
Chapter 3 Importing Textual Data into SAS Text Miner
An Introduction to SAS Enterprise Miner and SAS Text Miner
Data Types, Roles, and Levels in SAS Text Miner
Creating a Data Source in SAS Enterprise Miner
Importing Textual Data into SAS.
Importing Data into SAS Text Miner Using the Text Import Node
Importing XLS and XML Files into SAS Text Miner
Managing Text Using SAS Character Functions
This chapter starts with a brief introduction to SAS Enterprise Miner and SAS Text Miner. We later discuss how SAS Text Miner can be used to import raw data available in various file formats into SAS and how to import data from the web using a web crawler. We briefly discuss and demonstrate the powerful use of Perl regular expressions for cleaning textual data before it is used for text mining. This chapter includes a brief introduction to the rich collection of character functions available in SAS for manipulating textual data.
An Introduction to SAS Enterprise Miner and SAS Text Miner
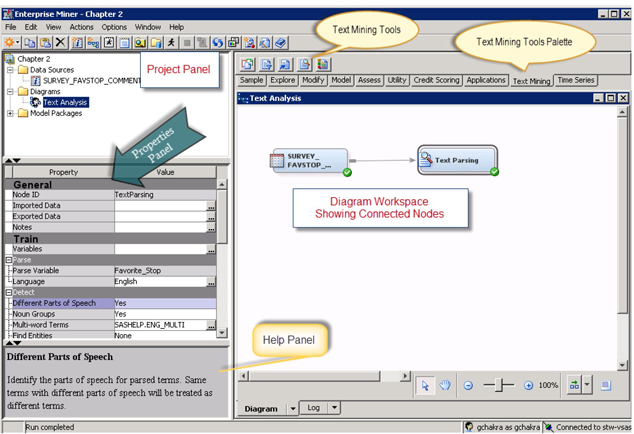
SAS Enterprise Miner lets you build predictive and descriptive data mining models based on large volumes of data. The easy-to-use interface simplifies many common tasks associated with applied data mining, including text mining. Text mining results can be easily integrated with the data mining model process flow to enhance model performance. SAS Enterprise Miner offers secure analysis management and provides a wide variety of tools with a consistent graphical interface. You can customize it by incorporating your choice of analysis methods and tools that you want to analyze. The interface window is divided into several functional components.
• The menu bar and corresponding shortcut buttons perform the usual Windows tasks, in addition to starting, stopping, and reviewing analyses.
• The Project panel manages and displays data sources, diagrams, results, and project users.
• The Properties panel enables you to view and edit the settings of data sources, diagrams, nodes, results, and users.
• The Help panel displays a short description of the property that you select in the Properties panel. Extended help can be found in the Help Topics option in the Help main menu.
• In the Diagram workspace, process flow diagrams are built, edited, and run. The workspace is where you graphically sequence the tools that you use to analyze your data and to generate reports. The Diagram workspace contains one or more process flows.
A process flow starts with a data source and sequentially applies SAS Enterprise Miner tools to complete your analytic objective. A process flow contains several nodes. Nodes are SAS Enterprise Miner tools connected by arrows to show the direction of information flow in an analysis. The SAS Enterprise Miner tools available to your analysis are contained in the tools palette. The tools palette is arranged based on the SAS process for data mining, SEMMA (Sample, Explore, Modify, Model, and Assess). Additional tools are available in the Utility group. Other specialized group tools (for example, Credit Scoring, Applications, Text Mining, and Time Series) are available if licensed. Each group of tools contains specialized tools for doing appropriate analysis. For example, the Text Mining group contains the following tools: Text Cluster, Text Filter, Text Import, Text Parsing, Text Topic, and Text Rule Builder.
Display 3.1: SAS Enterprise Miner Interface
Data Types, Roles, and Levels in SAS Text Miner
SAS Text Miner provides a set of tools that enable you to collect textual data and analyze the data to extract information. In addition, because you can embed the SAS Text Miner node in a SAS Enterprise Miner process flow diagram, you can combine quantitative variables with unstructured text in the mining process. As a result, you are incorporating text mining with other traditional data mining techniques. Therefore, data types in SAS Text Miner accommodate both structured (numeric) and unstructured (textual) data.
