
![]()
In-Memory OLTP Programmability
This chapter focuses on the programmability aspects of the in-memory OLTP engine in SQL Server. It describes the process of native compilation, and it provides an overview of the natively-compiled stored procedures and T-SQL features, which are supported in in-memory OLTP. Finally, it discusses several questions related to the design of new and the migration of existing systems to the in-memory OLTP architecture.
Native Compilation
As you already know, memory-optimized tables can be accessed from regular T-SQL code using the query interop engine. This approach is very flexible. As long as you work within the supported feature set, the location of data is transparent. The code does not need to know, nor does it need to worry about if it works with on-disk or with memory-optimized tables.
Unfortunately, this flexibility comes at a cost. T-SQL is an interpreted and CPU-intensive language. Even a simple T-SQL statement requires thousands, and sometimes millions, of CPU instructions to execute. Even though in-memory data location dramatically speeds up data access and eliminates latching and locking contentions, the overhead of T-SQL interpretation and execution sets limits the level of performance improvements achievable with in-memory OLTP.
In practice, it is possible to see a 2X-3X system throughput increase when memory-optimized data is accessed through the interop engine. To improve performance even further, in-memory OLTP utilizes native compilation. As a first step, it converts any row-data manipulation and access logic into C code, which is compiled into DLLs and loaded into SQL Server process memory. Those DLLs (one per table) consist of native CPU instructions, and they execute without any further code interpretation overhead of T-SQL statements.
Consider the simple situation where you need to read the value of a fixed-length column from a data row. In the case of on-disk tables, SQL Server obtains the starting offset and length of the column from the system catalogs, and it performs the required manipulations to convert the sequence of bytes to the required data type. With memory-optimized tables, the DLL already knows what is the column offset and data type. SQL Server can read data from a pre-defined offset in a row using a pointer of the correct data type without any further overhead involved. As you can guess, this approach dramatically reduces the number of CPU instructions required for the operation.
On the flip side, this approach brings some limitations. You cannot change the format of a row after the DLL is generated. The compiled code would not know anything about the changes. This problem is more complicated than it seems, and simple recompilation of the DLL does not address it.
Again, consider the situation where you need to add another nullable column to a table. This is a metadata-level operation for on-disk tables, which does not change the data in existing table rows. T-SQL would be able to detect that column data is not present by analyzing the various data row properties at runtime.
The situation is far more complicated in the case of memory-optimized tables and natively-compiled code. It is easy to generate a new version of the DLL that knows about new data column; however, that is not enough. The DLL needs to handle different versions of rows and different data formats depending on the presence of column data. While this is technically possible, it adds extra logic to the DLL, which leads to additional processing instructions, which slows data access. Moreover, the logic to support multiple data formats would remain in the code forever, degrading performance even further with each table alteration.
The only way to address this problem is to convert all existing data rows into the new format. This is a very complex and time-consuming operation that requires exclusive access to a table for its duration. Such a condition would introduce the concept of locking in the in-memory OLTP engine, which violates its design goals and, therefore, table alteration is not supported in in-memory OLTP.
![]() Note Technically speaking, the requirement of locking could be avoided if the alteration runs in a SINGLE_USER database mode. However, if the database can be switched to a SINGLE_USER mode, you can work around the restriction by creating another table with the new structure, copying the data there, dropping the old table and renaming the new table afterwards. Keep in mind, however, that the server should have enough memory to accommodate data from both tables during this process.
Note Technically speaking, the requirement of locking could be avoided if the alteration runs in a SINGLE_USER database mode. However, if the database can be switched to a SINGLE_USER mode, you can work around the restriction by creating another table with the new structure, copying the data there, dropping the old table and renaming the new table afterwards. Keep in mind, however, that the server should have enough memory to accommodate data from both tables during this process.
To reduce the overhead of T-SQL interpretation even further, the in-memory OLTP engine allows you to perform native compilation of the stored procedures. Those stored procedures are compiled in the same way as table-related DLLs and are also loaded to SQL Server process memory. We will discuss natively-compiled stored procedures in greater detail later in the chapter.
Native compilation utilizes both the SQL Server and in-memory OLTP engines. As a first step, SQL Server parses the T-SQL code and, in the case of stored procedures, it generates an execution plan using Query Optimizer. At the end of this stage, SQL Server generates a structure called MAT (Mixed Abstract Tree), which represents metadata, imperative logic, expressions, and query plans.
As a next step, in-memory OLTP transforms MAT to another structure called PIT (Pure Imperative Tree), which is used to generate source code that is compiled and linked into the DLL.
