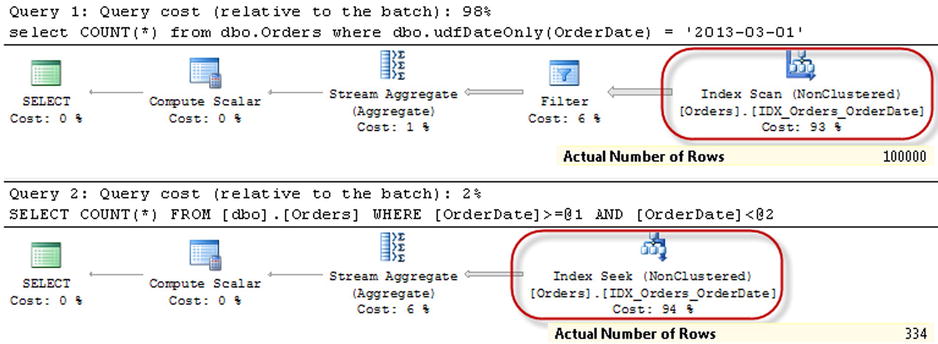
Figure 10-5. Execution plans of the queries with a non-clustered index on the OrderDate column
There are also some limitations on how the Query Optimizer works with multi-statement functions. First, it does not factor function execution overhead into the plan. As you already saw in Figure 10-4, there is an additional Filter operator in the execution plan, although SQL Server expects that this operator to have a very low cost, which is not even close to the real overhead it introduces. Moreover, SQL Server does not factor the cost of the operators from within the function into the execution plan cost of the calling query.
To illustrate this behavior, let’s create a function that returns the number of orders for a specific client based on the ClientId provided as the parameter. This function is shown in Listing 10-9.
Listing 10-9. Multi-statement function costs and estimates: Function creation
create function dbo.ClientOrderCount(@ClientId int)
returns int
with schemabinding
as
begin
return
(
select count(*)
from dbo.Orders
where ClientId = @ClientId
)
end
Now, let’s look at the estimated execution plan for the function call, as shown in Listing 10-10 and in Figure 10-6.
Listing 10-10. Multi-statement functions cost and estimates: Function call
select dbo.ClientOrderCount(1)

Figure 10-6. Estimated execution plan for the multi-statement function
As you see, SQL Server displays the execution plans for two queries. There are no indexes on the ClientId column and the function needs to perform a clustered index scan on Orders table even though the Query Optimizer does not factor the estimated cost of the function into the outer query cost.
Another limitation is that Query Optimizer always estimates that a multi-statement table-valued function returns just a single row, regardless of the statistics available. To demonstrate this, let’s create a nonclustered index on the ClientId column, as shown in Listing 10-11.
Listing 10-11. Multi-statement function costs and estimates: IDX_Orders_ClientId index creation
create nonclustered index IDX_Orders_ClientId on dbo.Orders(ClientId)
In this demo, we have 100 clients in the system with 1000 orders per client. As you remember, a statistics histogram retains 200 steps, so you would have the information for every ClientId. You can see this in Listing 10-12 and Figure 10-7.
Listing 10-12. Multi-statement function costs and estimates: IDX_Orders_ClientId index statistics
dbcc show_statistics('dbo.Orders','IDX_Orders_ClientId')
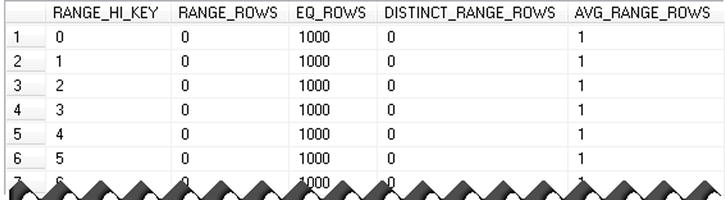
Figure 10-7. Index IDX_Orders_ClientId histogram
Now let’s create a multi-statement table-valued function that returns the order information for a specific client and call it in the single client scope. The code for accomplishing this is shown in Listing 10-13.
