
![]()
It is impossible to modify data in tables with nonclustered columnstore indexes. This limitation is one of the major factors preventing their widespread adoption in SQL Server 2012. SQL Server 2014 addresses this problem by introducing updatable clustered columnstore indexes (CCI).
This chapter provides an overview of the internal structure of CCI and discusses best practices for data loading and maintenance of them.
Internal Structure of Clustered Columnstore Indexes
A clustered columnstore indexis a single instance of the data in a table. Tables with clustered columnstore indexes cannot have any other indexes defined—neither B-Tree nor nonclustered columnstore indexes.
Clustered columnstore indexes also have several other limitations. You cannot make them UNIQUE, nor can you define triggers on a table. A table cannot have foreign key constraints, nor can foreign keys defined in other tables reference it. Some other features, such as Replication, Change Tracking, and Change Data Capture are not supported either.
You can create a clustered columnstore index with the CREATE CLUSTERED COLUMNSTORE INDEX command. You do not need to specify any columns in the statement—the index will include all table columns. This adds further restrictions on the column data types, as we have discussed in the previous chapter.
Internal Structure
Clustered columnstore indexes use the same storage format as nonclustered columnstore indexes, storing columnstore data in row groups. However, they have two additional elements to support data modifications. The first is delete bitmap, which indicates what rows were deleted from a table. The second structure is delta store, which includes newly inserted rows. Both delta store and delete bitmap use the B-Tree format to store data.
![]() Note SQL Server’s use of delete bitmaps and delta stores is transparent to users, which makes the relevant terminology confusing. You will often see delta stores referenced as another row group in documentation and technical articles. Moreover, a delete bitmap is often considered a part of a delta store and/or row groups.
Note SQL Server’s use of delete bitmaps and delta stores is transparent to users, which makes the relevant terminology confusing. You will often see delta stores referenced as another row group in documentation and technical articles. Moreover, a delete bitmap is often considered a part of a delta store and/or row groups.
To avoid confusion, I will use the following terminology in this chapter. A term row group references data stored in a column-based storage format. I will explicitly reference delta stores and delete bitmaps as two separate sets of internal objects as needed.
Figure 35-1 illustrates the structure of a clustered columnstore index in a table that has two partitions. Each partition can have a single delete bitmap and multiple delta stores. This structure makes each partition self-contained and independent from other partitions, which allows you to perform a partition switch on tables that have clustered columnstore indexes defined.

Figure 35-1. Clustered columnstore index structure
It is worth noting that delete bitmaps and delta stores are created on-demand. For example, a delete bitmap would not be created unless some of the rows in the row groups were deleted.
Every time you delete a row that is stored in a row group (not in a delta store), SQL Server adds information about the deleted row to the delete bitmap. Nothing happens to the original row. It is still stored in a row group. However, SQL Server checks the delete bitmap during query execution, excluding deleted rows from the processing.
As already mentioned, when you insert data into a columnstore index, it goes into a delta store, which uses a B-Tree format. Updating a row that is stored in a row group does not change the row data either. Such an update triggers the deletion of a row, which is, in fact, insertion to a delete bitmap, and insertion of a new version of a row to a delta store. However, any data modifications of the rows in a delta store are done the same way as in regular B-Tree indexes by updating and deleting actual rows there. You will see one such example later in this chapter.
Each delta store can be either in open or closed state. Open delta stores accept new rows and allow modifications and deletions of data. SQL Server closes a delta store when it reaches 1,048,576 rows, which is the maximum number of rows that can be stored in a row group. Another SQL Server process, called tuple mover, runs every five minutes and converts closed delta stores to row groups that store data in a column-based storage format.
Alternatively, you can force the conversion of closed delta stores to row groups by reorganizing an index with the ALTER INDEX REORGANIZE command. While both approaches achieve the same goal of converting closed delta stores to row groups, their implementation is slightly different. Tuple mover is a single-threaded process that works in the background, preserving system resources. Alternatively, index reorganizing runs in parallel using multiple threads. That approach can significantly decrease conversion time at a cost of extra CPU load and memory usage.
![]() Note We will discuss clustered columnstore index maintenance in more detail later in this chapter.
Note We will discuss clustered columnstore index maintenance in more detail later in this chapter.
