
![]()
CLR Types
CLR types is another area of Common Language Runtime integration in SQL Server. User-defined CLR types allow us to expand the standard type library by developing .Net classes and registering them as user-defined types in the database. Standard CLR types, such as Geometry, Geography, and HierarchyId, provide built-in support for spatial and hierarchical data.
In this chapter, you will learn about both user-defined and system CLR types.
User-Defined CLR Types
SQL Server has supported user-defined types (UDT) for years. Historically, T-SQL based user-defined types were used to enforce type consistency. For example, when you needed to persist U.S. postal addresses in a several tables, you could consider creating a PostalState UDT to store state information, as shown in Listing 14-1.
Listing 14-1. Creating a T-SQL user-defined type
create type dbo.PostalState from char(2) not null
Now you can use PostalState as a data type that defines table columns, parameters, and SQL variables. This guarantees that every reference to the postal state in the database has exactly the same format: a non-nullable, two-character string.
This approach has a few downsides, though. SQL Server does not permit altering of type definition. If, at any point in time you need to make PostalState nullable or, perhaps, allow full state names rather than abbreviations, the only option is to drop and recreate the type. Moreover, you must remove any references to that type in the database in order to do that.
![]() Tip You can alter the type of the column to the base data type used by UDT. This is a metadata-only operation.
Tip You can alter the type of the column to the base data type used by UDT. This is a metadata-only operation.
T-SQL user-defined types are always delivered from the scalar T-SQL type. For example, you cannot create a T-SQL user-defined data called Address, which includes multiple attributes. Neither can you define check constraints on the type level. Constraints still can be defined individually on the column level, although such an approach is less convenient.
![]() Note You can perform validation on the type level by binding the rule object to UDT. It is not recommended, however, as rules are deprecated and will be removed in a future versions of SQL Server.
Note You can perform validation on the type level by binding the rule object to UDT. It is not recommended, however, as rules are deprecated and will be removed in a future versions of SQL Server.
Keeping all of this in mind, we can conclude that T-SQL user-defined types have very limited use in SQL Server.
CLR user-defined types, on the other hand, addresses some of these issues. They allow you to create the complex types with multiple attributes/properties, defining the data validation rules for the type and, finally, implementing the methods that you can use to enhance the functionality of the type.
As an example, let’s look at the implementation of the type that represents a simplified version of a U.S. postal address. The code for this is shown in Listing 14-2.
Listing 14-2. CLR user-defined type
[Serializable]
[Microsoft.SqlServer.Server.SqlUserDefinedType(
Format.UserDefined,
ValidationMethodName = "ValidateAddress",
MaxByteSize=8000
)]
public struct USPostalAddress : INullable, IBinarySerialize
{
// Needs to be sorted to support BinarySearch
private static readonly List<string> _validStates = new List<string>
{
"AK","AL","AR","AZ","CA","CO","CT","DC","DE","FL","GA","HI","IA"
,"ID","IL","IN","KS","KY","LA","MA","MD","ME","MI","MN","MO","MS"
,"MT","NC","ND","NE","NH","NJ","NM","NV","NY","OH","OK","OR","PA"
,"PR","RI","SC","SD","TN","TX","UT","VA","VT","WA","WI","WV","WY"
};
private bool _null;
private string _address;
private string _city;
private string _state;
private string _zipCode;
public bool IsNull { get { return _null; } }
public string Address
{
[SqlMethod(IsDeterministic = true, IsPrecise = true)]
get { return _address; }
}
public string City
{
[SqlMethod(IsDeterministic = true, IsPrecise = true)]
get { return _city; }
}
public string State
{
[SqlMethod(IsDeterministic = true, IsPrecise=true)]
get { return _state; }
}
public string ZipCode
{
[SqlMethod(IsDeterministic = true, IsPrecise = true)]
get { return _zipCode; }
}
public override string ToString()
{
return String.Format("{0}, {1}, {2}, {3}", _address, _city, _state, _zipCode);
}
// The static representation of Null object
public static USPostalAddress Null
{
get
{
USPostalAddress h = new USPostalAddress();
h._null = true;
return h;
}
}
// Validation that Address information is correct
private bool ValidateAddress()
{
// Check that all attributes are specified and state is valid
return
!(
String.IsNullOrEmpty(_address) ||
String.IsNullOrEmpty(_city) ||
String.IsNullOrEmpty(_state) ||
String.IsNullOrEmpty(_zipCode) ||
_validStates.BinarySearch(_state.ToUpper()) == -1
);
}
// Creating object from the string
public static USPostalAddress Parse(SqlString s)
{
if (s.IsNull)
return Null;
USPostalAddress u = new USPostalAddress();
string[] parts = s.Value.Split(",".ToCharArray());
if (parts.Length != 4)
throw new ArgumentException("The value has incorrect format. Should be <Address>, <City>, <State>, <ZipCode>");
u._address = parts[0].Trim();
u._city = parts[1].Trim();
u._state = parts[2].Trim();
u._zipCode = parts[3].Trim();
if (!u.ValidateAddress())
throw new ArgumentException("The value has incorrect format. Attributes are empty or State is incorrect");
return u;
}
// Example of the class method
[SqlMethod(
OnNullCall = false,
IsDeterministic = true,
DataAccess=DataAccessKind.None
)]
public double CalculateShippingCost(USPostalAddress destination)
{
// Calculating shipping cost between two addresses
if (destination.State == this.State)
return 15.0;
else
return 25.0;
}
// IBinarySerializer.Read
public void Read(System.IO.BinaryReader r)
{
_address = r.ReadString();
_city = r.ReadString();
_state = r.ReadString();
_zipCode = r.ReadString();
}
// IBinarySerializer.Write
public void Write(System.IO.BinaryWriter w)
{
w.Write(_address);
w.Write(_city);
w.Write(_state);
w.Write(_zipCode);
}
}
As you see, the type includes four different public attributes/properties (Street, City, State, and ZIPCode) and several methods. Some of the methods (ToString, Parse, Read, and Write) are required to support type creation and serialization. Another (CalculateShippingCost) is an example of a type functionality enhancement.