Figure 33-1 illustrates the process of native compilation in SQL Server.
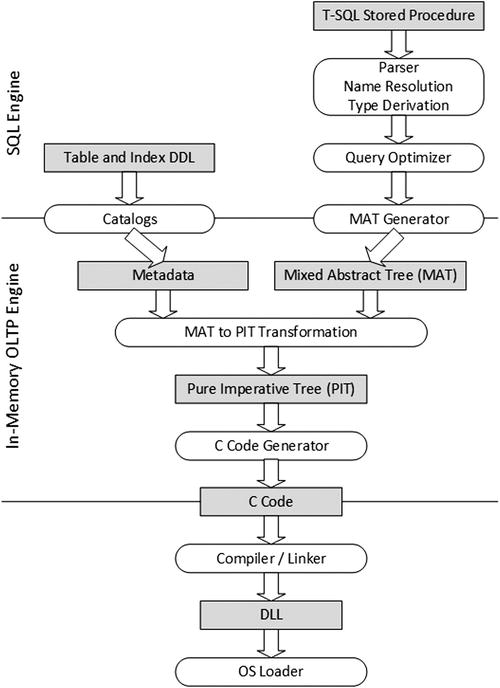
Figure 33-1. Native compilation in SQL Server
The code generated for native compilation uses plain C language and is very efficient. It is very hard to read, however. For example, every method is implemented as a single function, which does not call other functions but rather implements its code inline using GOTO as a control flow statement. You should remember the intention has never been to generate human-readable code. It is used as the source for native compilation only.
Binary DLL files are not persisted in a database backup. SQL Server recreates table-related DLLs on startup and stored procedures-related DLLs at the time of first call. This approach addresses security risks from hackers, who can substitute DLLs with malicious copies.
SQL Server places binary DLLs and all other native compilation-related files in an XTP subfolder under the main SQL Server data directory. It groups files on a per-database basis by creating another level of subfolder. Figure 33-2 shows the content of the folder for the database (with ID=5), which contains one memory-optimized table and two natively-compiled stored procedures.
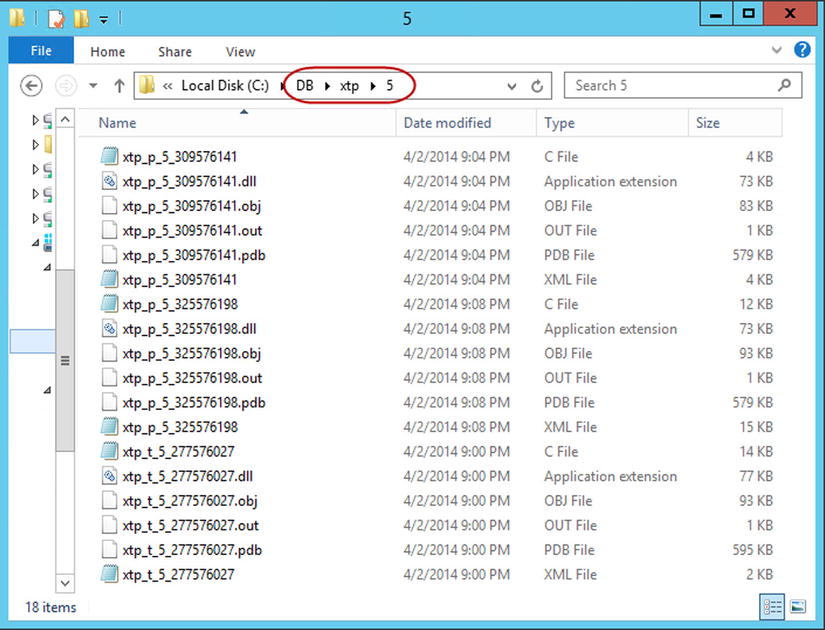
Figure 33-2. Folder with natively-compiled objects
All of the file names start with the prefix xtp_ followed either by the p (stored procedure) or t (table) character, which indicates the object type. The two last parts of the name include the database and object IDs for the object.
File extensions determine the type of the file, such as:
- *.mat.xml files store an XML representation of the MAT structure.
- *.c files are the source file generated by the C code generator.
- *.obj are the object files generated by the C compiler.
- *.pub are symbol files produced by the C compiler.
- *.out are log files from the C compiler.
- *.dll are natively-compiled DLLs generated by the C linker. Those files are loaded into SQL Server memory and used by the in-memory OLTP engine.
![]() Tip You can open and analyze C source code and XML MAT in the text editor application to get a sense of the native compilation process.