Neither tuple mover nor index reorganizing prevent other sessions from inserting new data into a table. New data will be inserted into different and open delta stores. However, deletions and data modifications would be blocked for the duration of the operation. In some cases, you may consider forcing index reorganization manually to reduce execution and, therefore, locking time.
You can examine the state of row groups and delta stores with the sys.column_store_row_groups view. Figure 35-2 illustrates the output of this view, which returns the combined information of all columnstore index objects. Rows in OPEN or CLOSED state correspond to delta stores. Rows in COMPRESSED state correspond to row groups with data in a column-based storage format. Finally, the deleted_rows column provides statistics about deleted rows stored in a delete bitmap.

Figure 35-2. sys.column_store_row_groups view output
As you can see, the second row in a view output from Figure 35-2 shows the closed delta store that has yet to be picked up by the tuple mover process. The situation will change after the tuple mover process converts the closed delta store to a row group on its next scheduled run. Figure 35-3 shows the output from a view after this occurs. It is worth noting that the row_group_id of the converted row group changed. Tuple mover created a new row group, dropping the closed delta store afterwards.

Figure 35-3. sys.column_store_row_groups view output after tuple mover process execution
Data Load
Two different types of data load can insert data into a columnstore index. The first type is bulk insert, which is used by the BULK INSERT operator, bcp utility, and other applications that utilize the bulk insert API. The second type, called trickle inserts, are regular INSERT operations that do not use the bulk insert API.
Bulk insert operations provide the number of rows in the batch as part of the API call. SQL Server inserts data into newly created row groups if that size exceeds a threshold of about 100,000 rows. Depending on the size of the batch, one or more row groups can be created and some rows may be stored in delta store.
Table 35-1 illustrates how data from the different batches are distributed between row groups and delta stores.
Table 35-1. Batch size and data distribution during bulk insert
Batch size |
Rows added to row groups |
Rows added to delta store |
|---|---|---|
99,000 |
0 |
99,000 |
150,000 |
150,000 |
0 |
1,048,577 |
1,048,576 |
1 |
2,100,000 |
1,048,576; 1,048,576 |
2,848 |
2,250,000 |
1,048,576; 1,048,576; 152,848 |
0 |
SQL Server loads columnstore data to memory on a per-segment basis and, as you remember, segments represent data for a single column in a row group. It is more efficient to load and process a smaller number of fully populated segments as compared to a large number of partially populated segments. An excessive number of partially populated row groups negatively affect SQL Server performance. I will provide an example of this later in the chapter.
If you bulk load data to a table with a clustered columnstore index, you will achieve the best results by choosing a batch size that is close to 1,048,576 rows. This will guarantee that every batch produces a fully populated row group, reduces the total number of row groups in a table, and improves query performance. Do not exceed that number, however, because the batch would not fit into a single row group.
Batch size is less important for non-bulk operations. Trickle inserts go directly to a delta store. In some cases, SQL Server can still create row groups on the fly in a similar manner to bulk insert when the size of the insert batch is close to or exceeds 1,048,576 rows. You should not rely on that behavior, however.
Delta Store and Delete Bitmap
Let’s analyze the structure of delta stores and delete bitmaps and look at the format of their rows. As a first step, let’s create a table, populate it with data, and define a clustered column store index there. Finally, we will look at segments and row groups with the sys.column_store_segments and sys.column_store_row_groups views.
Listing 35-1 shows the code that does just that. I am using MAXDOP=1 option during the index creation stage to minimize the number of partially-populated row groups in the index.
