
![]()
Database systems never live in a vacuum; they always have client applications that depend on them. Implementing efficient database design and T-SQL code is essential for good system health and performance; however, it is not enough. Poorly designed and written client applications will never perform well, regardless of the quality of the database backend.
In this chapter, we will talk about several important factors that help in designing an efficient data access layer in applications utilizing SQL Server as a backend database. We will also discuss the usage of ORM (Object-Relational Mapping) frameworks with Microsoft Entity Framework 6.
There was a time when developers were able to write successful business-oriented applications while working alone or in small teams. Those days are long gone, however. Modern enterprise-level systems consist of hundreds of thousands, or even millions, of lines of code, and they require thousands of man-hours to develop, test, deploy, and support them. Large teams create these applications with members who have different talents, skills, and areas of specialization.
The right system architecture is critical for the success of a project. It allows many people to work on the project in parallel without stepping on each other’s toes. It simplifies the support and refactoring of the system when requirements are changed.
The architecture of a modern system utilizes a layered approach, separating distinct roles and functional components from each other. In complex systems, layers are implemented as different service components and modules. Smaller systems can maintain the logical separation of the layers, developing them as different classes and assemblies in a single application. In the end, physical architecture is less important as long as logical separation is in place. However, good system design should allow you to scale the system and/or some of the layers with a minimal amount of refactoring involved.
![]() Note You can read more about system design and architecture considerations in the Microsoft Application Architecture Guide at: http://msdn.microsoft.com/en-us/library/ff650706.aspx.
Note You can read more about system design and architecture considerations in the Microsoft Application Architecture Guide at: http://msdn.microsoft.com/en-us/library/ff650706.aspx.
Figure 16-1 illustrates a high-level architectural diagram of a system with multiple layers.
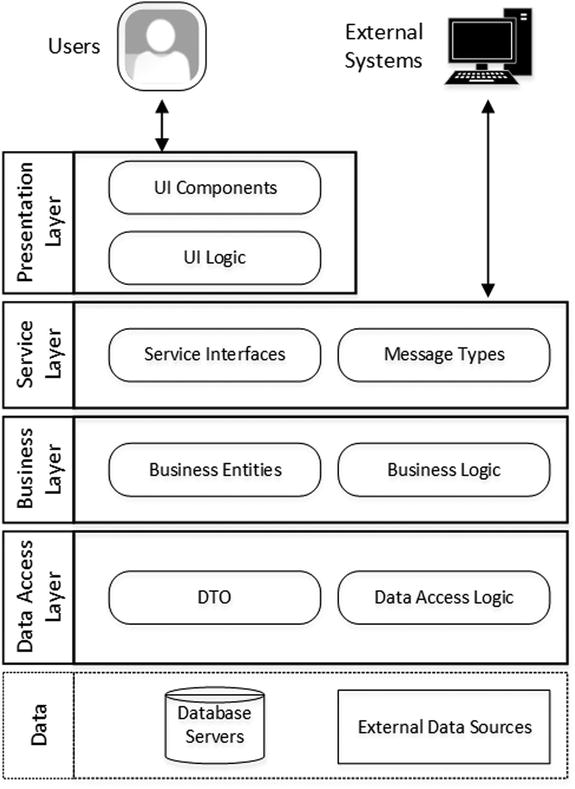
Figure 16-1. High-level system architecture diagram
Let’s look at layers in more detail.
- The Presentation Layer is responsible for system interaction with users. It includes UI elements and logic, which cover the navigation framework, multi-lingual and touch support, and quite a few other elements that control how the application looks and interacts with users.
- The Service Layer works as a gateway between the business layer and consumers, including users or external services. It allows the separation of the internal implementation of business logic from external applications and UI, which simplifies code refactoring when business requirements or processes change. The Service layer is usually present in large and complex systems with multiple components. However, it is often omitted in smaller systems.
- The Business Logic Layer contains the set of business objects that represent the business entities in the system, and it implements business logic and workflow. Usually, it is a good practice disconnecting business objects from the data using lightweight Data Transfer Objects (DTO) for communication. However, it is not uncommon to see business objects working with the data directly, especially in smaller systems.
- The Data Access Layeris responsible for dealing with the data. It serves as a gateway between the data sources and other subsystems, abstracting data location and schema. As already mentioned, it usually uses DTO objects to pass the data to or accept data from the Business Logic Layer. It is also entirely possible that the data access layer crosses the boundaries of the application code and uses stored procedures or database views as another layer of abstraction.
One of the key elements in this design is the separation of business objects from a database schema. The relational data model in the database is different from the object-oriented programming model by nature. Database tables should never be created with the goal of matching class definitions in the application.
![]() Note Even though SQL Server allows you to emulate pseudo-object oriented databases and use CLR user-defined types that store .Net business objects, it is an extremely bad idea. Doing so introduces supportability issues due to the inability to alter the type interfaces. It complicates access to the data and lowers system performance when compared to a classic relational implementation.
Note Even though SQL Server allows you to emulate pseudo-object oriented databases and use CLR user-defined types that store .Net business objects, it is an extremely bad idea. Doing so introduces supportability issues due to the inability to alter the type interfaces. It complicates access to the data and lowers system performance when compared to a classic relational implementation.
I would like to re-iterate a key point here. Physical separation of the layers in the system is less important than logical separation. The latter separation, when it is done the right way, reduces the cost of code refactoring by localizing the parts of the code that need to be changed.
Consider the situation where you need to change a data type of one of the columns in the database table. That change, in turn, requires modification of the application code that references the table. With layered architecture, the task is very simple, and all of the changes are localized in the data access and business logic layers. Even though other layers of the system could reference business objects and require some refactoring, you would be able to find references on the compilation stage, and the application would not compile due to data type mismatches. Last, but not least, all those changes can be done by the team of database and/or backend developers transparently to other teams and often deployed separately from other system components.
Spaghetti-like code that accesses the database from all over the place is another story. You will need to find all of the references to a particular database object in the code and change them. That situation is prone to errors, and it can lead to massive disruption for all of the developers on the team.
The choice of the data access technology affects other components in the system, and it should be done at the initial system design stage. Let’s look in depth at several common approaches.
Every client application that works with databases has a data access layer, even if it is not formally defined. In simple cases, the data access layer is implemented with regular DML queries against database tables. In more complex situations, client applications can work with the data through the layer of stored procedures and/or views, or they can utilize ORM frameworks and/or code generators.
