
Chapter 8. Digital Forensics
Digital forensics holds a unique distinction among the group of cybersecurity fields in this book because it requires science. Forensic science, by definition, is the use of scientific tests or techniques in connection with the detection of crime. There are many corporate investigators who use forensic-like tools and techniques for nonlegal uses such as internal investigations and data recovery, but the requirement for scientific rigor in those cases may be less demanding. In this chapter, we will talk about cybersecurity science in digital forensics, especially for tool developers, by exploring the requirements for scientific evidence in court, the scientific principle of repeatability, and a case study highlighting the differences between laboratory and real-world experiments.
The forensics community has a small but active international research community. There is a much larger population of digital forensic practitioners who use forensic tools and techniques to analyze digital systems but do not perform experimentation as their primary job. The research community supports the practitioners by investigating new and improved ways to collect, process, and analyze forensic data. In recent years the topics of interest to researchers have included memory analysis, mobile devices, nontraditional devices (e.g., gaming systems), and big data mining.
An Example Scientific Experiment in Digital Forensics
For an instructive example that illustrates scientific experimentation in digital forensic tool development, look at the abstract for “Language translation for file paths” by Rowe, Schwamm, and Garfinkel (2013). This paper presents a new tool and the experimental evaluation of its accuracy. In the abstract that follows, you can see that the first line of the abstract identifies the problem that these researchers were looking to address: forensic investigators need help understanding file paths in foreign languages. The implied hypothesis is that directory-language probabilities from words used in each directory name over a large corpus, combined with those from dictionary lookups and character-type distributions, can infer the most likely language. The authors give their contributions and results, including the sample size and accuracy. The test data is available to other researchers who might want to repeat or build upon these results, and the methodology is described in sufficient detail to enable other researchers to reproduce the experiment.
Abstract from a digital forensics experimentForensic examiners are frequently confronted with content in languages that they do not understand, and they could benefit from machine translation into their native language. But automated translation of file paths is a difficult problem because of the minimal context for translation and the frequent mixing of multiple languages within a path. This work developed a prototype implementation of a file-path translator that first identifies the language for each directory segment of a path, and then translates to English those that are not already English nor artificial words. Brown’s LA-Strings utility for language identification was tried, but its performance was found inadequate on short strings and it was supplemented with clues from dictionary lookup, Unicode character distributions for languages, country of origin, and language-related keywords. To provide better data for language inference, words used in each directory over a large corpus were aggregated for analysis. The resulting directory-language probabilities were combined with those for each path segment from dictionary lookup and character-type distributions to infer the segment’s most likely language. Tests were done on a corpus of 50.1 million file paths looking for 35 different languages. Tests showed 90.4% accuracy on identifying languages of directories and 93.7% accuracy on identifying languages of directory/file segments of filepaths, even after excluding 44.4% of the paths as obviously English or untranslatable. Two of seven proposed language clues were shown to impair directory-language identification. Experiments also compared three translation methods: the Systran translation tool, Google Translate, and word-for-word substitution using dictionaries. Google Translate usually performed the best, but all still made errors with European languages and a significant number of errors with Arabic and Chinese.
This example illustrates one kind of scientific experiment involving digital forensic tools. Such experiments could be done for other new tools, including those beyond digital forensics. In the next section, we will discuss the unique requirements for digital forensic tools because of their involvement in the legal process.
Scientific Validity and the Law
Digital evidence plays a part in nearly every legal case today. Even when the suspect is not attacking a computer system, he or she is likely to have used a cellphone, camera, email, website, or other digital medium that contains some bit of information relevant to investigation of a crime. It is important for forensic scientists to understand how the legal system deals with scientific evidence, and the unique requirements that the law imposes on tool development and scientific validity.
Scientific knowledge is presented in court by expert witnesses. Two Supreme Court decisions provide the framework for admitting scientific expert testimony in the United States today. The Daubert standard, from Daubert v. Merrell Dow Pharmaceuticals (1993) is used in federal cases and many states, though the Frye standard, from Frye v. United States (1923), is still used in the other states. Daubert says that scientific knowledge must be “derived by the scientific method.” It continues in the same way that we previously discussed the scientific method, saying “scientific methodology today is based on generating hypotheses and testing them to see if they can be falsified.”
According to Daubert, scientific evidence is valid and can be admitted in court when it adheres to testing, peer review, the existence of a known error rate or controlling standards, and the general acceptance of the relevant scientific community. These are important to remember as a digital forensic practitioner, developer, or researcher. Note that these standards deal with the method used to reach a conclusion, not the tool itself, though questions are often raised about the implementation or use of tools. The regulation of scientific evidence is unique to the United States, though it has been used in two Canadian Supreme Court cases and proposed in England and Wales. International law used between nations has few restrictions on the admissibility of evidence, and free evaluation of evidence in court prevails.
