
![]()
Index fragmentation is, perhaps, one of those rare topics that does not entirely belong to the “it depends” category. Every database professional agrees that fragmentation negatively affects the system. While that is correct, it is still important to understand the downside of index fragmentation and analyze how your system is affected by it.
In this chapter, we will talk about internal and external index fragmentation in SQL Server, what code and design patterns increase the fragmentation, and what factors must be taken into account when designing an index maintenance strategy.
As you will remember, SQL Server stores data on data pages combined into eight-page extents. There are two kinds of extents: mixed extents and uniform ones. Mixed extents store data that belongs to different objects. Uniform extentsstore data that belongs to the same object.
When you create the object, the first eight data pages are stored in mixed extents. All subsequent space allocation is accomplished with uniform extents only. Every data page in clustered and nonclustered indexes has pointers to the previous and next pages based on index key sorting order.
SQL Server neither reads nor modifies data directly on the disk. A data page needs to be in the memory to be accessible. Every time SQL Server accesses the data page in memory, it issues a logical read operation. When the data is not in memory, SQL Server also performs a physical read, which indicates physical disk access.
![]() Note You can find the number of I/O operations performed by a query on a per-table basis by enabling I/O statistics using set statistics io on command. An excessive number of logical reads often indicates suboptimal execution plans due to the missing indexes and/or suboptimal join strategies selected because of incorrect cardinality estimation. However, you should not use that number as the only criteria during optimization and take other factors into account, such as resource usage, parallelism, and related operators in the execution plan.
Note You can find the number of I/O operations performed by a query on a per-table basis by enabling I/O statistics using set statistics io on command. An excessive number of logical reads often indicates suboptimal execution plans due to the missing indexes and/or suboptimal join strategies selected because of incorrect cardinality estimation. However, you should not use that number as the only criteria during optimization and take other factors into account, such as resource usage, parallelism, and related operators in the execution plan.
Both logical and physical reads affect the performance of queries. Even though logical reads are very fast, they are not instantaneous. SQL Server burns CPU cycles while accessing data pages in memory, and physical I/O operations are slow. Even with a fast disk subsystem, latency quickly adds up with a large number of physical reads.
One of the optimization techniques that SQL Server uses to reduce number of physical reads is called Read-Ahead. With this technique, SQL Server determines if leaf-level pages reside continuously on the disk based on intermediate index-level information and reads multiple pages as part of single read operation from the data file. This increases the chance that the following read requests would reference data pages, which are already cached in memory, and it minimizes the number of physical reads required. Figure 5-1 illustrates this situation, and it shows two adjacent extents with all data pages fully populated with data.
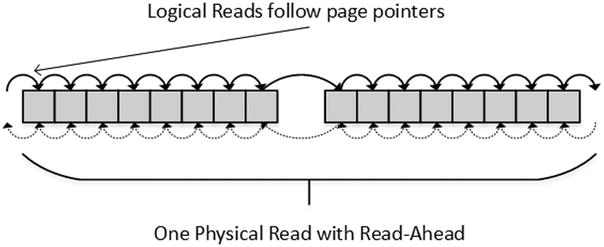
Figure 5-1. Logical and physical reads
Let’s see what happens when you insert a new row into the index. As you will remember, the data in clustered and nonclustered indexes is sorted based on the value of the index key, and SQL Server knows the data page in which the row must be inserted. If the data page has enough free space to accommodate a new row, that would be it. SQL Server just inserts the new row there. However, if data page does not have enough free space, the following happens:
- A new data page and, if needed, a new extent are allocated.
- Some data from old data page is moved to the newly allocated page.
- Previous and next page pointers are updated in order to maintain a logical sorting order in the index.
This process called page split. Figure 5-2 illustrates the data layout when this happens. It is worth mentioning that a page split can happen when you update an existing row, thereby increasing its size, and the data page does not have enough space to accommodate a new, larger version of the row.