Data roles are typically different based on data types. For unstructured (textual) data that you want to analyze, the role is usually set to Text and the measurement level to Nominal. For numeric data, there are many data role options depending on your analysis objectives. For example, you can set the role of a numeric variable to ID when you want to use that numeric variable to reflect the unique identification number for each value in the text data. You can set the role of a numeric variable to Time ID when you want to use that numeric variable to reflect the time stamp associated with each value in the text data. You can set the role of a numeric variable to Input when you want to use that variable as an input variable in any subsequent nodes. For example, if you created a flag variable to indicate the presence or absence of a graphics file for each value in your text, and you want to use this flag variable in subsequent analysis, then you can assign the flag variable a role of Input. You can set the role of a numeric variable to Target when you want to use that variable as a target variable in any subsequent modeling nodes such as Regression. For example, if you have a numeric variable that indicates positive, negative, or neutral sentiments expressed in text data, and you want to predict this sentiment variable using the text data, you can assign the sentiment variable a role of Target. For other data roles available for numeric data, see the online Help for SAS Enterprise Miner.
For numeric data, there are five possible measurement levels, depending on the measurement scale used in creating or collecting the data. The level Unary is used when a variable has the same value for every observation in the data set. The level Binary is used when a categorical variable has two distinct values. The level Nominal is used when a categorical variable has three or more values and the measurement property reflects that the observations with different values simply represent different categories. The level Ordinal is used when a categorical variable has three or more values and the measurement property of the attribute reflects that different values present a natural ordering, but on which no arithmetic-like operations can be performed. The level Interval is used when the variable has many numeric values and the measurement property of the attribute reflects meaningful and equal intervals in the scale.
Creating a Data Source in SAS Enterprise Miner
Before any data can be processed via SAS Text Miner, the data has to be brought into a SAS Enterprise Miner project. The following discussion takes you through the creation of a SAS Enterprise Miner project, the creation of a SAS library, the creation of a diagram, and the creation of a data source.
(a) Create a SAS Enterprise Miner Project
The exact procedure to access and start SAS Enterprise Miner depend on the type of installation. A commonly used procedure to access the welcome window is to select Start ▸ Programs ▸ SAS ▸ Analytics ▸ SAS Enterprise Miner (or, double-click the SAS Enterprise Miner icon if it is on the desktop).
Display 3.2: SAS Enterprise Miner Welcome Window
To define a project, you specify a project name and the location of the project on the SAS Foundation Server.
• Select File ▸ New ▸ Project from the main menu or click New Project in the welcome window.
The Create New Project wizard opens at Step 1. Enter a project name and specify a path to a folder on your machine where you want the project to be saved.
Display 3.3: SAS Enterprise Miner Create New Project Wizard
• Click Next. To finish defining the project, click Finish in the next step.
The SAS Enterprise Miner client application opens the project that you created.
Display 3.4: SAS Enterprise Miner Window after Project Creation
(b) Create a SAS Library
A SAS library connects SAS Enterprise Miner with the raw data sources, which are the basis of your analysis. To define a SAS library, you need to know the name and location of the data that you want to link with SAS Enterprise Miner.
• Select File ▸ New ▸ Library from the main menu.
Display 3.5: SAS Enterprise Miner Library Wizard—Step 1
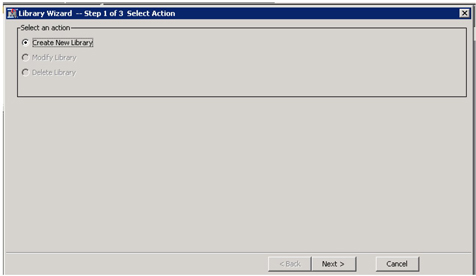
• Click Next. In Step 2, enter a name for the library (book) and specify a path to the folder where your data is located.