Listing 10-13. Multi-statement function costs and estimates: Function that returns orders for the clientid provided
create function dbo.udfClientOrders(@ClientId int)
returns @Orders table
(
OrderId int not null,
OrderDate datetime not null,
OrderNumber varchar(32) not null,
Amount smallmoney not null
)
with schemabinding
as
begin
insert into @Orders(OrderId, OrderDate, OrderNumber, Amount)
select OrderId, OrderDate, OrderNumber, Amount
from dbo.Orders
where ClientId = @ClientId
return
end
go
select c.ClientName, o.OrderId, o.OrderDate, o.OrderNumber, o.Amount
from dbo.Clients c cross apply dbo.udfClientOrders(c.ClientId) o
where c.ClientId = 1
![]() Note The APPLY operator invokes a table-valued function for every row from the outer table. The table-valued function can accept values from the row as the parameters. SQL Server joins the row from the outer table with every row from the function output, similar to the two-table join. CROSS APPLY works in a similar manner to the inner join. Thus if function does not return any rows, the row from the outer table would be excluded from the output. OUTER APPLY works in a similar way to the outer join.
Note The APPLY operator invokes a table-valued function for every row from the outer table. The table-valued function can accept values from the row as the parameters. SQL Server joins the row from the outer table with every row from the function output, similar to the two-table join. CROSS APPLY works in a similar manner to the inner join. Thus if function does not return any rows, the row from the outer table would be excluded from the output. OUTER APPLY works in a similar way to the outer join.
Even though there is enough statistical information to estimate the number of orders correctly for the client with ClientId = 1, the estimated number of rows is incorrect. Figure 10-8 demonstrates this. This behavior can lead to a highly inefficient execution plan when functions return the large number of rows.
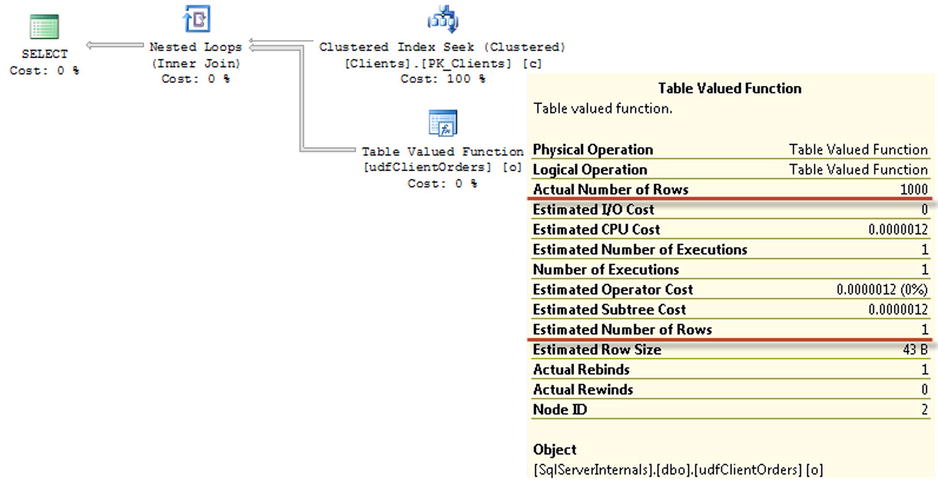
Figure 10-8. Execution plan of the query with the multi-statement table-valued function
As you probably noticed, all of the functions were created with the schemabinding option. While it is not required, specifying this option can help in several ways. It binds the function with the objects they reference, and it prevents any metadata changes that can potentially break the code. When the function does not access the data, schemabinding forces SQL Server to analyze the function body. SQL Server will know that function does not access any data, which in some cases helps to generate more efficient execution plans.
Inline table-valued functions work in completely different manner than multi-statement functions. Sometimes these functions are even named parameterized views. That definition makes a lot of sense. As opposed to multi-statement functions, which execute as separate code blocks, SQL Server expands and embeds inline table-valued functions into the actual queries, similar to regular views, and it optimizes their statements as part of the queries. As a result, there are no separate calls of the function and its associated overhead.
Let’s rewrite our multi-statement table-valued function to an inline table-valued function, as shown in Listing 10-14. Then examine the execution plan in Figure 10-9.
