
Chapter 7. Hashes: Labeling Data

Throwing things in piles is fine, until you need to find something again. You’ve already seen how to create a collection of objects using an array. You’ve seen how to process each item in an array, and how to find items you want. In both cases, you start at the beginning of the array, and look through Every. Single. Object. You’ve also seen methods that take big collections of parameters. You’ve seen the problems this causes: method calls require a big, confusing collection of arguments that you have to remember the exact order for.
What if there were a kind of collection where all the data had labels on it? You could quickly find the elements you needed! In this chapter, we’ll learn about Ruby hashes, which do just that.
Counting votes
A seat on the Sleepy Creek County School Board is up for grabs this year, and polls have been showing that the election is really close. Now that it’s election night, the candidates are excitedly watching the votes roll in.

{"name" => "Amber Graham",
"occupation" => "Manager"}
{"name" => "Brian Martin",
"occupation" => "Accountant"}The electronic voting machines in use this year record the votes to text files, one vote per line. (Budgets are tight, so the city council chose the cheap voting machine vendor.)
Here’s a file with all the votes for District A:

We need to process each line of the file and tally the total number of times each name occurs. The name with the most votes will be our winner!
The development team’s first order of business is to read the contents of the votes.txt file. That part is easy; it’s just like the code we used to read the movie reviews file back in Chapter 6.

Now we need to get the name from each line of the file, and increment a tally of the number of times that name has occurred.
An array of arrays...is not ideal
But how do we keep track of all those names and associate a vote total with each of them? We’ll show you two ways. The first approach uses arrays, which we already know about from Chapter 5. The second way uses a new data structure, hashes.
If all we had to work with were arrays, we might build an array of arrays to hold everything. That’s right: Ruby arrays can hold any object, including other arrays. So we could create an array with the candidate’s name and the number of votes we’ve counted for it:
["Brian Martin", 1]
We could put this array inside another array that holds all the other candidate names and their totals:

For each name we encountered in the text file...
"Mikey Moose"
...we’d need to loop through the outer array and check whether the first element of the inner array matches it.
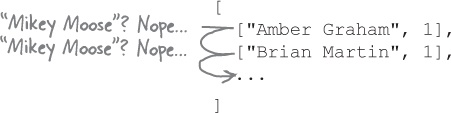
If none matched, we’d add a new inner array with the new name.

But if we encountered a name in the text file that did already exist in the array of arrays...
"Brian Martin"
...then we’d update the existing total for that name.