As usual, the answer to the question “How should the data access layer be implemented?” is in “It Depends” category. Each approach comes with a set of benefits and limitations, and each has an implementation cost. Moreover, you can combine different techniques when needed. For example, systems that use ORM Frameworks can call stored procedures for performance-critical use cases.
We will discuss a few data access techniques commonly used in applications; however, it is important to talk about database connections and connection pooling as a first step.
It is expensive to establish a connection to SQL Server. It requires an application to parse the connection string information and establish communication with the server through a socket or name pipe. SQL Server needs to authenticate a client and perform a few other steps before the connection can be used.
However, it is also beneficial to avoid keeping open connections in applications. Each open connection becomes a SQL Server session and has a worker thread assigned to it. A large number of open connections can consume a large number of threads, which negatively affect SQL Server performance and can prevent other clients from connecting to it.
![]() Note We will discuss the SQL Server Execution Model in greater detail in Chapter 27, “System Troubleshooting.”
Note We will discuss the SQL Server Execution Model in greater detail in Chapter 27, “System Troubleshooting.”
Consider the typical ASP.Net MVC-based application that works with SQL Server. A busy application can handle dozens or even hundreds of users simultaneously. Internet Information Server (IIS) would create an instance of the controller class to handle each request. Obviously, you would like to avoid the overhead of establishing a new database connection every time a controller object is created.
Fortunately, SQL Server client libraries address this issue by utilizing connection pooling and caching active SQL Server connections. When an application closes or disposes of a connection, the client library returns it to the pool keeping the connection open rather than closing it. When the application requests the connection the next time, it is reusing an already active connection from the pool rather than opening a new one.
Connection pooling can significantly decrease the number of connections required for an application. In our web application example, every instance of the controller can access a database as part of the Action method, which processes requests; however, the database connection could be kept open just for a fraction of the method execution time. This will allow multiple objects to reuse connections without the overhead of opening them with every call.
Connection pooling is enabled by default and controlled by a connection string. Each unique connection string creates its own pool. By default, in ADO.Net, a connection pool is limited to 100 connections; however, you can change it with the Max Pool Size connection string property. You can also specify the minimum number of connections to keep in the pool with the Min Pool Size property and prevent providers from closing connections after a period of inactivity. Finally, you can disable connection pooling with the Pooling=false configuration setting if needed.
It is extremely important to dispose of connections properly in the client applications and return them to the pool. A client application would be unable to connect to SQL Server when the number of connections in the pool reaches its maximum size and all connections are currently utilized.
Listing 16-1 shows how connections need to be managed in ADO.Net. A connection is opened when a client needs it, kept active as little as possible, and disposed of afterwards.
Listing 16-1. Working with SqlConnections in ADO.Net
using (SqlConnection connection = new SqlConnection(connectionString))
{
connection.Open();
// Do work here; Keep connection open as little time as possible.
// SqlConnection.Dispose method will be called at the end of
// using block. It will close connection and return it to pool.
}
The SQL Client calls the sp_reset_connection system stored procedure when it reuses a connection from the pool. That procedure re-authenticates on SQL Server, making sure that the login credentials are still valid, and resets the connection context. There is one very important catch, however. The sp_reset_connection procedure does not reset the transaction isolation level used by the previous session. This behavior can introduce very unpleasant and hard to reproduce issues in client applications.
![]() Note We will discuss transaction isolation levels and locking behavior in greater detail in Chapter 17, “Lock Types.”
Note We will discuss transaction isolation levels and locking behavior in greater detail in Chapter 17, “Lock Types.”
Consider the situation where an application needs to generate a unique value for the primary key column. One of the common patterns in this case is a counters table that stores the name of the counter and the most recently generated key value. When a new unique key needs to be generated, the application can select and increment a specific counter value from the table using the SERIALIZABLE transaction isolation level to prevent other sessions from accessing it.
Unless the application resets the isolation level before closing the connection, the session that reuses the connection from the pool would run in SERIALIZABLE isolation level. This greatly increases blocking in the system, and it is very confusing and hard to troubleshoot. Even though you can detect blocking and see that the SERIALIZEABLE isolation level is in use, it is very hard to explain why it happens unless you are aware of such behavior.
![]() Tip Consider setting the desired transaction isolation level in each session after you open a connection to avoid this issue.
Tip Consider setting the desired transaction isolation level in each session after you open a connection to avoid this issue.
![]() Note You can read more about connection pooling at: http://msdn.microsoft.com/en-us/library/8xx3tyca.aspx.
Note You can read more about connection pooling at: http://msdn.microsoft.com/en-us/library/8xx3tyca.aspx.
Working with Database Tables Directly
Code that works with database tables directly is very common, especially in the small applications. This approach can be convenient at beginning of the development process when everything is fluid and the code is frequently refactored. Developers can change queries on the fly without any dependencies on either the database changes or other members of the team.
Unfortunately, this situation changes when the system is deployed to production. The queries are compiled into the application. If you detect errors or inefficiencies that cannot be addressed at the database level, you will need to recompile, retest, and redeploy the application to fix them. This could be very time consuming and resource intense.
While it is not always the case, direct access to database tables often negatively affects the separation of duties within the team. Every developer writes T-SQL code, which is not always an optimal solution. It also increases the chance of difficult-to-support spaghetti-like code when the data is accessed from different layers within the system.
SEPARATION OF DUTIES IN DEVELOPMENT TEAMS
It is impossible not to talk about separation of duties within development teams. Unfortunately, even nowadays when systems work with hundreds of gigabytes or even terabytes of data, you will rarely find teams with a dedicated database professional role. Every developer is expected to know SQL and to be able to write database code. Agile development teams usually focus on the functional items and do not spend much time on optimization and performance testing.
I use the term “database professional” rather than “database developer” on purpose. The line between database developers and administrators is very thin nowadays. It is impossible to develop efficient database code without a deep understanding of how SQL Server works under the hood.
It is expected that database administrators will perform index tuning and optimizations at a very late stage of development or even after production deployment. However, at that time, the code and database schema refactoring becomes very expensive and, frequently, leads to missed deadlines. It is always better and cheaper not to make mistakes in the first place, rather than address them later.
The team should always include database professionals when working on complex projects. These professionals should take ownership of the data access layer and database code. It does not necessarily mean that database developers should write all of the database code; however, they should make important database design decisions and review queries against critical tables with large amounts of data. This will help reduce development time and avoid costly mistakes during development.
One of the common problems frequently encountered in systems that query database objects directly is an excessive amount of dynamic and ad-hoc SQL. Queries are generated on the fly, and they frequently use constants rather than parameters. This negatively affects SQL Server performance by adding extra CPU load due to recompilations and increases plan cache memory usage. Moreover, it makes an application vulnerable to SQL Injection attacks.
