
![]()
Temporary Tables
Temporary tables are an essential part of SQL Server. SQL Server will sometimes create them during query execution to store working tables and intermediate result sets. At other times, they are created by developers.
In this chapter, we will discuss a few different types of temporary tables that can be created by users: local and global temporary tables, table variables, user-defined table types, and table-valued parameters.
Temporary Tables
We create temporary tables to store short-term information, such as intermediate results and temporary data during data processing. Temporary tables live in tempdb, and they behave very similarly to regular tables. There are a few minor differences, however, which we will discuss later in the chapter.
There are two kinds of the temporary tables: local and global. Local temporary tables are named starting with the # symbol, and they are visible only in the session in which they were created and in the modules called from that session. When multiple sessions simultaneously create local temporary tables with the same name, every session will have its own instance of the table.
When we create a temporary table in a stored procedure, for example, we are able to access it in that specific stored procedure as well as in the stored procedures that we call from that stored procedure.
![]() Caution You can access a temporary table created in a stored procedure from the triggers defined in some tables if the stored procedure performs the action that fires those triggers. However, this is clearly a bad idea, as the data modification operation will fail if a temporary table has not been created.
Caution You can access a temporary table created in a stored procedure from the triggers defined in some tables if the stored procedure performs the action that fires those triggers. However, this is clearly a bad idea, as the data modification operation will fail if a temporary table has not been created.
Listing 12-1 provides an example that demonstrates a temporary table scope.
Listing 12-1. Local temporary table scope and visibility
create table #SessionScope(C1 int not null)
go
create proc dbo.P1
as
begin
-- Success: #SessionScope is visible because it's created
-- in the session scope
select * from #SessionScope
-- Results depends on how P1 is called
select * from #P2Scope
end
go
create proc dbo.P2
as
begin
create table #P2Scope(ID int)
-- Success: #SessionScope is visible because it's created
-- in the session scope
select * from #SessionScope
-- Success - P1 is called from P2 so table #P2Scope is visible there
exec dbo.P1
-- Success #P2Scope is visible from dynamic SQL called from within P2
exec sp_executesql N'select * from #P2Scope'
end
go
-- Success: #SessionScope is visible because it's created in the session scope
select * from #SessionScope
-- Success
exec dbo.P2
-- Error: Invalid object name '#P2Scope'
exec dbo.P1
The temporary table #SessionScope is created on the connection/session level. This table is visible and accessible from anywhere within the session. Another temporary table, #P2Scope, is created in the stored procedure dbo.P2. This table would be visible in the stored procedure (after it has been created) as well as in the other stored procedures and dynamic SQL called from dbo.P2. Finally, as you can see, stored procedure dbo.P1 references both the #SessionScope and #P2Scope tables. As a result, that stored procedure works just fine when it is called from dbo.P2 stored procedure, although it would fail when called from anywhere else if the temporary table #P2Scope has not been created.
You can drop temporary tables using the DROP TABLE statement. Alternatively, SQL Server will drop them when the session has disconnected, or after finishing the execution of the module in which they were created. In the above example, the #SessionScope table would be dropped when the session disconnects and #P2Scope would be dropped after the dbo.P2 stored procedure finishes execution.
Global temporary tables are created with the names starting with ## symbols, and they are visible to all sessions. They are dropped after the session in which they were created disconnects and when other sessions stop referencing them.
Neither global nor local temporary tables can have triggers defined nor can they participate in views. Nonetheless, like regular tables, you can create clustered and non-clustered indexes and define constraints in them.
SQL Server maintains statistics on the indexes defined in the temporary tables in a similar manner to regular tables. Temporary tables have an additional statistics update threshold of six changes to the statistics column, which regular tables do not have. A KEEP PLAN query hint lets us prevent a statistics update based on that threshold and match a regular table’s behavior.
Temporary tables are often used to simplify large and complex queries by splitting them into smaller and simpler ones. This helps the Query Optimizer find a better execution plan in a few ways. First, simpler queries usually have a smaller number of possible execution plan options. This reduces the search area for Query Optimizer, and it improves the chances of finding a better execution plan. In addition, simpler queries usually have better cardinality estimates because the number of errors tends to grow quickly when more and more operators appear in the plan. Moreover, statistics kept by temporary tables allow Query Optimizer to use actual cardinality data rather than relying on those, often-incorrect, estimates.
Let’s look at one such example. In the first step, shown in Listing 12-2, we create a temporary table and populate it with data.
Listing 12-2. Using temporary tables to optimize queries: Table creation
create table dbo.Orders
(
OrderId int not null,
CustomerId int not null,
Amount money not null,
Placeholder char(100),
constraint PK_Orders
primary key clustered(OrderId)
);
create index IDX_Orders_CustomerId on dbo.Orders(CustomerId);
with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 CROSS JOIN N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 CROSS JOIN N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 CROSS JOIN N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 CROSS JOIN N4 as T2) -- 65,536 rows
,IDs(ID) as (select row_number() over (order by (select NULL)) from N5)
insert into dbo.Orders(OrderId, CustomerId, Amount)
select ID, ID % 250 + 1, Id % 50
from IDs
At this point, the table has 65,536 order rows evenly distributed across 250 customers. In the next step, let’s create a multi-statement table-valued function that accepts a comma-separated list of ID values as the parameter and returns a table with individual ID values in the rows. One possible implementation of such a function is shown in Listing 12-3.
