
![]()
Transaction Log Internals
As you already know, every database in SQL Server has one or more transaction log files in addition to data files. Transaction logs store the information about all of the changes made in the database, and they allow SQL Server to recover databases to transactionally consistent states in case of an unexpected shut down or crash.
In this chapter, we will examine the internal structure of the transaction log, discuss how SQL Server logs data modifications, and review how it performs database crash recovery. We will also cover how to diagnose excessive transaction log growth and discuss a few best practices related to log management and I/O file placement.
Data Modifications, Logging, and Recovery
SQL Server always keeps databases in a transactionally consistent state. Data modifications done from within transactions must either be committed or rolled back in full. SQL Server never allows data to be transactionally inconsistent by applying just a subset of the changes from uncommitted transactions.
This is true even when SQL Server shuts down unexpectedly. Every time SQL Server restarts, it runs a recovery process on every database in the instance. SQL Server rolls back (undo) all changes from uncommitted transactions and re-applies (redo) all changes done by committed transactions if they have not been saved into data files at the time of the shutdown or crash.
The same process happens when you restore a database from the backup. There is no guarantee that all transactions would have been completed at the time when the backup was run. Therefore, SQL Server needs to recover the database as the final step of the restore process.
![]() Note We will discuss the database backup and restore process in greater detail in Chapter 30, “Designing a Backup Strategy.”
Note We will discuss the database backup and restore process in greater detail in Chapter 30, “Designing a Backup Strategy.”
The transaction log guarantees the transactional consistency of the data in the database. It consists of the stream of the log records generated by data modification operations. Every log record has a unique, auto-incrementing Log Sequence Number (LSN), and it also describes the data change. It includes the information about the operation and affected row; the old and new version of the data; the transaction that performed the modification; and so forth. Moreover, some internal operations, such as CHECKPOINT, generate their own log records.
Every data page keeps the LSN of the last log record that modified it. At the recovery stage, SQL Server can compare the LSNs of the log records from the log and data pages and find out if the most recent changes were saved to the data files. There is enough information stored in a log record to undo or redo the operation if needed.
SQL Server uses Write-Ahead Logging, which guarantees that log records are always written to the log file before dirty data pages are saved to the database. In Chapter 1, I mentioned that log records are saved synchronously with data modifications, while data pages are saved asynchronously during the CHECKPOINT process. That is not 100 percent accurate, however. SQL Server caches log records in the small (about 60KB per database) memory cache called Log Buffer saving multiple log records at once. This helps reduce the number of physical I/O operations required.
Now let’s look at how data modifications work in greater detail. Let’s assume that we have a system with an empty Log Buffer and the last LSN of 7213 in the transaction log, as shown in Figure 29-1. Let’s also assume that there are two active transactions: T1 and T2. Each of those transactions has BEGIN TRAN log records already saved in the transaction log.
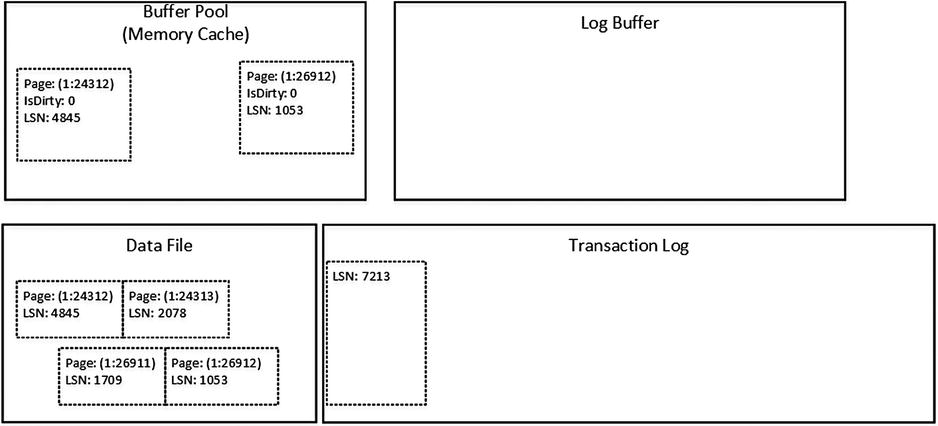
Figure 29-1. Data modifications: Initial State
As a first step, let’s assume that we have transaction T1, which updates one of the rows from page (1:24312). As you can see in Figure 29-2, this operation generates a new log record, which has been placed into the Log Buffer. In addition, it modifies data page marking it as dirty, updating the LSN in the page header, and changing the data row. Even though the log record has not been saved (hardened) to the log file, it is not critical as long as the data page has not been saved in the data file. Both log record and modifications on the data page will be gone in case of a SQL Server crash, which is fine because the transaction has not been committed.