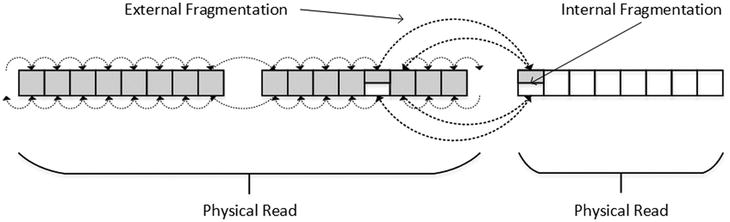
Figure 5-2. Page split and fragmentation
At this point, you have index fragmentation of two kinds: internal and external.
External fragmentationmeans that the logical order of the pages does not match their physical order, and/or logically subsequent pages are not located in the same or adjacent extents. Such fragmentation forces SQL Server to jump around reading the data from the disk, which makes read-ahead less efficient and increases the number of physical reads required. Moreover, it increases random disk I/O, which is far less efficient when compared to sequential I/O in the case of magnetic hard drives.
Internal fragmentation, on the other hand, means that data pages in the index have free space. As a result, the index uses more data pages to store data, which increases the number of logical reads during query execution. In addition, SQL Server uses more memory in buffer pool to cache index pages.
A small degree of internal fragmentation is not necessarily bad. It reduces page splits during insert and update operations when data is inserted into or updated from different parts of the index. Nonetheless, a large degree of internal fragmentation wastes index space and reduces the performance of the system. Moreover, for indexes with ever-increasing keys, for example on identity columns, internal fragmentation is not desirable because the data is always inserted at the end of the index.
There is a data management function, sys.dm_db_index_physical_stats, which you can use to analyze fragmentation in the system. The three most important columns from the result set are:
- avg_page_space_used_in_percent shows the average percentage of the data storage space used on the page. This value shows you the internal index fragmentation.
- avg_fragmentation_in_percent provides you with information about external index fragmentation. For tables with clustered indexes, it indicates the percent of out-of-order pages when the next physical page allocated in the index is different from the page referenced by the next-page pointer of the current page. For heap tables, it indicates the percent of out-of-order extents, when extents are not residing continuously in data files.
- fragment_count indicates how many continuous data fragments the index has. Every fragment constitutes the group of extents adjacent to each other. Adjacent data increases the chances that SQL Server will use sequential I/O and Read-Ahead while accessing the data.
Sys.dm_db_index_physical_stats can analyze data in three different modes: LIMITED, SAMPLED, and DETAILED, which you need to specify as a parameter of the function. In LIMITED mode, SQL Server uses non-leaf index pages to analyze the data. It is the fastest mode, although it does not provide information about internal fragmentation.
In DETAILED mode, SQL Server scans the entire index. As you can guess, that mode provides most accurate results, although it is the most I/O intensive method.
In SAMPLED mode, SQL Server returns statistics based on a one percent data sample from the table when it has 10,000 or more data pages. It reads every 100th page from leaf-level during execution. For tables with less than 10,000 data pages, SQL Server scans the entire index using DETAILED mode instead.
![]() Note Check out the Books Online article at: http://technet.microsoft.com/en-us/library/ms188917.aspx for more details about sys.dm_db_index_physical_stats.
Note Check out the Books Online article at: http://technet.microsoft.com/en-us/library/ms188917.aspx for more details about sys.dm_db_index_physical_stats.
Page split is not limited to single page allocation and data movement. Let’s look at an example, and create the table and populate it with some data, as shown in Listing 5-1.
Listing 5-1. Multiple page splits: Table creation
create table dbo.PageSplitDemo
(
ID int not null,
Data varchar(8000) null
);
create unique clustered index IDX_PageSplitDemo_ID
on dbo.PageSplitDemo(ID);
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 cross join N2 as T2) -- 1,024 rows
,IDs(ID) as (select row_number() over (order by (select NULL)) from N5)
insert into dbo.PageSplitDemo(ID)
select ID * 2
from Ids
where ID <= 620
select page_count, avg_page_space_used_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.PageSplitDemo'),1,null,'DETAILED'),
Following is the output from the code shown from Listing 5-1. As you can see, there is the single data page, which is almost full.
page_count avg_page_space_used_in_percent
---------------- ---------------------------------------------
1 99.5552260934025
As a next step, let’s insert a large row into the table with the code from Listing 5-2 using SQL Server 2008.
