
Chapter 11. Human-Computer Interaction and Usable Security
Usability affects many cybersecurity domains presented throughout this book. Like other cybersecurity issues, human-computer interaction and usable security also rely on empirical experimentation. Good work in these areas also requires an understanding of how humans work. Despite its widespread applicability, usability evaluation is often overlooked and undervalued. In this chapter you will learn about the scientific principle of double-blind experimentation, how to measure usability during design and validation, and how to evaluate the usability of a cybersecurity product.
In “A Roadmap for Cybersecurity Research” published by DHS in 2009, usable security is identified as one of 11 hard problems in infosec research. This report, and others like it, point out that security and usability have historically been at odds. This situation comes in part from implementation choices that make security choices unintuitive and confusing. Security adds complexity to a system and interferes with the user’s primary goals, so it is an area where collaboration between the cybersecurity community and the usability research community is required. The science of usability as applied to security is an unmet goal.
Usability is important to consumers, as evidenced by online product reviews. For example, Qihoo 360 Security - Antivirus Free (for Android) received this review from PC Magazine:
“…I felt overwhelmed by the sheer number of features, and was disappointed when several of them didn’t work as advertised (or at all). And the app doesn’t do a great job of explaining itself, or making some of its most critical features—like anti-theft tools—easy to use.”
Experimentation and testing in human-computer interaction and usable security are naturally more difficult to automate and scale than some other problems we’ve explored in the book. When Ford wants to test a new engine part, it can use well-designed models and simulations to run 20,000 tests with the push of a button and very little cost. When it wants to test dashboards, it’s not so easy to know what consumers are going to like without doing user studies.
Usability for cybersecurity differs from general usability in several ways. For one, security is often not the primary task or concern for users. Adding security features to an email client, for example, disrupts the primary goal of sending and receiving email. Another uniqueness to usable security is the adversary. An adversary might try to take advantage of the features or flaws in human-computer interfaces and usability, even using social engineering to persuade the user into compromising security. Research topics in human-computer interaction (HCI) and usable security evolve over time as computer interaction changes. Usability of wearable technology such as fitness trackers differs from usability of a traditional laptop computer.1
An Example Scientific Experiment in Usable Security
Experiments in design and usability follow a variation on our familiar formula: participants (evaluators and users), evaluation procedure, and the environment and system setup. One kind of experiment is usability testing, completing specific tasks in a controlled manner. Another kind of experiment requires users to responding to specific questions. Yet another compares alternative designs, perhaps using analytical modeling and simulation. In his classic handbook on usability, Usability Engineering, Jakob Nielsen recommends that you conduct pilot runs during this phase, especially if user involvement is required.
Recall from Chapter 3 that there are important choices about where to conduct an experiment. In human factors, the setting can be especially important if it influences the participants. A 2011 study experimentally showed a difference between self-reported and observed actions related to web browser SSL warnings. The authors reported that “...one third of our participants claimed that their reaction would be different if they were not in a study environment and did not have the reassurance from the study environment (e.g., ethics board approval, the university as a reputable organization) that their information would be safe and secure.”2
For an example of scientific experimentation in usability, look at the paper “Does My Password Go Up to Eleven? The Impact of Password Meters on Password Selection” by Egelman et al. (2013).3 In the abstract below you can see that this study involved both a laboratory experiment and field experiment. The stated hypotheses (presented later in the paper) for the laboratory experiment were:
- H0
Passwords are not stronger when meters are present.
- H1
Passwords are stronger when users see relative strength meters compared to no meters.
- H2
Passwords are stronger when users see relative strength meters compared to “traditional” meters.
The stated hypotheses for the field experiment, based on data collected in the laboratory, were:
- H0a
Passwords are not stronger when users see meters, when creating unimportant accounts.
- H0b
Changes to the orientation and text of password meters will not result in different passwords.
Abstract from a human factors experimentPassword meters tell users whether their passwords are “weak” or “strong.” We performed a laboratory experiment to examine whether these meters influenced users’ password selections when they were forced to change their real passwords, and when they were not told that their passwords were the subject of a study. We observed that the presence of meters yielded significantly stronger passwords. We performed a followup field experiment to test a different scenario: creating a password for an unimportant account. In this scenario, we found that the meters made no observable difference: participants simply reused weak passwords that they used to protect similar low-risk accounts. We conclude that meters result in stronger passwords when users are forced to change existing passwords on “important” accounts and that individual meter design decisions likely have a marginal impact.
