
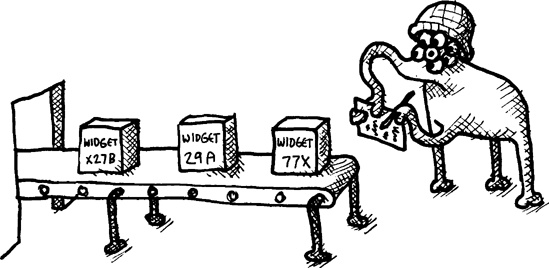
Now that we’ve discussed how functional programming is done, let’s write a simple program that follows this style. Since we want this program to be a typical example of most software, we should figure out what most software in the world actually does. So what do most programs in the world actually do? They keep track of widgets!
Here’s our entire example program, written in the functional style:
;the clean, functional part(defun add-widget (database widget)
(cons widget database)) ;the dirty, nonfunctional part
(defparameter *database* nil)
(defun main-loop ()
(loop (princ "Please enter the name of a new widget:")
(setf *database* (add-widget *database* (read))) (format t "The database contains the following: ˜a˜%" *database*)))
As promised, it is split into two parts: the clean part and the dirty part. I did say that the clean part of the program should be much bigger than the dirty part. However, since this example is so short, the dirty part ended up a bit bigger. Usually, you can expect the clean part to be around 80 percent of the actual code.
Note
Some programming languages are even more focused on functional programming than Lisp is. Haskell, for instance, has powerful features that let you write 99.9 percent of your code in a functional style. In the end, however, your program will still need to have some kind of side effect; otherwise, your code couldn’t accomplish anything useful.
So what does our example program do? Well, it basically does what most computer programs in the world are designed to do: It keeps track of widgets in a database!
The database in this example is very primitive. It’s just a Lisp list, stored in the global variable *database*. Since the database is going to start off empty, we initialize this variable and set it to be empty ![]() .
.
We can call the function main-loop to start tracking some widgets ![]() . This function just starts an infinite loop, asking the user for a widget name
. This function just starts an infinite loop, asking the user for a widget name ![]() . Then, after it reads in the widget, it calls the
. Then, after it reads in the widget, it calls the add-widget function to add the new widget to the database ![]() .
.
However, the add-widget function ![]() is in the clean part of the code. That means it’s functional and isn’t allowed to modify the
is in the clean part of the code. That means it’s functional and isn’t allowed to modify the *database* variable directly. Like all functional code, the add-widget function is allowed to do nothing more than return a new value. This means that the only way it can “add” a widget to a database is to return a brand-new database! It does this by simply taking the database passed to it and then consing the widget to the database to create a new database ![]() . The new database is identical to the previous one, except that it now contains a new widget at the front of the list.
. The new database is identical to the previous one, except that it now contains a new widget at the front of the list.
Think of how crazy this sounds on the face of it. Imagine that we’re running an Oracle database server, containing millions of widgets:
Then, when we add a new widget, the database server accomplishes this by creating a brand-new replica of the previous database, which differs only in that a single new item has been added:
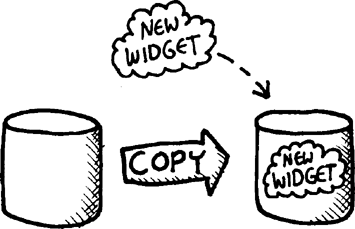
This would be horribly inefficient. However, in our widgets example, things are not as bad as they may first appear. It is true that the add-widgets function creates a new list of widgets every time it is called, and that repeated calls to this function would make the list longer and longer. However, since every new widget is simply added to the front of the list, it turns out that the tail end of the widget list is identical to the previous version of the list. Hence, the add-widget function can “cheat” whenever it creates a new list, by simply consing a single new widget to the front of the list, and then repurposing the old list as a tail to hold the rest of the items ![]() . This allows the new list to be created in a way that is fast and also requires very little new memory to be allocated. In fact, the only new memory allocated by
. This allows the new list to be created in a way that is fast and also requires very little new memory to be allocated. In fact, the only new memory allocated by add-widget is a single new cons cell to link the new widget to the previous list.
This type of cheating when creating new data structures is a key technique that makes efficient functional programming possible. Furthermore, sharing of structures can be done safely, since one of the tenets of functional programming is to never modify old pieces of data.
So our add-widget function creates a new database for us with the additional item added to it. The main-loop function, in the dirty part of the code, sets the global *database* variable equal to this new database. In this way, we have indirectly modified the database in two steps:
The
add-widgetfunction, which is basically the brains of this program, generated an updated database for us.The
main-loopfunction, which was in charge of the dirty work, modified the global*database*variable to complete the operation.
This example program illustrates the basic layout of a Lisp program written in the functional style. Let’s try out our new program to see it in action:
>(main-loop)Please enter the name of a new widget:FrombulatorThe database contains the following: (FROMBULATOR) Please enter the name of a new widget:Double-ZingomatThe database contains the following: (DOUBLE-ZINGOMAT FROMBULATOR) ...
Remember that you can hit ctrl-C to exit the infinite loop in this example.