Listing 10-14. Inline table-valued functions: Function that returns orders for the clientid provided
create function dbo.udfClientOrdersInline(@ClientId int)
returns table
as
return
(
select OrderId, OrderDate, OrderNumber, Amount
from dbo.Orders
where ClientId = @ClientId
)
go
select c.ClientName, o.OrderId, o.OrderDate, o.OrderNumber, o.Amount
from dbo.Clients c cross apply dbo.udfClientOrdersInline(c.ClientId) o
where c.ClientId = 1
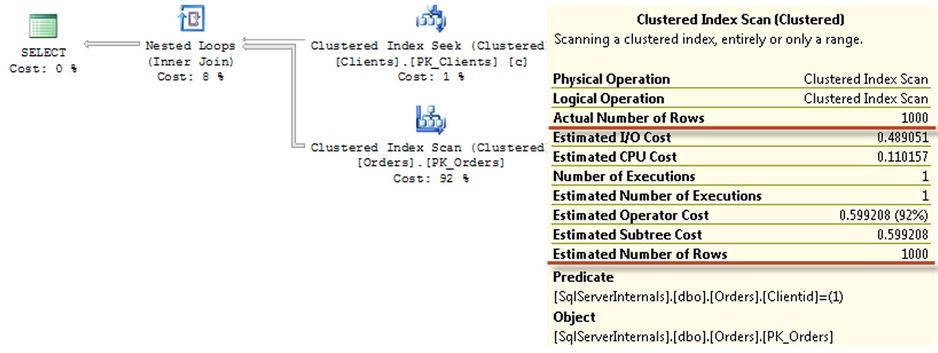
Figure 10-9. Execution plan of the query with an inline table-valued function
As you see, there is no reference to the function in the execution plan, and now the estimated number of rows is correct. In fact, you will get exactly the same execution plan if you do not use the inline table-valued function at all. Listing 10-15 and Figure 10-10 illustrate this point.
Listing 10-15. Inline table-valued functions: Select statement without inline table-valued function
select c.ClientName, o.OrderId, o.OrderDate, o.OrderNumber, o.Amount
from dbo.Clients c join dbo.Orders o on
c.ClientId = o.Clientid
where c.ClientId = 1
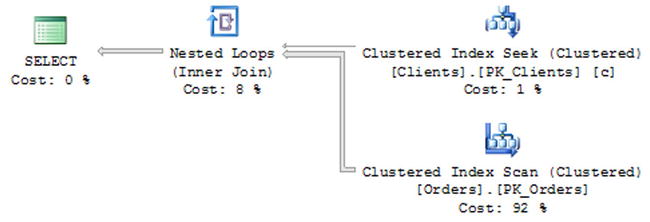
Figure 10-10. Execution plan of the query without the inline table-valued function
While inline table-valued functions can help us encapsulate and reuse code without unnecessary side effects, they cannot include more than one statement. Fortunately, in some cases, we can refactor the code and convert multi-statement functions into inline table-valued functions.
As a general rule, scalar functions can be replaced with inline table-valued functions that return a one-row table with the single column. As an example, take a look at the implementation of dbo.udfDateOnly function. You can convert it to inline table-valued function, as shown in Table 10-1.
Table 10-1. Converting multi-statement scalar to inline table-valued function
Multi-statement scalar function |
Inline table-valued function |
|---|---|
create function dbo.udfDateOnly(@Value datetime) |
create function dbo.udfDateOnlyInline(@Value datetime) |
select count(*) |
select count(*) |
If you run the SELECT with an inline table-valued function, the execution plan shown in Figure 10-11 would still use an Index Scan operator instead of an Index Seek. Even with an inline table-valued function, you cannot make our predicate SARGable due to the convert system function calls.

Figure 10-11. Execution plan of the query with inline table-valued function
If you compare the execution plan shown in Figure 10-11 with the plan that uses a multi-statement scalar function, as shown in Figure 10-5, you will observe that there is no Filter operator. SQL Server checks the predicate as part of the Index Scan operator. This behavior is the same with the query from Listing 10-6.
The execution time on my computer is:
SQL Server Execution Times:
CPU time = 78 ms, elapsed time = 84 ms.
While it is still far from being optimal due to the scan performed, these numbers are much better than what we had before.
Of course, it is much trickier when the function consists of the multiple statements. Fortunately, in some cases, we can be creative and refactor those functions to inline ones. An IF statement can often be replaced with a CASE operator,and Common Table Expressions can sometimes take care of procedural style code.