This would be a straightforward experiment for you to replicate. The most challenging part of this study is the experimental design: how do you get study participants to think that the thing you’re measuring (passwords) isn’t the subject of the study?
Double-Blind Experimentation
Blind experimentation describes a type of experimental procedure where information is concealed from the test subject or the experimenter to avoid human bias. In a blind medical trial of a new drug, for example, some test subjects are given the new drug and some are given a placebo, and neither knows which he or she has been given. An experiment is double-blind when neither the subjects nor the experimenters know which subjects are in the test and control groups during the experiment. To maintain the integrity of the test, it is important for test subjects to be randomly assigned to the test and control groups. Double-blind experiments are generally considered more scientifically rigorous than blind or nonblind experiments.
The practice of double-blind experimentation can be extended to various areas of cybersecurity. A double-blind penetration test would be one in which the testers are given very little information about the target, perhaps only a name or website, and the target organization is mostly unaware about the test. With this setup, we seek to create a more realistic test by removing the bias that the pen testers had guilty knowledge that real attackers would not have. We also hope to create a realistic situation to test the target organization’s security response by not informing them about the test.
Here’s another example. You want to compare the detection performance of two malware protection systems. Using a collection of malicious and benign binaries, you randomly select a binary, present it to one of the systems, and observe if the binary is identified as malicious or benign. The experiment is double-blind because neither you nor the malware protection system knows whether the test binary is malicious or not during the test. Of course, you must also have a colleague or program record the actual disposition of each binary in the experiment. After the experiment is over, you can compare how many binaries each malware protection system got right. The benefit of doing a double-blind test in this situation is to remove the real or perceived bias that you, the experimenter, might selectively choose test samples that you know one system might get right or wrong.
The cybersecurity community uses another type of testing called black box testing, which may appear to resemble blind testing. In a black box test, the examiner investigates the functionality of the target without knowing how it works. The black box methodology is sometimes used to eliminate examiner bias. In most cases, however, black box testing is used to abstract unnecessary details from testers.
Another time you may hear about double-blind procedures is in the prepublication peer review of scientific papers for conferences and journals. In a double-blind review, the people reviewing the paper are unaware of the authors’ identities and the reviewers’ identities are likewise concealed from the authors. The primary goal in double-blind review is to avoid biases and conflicts of interest between the reviewers and authors.
Usability Measures: Effectiveness, Efficiency, and Satisfaction
The International Standards Organization (ISO) defines usability as “the effectiveness, efficiency, and satisfaction with which specified users achieve specified goals in particular environments.” (ISO 9241-11: Guidance on Usability (1998)). The three defining characteristics are explained as follows:
- Effectiveness
The accuracy and completeness with which specified users can achieve specified goals in particular environments. Example measurements include percentage of goals achieved, functions learned, and errors corrected successfully.
- Efficiency
The resources expended in relation to the accuracy and completeness of goals achieved. Example measurements include the time to complete a task, learning time, and time spent correcting errors.
- Satisfaction
The comfort and acceptability of the work system to its users and other people affected by its use. Example measurements include ratings for satisfaction, ease of learning, and error handling.
A subsequent standard, ISO 20282: Ease of Operation of Every Day Products, makes specific recommendations of design attributes and test methodologies for everyday products. This document makes these five recommendations for easy-to-operate products:
Identify the main goal of your product.
Identify which user characteristics and which elements of the context of use could affect the ease of operation of your product.
Establish the impact of each of these characteristics on the ease of operation of your product.
Ensure that the product design takes account of these characteristics.
Review the final design to ensure it complies with the characteristics.
One key benefit of these characteristics to science is that they are quantitative in nature. Want to measure the usability of a reverse engineering tool? Give it to a user along with a set of tasks to accomplish using the tool, then measure how many questions she got right, how long it took to complete the questions, and how well she liked the tool. The test methods in ISO 20282 use effectiveness as the critical performance measure, defined explicitly as “the percentage of users who achieve the main goal(s) of use of a product accurately and completely.”
Of the three usability characteristics, satisfaction is the one that many infosec professionals are unaccustomed to measuring. You have no doubt filled out surveys of this type that measure your satisfaction with a conference or hotel or breakfast cereal. Common practice is to use an ordinal scale with five or fewer points. There is no consensus among experts about whether to use an even or odd point scale, but labeling the points on the scale with descriptive text is preferred to numbers alone. In Figure 11-1, you can see an example scale that you might use with the survey question “How satisfied were you with the reverse engineering tool?”