Tip You can open and analyze C source code and XML MAT in the text editor application to get a sense of the native compilation process.
Listing 33-1 shows how to obtain a list of the natively-compiled objects loaded into SQL Server memory. It also returns the list of tables and stored procedures from the database to show the correlation between a DLL file name and object IDs.
Listing 33-1. Obtaining a list of natively-compiled objects loaded into SQL Server memory
select
s.name + '.' + o.name as [Object Name]
,o.object_id
from
(
select schema_id, name, object_id
from sys.tables
where is_memory_optimized = 1
union all
select schema_id, name, object_id
from sys.procedures
) o join sys.schemas s on
o.schema_id = s.schema_id;
select *
from sys.dm_os_loaded_modules
where description = 'XTP Native DLL';
Figure 33-3 illustrates the output of the code.

Figure 33-3. Natively-compiled objects loaded into SQL Server memory
Natively-Compiled Stored Procedures
Natively-compiled stored procedures are the stored procedures that are compiled into native code. They are extremely efficient, and they can provide major performance improvements while working with memory-optimized tables, as compared to interpreted T-SQL statements, which access those tables through the query interop component.
![]() Note In this chapter, I will reference regular interpreted (non-natively compiled) stored procedures as T-SQL procedures.
Note In this chapter, I will reference regular interpreted (non-natively compiled) stored procedures as T-SQL procedures.
Natively-compiled stored procedures can access only memory-optimized tables. Moreover, they support a smaller set of T-SQL features as compared to the query interop engine. We will talk about those limitations in more detail shortly after we discuss when SQL Server compiles and how it optimizes natively-compiled stored procedures.
Optimization of Natively-Compiled Stored Procedures
Interpreted T-SQL stored procedures are compiled at time of first execution. Additionally, they can be recompiled after they are evicted from plan cache and in a few other cases, such as outdated statistics, changes in database schema or recompilation, which are explicitly requested in the code.
This behavior is different from natively-compiled stored procedures, which are compiled at creation time. They are never recompiled, only with the exception of SQL Server or database restart. In these cases, recompilation occurs at the time of the first stored procedure call.
SQL Server does not sniff parameters at the time of compilation, optimizing statements for UNKNOWN values. It uses memory-optimized table statistics during optimization. However, as you already know, those statistics are not updated automatically, and they can be outdated at that time.
Fortunately, cardinality estimation errors have a smaller impact on performance in the case of natively-compiled stored procedures. Contrary to on-disk tables, where such errors can lead to highly inefficient plans due to the high number of Key or RID Lookup operations, all indexes in memory-optimized tables reference the same data row and, in a nutshell, are covering indexes. Moreover, errors will not affect the choice of join strategy—inner nested loop is the only physical join type supported in natively-compiled stored procedures in the first release of in-memory OLTP.
Outdated statistics at time of compilation, however, can still lead to inefficient plans. One such example is a query with multiple predicates on indexed columns. SQL Server needs to know the index’s selectivity to choose the most efficient one.
It is better to recompile natively-compiled stored procedures if the data in the table has significantly changed. You can do it with the following actions:
- Update statistics to reflect the current data distribution in the table(s).
- Script permissions assigned to natively-compiled stored procedures.
- Drop and recreate procedures. Those actions force recompilation.
- Assign required permissions to the procedures.
Finally, it is worth mentioning that the presence of natively-compiled stored procedures requires you to adjust the deployment process in the system. It is common to create all database schema objects, including tables and stored procedures, at the beginning of deployment. While the time of deployment does not matter for T-SQL procedures, such a strategy compiles natively-compiled stored procedures at a time when database tables are empty. You should recompile (recreate) natively-compiled procedures later; after the tables are populated with data.
Creating Natively-Compiled Stored Procedures
Natively-compiled stored procedures execute as atomic blocks, which is an all or nothing approach. Either all statements in the procedure succeed or all of them fail.
When a natively-compiled stored procedure is called outside of the context of an active transaction, it starts a new transaction and either commits or rolls it back at the end of the execution.
In cases where a procedure is called in the context of an active transaction, SQL Server creates a savepoint at the beginning of the procedure’s execution. In case of an error in the procedure, SQL Server rolls back the transaction to the created savepoint. Based on the severity and type of the error, the transaction is either going to be able to continue and commit or became doomed and uncommittable.
Let’s look at an example and create a memory-optimized table and natively-compiled stored procedure, as shown in Listing 33-2. Do not focus on unfamiliar constructs in the stored procedure body. I will explain those shortly.