Listing 12-3. Using temporary tables to optimize queries: Function creation
create function dbo.ParseIDList(@List varchar(8000))
returns @IDList table
(
ID int
)
as
begin
if (IsNull(@List,'') = '')
return
if (right(@List,1) <> ',')
select @List += ','
;with CTE(F, L)
as
(
select 1, charindex(',',@List)
union all
select L + 1, charindex(',',@List,L + 1)
from CTE
where charindex(',',@List,L + 1) <> 0
)
insert into @IDList(ID)
select distinct convert(int,substring(@List,F,L-F))
from CTE
option (maxrecursion 0);
return
end
Now let’s run a SELECT statement that calculates the total amount for all orders for all customers. We will build a comma-separated list of values from 1 to 250 and use a dbo.ParseIDList function to parse it. We will join the Orders table with the function, as shown in Listing 12-4, and then examine the execution plan, as shown in Figure 12-1.
Listing 12-4. Using temporary tables to optimize queries: Joining the Orders table with a multi-statement table-valued function
declare
@List varchar(8000)
-- Populate @List with comma-separated list of integers
-- from 1 to 250
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 CROSS JOIN N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 CROSS JOIN N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 CROSS JOIN N3 as T2) -- 256 rows
,IDs(ID) as (select row_number() over (order by (select NULL)) from N4)
select @List = convert(varchar(8000),
(
select ID as [text()], ',' as [text()]
from IDs
where ID <= 250
for xml path('')
)
)
select sum(o.Amount)
from dbo.Orders o join dbo.ParseIDList(@List) l on
o.CustomerID = l.ID
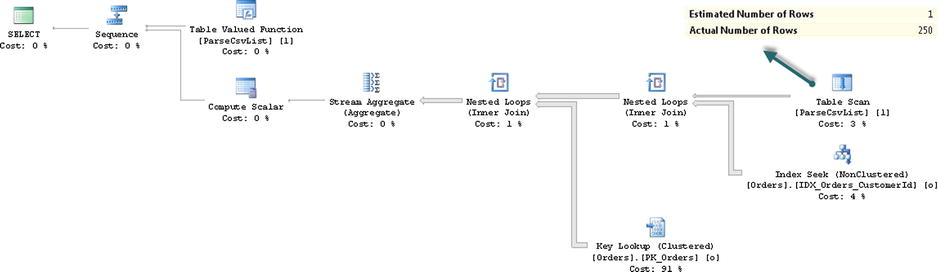
Figure 12-1. Execution plan for the query that joins a table and a function
As you know, SQL Server always estimates that multi-statement table-valued functions return just one row. It would lead to a very inefficient execution plan in our example.
The I/O statistics and execution time on my computer produced the results shown in Listing 12-5.
Listing 12-5. Using temporary tables to optimize queries: I/O statistics and execution time
Table 'Orders'. Scan count 250, logical reads 201295
Table '#25869641'. Scan count 1, logical reads 1
SQL Server Execution Times:
CPU time = 249 ms, elapsed time = 239 ms.
Now let’s change our approach and populate a temporary table with the values returned by ParseIDList function, as shown in Listing 12-6.
Listing 12-6. Using temporary tables to optimize queries: temporary table approach
declare
@List varchar(8000)
-- Populate @List with comma-separated list of integers
-- from 1 to 250
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 CROSS JOIN N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 CROSS JOIN N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 CROSS JOIN N3 as T2) -- 256 rows
,IDs(ID) as (select row_number() over (order by (select NULL)) from N4)
select @List = convert(varchar(8000),
(
select ID as [text()], ',' as [text()]
from IDs
where ID <= 250
for xml path('')
)
)
create table #Customers(ID int not null primary key)
insert into #Customers(ID)
select ID from dbo.ParseIDList(@List)
select sum(o.Amount)
from dbo.Orders o join #Customers c on
o.CustomerID = c.ID
drop table #Customers
As you see in Figure 12-2, SQL Server estimates the number of the IDs correctly and, as a result, you end up with a much more efficient execution plan.

Figure 12-2. Execution plan for a query that uses temporary table
Now let’s look at the I/O statistics and execution time shown in Listing 12-7.
Listing 12-7. Using temporary tables to optimize queries: I/O statistics and execution time
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
Table '#Customers__________00000000001D'. Scan count 0, logical reads 501
Table '#25869641'. Scan count 1, logical reads 1
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 6 ms.
Table 'Orders'. Scan count 1, logical reads 1029
Table '#Customers__________00000000001D'. Scan count 1, logical reads 2
You can see that with the temporary table, our query is more than 30 times faster and uses two orders of magnitude less I/O compared to the query that used a multi-statement table-valued function.