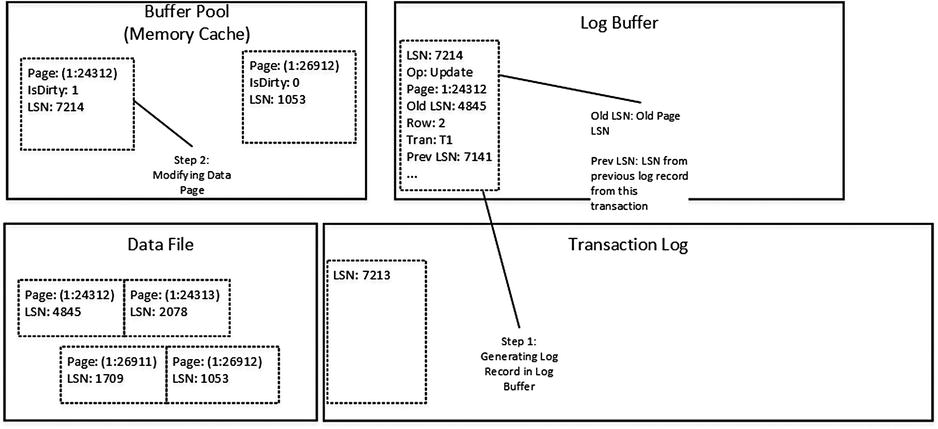
Figure 29-2. Data modifications: T1 updates one of the rows
Next, let’s assume that transaction T2 inserts a new row into page (1:26912) and transaction T1 deletes another row on the same page. Those operations generate two log records placed into log buffer, as shown in Figure 29-3.
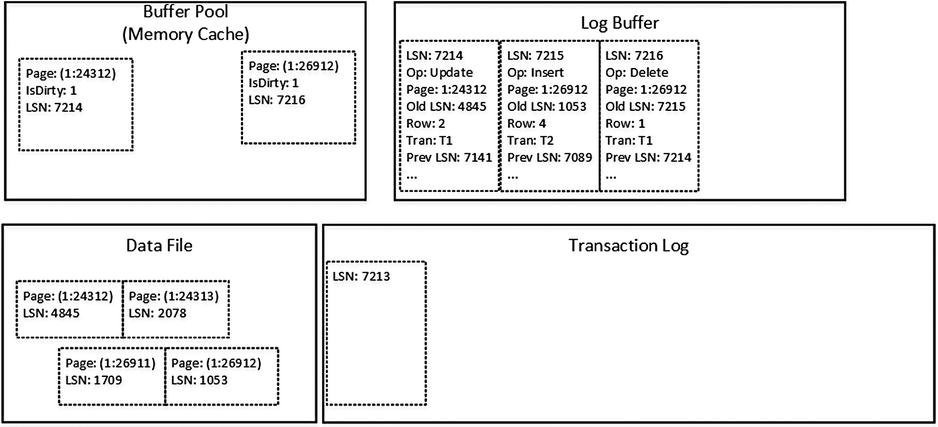
Figure 29-3. Data modifications: T1 and T2 changes data on another page
As you can see, all log records are still in the Log Buffer. Now let’s assume that transaction T2 wants to commit. This action generates another log record and forces SQL Server to flush the content of the Log Buffer to the disk, as shown in Figure 29-4. SQL Server hardens all of the log records from the Log Buffer into the transaction log, regardless of the transactions that generated them.
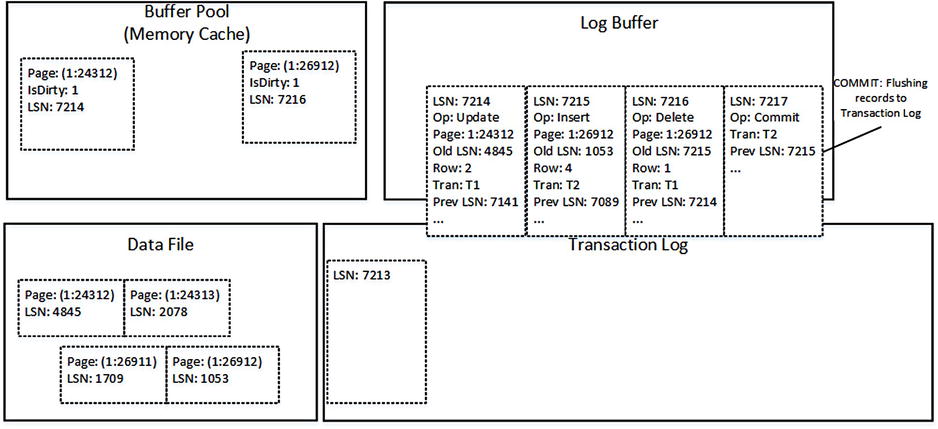
Figure 29-4. Data modifications: Commit
Client applications would receive confirmation that the transaction is committed only after all log records are hardened. Even though the data page (1:26912) is still dirty and has not been saved into the data file, hardened log records on the disk have enough information to re-apply (redo) all of the changes done by the committed T2 transaction. Thus it guarantees no data loss in case of a SQL Server crash.
![]() Tip Updating multiple rows from within a transaction allows SQL Server to buffer transaction log I/O operations, saving multiple records at once. It is more efficient compared to multiple transactions, each updating a single row, and forcing SQL Server to flush the log buffer on every commit operation.
Tip Updating multiple rows from within a transaction allows SQL Server to buffer transaction log I/O operations, saving multiple records at once. It is more efficient compared to multiple transactions, each updating a single row, and forcing SQL Server to flush the log buffer on every commit operation.
Nevertheless, remember locking behavior and avoid situations where the system holds a large number of exclusive (X) locks for an extended period of time.
At this point, the system has log records hardened in transaction log even though the data pages in the data files have yet to be updated. The next CHECKPOINT process saves dirty data pages and marks them as clean in the Buffer Pool. CHECKPOINT also generates its own log record, as shown in Figure 29-5.
