
Now that you have a basic understanding of sockets (covered in Chapter 12) and error handling, you know enough to make a web server that can serve dynamic web pages written in Lisp. After all, why should Apache (the world’s most popular web server) have all the fun?
Hypertext Transfer Protocol, or HTTP, is the Internet protocol used for transferring web pages. It adds a layer on top of TCP/IP for requesting pages once a socket connection has been established. When a program running on a client computer (usually a web browser) sends a properly encoded request, the server will retrieve the requested page and send it over the socket stream in response.

For example, suppose the client is the Firefox web browser, and it asks for the page lolcats.html. The client’s request might look like this:
GET /lolcats.html HTTP/1.1 Host: localhost:8080 User-Agent: Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.5) Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-us,en;q=0.5 Accept-Encoding: gzip,deflate Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7 Keep-Alive: 300 Connection: keep-alive
For our web server, the most important part of this request is the first line. There we can see the type of request made (a GET request, which means we just want to look at a page without modifying it), and the name of the page requested (lolcats.html). This data sent to the server is called the request header. You’ll see later that additional information can be sent to the server below the request header, in a request body.
Note
To readers from the distant future, lolcats was a viral Internet phenomenon from early in the third millennium. It involved pictures of cats with funny captions. If people of your time are no longer familiar with lolcats, it is of no great loss.
In response, the server will send an HTML document that represents the web page over the socket stream. This is called the response body. Here is what a response body might look like:
<html>
<body>
Sorry dudez, I don't have any L0LZ for you today :-( </body>
</html>
An HTML document is wrapped in html opening ![]() and closing tags
and closing tags ![]() . Within these tags, you can declare a body section
. Within these tags, you can declare a body section ![]() . In the body section, you can write a text message that will be displayed in the web browser as the body of the web page
. In the body section, you can write a text message that will be displayed in the web browser as the body of the web page![]() .
.
For a fully HTML-compliant web page, other items must exist in the document, such as a DOCTYPE declaration. However, our example will work just fine, and we can ignore these technical details for our simple demonstration.
A web server will typically also generate a response header. This header can give a web browser additional information about the document it has just received, such as whether it is in HTML or another format. However, the simplified web server we’re going to create does not generate such a header and instead simply returns a body.
Note
Since we’re using CLISP-specific socket commands, you must be running CLISP for the sample web server presented in this chapter to work.
Web forms are an essential element in powering websites. For instance, suppose we create a simple login form for a website.
After the visitor to our website hits the Submit button on this page, it will send a POST request back to the website. A POST request looks very similar to the GET request in the preceding example. However, a POST request usually carries the expectation that it may alter data on the server.
In our sample login form, we need to tell the server the user ID and password that the visitor to our site had entered into the text fields on this form. The values of these fields that are sent to the server as part of the POST request are called request parameters. They are sent within the POST request by appending them below the request header, in the area that makes up the request body.
This is what the POST request might look like for our login example:
POST /login.html HTTP/1.1 Host: www.mywebsite.com User-Agent: Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.5) Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-us,en;q=0.5 Accept-Encoding: gzip,deflate Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7 Keep-Alive: 300 Connection: keep-aliveContent-Length: 39userid=foo&password=supersecretpassword
The extra parameter in the header of this POST request, Content-Length, indicates the length of the parameter data at the bottom of the request. Specifically, Content-Length: 39 tells the server that the text containing the request parameters ![]() is 39 characters long.
is 39 characters long.
As we’ve discussed, the typical purpose of request parameters is to send web form data back to the server during a POST request. However, GET requests may also contain request parameters. Usually, with a GET request, we want to see what the parameters are in the URL of the request, whereas with a POST request, the parameters are hidden in the body of the request.
For instance, suppose you go to Google and search for “dogs.” In this case, the follow-up page will have a URL that reads something like http://www.google.com/search?q=dogs&hl=en&safe=off&.... These values in the URL (such as the one stating that the [q]uery=“dogs”) are also request parameters.
The web server we’re creating will need to give the server code access to both types of request parameters: the ones in the body of the request (as is common with POST requests) as well as the ones that appear in the URL (as is common with GET requests.)
HTTP has a special way to represent the nonalphanumeric characters that a user might enter into a form, using HTTP escape codes. These escape codes let you have characters in the values of a request parameter that would not otherwise be available in the HTTP format. For instance, if a user enters "foo?", it will appear in the request as "foo%3F", since the question mark is represented with an escape code. Our web server will need to decode these escape characters, so the first function we’ll write is decode-param:
(otherwise (cons (car lst) (f (cdr lst))))))))
(coerce (f (coerce s 'list)) 'string)))
Note
The HTTP escape codes we are discussing here are unrelated to the escape characters in Lisp strings we’ve discussed in other parts of this book.
First, this function defines a local function named f ![]() , which we’ll use to recursively process the characters. To make this recursion work, we need to use
, which we’ll use to recursively process the characters. To make this recursion work, we need to use coerce to turn the string into a list of characters ![]() , and then pass this list to
, and then pass this list to f.