Obviously, there is overhead associated with temporary tables, especially in cases when you insert a large amount of data. In some cases, such overhead would degrade the performance of the queries, even with the more efficient execution plans that were generated. For example, if in majority of cases you calculate the total orders amount for a single or for very few customers, the approach with the temporary table would be slower than without it. You will end up with similar execution plans, but you will have to deal with the overhead from creating and populating the table. On the other hand, you may decide to live with such overhead, rather than having to deal with poor performance that results in the rare cases when you run the query for a large list of customers.
Creation and deletion of temporary tables requires access to and modifications of the allocation map pages, such as IAM, SGAM, and PFS as well as of the system tables. While the same actions occur during the creation of the regular tables in users’ databases, the system rarely creates and drops users’ table at a high rate. Temporary tables, on the other hand, can be created and dropped quite frequently. On busy systems, this can lead to contention when multiple sessions are trying to modify allocation map pages.
![]() Note We will talk how to detect such contentions in Part 5 of this book, “Practical Troubleshooting.”
Note We will talk how to detect such contentions in Part 5 of this book, “Practical Troubleshooting.”
In order to improve performance, SQL Server introduces the concept of temporary table caching. This term is a bit confusing. It relates to temporary table allocation rather than data pages, which are cached in a buffer pool, similar to regular tables.
In a nutshell, with temporary table caching, instead of dropping the table, SQL Server truncates it, keeping two pages per index pre-allocated: one IAM and one data page. The next time the table is created, SQL Server will reuse these pages, which helps reduce the number of modifications required in the allocation map pages.
Let’s look at the example shown in Listing 12-8. In the first step, we write the stored procedure that creates and drops the temporary table.
Listing 12-8. Temporary tables caching: Stored procedure
create proc dbo.TempTableCaching
as
create table #T(C int not null primary key)
drop table #T
In the next step, we run the stored procedure and examine the transaction log activity it generates. You can see the code for doing this in Listing 12-9.
Listing 12-9. Temporary tables caching: Running the stored procedure
checkpoint
go
exec dbo.TempTableCaching
go
select Operation, Context, AllocUnitName, [Transaction Name], [Description]
from sys.fn_dblog(null, null)
When you run this code for the first time, you will see results similar to Figure 12-3.
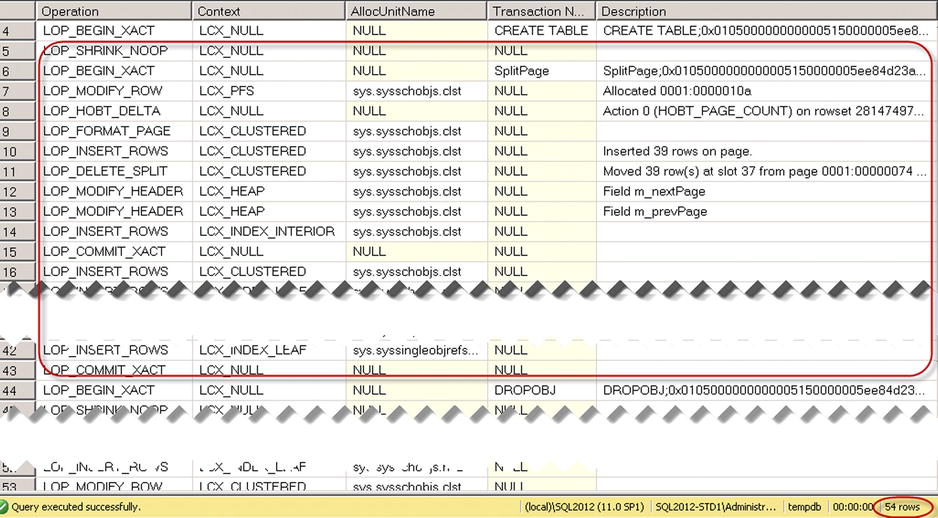
Figure 12-3. Log activity when a temporary table has not been cached
As you see, the first stored procedure call produced 50 log records. Forty of them (the highlighted portion) related to the update of the allocation map pages and system tables during temporary table creation.
If you run the code from Listing 12-9 a second time, you will see a different picture, as shown in Figure 12-4.

Figure 12-4. Log activity when the temporary table has been cached
This time, when the temporary table is cached, table creation introduces just a few log records, all of which are against the system table with no allocation map pages involved.
SQL Server does not cache IAM and data pages for global temporary tables nor does it cache local temporary tables created in the session scope. Only the temporary tables created within the stored procedures and triggers are cached.
There are also a few requirements of the table and code, including:
- The table needs to be smaller than eight megabytes. Large tables are not cached.
- There are no DDL statements that change the table structure. Any schema modification statements in the code, with exception of DROP TABLE, will prevent a temporary table caching. However, you can create indexes on the table and, as mentioned previously, SQL Server will cache them.
- There are no named constraints defined in the table. Unnamed constraints will not prevent the caching.
As you see, it is very easy to follow the guidelines that make temporary tables cacheable. This can significantly improve performance and reduce tempdb allocation map pages contention on busy systems.
Despite the myth that table variables are in-memory objects, they are actually created and live in tempdb similar to regular temporary tables. You can think about them as lightweight temporary tables, although their lightness comes with the set of the limitations and restrictions.