Listing 35-1. Delta store and Delete bitmap: Test table creation
create table dbo.CCI
(
Col1 int not null,
Col2 varchar(4000) not null,
);
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 cross join N4 as T2) -- 65,536 rows
,N6(C) as -- 1,048,592 rows
(
select 0 from N5 as T1 cross join N3 as T2
union all
select 0 from N3
)
,IDs(ID) as (select row_number() over (order by (select NULL)) from N6)
insert into dbo.CCI(Col1,Col2)
select ID, 'aaa'
from IDS
go
create clustered columnstore index IDX_CS_CLUST on dbo.CCI
with (maxdop=1)
go
select g.state_description, g.row_group_id, s.column_id
,s.row_count, s.min_data_id, s.max_data_id, g.deleted_rows
from
sys.column_store_segments s join sys.partitions p on
s.partition_id = p.partition_id
join sys.column_store_row_groups g on
p.object_id = g.object_id and
s.segment_id = g.row_group_id
where
p.object_id = object_id(N'dbo.CCI')
order by
g.row_group_id, s.column_id;
Figure 35-4 shows the output from sys.column_store_segments and sys.column_store_row_groups views. The columnstore index has two row groups and does not have delta store nor delete bitmap. You can see Col1 values that are stored in both row groups in min_data_id and max_data_id columns for the rows that have column_id=1.

Figure 35-4. Delta store and Delete bitmap: Sys.column_store_segments and sys.column_store_row_groups output
In the next step, shown in Listing 35-2, we will perform some data modifications in the table. The first statement inserts two new rows into the table. The second statement deletes three rows, including one of the rows that we just inserted. Finally, we will update another newly inserted row.
Listing 35-2. Delta store and Delete bitmap: Data modifications
insert into dbo.CCI(Col1,Col2)
values
(2000000,REPLICATE('c',4000)),
(2000001,REPLICATE('d',4000));
delete from dbo.CCI
where Col1 in
(
100 -- Row group 0
,16150 -- Row group 1
,2000000 -- Newly inserted row (Delta Store)
);
update dbo.CCI
set Col2 = REPLICATE('z',4000)
where Col1 = 2000001; -- Newly inserted row (Delta Store)
Now it is time to find the data pages that are used by delta store and delete bitmap. We will use the undocumented sys.dm_db_database_page_allocations system function, as shown in Listing 35-3.
Listing 35-3. Delta store and Delete bitmap: Analyzing page allocations
select object_id, index_id, partition_id
,allocation_unit_type_desc as [Type]
,is_allocated,is_iam_page,page_type,page_type_desc
,allocated_page_file_id as [FileId]
,allocated_page_page_id as [PageId]
from sys.dm_db_database_page_allocations
(db_id(), object_id('dbo.CCI'),NULL, NULL, 'DETAILED')
You can see the output of the query in Figure 35-5. As you know, SQL Server stores columnstore segments in LOB_DATA allocation units. Delta store and delete bitmap are using IN_ROW_DATA allocation.
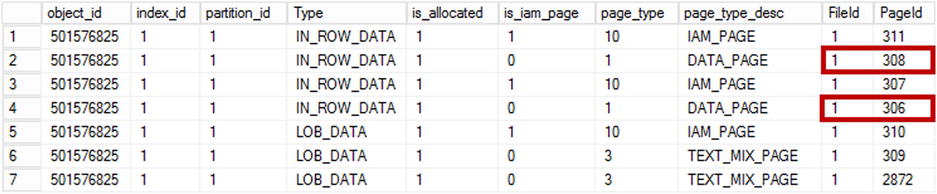
Figure 35-5. Delta store and Delete bitmap: Allocation units
Let's look at the data pages using another undocumented command, DBCC PAGE, with the code shown in Listing 35-4. Obviously, the database, file, and page IDs would be different in your environment.
Listing 35-4. Delta store and Delete bitmap: Analyzing page data
-- Redirecting output to console
dbcc traceon(3604)
-- Analyzing content of a page
dbcc page
(
9 -- Database Id
,1 -- FileId
,306 -- PageId
,3 -- Output style
)
Figure 35-6 shows the partial content of a data page, which is a delta store page. As you can see, SQL Server stores data in regular row-based storage. There is one internal column, CSILOCATOR, in addition to two table columns. CSILOCATOR is used as an internal unique identifier of the row in delta store.

Figure 35-6. Delta store and Delete bitmap: Delta store data page
Finally, it is worth noting that a row with Col1=2000000, which we have inserted and deleted after the clustered columnstore index was created, is not present in the delta store. SQL Server deletes (and updates) rows in the B-Tree delta store the same way as regular B-Tree tables.
You can use the same approach to examine the content of a deleted bitmap data page. In my case, the page id is 308.