The f function checks the first character in the list to see if it’s a percent sign (%) or a plus sign (+). If it’s a percent sign, we know that the next value in the list is an ASCII code, represented as a hexadecimal number. (ASCII codes are a standard set of numbers that correspond to text characters, shared among many computer systems and applications.)
To decode this ASCII code, we’ve created a function named http-char ![]() . In this function, we use the
. In this function, we use the parse-integer function to convert this string to an integer ![]() . In this case, we’re using some keyword parameters on
. In this case, we’re using some keyword parameters on parse-integer: the :radix parameter, which tells the function to parse a hexadecimal number, and the :junk-allowed parameter, which tells it to just return nil when an invalid number is given, rather than signaling an error.
We then use the code-char function to convert this integer (which holds an ASCII code) into the actual character that the user entered.
As per the rules of HTTP encoding, if a value in a request parameter contains a plus sign, it should be translated into a space character. We make this conversion here ![]() .
.
Any other character passes through the f function unchanged. However, we still need to call f on the remainder of the list until all the characters have been processed ![]() .
.
Here are some examples of decode-param in action:
>(decode-param "foo")"foo" >(decode-param "foo%3F")"foo?" >(decode-param "foo+bar")"foo bar"
The next thing our server needs to do is to decode a list of parameters, which will be given as name/value pairs in a string such as "name=bob&age=25&gender=male". As we’ve discussed, URLs for web pages often contain such name/value pairs at the end. As you can see, this string says that the person we’re looking for on the web page has a name of bob, an age of 25, and a gender of male. These name/value pairs are separated by an ampersand (&). The structure of these strings is equivalent to that of an association list (alist), so we’ll store these parameters as an alist using the following function:
(defun parse-params (s)
The parse-params function finds the first occurrence of an ampersand (&) and equal sign (=) in the string, using the position function ![]() . If a name/value pair is found (we know this is true if an equal sign was found in the string and is stored in
. If a name/value pair is found (we know this is true if an equal sign was found in the string and is stored in i1), we use the intern function to convert the name into a Lisp symbol ![]() . We
. We cons this name to the value of the parameter, which we decode with our decode-param function ![]() . Finally, we recursively call
. Finally, we recursively call parse-params on the remainder of the string ![]() .
.
Let’s give our new parse-params function a try:
> (parse-params "name=bob&age=25&gender=male")
((NAME . "bob") (AGE . "25") (GENDER . "male"))Putting this data into an alist will allow our code to easily reference a specific variable whenever that’s necessary.
Note
Both decode-param and parse-params could achieve higher performance if they were written using a tail call, as we’ll discuss in Chapter 14.
Next, we’ll write a function to process the first line of the request header. (This is the line that will look something like GET /lolcats.html HTTP/1.1).
The following parse-url function will process these strings:
(defun parse-url (s)
(let* ((url (subseq s
(+ 2 (position #space s))
(position #space s :from-end t)))
(x (position #? url)))
(if x
(cons (subseq url 0 x) (parse-params (subseq url (1+ x))))
(cons url '()))))This function first uses the string’s delimiting spaces to find and extract the URL ![]() . It then checks this URL for a question mark, which may indicate that there are request parameters that need to be handled
. It then checks this URL for a question mark, which may indicate that there are request parameters that need to be handled ![]() . For instance, if the URL is lolcats.html?extra-funny=yes, then the question mark lets us know that there is a parameter named extra-funny in the URL. If such parameters exist, we’ll need to extract them, and then parse them using our
. For instance, if the URL is lolcats.html?extra-funny=yes, then the question mark lets us know that there is a parameter named extra-funny in the URL. If such parameters exist, we’ll need to extract them, and then parse them using our parse-params function ![]() . If there aren’t any request parameters, we just return the URL
. If there aren’t any request parameters, we just return the URL ![]() . Note that this function skips over the request method (most often
. Note that this function skips over the request method (most often GET or POST). A fancier web server would extract this data point as well.
Let’s try out our new URL extractor:
>(parse-url "GET /lolcats.html HTTP/1.1")("lolcats.html") >(parse-url "GET /lolcats.html?extra-funny=yes HTTP/1.1")("lolcats.html" (EXTRA-FUNNY . "yes"))
Now that we can read the first line, we’ll process the rest of the request. The following get-header function will convert the remaining lines of the request into a nice alist:
(defun get-header (stream)
This function reads in a line from the stream ![]() , converts it to a key/value pair based on the location of a colon
, converts it to a key/value pair based on the location of a colon ![]() , and then recurses to convert additional lines in the header
, and then recurses to convert additional lines in the header ![]() . If it encounters a line that doesn’t conform to a header line, it means we’ve reached the blank line at the end of the header and are finished. In this case, both
. If it encounters a line that doesn’t conform to a header line, it means we’ve reached the blank line at the end of the header and are finished. In this case, both i and h will be nil, and the function terminates.