You could do all that. But it would require extra code, and all that looping would take a long time when processing large lists. As usual, Ruby has a better way.
Hashes
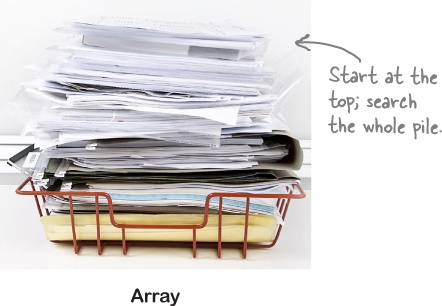
The problem with storing the vote tally for each candidate in an array is the inefficiency of looking it up again later. For each name we want to find, we have to search through all the others.
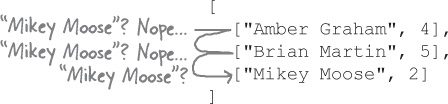
Putting data in an array is like stacking it in a big pile; you can get particular items back out, but you’ll have to search through everything to find them.
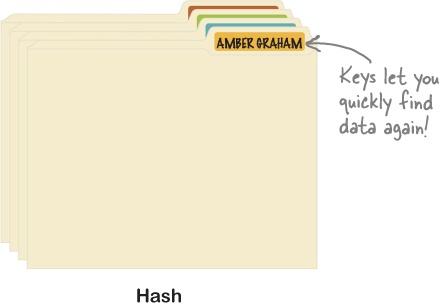
Ruby has another way of storing collections of data: hashes. A hash is a collection where each value is accessed via a key. Keys are an easy way to get data back out of your hash. It’s like having neatly labeled file folders instead of a messy pile.
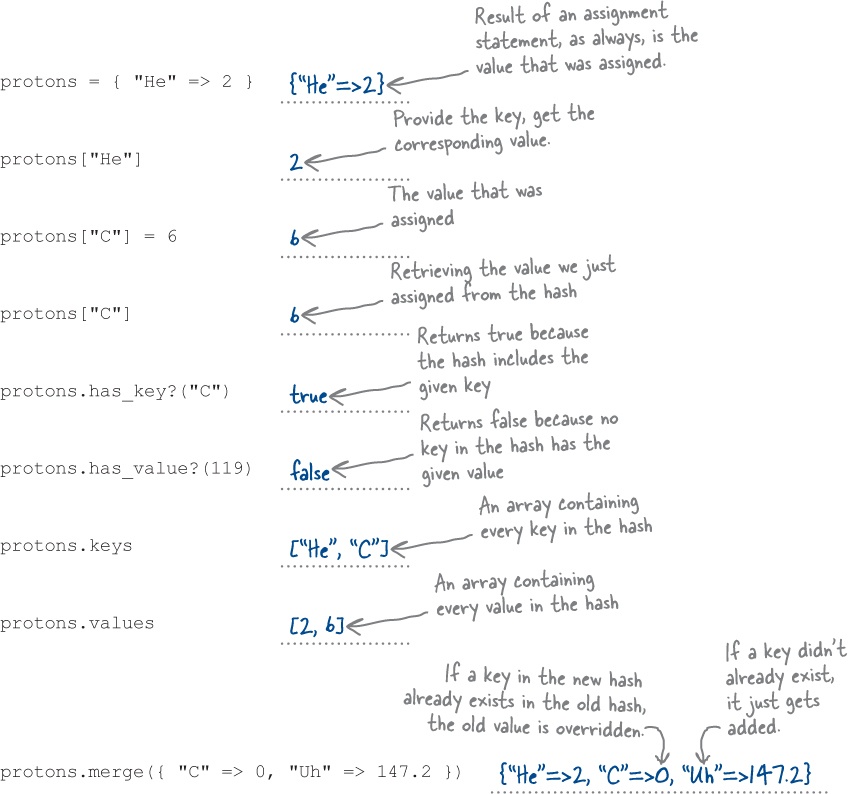
Just as with arrays, you can create a new hash and add some data to it at the same time using a hash literal. The syntax looks like this:

Those => symbols show which key points to which value. They look a bit like a rocket, so they are sometimes called “hash rockets.”
We can assign a new hash to a variable:

Then we can access values from that hash using the keys we set up for them. Whereas hash literals use curly braces, you use square brackets to access individual values. It looks just like the syntax to access values from an array, except you place the hash key within the brackets instead of a numeric index.
We can also add new keys and values to an existing hash. Again, the syntax looks a lot like the syntax to assign to an array element:
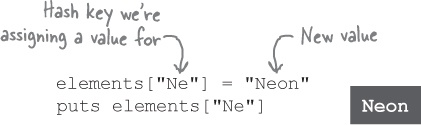
Whereas an array can only use integers as indexes, a hash can use any object as a key. That includes numbers, strings, and symbols.

An array can only use integers as indexes, but a hash can use any object as a key.
Although arrays and hashes have major differences, there are enough similarities that it’s worth taking a moment to compare them...
Arrays: | Hashes: |
|
|


Hashes are objects
We’ve been hearing over and over that everything in Ruby is an object. We saw that arrays are objects, and it probably won’t surprise you to learn that hashes are objects, too.
And, like most Ruby objects, hashes have lots of useful instance methods. Here’s a sampling...
They have the methods that you expect every Ruby object to have, like inspect:
The length method lets you determine how many key/value pairs the hash holds:
There are methods to quickly test whether the hash includes particular keys or values:

There are methods that will give you an array with all the keys or all the values:

And, as with arrays, there are methods that will let you use a block to iterate over the hash’s contents. The each method, for example, takes a block with two parameters, one for the key and one for the value. (More about each in a few pages.)

Hashes return “nil” by default
Let’s take a look at the array of lines we read from the sample file of votes. We need to tally the number of times each name occurs within this array.