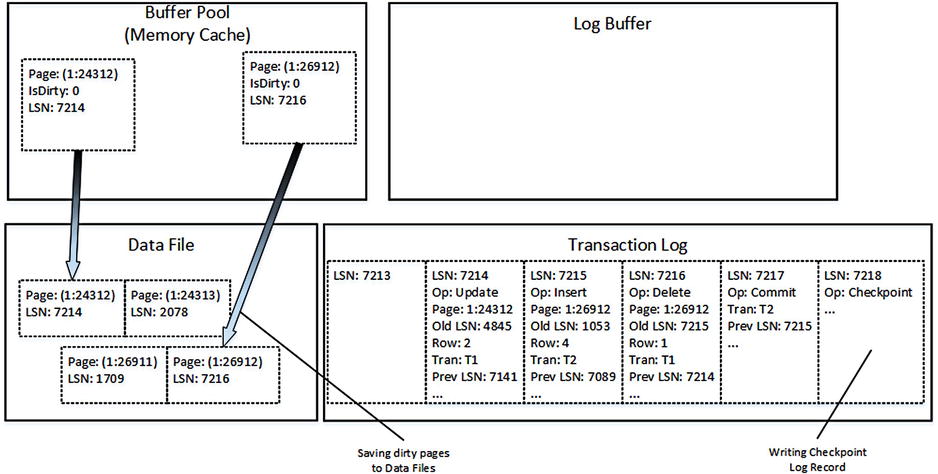
Figure 29-5. Data modifications: CHECKPOINT
At this time, pages in the data file store data from uncommitted transaction T1. However, log records in the transaction log have enough information to undo the changes if needed. When this is the case, SQL Server performs compensation operations, which execute the opposite actions of the original data modifications and generate compensation log records.
Figure 29-6 shows such an example. SQL Server performed a compensation update generating the compensation log record with an LSN of 7219 to reverse the changes of the original update operation with an LSN of 7214. It also generated a compensation insert with an LSN of 7920 to compensate the delete operation with an LSN of 7216.
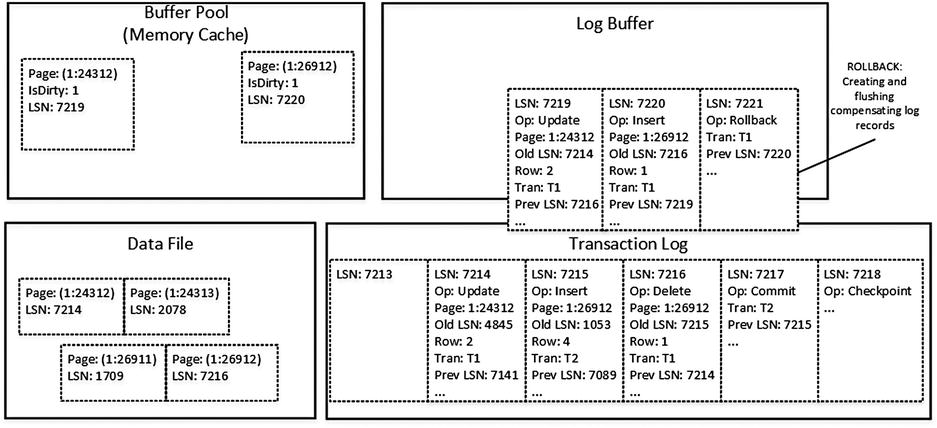
Figure 29-6. Data modifications: ROLLBACK
A write-ahead logging mechanism guarantees that dirty data pages are never saved into the data files until the corresponding log records are hardened in the transaction log. The opposite, however, is not true. The CHECKPOINT process is asynchronous, and there is a delay in between when log records are hardened and when pages in the data files are updated. Moreover, CHECKPOINT does not analyze if the transactions that modified data pages were actually committed. Therefore, some pages in the data files reflect changes from uncommitted transactions.
The goal of the recovery process is to make the database transactionally consistent. SQL Server analyzes the transaction log, making sure that all changes from committed transactions are saved into the data files and all changes from uncommitted transactions are rolled back.
The recovery process consists of three different phases:
- During the analysis phase, SQL Server locates the last CHECKPOINT operation in the log file, which is the last time dirty pages were saved into the data file. SQL Server builds the list of pages that were modified after CHECKPOINT as well as the list of uncommitted transactions at the time when SQL Server stopped.
- During the redo phase, SQL Server analyzes the transaction log from the initial LSN of the oldest active transaction at the moment of the crash, which is stored in the database boot page, and applies the changes to the data. Even though some of the changes could already be saved to the data files, SQL Server acquires locks on the modified rows similar to a regular workload. At the end of redo phase, the database is then in the state that it was at the time when SQL Server shut down unexpectedly.
- Finally, during the undo phase, SQL Server rolls back all active, uncommitted transactions.
Figure 29-7 shows an example of a recovery scenario for the database. SQL Server will redo and commit transactions T2 and T3 and roll back transaction T4.
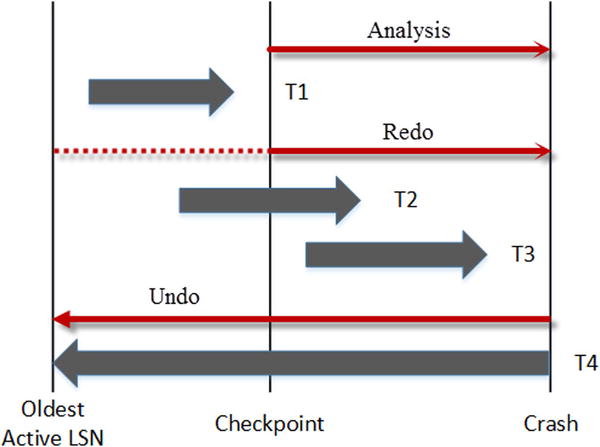
Figure 29-7. Database recovery
The recovery process uses a single thread per database. The Enterprise edition of SQL Server supports fast recovery, which makes the database available to users after the redo stage.