In the database, you can use that type when defining table columns, variables, and parameters. Listing 14-3 and Figure 14-1 show an example of this.
Listing 14-3. CLR user-defined type usage
declare
@MicrosoftAddr dbo.USPostalAddress =
'One Microsoft Way, Redmond, WA, 98052'
,@GoogleAddr dbo.USPostalAddress =
'1600 Amphitheatre Pkwy, Mountain View, CA, 94043'
select
@MicrosoftAddr as [Raw Data]
,@MicrosoftAddr.ToString() as [Text Data]
,@MicrosoftAddr.Address as [Address]
,@MicrosoftAddr.CalculateShippingCost(@GoogleAddr) as [ShippingCost]

Figure 14-1. CLR user-defined type usage
CLR user-defined types let you easily expand the SQL Server type library with your own types, developed and used in object-oriented manner. It sounds too good to be true from a development standpoint and, unfortunately, there are a few caveats about which you need to be aware.
As I already mentioned, SQL Server does not let you alter the type after you create it. You can redeploy the new version of assembly with the ALTER ASSEMBLY command. This allows you to change the implementation of the methods and/or fix the bugs in the implementation, although you would not be able to change the interface of existing methods nor would you be able to utilize new public methods unless you drop and re-create the type. This requires removing all type references from the database code.
All of this means that you must perform the following set of actions to re-deploy the type:
- Remove all type references from T-SQL code.
- Persist all data from columns of that type somewhere else, either by shredding type attributes to relational format or casting them to varbinary. You need to be careful with the latter approach and make sure that the new version of type objects can be deserialized from the old object’s binary data.
- Drop all columns of that type.
- Drop type, redeploy assembly, and create type again.
- Recreate the columns, and re-populate them with the data.
- Rebuild the indexes, reclaiming the space from the old columns and reducing the fragmentation.
- Recreate T-SQL code that references the type.
As you see, that introduces a large amount of maintenance overhead, and it can lead to prolonged system downtimes.
Performance is another very important aspect to consider. SQL Server stores CLR types in binary format. Every time you access attributes or methods of CLR type, SQL Server deserializes the object and calls the CLR method, which leads to overhead similar to what you saw in Chapter 13.
Let’s run some tests and create two tables with address information: one using regular T-SQL data types and another using a dbo.USPostalAddress user-defined type. You can see the code for doing this in Listing 14-4.
Listing 14-4. UDT performance: Table creation
create table dbo.Addresses
(
ID int not null identity(1,1),
Address varchar(128) not null,
City varchar(64) not null,
State char(2) not null,
constraint CHK_Address_State
check (
State in (
'AK','AL','AR','AZ','CA','CO','CT','DC','DE','FL','GA','HI','IA'
,'ID','IL','IN','KS','KY','LA','MA','MD','ME','MI','MN','MO','MS'
,'MT','NC','ND','NE','NH','NJ','NM','NV','NY','OH','OK','OR','PA'
,'PR','RI','SC','SD','TN','TX','UT','VA','VT','WA','WI','WV','WY'
)
),
ZipCode varchar(10) not null,
constraint PK_Addresses primary key clustered(ID)
);
create table dbo.AddressesCLR
(
ID int not null identity(1,1),
Address dbo.USPostalAddress not null,
constraint PK_AddressesCLR primary key clustered(ID)
);
;with Streets(Street)
as
(
select v.v
from (
values('Street 1'),('Street 2'),('Street 3'),('Street 4')
,('Street 5'), ('Street 6'),('Street 7'),('Street 8')
,('Street 9'),('Street 10')
) v(v)
)
,Cities(City)
as
(
select v.v
from (
values('City 1'),('City 2'),('City 3'),('City 4'),('City 5'),
('City 6'),('City 7'),('City 8'),('City 9'),('City 10')
) v(v)
)
,ZipCodes(Zip)
as
(
select v.v
from (
values('99991'),('99992'),('99993'),('99994'),('99995'),
('99996'),('99997'),('99998'),('99999'),('99990')
) v(v)
)
,States(state)
as
(
select v.v
from (
values('AL'),('AK'),('AZ'),('AR'),('CA'),('CO'),('CT'),('DE'),('FL'),
('GA'),('HI'),('ID'),('IL'),('IN'),('IA'),('KS'),('KY'),('LA'),('ME'),
('MD'),('MA'),('MI'),('MN'),('MS'),('MO'),('MT'),('NE'),('NV'),('NH'),
('NJ'),('NM'),('NY'),('NC'),('ND'),('OH'),('OK'),('OR'),('PA'),('RI'),
('SC'),('SD'),('TN'),('TX'),('UT'),('VT'),('VA'),('WA'),('WV'),('WI')
,('WY'),('DC'),('PR')
) v(v)
)
insert into dbo.Addresses(Address,City,State,ZipCode)
select Street,City,State,Zip
from Streets cross join Cities cross join States cross join ZipCodes;
insert into dbo.AddressesCLR(Address)
select Address + ', ' + City + ', ' + State + ', ' + ZipCode
from dbo.Addresses;
Now let’s run the test and look at the performance of the queries against both tables. We will use the queries shown in Listing 14-5.
Listing 14-5. UDT performance: Querying the data
select State, count(*)
from dbo.Addresses
group by State
select Address.State, count(*)
from dbo.AddressesCLR
group by Address.State
As you see in Figure 14-2, the second select introduces a CLR method call for every row, and this significantly affects the performance of the query. You can see information about the call in the Computer Scalar operator properties, as shown in Figure 14-3.