It is insightful to observe exactly how expert witness and tool validation plays out in the courtroom. Below is an excerpt of court testimony from United States of America v. Rudy Frabizio (2004), in which Mr. Frabizio was charged with possession of child pornography.1 In this exchange, attorney Dana Gershengorn asks the witness, Dr. Hany Farid, questions seeking to establish general acceptance of the science of steganography:
Q. Professor Farid, is the science underlining your work in steganography, that is, the patterns and the fact that they’re distinguishable in images that have been tampered with by putting in covert messages as opposed to images that have not been so tampered, is that well accepted now in your field?
A. Yes, it is.
Q. Is there any controversy on that that you’re aware of, that is, that maybe these differences in statistics don’t exist? Are you aware of any published material that contradicts that?
A. No.
Q. And is the technology that you’ve used in your steganography work, the program that you’ve used, is that the same technology, similar program that you used in examining images in the Frabizio case?
A. Yes, it is.
Later in the questioning, Dr. Farid describes the error rate for the software he used to analyze images in the case:
THE COURT: A fixed false positive rate means what now?
THE WITNESS: It means .5 percent of the time, a CG image, computer graphics will be misclassified as photographic.
Q. .5 percent of the time?
A. Yes, one in two hundred.
Q. Now, 30 percent of the time an image that is real, your program will say—
A. Is computer generated. Right. We need to be safe. We need to be careful. And, of course, you know, ideally the statistics would be perfect, they’d be 100 percent here and 100 percent here, but that’s hard. We’re moving towards that, but this is where we are right now.
Q. And in your field, having worked in this field for a long time and having reviewed other people’s publications in peer review journals, is .5 percent accuracy acceptable in your field?
A. Yes.
This exchange illustrates the type of questioning that occurs in many court cases where digital evidence is presented. It may eventually happen with software you create if that software is used to produce evidence used in court! EnCase is one of the most widely used commercial software packages for digital forensics, and is routinely used to produce evidence used in court. Guidance Software, the makers of EnCase, has published a lengthy report that documents cases where EnCase was used and validated against the Daubert/Frye standards in court. You need not create such comprehensive documentation for every tool you create, but there are a few simple things you should do.
Warning
Cybersecurity science in forensics that involves looking at potentially offensive, illegal, or personal information can raise complex legal and ethical issues. Consult an attorney or ethics professional to ensure that your experiments are safe, legal, and ethical. For more on human factors, see Chapters 11 and 12.
If you develop digital forensics software, and the evidence resulting from the use of your tools may be used in court, an expert witness may someday be asked to testify to the validity of your software. Here are a few things you can do to help ensure that your tools will be found valid in court, should the need arise:
Make your tools available. Whether you develop free and open source software or commercial software, your software can only be tested and independently validated if it is available to a wide audience. Consider putting them on GitHub or SourceForge. As much as you are able, keep them up-to-date—abandoned and unmaintained tools may be discounted in court.
Seek peer review and publication. It is important to the courts that your peers in the digital forensics community review, validate, and test your tools. This is an excellent opportunity for scientific experimentation. Publication is also one way to report on tests of error rates.
Test and document error rates. No software is flawless. Apply the scientific method and objectively determine the error rates for your software. It is much better to be honest and truthful than to hide imperfections.
Use accepted procedures. The courts want procedures to have “general acceptance” within the scientific community (this is commonly misunderstood to mean that the tools must have general acceptance). Open source is one way to show procedures you used, allowing the community to evaluate and accept them.
It may not be necessary to prepare every forensic tool and technique you create for the court. Following the scientific method and best practices in the field is always advised, and will help ensure that your tools are accepted and validated for court if the need arises.
Scientific Reproducibility and Repeatability
Reproducibility and repeatability are two important components for the evaluation of digital forensic tools and for scientific inquiry in general. Reproducibility is the ability for someone else to re-create your experiment using the same code and data that you used. Repeatability is about you running the test again, using the same code, the same data, and the same conditions. These two cornerstones of scientific investigation are too often overlooked in cybersecurity. A 2015 article in Communications of the ACM described their benefits this way: “Science advances faster when we can build on existing results, and when new ideas can easily be measured against the state of the art… Our goal is to get to the point where any published idea that has been evaluated, measured, or benchmarked is accompanied by the artifact that embodies it. Just as formal results are increasingly expected to come with mechanized proofs, empirical results should come with code.”2
Consider a digital forensics technique that attempts to identify images of human beings in digital images. This is an important problem when investigating child pornography cases, and a computationally challenging problem to train a computer to identify images of humans. The developers of a new program, which contains a new algorithm for detecting human images, wish to show reproducibility and repeatability. They can show repeatability by running the same program several times, using the same input files, and achieving the same results. If the results vary, the experimenters must explain why. To achieve reproducibility, the developers should offer the exact program, the exact input files, and a detailed description of the test environment to others, allowing independent parties to show that they can (or cannot) achieve the same results as the original developers.