Listing 5-2. Multiple page splits: Insert a large row into the table
insert into dbo.PageSplitDemo(ID,Data) values(101,replicate('a',8000));
select page_count, avg_page_space_used_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.PageSplitDemo'),1,null,'DETAILED'),
Following is the output of the code from Listing 5-2. As you can see, SQL Server had to allocate seven new leaf-level data pages to accommodate a new data row and to preserve the logical sorting order in the index.
The process worked in the following way. SQL Server kept 50 rows with ID<=100 on the original page, trying to fit new (ID=101) and remaining (ID>=102) rows into the newly allocated data page. They did not fit into the single page, and SQL Server continued to allocate pages, splitting rows by half until they finally fit.
It is also worth mentioning that SQL Server had to create the root level in the index.
page_count avg_page_space_used_in_percent
---------------- ---------------------------------------------
8 24.8038670620213
1 1.26019273535953
Fortunately, the page split algorithm has been dramatically improved in SQL Server 2012. Following is the output of the code from Listing 5-2 if you run it using SQL Server 2012. When SQL Server 2012 detected that the data does not fit into the newly allocated page, it allocated another (third) page, put new (ID=101) row to one of the pages and all of the remaining rows (ID >= 102) to another one. Therefore, with SQL Server 2012-2014, page split introduces at most two new page allocations.
page_count avg_page_space_used_in_percent
---------------- ---------------------------------------------
3 99.5552260934025
1 0.457128737336299
FILLFACTOR and PAD_INDEX
Every index in SQL Server has a FILLFACTOR option, which allows you to reserve some space on the leaf-level index data pages. Setting FILLFACTOR to something less than 100, which is default value, increases the chances that data pages will have enough free space to accommodate the newly inserted or updated data rows without a page split involved. That option can be set on both the server and individual index levels. SQL Server uses the server level FILLFACTOR when the index does not have FILLFACTOR explicitly specified.
SQL Server maintains FILLFACTOR only when creating or rebuilding the index. It still fills pages up to 100 percent during normal workload, splitting pages when needed.
Another important factor to keep in mind is that by reducing FILLFACTOR, you decrease external index fragmentation and the number of page splits by increasing internal index fragmentation. The index will have more data pages, which will negatively affect the performance of scan operations. Moreover, SQL Server will use more memory in buffer pool to accommodate the increased number of index pages.
There is no recommended setting for FILLFACTOR. You need to fine-tune it by gradually decreasing its value and monitoring how it affects fragmentation with the sys.dm_db_index_physical_stats function. You can start with FILLFACTOR = 100, and decrease it by 5 percent by rebuilding the index with a new FILLFACTOR until you find the optimal value that has the lowest degree of both internal and external fragmentation.
It is recommended that you keep FILLFACTOR = 100 with indexes that have ever-increasing key values. All inserts into those indexes come at the end of the index, and existing data pages do not benefit from the reserved free space unless you are updating data and increasing row size afterwards.
Finally, there is another index option, PAD_INDEX, which controls whether FILLFACTOR is maintained in non-leaf index pages. It is OFF by default and rarely needs to be enabled.
Index Maintenance
SQL Server supports two methods of index maintenance that reduce the fragmentation: index reorganize and index rebuild.
Index reorganize, which is often called index defragmentation, reorders leaf-level data pages into their logical order. This is an online operation, which can be interrupted at any time without forgoing the operation’s progress up to the point of interruption. You can reorganize indexes with the ALTER INDEX REORGANIZE command.
An index rebuild operation, which can be done with the ALTER INDEX REBUILD command, removes external fragmentation by creating another index as a replacement of the old, fragmented one. By default, this is an offline operation, and SQL Server acquires and holds shared (S) table lock for the duration of the operation, which prevents any data modifications of the table.