The first major difference between temporary tables and table variables is the scope. Table variables live only within the batch in which they were created. They are not accessible from outside of the batch, as opposed to temporary tables. For example, when you define the table variable in a stored procedure, you are not able to reference it from the dynamic SQL nor from other stored procedures called from the original one.
You cannot create indexes on table variables, with exception of primary key and unique constraints.
![]() Important SQL Server does not maintain any statistics on table variables, and it always estimates that a table variable has just a single row, unless a statement-level recompile is used.
Important SQL Server does not maintain any statistics on table variables, and it always estimates that a table variable has just a single row, unless a statement-level recompile is used.
Look at the example shown in Listing 12-10. In this example, we create a temporary table and table variable, populate it with some data, and check SQL Server’s cardinality estimations.
Listing 12-10. Cardinality estimation for temporary tables and table variables
declare
@TTV table(ID int not null primary key)
create table #TT(ID int not null primary key)
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 CROSS JOIN N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 CROSS JOIN N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 CROSS JOIN N3 as T2) -- 256 rows
,IDs(ID) as (select row_number() over (order by (select NULL)) from N4)
insert into #TT(ID)
select ID from IDs
insert into @TTV(ID)
select ID from #TT
select count(*) from #TT
select count(*) from @TTV
select count(*) from @TTV option (recompile)
As you see in Figure 12-5, unless you are using a statement level recompile, SQL Server estimates that a table variable has only one row. Cardinality estimation errors often progress quickly through the execution plan, and this can lead to highly inefficient plans when table variables are used.

Figure 12-5. Cardinality estimation for temporary tables and table variables
A statement level recompile provides the Query Optimizer with information about the total number of rows, although no statistics are kept and the Query Optimizer knows nothing about data distribution in the table variable.
Now let’s change our previous example and add a where ID > 0 clause to all three selects. As you know, all ID values in both tables are positive. When you run these selects, you will receive the cardinality estimations shown in Figure 12-6.

Figure 12-6. Cardinality estimations for temporary tables and table variables
Regular temporary tables maintain statistics on indexes and, as a result, SQL Server was able to estimate the number of rows in the first select correctly. As previously, without a statement level recompile, it is assumed that the table variable has only a single row. Nevertheless, even with a statement level recompile, the estimations were way off. There are no statistics, and SQL Server assumes that the greater operator will return one-third of the rows from the table, which is incorrect in our case.
Another difference between temporary tables and table variables is how they handle transactions. Temporary tables are fully transaction-aware, similar to the regular tables. Table variables, on the other hand, only support statement-level rollback. Any statement-level errors, for example “key violation,” would rollback the statement. Although explicit transaction rollback keeps the table variable data intact.
Let’s look at a couple of examples. In the first example, we will produce a primary key violation error during the insert operation. The code for this is shown in Listing 12-11.
Listing 12-11. Temporary table variables: statement-level rollback
declare
@T table(ID int not null primary key)
-- Success
insert into @T(ID) values(1)
-- Error: primary key violation
insert into @T(ID) values(2),(3),(3)
-- 1 row
select * from @T
As you see in Figure 12-7, the second insert statement did not add the rows to the table.

Figure 12-7. Table variables: statement-level rollback
Now let’s examine what happens when we rollback an explicit transaction. The code for doing this is shown in Listing 12-12.
Listing 12-12. Table variables: explicit transactions
declare
@Errors table
(
RecId int not null,
[Error] nvarchar(512) not null,
primary key(RecId)
)
begin tran
-- Insert error information
insert into @Errors(RecId, [Error])
values
(11,'Price mistake'),
(42,'Insufficient stock')
rollback
/* Do something with errors */
select RecId, [Error] from @Errors
As you see in Figure 12-8, the explicit rollback statement did not affect the table variable data. You can benefit from such behavior when you need to collect some error or log information that you want to persist after the transaction has been rolled back.

Figure 12-8. Table variables: explicit transactions
![]() Caution While table variables can outperform temporary tables in some cases, due to their lower overhead, you need to be extremely careful with them. Especially when you store large amounts of data in the table variable. The single row cardinality estimation rule and missing statistics can produce highly inefficient plans with a large number of rows involved. A statement level recompile can help address cardinality estimation issues, although it will not help when the data distribution needs to be analyzed.
Caution While table variables can outperform temporary tables in some cases, due to their lower overhead, you need to be extremely careful with them. Especially when you store large amounts of data in the table variable. The single row cardinality estimation rule and missing statistics can produce highly inefficient plans with a large number of rows involved. A statement level recompile can help address cardinality estimation issues, although it will not help when the data distribution needs to be analyzed.
As a general rule of thumb, it is safer to use temporary tables rather than table variables when you need to join them with other tables. This is the case except when you are dealing a with very small number of rows, and table variables limitations would not create suboptimal plans.
Table variables are a good choice when you need to deal with a large number of rows when no joins with other tables are involved. For example, you can think about the stored procedure where you stage the data, do some processing, and return the data to the client. If there is no other choice but to scan the entire table, you will have the same execution plans, which scan the data, regardless of what object types are used. In these cases, table variables can outperform temporary tables. Finally, table variables are cached in the same way as temporary tables.