Listing 33-2. Atomic blocks and transactions: Object creation
create table dbo.MOData
(
ID int not null
primary key nonclustered
hash with (bucket_count=10),
Value int null
)
with (memory_optimized=on, durability=schema_only);
insert into dbo.MOData(ID, Value)
values(1,1), (2,2)
go
create proc dbo.AtomicBlockDemo
(
@ID1 int not null
,@Value1 bigint not null
,@ID2 int
,@Value2 bigint
)
with native_compilation , schemabinding, execute as owner
as
begin atomic
with (transaction isolation level = snapshot, language=N'us_english')
update dbo.MOData set Value = @Value1 where ID = @ID1
if @ID2 is not null
update dbo.MOData set Value = @Value2 where ID = @ID2
end
At this point, the dbo.MOData table has two rows with values (1,1) and (2,2). As a first step, let’s start the transaction and call a stored procedure twice, as shown in Listing 33-3.
Listing 33-3. Atomic blocks and transactions: Calling stored procedure
begin tran
exec dbo.AtomicBlockDemo 1, -1, 2, -2
exec dbo.AtomicBlockDemo 1, 0, 2, 999999999999999
The first call of the stored procedure succeeds, while the second call triggers an arithmetic overflow error as shown below:
Msg 8115, Level 16, State 0, Procedure AtomicBlockDemo, Line 49
Arithmetic overflow error converting bigint to data type int.
You can check that the transaction is still active and committable with this select: select @@TRANCOUNT as [@@TRANCOUNT], XACT_STATE() as [XACT_STATE()]. It would return the following results:
@@TRANCOUNT XACT_STATE()
----------- ------------
1 1
If you commit the transaction and check the content of the table, you will see that the data reflects the changes caused by the first stored procedure call. Even though the first update statement from the second call succeeded, SQL Server rolled it back because the natively-compiled stored procedure executed as an atomic block. You can see the data in the table below.
ID Value
----------- -----------
1 -1
2 -2
As a second example, let’s trigger a critical error, which dooms the transaction, making it uncommittable. One such situation is a write/write conflict. You can trigger it by executing the code in Listing 33-4 in two different sessions.
Listing 33-4. Atomic blocks and transactions: Write/write conflict
begin tran
exec dbo.AtomicBlockDemo 1, 0, null, null
When you run the code in the second session, it triggers the following exception:
Msg 41302, Level 16, State 110, Procedure AtomicBlockDemo, Line 13
The current transaction attempted to update a record that has been updated since this transaction started. The transaction was aborted.
Msg 3998, Level 16, State 1, Line 1
Uncommittable transaction is detected at the end of the batch. The transaction is rolled back.
If you check @@TRANCOUNT in the second session, you will see that SQL Server terminates the transaction as follows.
@@TRANCOUNT
-----------
0
You should specify that the natively-compiled stored procedure is an atomic block by using BEGIN ATOMIC..END at the top level of the stored procedure. You should also specify the isolation level for a block and a language, which dictates the date/time format and system messages language. Finally, you can use three optional properties, such as DATEFORMAT, DATEFIRST, and DELAYED_DURABILITY to specify the formats and transaction durability option.
![]() Note Atomic blocks are not supported in interpreted T-SQL stored procedures.
Note Atomic blocks are not supported in interpreted T-SQL stored procedures.
All natively-compiled stored procedures are schema-bound, and they require you to specify the SCHEMABINDING option. Finally, setting the execution context is a requirement. Natively-compiled stored procedures do not support the EXECUTE AS CALLER security context and require you to specify EXECUTE AS OWNER, EXECUTE AS USER, or EXECUTE AS SELF context in the definition.
![]() Note You can read about execution context at: http://technet.microsoft.com/en-us/library/ms188354.aspx.
Note You can read about execution context at: http://technet.microsoft.com/en-us/library/ms188354.aspx.
As you have already seen in Listing 33-2, you can specify the required parameters by using the NOT NULL construct in the parameter’s definition. SQL Server raises an error if you do not provide their values at the time of the stored procedure call.
Finally, it is recommended that you avoid type conversion and do not use named parameters when you call natively-compiled stored procedures. It is more efficient to use the: exec Proc value [..,value] rather than the exec Proc @Param=value [..,@Param=value] calling format.
![]() Note You can detect inefficient parameterization with hekaton_slow_parameter_parsing Extended Event.
Note You can detect inefficient parameterization with hekaton_slow_parameter_parsing Extended Event.
Supported T-SQL Features
Natively-compiled stored procedures support only a limited set of T-SQL constructs. Let’s look at the supported features in different areas.