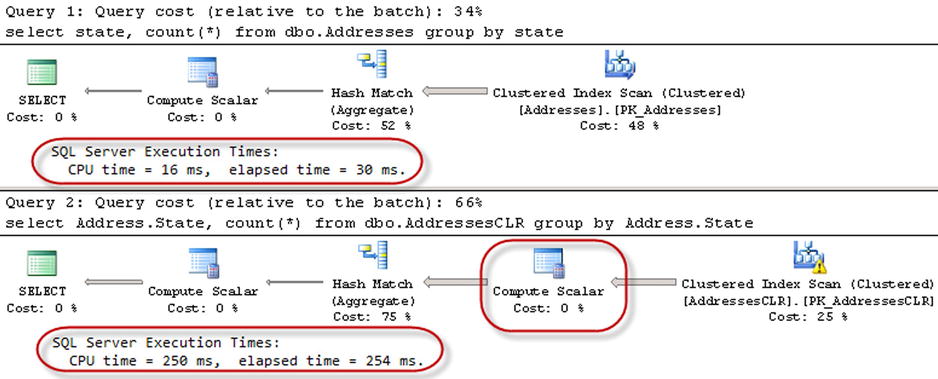
Figure 14-2. UDT performance: Querying the data
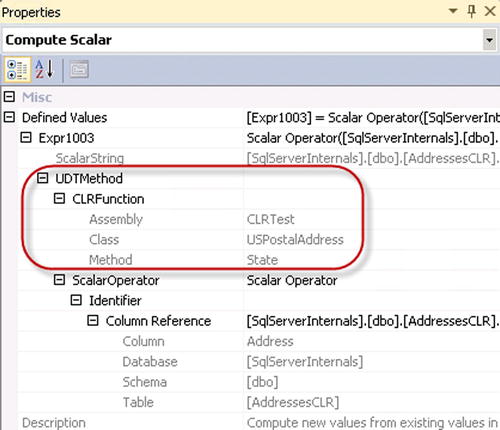
Figure 14-3. UDT performance: Computer Scalar operator properties
Some of the performance issues can be addressed with persisted computed columns, which can even be indexed if needed. Let’s test this by adding a State column to the AddressesCLR table and creating the indexes in both tables. The code for doing this is shown in Listing 14-6.
Listing 14-6. UDT performance: Adding a persisted calculated column
alter table dbo.AddressesCLR add State as Address.State persisted;
-- Repuild the index to reduce the fragmentation caused by alteration
alter index PK_AddressesCLR on dbo.AddressesCLR rebuild;
create index IDX_AddressesCLR_State on dbo.AddressesCLR(State);
create index IDX_Addresses_State on dbo.Addresses(State);
Now, if you run the queries from Listing 14-5 again, you will see the results shown in Figure 14-4.

Figure 14-4. UDT performance: Persisted calculated column
There is still a Compute Scalar operator in the second execution plan, although this time it is not related to the CLR method call, and it is used as the column reference placeholder, as shown in Figure 14-5.
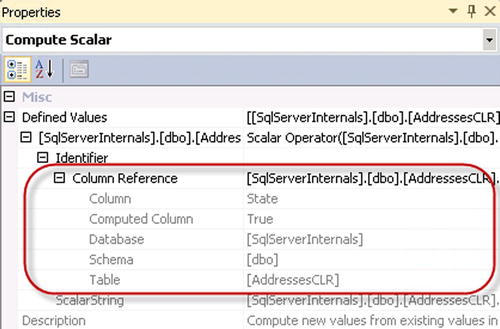
Figure 14-5. UDT performance: Computer Scalar operator with computed column
Although persisted computed columns can help with performance, they are increasing the size of the rows. You are storing the same information several times, once as part of UDT binary value and in clustered and potentially non-clustered indexes. They also introduce additional overhead for maintaining calculated columns when UDT is frequently modified.
Keeping supportability and performance aspects in mind, you should be very careful when introducing CLR user-defined types in your systems. The public methods of the type should be finalized before initial deployment, and the code must be carefully tested. This will help to avoid situations when the type needs to be redeployed.
In addition, you need to minimize the number of CLR calls by creating and possibly indexing persisted calculated columns, which store the values of the UDT properties and methods that are frequently called from the queries.
SQL Server supports two data types to store spatial information: geometry and geography. Geometrysupports planar, or Euclidean, flat-earth data. Geographysupports ellipsoidal round-earth surfaces. Both data types can be used to store location information, such as GPS latitude and longitude coordinates. Geography data type consider the Earth’s roundness and provide slightly better accuracy, although it has stricter requirements for the data. For example, data must fit in a single hemisphere and polygons must be defined in specific ring orientation. Client applications need to be aware of these requirements and handle them correctly in the code.
Storing location information in a geometry data type introduces its own class of problems. It works fine and often has better performance than a geography data type when you need to find out if a location belongs to a specific area or if areas are intersecting. However, you cannot calculate the distance between points: the unit of measure for the result is in decimal degrees, which are useless in a non-flat surface.
![]() Note Coverage of spatial data type methods is outside of the scope of this book. If you are interested in learning more about this, check out this site for more details: http://msdn.microsoft.com/en-us/library/bb933790.aspx.
Note Coverage of spatial data type methods is outside of the scope of this book. If you are interested in learning more about this, check out this site for more details: http://msdn.microsoft.com/en-us/library/bb933790.aspx.
Although spatial data types provide a rich set of methods to work with the data, you must consider performance aspects when dealing with them. Let’s compare the performance of the methods that calculate the distance between two points. A typical use-case for such a scenario is the search for a point of interest (POI) close to a specific location. As a first step, let’s create three different tables that store POI information.
The first table, dbo.Locations, stores coordinates using the decimal(9,6) data type. The two other tables use a geography data type. Finally, the table dbo.LocationsGeoIndexed has a Location column indexed with a special type of index called a spatial index. These indexes help improve the performance of some operations, such as distance calculations or ones that check to see if objects are intersecting. The code is shown in Listing 14-7.