![]() Note We will discuss lock types and their compatibility in greater detail in Chapter 17, “Lock Types.”
Note We will discuss lock types and their compatibility in greater detail in Chapter 17, “Lock Types.”
The Enterprise edition of SQL Server can perform an online index rebuild. This operation uses row-versioning under the hood, and it allows other sessions to modify data while the index rebuild is still in process.
![]() Note Online index rebuild acquires schema modification (SCH-M) lock during the final phase of execution. Even though this lock is held for a very short time, it can increase locking and blocking in very active OLTP systems. SQL Server 2014 introduces the concept of low-priority locks, which can be used to improve system concurrency during online index rebuild operations. We will discuss low-priority locks in detail in Chapter 23, “Schema Locks.”
Note Online index rebuild acquires schema modification (SCH-M) lock during the final phase of execution. Even though this lock is held for a very short time, it can increase locking and blocking in very active OLTP systems. SQL Server 2014 introduces the concept of low-priority locks, which can be used to improve system concurrency during online index rebuild operations. We will discuss low-priority locks in detail in Chapter 23, “Schema Locks.”
Index rebuild achieves better results than index reorganize, although it is an all or nothing operation; that is, SQL Server rolls back the entire operation if the index rebuild is interrupted. You should also have enough free space in the database to accommodate another copy of the data generated during the index rebuild stage.
Finally, index rebuild updates statistics, while index reorganize does not. You need to factor in this behavior into the statistics maintenance strategy in your system if an automatic statistics update is not optimal in the case of large tables.
Designing an Index Maintenance Strategy
Microsoft suggests performing an index rebuild when the external index fragmentation (avg_fragmentation_in_percent value in sys.dm_dm_index_physical_stats) exceeds 30 percent, and an index reorganize when fragmentation is between 5 and 30 percent. While this may work as general advice, it is important to analyze how badly the system is affected by fragmentation when designing index maintenance strategy.
Index fragmentation hurts most during index scans, when SQL Server needs to read large amounts of data from the disk. Highly tuned OLTP systems, which primarily use index seeks, are usually affected less by fragmentation. It does not really matter where data resides on the disk if a query needs to traverse the index tree and read just a handful of data pages. Moreover, when the data is already cached in the buffer pool, external fragmentation hardly matters at all.
Database file placement is another factor that you need to take into account. One of the reasons why you want to reduce external fragmentation is sequential I/O performance, which, in the case of magnetic hard drives, is usually an order of magnitude better than random I/O performance. However, if multiple database files share the same disk array, it hardly matters. Simultaneous I/O activity generated by multiple databases randomizes all I/O activity on the disk array, making external fragmentation less critical.
Nevertheless, internal fragmentation is still a problem. Indexes use more memory, and queries need to scan more data pages when data pages have large amounts of unused space. This negatively affects system performance, whether data pages are cached or not.
Another important factor is system workload. Index maintenance adds the load to SQL Server, and it is better to perform index maintenance at a time of low activity. Keep in mind that index maintenance overhead is not limited to the single database, and you need to analyze how it affects other databases residing on the same server and/or disk array.
Both index rebuild and reorganize introduce heavy transaction log activity, and generate a large number of log records. This affects the size of the transaction log backup, and it can produce an enormous amount of network traffic if the system uses a transaction log based high-availability technologies, such as AlwaysOn availability groups, database mirroring, log shipping, and replication. It can also affect the availability of the system if failover to another node occurs.
![]() Note We will discuss high-availability strategies in greater detail in Chapter 31, “Designing a High-Availability Strategy.”
Note We will discuss high-availability strategies in greater detail in Chapter 31, “Designing a High-Availability Strategy.”
It is important to consider index maintenance overhead on busy servers that work around the clock. In some cases, it is better to reduce the frequency of index maintenance routines, keeping some level of fragmentation in the system. However, you should always perform index maintenance if such overhead is not an issue. For example, for systems with low activity outside of business hours, there is no reason not to perform index maintenance at nights or on weekends.