Delayed Durability (SQL Server 2014)
Delayed durability, also known as Lazy Commit, is a new feature of SQL Server 2014. As already discussed, by default, a commit operation is synchronous. SQL Server flushes the content of Log Buffer hardening log records into a log file at the time of commit, and it sends a confirmation to the client, only after a commit record is written to disk. Delayed durability changes this behavior making the commit operation asynchronous. The client receives the confirmation that the transaction is committed immediately without waiting for the commit record to be hardened to disk. The commit record stays in a log buffer until its content is flushed, which happens in one of the following cases:
- The log buffer is full.
- A fully durable transaction in the same database is committed. The commit record from such a transaction flushes the content of the log buffer to disk.
- A CHECKPOINT operation occurs.
- A sp_flush_logstored procedure is completed successfully.
If SQL Server crashed before the commit record is hardened, the data modifications from that transaction would be rolled back at recovery as if the transaction had never been committed at all. However, other transactions would be able to see the data modifications done by such a transaction in between the time of commit and the SQL Server crash.
![]() Note Data loss is also possible in the case of a regular SQL Server shutdown. Even though SQL Server tries to flush log buffers at the time of shutdown, there is no guarantee that this operation will succeed.
Note Data loss is also possible in the case of a regular SQL Server shutdown. Even though SQL Server tries to flush log buffers at the time of shutdown, there is no guarantee that this operation will succeed.
Delayed durability may be a good choice for systems that experience a bottleneck in transaction log writes and that can tolerate a small data loss. Fortunately, due to the limited size of a log buffer, the possibility of such an event occurring is relatively small.
One database option, DELAYED_DURABILITY, controls the behavior of delayed durability in the database scope. It may have one of three options.
- DISABLED: This option disables delayed durability for database transactions regardless of the transaction durability mode. All transactions in the database are always fully durable. This is the default option and matches behavior of previous versions of SQL Server.
- FORCED: This option forces delayed durability for database transactions regardless of the transaction durability mode.
- ALLOWED: Delayed durability is controlled at the transaction level. Transactions are fully durable unless delayed durability is specified.
It is worth noting that in the case of cross database or distributed transactions; all transactions are fully durable regardless of their settings. The same applies to Change Tracking and Change Data Capture technologies. Any transaction that updates tables that are enabled for either of those technologies will be fully durable.
You can control transaction durability by specifying the durability mode in the COMMIT operator. Listing 29-1 shows an example of a transaction that uses delayed durability. As already mentioned, the DELAYED_DURABILITY database option can override that setting.
Listing 29-1. Transaction with delayed durability
begin tran
/* Do something */
commit with (delayed_durability=on)
Any other SQL Server technologies that work with the transaction log would see and process commit records from transactions with delayed durability only after those records were hardened in the log and, therefore become durable in the database. For example, if a database backup finishes in between a transaction commit and log buffer flush, the commit log record would not be included in the backup and, therefore, the transaction would be rolled back at the time of a restore.
Another example is AlwaysOn Availability Groups. Secondary nodes will receive commit records only after those records are hardened in the log on the primary node and transmitted over network.
![]() Note We will discuss database backup and restore processes in detail in Chapter 30, “Designing a Backup Strategy,” and about AlwaysOn Availability Groups in Chapter 31, “Designing a High Availability Strategy.”
Note We will discuss database backup and restore processes in detail in Chapter 30, “Designing a Backup Strategy,” and about AlwaysOn Availability Groups in Chapter 31, “Designing a High Availability Strategy.”
Virtual Log Files
Even though a transaction log can have multiple files, SQL Server works with it in a sequential manner while writing and reading a stream of log records. As a result, SQL Server does not benefit from the multiple physical log files.
Internally, SQL Server divides every physical log file into smaller sections called Virtual Log Files (VLF). SQL Server uses virtual log files as a unit of management, which can be either active or inactive.
A VLF is active when it stores the active portion of the transaction log, which contains the stream of log records required to keep the database transactionally consistent in the event of a transaction rollback or unexpected SQL Server shutdown. For now, do not focus on what keeps log active; we will examine this later in the chapter. An inactive VLF contains the truncated (inactive) and unused parts of the transaction log.
Figure 29-8 shows an example of a transaction log and virtual log files.
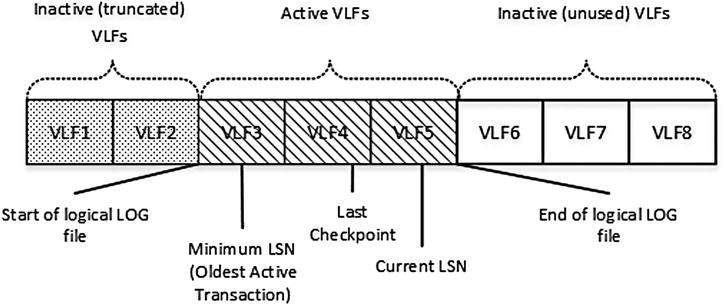
Figure 29-8. Transaction Log and Virtual Log Files
![]() Note Transaction log truncation does not reduce the size of the log file on disk. Truncation means that parts of transaction log (one or more VLFs) are marked as inactive and ready for reuse. It clears up the internal space in the log, keeping log file size intact.