As an example let’s look at a multi-statement function that accepts geographic location as the input parameter and returns a table with information about nearby points of interest (POI). This table includes information about the first POI in alphabetical order by name as well as an optional XML column that contains the list of all POI IDs to which that location belongs. In the database, each POI is specified by a pair of min and max latitudes and longitudes. Listing 10-16 shows the implementation of the multi-statement table-valued function.
Listing 10-16. Converting multi-statement to inline functions: Multi-statement function implementation
create function dbo.GetPOIInfo(@Lat decimal(9,6), @Lon decimal(9,6), @ReturnList bit)
returns @Result table
(
POIID int not null,
POIName nvarchar(64) not null,
IDList xml null
)
as
begin
declare
@POIID int, @POIName nvarchar(64), @IDList xml
select top 1 @POIID = POIID, @POIName = Name
from dbo.POI
where @Lat between MinLat and MaxLat and @Lon between MinLon and MaxLon
order by Name
if @@rowcount > 0
begin
if @ReturnList = 1
select @IDList =
(
select POIID as [@POIID]
from dbo.POI
where
@Lat between MinLat and MaxLat and
@Lon between MinLon and MaxLon
for xml path('POI'), root('POIS')
)
insert into @Result(POIID, POIName, IDList) values(@POIID, @POIName, @IDList)
end
return
end
As you see, there are two separate queries against the table in the implementation. If you want to convert this function to an inline table-valued function, you can run the queries either as two CTEs or as subselects and cross-join their results. The If @ReturnList = 1 statement can be replaced with the CASE operator, as you can see in the implementation shown in Listing 10-17.
Listing 10-17. Converting multi-statement to inline functions: Inline function implementation
create function dbo.GetPOIInfoInline(@Lat decimal(9,6), @Lon decimal(9,6), @ReturnList bit)
returns table
as
return
(
with TopPOI(POIID, POIName)
as
(
select top 1 POIID, Name
from dbo.POI
where @Lat between MinLat and MaxLat and @Lon between MinLon and MaxLon
order by Name
)
,IDList(IDList)
as
(
select
case
when @ReturnList = 1
then
(
select POIID as [@POIID]
from dbo.POI
where
@Lat between MinLat and MaxLat and
@Lon between MinLon and MaxLon
for xml path('POI'), root('POIS'), type
)
else null
end
)
select TopPOI.POIID, TopPOI.POIName, IDList.IDList
from TopPOI cross join IDList
)
There is the very important difference between the two implementations, however. The multi-statement function will not run the second select that generates the XML when the first query does not return any rows. There is no reason for it to do that: location does not belong to any POI. Alternatively, inline implementation would always run the two queries. It could even degrade performance when the location does not belong to a POI, and the underlying query against the POI table is expensive. It would be better to split the function into two separate ones: GetPOINameInline and GetPOIIDListInline, and refactor the outer queries in the manner shown in Listing 10-18.
Listing 10-18. Converting multi-statement to inline functions: Refactoring of the outer query
from
dbo.Locations l
outer apply dbo.GetPOINameInline(l.Latitude, l.Longitude) pn
outer apply
(
select
case
when @ReturnList = 1 and pn.POIID is not null
then (
select IDList
from dbo.GetPOIIDListInline(l.latitude,l.longitude)
)
else null
end
) pids
A CASE statement in the second OUTER APPLY operator guarantees that the second function will be executed only when the dbo.GetPOINameInline function returns the data (pn.POIID is not null); that is, there is at least one POI for the location.
Summary
While encapsulation and code reuse are great processes that can simplify and reduce the cost of development, they are not always well suited for T-SQL code. Generalization of the implementation in order to support multiple use-cases within a single method can lead to suboptimal execution plans in some cases. This is especially true for the multi-statement functions, both scalar and table-valued. There is large overhead associated with their calls, which in turn introduces serious performance issues when functions are called for a large number of rows. Moreover, SQL Server does not expand them to the referenced queries, and it always estimates that table-valued functions return a single row.
Predicates that include multi-statement functions are always non-SARGable, regardless of the indexes defined on the table. This can lead to suboptimal execution plans of the queries and extra CPU load due to the function calls. You need to keep all of these factors in mind when creating multi-statement functions.
On the other hand, inline table-valued functions are expanded to the outer queries similar to regular views. They do not have the same overhead as multi-statement functions and are optimized as part of the queries. You should refactor multi-statement functions to inline table-valued functions whenever possible.