In the place of the array of arrays we discussed earlier, let’s use a hash to store the vote counts. When we encounter a name within the lines array, if that name doesn’t exist, we’ll add it to the hash.
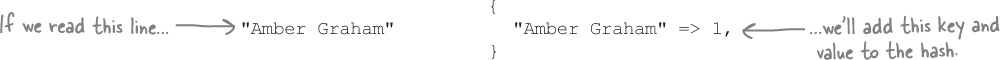
Each new name we encounter will get its own key and value added to the hash.
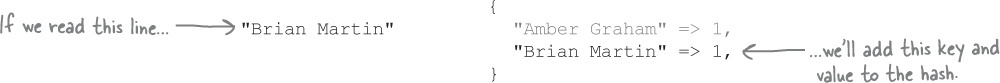
If we encounter a name that we’ve already added, we’ll update its count instead.
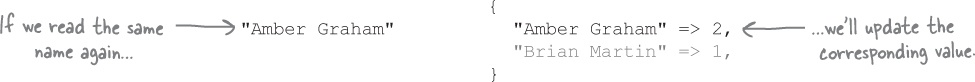
...and so on, until we’ve counted all the votes.
That’s the plan, anyway. But our first version of the code to do this fails with an error...
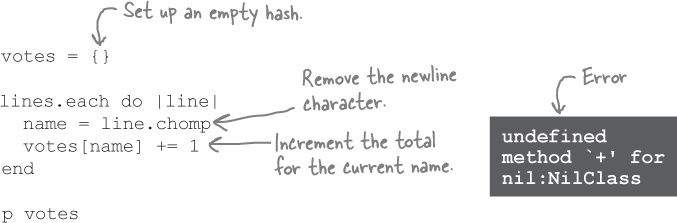
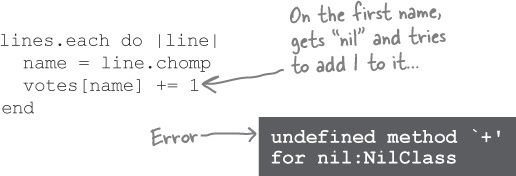
So what happened? As we saw in Chapter 5, if you try to access an array element that hasn’t been assigned to yet, you’ll get nil back. If you try to access a hash key that has never been assigned to, the default value is also nil.
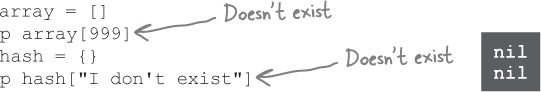
When we try to access the votes for a candidate name that has never been assigned to, we get nil back. And trying to add to nil produces an error.
The first time we encounter a candidate’s name, instead of getting a vote tally back from the hash, we get nil. This results in an error when we try to add to it.

To fix this, we can test whether the value for the current hash key is nil. If it’s not, then we can safely increment whatever number is there. But if it is nil, then we’ll need to set up an initial value (a tally of 1) for that key.

And in the output, we see the populated hash. Our code is working!
nil (and only nil) is “falsy”
There’s a small improvement to be made, though; that conditional is a little ugly.
if votes[name] != nil
We can clean that up by taking advantage of the fact that any Ruby expression can be used in a conditional statement. Most of them will be treated as if they were a true value. (Rubyists often say these values are “truthy.”)

In fact, aside from the false Boolean value, there is only one value that Ruby treats as if it were false: nil. (Rubyists often say that nil is “falsy.”)
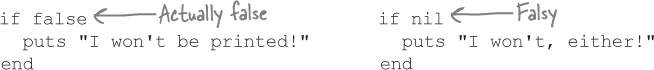
Ruby treats nil like it’s false to make it easier to test whether values have been assigned or not. For example, if you access a hash value within an if statement, the code within will be run if the value exists. If the value doesn’t exist, the code won’t be run.

We can make our conditional read a little better by changing it from if votes[name] != nil to just if votes[name].

Our code still works the same as before; it’s just a bit cleaner looking. This may be a small victory now, but the average program has to test for the existence of objects a lot. Over time, this technique will save you many keystrokes!

Watch it!
We mean it when we say that only nil is falsy.
Most values that are treated as falsy in some other languages—such as empty strings, empty arrays, and the number 0—are truthy in Ruby.