User-Defined Table Types and Table-Valued Parameters
You can define table types in the database. When you declare the variable of the table type in the code, it works the same way as with table variables.
Alternatively, you can pass the variables of the table types, called table-valued parameters, to T-SQL modules. While table-valued parameters are implemented as table variables under the hood, they are actually read-only. You cannot insert, update, or delete the data from table-valued parameters.
The code in Listing 12-13 shows how you can use table-valued parameters. It creates the table type dbo.tvpErrors, calls the stored procedure with a table-valued parameter, and uses this parameter in dynamic SQL.
Listing 12-13. Table-valued parameters
create type dbo.tvpErrors as table
(
RecId int not null,
[Error] nvarchar(512) not null,
primary key(RecId)
)
go
create proc dbo.TvpDemo
(
@Errors dbo.tvpErrors readonly
)
as
select RecId, [Error] from @Errors
exec sp_executesql
N'select RecId, [Error] from @Err'
,N'@Err dbo.tvpErrors readonly'
,@Err = @Errors
go
declare
@Errors dbo.tvpErrors
insert into @Errors(RecId, [Error])
values
(11,'Price mistake'),
(42,'Insufficient stock')
exec dbo.TvpDemo @Errors
As you see, you need to mention explicitly that the table-valued parameter is read-only in both, the stored procedure and the dynamic sql parameter lists.
Table-valued parameters are one of the fastest ways to pass a batch of rows from a client application to a T-SQL routine. Table-valued parameters are an order of magnitude faster than separate DML statements and, in some cases, they can even outperform bulk operations.
Now let’s run a few tests comparing the performance of inserting the data into the table using different methods and different batch sizes. As a first step, we create a table to store the data, as shown in Listing 12-14. The actual table used in the tests has 21 data columns. A few data columns are omitted in the listing in order to save space.
Listing 12-14. Inserting a batch of rows: Table creation
create table dbo.Data
(
ID int not null,
Col1 varchar(20) not null,
Col2 varchar(20) not null,
/* Seventeen more columns Col3 - Col19*/
Col20 varchar(20) not null,
constraint PK_DataRecords
primary key clustered(ID)
)
The first method we will use to measure performance is to run separate insert statements within the transaction. The .Net code to do this is shown in Listing 12-15. It is worth mentioning that the only purpose of the code is to generate dummy data and to test the performance of the different methods that insert the data into the database.
Listing 12-15. Inserting a batch of rows: Using separate inserts
TruncateTable();
using (SqlConnection conn = GetConnection())
{
/* Generating SqlCommand and parameters */
SqlCommand insertCmd = new SqlCommand(
@"insert into dbo.Data(ID,Col1,Col2,Col3,Col4,Col5,Col6,Col7
,Col8,Col9,Col10,Col11,Col12,Col13,Col14,Col15,Col16,Col17
,Col18,Col19,Col20)
values(@ID,@Col1,@Col2,@Col3,@Col4,@Col5,@Col6,@Col7,@Col8
,@Col9,@Col10,@Col11,@Col12,@Col13,@Col14,@Col15,@Col16,@Col17
,@Col18,@Col19,@Col20)",conn);
insertCmd.Parameters.Add("@ID", SqlDbType.Int);
for (int i = 1; i <= 20; i++)
insertCmd.Parameters.Add("@Col" + i.ToString(), SqlDbType.VarChar, 20);
/* Running individual insert statements in the loop within explicit transaction */
using (SqlTransaction tran = conn.BeginTransaction(IsolationLevel.ReadCommitted))
{
try
{
insertCmd.Transaction = tran;
for (int i = 0; i < packetSize; i++)
{
insertCmd.Parameters[0].Value = i;
for (int p = 1; p <= 20; p++)
insertCmd.Parameters[p].Value = "Parameter: " + p.ToString();
insertCmd.ExecuteNonQuery();
}
tran.Commit();
}
catch (Exception ex)
{
tran.Rollback();
}
}
The second method is to send the entire batch at once in an element-centric XML format using the stored procedure to parse it. The .Net code is omitted, and the stored procedure is shown in Listing 12-16.
Listing 12-16. Inserting a batch of rows: Using element-centric XML
create proc dbo.InsertDataXmlElementCentric
(
@Data xml
)
as
-- @Data is in the following format:
-- <Rows><R><ID>{0}</ID><C1>{1}</C1><C2>{2}</C2>..<C20>{20}</C20></R></Rows>
insert into dbo.Data(ID,Col1,Col2,Col3,Col4,Col5,Col6,Col7,Col8,Col9
,Col10,Col11,Col12,Col13,Col14,Col15,Col16,Col17,Col18,Col19,Col20)
select
rows.n.value('(ID/text())[1]', 'int')
,rows.n.value('(C1/text())[1]', 'varchar(20)')
,rows.n.value('(C2/text())[1]', 'varchar(20)')
/* other 17 columns */
,rows.n.value('(C20/text())[1]', 'varchar(20)')
from
@Data.nodes('//Rows/R') rows(n)
The third method is very similar to the second, but it uses attribute-centric XML instead. The code for this is shown in Listing 12-17.