The intern command used when generating the key above is a simple function that converts a string into a symbol. We could, instead, have used the read command for this purpose, as we have previously in this book. But remember that the flexibility of the read command also makes it a great target for hackers, who might try creating malformed headers to crack your web server. That’s why it’s wise to use the more limited, specific intern function to process this data sent over the Internet to our web server.
Since the get-header function pulls its data directly from a socket stream, you might think we can’t test it directly through the REPL. However, as you saw in the previous chapter, there are actually several different types of resources besides sockets that can be accessed through the stream interface in Common Lisp. Because of the common interface among streams, we can test our get-header function by passing it a string stream instead of a socket stream:
(get-header (make-string-input-stream "foo: 1bar: abc, 123"))((FOO . "1") (BAR . "abc, 123"))
Using the make-string-input-stream function, we can create an input stream from a literal string. In this example, we’re taking a string defining two keys (foo and bar) and ending it with an empty line, just like a typical HTTP header. Note that we have a single literal string from ![]() to
to ![]() . Such strings are permitted in Common Lisp. As you can see, the
. Such strings are permitted in Common Lisp. As you can see, the get-header function appropriately pulled the two keys and their values out of this stream, in the same way it would pull these values out of a socket stream.
Using this trick, you can test functions that manipulate streams directly from the REPL. To do this, simply substitute string streams for other, more complicated stream types.
In a POST request, there will usually be parameters stored beneath the header, in an area known as the request body or request content. The following get-content-params function extracts these parameters:
(defun get-content-params (stream header)
First, this function searches the header for a value called content-length ![]() , which tells us the length of the string that contains these content parameters. If
, which tells us the length of the string that contains these content parameters. If content-length exists, then we know there are parameters to parse ![]() . The function will then create a string with the given length using
. The function will then create a string with the given length using make-string ![]() , and use
, and use read-sequence to fill that string with characters from the stream ![]() . It then runs the result through our
. It then runs the result through our parse-params function to translate the parameters into our cleaned-up alist format ![]() .
.
Now all the pieces are in place to write the heart of our web server: the serve function. Here it is in all its glory:
The serve function takes a single parameter: request-handler ![]() , which is supplied by the creator of a website that wants to use this web server. When the server receives a request over the network, it parses the request into clean Lisp data structures (using the functions we’ve discussed throughout this chapter), and then passes this request information to
, which is supplied by the creator of a website that wants to use this web server. When the server receives a request over the network, it parses the request into clean Lisp data structures (using the functions we’ve discussed throughout this chapter), and then passes this request information to request-handler. The request-handler then displays the correct HTML.
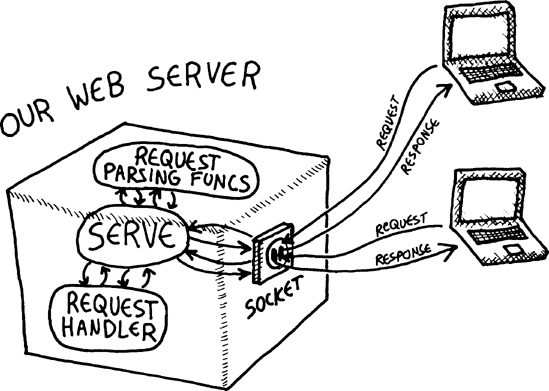
Let’s look at our serve function in detail to see how it accomplishes this.
First, serve creates a socket bound to port 8080 ![]() . This is one of several ports that is commonly used for serving web pages, especially when a site is still under development. (Port 80 is usually used for a production website/web server.) We then call
. This is one of several ports that is commonly used for serving web pages, especially when a site is still under development. (Port 80 is usually used for a production website/web server.) We then call unwind-protect ![]() , which ensures that no matter what happens as the server runs,
, which ensures that no matter what happens as the server runs, socket-server-close will be called at some point to free the socket.
Next, we start the main web-serving loop. Within this loop, we open a stream for any client that accesses our server ![]() . We then use the
. We then use the with-open-stream macro to guarantee that, no matter what, that stream will be properly closed. Now we’re ready to read and parse the website request that the client has made to our server, using all of the reading and parsing functions we created ![]() .
.
Finally, we call the request-handler function, passing in the request details ![]() . Note how we redefine the
. Note how we redefine the *standard-output* dynamic variable beforehand. This means that the request handler can just write to standard output, and all the printed data will be redirected to the client stream automatically. As you learned in Chapter 12, capturing data from standard output allows us to minimize string concatenation. Also, it will make our request-handler function easier to debug, as you’ll see shortly.
Note
One thing we did not do with our web server is prevent the web server from crashing if the request-handler triggers an exception. Instead, we simply guarantee that no resources are mangled in the case of an exception. We could easily add extra exception handling to keep the server ticking even if horrible exceptions occur. However, since our goal is to learn Lisp and develop games in a browser, it’s better for us to know right away about any exceptions, even if that brings down our server.