Listing 14-7. POI Lookup: Creating test tables
create table dbo.Locations
(
Id int not null identity(1,1),
Latitude decimal(9,6) not null,
Longitude decimal(9,6) not null,
primary key(Id)
);
create table dbo.LocationsGeo
(
Id int not null identity(1,1),
Location geography not null,
primary key(Id)
);
create table dbo.LocationsGeoIndexed
(
Id int not null identity(1,1),
Location geography not null,
primary key(Id)
);
-- 241,402 rows
;with Latitudes(Lat)
as
(
select convert(float,40.0)
union all
select convert(float,Lat + 0.01)
from Latitudes
where Lat < convert(float,48.0)
)
,Longitudes(Lon)
as
(
select convert(float,-120.0)
union all
select Lon - 0.01
from Longitudes
where Lon > -123
)
insert into dbo.Locations(Latitude, Longitude)
select Latitudes.Lat, Longitudes.Lon
from Latitudes cross join Longitudes
option (maxrecursion 0);
insert into dbo.LocationsGeo(Location)
select geography::Point(Latitude, Longitude, 4326)
from dbo.Locations;
insert into dbo.LocationsGeoIndexed(Location)
select Location
from dbo.LocationsGeo;
create spatial index Idx_LocationsGeoIndexed_Spatial
on dbo.LocationsGeoIndexed(Location);
![]() Tip We store location information in relational format using the decimal(9,6) data type rather than float. Decimal data types use six bytes less storage space per pair of values, and they provide accuracy which exceeds that of commercial-grade GPS receivers.
Tip We store location information in relational format using the decimal(9,6) data type rather than float. Decimal data types use six bytes less storage space per pair of values, and they provide accuracy which exceeds that of commercial-grade GPS receivers.
The storage space used by the tables from Listing 14-7 is shown in Table 14-1.
Table 14-1. Storage space used by the tables Listing 14-6
dbo.Locations |
dbo.LocationsGeo |
dbo.LocationsGeoIndexed |
|---|---|---|
8,898 KB |
12,780 KB |
17,320KB |
As you see, the binary representation of the spatial type uses more space than the relational format. As expected, the spatial index requires additional space, although the overhead is not nearly as much as the overhead produced by XML indexes that you saw in Chapter 11. “XML.”
Let’s run tests that measure the performance of queries that calculate the number of locations within one mile of Seattle city center. In the dbo.Locations table, we will use the dbo.CalcDistanceCLR function, which was defined in Chapter 13. For the two other tables, we will call the spatial method: STDistance. The test code to accomplish this is shown in Listing 14-8. The query execution plans are shown in Figure 14-6.
Listing 14-8. POI Lookup: Test queries
declare
@Lat decimal(9,6) = 47.620309
,@Lon decimal(9,6) = -122.349563
declare
@G geography = geography::Point(@Lat,@Lon,4326)
select ID
from dbo.Locations
where dbo.CalcDistanceCLR(Latitude, Longitude, @Lat, @Lon) < 1609
select ID
from dbo.LocationsGeo
where Location.STDistance(@G) < 1609
select ID
from dbo.LocationsGeoIndexed
where Location.STDistance(@G) < 1609
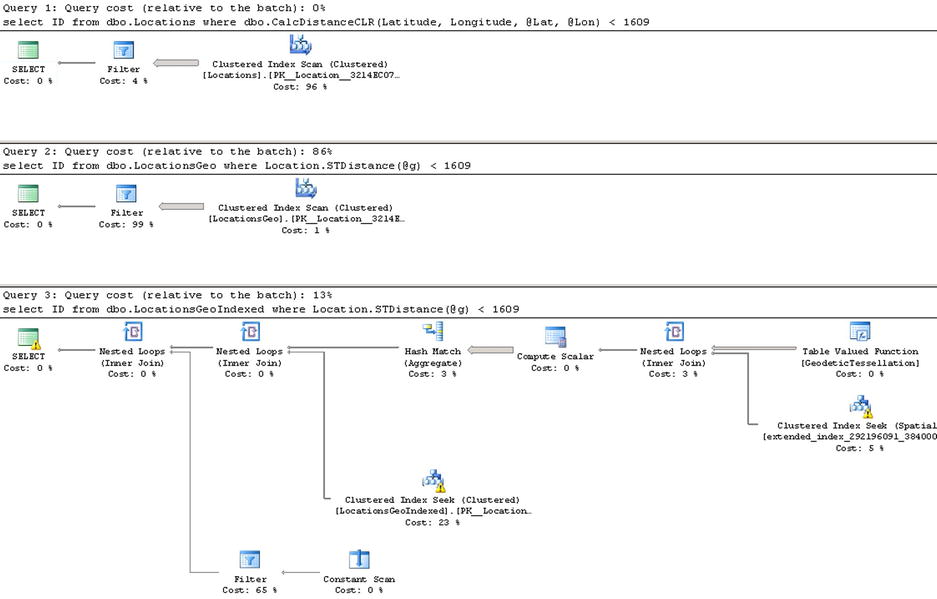
Figure 14-6. POI Lookup: Execution plans
The first and second queries perform a clustered index scan and calculate the distance for every row of the table. The last query uses a spatial index to lookup such rows. You can see the execution times for the queries in Table 14-2.
Table 14-2. POI Lookup: Execution time
dbo.Locations |
dbo.LocationsGeo |
dbo.LocationsGeoIndexed |
|---|---|---|
473 ms |
9,433 ms |
18 ms |
As you see, the spatial index greatly benefits the query. It is also worth mentioning that without the index, the performance of the CalcDistanceCLR method is better compared to the STDistance method.
Although the spatial index greatly improves performance, it has its own limitations. It works within the scope of the entire table, and all other predicates are evaluated after spatial index operations. This can introduce suboptimal plans in some cases.
As an example, let’s look at the use-case, for when we store POI information on a customer-by-customer basis, as shown in Listing 14-9.