Display 3.6: SAS Enterprise Miner Library Wizard—Step 2
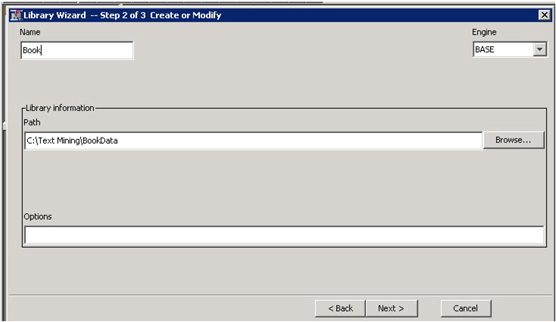
• Click Next. Click Finish.
Alternatively, with the project name selected, open the Project Start Code dialog box in the Properties panel, enter the following code, and run it to create a library:
libname Book ‘C:TextMiningBookData’;
All data available in the SAS library can now be used by SAS Enterprise Miner.
(c) Create a SAS Enterprise Miner Diagram
All analyses in SAS Enterprise Miner are usually performed by adding nodes to a diagram.
• To create a diagram, select File ▸ New ▸ Diagram from the main menu.
Display 3.7: SAS Enterprise Miner Create New Diagram
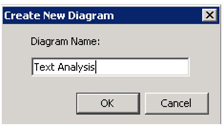
• Enter an appropriate name (such as Text Analysis) for your diagram, and click OK.
Display 3.8: SAS Enterprise Miner Text Analysis Diagram
(d) Create a SAS Enterprise Miner Data Source
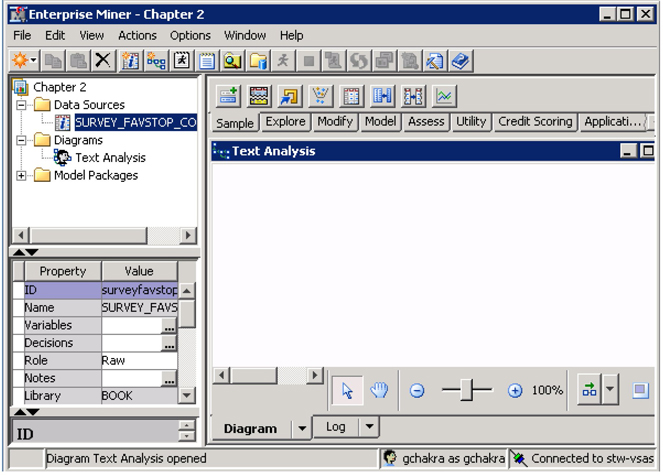
A data source links SAS Enterprise Miner to an existing data table. In this example, you create a data source that has comments from customers of a national fuel chain. These customers completed a survey that has closed-ended questions (with numeric categories as responses) and open-ended questions (where customers entered their comments). For this example, you use only the data that has comments from one question in the survey, “Why do you consider this store a favorite stop?” The SAS data set name is Survey_FavStop_Comments.
• Select File ⇨ New ⇨ Data Source from the main menu to create a data source. Alternatively, you can right-click on the Data Sources folder in the Project panel, and select Create Data Source to start the Data Source Wizard.
• In Step 1 of the Data Source Wizard, click Next.
• In Step 2 of the Data Source Wizard, click Browse.
∘ Double-click to open the library where the data is located (Book).
∘ Select the table or data that you want to analyze (Survey_FavStop_Comments).
∘ Click OK.
∘ Click Next.
• Step 3 of the Data Source Wizard provides some basic information about the data set such as the number of variables, number of observations, etc. Click Next.
• Step 4 of the Data Source Wizard starts the metadata definition process. SAS Enterprise Miner assigns initial values to the metadata based on characteristics of the selected SAS table. The Basic setting assigns initial values to the metadata based on variable attributes such as the variable name, data type, and assigned SAS format. The Advanced setting assigns initial values to the metadata in the same way as the Basic setting, but it also assesses the distribution of each variable to better determine the appropriate measurement level. This is where it becomes important for you to know the modeling role and appropriate measurement level of each variable in the source data set. Click Next to use the Basic setting.