There are many challenges to reproducibility in cybersecurity and digital forensics. One obvious challenge is the incredible difficulty of ensuring identical conditions for different program runs. Computers are logical and predictable machines, yet replicating the exact state of a machine is nontrivial given their complexity. Sometimes the very act of doing an experiment changes the conditions, so documentation is critical. Virtual machine snapshots offer the ability to revert to an identical machine snapshot, but virtual machine guest performance may be affected by the host’s performance (including other VMs running on the host).
A second significant challenge to reproducibility is that useful datasets are not widely available to researchers. As we saw in Chapter 2, there are a few repositories of available real, simulated, and synthetic test data. DigitalCorpora.org is a site specifically devoted to datasets for digital forensics research and contains various collections of disk images, packet captures, and files.
Case Study: Scientific Comparison of Forensic Tool Performance
In this section, we will walk through a hypothetical scientific experiment in digital forensics. In this experiment you are curious to know if parallel, distributed, cloud-based forensic processing using MapReduce can improve the speed of common forensic tasks. Given the volumes of data that forensic laboratories and analysts have to process, increased throughput would be valuable to the community. In your preliminary background reading, you find an implementation of the common open source forensic suite The Sleuth Kit for Hadoop. Further, no performance data seems to exist, making this a new and interesting question to consider. You form your hypothesis as follows:
The time required to construct a digital forensic timeline will be 75% faster using a Hadoop cluster than a traditional forensic workstation.
The independent variable in the hypothesis is the execution platform, which is a cloud and a desktop. You want to experimentally measure the execution time on both platforms, ensuring as much as possible that other variables are consistent. Therefore, you must use the same disk image in both cases for a fair test. You select a publicly available 500 MB USB drive image for this test. Because you wish to compare the benefit of parallel processing using TSK Hadoop, it would be wise to use comparable machine specifications so that one test is not unfairly advantaged by better hardware. Table 8-1 shows basic specifications for a single forensic workstation and 10 Amazon EC2 instances. The combination of the 10 EC2 instances is roughly equivalent to the workstation in CPU, memory, and storage. It is important to record and report the hardware specifications you used so that other researchers can replicate and validate your results.
| Forensic workstation | Amazon EC2 instances (x10) |
|---|---|
Dell Precision T5500 Ubuntu 14.04.1 LTS (64-bit) Dual Intel 6 Core Xeon X5650 @2.66GHz 24GB DDR3 Memory 1TB 3.5” 7200 RPM SATA | T2 Small Type Amazon Linux AMI (64-bit) 1 Intel Xeon family vCPU @2.5GHz 2GB Memory 100GB EBS magnetic storage volume |
Each run of the experiment will measure the execution time required for The Sleuth Kit to construct a timeline of the input drive image. You prepare both execution environments, run the process, and get a result. Because individual executions of a program are subject to many variables on the host computer (e.g., other background processes, etc.), you repeat the timeline creation five times to assure yourself that the results are consistent. This gives you the results in Table 8-2.
| TSK on forensic workstation | TSK Hadoop on Amazon EC2 |
|---|---|
| Run #1: 25 seconds | Run #1: 15 seconds |
| Run #2: 20 seconds | Run #2: 17 seconds |
| Run #3: 21 seconds | Run #3: 16 seconds |
| Run #4: 24 seconds | Run #4: 13 seconds |
| Run #5: 22 seconds | Run #5: 15 seconds |
These results indicate that MapReduce runs approximately 33% faster on the 500 MB disk image. There were no extreme outliers, giving confidence to the data obtained. The data so far shows that you should reject your hypothesis, even though MapReduce is measurably faster. You now decide to test whether these results hold for different sizes of disk images. Using the Real Data Corpus, you obtain one disk image each of size 1 GB, 10 GB, 500 GB, and 2 TB. You repeat the timeline creation five times for each disk image size, and graph the results as shown in Figure 8-1. As before, it appears that Hadoop is consistently faster than the single workstation, but not 75% faster as you hypothesized. At this point you could modify your hypothesis to reflect and apply your new knowledge. You could also extend the experiment with a new hypothesis and compare various Hadoop node sizes. Perhaps a five-node cluster performs as well as 10 in this case, or perhaps 20 nodes is substantially faster.