Listing 12-17. Inserting a batch of rows: Using attribute-centric XML
create proc dbo.InsertDataXmlAttributeCentric
(
@Data xml
)
as
-- @Data is in the following format:
-- <Rows><R ID="{0}" C1="{1}" C2="{2}"..C20="{20}"/></Rows>
insert into dbo.Data(ID,Col1,Col2,Col3,Col4,Col5,Col6,Col7,Col8,Col9
,Col10,Col11,Col12,Col13,Col14,Col15,Col16,Col17,Col18,Col19,Col20)
select
rows.n.value('@ID', 'int')
,rows.n.value('@C1', 'varchar(20)')
,rows.n.value('@C2', 'varchar(20)')
/* other 17 columns */
,rows.n.value('@C20', 'varchar(20)')
from
@Data.nodes('//Rows/R') rows(n)
The fourth method uses a SqlBulkCopy .Net class with DataTable as the source using row-level locks. The code for this is shown in Listing 12-18.
Listing 12-18. Inserting a batch of rows: Using SqlBulkCopy .Net class
TruncateTable();
using (SqlConnection conn = GetConnection())
{
/* Creating and populating DataTable object with dummy data */
DataTable table = new DataTable();
.Columns.Add("ID", typeof(Int32));
for (int i = 1; i <= 20; i++)
table.Columns.Add("Col" + i.ToString(), typeof(string));
for (int i = 0; i < packetSize; i++)
table.Rows.Add(i, "Parameter: 1", "Parameter: 2", /* Other columns */ "Parameter: 20");
/* Saving data into the database */
using (SqlBulkCopy bc = new SqlBulkCopy(conn))
{
bc.BatchSize = packetSize;
bc.DestinationTableName = "dbo.Data";
bc.WriteToServer(table);
}
}
Finally, the last method uses table-valued parameters. Listing 12-19 shows the T-SQL code and Listing 12-20 shows the .Net part of the implementation.
Listing 12-19. Inserting a batch of rows: Table-valued parameters T-SQL code
create type dbo.tvpData as table
(
ID int not null,
Col1 varchar(20) not null,
Col2 varchar(20) not null,
/* Seventeen more columns: Col3 - Col19 */
Col20 varchar(20) not null,
primary key(ID)
)
go
create proc dbo.InsertDataTVP
(
@Data dbo.tvpData readonly
)
as
insert into dbo.Data(ID,Col1,Col2,Col3,Col4,Col5,Col6,Col7,Col8,Col9,Col10
,Col11,Col12,Col13,Col14,Col15,Col16,Col17,Col18,Col19,Col20)
select ID,Col1,Col2,Col3,Col4,Col5,Col6,Col7,Col8,Col9,Col10
,Col11,Col12,Col13, Col14,Col15,Col16,Col17,Col18,Col19,Col20
from @Data
Listing 12-20. Inserting a batch of rows: Table-valued parameters .Net code
TruncateTable();
using (SqlConnection conn = GetConnection())
{
/* Creating and populating DataTable object with dummy data */
DataTable table = new DataTable();
table.Columns.Add("ID", typeof(Int32));
for (int i = 1; i <= 20; i++)
table.Columns.Add("Col" + i.ToString(), typeof(string));
for (int i = 0; i < packetSize; i++)
table.Rows.Add(i, "Parameter: 1", "Parameter: 2", /* Other columns */ "Parameter: 20");
/* Calling SP with TVP parameter */
SqlCommand insertCmd = new SqlCommand("dbo.InsertDataTVP", conn);
insertCmd.Parameters.Add("@Data", SqlDbType.Structured);
insertCmd.Parameters[0].TypeName = "dbo.tvpData";
insertCmd.Parameters[0].Value = table;
insertCmd.ExecuteNonQuery();
}
I ran two series of tests measuring average execution time for the different methods and different batch sizes. In the first test, the application ran on the same server as SQL Server. On the second test, the application connected to SQL Server over a network. You can see the execution time for these two tests in milliseconds in Tables 12-1 and 12-2.
Table 12-1. Execution time when the application was run locally (in milliseconds)
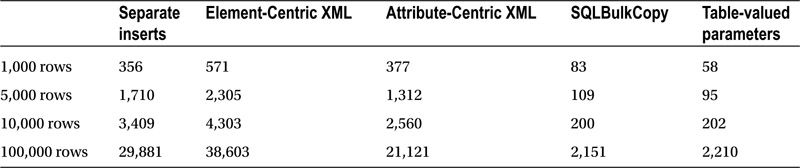
Table 12-2. Execution time when the application was run remotely (in milliseconds)
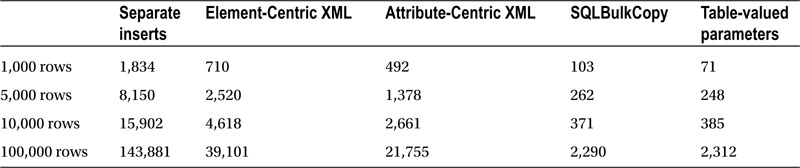
Performance of the separate insert statements greatly depends on network speed. This approach introduces a lot of network activity, and it does not perform well, especially with slow networks. The performance of the other methods do not depend greatly on the network.