• Step 5 of the Data Source Wizard displays its best guess for the metadata assignments.
Display 3.9: SAS Enterprise Miner Text Analysis Diagram

The variable ID_Survey is an identification number and is assigned a role of ID and measurement level of Nominal. The variable Favorite_Stop is text data and is assigned a role of Text and measurement level of Nominal. You can click next to each variable’s role or level and change it to another value if the metadata guess is incorrect. In this case, it appears that the metadata guesses are correct.
• Click Next to accept these role and level assignments.
• Step 6 of the Data Source Wizard gives you the option to create a sample data set. Click Next to accept the default (no sample data set) option.
• Step 7 of the Data Source Wizard enables you to set a role for the data source and to add descriptive comments about the data source definition. For most analyses, a table role of Raw is acceptable. Click Next to accept the default options.
• The final step in the Data Source Wizard provides summary details about the data source that you created. Click Finish.
The Survey_FavStop_Comments data source is added to the Data Sources folder in the Project panel and is now ready to be analyzed.
Display 3.10: SAS Enterprise Miner Text Analysis Diagram
Importing Textual Data into SAS
As discussed in Chapter 1, the first step in the text mining process is collecting textual data and setting up what is sometimes referred to as a corpus. Often, a text corpus usually represents documents from a particular domain. For example, all papers published in a journal during a year could be a document corpus. Though collecting data looks like a simple task, this is one of the most tedious and challenging steps in the text mining process. This is because the unstructured data exists in various forms that cannot always be directly processed by SAS Text Miner. A data conversion step usually takes place before the data is used in the text mining task unless the data is readily available as a SAS data set.
The data collection step heavily depends on the business problem. This involves answering simple questions such as the following:
• What data is needed for this project?
✓ Customer reviews, application documents, news articles, e-mails, etc.
• Where is the data available?
✓ Client directory, database, data warehouse, web, etc.
• How is it available?
✓ PDF files, XML pages, Word documents, web pages, etc.
• When should the data be collected (when collecting non-static data)?
✓ Before or after a specific event, data from wikis or blogs that are frequently updated.
Once the data that is needed to solve the current problem is identified, the next challenge is to collect the data and convert it for SAS Text Miner to process. It is quite possible that you will face any of the following situations in your project:
1. Data is readily available as a SAS data set.
2. Data is available as textual files (PDF, XML, HTML, Word, etc.) in a directory or in a database.
3. Data needs to be collected from the Internet.
The text mining process in SAS requires that the data be available as a SAS data set. This does not mean that the source data has to exist as a SAS data set (see situations 2 and 3 for other formats). In the first situation, you can directly create a data source and perform text mining. In the latter two situations, the source data has to be converted into a SAS data set. There are various ways to create a SAS data set from the data available in commercial databases using SAS data access features. Files in common formats such as comma-separated values (CSV) or Microsoft Excel can be easily imported into SAS using the SAS Enterprise Guide Data Import Wizard or the File Import node in SAS Enterprise Miner. The challenging part is to create SAS data sets from textual files. SAS Text Miner has the capability to create SAS data sets dynamically from textual files available in a directory or on the web. This is accomplished using the Text Import node in SAS Text Miner.
In Chapter 2, you learned how to collect data from the web and local files using SAS Information Retrieval Studio. Data collected using SAS Information Retrieval Studio is fed into SAS Text Miner for further text mining accomplishments. The following sections discuss in detail the different ways to collect textual data using SAS Text Miner.