Control Flow
The following control flow options are supported:
- IF and WHILE
- Assigning a value to a variable with the SELECT and SET operators.
- RETURN
- TRY/CATCH/THROW (RAISERROR is not supported). It is recommended that you use a single TRY/CATCH block for the entire stored procedure for better performance.
- It is possible to declare variables as NOT NULL as long as they have an initializer as part of the DECLARE statement.
Operators
The following operators are supported:
- Comparison operators, such as =, <, <=, >, >=, <>.
- Unary and binary operators, such as +, -, *, /, %. + operators are supported for both numbers and strings.
- Bitwise operators, such as &, |, ~, ^.
- Logical operators, such as AND, OR, and NOT. However, the OR and NOT operators are not supported in the WHERE and HAVING clauses of the query.
Build-In Functions
The following build-in functions are supported:
- Math functions: ACOS, ASIN, ATAN, ATN2, COS, COT, DEGREES, EXP, LOG, LOG10, PI, POWER, RAND, SIN, SQRT, SQUARE, and TAN
- Date/time functions: CURRENT_TIMESTAMP, DATEADD, DATEDIFF, DATEFROMPARTS, DATEPART, DATETIME2FROMPARTS, DATETIMEFROMPARTS, DAY, EOMONTH, GETDATE, GETUTCDATE, MONTH, SMALLDATETIMEFROMPARTS, SYSDATETIME, SYSUTCDATETIME, and YEAR
- String functions: LEN, LTRIM, RTRIM, and SUBSTRING
- Error functions: ERROR_LINE, ERROR_MESSAGE, ERROR_NUMBER, ERROR_PROCEDURE, ERROR_SEVERITY, and ERROR_STATE
- NEWID and NEWSEQUENTIALID
- CAST and CONVERT. However, it is impossible to convert between a non-unicode and a unicode string.
ISNULL- SCOPE_IDENTITY
- You can use @@ROWCOUNT within a natively-compiled stored procedure; however, its value is reset to 0 at the beginning and end of the procedure.
Query Surface Area
The following query surface area functions are supported:
- SELECT, INSERT, UPDATE, and DELETE
- CROSS JOIN and INNER JOIN are the only join types supported. Moreover, you can use joins only with SELECT operators.
- Expressions in the SELECT list and WHERE and HAVING clauses are supported as long as they use supported operators.
- IS NULL and IS NOT NULL
- GROUP BY is supported with the exception of grouping by string or binary data.
- TOP and ORDER BY. However, you cannot use these WITH TIES and PERCENT in the TOP clause. Moreover, the TOP operator is limited to 8,192 rows when the TOP <constant> is used, or even a lesser number of rows in the case of joins. You can address this last limitation by using a TOP <variable> approach. However, it is less efficient in terms of performance.
Execution Statistics
By default, SQL Server does not collect execution statistics for natively-compiled stored procedures due to the performance impact it introduces. You can enable such a collection at the procedure level with the exec sys.sp_xtp_control_proc_exec_stats 1 command. Moreover, you can use the exec sys.sp_xtp_control_query_exec_stats 1 command to enable a collection at the statement level. SQL Server does not persist those settings, and you will need to re-enable statistics collection after each SQL Server restart.
![]() Note Do not collect execution statistics unless you are troubleshooting performance.
Note Do not collect execution statistics unless you are troubleshooting performance.
Listing 33-5 shows the code that returns execution statistics for stored procedures using the sys.dm_exec_procedure_stats view.
Listing 33-5. Analyzing stored procedures execution statistics
select
object_name(object_id) as [Proc Name]
,execution_count as [Exec Cnt]
,total_worker_time as [Total CPU]
,convert(int,total_worker_time / 1000 / execution_count)
as [Avg CPU] -- in Milliseconds
,total_elapsed_time as [Total Elps]
,convert(int,total_elapsed_time / 1000 / execution_count)
as [Avg Elps] -- in Milliseconds
,cached_time as [Cached]
,last_execution_time as [Last Exec]
,sql_handle
,plan_handle
,total_logical_reads as [Reads]
,total_logical_writes as [Writes]
from
sys.dm_exec_procedure_stats
order by
[AVG CPU] desc
Figure 33-4 illustrates the output of the code from Listing 33-5. As you can see, neither the sql_handle nor plan_handle columns are populated. Execution plans for natively-compiled stored procedures are embedded into the code and not cached in plan cache. Nor are I/O related statistics provided. Natively-compiled stored procedures work with memory-optimized tables only, and therefore there is no I/O involved.