Figure 11-1. A rating scale with five labeled points and two nonscaled choices for a question like “How satisfied were you with the tool?”
Professor Ben Shneiderman at the University of Maryland is an expert on human-computer interaction and information visualization. He has proposed the following Eight Golden Rules of Interface Design in his book Designing the User Interface:
Strive for consistency
Cater to universal usability
Offer informative feedback
Design dialogs to yield closure
Prevent errors
Permit easy reversal of actions
Support internal locus of control
Reduce short-term memory load
These “rules” distill much research into just a few principles and offer a guide to good interaction design. As with most sets of rules, these offer the opportunity to measure and evaluate how well the proposed solution has achieved the desired principle. This list offers another set of usability measures that are complementary to effectiveness, efficiency, and satisfaction. An ideal interface which achieves Shneiderman’s principles should score highly in usability.
Let’s say you wanted to use Shneiderman’s rules as motivation for a test of a new product. Rule #1 is consistency, which is related to predictable and stable language, layout, and design. You could measure consistency in any number of ways. For example, you might compare the training time required to learn Version 1.0 of your software compared to Version 2.0, and find that changes you made to increase consistency directly reduced the amount of training time. On the other hand, you might find that consistency as a primary concern is distracting for users and their work. Or, you might have specialized knowledge about the context in which people will use the product that contradicts the standard rule. If your target users always run EnCase (for forensic analysis) alongside Microsoft Word (for documentation and reporting), you might want to know if consistency between the tools—does Ctrl-S mean Save in both?—is more important than the internal consistency of a single tool.
Usability is not necessarily the same as utility and desirability. People use tools with low usability all the time, perhaps because the tools meet a need or achieve an objective. The three usability characteristics can be correlated—high effectiveness may lead to high satisfaction—but may also be independent. Users can be highly effective with a tool but be highly unsatisfied with it.
Finally, let’s discuss the difference between beta testing and usability testing. Both beta testing and usability testing are intended to gather user feedback to help developers improve a product. Beta testing typically occurs late in the software development cycle when most design and functionality decisions have already been made. Beta testing provides bug reports and general usage of new features. Usability testing tends to happen before beta testing when there is still time to change fundamental aspects of the solution, and provides insights about whether new features are usable. These two tests are complementary and both should be done when possible. While users often do beta testing in their home or office, and usability testing is sometimes done in a lab, both tests are flexible and amenable to variations in execution.
With these ideas and considerations for what data to collect, the next section discusses methods for how to collect data.
Methods for Gathering Usability Data
There are many ways to gather usability data. In this section, we’ll present some standard methods and other considerations for gathering usability data during two different phases of development: design and validation. Different approaches to usability testing are used during these two phases.
Testing Usability During Design
Usability testing during the design phase is focused on formative assessment, which provides insights about how to improve the design. There are two approaches to usability testing protocols during the tool design phase: moderated and unmoderated.
Moderated data gathering involves the use of a facilitator who observes and/or asks questions as a participant attempts a task, and are often conducted in a controlled setting such as a laboratory. A trained and experienced facilitator can document and solicit very valuable insights about the participant’s tool experience during the session. If you have the luxury of time, money, and staff, moderated sessions are a powerful choice.
Unmoderated sessions allow test subjects to provide usability input independently. Remote unmoderated usability testing over the Internet even allows data gathering from the comfort of home. Unmoderated tests are increasingly popular given their convenience and low cost. Remote testing is well suited for web-based interfaces but may be inappropriate for cybersecurity hardware or specialized environments. Remote testing can enable you to more easily draw a large and diverse group of study participants, and several online services can handle participant recruitment, testing, data gathering—even some data analysis.
There are four common approaches for ways of gathering data during usability testing, and one or more may be appropriate for your situation:
Concurrent Think Aloud testing encourages the participant to speak aloud to a (mostly passive) facilitator and explain in a stream of consciousness what he or she is thinking and doing.
Retrospective Think Aloud is a technique where a facilitator asks the participant after the task is complete to orally explain what he or she did. The participant may narrate his or her actions while watching a video replay of the task.
Concurrent Probing involves a facilitator asking probing questions to the participant during the test to solicit details about what or why the participant took a certain action.
Retrospective Probing is a technique for asking the participant probing questions after the session is over. This technique may be done with or without a human facilitator, and may be used along with another method.