Importing Data into SAS Text Miner Using the Text Import Node
The Text Import node in the Text Mining collection of nodes can be used to import source data into SAS Text Miner as a SAS data set. The source data can exist in a directory in any proprietary file format type. The Text Import node requires that the SAS Document Server be installed and running for performing document conversion. More than 100 file formats are supported by the Text Import node. Some of them include the following:
• Microsoft Word (.doc, .docx)
• Microsoft Excel (.xls, .xlsx)
• Microsoft PowerPoint (.ppt, .pptx)
• Rich Text Format (.rtf)
• Adobe Acrobat (.pdf)
• ASCII (.txt)
The node requires a source directory (or Import File directory) that contains all of the source files and a destination directory to save all of the converted files. SAS Text Miner traverses the source directory, extracts the text from the files in this directory, and creates plain text files in the destination directory. Any source file in a form not readable by SAS Text Miner is omitted from the document conversion. Similarly, if the number of characters in each file exceeds 32,000, then the file is truncated. If source data is collected from the web, the node crawls the websites, retrieves files, and puts them in the source directory before the extraction process. The node can easily identify the language of the document and then transcode the document into the session encoding. Analysts who prefer programming can perform the same text import tasks. They can automate the process using the %TMFILTER macro. We discuss the macro in the next section.
(a) Extract Text from PDF Files and Create a SAS Data Set
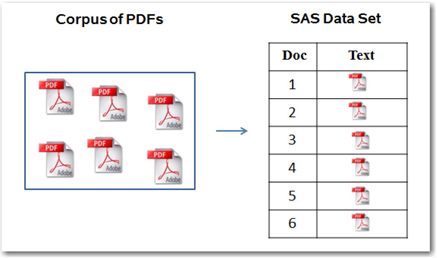
Suppose you want to analyze thousands of documents that are available in PDF format and stored on your desktop or on a network location. You want to represent each PDF file as a unit of analysis (i.e., the contents of one PDF file should reside in exactly one cell in your table or SAS data set as shown in Display 3.11).
Display 3.11: Mapping Each PDF Document to Each Cell in a SAS Data Set
In this example, you can use the Text Import node to convert 1,000 SAS Global Forum conference papers available in PDF format to a SAS data set. After this step, you will have a SAS data set of 1,000 observations in which each observation corresponds to one SAS Global Forum paper. A SAS data set cell can hold a maximum of 32,000 characters. Hence, it is not possible to include all of the contents of a single paper in one cell. In this situation, a cell can take only the first 32,000 characters in the paper. The Text Import node provides a facility to capture the links to the actual papers instead of the content of the actual papers. The output data set contains a variable that tells the successor nodes to use the document path information to access the full content of the papers. If you think you need only a certain number of bytes of text from each paper, you can set the node properties to fetch only that number of bytes of text. Only text that is present in the documents is imported. To extract tables, check boxes, or any other objects from the documents requires additional preprocessing. If the PDF is produced by a scanner, you first need to convert the images to textual documents by using any optical character recognition (OCR) software.
Let’s see in detail how you can perform these operations using the Text Import node.
We start by creating the two necessary folders for the Text Import node to work right. We have a folder named Source created on our desktop that contains 1,000 SAS Global Forum papers, all available as PDF files. We have another folder named Destination in the same parent folder to save the filtered files. Drag and drop a Text Import node onto the Diagram workspace in SAS Enterprise Miner. This node does not require any predecessor nodes. Set the Train properties of the node as shown in Display 3.12.
Import File Directory: C:TextMiningSource
Destination Directory: C:TextMiningDestination
Display 3.12: Text Import Node Train Property Settings
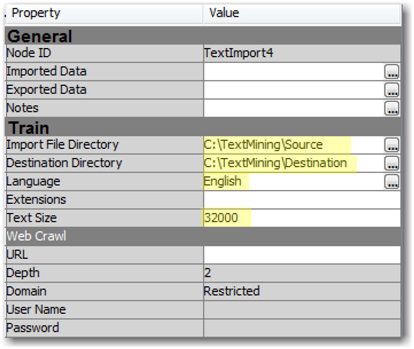
The Extensions property is used to restrict the types of files to extract. For example, if you provide HTML as the value for this property, the node will filter only files with an HTML extension. If you leave this value blank, the node will filter all of the file types that are supported by the SAS Document Conversion server. The Text Size property is used to control the size of the text that you want to extract from each document into the TEXT variable in the output data set. This will serve as a snippet when the size is small. We have set it to 32,000 to extract the maximum possible text.