Listing 14-9. Customer-based POI Lookup: Table creation
create table dbo.LocationsGeo2
(
CompanyId int not null,
Id int not null identity(1,1),
Location geography not null,
constraint PK_LocationsGeo2
primary key clustered(CompanyId,Id)
);
-- 12,070,100 rows; 50 companies; 241,402 rows per company
;with Companies(CID)
as
(
select 1
union all
select CID + 1 from Companies where CID < 50
)
insert into dbo.LocationsGeo2(CompanyId,Location)
select c.CID, l.Location
from dbo.LocationsGeo l cross join Companies c;
create spatial index Idx_LocationsGeo2_Spatial
on dbo.LocationsGeo2(Location);
In this case, when we perform POI lookup for a specific company, the CompanyId column must be included as the predicate to the queries. SQL Server has two choices on how to proceed: the first choice is a clustered index seek based on the CompanyId value calling STDistance method for every POI that belongs to the company. The second choice is to use a spatial index, find all POIs within the specified distance regardless of the company to which they belong, and, finally, join it with the clustered index data. Let’s run the queries shown in Listing 14-10.
Listing 14-10. Customer-based POI Lookup: Test queries
declare
@Lat decimal(9,6) = 47.620309
,@Lon decimal(9,6) = -122.349563
,@CompanyId int = 15
declare
@g geography = geography::Point(@Lat,@Lon,4326)
select count(*)
from dbo.LocationsGeo2
where Location.STDistance(@g) < 1609 and CompanyId = @CompanyId
select count(*)
from dbo.LocationsGeo2 with (index=Idx_LocationsGeo2_Spatial)
where Location.STDistance(@g) < 1609 and CompanyId = @CompanyId
Neither method is efficient when a table stores a large amount of data for a sizable number of companies. The execution plan of the first query utilizing clustered index seek shows that it performed an STDistance call 241,402 times, or once per every company POI. The execution plan is shown in Figure 14-7.

Figure 14-7. Customer-based POI Lookup: Execution plan for the first query
The execution plan for the second query, which is shown in Figure 14-8, indicates that the spatial index lookup returned 550 rows; that is, all POI in the area, regardless of to which company they belong. SQL Server had to join the rows with the clustered index before evaluating the CompanyId predicate.

Figure 14-8. Customer-based POI Lookup: Execution plan for the second query
One of the ways to solve such a problem is called the Bounding Box approach. This method lets us minimize the number of calculations by filtering out POIs that are outside of the area of interest.
As you see in Figure 14-9, all points that we need to select reside in the circle with the location at the center point and radius specified by the distance. The only points that we need to evaluate reside within the box that surrounds the circle.

Figure 14-9. Customer-based POI Lookup: Bounding box
We can calculate the coordinates of the corner points of the box, persist them in the table, and use a regular nonclustered index to pre-filter the data. This lets us minimize the number of expensive distance calculations to be performed.
Calculation of the bounding box corner points can be done with a CLR table-valued function, as shown in Listing 14-11. Listing 14-12 shows the T-SQL code that alters the table and creates a nonclustered index there.
Listing 14-11. Customer-based POI Lookup: Calculating bounding box coordinates
private struct BoundingBox
{
public double minLat;
public double maxLat;
public double minLon;
public double maxLon;
}
private static void CircleBoundingBox_FillValues(
object obj, out SqlDouble MinLat, out SqlDouble MaxLat,
out SqlDouble MinLon, out SqlDouble MaxLon)
{
BoundingBox box = (BoundingBox)obj;
MinLat = new SqlDouble(box.minLat);
MaxLat = new SqlDouble(box.maxLat);
MinLon = new SqlDouble(box.minLon);
MaxLon = new SqlDouble(box.maxLon);
}
[Microsoft.SqlServer.Server.SqlFunction(
DataAccess = DataAccessKind.None,
IsDeterministic = true, IsPrecise = false,
SystemDataAccess = SystemDataAccessKind.None,
FillRowMethodName = "CircleBoundingBox_FillValues",
TableDefinition = "MinLat float, MaxLat float, MinLon float, MaxLon float"
)]
public static IEnumerable CalcCircleBoundingBox(SqlDouble lat, SqlDouble lon, SqlInt32 distance)
{
if (lat.IsNull || lon.IsNull || distance.IsNull)
return null;
BoundingBox[] box = new BoundingBox[1];
double latR = Math.PI / 180 * lat.Value;
double lonR = Math.PI / 180 * lon.Value;
double rad45 = 0.785398163397448300; // RADIANS(45.)
double rad135 = 2.356194490192344800; // RADIANS(135.)
double rad225 = 3.926990816987241400; // RADIANS(225.)
double rad315 = 5.497787143782137900; // RADIANS(315.)