The version and edition of SQL Server in use dictates the ability to perform an index maintenance operation online. Table 5-1 shows what options are available based on the version and edition of SQL Server
Table 5-1. Index maintenance options based on SQL Server version and edition

![]() Note Be careful with SQL Server maintenance plans. They tend to perform index maintenance on all indexes, even when it is not required.
Note Be careful with SQL Server maintenance plans. They tend to perform index maintenance on all indexes, even when it is not required.
![]() Tip Ola Hallengren’s free database maintenance script is a great solution that analyzes fragmentation level on a per-index basis, and it performs index rebuild/reorganize only when needed. It is available for download at: http://ola.hallengren.com/.
Tip Ola Hallengren’s free database maintenance script is a great solution that analyzes fragmentation level on a per-index basis, and it performs index rebuild/reorganize only when needed. It is available for download at: http://ola.hallengren.com/.
Finally, do not worry about index fragmentation when a table or index is small, perhaps less than 1,000 data pages. That number, however, could be greater based on the server and system load, available memory, and the number of indexes to rebuild.
With all that being said, the best way to reduce fragmentation is to avoid creating patterns in the database design and code that lead to such conditions.
Patterns that Increase Fragmentation
One of the most common cases that leads to fragmentation is indexing complete random values, such as uniqueidentifiers generated with NEWID() or byte sequences generated with HASHBYTE() functions. Values generated with those functions are randomly inserted into different part of the index, which cause excessive page splits and fragmentation. You should avoid using such indexes if it is at all possible.
![]() Note We will discuss the performance implications of indexes on random values in the next chapter.
Note We will discuss the performance implications of indexes on random values in the next chapter.
Another common pattern contributing to index fragmentation is increasing the size of the row during an update, for example when a system collects data and performs post-processing of some kind, populating additional attributes/columns in a data row. This increases the size of the row, which triggers a page split if the page does not have enough space to accommodate it.
As an example, let’s think about a table that stores GPS location information, which includes both geographic coordinates and the address of the location. Let’s assume that the address is populated during post-processing, after the location information has already been inserted into the system. Listing 5-3 shows the code that creates the table and populates it with some data.
Listing 5-3. Patterns that lead to fragmentation: Table creation
create table dbo.Positions
(
DeviceId int not null,
ATime datetime2(0) not null,
Latitude decimal(9,6) not null,
Longitude decimal(9,6) not null,
Address nvarchar(200) null,
Placeholder char(100) null,
);
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 cross join N4 as T2) -- 65,536 rows
,IDs(ID) as (select row_number() over (order by (select NULL)) from N5)
insert into dbo.Positions(DeviceId, ATime, Latitude, Longitude)
select
ID % 100 /*DeviceId*/
,dateadd(minute, -(ID % 657), getutcdate()) /*ATime*/
,0 /*Latitude - just dummy value*/
,0 /*Longitude - just dummy value*/
from IDs;
create unique clustered index IDX_Postitions_DeviceId_ATime
on dbo.Positions(DeviceId, ATime);
select index_level, page_count, avg_page_space_used_in_percent, avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID(N'dbo.Positions'),1,null,'DETAILED')
At this point, the table has 65,536 rows. A clustered index is created as the last stage during execution. As a result, there is no fragmentation on the index. Figure 5-3 illustrates this point.

Figure 5-3. Fragmentation after table creation
Let’s run the code that populates the address information. This code, shown in Listing 5-4, emulates post-processing.
Listing 5-4. Patterns that lead to fragmentation: Post-processing
update dbo.Positions set Address = N'Position address';
select index_level, page_count, avg_page_space_used_in_percent, avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID(N'dbo.Positions'),1,null,'DETAILED')
Figure 5-4 shows the index fragmentation. Post-processing doubled the number of leaf-level pages of the index, making it heavily fragmented both internally and externally.

Figure 5-4. Fragmentation after post-processing
As you may guess, you can avoid this situation by populating the address information during the insert stage. This option, however, is not always available.