Figure 33-4. Data from sys.dm_exec_procedure_stats view
Listing 33-6 shows the code that obtains execution statistics for individual statements using the sys.dm_exec_query_stats view.
Listing 33-6. Analyzing stored procedure statement execution statistics
select
substring(qt.text, (qs.statement_start_offset/2)+1,
((
case qs.statement_end_offset
when -1 then datalength(qt.text)
else qs.statement_end_offset
end - qs.statement_start_offset)/2)+1) as SQL
,qs.execution_count as [Exec Cnt]
,qs.total_worker_time as [Total CPU]
,convert(int,qs.total_worker_time / 1000 / qs.execution_count)
as [Avg CPU] -- in Milliseconds
,total_elapsed_time as [Total Elps]
,convert(int,qs.total_elapsed_time / 1000 / qs.execution_count)
as [Avg Elps] -- in Milliseconds
,qs.creation_time as [Cached]
,last_execution_time as [Last Exec]
,qs.plan_handle
,qs.total_logical_reads as [Reads]
,qs.total_logical_writes as [Writes]
from
sys.dm_exec_query_stats qs
cross apply sys.dm_exec_sql_text(qs.sql_handle) qt
where
qs.plan_generation_num is null
order by
[AVG CPU] desc
Figure 33-5 illustrates the output of the code from Listing 33-6. Like procedure execution statistics, it is impossible to obtain the execution plans of the statements. However, you can analyze the CPU time consumed by individual statements and the frequency of their execution.

Figure 33-5. Data from the sys.dm_exec_query_stats view
Interpreted T-SQL and Memory-Optimized Tables
The query interop component provides transparent, memory-optimized table access to interpreted T-SQL code. In interpreted mode, SQL Server treats memory-optimized tables pretty much the same way as on-disk tables. It optimizes queries and caches execution plans, regardless of where table is located. The same set of operators is used during query execution. From a high level, when the operator’s GetRow() method is called, it is routed either to the Storage Engine or to the in-memory OLTP engine, depending on the underlying table type.
Most T-SQL features are supported in interpreted mode. There are still a few exceptions, however:
- TRUNCATE TABLE
- MERGE operator with memory-optimized table as the target.
- Context connection from CLR code
- Referencing memory-optimized tables in indexed views. You can reference memory-optimized tables in partitioned views, combining data from memory-optimized and on-disk tables.
- DYNAMIC and KEYSET cursors, which are automatically downgraded to STATIC
- Cross-database queries and transactions
- Linked servers
As you can see, the list of limitations is pretty small. However, the flexibility of query interop access comes at a cost. Natively-compiled stored procedures are usually several times more efficient as compared to their interpreted T-SQL counterparts. In some cases, for example joins between memory-optimized and on-disk tables, query interop is the only choice; however, it is usually preferable to use natively-compiled stored procedures when possible.
Memory-Optimized Table Types and Variables
SQL Server allows you to create memory-optimized table types. Table variables of those types are called memory-optimized table variables. In contrast to regular disk-based table variables, memory-optimized table variables live in memory only and do not utilize tempdb.
Memory-optimized table variables provide great performance. They can be used as a replacement for disk-based table variables and, in some cases, temporary tables. Obviously, they have the same set of functional limitations as memory-optimized tables.
Contrary to disk-based table types, you can define indexes on memory-optimized table types. The same statistics-related limitations still apply, however, as we already discussed. Due to the nature of the indexes on memory-optimized tables, cardinality estimation errors yield a much lower negative impact as compared to those of on-disk tables.
SQL Server does not support inline declaration of memory-optimized table variables. For example, the code shown in Listing 33-7 would not compile and it would raise an error. The reason behind this limitation is that SQL Server compiles a DLL for every memory-optimized table type, which would not work in the case of inline declaration.
Listing 33-7. (Non-functional) inline declaration of memory-optimized table variables
declare
@IDList table
(
ID int not null
primary key nonclustered hash
with (bucket_count=10000)
)
with (memory_optimized=on)
Msg 319, Level 15, State 1, Line 91
Incorrect syntax near the keyword 'with'. If this statement is a common table expression, an xmlnamespaces clause or a change tracking context clause, the previous statement must be terminated with a semicolon.
You should define and use a memory-optimized table type instead, as shown in Listing 33-8.