![]() Note You can read about SQL Injection at: http://technet.microsoft.com/en-us/library/ms161953(v=sql.105).aspx.
Note You can read about SQL Injection at: http://technet.microsoft.com/en-us/library/ms161953(v=sql.105).aspx.
We will discuss recompilations and plan caching in greater detail in Chapter 26, “Plan Caching.”
Security is another important aspect to consider. When database tables are accessed directly, permissions should be managed at the objects or schema level. You cannot prevent users from accessing data from a subset of columns unless you are using column-level permissions, which introduce management overhead. With all that being said, it is completely normal to work with database tables directly, especially in small systems. Make sure that you have all of the database code separated in the data access layer and avoid using non-parameterized ad-hoc SQL.
Database views provide a basic level of abstraction, hiding database schema implementation details from the client applications. They help address some security issues; that is, you can grant permissions on views rather than tables, therefore, client applications would not have access to columns that are not included in the views.
Similar to database tables, queries that reference views from the client applications can be refactored on the fly without any database changes required. This works perfectly for queries that read data; however, updating data through views introduces a new set of challenges. As we discussed in Chapter 9, there is a set of restrictions that can prevent a view from being updateable. Alternatively, you can define INSTEAD OF triggers on views, although they work less efficiently as compared to updating tables directly.
Views allow you to perform some level of database schema refactoring transparently to client applications. For example, you can normalize or denormalize tables and hide the changes by adding or removing joins in the view. Those changes would be transparent to client applications as long as the view interface remains intact, and the view is still updateable if needed.
As you already know, this flexibility comes at a cost. Accessing data through views can introduce unnecessary joins, which contributes to SQL Server load. You should create underlying foreign key constraints and allow SQL Server to eliminate unnecessary joins when working with views.
![]() Tip SQL Server does not perform join elimination in the case of composite foreign key constraints. As a workaround, you can define views with outer joins when possible.
Tip SQL Server does not perform join elimination in the case of composite foreign key constraints. As a workaround, you can define views with outer joins when possible.
Using views for the sole purpose of abstracting database schema from client applications is not very beneficial due to the potential performance issues that views introduce. However, views can help if security is a concern. You should consider combining them with other techniques when modifying the data, however. As an example, you can use views to read the data using stored procedures for data modifications.
The approach of using stored procedures for data access has been historically favored by a large number of database professionals. It completely isolates client applications from the data, and it allows easy and transparent database schema and code refactoring during development and performance tuning. Similar to database views, stored procedures can provide an additional layer of security; you can grant users the ability to execute stored procedures without giving them access to the underlying tables.
Stored procedures reduce the load on SQL Server by reusing execution plans, which are typically cached. They can also solve the problem of inefficient execution plans due to implicit conversions when parameters and column data types do not match.
Listing 16-2 illustrates an example of this. As you know, nvarchar is not a SARGable predicate for the indexes on the varchar columns. It is very common for client applications to treat strings as unicode and generate nvarchar parameters when the parameter type has not been explicitly specified. Two calls of the sp_executesql procedure in the listing show typical calls from the ADO.Net client library.
Listing 16-2. Implicit data type conversion in the case of stored procedures and dynamic SQL
create table dbo.Customers
(
CustomerId int not null,
CustomerName varchar(64) not null,
PlaceHolder char(100),
constraint PK_Customers
primary key clustered(CustomerId)
);
create unique index IDX_Customers_Name
on dbo.Customers(CustomerName)
go
create proc dbo.SearchCustomerByName
(
@CustomerName varchar(64)
)
as
select CustomerId, CustomerName, PlaceHolder
from dbo.Customers
where CustomerName = @CustomerName
go
exec sp_executesql
@SQL =
N'select CustomerId, CustomerName, PlaceHolder
from dbo.Customers
where CustomerName = @CustomerName'
,@Params = N'@CustomerName nvarchar(64)'
,@CustomerName = N'Customer';
exec sp_executesql
@SQL = N'exec dbo.SearchCustomerByName @CustomerName'
,@Params = N'@CustomerName nvarchar(64)'
,@CustomerName = N'Customer';
As you can see in Figure 16-2, dynamic SQL generates the plan with a Clustered Index Scan, implicitly converting the CustomerName value from every row to nvarchar. A stored procedure, on the other hand, performs that conversion at the initial assignment of parameter values and generates a much more efficient execution plan with the Index Seek operation.
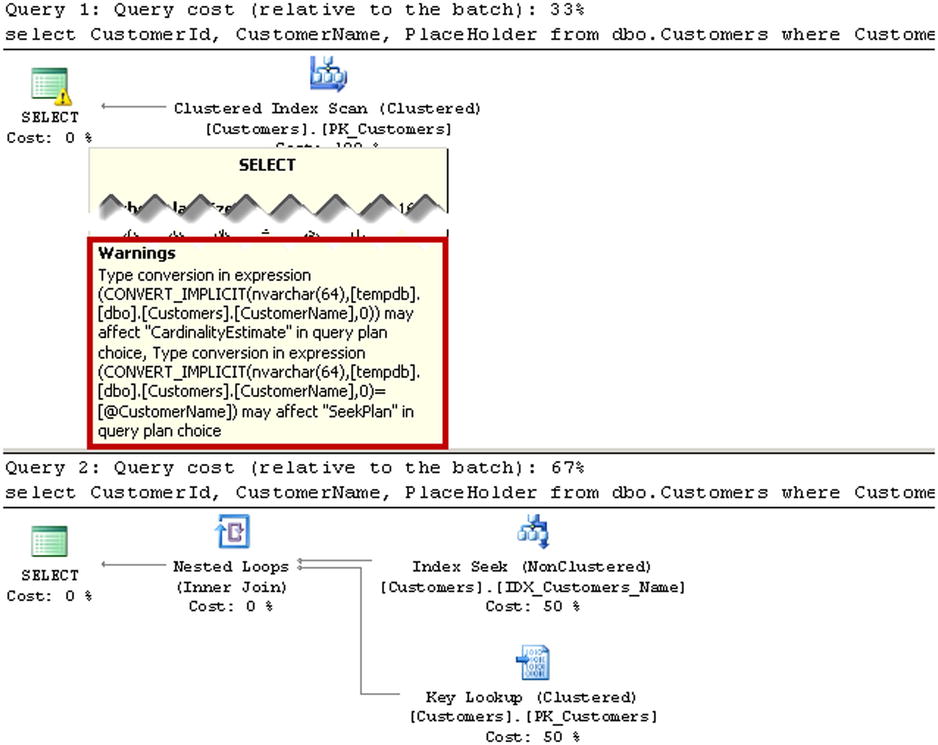
Figure 16-2. Execution plans of dynamic SQL and stored procedures
Unfortunately, stored procedures complicate client code refactoring. The data access layer code in the applications must be in sync with the stored procedure interface. Consider the situation where a stored procedure is used to read the data and you need to add another filter to the underlying query. This requires you to add another parameter to the stored procedure and change both the client and stored procedure code.