Another option is that you can reserve the space in the row during the insert stage by populating the address with a default value, preallocating the space. Let’s find out how much space is used by the address information with the code shown in Listing 5-5. Figure 5-5 shows the result.
Listing 5-5. Patterns that lead to fragmentation: Calculating average address size
select avg(datalength(Address)) as [Avg Address Size] from dbo.Positions

Figure 5-5. Fragmentation after post-processing
Average address size is 32 bytes, which is 16 Unicode characters. You can populate it with a string of 16 space characters during the insert stage, which would reserve the required space in the row. The code in Listing 5-6 demonstrates this approach.
Listing 5-6. Patterns that lead to fragmentation: Populating address with 16 space characters during insert stage
drop table dbo.Positions
go
create table dbo.Positions
(
DeviceId int not null,
ATime datetime2(0) not null,
Latitude decimal(9,6) not null,
Longitude decimal(9,6) not null,
Address nvarchar(200) null,
Placeholder char(100) null,
);
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 cross join N4 as T2) -- 65,536 rows
,IDs(ID) as (select row_number() over (order by (select NULL)) from N5)
insert into dbo.Positions(DeviceId, ATime, Latitude, Longitude, Address)
select
ID % 100 /*DeviceId*/
,dateadd(minute, -(ID % 657), getutcdate()) /*ATime*/
,0 /*Latitude - just dummy value*/
,0 /*Longitude - just dummy value*/
,replicate(N' ',16) /*Address - adding string of 16 space characters*/
from IDs;
create unique clustered index IDX_Postitions_DeviceId_ATime
on dbo.Positions(DeviceId, ATime);
update dbo.Positions set Address = N'Position address';
select index_level, page_count, avg_page_space_used_in_percent, avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID(N'Positions'),1,null,'DETAILED')
Even though you update the address information during post-processing, it did not increase the size of the data rows. As a result, there is no fragmentation in the table, as shown in Figure 5-6.

Figure 5-6. Fragmentation when address has been pre-populated with 16 space characters during the insert stage
Unfortunately, in some cases you cannot pre-populate some of the columns in the insert stage because of the business or functional requirements of the system. As a workaround, you can create a variable-length column in the table and use it as the placeholder to reserve the space. Listing 5-7 shows such an approach.
Listing 5-7. Patterns that lead to fragmentation: Using a placeholder column to reserve the space
drop table dbo.Positions
go
create table dbo.Positions
(
DeviceId int not null,
ATime datetime2(0) not null,
Latitude decimal(9,6) not null,
Longitude decimal(9,6) not null,
Address nvarchar(200) null,
Placeholder char(100) null,
Dummy varbinary(32)
);
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 cross join N4 as T2) -- 65,536 rows
,IDs(ID) as (select row_number() over (order by (select NULL)) from N5)
insert into dbo.Positions(DeviceId, ATime, Latitude, Longitude, Dummy)
select
ID % 100 /*DeviceId*/
,dateadd(minute, -(ID % 657), getutcdate()) /*ATime*/
,0 /*Latitude - just dummy value*/
,0 /*Longitude - just dummy value*/
,convert(varbinary(32),replicate('0',32)) /*Dummy column to reserve the space*/
from IDs;
create unique clustered index IDX_Postitions_DeviceId_ATime
on dbo.Positions(DeviceId, ATime);
update dbo.Positions
set
Address = N'Position address'
,Dummy = null;
select index_level, page_count, avg_page_space_used_in_percent, avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID(N'Positions'),1,null,'DETAILED')
Row size during post-processing remains the same. Even though it adds 32 bytes to the Address column, it also decreases the row size for the same 32 bytes by setting the Dummy column to null. Figure 5-7 illustrates the fragmentation after the execution of the code.

Figure 5-7. Fragmentation when a placeholder column was used
It is worth mentioning that the efficiency of such a method depends on several factors. First, it would be difficult to predict the amount of space to reserve when the row size increase varies significantly. You can decide to err on the side of caution if this is the case. Keep in mind that even though overestimation reduced external fragmentation, it increased internal fragmentation and left unused space on the data pages.