Figure 35-7 shows the partial output of the DBCC PAGE command. As you can see, the delete bitmap includes two columns that uniquely identify a row. The first column is a row group id and the second column is the offset of the row in the segment. Do not be confused by the fact that the column names match table columns. DBCC PAGE uses table metadata to prepare the output.
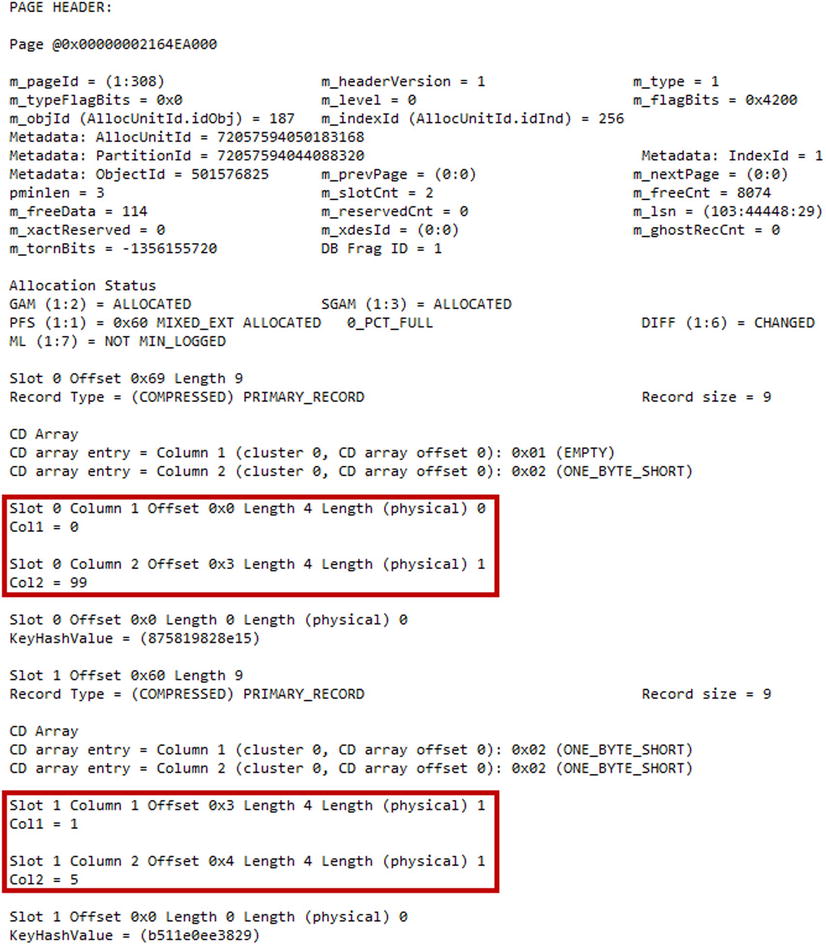
Figure 35-7. Delta store and Delete bitmap: Delete bitmap page
It is worth noting that delta store uses page compression. As you will remember, SQL Server performs page compression only when a page is full and retaining it only if the page compression provides significant space savings as compared to row compression. Neither happened in our example; therefore, SQL Server kept row compression for the data.
![]() Tip You can explore page compression in a delta store by recreating the dbo.CCI table and inserting a batch of rows, which benefit from page compression after the clustered columnstore index is created. The simple way to do this is by populating Col2 with repetitive strings using the REPLICATE('a',100) function. You will notice the compression information record if you examine the delta store data page with the DBCC PAGE command afterwards.
Tip You can explore page compression in a delta store by recreating the dbo.CCI table and inserting a batch of rows, which benefit from page compression after the clustered columnstore index is created. The simple way to do this is by populating Col2 with repetitive strings using the REPLICATE('a',100) function. You will notice the compression information record if you examine the delta store data page with the DBCC PAGE command afterwards.
Archival Compression
Archival compressionis another feature introduced in SQL Server 2014. It can be applied on a table or on an individual partition by specifying a DATA_COMPRESSION=COLUMNSTORE_ARCHIVE columnstore index property, and it reduces storage space even further. It uses the Xpress 8 compression library, which is an internal Microsoft implementation of the LZ77 algorithm. This compression works directly with binary data without any knowledge of the underlying SQL Server data structures.