The extra complexity, however, is not necessarily a bad thing. It can work as a safety valve. The database professionals who are implementing this change can detect and take care of potential performance issues at the development stage rather than after a new version of the application is deployed to production.
Using stored procedures as part of the data access layer can be very advantageous if the team structure and development procedures allow it. The team should have dedicated database professionals who write and/or optimize stored procedures; however, this can slow down development due to the extra overhead it introduces during code refactoring.
Code Generators and ORM Frameworks
Code Generators and ORM (Object-Relational Mapping) Frameworks have never been particularly popular in the community of database professionals. Those frameworks were always targeted at developers, helping them to speed up the development process. ORM Frameworks also offered the ability to develop database-agnostic systems (on paper, at least), where you can transparently switch an application to a different database backend.
DATABASE-AGNOSTIC SYSTEMS: IS IT REALLY WORTH THE EFFORT?
The decision of making a system database-agnostic is very dangerous. The ability to support different database backends looks great in marketing materials, and it can open up business opportunities for Independent Software Vendors. Developers often argue that such benefits come for free with an ORM framework. That is not true, however. In fact, these benefits come at a high cost.
The ability to support multiple database backends requires you to work based on the lowest common denominator and use only features and data types that are supported in all database platforms and in the framework itself. You will not be able to take advantage of server-specific features, which can simplify and/or improve performance of some of the tasks. You will also need to test every supported database backend, which can greatly increase development times and cost.
Moreover, different database servers require different approaches during system optimization and performance tuning. Development and Product Support teams should have engineers with deep knowledge of the all supported backends to address those challenges.
Obviously, you can detect what database backend is in use and add backend-specific code to support some of the use-cases. However, this approach requires extra effort, and it increases development and support costs.
Finally, it is not uncommon to see examples of database-agnostic systems when most, if not all, installations utilize just a single backend. Customers tend to deploy a system to database servers, which are cheaper to acquire and maintain.
In the past, ORM frameworks did not generate high-quality SQL code. They did not handle query parameterization correctly nor generate efficient queries. However, they have become more mature and have begun to address some of the issues over the years.
The generated SQL code is still not perfect, and it greatly depends on the version of framework, the quality of entity model, and the developers’ experience and skills. Nevertheless, frameworks have become more and more popular nowadays as hardware costs continue to decline and the time to market and development costs are the most important factors in projects.
Frameworks allow application developers to work within familiar object-oriented models without diving deep into the database implementation and T-SQL code. Moreover, they significantly reduce code-refactoring time and make it possible to catch a large number of errors at the compilation stage.
Code generators and ORM frameworks change performance tuning and optimization workflow. It is very difficult, if even possible, to predict how SQL statements are generated, which often masks performance issues until the application is deployed to production.
There is very little that can be done to avoid it. Obviously, thorough testing can help to pinpoint inefficiencies; however, agile development teams rarely reserve enough time for that. In a large number of cases, the only available option is monitoring systems after they are deployed to production, refactoring problematic queries on the fly.
![]() Note We will discuss how to detect inefficient queries in Chapter 27, “System Troubleshooting.”
Note We will discuss how to detect inefficient queries in Chapter 27, “System Troubleshooting.”
Choosing the right framework is one of the most important decisions during the system design stage. Unfortunately, developers often make this decision by themselves without any database professional involvement. This is a very bad practice, which can lead to very serious performance issues if poor decisions are made.
You should always research how the framework works with the database backend. You need to read the documentation and online resources as well as run tests that capture and analyze SQL statements generated by the frameworks. The set of important questions to ask are outlined below.
What database platform features arenotsupported by the framework? As already mentioned, cross-platform support limits the feature set by using the lowest-common denominator principle. In some cases, missing platform-specific features could be a deal breaker. For example, neither of the major frameworks supports table-valued parameters, which could be a big limitation on systems that need to process and update large batches of data. The same is true for some SQL Server data types. Not all frameworks support sql_variant, date2, time2, datetime2, and datetimeoffset.
Does the framework allow you to run custom queries and stored procedures? Even though auto-generated code can be good enough in most cases, you should be able to execute queries and stored procedures from within the framework. This will allow you to address critical performance issues if the quality of auto-generated code is not sufficient.
How does the framework work with database transactions? At a bare minimum, you should be able to explicitly control transaction scope and isolation levels.
How does the framework work with parameters? Inefficient parameterization leads to unnecessary recompilations, increases the size of the plan cache, and negatively affects SQL Server performance. Frameworks, which do not parameterize queries, should never be used. Fortunately, that is rarely the case nowadays.
You should research, however, how the framework chooses parameter data types and length, especially in the case of strings. You should be able to control what data type to choose: varchars or nvarchars. Data length is another important factor. Unfortunately, there are plenty of frameworks that generate it based on the actual value rather than the column size. For example, City=N'New York' would generate nvarchar(8) and City=N'Paris' would generate nvarchar(5) parameters. Queries with those parameters will be recompiled and have plans cached separately from each other. Obviously, it is better to choose a framework that can generate parameter length based on the actual size of the data column or allow you to specify it.
Does the framework allow you to load a subset of the attributes in the Entity Object? As we discussed in Chapter 1, selecting unnecessary columns adds extra load to SQL Server and makes query optimization more complicated, especially when data is stored in ROW_OVERFLOW or LOB pages. It is beneficial to use frameworks that support the partial load of entity objects to avoid such problems. As a workaround, you can create separate entity objects for different use-cases. For example, Customer class can include all customer attributes and CustomerInfo class can provide small set of attributes to display in grid control.
The above list is by no means complete; however, it can work as a good starting point. Let’s look at Microsoft Entity Framework 6 and perform this analysis.
Analyzing Microsoft Entity Framework 6
As a first step, let’s create the set of tables as shown in Listing 16-3.