Another factor is how fragmentation is introduced. That method works best with ever-increasing indexes, when insert fragmentation is minimal. It is less efficient when page splits and fragmentation occur during the insert stage. For example when the indexes on the uniqueidentifier column are populated with the NEWID() value.
Finally, even though this method reduces fragmentation, it does not replace, but rather works in parallel with other index maintenance routines.
Unfortunately, the situation where row size increases during an update is much more common than it might appear at first. SQL Server uses row-versioning to support some of its features. With row-versioning, SQL Server stores one or more old versions of the row in the special part of tempdbcalled version store. It also adds a 14-byte version tag to the rows in the data file to reference rows from version store. That 14-byte version tag is added when a row is modified and, in a nutshell, it increases the row size in a manner that is similar to what you just saw in the post-processing example. The version tag stays in the rows until the index is rebuilt.
The two most common SQL Server features that rely on row-versioning are optimistic transaction isolation levels and AFTER triggers. Both features contribute to index fragmentation, and they need to be taken into account when you design an index maintenance strategy.
![]() Note We will discuss the fragmentation introduced by triggers in Chapter 8, “Triggers.” Optimistic transaction isolation levels are covered in detail in Chapter 21, “Optimistic Isolation Levels.”
Note We will discuss the fragmentation introduced by triggers in Chapter 8, “Triggers.” Optimistic transaction isolation levels are covered in detail in Chapter 21, “Optimistic Isolation Levels.”
Finally, database shrink greatly contributes to external fragmentation due to the way it is implemented. The DBCC SHRINK command works on a per-file basis. It locates the highest page allocated in a file based on the GAM allocation map, and it moves it as far forward as possible without considering to which object those pages belong. It is recommended that you avoid shrink unless absolutely necessary.
It is better to reorganize rather than rebuild indexes after a shrink operation is completed. An index rebuild creates another copy of the index, which increases the size of the data file and defeats the purpose of the shrink.
As the alternative to the shrink process, you can create a new filegroup and recreate indexes by moving objects there. After that, the old and empty filegroup can be dropped. This approach reduces the size of the database similar to a shrink operation without introducing fragmentation.
Summary
There are two types of index fragmentation in SQL Server. External fragmentation occurs when logically subsequent data pages are not located in the same or adjacent extents. Such fragmentation affects the performance of scan operations that require physical I/O reads.
External fragmentation has a much lower effect on the performance of index seek operations, when just a handful of rows and data pages need to be read. Moreover, it does not affect performance when data pages are cached in the buffer pool.
Internal fragmentation occurs when leaf-level data pages in the index have free space. As a result, the index uses more data pages to store data on disk and in memory. Internal fragmentation negatively affects the performance of scan operations, even when data pages are cached, due to the extra data pages that need to be processed.
A small degree of internal fragmentation can speed up insert and update operations and reduce the number of page splits. You can reserve some space in leaf-level index pages during index creation or index rebuild by specifying the FILLFACTOR property. It is recommended that you fine-tune FILLFACTOR by gradually decreasing its value and monitoring how it affects fragmentation in the system.
The sys.dm_db_index_physical_stats data management function allows you to monitor both internal and external fragmentation. There are two ways to reduce index fragmentation. The ALTER INDEX REORGANIZE command reorders index-leaf pages. This is an online operation that can be cancelled at any time without losing its progress. The ALTER INDEX REBUILD command replaces an old fragmented index with its new copy. By default, it is an offline operation, although the Enterprise edition of SQL Server can rebuild indexes online.
You must consider multiple factors when designing index maintenance strategies, such as system workload and availability, the version and edition of SQL Server, and any high-availability technologies used in the system. You should also analyze how fragmentation affects the system. Index maintenance is very resource intensive and, in some cases, the overhead it introduces exceeds the benefits it provides.
The best way to minimize fragmentation, however, is by eliminating its root-cause. Consider avoiding situations where row size increases during updates, do not shrink data files, do not use AFTER triggers, and avoid indexes on the uniqueidentifier or hashbyte columns that are populated with random values.