Archival compression works transparently with other SQL Server features. Columnstore data is compressed at the time it is saved on disk and decompressed before it is loaded into memory.
Let’s compare the results of different compression methods. I created four different tables with the same schema, as shown in Listing 35-5. The first two tables are heaps with no nonclustered indexes defined. The first table was uncompressed and the second one was compressed with page compression. The third and fourth tables had clustered columnstore indexes compressed with COLUMNSTORE and COLUMNSTORE_ARCHIVE compression methods respectively. Each table had almost 62 million rows generated based on the dbo.FactResellerSales table from the AdventureWorksDW2012 database.
Listing 35-5. Schema of test tables
create table dbo.FactSalesBig
(
ProductKey int not null,
OrderDateKey int not null,
DueDateKey int not null,
ShipDateKey int not null,
CustomerKey int not null,
PromotionKey int not null,
CurrencyKey int not null,
SalesTerritoryKey int not null,
SalesOrderNumber nvarchar(20) not null,
SalesOrderLineNumber tinyint not null,
RevisionNumber tinyint not null,
OrderQuantity smallint not null,
UnitPrice money not null,
ExtendedAmount money not null,
UnitPriceDiscountPct float not null,
DiscountAmount float not null,
ProductStandardCost money not null,
TotalProductCost money not null,
SalesAmount money not null,
TaxAmt money not null,
Freight money not null,
CarrierTrackingNumber nvarchar(25) null,
CustomerPONumber nvarchar(25) null,
OrderDate datetime null,
DueDate datetime null,
ShipDate datetime null
)
Table 35-2 compares the on-disk size of all four tables.
Table 35-2. On-disk data size for different compression methods

Obviously, different table schema and data lead to different compression results; however, in most cases, you will achieve significantly greater space saving when archival compression is implemented.
Archival compression introduces additional CPU overhead at the compression and decompression stages. Let’s run a query that performs a MAX() aggregation on 20 columns in a table. The result of the query is meaningless; however, it forces SQL Server to read data from 20 different column segments in each row group in the table. Listing 35-6 shows the query.
Listing 35-6. Test query
-- Clear buffer pool forcing SQL Server to read data from disk
dbcc dropcleanbuffers
go
select
max(ProductKey),max(OrderDateKey),max(DueDateKey)
,max(ShipDateKey),max(CustomerKey),max(PromotionKey)
,max(CurrencyKey),max(SalesTerritoryKey),max(SalesOrderLineNumber)
,max(RevisionNumber),max(OrderQuantity),max(UnitPrice)
,max(ExtendedAmount),max(UnitPriceDiscountPct),max(DiscountAmount)
,max(ProductStandardCost),max(TotalProductCost),max(SalesAmount)
,max(TaxAmt),max(Freight)
from dbo.FactSalesBig
Table 35-3 illustrates the execution time of the query against the tables with different columnstore compression methods. Even though the data compressed using archival compression uses significantly less space on disk, it takes longer for the query to complete due to the decompression overhead involved. Obviously, the results would vary based on the CPU and I/O performance of the system.
Table 35-3. Execution time for different compression methods
COLUMNSTORE compression |
COLUMNSTORE_ARCHIVE compression |
|---|---|
2,025ms / 6,573ms |
2,464ms / 8,470ms |
Archival compression is a great choice for static, rarely accessed, data. It is common for Data Warehouses to retain data for a long time, even though historical data is rarely accessed. You may wish to consider applying archival compression on partitions that store historical data and benefit from the disk space saving it achieves.
Clustered Columnstore Index Maintenance
Clustered columnstore indexes require maintenance similar to regular B-Tree indexes, even though the reasons for doing the maintenance are different. Columnstore indexes do not become fragmented; however, they can suffer from a large number of partially populated row groups. Another issue is the overhead of delta store and deleted bitmap scans during query execution.
Let’s run several tests and look at the issues involved in detail.
Excessive Number of Partially Populated Row Groups
For this test, I created two tables of a similar structure to the table shown in Listing 35-5, and I bulk imported almost 62 million rows with the bcp utility using 1,000,000 rows batches and 102,500 rows batches respectively.
Figure 35-8 illustrates the row groups in both tables after the import.