Returning something other than “nil” by default
A disproportionate amount of our code for tallying the votes lies in the if/else statement that checks whether a key exists within the hash...
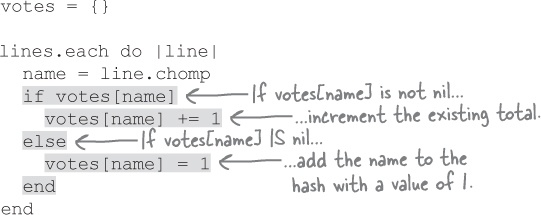
And we need that if statement. Normally, when you try to access a hash key that hasn’t had a value assigned yet, you get nil back. The first time we tried to add to the tally for a key that didn’t yet exist, we’d get an error (because you can’t add to nil).
But what if we got a value other than nil for the unassigned keys? A value that we can increment? Let’s find out how to make that happen...
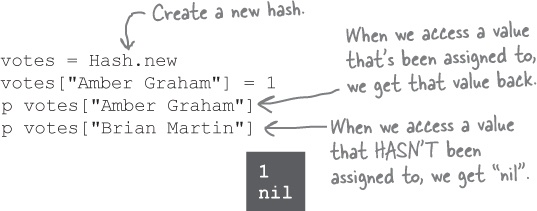
Instead of using a hash literal ({}), you can also call Hash.new to create new hashes. Without any arguments, Hash.new works just like {}, giving you a hash that returns nil for unassigned keys.
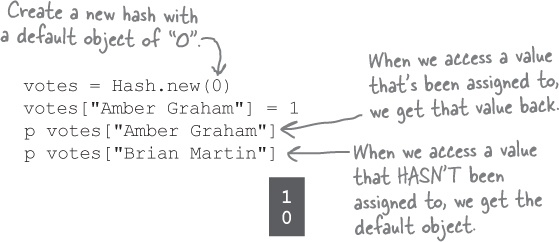
But when you call Hash.new and pass an object as an argument, that argument becomes that hash’s default object. Any time you access a key in that hash that hasn’t been assigned to yet, instead of nil, you’ll get the default object you specified.
Let’s use a hash default object to shorten up our vote counting code...
Watch it!
Using anything other than a number as a hash default object may cause bugs!
We’ll cover ways to safely use other objects in Chapter 8. Until then, don’t use anything other than a number as a default!
If we create our hash with Hash.new(0), it will return the default object (0) when we try to access the vote tally for any key that hasn’t been assigned to yet. That 0 value gets incremented to 1, then 2, and so on as the same name is encountered again and again.
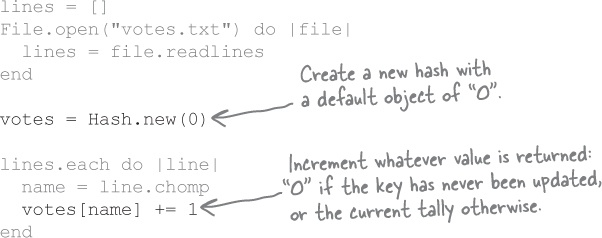
We can get rid of the if statement entirely!
And as you can see from the output, the code still works.
Normalizing hash keys

{"name" => "Kevin Wagner",
"occupation" => "Election Volunteer"}
Here’s what we get if we run this new file through our existing code:

Well, this won’t do... It looks like the last few votes were added with the candidates’ names in lowercase, and they were treated as entirely separate candidates!
This highlights a problem when you’re working with hashes: if you want to access or modify a value, whatever you provide as a key needs to match the existing key exactly. Otherwise, it will be treated as an entirely new key.

So how will we ensure that the new lowercase entries in our text file get matched with the capitalized entries? We need to normalize the input: we need one standard way of representing candidates’ names, and we need to use that for our hash keys.
Fortunately, in this case, normalizing the candidate names is really easy. We’ll add one line of code to ensure the case on each name matches prior to storing it in the hash.

And in the output we see the updated contents of our hash: votes from the lowercase entries have been added to the totals for the capitalized entries. Our counts are fixed!

Watch it!
You also need to normalize the keys when accessing values.
If you normalize the keys when you’re adding values to the hash, you have to normalize the keys when you’re accessing the values as well. Otherwise, it might appear that your value is missing, when it’s really just under a different key!

Hashes and “each”
We’ve processed the lines in the sample file and built a hash with the total number of votes:
It would be far better, though, if we could print one line for each candidate name, together with its vote count.
As we saw back in Chapter 5, arrays have an each method that takes a block with a single parameter. The each method passes each element of the array to the block for processing, one at a time. Hashes also have an each method, which works in about the same way. The only difference is that on hashes, each expects a block with two parameters: one for the key, and one for the corresponding value.