Note Transaction log truncation does not reduce the size of the log file on disk. Truncation means that parts of transaction log (one or more VLFs) are marked as inactive and ready for reuse. It clears up the internal space in the log, keeping log file size intact.
A transaction log is a wraparound file. When the end of the logical log file reaches the end of physical file, the log wraps around it, as shown in Figure 29-9.
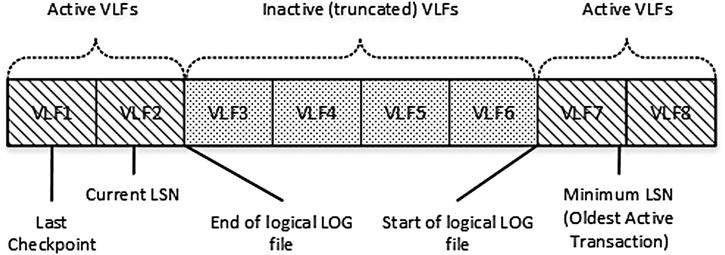
Figure 29-9. A Transaction Log is a wraparound file
SQL Server creates new virtual log files every time the log grows. The number of VLFs depends on the newly allocated space size as shown in Table 29-1.
Table 29-1. Allocation size and number of VLF created
Allocation Size |
Number of VLF Created |
|---|---|
<64MB |
4 VLFs |
64MB – 1GB |
8 VLFs |
>1GB |
16 VLFs |
You can examine virtual log files with the DBCC LOGINFO command. Figure 29-10 illustrates the output of such a command running against the master database on one SQL Server instance. It shows that the database has one physical log file with FileId = 2 and three virtual log files. Other columns indicate the following:
- Status is the status of VLF. Values 0 and 2 indicate inactive and active VLFs respectively.
- FileSize is the size of the VLF in bytes.
- StartOffset is the starting offset of the VLF in the file.
- CreateLSN is the LSN at the moment when the VLF was created. Zero means that the VLF was created at the database creation time.
- FSeqNo is the order of usage of the VLFs. The VLF with the highest FSeqNo is the file where the current log records are written.
- Parity can be one of two possible values: 64 and 128. SQL Server switches the parity value every time a VLF is reused. SQL Server uses the parity value to detect where to stop processing log records during a crash recovery.

Figure 29-10. DBCC LOGINFO output
There are three database recovery models that affect transaction log management and truncation behavior: SIMPLE, FULL, and BULK-LOGGED. While SQL Server logs enough information to roll back transactions and/or perform crash recovery regardless of the recovery model, they control when a log is truncated and when VLFs become inactive. You cannot access and redo any actions from the inactive part of the log, and therefore truncation affects the amount of potential work loss if data files are unavailable.
It is again worth mentioning that transaction log truncation does not reduce the size of the log file, but rather it marks VLFs as inactive and ready for reuse.
In the SIMPLE recovery model, SQL Server truncates the transaction log at CHECKPOINT. Let’s assume that you have a system with three active VLFs, as shown in Figure 29-11. The oldest active LSN is in VLF4. Therefore, there is the possibility that SQL Server will need to access log records from VLF4 and VLF5 in case of transaction rollbacks, which require SQL Server to keep VLF4 and VLF5 active.
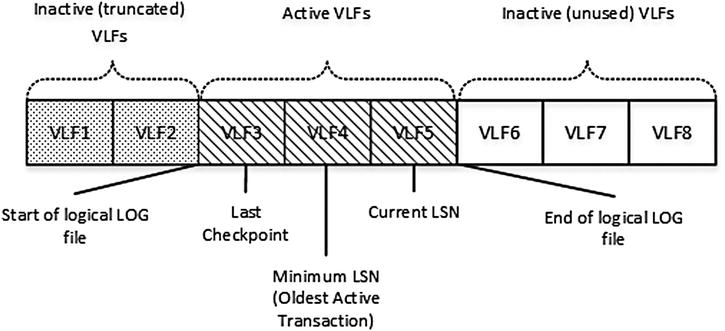
Figure 29-11. SIMPLE recovery model: Initial stage
There are no log records from the active transactions in VLF3, although some of the dirty data pages in the buffer pool may have corresponding log records stored there. SQL Server needs to access those records in case of a crash recovery to be able to redo the changes; therefore VLF3 should also be kept active.
When SQL Server performs a CHECKPOINT, all of the dirty data pages are saved into the data file. As a result, crash recovery does not need to redo any changes related to log records from VLF3, and it can be truncated and marked as inactive. However, VLF4 must be kept active to support the rollback of the transactions, which have corresponding log records stored in VLF4. Figure 29-12 illustrates this point.

Figure 29-12. SIMPLE recovery model: Log truncation after CHECKPOINT
Thus, in the SIMPLE recovery model, the active part of transaction log starts with VLF, which contains the oldest of LSN of the oldest active transaction or the last CHECKPOINT.
![]() Note An active database backup can defer transaction log truncation until it is completed.
Note An active database backup can defer transaction log truncation until it is completed.
As you can guess, even though SQL Server supports crash recovery in the SIMPLE model, you should keep both data and log files intact to avoid data loss and to keep the database transactionally consistent.