The Language property sets the possible choices that the language identifier uses when assigning a language to each document. Select one or more languages in the Languages dialog box (this dialog box can be opened by clicking the ellipsis button next to the property). Only languages that are licensed can be used. We have only a license for English as shown in Display 3.13.
Display 3.13: Dialog Box to Select Language Choices
The results from running the Text Import node with these settings produces the results shown in Display 3.14.
Display 3.14: Text Import Node Results Window
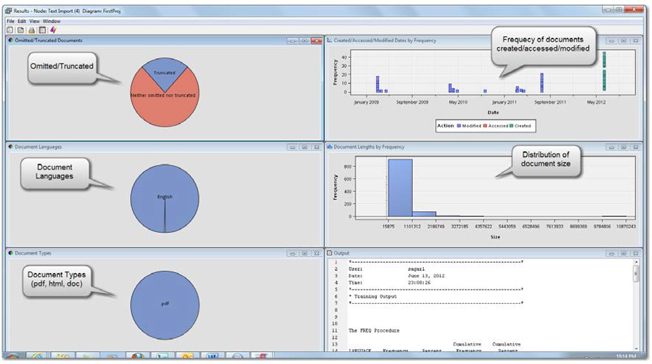
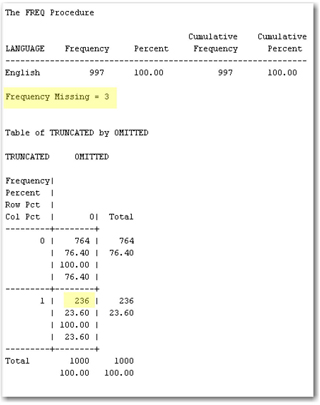
The Results window of the Text Import node shows various distribution plots that report the number of documents that were omitted or truncated, document languages, types, sizes, and a time series plot of when the document was created, modified, and accessed. These plots give a basic idea of how successful the text import task was. The Output window (lower right corner in Display 3.14) reports the PROC FREQ results on document languages and a cross tabulation of omitted versus truncated documents. In Display 3.15 , there are three documents for which the Text Import node was not able to correctly identify the language. The cross tabulation shows that no documents were omitted, but 236 of them were truncated. You can explore the Destination folder for the TXT files that were extracted from PDF files.
Display 3.15: PROC FREQ Results of the Document Import Process
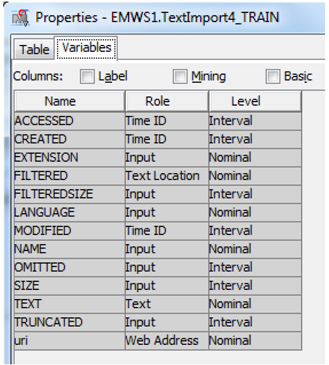
The variables in the data set that was exported by the Text Import node are shown in Display 3.16.
Display 3.16: Variables in the Output Data Set from the Text Import Node
It is usually the Text Parsing node that is connected to the Text Import node in the process flow. There are two columns that can be used by the Text Parsing node to identify the text: FILTERED and TEXT. In the Text Parsing node, when you set the Use property of the TEXT variable to Yes, and the Use property of the FILTERED variable to No, only the text that is contained in the TEXT variable will be used for parsing. Otherwise, the FILTERED variable is always given the preference when both of the variables have the Use property set to Yes.