As expected, the performance of attribute-centric XML is better than element-centric XML. It will also outperform separate inserts with the large batches—even with no network overhead involved. It is worth mentioning that the performance of XML implementations greatly depends on the data schema. Every XML element adds another operator to the execution plan, which slows XML parsing.
SQLBulkCopy and table-valued parameters are by far the fastest methods. Table-valued parameters are slightly more efficient with smaller batches, while SqlBulkCopy is slightly faster with the large ones. Nonetheless, the variation in performance is negligible.
When you work with table-valued parameters in the client code, you need to assign a DataTable object to a corresponding SqlParameter object. The DataTable object should match the corresponding table type definition from both the schema and data standpoints. The DataTable object should have the same number of columns, and these columns should have the same names and be in the same order as the table type defined in the database. They also need to support type conversions between the corresponding .Net and SQL data types.
Data in the table needs to conform to the table type primary and unique constraints, and it should not exceed the defined column sizes and T-SQL data type’s domain values.
Finally, table types should not have sql_variant columns. Unfortunately, the .Net SQL client does not work with them correctly, and it raises exceptions during the call when the table-valued type has a sql_variant column defined.
Regular Tables in tempdb
You can create regular tables in tempdb, either directly or through the model database. User tables in tempdb are visible in all sessions.
Tempdb is recreated every time SQL Server restarts and, because of this, it does not need to support crash recovery. As a result, Tempdb uses the SIMPLE recovery model, and it has some additional logging optimizations, which make it more efficient than logging in the user’s databases.
![]() Note We will discuss recovery models, and the differences in logging between tempdb and user databases in Chapter 29, “Transaction Log Internals.”
Note We will discuss recovery models, and the differences in logging between tempdb and user databases in Chapter 29, “Transaction Log Internals.”
Tempdb could be a choice as the staging area for ETL processes, where you need to load and process a large amount of data as fast as possible with minimum logging overhead. You can use temporary tables when the process is done as a single session, however you need to use regular tables in more complex cases.
![]() Important While tempdb can help with staging area performance, client applications need to handle the situation when tempdb is recreated and the tables with the data are gone. This may occur if SQL Server restarts or fails over to another node.
Important While tempdb can help with staging area performance, client applications need to handle the situation when tempdb is recreated and the tables with the data are gone. This may occur if SQL Server restarts or fails over to another node.
To make the situation even worse, this can happen transparently to the client applications in some cases. Applications need to handle those situations either by checking the existence of the staging tables or, if you are creating tables automatically, the state information needs to be persisted somewhere else.
Let’s assume that we have a table called ETLStatuses, which contains information about the ETL process statuses. There are a couple ways that you can create such a table. One is using a model database. All objects created in a model database are copied to tempdb during SQL Server startup.
![]() Caution All objects created in a model database will be copied into the user databases that are created afterward.
Caution All objects created in a model database will be copied into the user databases that are created afterward.
Alternatively, you can create objects in tempdb using a stored procedure that executes upon SQL Server startup. Listing 12-21 shows such an example.
Listing 12-21. Creating a table in tempdb with a startup stored procedure
use master;
GO
-- Enable scan for startup procs
exec sp_configure 'show advanced option', '1';
reconfigure;
exec sp_configure 'scan for startup procs', '1';
reconfigure;
go
create proc dbo.CreateETLStatusesTable
as
create table tempdb.dbo.ETLStatuses
(
ProcessId int not null,
ActivityTime datetime not null,
StageNo smallint not null,
[Status] varchar(16) not null,
constraint PK_ETLStatuses
primary key clustered (ProcessID)
)
Go
-- Mark procedure to run on SQL Server Startup
exec sp_procoption N'CreateETLStatusesTable', 'startup', 'on'
Listing 12-22 shows a possible implementation of the procedure that performs one of the stages of ETL processing using the ETLStatuses table to validate process state information.
Listing 12-22. Creating a table in tempdb with the startup stored procedure
-- Either defined in user db or in tempdb
create proc dbo.ETL_Process1Stage2
as
begin
-- Returns
-- 0: Success
-- -1: ETL tables do not exist – something is wrong
-- -2: ETLStatuses table does not have the record for the process
-- -3: Invalid stage
set xact_abort on
declare
@StageNo smallint
,@Status varchar(16)
if object_id(N'tempdb.dbo.ETLStatuses') is null or object_id(N'tempdb.dbo.ETLData') is null
return -1
select @StageNo = StageNo, @Status = [Status]
from tempdb.dbo.ETLStatuses
where ProcessId = 1
if @@rowcount = 0
return -2
if @StageNo <> 1 or @Status <> 'COMPLETED'
return -3
-- This implementation rolls back all the changes in case of the error
-- and throw the exception to the client application.