Alternatively, with the FULL or BULK-LOGGED recovery models, SQL Server supports transaction log backups, which allow you to recover the database and avoid data loss regardless of the state of the data files, as long as the transaction log is intact. This assumes, of course, that a proper set of backups is available.
![]() Note We will talk about the backup and recovery process in greater detail in Chapter 30, “Designing a Backup Strategy.”
Note We will talk about the backup and recovery process in greater detail in Chapter 30, “Designing a Backup Strategy.”
In the FULL and BULK-LOGGED recovery model, SQL Server requires you to perform transaction log backup in order to trigger log truncation. Moreover, truncation can be delayed if you have other processes that need to read the transaction log records. Think about Transactional Replication, Database Mirroring, and AlwaysOn Availability Groups as examples of such processes.
Figure 29-13 shows one example. Both minimum and current LSNs are in VLF5, although the LSN of the last transaction log backup is in VLF3. Therefore, the active portion of transaction log includes VLF3, VLF4, and VLF5.

Figure 29-13. FULL and BULK-LOGGED recovery models: Initial Stage
After another transaction log backup, SQL Server can truncate VLF3. However, VLF4 must remain active because the Replication Log Reader has yet to process some of the log records from VLF4. Figure 29-14 illustrates this point.
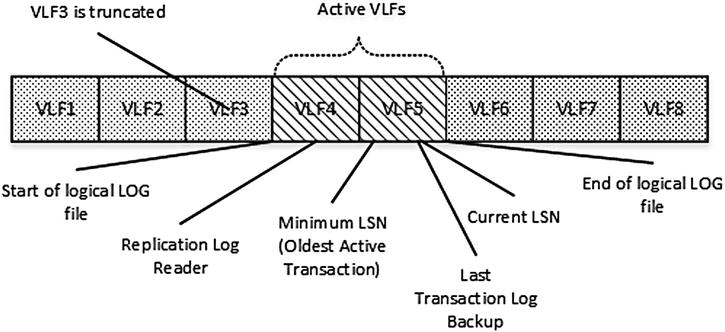
Figure 29-14. FULL and BULK-LOGGED recovery models: Log truncation
As you can see, in the FULL or BULK-LOGGED recovery models, the active part of transaction log starts with VLF, which contains the oldest of the following:
- LSN of the last log backup
- LSN of the oldest active transaction
- LSN of the process that reads transaction log records
![]() Important FULL database backup does not truncate the transaction log. You should perform transaction log backup in order to do so.
Important FULL database backup does not truncate the transaction log. You should perform transaction log backup in order to do so.
The difference between the FULL and BULK-LOGGED recovery models is in how SQL Server logs bulk copy operations, such as CREATE INDEX, ALTER INDEX REBUILD, BULK INSERT, INSERT INTO, INSERT SELECT, and a couple of others. In the FULL recovery model, those operations are fully logged. SQL Server writes log records for every data row affected by the operation. Alternatively, in the BULK-LOGGED recovery model, SQL Server does not log bulk copy operations on a row-by-row basis; rather it logs extents allocation instead. All bulk operations generate new (or a copy of existing) objects, and extents deallocation rolls back the changes.
![]() Note The SIMPLE recovery model logs bulk operations in a similar manner as the BULK-LOGGED recovery model.
Note The SIMPLE recovery model logs bulk operations in a similar manner as the BULK-LOGGED recovery model.
The BULK-LOGGED recovery model reduces transaction log load during bulk operations, but it comes at price. First, SQL Server is not able to perform point-in-time recovery if bulk operations were running at a particular time. Moreover, SQL Server must have access to the data files while performing log backups, and it stores data pages modified by bulk operations as part of the backup file. This can lead to data loss if data files become unavailable in between log backups. It is worth mentioning that non-bulk operations are always fully logged in the BULK-LOGGED model, like they are in the FULL recovery model.
Choosing the right recovery model is a very important decision that dictates the potential amount of data loss in case of disaster. It is an essential part of designing backup and disaster recovery strategies, which we will discuss in the next chapter, “Designing a Backup Strategy.”
TempDB Logging
All user objects in tempdb must be transactionally consistent. SQL Server must be able to roll back transactions that change data in tempdb in the same way as in the users’ databases. However, tempdb is always recreated at SQL Server startup. Therefore, logging in tempdb does not need to support the redo stage of crash recovery. Log records in tempdb store just the old values from the modified data rows, omitting new values.
This behavior makes tempdb a good candidate for a staging area for ETL processes. Data modifications in tempdb are more efficient as compared to users’ databases due to the lower amount of logging involved. Log records are not part of transaction log activity in users’ databases, which reduces the size of log backups. Moreover, those modifications are not transmitted over the network if any transaction-log based high availability technologies are in use.
![]() Note We will talk about high availability technologies in greater detail in Chapter 31, “Designing High Availability Strategy.”
Note We will talk about high availability technologies in greater detail in Chapter 31, “Designing High Availability Strategy.”
As we discussed in Chapter 12 “Temporary Tables,” using tempdb as a staging area introduces a set of challenges during implementation. All of the data stored in tempdb would be lost in the case of a SQL Server restart or failover to another node. The code must be aware of such a possibility and handle it accordingly.
Excessive Transaction Log Growth
Excessive transaction log growth is one of the common problems that junior or accidental database administrators have to handle. It happens when SQL Server is unable to truncate the transaction log and reuse the space in the log file. In such a case, the log file continues to grow until it fills the entire disk, switching the database to read-only mode with this 9002 error: “Transaction log full.”