Figure 35-8. Row groups after bulk import
Table 35-4 illustrates the execution time and number of I/O operations for the query from Listing 35-6 running against both tables. As you can see, the query against a table with partially populated row groups took a considerably longer time to execute.
Table 35-4. Execution statistics for the tables with fully and partially populated row groups
Partially populated row groups |
||
|---|---|---|
Elapsed/CPU time |
2,093ms / 6,612ms |
3,762ms / 8,953ms |
Logical reads |
177,861 |
192,533 |
Physical reads |
568 |
9,725 |
It is worth noting that the performance of batch inserts was also affected by smaller batch sizes. In the case of 1,000,000-row batches, my system was able to insert about 103,500 rows per second, contrary to 94,300 rows per second in the case of the 102,500-row batches.
![]() Note Loading data in smaller batches puts new data into the delta store and produces fully populated row groups afterwards. However, insert performance is seriously affected. For example, when I inserted data in 99,999-row batches, my system was able to insert only 37,500 rows per second.
Note Loading data in smaller batches puts new data into the delta store and produces fully populated row groups afterwards. However, insert performance is seriously affected. For example, when I inserted data in 99,999-row batches, my system was able to insert only 37,500 rows per second.
For the next step, let’s look at how large delta stores affect the performance of queries. SQL Server needs to scan these delta stores during query execution.
For this test, I inserted 1,000,000 rows in small batches into the delta store of the first table from the previous test (the table that had row groups fully populated). After that, I rebuilt the columnstore index, comparing the execution time of the test query before and after the index rebuild.
The index rebuild process moved all data from the delta store to row groups. You can see the status of row groups and the delta store before (on the left side) and after (on the right side) the index rebuild in Figure 35-9.

Figure 35-9. Row groups and delta store after insertion of 1,000,000 rows
Table 35-5 illustrates the execution times of the test query in both scenarios, and it shows the overhead introduced by the large delta store scan during query execution.
Table 35-5. Execution time and delta store size
Empty delta store |
1,000,000 rows in delta store |
|---|---|
2,148ms / 6,815ms |
4,177ms / 8,453ms |
Large Delete Bitmap
Finally, let’s see how delete bitmaps affect query performance. For that test, I deleted almost 30,000,000 rows from a table.
You can see the row groups’ information in Figure 35-10.

Figure 35-10. Row groups after deletion of 30,000,000 rows
The test query needs to validate that rows have not been deleted during query execution. Similar to the previous test, this adds considerable overhead. Table 35-6 shows the execution time of the test query, comparing it to the execution time of the query before the data deletion.
Table 35-6. Execution time and delete bitmap
Empty delete bitmap |
Delete bitmap with large number of rows |
|---|---|
2,148ms / 6,815ms |
3,995ms / 11,421ms |
You can address all of these performance issues by rebuilding the columnstore index, which you can trigger with the ALTER INDEX REBUILD command. The index rebuild forces SQL Server to remove deleted rows physically from the index and to merge the delta stores’ and row groups’ data. All column segments are recreated with row groups fully populated.
Similar to index creation, the index rebuild process is very resource intensive. Moreover, it prevents any data modifications in the table by holding shared (S) table lock. However, other sessions can still read data from a table while the rebuild is running.
One of the methods used to mitigate the overhead of index rebuild is table/index partitioning. You can rebuild indexes on a partition-basis and only perform it for partitions that have volatile data. Old facts table data in most Data Warehouse solutions is relatively static, and ETL processes usually load new data only. Partitioning by date in this scenario localizes modifications within the scope of one or very few partitions. This can help you dramatically reduce the overhead of an index rebuild.
As we already discussed, columnstore indexes support an index reorganize process, which you can trigger with the ALTER INDEX REORGANIZE command. The term index reorganize is a bit vague here; you can think of it as a tuple mover process running on-demand. The only action performed by index reorganization is compressing and moving data from closed delta stores to row groups. Deleted bitmap and open delta stores stay intact.
In contrast to a single-threaded tuple mover process, the ALTER INDEX REORGANIZE operation uses all available system resources while it is running. This can significantly speed up the execution process and reduce the time that other sessions cannot modify or delete data in a table. It is worth noting again that insert processes are not blocked during that time.