In a good usability test, your testers will use your tool to do whatever your real users want to do. Rather than simply asking your testers to “look at” your tool and tell you what they think, come up with a short list of definite tasks—finding a bit of information, collecting and comparing information from different locations, making judgments about the content, etc. Avoid yes/no questions like “Did you think the navigation was clear?” Instead, ask subjects to rate their own responses, as shown in Example 11-1.
Example 11-1. Example usability question
Respond to the following statement: This tool was easy to use.
Disagree Strongly
Disagree
Disagree Somewhat
No Opinion
Agree Somewhat
Agree
Agree Strongly
Not only does this allow you to report trends (“Subjects reported an average score of 4.2 for Question 1”), but it allows you to easily quantify changes between tests. Take a look at Table 11-1.
| Test 1 | Test 2 | Improvement | |
|---|---|---|---|
| Q1. The tool is easy to use. | 4.2 | 5.0 | +19% |
| Q2. The tool is too complex. | 4.0 | 3.0 | +25% |
| Q3. The tool could do everything I wanted it to do. | 3.0 | 4.5 | +50% |
Tip
Usability testing allows you to observe what people do and to measure their performance. You are the expert who will use the resulting data to make decisions about whether or not to change the design.
Testing Usability During Validation and Verification
It is important to conduct usability testing when the design is complete, during the validation and verification stage. In this phase, you may want to conduct summative testing. Summative testing is used to determine metrics for complete tasks, including time and success rates.
It may be helpful to describe in detail one example of gathering usability data. Assume you just finished creating a new open source network scanning tool. You want to get feedback from users about usability and decide to use retrospective probing. You find some willing participants and give them the tool along with three short questionnaires: pre-test, post-task, and post-test.
Note
Surveys and questionnaires are prescriptive methods of data collection because the structure dictates the type and depth of answers that participants provide. The way that questions are asked is very important because the response choices offered strongly affect the responses that participants can provide.
In the pre-test questionnaire, you might want to ask the user’s education, age, years of experience, and familiarity with other network scanning tools. The post-task questionnaire includes items related to the task and your desired usability metrics. For example, using a five-point scale (like that in Figure 11-1), ask for agreement with the statement “I was satisfied with the ease of completing this task.” In the post-test questionnaire, you can ask structured but free-form questions such as “What are two things about the design that you really liked?” and “What are two things about the design that you didn’t like?”
Case Study: An Interface for User-Friendly Encrypted Email
Usable interfaces for email encryption remain an open problem. One of the classic papers in security usability written in 1999 is “Why Johnny Can’t Encrypt: A Usability Evaluation of PGP 5.0,”4 and considers the Pretty Good Privacy (PGP) encryption software that had come out eight years prior in 1991. “We conclude that PGP 5.0 is not usable enough to provide effective security for most computer users,” write the authors, “despite its attractive graphical user interface, supporting our hypothesis that user interface design for effective security remains an open problem.” In 2015, sixteen years later, usable email encryption and widespread adoption of such solutions remain elusive.
Let’s walk through a hypothetical scientific experiment in usability that evaluates secure, encrypted email. Assume that prior work has shown the following assertions about secure email:
Users will reject secure email if it requires too much effort.
Users are uninterested and unwilling to obtain or manage cryptographic keys.
Cryptography is confusing and overwhelming for users, even those who desire security and privacy.
Now assume you work for a university that wants to deploy a Cisco secure email solution called Cisco Registered Envelope Service (CRES), and you want to evaluate its usability as a security product. Companies, universities, and other customers deploy CRES inside their network alongside a traditional email server. To encrypt an email with CRES, the sender simply adds a special keyword like “[secure]” in the email subject line. The email is automatically routed to a secure internal email server where it is encrypted. Email recipients inside the company receive secure email like any non-secure message. External recipients are redirected to a web interface where they register and then view the secure message in a browser. How could you evaluate the usability of this solution?
A New Experiment
For this experiment, you will have a representative group of test subjects perform the task of using CRES. You will gather usability data from the group by collecting measurements that can help you accept or reject this hypothesis:
University students and faculty will be capable of using CRES to send and receive encrypted email within a reasonable time overhead, and report satisfaction with the experience.
Imagine that the university has 14,000 students and faculty. In order to achieve a 95% confidence level with a 5% confidence interval, a sample size of 374 participants is required. Ideally, you would like a completely random sample of the university population without the added bias of using only freshmen or only computer engineering students. In reality, this goal is often difficult, so let’s pretend that you sample from a mandatory course.