Listing 16-3. Test tables
create table dbo.Customers
(
CustomerId int not null identity(1,1),
FirstName nvarchar(255) null,
LastName nvarchar(255) null,
Email varchar(254) null,
LastPurchaseDate datetime2(0) null,
CreditLimit int null,
Photo varbinary(max) null,
Ver timestamp not null,
constraint PK_Customers
primary key clustered(CustomerId)
);
create table dbo.Orders
(
OrderId int not null identity(1,1),
CustomerId int not null,
OrderNo varchar(32) not null,
constraint PK_Orders
primary key clustered(OrderId),
constraint FK_Orders_Customers
foreign key(CustomerId)
references dbo.Customers(CustomerId)
);
create index IDX_Orders_Customers on dbo.Orders(CustomerId);
create table dbo.OrderItems
(
OrderId int not null,
OrderItemId int not null identity(1,1),
Qty float not null,
Price money not null,
constraint PK_OrderItems
primary key clustered(OrderId, OrderItemID),
constraint FK_OrderItems_Orders
foreign key(OrderId)
references dbo.Orders(OrderId)
);
Listing 16-4 shows the Entity Framework model that corresponds to the database schema.
Listing 16-4. Entity Framework model
public class Customer
{
public Customer()
{
Orders = new HashSet<Order>();
}
public int CustomerId { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public string Email { get; set; }
public int? CreditLimit { get; set; }
public byte[] Photo { get; set; }
public byte[] Ver { get; set; }
public virtual ICollection<Order> Orders { get; set; }
}
public class Order
{
public Order()
{
Items = new HashSet<OrderItem>();
}
public int OrderId { get; set; }
public int CustomerId { get; set; }
public virtual Customer Customer { get; set; }
public string OrderNo { get; set; }
public virtual ICollection<OrderItem> Items { get; set; }
}
public class OrderItem
{
public int OrderId { get; set; }
public virtual Order Order { get; set; }
public int OrderItemId { get; set; }
public Double Qty { get; set; }
public Decimal Price { get; set; }
}
Every major ORM framework supports two design patterns, such as a Repository Pattern and Unit of Work Pattern.
A Repository Pattern abstracts data from business entities, making it agnostic to the data source. The business layer does not know the location of the data nor the type of the data storage. For example, data can live in the database or be provided by a set of web services. A Repository Pattern establishes a mapping between the business entities and the underlying data structures, and it transforms requests from the applications to data access methods, for example, database queries or web service method calls.
![]() Note You can read more about Repository Patterns at: http://msdn.microsoft.com/en-us/library/ff649690.aspx.
Note You can read more about Repository Patterns at: http://msdn.microsoft.com/en-us/library/ff649690.aspx.
A Unit of Work Pattern is responsible for tracking all of the changes in business objects and saving them into the data sources. It performs transaction management on the data side, handles concurrency issues, and is responsible for all aspects of data modifications in the system.
The functionality of the both patterns is implemented in the DbContext class of Entity Framework, which manages the entity objects during run time. Applications need to inherit the class from DbContext and initialize the data mapping required for the Repository Pattern. Every time changes need to be applied to the database, applications should call the SaveChanges() method of DbContext class.
![]() Note You can read more about the DbContext class, including its lifetime considerations, at:http://msdn.microsoft.com/en-us/data/jj729737.aspx.
Note You can read more about the DbContext class, including its lifetime considerations, at:http://msdn.microsoft.com/en-us/data/jj729737.aspx.
The code that works with DbContext class looks similar to the code that uses the ADO.Net SqlConnection class. There is a major difference in how database connections are handled, however. The SqlConnection class requires you to explicitly open and close connections. The DbContext class, on the other hand, implicitly opens and closes connections when corresponding objects need to access the data. In the example shown in Listing 16-5, Entity Framework opens a database connection at the beginning and closes it at the end of the context.Customers.ToLists() method call. After that, a connection would be opened and closed every time the application loads orders for a specific customer; that is, during each foreach (var order in context.Orders.Where(o => o.Customer == customer.Id)) call. This behavior can introduce the significant overhead of establishing database connections if connection pooling is not enabled. The EFDbContext class in the example in Listing 16-5 is inherited from the DbContext class.
Listing 16-5. Working with DbContext class
using (var context = new EFDbContext())
{
var customers = context.Customers.ToList();
foreach (var customer in customers)
{
Trace.WriteLine(string.Format(
"Customer Id: {0}", customer.CustomerId));
foreach (var order in context.Orders.Where(o => o.Customer == customer.Id)) Trace.WriteLine(string.Format(
"Customer Id: {0}", customer.CustomerId));
}
}
![]() Note You can read more about connection management in Entity Framework at: http://msdn.microsoft.com/en-us/data/dn456849.
Note You can read more about connection management in Entity Framework at: http://msdn.microsoft.com/en-us/data/dn456849.
You can explicitly control transactions in Entity Framework by using either .Net TransactionScope or Entity Framework DbContextTransaction classes. Listing 16-6 illustrates the latter approach. It is also worth mentioning that explicit transactions force Entity Framework to keep a database connection open for the duration of the transaction.
Listing 16-6. Working with the DbContextTransaction class
using (var context = new EFDbContext())
{
using (var transaciton =
context.Database.BeginTransaction(IsolationLevel.ReadCommitted))
{
try
{
context.SaveChanges();
transaciton.Commit();
}
catch
{
transaciton.Rollback();
}
}
}
![]() Important You should always specify transaction isolation level when you work with a TransactionScope class. It uses a SERIALIZABLE isolation level by default unless you override it.
Important You should always specify transaction isolation level when you work with a TransactionScope class. It uses a SERIALIZABLE isolation level by default unless you override it.
![]() Note You can read more about transaction management in Entity Framework at: http://msdn.microsoft.com/en-us/data/dn456843.
Note You can read more about transaction management in Entity Framework at: http://msdn.microsoft.com/en-us/data/dn456843.
Executing Stored Procedures and Queries
You can run queries and stored procedures in Entity Framework by using the ExecuteSqlCommand method of the Database class, accessing it through the property exposed by the DbContext class. This extremely important feature allows you to avoid auto-generated SQL in performance-critical use cases.
Listing 16-7 shows you how to call a stored procedure within an Entity Framework context.
Listing 16-7. Executing a stored procedure in Entity Framework
using (var context = new EFDbContext())
{
context.Database.ExecuteSqlCommand("exec dbo.ReconcileOrder @CustomerId",
new SqlParameter("@CustomerId", SqlDbType.Int) {Value = 50});
}
The ability to execute queries is also beneficial during deletion of multiple rows when foreign key constraints are involved. We will review such an example later in the chapter.