Begin tran
update tempdb.dbo.ETLStatuses
set ActivityTime = getutcdate(), StageNo = 2, [Status] = 'STARTED'
where ProcessId = 1
/* Processing */
update tempdb.dbo.ETLStatuses
set ActivityTime = getutcdate(), [Status] = 'COMPLETED'
where ProcessId = 1
commit
return 0
end
Of course, there are other ways to accomplish the same task. However, the key point here is the need to make your code aware of the situations when tempdb is recreated and the staged data is gone.
Optimizing tempdb Performance
Tempdb is usually the busiest database on the server. In addition to temporary objects created by users, SQL Server uses this database to store internal result sets during query executions, version store, internal temporary tables for sorting, hashing, and database consistency checking, and so forth. Tempdb performance is a crucial component in overall server health and performance. Thus in most cases, you would like to put tempdb on the fastest disk array that you have available.
Redundancy of the array is another issue. On one hand, you do not need to worry much about the data that you are storing in tempdb. On the other hand, if the tempdb disk array goes down, SQL Server becomes unavailable. As a general rule then, you would like to have disk array redundant.
Although, in some cases, when tempdb performance becomes a bottleneck and your high-availability strategy supports simultaneous failure of two or more nodes, and furthermore there are spare parts available and there is a process in place that allows you to bring the failed node(s) online quickly, you could consider making tempdb disk array non-redundant. This is dangerous route, however, and you need to consider the pros and cons of this decision very carefully.
There is a trace flag T1118 that prevents SQL Server from using mixed extents for space allocation. By allocating uniform extents only, you would reduce the number of changes required in the allocation map pages during object creation. Moreover, even if temporary table caching keeps only one data page cached, that page would belong to its own free uniform extent. As a result, SQL Server does not need to search, and potentially allocate, the mixed extents with free pages available during the allocation of pages two to eight of the table. Those page can be stored in the same uniform extent in which the first cached data page belongs.
The bottom line is that trace flag T1118 can significantly reduce allocation map pages contention in tempdb. This trace flag should be enabled in every SQL Server instance; that is, there is no downside to doing this.
Another way to reduce contention is by creating multiple tempdb data files. Every data file has its own set of allocation map pages and, as a result, allocations are spread across these files and pages. This reduces the chances of contention because fewer threads are then competing simultaneously for access to the same allocation map pages.
There is no generic rule that defines the optimal number of tempdb data files—everything depends on the actual system workload and behavior. The old guidance to have the number of data files equal the number of logical processors is no longer the best advice. While that approach still works, an extremely large number of the data files could even degrade the performance of the system in some cases.
The Microsoft CSS team performed the stress test of tempdb performance using a server with 64 logical processors running under a heavy load with 500 connections that create, populate, and drop temporary tables into the loop. Table 12-3 displays the execution time based on the number of files in tempdb and a Trace Flag 1118 configuration.
Table 12-3. Execution time based on the number of data files in tempdb

As you see, creating more than one data file dramatically improved tempdb performance, although it stabilizes at some point. For instance, there was only a marginal difference in performance between the 32 and 64 data file scenarios.
In general, you should start with the number of files equal to the number of logical processors in case the system has eight or fewer logical processors. Otherwise, start with eight data files and add them in groups of four in case there is still contention in the system. Make sure that the files were created with the same initial size and same auto-growth parameters, with growth size set in megabytes rather than by percent. This helps to avoid situations where files grow disproportionately and, as a result, some files would process more allocations than others.
Of course, the best method of optimizing tempdb performance is to reduce unnecessary activity. You can refactor your code to avoid unnecessary usage of temporary tables, avoid extra load to the version store because of triggers or unnecessary optimistic transaction isolation levels, reduce the number of internal working tables created by SQL Server by optimizing the queries and simplifying execution plans, and so on. The less unnecessary activity tempdb has, the better it performs.
Summary
There are many different object types that can be created in tempdb by users. Temporary tables behave similarly to regular tables. They can be used to store intermediate data during the processing. In some cases, you can split complex queries into smaller ones by keeping intermediate results in temporary tables. While this introduces the overhead of creating and populating the temporary tables, it can help Query Optimizer to generate simpler and more efficient execution plans.
Table variables are a lightweight version of temporary tables. While they can outperform temporary tables in some cases, they have a set of restrictions and limitations. These limitations can introduce suboptimal execution plans when you join table variables with other tables.
Table-valued parameters allow you to pass rowsets as parameters to stored procedures and functions. They are the one of the fastest ways to pass batches of rows from client applications to T-SQL routines.
The user’s table in tempdb can be used as the staging area for data during ETL processes. This approach can outperform the staging tables in the user databases due to the more efficient logging in tempdb. However, client applications need to handle the situation when those tables and/or data disappear after a SQL Server restart or failover to another node.
As opposed to regular tables in the user’s database, temporary objects can be created at a very high rate and they can introduce allocation map pages and system object contention in tempdb. You should create multiple tempdb data files and use trace flag T1118 to reduce it.
Finally, you should utilize temporary table caching, which reduces the contention even further. You need to avoid named constraints in temporary tables, and do not alter them to make them cacheable.