In this study plan, we will invite our prospective participants by email to the study website. In a few brief paragraphs, the page describes the purpose of the study (to understand how well users like and perform with encrypted email), the time required (say, 20 minutes), and the benefits to the participant (a chance to influence the ultimate solution). Next we ask a few preliminary questions about computer skills and previous experience with encryption. Then we provide a brief tutorial including step-by-step instructions for using CRES. Then we begin the actual task as follows. Users are instructed to send an encrypted email to the study team at a particular email address. The server records the time when the user logs into the mail server and records when the encrypted message is sent (we could alternatively or additionally ask the user to self-report the amount spent on the task). Your study team later analyzes the study’s special mailbox and records the senders who successfully sent them an encrypted message. You also want to test decryption. When the participant is ready, he clicks a web form indicating that he is ready to begin. An automated system sends him an encrypted email and he is instructed to email the decrypted message content to the study’s special email address. The server again records the timestamps of each event in this task. Having completed encryption and decryption, you ask the participant how satisfied he was with CRES.
When data collection is complete, you then aggregate and graph the results as shown in Figure 11-2.
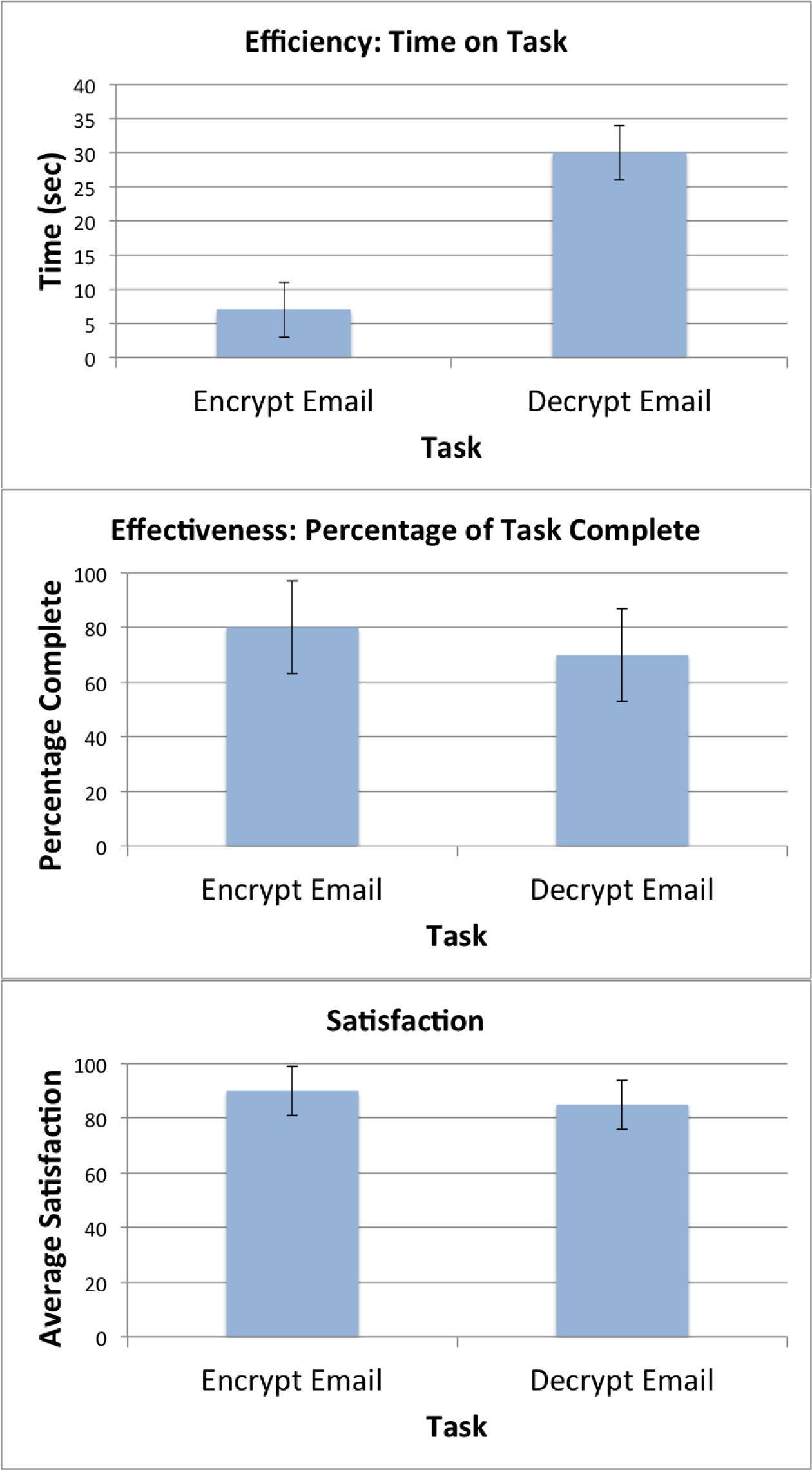
Figure 11-2. Efficiency, effectiveness, and satisfaction with CRES
The data offers insights about how efficiently and effectively users could perform the encryption and decryption task. You might want to dig deeper with statistical analysis into the correlation between effectiveness or efficiency and satisfaction—did users who failed to complete a task report lower satisfaction, or did satisfaction go down the longer it took to complete the task? These results alone are insufficient to make a recommendation about whether to adopt CRES. This data should be compared to a control that in this study would be regular unencrypted email. By performing a well-designed experiment and accepting a hypothesis, you can be confident that the results offer scientifically grounded insights to help you and other decision-makers choose an encrypted email solution.