Entity Framework supports partial loading when a subset of the entity attributes are selected. Listing 16-8 demonstrates such an example. The CustNames is the list of anonymous type objects with two attributes: FirstName and LastName.
Listing 16-8. Partial load: Client code
var custNames = context.Customers
.Where(t => t.FirstName == "John")
.Select(t => new{t.FirstName,t.LastName});
The SQL generated by Entity Framework selects only two columns, as shown in Listing 16-9.
Listing 16-9. Partial load: Generated SQL
SELECT
1 AS [C1],
[Extent1].[FirstName] AS [FirstName],
[Extent1].[LastName] AS [LastName]
FROM [dbo].[Customers] AS [Extent1]
WHERE N'John' = [Extent1].[FirstName]
As you may have already noticed, classes in our entity model reference each other. For example, Customer and OrderItems are defined as the properties in the Orders class. By default, Entity Framework uses lazy loading and does not load them until those attributes are requested by the client.
Lazy loading improves the performance of the system because attributes are not loaded unless the application needs them. However, it can make objects logically inconsistent, because data is loaded at different times. Consider the situation where an application uses lazy loading to load a list of OrderItems for an Order. If another user changed the Order and added another OrderItem row, the loaded list would be inconsistent with the Order object loaded previously by the application.
You can disable lazy loading through the Configuration.LazyLoadingEnabled property or, alternatively, you can force Entity Framework to load all of the attributes with the object. Listing 16-10 shows such an example. The code loads the Order object with a specific OrderId including Customer and Items attributes.
Listing 16-10. Loading attributes with the main object
var order = context.Orders.Include("Customer").Include("Items")
.Where(t => t.OrderId == 1).First();
Even though it looks very simple in the client code, the SELECT statement generated by Entity Framework could surprise you. Listing 16-11 demonstrates this occurrence.
Listing 16-11. Loading attributes with main object: Generated SQL
SELECT
[Project1].[OrderId] AS [OrderId],
[Project1].[CustomerId] AS [CustomerId],
[Project1].[OrderNo] AS [OrderNo],
[Project1].[CustomerId1] AS [CustomerId1],
[Project1].[FirstName] AS [FirstName],
[Project1].[LastName] AS [LastName],
[Project1].[Email] AS [Email],
[Project1].[LastPurchaseDate] AS [LastPurchaseDate],
[Project1].[CreditLimit] AS [CreditLimit],
[Project1].[Photo] AS [Photo],
[Project1].[C1] AS [C1],
[Project1].[OrderItemId] AS [OrderItemId],
[Project1].[OrderId1] AS [OrderId1],
[Project1].[Qty] AS [Qty],
[Project1].[Price] AS [Price]
FROM (
SELECT
[Limit1].[OrderId] AS [OrderId],
[Limit1].[CustomerId1] AS [CustomerId],
[Limit1].[OrderNo] AS [OrderNo],
[Limit1].[CustomerId2] AS [CustomerId1],
[Limit1].[FirstName] AS [FirstName],
[Limit1].[LastName] AS [LastName],
[Limit1].[Email] AS [Email],
[Limit1].[LastPurchaseDate] AS [LastPurchaseDate],
[Limit1].[CreditLimit] AS [CreditLimit],
[Limit1].[Photo] AS [Photo],
[Extent3].[OrderItemId] AS [OrderItemId],
[Extent3].[OrderId] AS [OrderId1],
[Extent3].[Qty] AS [Qty],
[Extent3].[Price] AS [Price],
CASE
WHEN ([Extent3].[OrderItemId] IS NULL)
THEN CAST(NULL AS int)
ELSE 1
END AS [C1]
FROM (
SELECT TOP (1)
[Extent1].[OrderId] AS [OrderId],
[Extent1].[CustomerId] AS [CustomerId1],
[Extent1].[OrderNo] AS [OrderNo],
[Extent2].[CustomerId] AS [CustomerId2],
[Extent2].[FirstName] AS [FirstName],
[Extent2].[LastName] AS [LastName],
[Extent2].[Email] AS [Email],
[Extent2].[LastPurchaseDate] AS [LastPurchaseDate],
[Extent2].[CreditLimit] AS [CreditLimit],
[Extent2].[Photo] AS [Photo]
FROM [dbo].[Orders] AS [Extent1]
INNER JOIN [dbo].[Customers] AS [Extent2] ON
[Extent1].[CustomerId] = [Extent2].[CustomerId]
WHERE 1 = [Extent1].[OrderId]
) AS [Limit1]
LEFT OUTER JOIN [dbo].[OrderItems] AS [Extent3] ON
[Limit1].[OrderId] = [Extent3].[OrderId]
) AS [Project1]
ORDER BY [Project1].[OrderId] ASC, [Project1].[CustomerId1] ASC,
[Project1].[C1] ASC
Keeping the supportability aspect out of discussion, you can see that this query is inefficient. Rather than reading Orders and OrderItems data separately from each other, Entity Framework joined all of the tables together including the Orders and Customers attributes with every OrderItems row. This behavior can introduce significant overhead to SQL Server and the network, especially if some columns contain large amounts of data. The Photo column in the Customers table is a perfect example of such a situation.
Parameterization
Correct parameterization is, perhaps, the most important factor that contributes to the success of the framework. As I already mentioned, incorrectly parameterized queries add to the CPU load on the server due to recompilations, increases the size of plan cache, and results in inefficient execution plans due to the implicit data type conversions. It is extremely important to understand how frameworks handle parameters and to avoid inefficiencies whenever possible.
There are several important questions related to parameterization, such as when the framework uses parameters and how it chooses parameter data types and length.
Listing 16-12 generates several queries using the integer Customer.CreditLimit column in the predicate.
Listing 16-12. Parameterization and data types: C# code
/* Using constant */
var q = context.Customers.Where(t => t.CreditLimit > 200)
.Select(t => t.FirstName);
/* Using Int64 */
long i64 = 200;
var q = context.Customers.Where(t => t.CreditLimit > i64)
.Select(t => t.FirstName);
/* Using Int */
int i32 = 200;
var q = context.Customers.Where(t => t.CreditLimit > i32)
.Select(t => t.FirstName);
/* Using byte */
byte b = 200;
var q = context.Customers.Where(t => t.CreditLimit > b)
.Select(t => t.FirstName);
Listing 16-13 shows auto-generated SQL. As you can see, constant values from the client code are not parameterized. In the case of variables, Entity Framework uses either the data type of the variables or the property from the class, choosing the type with the larger range of domain values and precision.