There are plenty of reasons SQL Server is unable to truncate the transaction log. You can examine the log_reuse_wait_desc column in the sys.databases view to discover the reason the transaction log cannot be reused. You can see the query, which checks log_reuse_wait_desc for the users’ databases in Listing 29-2. The output of the query is shown in Figure 29-15.
Listing 29-2. Check log_reuse_wait_desc for users’ databases
select database_id, name, recovery_model_desc, log_reuse_wait_desc
from sys.databases
where database_id >=5

Figure 29-15. Log_reuse_wait_desc output
For databases in the FULL or BULK-LOGGED recovery models, one of the most common reasons the transaction log is not truncated is the lack of log backups. It is a common misconception that a FULL database backup truncates the transaction log. It is not true, and you must perform log backup in order to do so. The Log_reuse_wait_desc value of LOG_BACKUP indicates such a condition.
The Log_reuse_wait_desc value of ACTIVE_TRANSACTION indicates that there are long and/or uncommitted transactions in the system. SQL Server is unable to truncate the transaction log past the LSN of the oldest uncommitted transaction, regardless of the database recovery model in use.
The query in Listing 29-3 returns the list of the five oldest uncommitted transactions in the current database. It returns the time when the transaction was started, information about the session, and log usage statistics.
Listing 29-3. Query that returns a list of the five oldest active transactions in the system
select top 5
ses_tran.session_id as [Session Id]
,es.login_name as [Login]
,es.host_name as [Host]
,es.program_name as [Program]
,es.login_time as [Login Time]
,db_tran.database_transaction_begin_time as [Tran Begin Time]
,db_tran.database_transaction_log_record_count as [Log Records]
,db_tran.[database_transaction_log_bytes_used] as [Log Used]
,db_tran.[database_transaction_log_bytes_reserved] as [Log Rsrvd]
,sqlText.text as [SQL]
,qp.query_plan as [Plan]
from
sys.dm_tran_database_transactions db_tran join
sys.dm_tran_session_transactions ses_tran on
db_tran.transaction_id = ses_tran.transaction_id
join sys.dm_exec_sessions es on
es.[session_id] = ses_tran.[session_id]
left outer join sys.dm_exec_requests er on
er.session_id = ses_tran.session_id
join sys.dm_exec_connections ec on
ec.session_id = ses_tran.session_id
cross apply
sys.dm_exec_sql_text (ec.most_recent_sql_handle) sqlText
outer apply
sys.dm_exec_query_plan (er.plan_handle) qp
where
db_tran.database_id = DB_ID()
order by
db_tran.database_transaction_begin_time
![]() Tip You can use the query shown in Listing 29-3, sorting data by the Log Used column if you need to find transactions that consumed the most of log space.
Tip You can use the query shown in Listing 29-3, sorting data by the Log Used column if you need to find transactions that consumed the most of log space.
As I mentioned, SQL Server has many processes that read the transaction log, such as Transactional Replication, Change Data Capture, Database Mirroring, AlwaysOn Availability Groups, and others. Any of these processes can prevent transaction log truncation where there is a backlog. While it rarely happens when everything is working as expected, you may experience this issue in case of an error.
A common example of this situation is an unreachable secondary node in an Availability Group or Database Mirroring session. Log records, which have not been sent to the secondaries, will remain part of the active transaction log. This prevents its truncation. The Log_reuse_wait_desc column value would indicate this condition.
![]() Note You can see the list of possible log_reuse_wait_desc values at: http://technet.microsoft.com/en-us/library/ms178534.aspx.
Note You can see the list of possible log_reuse_wait_desc values at: http://technet.microsoft.com/en-us/library/ms178534.aspx.
If you experience a 9002 Transaction log full error, the key point is not to panic. The worst thing you can do is to perform an action that makes the database transactionally inconsistent. For example, shutting down SQL Server or detaching the database and deleting the transaction log file afterwards will do just that. If the database had not been shut down cleanly, SQL Server may not be able to recover it because the transaction log is missing.
Another very bad practice is to use the BACKUP LOG WITH TRUNCATE_ONLY command in the production environment to force transaction log truncation without a log backup. Even though it truncates the transaction log, it breaks the backup chain, which prevents you from properly restoring the database in case of a disaster. This command has been removed in SQL Server 2008 (though it still exists in SQL Server 2005).
![]() Note You can start a new backup chain by performing a FULL backup.
Note You can start a new backup chain by performing a FULL backup.
Creating another log file could be the fastest and simplest way to address this issue, however it is hardly the best option in the long run. Multiple log files complicate database management. Moreover, it is hard to drop the log files. SQL Server does not allow you to drop log files if they store an active portion of the log.
You must understand why the transaction log cannot be truncated and react accordingly. You can perform a log backup, identify and kill sessions that keep uncommitted active transactions, or remove an unreachable secondary node from the availability group depending on the root cause of the problem.
Transaction Log Management
It is better to manage transaction log size manually than to allow SQL Server to auto-grow it. Unfortunately, it is not always easy to determine optimal log size. On one hand, you want the transaction log to be big enough to avoid auto-growth events. On the other hand, you would like to keep the log small, saving disk space and reducing the time required to zero-initialize the log when the database is restored from a backup.