How to Find More Information
One of the premier venues for human factors research, including usability, is the yearly ACM CHI (Computer-Human Interaction) Conference on Human Factors in Computing Systems. The annual Symposium on Usable Privacy and Security (SOUPS) brings together researchers and practitioners in human-computer interaction, security, and privacy. The Workshop on Usable Security (USEC) is another.
Conclusion
This chapter applied cybersecurity science to human-computer interaction and usability. The key concepts and takeaways are:
Experimentation and testing in human-computer interaction and usable security are difficult to automate and scale but are highly important to end users.
Experiments in usability testing include completing specific tasks in a controlled manner and comparing alternative designs.
Blind experimentation is a procedure where information is concealed from the test subject or the experimenter to avoid human bias in the experiment. In double-blind experiments, neither the subjects nor the experimenters know which subjects are in the test and control groups during the experiment.
Three measurable usability characteristics are effectiveness, efficiency, and satisfaction.
Beta testing occurs late in the software development cycle. Usability testing occurs earlier in the design phase while there is still time to change fundamental aspects of the solution.
Usability experiments can be done during design or validation. Testing during the design phase is focused on providing insights about how to improve the design. Testing during validation is used to determine metrics for complete tasks, including time and success rates.
References
Lorrie Faith Cranor and Simson Garfinkel. Security and Usability: Designing Secure Systems that People Can Use (Boston, MA: O’Reilly Media, 2005)
Joseph S. Dumas and Janice C. Redish. A Practical Guide to Usability Testing (Bristol, UK: Intellect Ltd; Rev Sub edition, 1999)
Simson Garfinkel and Heather Richter Lipford. Usable Security: History, Themes, and Challenges (San Rafael, CA: Morgan & Claypool Publishers, 2014)
Jonathan Lazar, Jinjuan Feng, and Harry Hochheiser. Research Methods in Human-Computer Interaction (Indianapolis, IN: Wiley, 2010)
Ben Shneiderman and Catherine Plaisant. Designing the User Interface: Strategies for Effective Human-Computer Interaction: Fifth Edition (Boston, MA: Addison-Wesley, 2010)
Stephen A. Thomas. Data Visualization with JavaScript (San Francisco, CA: No Starch Press, 2015)
1 For more, see National Research Council Steering Committee on the Usability, Security, and Privacy of Computer Systems, Toward Better Usability, Security, and Privacy of Information Technology: A Report of a Workshop. Washington, DC: The National Academies Press, 2010.
2 Andreas Sotirakopoulos, Kirstie Hawkey, and Konstantin Beznosov. On the Challenges in Usable Security Lab Studies: Lessons Learned from Replicating a Study on SSL Warnings (Proceedings of the Seventh Symposium on Usable Privacy and Security (SOUPS), 2011).
3 Serge Egelman, Andreas Sotirakopoulos, Ildar Muslukhov, Konstantin Beznosov, and Cormac Herley. 2013. Does my password go up to eleven?: The impact of password meters on password selection. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’13). ACM, New York, NY.
4 Alma Whitten and J. D. Tygar. Why Johnny Can’t Encrypt: A Usability Evaluation of PGP 5.0 (Proceedings of the 8th USENIX Security Symposium, 1999).