A columnstore indexes maintenance strategy should depend on the volatility of the data and the ETL processes implemented in the system. You should rebuild indexes when a table has a considerable amount of deleted rows and/or a large number of partially populated row groups.
It is also advantageous to rebuild partition(s) that have a large number of rows in open delta stores after the ETL process has completed, especially if the ETL process does not use a bulk insert API.
SQL Server 2014 Batch-Mode Execution Enhancements
Even though we have not specifically discussed how to write queries that trigger batch-mode execution in SQL Server, it is impossible not to mention that SQL Server 2014 has multiple enhancements in this area relative to SQL Server 2012. Only few operators in SQL Server 2012 can support batch-mode execution. As an example, batch-mode execution in SQL Server 2012 does not support any join types with the exception of inner hash joins; it does not support scalar aggregates, nor does it support the union all operator, and it has quite a few other limitations.
A large number of those limitations have been addressed in SQL Server 2014. Now batch-mode execution supports all join types and outer joins, explores different join orders during the query optimization stage, and supports scalar aggregates and the union all operator. Moreover, the execution algorithms for various operators have been improved. For example, the hash join operator in SQL Server 2014 can now spill to tempdb without switching to row-mode execution, which was impossible in SQL Server 2012.
Let’s look at an example and run a query with a scalar aggregate, as shown in Listing 35-7, against the database that we created in Listing 34-3 in the previous chapter.
Listing 35-7. Batch-mode execution: Test Query
select sum(Amount) as [Total Sales]
from dbo.FactSales;
When you run this query in SQL Server 2014, you will see an execution plan that utilizes batch-mode execution, as shown in Figure 35-11.

Figure 35-11. Execution plan of test query in SQL Server 2014
Unfortunately, SQL Server 2012 is unable to use batch-mode execution with scalar aggregates, and it produces the execution plan shown in Figure 35-12, which is significantly less efficient.

Figure 35-12. Execution plan of test query in SQL Server 2012
It is still possible to force batch-mode execution with SQL Server 2012; however, it requires cumbersome query refactoring with subselects and/or common table expressions. Listing 35-8 shows you how to refactor the test query by introducing the group by aggregate.
Listing 35-8. Batch-mode execution: Refactoring of test query to utilize batch-mode execution in SQL Server 2012
;with CTE(BranchId, TotalSales)
as
(
select BranchId, Sum(Amount)
from dbo.FactSales
group by BranchId
)
select sum(TotalSales) as TotalSales
from CTE
Figure 35-13 shows the execution plan of the query after refactoring.

Figure 35-13. Execution plan of test query after refactoring in SQL Server 2012
As you can see, query refactoring is not always trivial and requires a deep understanding of SQL Server query processing. This prevents the widespread adoption of such techniques within the SQL Server 2012 community. Fortunately, SQL Server 2014 makes query refactoring unnecessary in a large number of cases. Those improvements alone make upgrading from SQL Server 2012 to 2014 in Data Warehouse environments worth the effort.
Design Considerations
The choice between columnstore and B-Tree indexes depends on several factors. The most important factor, however, is the type of workload in the system. Both types of indexes are targeted to different use-cases, and each has its own set of strength and weaknesses.
Columnstore indexes shine with Data Warehouse workloads when queries need to scan a large amount of data in a table. However, they are not a good fit for cases where you need to select one or a handful of rows using Singleton Lookup or small Range Scan operations. An Index Scan is the only access method supported by columnstore indexes, and SQL Server will scan the data even if your query needs to select a single row from a table. The amount of data to scan can be reduced by partition and segment eliminations. In either case, however, a scan would be far less efficient than the use of a B-Tree Index Seek operation.
Most large Data Warehouse systems would benefit from columnstore indexes, even though their implementation requires some work in order to get the most from them. You often need to change a database schema to fit into star or snowflake patterns better and/or to normalize facts tables and remove string attributes from them. In the case of SQL Server 2012, you need to change ETL processes to address the read-only limitation of nonclustered columnstore indexes, and you must often refactor queries to utilize batch-mode execution.