We can use each to print the name of each candidate in the votes hash, along with the corresponding vote count:
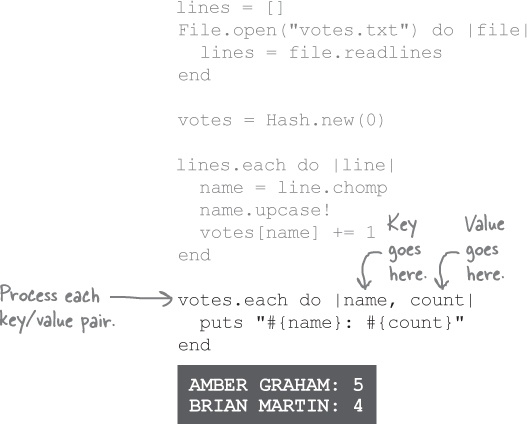
There are our totals, neatly formatted!
Now you’ve seen one of the classic uses of hashes—a program where we need to look up values for a given key repeatedly. Up next, we’ll look at another common way to use hashes: as method arguments.

Tonight's talk: An array and a hash work out their differences.
Hash: | Array: |
Nice to see you again, Array. | |
I didn’t really want to be here, but whatever, Hash. | |
There’s no need to be like that. | |
Isn’t there? I was doing a perfectly fine job storing everyone’s collections, and then you come along, and developers everywhere are like, “Ooh! Why use an array when I can use a hash? Hashes are so cool!” | |
Well, I do have a certain glamor about me... But even I know there are still times when developers should use an array instead of a hash. | |
Darn right! Arrays are way more efficient than hashes! If you’re happy retrieving elements in the same order you added them (say, with | |
It’s true; it’s a lot of work keeping all of my elements where I can retrieve them quickly! It pays off if someone wants to retrieve a particular item from the middle of the collection, though. If they give me the correct key, I always know right where to find a value. | |
Hey, we arrays can get data back too, you know. | |
Yes, but the developer has to know the exact index where the data is stored, right? All those numbers are a pain to keep track of ! But it’s either that, or wait for the array to search through all its elements, one by one... | |
But the point is, we can do it. And if you’re just building a simple queue, we’re still the better choice. | |
Agreed. Developers should know about both arrays and hashes, and pick the right one for their current task. | |
Fair enough. |
A mess of method arguments
Suppose we’re making an app to track basic information regarding candidates so voters can learn about them. We’ve created a Candidate class to keep all of a candidate’s info in one place. For convenience, we’ve set up an initialize method so that we can set all of an instance’s attributes directly from a call to Candidate.new.

Let’s add some code following the class definition to create a Candidate instance and print out its data.

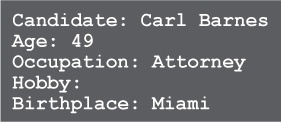
Our very first attempt at calling Candidate.new shows that its usage could be a lot smoother. We have to provide all the arguments whether we’re going to use them or not.
We could just make the hobby parameter optional, if it didn’t have the birthplace parameter following it...

Since birthplace is present, though, we get an error if we try to omit hobby...

We encounter another problem if we forget the order that method arguments should appear in...

It’s becoming clear that there are some issues with using a long list of parameters for a method. The order is confusing, and it’s hard to leave unwanted arguments off.
Using hashes as method parameters
Historically, Rubyists have dealt with these issues by using hashes as method parameters. Here’s a simple area method that, instead of separate length and width parameters, accepts a single hash. (We realize this is a bit messy. Over the next few pages, we’ll show you some shortcuts to make hash parameters much more readable!)

The convention in Ruby is to use symbols instead of strings for hash parameter keys, because looking up symbol keys is more efficient than looking up strings.
Using hash parameters offers several benefits over regular method parameters...
With regular parameters: | With hash parameters: |
|
|
Hash parameters in our Candidate class
Here’s a revision of our Candidate class’s initialize method using a hash parameter.

We can now call Candidate.new by passing the name as a string, followed by a hash with the values for all the other Candidate attributes:

We can leave one or more of the hash keys off, if we want. The attribute will just get assigned the hash default object, nil.

We can put the hash keys in any order we want:

Leave off the braces!
We’ll admit that the method calls we’ve been showing so far are a little uglier than method calls with regular arguments, what with all those curly braces:.
candidate = Candidate.new("Carl Barnes",
{:age => 49, :occupation => "Attorney"})...which is why Ruby lets you leave the curly braces off, as long as the hash argument is the final argument:

For this reason, you’ll find that most methods that define a hash parameter define it as the last parameter.
Leave out the arrows!
Ruby offers one more shortcut we can make use of. If a hash uses symbols as keys, hash literals let you leave the colon (:) off the symbol and replace the hash rocket (=>) with a colon.