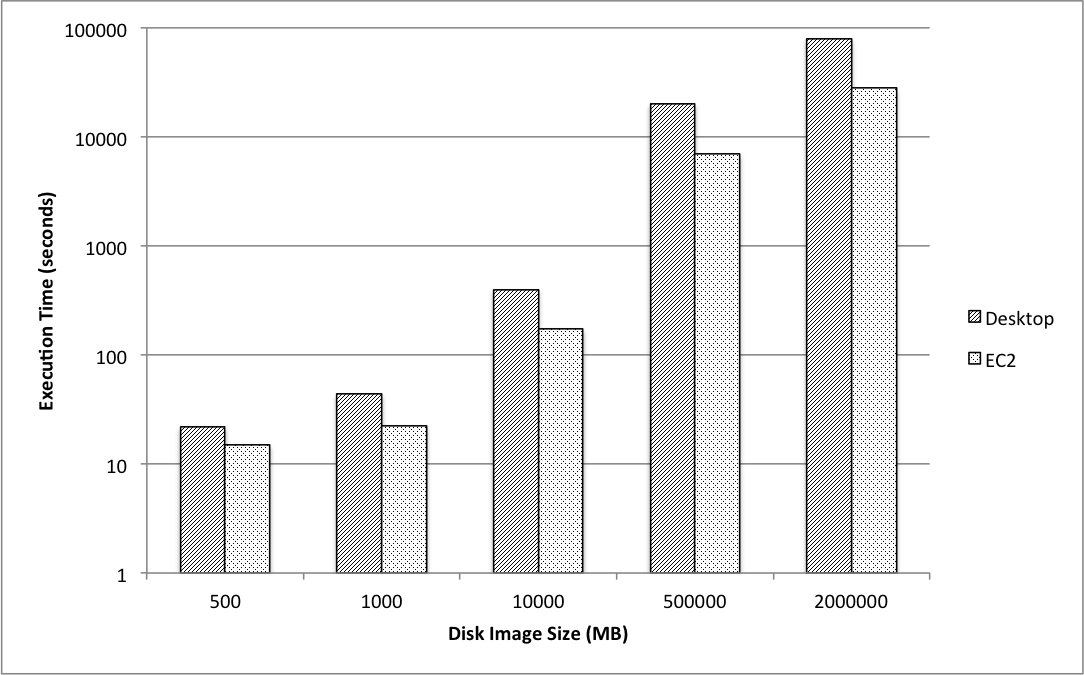
Figure 8-1. Example comparison of execution times on a workstation versus MapReduce for various disk image sizes
There are several ways to put your results to work. You should at least consider publishing your results online or in a paper. This preliminary data might be convincing enough to even start a company or build a new product that specializes in forensics as a service using MapReduce. At the very least you will have learned something!
How to Find More Information
Research is presented in general cybersecurity journals and conferences but also at forensic-specific venues including the Digital Forensics Research Workshop (DFRWS), IFIP Working Group 11.9 on Digital Forensics, and American Academy of Forensic Sciences. A popular publication for scientific advances in digital forensics is the journal Digital Investigation.
Conclusion
This chapter covered cybersecurity science as applied to digital forensics and forensic-like investigations and data recovery. The key takeaways are:
Digital forensic scientists and practitioners must understand how the legal system deals with scientific evidence, and the unique requirements that the law imposes on tool development and scientific validity.
According to Daubert, scientific evidence is valid and can be admitted to court when it adheres to testing, peer review, the existence of a known error rate or controlling standards, and the general acceptance of the relevant scientific community.
Reproducibility is the ability for someone else to re-create your experiment using the same code and data that you used. Repeatability is the ability for you to run a test again, using the same code, the same data, and the same conditions.
We explored an example experiment to study if cloud-based forensic processing could construct a forensic timeline faster than traditional methods.
References
Eoghan Casey. Digital Evidence and Computer Crime, Third Edition. (Waltham, MA: Academic Press, 2011)
Cara Morris and Joseph R. Carvalko. The Science and Technology Guidebook for Lawyers. (Chicago, IL: American Bar Association, 2014)
1 Note: this is offered only as an example of the Daubert process. In 2006, a motion was filed to exclude this expert testimony. The memo stated, “The government initially offered Professor Hany Farid, a Dartmouth College professor of computer science and neuroscience. Professor Farid sought to distinguish real and computer-generated images through a computer, rather than using visual inspection. Farid’s computer program purported to measure statistical consistencies within photographs and computer-generated images to determine whether or not an image was real. After one day of a hearing, the government withdrew Dr. Farid as an expert witness. Defense counsel noted that 30 percent of the time, Farid’s program classified a photograph [i.e., a real image] as a computer-generated image, and she highlighted these errors. One stood out in particular: an image of a cartoon character, ‘Zembad,’ a surrealistic dragon, falsely labeled ‘real.’”
2 Shriram Krishnamurthi and Jan Vitek. The real software crisis: repeatability as a core value. Communications of the ACM 58, 3 (February 2015), 34−36.