Listing 33-8. Creating a memory-optimized table type and memory-optimized table variable
create type dbo.mtvIDList as table
(
ID int not null
primary key nonclustered hash
with (bucket_count=10000)
)
with (memory_optimized=on)
go
declare
@IDList dbo.mtvIDList
You can pass memory-optimized table variables as table-valued parameters (TVP) to natively compiled and regular T-SQL procedures. As with on-disk based table-valued parameters, it is a very efficient way to pass a batch of rows to a T-SQL routine.
You can use memory-optimized table variables to imitate row-by-row processing using cursors, which are not supported in natively compiled stored procedures. Listing 33-9 illustrates an example of using a memory-optimized table variable to imitate a static cursor. Obviously, it is better to avoid cursors and use set-based logic if at all possible.
Listing 33-9. Using a memory-optimized table variable to imitate a cursor
create type dbo.MODataStage as table
(
ID int not null
primary key nonclustered
hash with (bucket_count=1000),
Value int null
)
with (memory_optimized=on)
go
create proc dbo.CursorDemo
with native_compilation, schemabinding, execute as owner
as
begin atomic
with (transaction isolation level = snapshot, language=N'us_english')
declare
@tblCursor dbo.MODataStage
,@ID int = -1
,@Value int
,@RC int = 1
/* Staging data in temporary table to imitate STATIC cursor */
insert into @tblCursor(ID, Value)
select ID, Value
from dbo.MOData
while @RC = 1
begin
select top 1 @ID = ID, @Value = Value
from @tblCursor
where ID > @ID
order by ID
select @RC = @@rowcount
if @RC = 1
begin
/* Row processing */
update dbo.MOData set Value = Value * 2 where ID = @ID
end
end
end
In-Memory OLTP: Implementation Considerations
As with any new technology, adoption of in-memory OLTP comes at a cost. You will need to acquire and/or upgrade to SQL Server 2014, spend time learning the technology and, if you are updating an existing system, refactor code and test the changes. It is important to perform a cost/benefits analysis and determine if in-memory OLTP provides you with adequate benefits to outweigh the costs.
In-memory OLTP is hardly a magical solution, which can help you improve server performance by simply flipping a switch and moving data into memory. It is designed to address a specific set of problems, such as latch and lock contentions on very active OLTP systems. It is less beneficial in the case of Data Warehouse systems with low concurrent activity, large amounts of data, and queries that require complex aggregations. While in some cases it is still possible to achieve performance improvements by moving data into memory, you can often obtain better results by implementing columnstore indexes, indexing views, data compression, and other database schema changes.
It is also worth remembering that most performance improvements are achieved by using natively-compiled stored procedures, which can rarely be used in Data Warehouse workloads due to the limited set of T-SQL features that they support.
Another important factor is whether you plan to use in-memory OLTP during the development of new or the migration of existing systems. It is obvious that you need to make changes in existing systems, addressing the limitations of memory-optimized tables, such as missing support of triggers, foreign key constraints, check and unique constraints, calculated columns, and quite a few other restrictions.
I would like to discuss a few less obvious items that can greatly increase migration cost. The first is the 8,060-byte maximum row size limitation in memory-optimized tables without any off-row data storage support. Such a limitation can lead to a significant amount of work when the existing active OLTP tables use LOB data types, such as (n)varchar(max) or xml. While it is possible to change the data types, limiting the size of the strings and/or store xml as text or in binary format and/or store large objects in separate tables, such changes are complex, time-consuming, and require careful planning, especially if the table has multiple LOB columns defined. Do not forget that in-memory OLTP does not allow you to create a table if there is a possibility that the size of a row exceeds 8,060 bytes. For example, you cannot create a table with three varchar(3000) columns.
Indexing of memory-optimizing tables is another important factor. While range indexes can mimic some of the behavior of indexes in on-disk tables, there still is a significant difference between them. Range indexes are implemented as a single-linked list, and they would not help much if the data needs to be accessed in the opposite sorting order of an index key. This often requires you to reevaluate your index strategy when a table is moved from disk into memory. However, the bigger issue with indexing is the requirement to have binary collation of the indexed text columns. This is a breaking change in system behavior, and it often requires non-trivial changes in the code and some sort of data conversion.
Consider the situation where an application performs a search on the Name column, which uses case-insensitive collation. You will need to convert all values to upper- or lower-case in order to be able to utilize a range index after the table becomes memory-optimized.
It is also worth noting that using binary collations for data will lead to changes in the T-SQL code. You will need to specify collations for variables in stored procedures and other T-SQL routines, unless you change the database collation to be a binary one. However, if the database and server collations do not match, you will need to specify a collation for the columns in temporary tables created in tempdb.