Listing 16-13. Parameterization and data types: Generated SQL
-- Constant
SELECT [Extent1].[FirstName] AS [FirstName]
FROM [dbo].[Customers] AS [Extent1]
WHERE [Extent1].[CreditLimit] > 200 '
-- Int64
exec sp_executesql N'SELECT
[Extent1].[FirstName] AS [FirstName]
FROM [dbo].[Customers] AS [Extent1]
WHERE [Extent1].CreditLimit > @p__linq__0'
,N'@p__linq__0 bigint',@p__linq__0=200
-- Int32
exec sp_executesql N'SELECT
[Extent1].[FirstName] AS [FirstName]
FROM [dbo].[Customers] AS [Extent1]
WHERE [Extent1].CreditLimit > @p__linq__0'
,N'@p__linq__0 int',@p__linq__0=200
-- byte
exec sp_executesql N'SELECT
[Extent1].[FirstName] AS [FirstName]
FROM [dbo].[Customers] AS [Extent1]
WHERE [Extent1].CreditLimit > @p__linq__0'
,N'@p__linq__0 int',@p__linq__0=200
As with all current development environments, .Net treats strings as unicode and generates nvarchar parameters by default. Listing 16-14 demonstrates this behavior.
Listing 16-14. String parameters
/* C# code */
string email = "[email protected]";
var q = context.Customers.Where(t => t.Email == email)
.Select(t => t.FirstName);
/* Generated SQL */
exec sp_executesql N'SELECT
[Extent1].[FirstName] AS [FirstName]
FROM [dbo].[Customers] AS [Extent1]
WHERE [Extent1].[Email] = @p__linq__0'
,N'@p__linq__0 nvarchar(4000)',@p__linq__0=N'[email protected]'
As you know, nvarchar parameters lead to implicit data type conversions and are not SARGable for indexes on the varchar column. SQL Server would not be able to utilize Index Seek operations on such indexes, which lead to suboptimal execution plans.
There are two ways to address such a situation. First, you can use the EntityFunctions.AsNonUnicode function as part of the call, as shown in Listing 16-15.
Listing 16-15. Forcing Entity Framework to generate a varchar parameter
string email = "[email protected]";
var q = context.Customers
.Where(t => t.Email == EntityFunctions.AsNonUnicode(email))
.Select(t => t.FirstName);
![]() Tip Make sure to use the EntityFunction class defined in the System.Data.Entity.Core.Objects namespace. There is a different class with the same name defined in the System.Data.Objects namespace.
Tip Make sure to use the EntityFunction class defined in the System.Data.Entity.Core.Objects namespace. There is a different class with the same name defined in the System.Data.Objects namespace.
Alternatively, you can let Entity Framework know about the non-unicode data type of the column by explicitly specifying mapping using the Fluent API, as shown in Listing 16-16. This approach allows you to avoid calling the AsNonUnicode function in every method call.
Listing 16-16. Setting up mapping in the model
/* Setting up mapping in configuration */
internal class CustomerMap : EntityTypeConfiguration<Customer>
{
public CustomerMap()
{
Property(t => t.Email).IsUnicode(false);
}
}
/* Adding configuration to context class by overriding the method */
public class EFDbContext : DbContext
{
protected override void OnModelCreating(DbModelBuilder modelBuilder)
{
base.OnModelCreating(modelBuilder);
modelBuilder.Configurations.Add(new CustomerMap());
}
}
For queries that select data, Entity Framework generates string parameters as nvarchar(4000) or varchar(8000) when the length of string does not exceed 4000 or 8000 bytes respectively. For larger strings, Entity Framework generates nvarchar(max) or varchar(max) parameters. For queries that modify data, the length of the parameters matches the properties’ length defined in the model.
IN Lists
One of the areas where Entity Framework does not perform well is working with lists of rows. Let’s try to load multiple customers based on the list of their CustomerId values. Listing 16-17 shows the client code and generated SQL for doing this.
Listing 16-17. Loading a list of rows
/*C# Code*/
var list = new List<int>();
for (int i = 1; i < 100; i++)
list.Add(i);
using (var context = new EFDbContext())
{
var q = context.Customers.Where(t => list.Contains(t.CustomerId))
.Select(t => new {t.CustomerID, t.FirstName, t.LastName});
var result = q.ToList();
}
/* Generated SQL */
SELECT
[Extent1].[CustomerId] AS [CustomerId],
[Extent1].[FirstName] AS [FirstName],
[Extent1].[LastName] AS [LastName]
FROM [dbo].[Customers] AS [Extent1]
WHERE [Extent1].[CustomerId] IN (1, 2, 3, 4, 5, 6, 7, 8, 9, 10,
11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26,
27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42,
43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58,
59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74,
75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90,
91, 92, 93, 94, 95, 96, 97, 98, 99)'
There are two problems with this code. First, SQL Server does not parameterize the statement, which, as we already discussed, adds the load to SQL Server. Moreover, SQL Server does not work efficiently with large IN lists. Those statements take a longer time to compile, execution plans consume large amounts of memory, and they are not always efficient.
Unfortunately, there is very little that can be done in this scenario. Loading rows one by one or in small batches is not efficient either. The best approach would be to execute a custom SQL Statement using table-valued parameters, and to create objects manually afterwards. However, this requires a large amount of coding. With all that being said, Entity Framework is not the best choice for systems that require batch data processing.
Deletions
Deleting data from within Entity Framework is a tricky process. While it is easy to write the code that performs a deletion, auto-generated SQL code is not ideal. Let’s look at the example shown in Listing 16-18, which deletes a row in the code.
Listing 16-18. Deleting Data: Client code
int customerID = 10;
var customer = context.Customers.Find(customerID);
context.Customers.Remove(customer);
context.SaveChanges();
Unfortunately, this approach forces Entity Framework to load the Customer object before deletion. It leads to an additional SELECT statement, as shown in Listing 16-19.
Listing 16-19. Deleting Data: Generated SQL
exec sp_executesql N'SELECT TOP (2)
[Extent1].[CustomerId] AS [CustomerId],
[Extent1].[FirstName] AS [FirstName],
[Extent1].[LastName] AS [LastName],
[Extent1].[Email] AS [Email],
[Extent1].[LastPurchaseDate] AS [LastPurchaseDate],
[Extent1].[CreditLimit] AS [CreditLimit],
[Extent1].[Photo] AS [Photo],
[Extent1].[Ver] AS [Ver]
FROM [dbo].[Customers] AS [Extent1]
WHERE [Extent1].[CustomerId] = @p0',N'@p0 int',@p0=10
exec sp_executesql N'DELETE [dbo].[Customers]
WHERE ([CustomerId] = @0)',N'@0 int',@0=10
You can address this problem by creating a dummy Customer object and attaching it to the model, as shown in Listing 16-20.