double distR = distance.Value * 1.4142135623731 * Math.PI / 20001600.0;
double latR45 = Math.Asin(Math.Sin(latR) * Math.Cos(distR) + Math.Cos(latR) * Math.Sin(distR) * Math.Cos(rad45));
double latR135 = Math.Asin(Math.Sin(latR) * Math.Cos(distR) + Math.Cos(latR) * Math.Sin(distR) * Math.Cos(rad135));
double latR225 = Math.Asin(Math.Sin(latR) * Math.Cos(distR) + Math.Cos(latR) * Math.Sin(distR) * Math.Cos(rad225));
double latR315 = Math.Asin(Math.Sin(latR) * Math.Cos(distR) + Math.Cos(latR) * Math.Sin(distR) * Math.Cos(rad315));
double dLonR45 = Math.Atan2(Math.Sin(rad45) * Math.Sin(distR) * Math.Cos(latR),
Math.Cos(distR) - Math.Sin(latR) * Math.Sin(latR45));
double dLonR135 = Math.Atan2(Math.Sin(rad135) * Math.Sin(distR) * Math.Cos(latR),
Math.Cos(distR) - Math.Sin(latR) * Math.Sin(latR135));
double dLonR225 = Math.Atan2(Math.Sin(rad225) * Math.Sin(distR) * Math.Cos(latR),
Math.Cos(distR) - Math.Sin(latR) * Math.Sin(latR225));
double dLonR315 = Math.Atan2(Math.Sin(rad315) * Math.Sin(distR) * Math.Cos(latR),
Math.Cos(distR) - Math.Sin(latR) * Math.Sin(latR315));
double lat45 = latR45 * 180.0 / Math.PI;
double lat225 = latR225 * 180.0 / Math.PI;
double lon45 = (((lonR - dLonR45 + Math.PI) % (2 * Math.PI)) - Math.PI) * 180.0 / Math.PI;
double lon135 = (((lonR - dLonR135 + Math.PI) % (2 * Math.PI)) - Math.PI) *180.0 / Math.PI;
double lon225 = (((lonR - dLonR225 + Math.PI) % (2 * Math.PI)) - Math.PI) *180.0 / Math.PI;
double lon315 = (((lonR - dLonR315 + Math.PI) % (2 * Math.PI)) - Math.PI) *180.0 / Math.PI;
box[0].minLat = Math.Min(lat45, lat225);
box[0].maxLat = Math.Max(lat45, lat225);
box[0].minLon = Math.Min(Math.Min(lon45, lon135), Math.Min(lon225,lon315));
box[0].maxLon = Math.Max(Math.Max(lon45, lon135), Math.Max(lon225, lon315));
return box;
}
Listing 14-12. Customer-based POI Lookup: Altering the table
alter table dbo.LocationsGeo2 add MinLat decimal(9,6);
alter table dbo.LocationsGeo2 add MaxLat decimal(9,6);
alter table dbo.LocationsGeo2 add MinLon decimal(9,6);
alter table dbo.LocationsGeo2 add MaxLon decimal(9,6);
update t
set
t.MinLat = b.MinLat
,t.MinLon = b.MinLon
,t.MaxLat = b.MaxLat
,t.MaxLon = b.MaxLon
from
dbo.LocationsGeo2 t cross apply
dbo.CalcCircleBoundingBox(t.Location.Lat,t.Location.Long,1609) b;
create index IDX_LocationsGeo2_BoundingBox
on dbo.LocationsGeo2(CompanyId, MinLon, MaxLon)
include (MinLat, MaxLat);
Now you can change the query to utilize the bounding box. The query is shown in Listing 14-13. The execution plan is shown in Figure 14-10.
Listing 14-13. Customer-based POI Lookup: Query utilizing bounding box
declare
@Lat decimal(9,6) = 47.620309
,@Lon decimal(9,6) = -122.349563
,@CompanyId int = 15
declare
@g geography = geography::Point(@Lat,@Lon,4326)
select count(*)
from dbo.LocationsGeo2
where
Location.STDistance(@g) < 1609 and
CompanyId = @CompanyId and
@Lat between MinLat and MaxLat and
@Lon between MinLon and MaxLon

Figure 14-10. Customer-based POI Lookup: Execution plan (bounding box approach)
As you see, the last query calculated the distance 15 times. This is a significant improvement compared to the 241,402 calculations from the original query. The execution times are shown in Table 14-3.
Table 14-3. Customer-based POI Lookup: Execution times
Clustered index seek |
Spatial index |
Bounding box |
|---|---|---|
10,412 ms |
26 ms |
7 ms |
As you see, the bounding box outperforms both the clustered index seek and spatial index lookup. Obviously, this would be the case only when the bounding box reduces the number of the calculations to a degree that offsets the overhead of the nonclustered index seek and key lookup operations. It is also worth mentioning that you do not need a spatial index with such an approach.
You can also use a bounding box for the other use-cases; for example, when you are checking to see if a position belongs to the area defined by a polygon. The bounding box corner coordinates should store minimum and maximum latitude and longitude coordinates of the polygon’s corner points. Like the distance calculation, you would filter-out the locations outside of the box before performing an expensive spatial method call that validates if the point is within the polygon area.
HierarchyId
The HierarchyId data type helps you work with hierarchical data structures. It is optimized to represent trees, which are the most common type of hierarchical data.
![]() Note Coverage of HierarchyId data type methods is beyond the scope of this book. You can learn more about the HierarchyId data type at: http://technet.microsoft.com/en-us/library/bb677173.aspx.
Note Coverage of HierarchyId data type methods is beyond the scope of this book. You can learn more about the HierarchyId data type at: http://technet.microsoft.com/en-us/library/bb677173.aspx.
There are several techniques that allow us to store hierarchical information in a database. Let’s look at the most common ones:
- Adjacency List.This is perhaps the most commonly used technique. It persists the reference to the parent node in every child node. Such a structure is shown in Figure 14-11 and Listing 14-14.
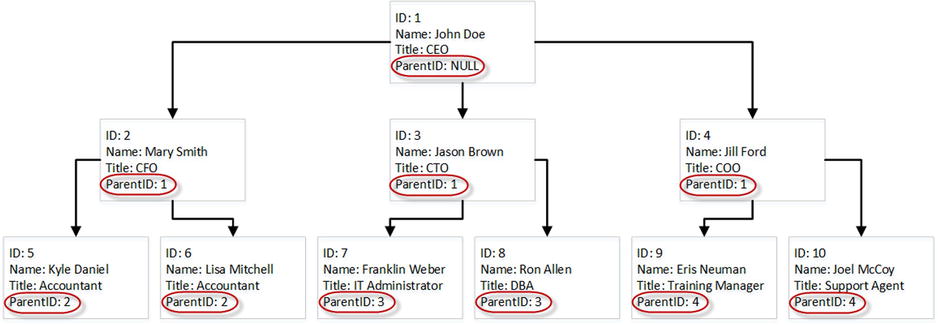
Figure 14-11. Adjacency List
Listing 14-14. Adjancency List DDL
create table dbo.OrgChart
(
ID int not null,
Name nvarchar(64) not null,
Title nvarchar(64) not null,
ParentID int null,
constraint PK_OrgChart
primary key clustered(ID),
constraint FK_OrgChart_OrgChart
foreign key(ParentId)
references dbo.OrgChart(ID)
)
- Closure Table.This is similar to an Adjacency List, however the parent-child relationship is stored separately. Figure 14-12 and Listing 14-15 show an example of a Closure Table.