There are plenty of other factors to consider. However, the key point is that you should perform a thorough analysis before starting a migration to in-memory OLTP. Such a migration can have a very significant cost impact, and it should not be done unless it benefits the system.
SQL Server 2014 Management Studio provides a set of tools that can help you analyze if in-memory OLTP will improve your application’s performance. This tool is based on the Management Data Warehouse, and it provides you with a set of data collectors and reports that can help identify the objects that would benefit the most from the conversion. While this tool can be beneficial during the initial analysis stage, you should not make a decision based solely on the tool’s output. Take into account all of the other factors and considerations we have already discussed in this chapter.
![]() Note You can read about the in-memory OLTP ARM tool at: http://msdn.microsoft.com/en-us/library/dn205133.aspx.
Note You can read about the in-memory OLTP ARM tool at: http://msdn.microsoft.com/en-us/library/dn205133.aspx.
Moreover, SQL Server 2014 Management Studio provides you with Memory Optimization and Native Compilation Advisors that can help you analyze and convert specific tables and stored procedures to in-memory OLTP objects. You can read more about them at: http://msdn.microsoft.com/en-us/library/dn284308.aspx and http://msdn.microsoft.com/en-us/library/dn358355.aspx respectively.
New development, on the other hand, is a very different story. You can design a new system and database schema taking in-memory OLTP limitations into account. It is also possible to adjust some functional requirements during the design phase. As an example, it is much easier to store data in a case-sensitive way from the beginning as compared to changing the behavior of existing systems after they are deployed to production.
You should remember, however, that in-memory OLTP is an Enterprise Edition feature, and it requires powerful hardware with a large amount of memory. It is an expensive feature due to its licensing costs. Moreover, it is impossible to “set it and forget it.” Database professionals should actively participate in monitoring and tuning the system after deployment. They need to monitor system memory usage, analyze data and recreate hash indexes if bucket counts need to be changed, update statistics, redeploy natively-compiled stored procedures, and perform other tasks as well.
All of that makes in-memory OLTP a bad choice for Independent Software Vendors who develop products that need be deployed to a large number of customers. Moreover, it is not practical for supporting two versions of a system—with and without in-memory OLTP—due to the increase in development and support costs.
Finally, if you are using the Enterprise Edition of SQL Server 2014, you can benefit from some of the in-memory OLTP features—even if you decided that in-memory OLTP migration is not cost effective for your organization’s needs. You can use memory-optimized table variables and/or non-durable memory-optimized tables as a staging area and for replacement of on-disk temporary tables. This will improve the performance of calculations and ETL processes, which need to store a temporary copy of the data.
Another possibility is using memory-optimized tables as a session state storage for ASP.Net applications and/or distributed cache for client applications, avoiding the purchase of expensive third-party solutions. You can use either durable or non-durable tables in this scenario. Durable tables will provide you with transparent failover, while non-durable tables will have incredibly fast performance. Obviously, you should remember the 8,060-byte maximum row size limitation and address it in code if this becomes an issue in your system.
Summary
SQL Server uses native compilation to minimize the processing overhead of interpreted T-SQL language. It generates separate DLLs for every memory-optimized object and loads it into process memory.
SQL Server supports native compilation of regular T-SQL stored procedures. It compiles them into DLLs at creation time or, in the case of a server or database restart, at the time of the first call. SQL Server optimizes natively-compiled stored procedures and embeds an execution plan into the code. That plan never changes unless the procedure is recompiled after a SQL Server or database restart. You should drop and recreate procedures if data distribution has been significantly changed after compilation.
While natively-compiled stored procedures are incredibly fast, they support a limited set of T-SQL language features. You can avoid such limitations by using interpreted T-SQL code that accesses memory-optimized tables through the query interop component of SQL Server. Almost all T-SQL language features are supported in this mode.
Memory-optimized table types and memory-optimized table variables are the in-memory analog of table types and table variables. They live in-memory only, and they do not use tempdb. You can use memory-optimized table variables as a staging area for the data and to pass a batch of rows to a T-SQL routine. Memory-optimized table types allow you to create indexes similar to memory-optimized tables.
In-memory OLTP is an Enterprise Edition feature that requires monitoring and tuning of systems in the post-deployment stage. It makes in-memory OLTP a bad choice for Independent Software Vendors who develop systems that need to be deployed to multiple customers.
Migration of existing systems could be a very time-consuming and expensive process, which requires you to address various limitations and differences in the behavior of memory-optimized and on-disk tables and indexes. You should perform a cost/benefit analysis, making sure that the benefits of migration overweigh its implementation costs.