Those hash arguments started out pretty ugly, we admit. But now that we know all the tricks to make them more readable, they’re looking rather nice, don’t you think? Almost like regular method arguments, but with handy labels next to them!
Candidate.new("Carl Barnes", age: 49, occupation: "Attorney")
Candidate.new("Amy Nguyen", age: 37, occupation: "Engineer")Conventional Wisdom
When you’re defining a method that takes a hash parameter, ensure the hash parameter comes last, so that callers to your method can leave the curly braces off their hash. When calling a method with a hash argument, you should leave the curly braces off if possible—it’s easier to read. And lastly, you should use symbols as keys whenever you’re working with a hash parameter; it’s more efficient.
Making the entire hash optional
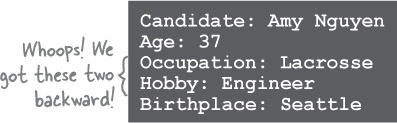
There’s one last improvement we can make to our Candidate class’s initialize method. Currently we can include all of our hash keys:
Candidate.new("Amy Nguyen", age: 37, occupation: "Engineer",
hobby: "Lacrosse", birthplace: "Seattle")Or we can leave most of them off:
Candidate.new("Amy Nguyen", age: 37)But if we try to leave them all off, we get an error:

If we leave all the keys off, then as far as Ruby is concerned, we didn’t pass a hash argument at all.
We can avoid this inconsistency by setting an empty hash as a default for the options argument:

Now, if no hash argument is passed, the empty hash will be used by default. All the Candidate attributes will be set to the nil default value from the empty hash.

If we specify at least one key/value pair, though, the hash argument will be treated as before:

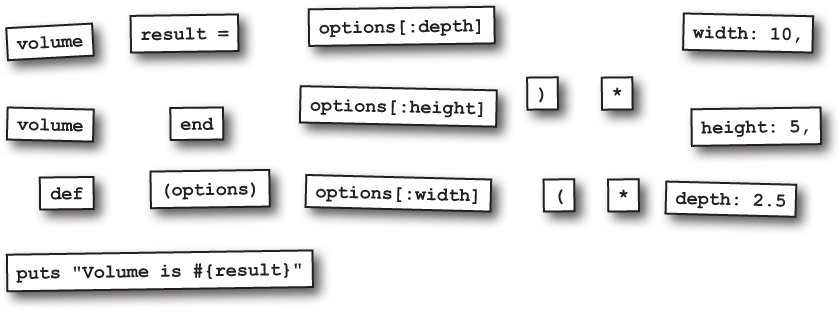
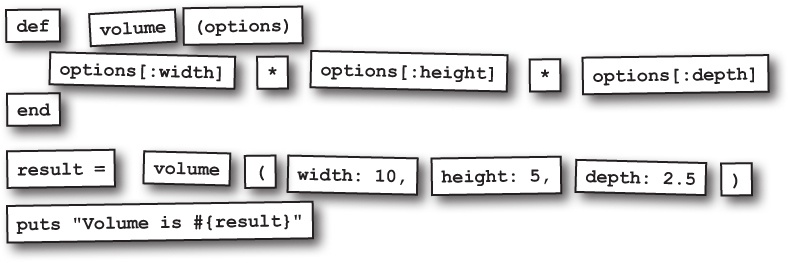
Typos in hash arguments are dangerous
There’s a downside to hash arguments that we haven’t discussed yet, and it’s just waiting to cause trouble for us... For example, you might expect this code to set the occupation attribute of the new Candidate instance, and you might be surprised when it doesn’t:

Why didn’t it work? Because we misspelled the symbol name in the hash key!

The code doesn’t even raise an error. Our initialize method just uses the value of the correctly spelled options[:occupation] key, which is of course nil, because it’s never been assigned to.

Don’t worry. In version 2.0, Ruby added keyword arguments, which can prevent this sort of issue.
Keyword arguments
Rather than require a single hash parameter in method definitions, we can specify the individual hash keys we want callers to provide, using this syntax:
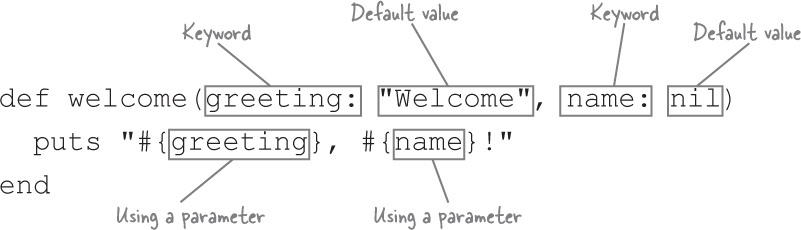
When we define the method this way, we don’t have to worry about providing keys to a hash in the method body. Ruby stores each value in a separate parameter, which can be accessed directly by name, just like a regular method parameter.
With the method defined, we can call it by providing keys and values, just like we have been:
In fact, callers are actually just passing a hash, like before:

The hash gets some special treatment within the method, though. Any keywords omitted from the call get set to the specified default values:
And if any unknown keywords are provided (or you make a typo in a key), an error will be raised:
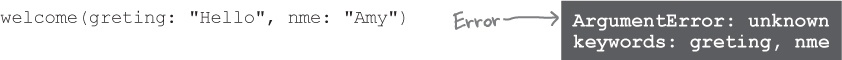
Using keyword arguments with our Candidate class
Currently, our Candidate class is using a hash parameter in its initialize method. The code is a bit ugly, and it won’t warn a caller if they make a typo in a hash key.

Let’s revise our Candidate class’s initialize method to take keyword arguments.

We use "Sleepy Creek" as a default value for the birthplace keyword, and nil as a default for the others. We also replace all those references to the options hash in the method body with parameter names. The method is a lot easier to read now!
It can still be called the same way as before...

...and it will warn callers if they make a typo in a keyword!

Required keyword arguments
Right now, we can still call Candidate.new even if we fail to provide the most basic information about a candidate:

This isn’t ideal. We want to require callers to provide at least an age and an occupation for a candidate.
Back when the initialize method was using ordinary method parameters, this wasn’t a problem; all the arguments were required.
class Candidate
attr_accessor :name, :age, :occupation, :hobby, :birthplace
def initialize(name, age, occupation, hobby, birthplace)
...
end
endThe only way to make a method parameter optional is to provide a default value for it.
class Candidate
attr_accessor :name, :age, :occupation, :hobby, :birthplace
def initialize(name, age = nil, occupation = nil, hobby = nil, birthplace = nil)
...
end
endBut wait—we provide default values for all our keywords now.
class Candidate
attr_accessor :name, :age, :occupation, :hobby, :birthplace
def initialize(name, age: nil, occupation: nil, hobby: nil, birthplace: "Sleepy Creek")
...
end
endIf you take away the default value for an ordinary method parameter, that parameter is required; you can’t call the method without providing a value. What happens if we take away the default values for our keyword arguments?
Let’s try removing the default values for the age and occupation keywords, and see if they’ll be required when we call initialize.
We can’t just remove the colon after the keyword, though. If we did, Ruby wouldn’t be able to tell age and occupation apart from ordinary method parameters.
Watch it!
Required keyword arguments were only added in Ruby 2.1.
If you’re running Ruby 2.0, you’ll get a syntax error if you try to use required keyword arguments. You’ll need to either upgrade to 2.1 (or later) or provide default values.

What if we removed the default value but left the colon after the keyword?

We can still call Candidate.new, as long as we provide the required keywords:

...and if we leave the required keywords off, Ruby will warn us!

You used to have to provide a long list of unlabeled arguments to Candidate.new, and you had to get the order exactly right. Now that you’ve learned to use hashes as arguments, whether explicitly or behind the scenes with keyword arguments, your code will be a lot cleaner!
Here are definitions for two Ruby methods. Match each of the six method calls below to the output it would produce.
def create(options = {})
puts "Creating #{options[:database]} for owner #{options[:user]}..."
end
def connect(database:, host: "localhost", port: 3306, user: "root")
puts "Connecting to #{database} on #{host} port #{port} as #{user}..."
endcreate(database: "catalog", user: "carl")create(user: "carl")createconnect(database: "catalog")connect(database: "catalog", password: "1234")connect(user: "carl")

Here are definitions for two Ruby methods. Match each of the six method calls below to the output it would produce.
def create(options = {})
puts "Creating #{options[:database]} for owner #{options[:user]}..."
end
def connect(database:, host: "localhost", port: 3306, user: "root")
puts "Connecting to #{database} on #{host} port #{port} as #{user}..."
endcreate(database: "catalog", user: "carl")create(user: "carl")createconnect(database: "catalog")connect(database: "catalog", password: "1234")connect(user: "carl")


Up Next...
We’ve shown you how to set up a hash default value. But when used incorrectly, hash default values can cause strange bugs. The problem has to do with references to objects, which we’ll learn about in the next chapter...