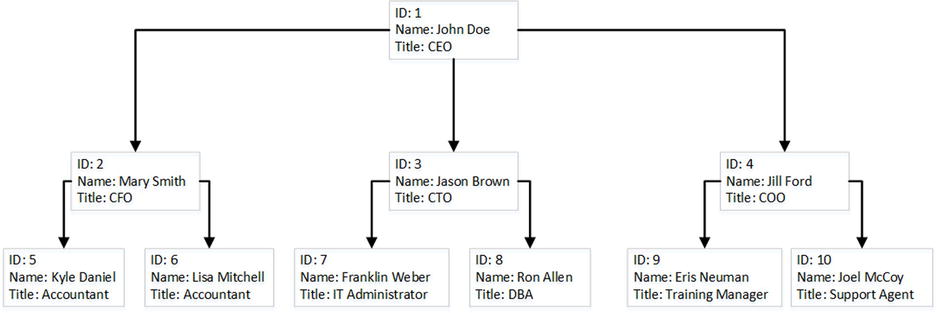
Figure 14-12. Closure Table
Listing 14-15. Closure Table DDL
create table dbo.OrgChart
(
ID int not null,
Name nvarchar(64) not null,
Title nvarchar(64) not null,
constraint PK_OrgChart
primary key clustered(ID),
);
create table dbo.OrgTree
(
ParentId int not null,
ChildId int not null,
constraint PK_OrgTree
primary key clustered(ParentId, ChildId),
constraint FK_OrgTree_OrgChart_Parent
foreign key(ParentId)
references dbo.OrgChart(ID),
constraint FK_OrgTree_OrgChart_Child
foreign key(ChildId)
references dbo.OrgChart(ID)
);
- Nested Sets.With Nested Sets, every node contains two values, called Left and Right Bowers. Child node bower values are within the interval of the parent node bowers. As a result, when you need to find all of the children of the parent, you can select all nodes with left and right bower values in between the parent values. Figure 14-13 and Listing 14-16 show an example of Nested Sets.

Figure 14-13. Nested Sets
Listing 14-16. Nested Sets DDL
create table dbo.OrgChart
(
ID int not null,
Name nvarchar(64) not null,
Title nvarchar(64) not null,
LeftBower float not null,
RightBower float not null,
constraint PK_OrgChart
primary key clustered(ID),
);
- Materialized Path. This persists the hierarchical path in every node by concatenating information about the parents up to the root of the hierarchy. As a result, you can find all child nodes by performing a prefix lookup based on the parent path. Some implementations store actual key values of the nodes in the path, while others store the relative position of the node in the hierarchy. Figure 14-14 shows an example of the latter. Listing 14-17 shows one possible implementation of such a method.
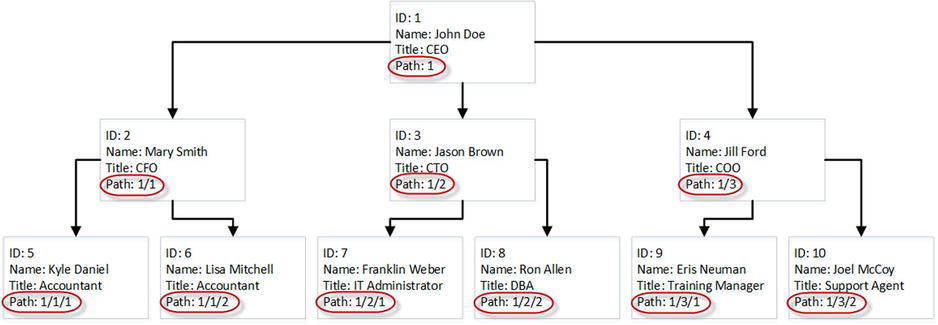
Figure 14-14. Materialized (hierarchical) Path
Listing 14-17. Materialized Path DDL
create table dbo.OrgChart
(
ID int not null,
Name nvarchar(64) not null,
Title nvarchar(64) not null,
Path varchar(256) not null,
constraint PK_OrgChart
primary key clustered(ID),
);
Each approach has its own strengths and weaknesses. Adjacency Lists and Closure Tables are easy to maintain—adding or removing new members to the hierarchy as well as subtree movement affects a single or very small number of the nodes. However, querying those structures often requires recursive or imperative code.
In contrast, Nested Sets and Materialized Paths are very easy to query, although hierarchy maintenance is expensive. For example, if you move the subtree to a different parent, you must update the corresponding bower or path values for each child in the subtree.
HierarchyId type uses the materialized path technique persisting relative path information similar to the example shown in Figure 14-14. The path information is stored in binary format. The actual storage space varies and depends on a few factors. Each level in the hierarchy adds an additional node to the path and increases its size.
Another important factor is how a new HierarchyId value is generated. As already mentioned, HierarchyId stores the relative positions rather than the absolute key values from the nodes. As a result, if you need to add a new child node at the rightmost node to the parent, you can increment the value from the former rightmost node. However, if you need to add the node in between two existing nodes, that would require persisting additional information in the path. Figure 14-15 shows an example of this.