Listing 16-20. Deleting Data: Using dummy object
var customer = new Customer();
customer.CustomerId = 10;
context.Customers.Attach(customer);
context.Customers.Remove(customer);
context.SaveChanges();
Unfortunately, the situation becomes more complicated in cases where referential integrity is involved. Unless foreign key constraints are defined with an ON DELETE CASCADE action, deletion of the dummy referenced object would trigger a foreign key violation exception. You can attach dummy referencing objects to the model to avoid this, but it requires you to know their key values to reference them.
The best way to address this problem is to run DELETE statements against the database directly. Listing 16-21 shows you how to delete the Order and all corresponding OrderItems rows from the database.
Listing 16-21. Deleting Data: Executing DELETE statements against the database
int orderId = 50
context.Database.ExecuteSqlCommand(
@"delete from OrderItems where OrderId = @OrderId;
delete from Orders where OrderId = @OrderId",
new SqlParameter("OrderId", SqlDbType.Int) { Value = orderId });
Finally, if you already have an Order object loaded into the model, you can remove it after deletion with the code shown in Listing 16-22.
Listing 16-22. Deleting Data: Removing an object from the model
context.Orders.Remove(order);
context.Entry(order).State = System.Data.Entity.EntityState.Detached;
Preventing situations where multiple users update the same data, overriding each other’s changes, is the one of the most common business requirements you can find in systems. This is especially important with Entity Framework, where UPDATE statements exclude columns that have not been modified in the object.
Consider the situation when two users work with the same order object simultaneously. Let’s assume that one user changes an article in OrderItem, which, in turn, changes its price and saves it to the database. At the same time, another user changes the price in his or her in-memory OrderItem object without changing the article. When the data is saved into the database, only the price column data would be updated, which makes the row data logically inconsistent.
A common way to address these issues is by adding a timestamp column to the database table. SQL Server changes its value every time a row is modified and, therefore, you can detect if the row has been changed after you loaded it.
Entity Framework supports this technique. You can mark the class property as a concurrency token in the mapping class similar to how we did it with the non-unicode string attribute in Listing 16-16. Listing 16-23 shows you how to set this property.
Listing 16-23. Setting the concurency token property
/* Setting up mapping in configuration */
internal class CustomerMap : EntityTypeConfiguration<Customer>
{
public CustomerMap()
{
Property(t => t.Email).IsUnicode(false);
Property(t => t.Ver)
.IsConcurrencyToken()
.HasDatabaseGeneratedOption(
DatabaseGeneratedOption.Computed
);
}
}
/* Adding configuration to context class by overriding the method */
public class EFDbContext : DbContext
{
protected override void OnModelCreating(DbModelBuilder modelBuilder)
{
base.OnModelCreating(modelBuilder);
modelBuilder.Configurations.Add(new CustomerMap());
}
}
Listing 16-24 shows the code that updates the Customer object and auto-generated SQL. As you can see, Entity Framework adds another predicate to the where clause of the UPDATE statement, followed by the SELECT statement that provides the new Ver value to the client. The @@ROWCOUNT predicate guarantees that no data will be returned to the client if the row was modified by another user. Finally, the client code detects objects that were modified by other users and reloads them.
Listing 16-24. Updating the Customer object
/* C# code */
customer.CreditLimnit = 5000;
customer.Modified = DateTime.Now;
try
{
context.SaveChanges();
}
catch (DbUpdateConcurrencyException ex)
{
// Notify User
foreach (var item in ex.Entries)
item.Reload();
}
/* Generated SQL*/
exec sp_executesql N'UPDATE [dbo].[Customers]
SET [CreditLimit] = @0, [Modified] = @1
WHERE (([CustomerId] = @2) AND ([Ver] = @3))
SELECT [Ver]
FROM [dbo].[Customers]
WHERE @@ROWCOUNT > 0 AND [CustomerId] = @2',
N'@0 int,@1 datetime2(7),@2 int,@3 varbinary(max)'
,@0=5000,@1='2014-03-02 12:52:00.0149354',@2=10,@3=0x0000000000000BCE
Conclusions
With the exception of batch processing, Entity Framework does a decent job with parameterization as long as the model has been accurately defined. It does not parameterize arrays or constants used in predicates. However, those use cases are rare in production systems.
Entity Framework allows you to control transactions similar to other client libraries. Moreover, it provides you with an ability to execute custom queries and stored procedures, and it addresses performance-critical use cases.
You should always remember to specify non-unicode attributes in the model to avoid generating nvarchar parameters when referencing varchar columns. For updateable entities, you should specify a primary key and the length of the properties/data columns, and you should also make sure that deletion operations do not introduce additional overhead by pre-loading the objects.
Unfortunately, the generation of easy-to-understand SQL code has never been a top priority for the framework, which has been designed to simplify and speed up client application development. Generated SQL statements are massive and very hard to read. This makes query analysis and optimization difficult and time consuming.
It is also worth mentioning that SQL generators are the hidden part of frameworks and can change over time. It is important to re-evaluate the quality of SQL code when upgrading to a new version of the framework.
Summary
The architecture of a modern complex system should utilize a layered approach, separating subsystems from each other. This separation improves the supportability of the code, simplifies refactoring, and allows multiple developers to work on the project in parallel.
The data access layer contains the code that works with the database backend. Various approaches can be used for data access layer implementation. Each approach has both advantages and disadvantages that need to be evaluated during the system architecture stage.
The boundaries of the data access layer can cross client code and utilize database views and stored procedures when appropriate. It is advantageous to have dedicated database professionals on the team who can take care of designing and developing data access code. This will help to avoid costly mistakes and code refactoring at a very late development stage or after deployment to production.
ORM Frameworks and Code Generators have become more and more popular. While they simplify and speed up client application development, they can introduce performance issues in systems due to the suboptimal SQL code that they generate. You should perform an analysis of framework functional and generated SQL code when choosing a framework for a system.
SQL Server client libraries utilize connection pooling to keep SQL Server connections open. Client applications reuse connections from the pool, which improves system performance. It is important to release connections back to the pool as fast as possible by closing or disposing of them in the client applications.
Reusing connections from the pool does not reset the transaction isolation level set by the previous session. You should reset the transaction isolation level before returning a connection to the pool, or after you open a connection.