Clustered columnstore indexes simplify the conversion process. You can continue to use existing ETL processes and insert data directly into facts tables. There is a hidden danger in this approach, however. Even though clustered columnstore indexes are fully updateable, they are optimized for large bulk load operations. As you have seen, excessive data modifications and a large number of partially populated row groups could and will negatively affect the performance of queries. In the end, you should either fine tune ETL processes or frequently rebuild indexes to avoid such performance overhead. In some cases, especially with frequently modified or deleted data, you need to rebuild indexes on a regular basis, regardless of the quality of the ETL processes.
Table partitioning becomes a must have element in this scenario. It allows you to perform index maintenance in the partition scope, which can dramatically reduce the overhead of such operations. It also allows you to save storage space and reduce the solution cost by implementing archival compression on the partitions that store old data.
The question of columnstore index usage in OLTP environments is more complex than it may seem. Even though tables with clustered columnstore indexes are updateable, they are not good candidates for active and volatile OLTP data. Unfortunately, performance issues are easy to overlook at the beginning of development; after all, any solution performs good enough with a small amount of data. However, as the amount of data increases, performance issues become noticeable and force the refactoring of systems.
Nevertheless, there are some legitimate cases for columnstore indexes even in OLTP environments. Almost all OLTP systems provide some reporting and analysis capabilities to customers. In some cases, you may consider using columnstore indexes on tables that store old and static historical data using regular B-Tree tables for volatile operational data. You can combine data from all tables with a partitioned view, hiding the data layout from the client applications.
One such example is a SaaS (Software as a Service) installation that collects some data and provides basic Self-Service Business Intelligence to customers. Even though a Self-Service Business Intelligence workload fits into the Data Warehouse profile, it is not always possible or practical to implement a separate Data Warehouse solution. An implementation that uses data partitioning and utilizes columnstore indexes on historical data may work here. Nevertheless, it will require a complex and thoughtful design process, deep knowledge of the system workload, and considerable effort to implement.
In some cases, especially if data is static and read-only, nonclustered columnstore indexes could be a better choice than clustered columnstore indexes. Even though they require extra storage space for B-Tree representation of the data, you can benefit from regular B-Tree indexes to support some use-cases and queries.
Finally, it is worth remembering that columnstore indexes are an Enterprise Edition feature only. Moreover, they are not a transparent feature, as is data compression and table partitioning, which can be removed from the database relatively easily if necessary. Implementation of columnstore indexes leads to specific database schema and code patterns, which can be less efficient in the case of B-Tree indexes. Think about over-normalization of facts tables, changes in ETL processes, and batch-mode execution query refactoring as examples of those patterns.
Summary
The clustered columnstore indexes introduced in SQL Server 2014 address the major limitation of nonclustered columnstore indexes, which prevent any modifications of the data in the table. Clustered columnstore indexes are updateable, and they are the only instance of the data that is stored in the table. No other indexes can be created on a table that has a clustered columnstore index defined.
Clustered and nonclustered columnstore indexes share the same storage format for column-based data. Two types of internal objects support data modifications in clustered columnstore indexes. A delete bitmap indicates what rows were deleted. A delta store stores new rows. Both delta stores and delete bitmaps use a B-Tree structure to store the data.
Updating rows stored in row groups is implemented as the deletion of old and insertion of a new version of the rows. Deletion and modifications of the data in a delta store deletes or updates rows in the delta store B-Tree.
Delta stores can store up to 1,048,576 rows. After this limit is reached, the delta store is closed and converted to a row group in column-based storage format by a background process called tuple mover. Alternatively, you can force this conversion with the ALTER INDEX REORGANIZE command.
A large amount of data in delta stores and/or delete bitmaps negatively affects query performance. You should monitor their size, and rebuild the indexes to address performance issues. You should partition tables to minimize index maintenance overhead.
Bulk insert operations with a batch size that exceeds approximately 100,000 rows creates new row groups and inserts data there. A large number of partially populated row groups is another factor that negatively affects query performance. You should import data in batches with a size of close to 1,048,576 rows to avoid this situation. Alternatively, you can rebuild indexes after ETL operations are completed.
Columnstore indexes do not support any access methods with exception of an Index Scan. They are targeted at Data Warehouse workload, and they should be used with extreme care in OLTP environments. In some cases, however, you can use them in tables with historical data, storing active OLTP data in B-Tree tables combining all data with partitioned views.