![]() Tip Remember to keep some space reserved in the log file if you are using any high-availability or other technologies that rely on transaction log records. SQL Server is not able to truncate transaction logs during log backups if something goes wrong with those processes. Moreover, you should implement a monitoring and notification framework, which alerts you to such conditions and gives you time to react before the transaction log becomes full.
Tip Remember to keep some space reserved in the log file if you are using any high-availability or other technologies that rely on transaction log records. SQL Server is not able to truncate transaction logs during log backups if something goes wrong with those processes. Moreover, you should implement a monitoring and notification framework, which alerts you to such conditions and gives you time to react before the transaction log becomes full.
Another important factor is the number of VLFs in the log files. You should avoid the situation where the transaction log becomes overly fragmented and has a large number of small VLFs. Similarly, you should avoid the situation where the log has too few, very large VLFs.
For the databases that require a large transaction log, you can pre-allocate space using 8000MB chunks, which generates 16 VLFs of 500MB each. If a database does not require a large (more than 8000MB) transaction log, you can pre-allocate log space in one operation based on the size requirements.
![]() Note There is a bug in SQL Server 2005-2008R2, which incorrectly grows the transaction log if its size is in multiples of 4GB. You can use multiples of 4000MB instead. This bug has been fixed in SQL Server 2012.
Note There is a bug in SQL Server 2005-2008R2, which incorrectly grows the transaction log if its size is in multiples of 4GB. You can use multiples of 4000MB instead. This bug has been fixed in SQL Server 2012.
You should still allow SQL Server to auto-grow the transaction log in case of an emergency. However, choosing the right auto-growth size is tricky. For databases with large transaction logs, it is wise to use 8000MB to reduce the number of VLFs. However, zeroing-out 8000MB of newly allocated space can be time consuming. All database activities that write to the log file are blocked during the auto-growth process. This is another argument for manual transaction log size management.
![]() Tip The decision of what auto-growth size should be used depends on the performance of the I/O subsystem. You should analyze how long zero-initialization takes and find a sweet spot where the auto-growth time and the size of the generated VLFs are acceptable. 1GB auto-growth could work in many cases.
Tip The decision of what auto-growth size should be used depends on the performance of the I/O subsystem. You should analyze how long zero-initialization takes and find a sweet spot where the auto-growth time and the size of the generated VLFs are acceptable. 1GB auto-growth could work in many cases.
SQL Server writes to the transaction log synchronously in the case of data modifications. OLTP systems, with volatile data and heavy transaction log activity, should have the transaction log stored on a disk array with good write performance and low latency. Transaction log I/O performance is less important when the data is static, for example in data warehouse systems; however, you should consider how it affects the performance and duration of the processes that refresh data there.
Best practices suggest storing the transaction log on a dedicated disk array optimized for sequential write performance. This is great advice for the situation where an underlying I/O subsystem has enough power to accommodate multiple high-performance disk arrays. In some cases, however, when faced with budget constraints and not enough disk drives, you can achieve better I/O performance by storing data and log files on a single disk array. You should remember, however, that keeping data and log files on the same disk array could lead to data loss in case of a disk array failure.
Another important factor is the number of databases. When you place transaction logs from multiple databases to a single disk array, log I/O access becomes random rather than sequential. You should factor in such behavior when testing your I/O subsystem and choose the test scenarios that represent the workload that you expect to have in production.
Most important, you should store the transaction log to highly redundant disk array. It is impossible to recover the database in a transactionally consistent state if the transaction log has been corrupted.
Summary
SQL Server uses a transaction log to store information about all data modifications made to the database. It allows SQL Server to keep the database transactionally consistent, even in the event of unexpected shutdown or crash.
SQL Server uses a write-ahead logging mechanism, which guarantees that log records are always saved into the log file before updated data pages are saved to the data files. SQL Server uses a small buffer to cache log records in memory, saving all of them at once when needed.
The transaction log is a wraparound file, which internally consists of multiple virtual log files. Every virtual log file can either be active or inactive. Transaction log truncation marks some VLFs as inactive, making them ready for reuse. In the SIMPLE recovery model, SQL Server truncates the transaction log at CHECKPOINT. In the FULL and BULK-LOGGED recovery models, SQL Server truncates the transaction log during log backups.
There are a number of issues that can prevent transaction log truncation. The most common ones are lack of transaction log backups in the FULL and BULK-LOGGED recovery models, or long-running uncommitted transactions. Moreover, some SQL Server processes, such as replication, database mirroring, and a few others, can prevent log truncation if some part of the active log is unprocessed. You can examine what prevents log truncation by analyzing the log_reuse_wait_desc column in sys.databases view.
You should avoid situations where the transaction log has too many or too few virtual log files. Either circumstance negatively affects system performance. For databases that require large transaction files, you can pre-allocate the transaction log with 8000MB chunks, which makes 16 VLF of about 500MB each.
It is recommended that you manage the transaction log size manually to avoid log auto-growth. However, you should still keep auto-growth enabled to avoid a “9002: Transaction Log Full” error. Auto-growth size should be specified in MB rather than as a percent. You need to fine-tune the size based on the I/O performance of the system. Large auto-growth chunks reduce the number of VLFs created, however SQL Server zero-initializes the newly allocated space, suspending all sessions that generate log records during that time.
Fast transaction log throughput is essential for good performance, especially with OLTP systems. You must store the transaction log on a fast disk array, minimizing writing latency. Most important, that array must be redundant. It is impossible to recover the database in a transactionally consistent state if the transaction log is corrupted.