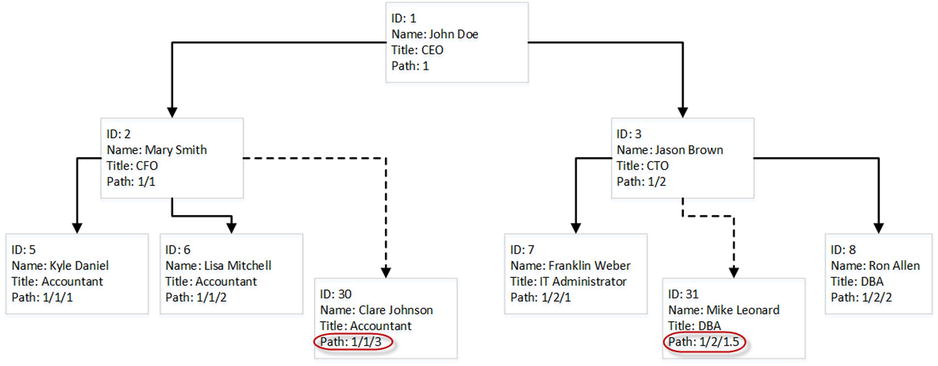
Figure 14-15. Inserting data
Let’s test how HierarchyId generation affects the path size and create the table shown in Listing 14-18.
Listing 14-18. HierarchyId: Test table
create table dbo.HierarchyTest
(
ID hierarchyid not null,
Level tinyint not null
)
The code shown in Listings 14-19 and 14-20 creates an eight-level hierarchy with eight children per node. We will compare the average data size of HierarchyId data when children nodes are inserted as the rightmost nodes (Listing 14-19) and when they are inserted in between existing nodes (Listing 14-20).
Listing 14-19. HierarchyId: Adding children nodes as rightmost nodes
truncate table dbo.HierarchyTest
go
declare
@MaxLevels int = 8
,@ItemPerLevel int = 8
,@Level int = 2
insert into dbo.HierarchyTest(ID, Level) values(hierarchyid::GetRoot(), 1);
while @Level <= @MaxLevels
begin
;with CTE(ID, Child, Num)
as
(
select ID, ID.GetDescendant(null,null), 1
from dbo.HierarchyTest
where Level = @Level - 1
union all
select ID, ID.GetDescendant(Child,null), Num + 1
from CTE
where Num < @ItemPerLevel
)
insert into dbo.HierarchyTest(ID, Level)
select Child, @Level
from CTE
option (maxrecursion 0)
set @Level += 1
end;
select avg(datalength(ID)) from dbo.HierarchyTest;
Result:
-----------
5
Listing 14-20. HierarchyId: Adding children nodes in-between existing nodes
truncate table dbo.HierarchyTest
go
declare
@MaxLevels int = 8
,@ItemPerLevel int = 8
,@Level int = 2
insert into dbo.HierarchyTest(ID, Level) values(hierarchyid::GetRoot(), 1);
while @Level <= @MaxLevels
begin
;with CTE(ID, Child, PrevChild, Num)
as
(
select ID, ID.GetDescendant(null,null), convert(hierarchyid,null), 1
from dbo.HierarchyTest
where Level = @Level - 1
union all
select ID,
case
when PrevChild < Child
then ID.GetDescendant(PrevChild, Child)
else ID.GetDescendant(Child, PrevChild)
end, Child, Num + 1
from CTE
where Num < @ItemPerLevel
)
insert into dbo.HierarchyTest(ID, Level)
select Child, @Level
from CTE
option (maxrecursion 0)
set @Level += 1
end;
select avg(datalength(ID)) from dbo.HierarchyTest;
Result:
-----------
11
As you see, adding children in between existing nodes in the hierarchy more than doubled the size of the path stored.
![]() Note The HierarchyId data type has an additional two bytes of overhead stored in variable-length data offset array in every row.
Note The HierarchyId data type has an additional two bytes of overhead stored in variable-length data offset array in every row.
The key point that you need to remember is that the HierarchyId data type persists a hierarchical path, and it provides a set of methods that help when working with hierarchical data. It does not enforce the correctness of the hierarchy stored in a table, nor the uniqueness of the values. It is your responsibility to enforce it in the code.
Maintenance of hierarchical data is expensive. Changing the path for the node with the children requires an update of the path in every child node. This leads to the update of multiple rows in the table. Moreover, the HierarchyId column is usually indexed, which introduces physical data movement and additional index fragmentation, especially when the HierarchyId column is part of a clustered index. You need to keep this in mind when designing an index maintenance strategy for tables with HierarchyId columns when the data is volatile.
Summary
User-defined CLR data types allow us to expand the standard SQL Server type library. Unfortunately, this flexibility has a price. CLR data types are stored in the database in binary format and accessing the object properties and methods leads to deserialization and CLR method calls. This can introduce serious performance issues when those calls are done for a large number of rows.
You can reduce the number of CLR calls by adding persistent calculated columns that store the results of frequently accessed properties and methods. At the same time, this increases the size of the rows and introduces the overhead when data is modified.
Another important aspect is maintainability. SQL Server does not support the ALTER TYPE operation. It is impossible to change the interface of existing methods or utilize new methods of the type until it is dropped and recreated.
Geometry and geography types help us work with spatial data. They provide a rich set of methods used to manipulate the data, although those methods are usually expensive and can lead to poor performance when called for a large number of a rows.
Spatial indexes can address some performance issues, although they work within the scope of the entire table. All further predicate evaluation is done on later execution stages. This leads to suboptimal performance when spatial operations are done on subsets of the data. You can use a bounding box approach and filter out the rows prior to calling spatial methods to address this issue.
HierarchyId types provide built-in support for hierarchical data. Although it has excellent query performance, hierarchy maintenance is expensive. Every change in the hierarchy requires an update of the hierarchical path in every child node. You must consider such overhead when data is volatile.
HierarchyId types do not enforce correctness of the hierarchical structure. That must be done in the code. You should also avoid inserting new nodes in between existing ones because it increases the size of the path stored.
Finally, support of system- and user-defined CLR types is not consistent across different development platforms. You need to make sure that client applications can utilize them before making the decision to use them. Alternatively, you can hide those types behind the data-access tier with T-SQL stored procedures when it is possible and feasible.