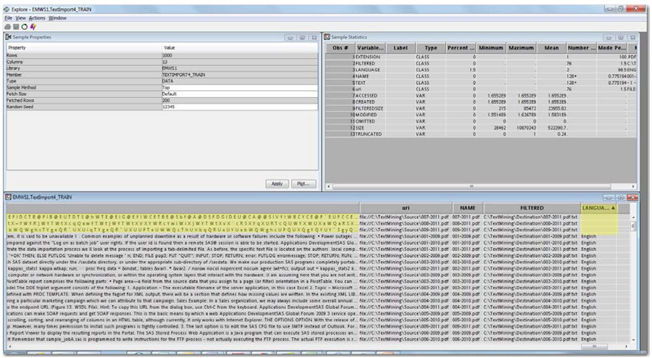
Exploring the exported data of the Text Import node will give you a sense of the data that will be used for parsing. The TEXT variable captures a snippet of the text that is extracted. From the Explore window of the exported training data set, sort the data by the Language column so that the table will show the records with a missing value for the Language column on the top. As shown in Display 3.17, the first three rows of the TEXT variable contain just letters and symbols without any words or sentences. This is because the three papers in these three rows were encoded in a form the document conversion tool cannot identify.
Display 3.17: Explore Window of the Exported Data Set from the Text Import Node
(b) Retrieve Data from the Web and Create a SAS Data Set
Analyzing the data available on the web has become a competitive advantage for almost any organization. A treasure trove of information about brands, customer preferences, product reviews, stock prices, movie reviews, etc., can be found on the World Wide Web. This information from the Internet, in combination with internal data, can make your analysis more powerful and current. However, the challenging part of the task is to find a way to get this data into SAS. This can be easily achieved using a web crawler.
A web crawler is a sophisticated computer program that crawls the web in a methodical and automated manner. Web crawling is used for various purposes by organizations. Internet search engines use web crawlers to index web pages and stay current. Others use crawlers for automating maintenance tasks on websites. The web crawling process starts with a list of starting URLs or seed pages. The pages identified with these URLs are downloaded and any hyperlinks on these pages are extracted for further downloading.
A web crawler undertakes the following four tasks:
1. Starts with an URL from candidate URLs.
2. Downloads the associated web pages.
3. Extracts any hyperlinks on these web pages.
4. Updates the candidate list with these hyperlinks for further downloading.
There are different methods available in SAS to use the web crawler functionality. You can write a simple DATA step program or use the Text Import node in SAS Enterprise Miner. SAS Crawler is a sophisticated tool with more advanced web crawler capabilities as discussed in Chapter 2. In this chapter, you will see how you can use the Text Import node for downloading web pages and creating SAS data sets for text mining. SAS Crawler enables you to download different types of files such as HTML, PDF, PPT, DOC, etc., from the web from which text can be extracted.
For example, we show you how to download the web pages from the website www.allanalytics.com. This website is a great resource for analytics professionals. It brings together professionals, researchers, and students working in the field of analytics to share their experiences and know-how on business intelligence, advanced analytics, and data management. This website is a good start if you want to understand the latest happenings in the field of analytics and what has happened in the recent past. However, numerous blogs and message boards on this website make it tough to read each post. An easy solution is to download the web pages and perform text mining to see what different topics were discussed and what was the trend for these topics.
The Text Import node properties that need to be set for web crawling are shown in Display 3.18. Similar to importing PDF files (as seen in an earlier section), you need two folders, a Source folder for storing the downloaded HTML pages, and a Destination folder for storing the textual extracts. The paths to these two folders are set as property values for the Import File directory and the Destination File directory settings:
Import File Directory: C:TextImportSource
Destination Directory: C:TextImportDestination
Display 3.18: Text Import Node Web Crawling Property Settings
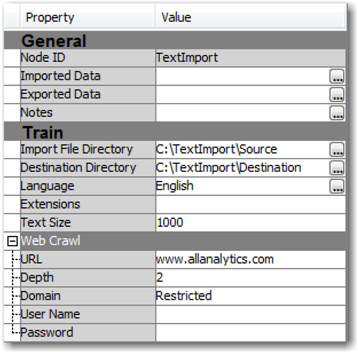
The use of the property settings Language, Extensions, and Text Size is the same as discussed in the previous section. Setting the Text Size property to 1000 will show a maximum text value of 1,000 characters for each extracted web page. The URL property is where you specify the initial web page to crawl. In this example, we have assigned the name of the website www.allanalytics.com. The Depth property is used to specify the extent of the number of levels of links to crawl from the initial URL page. A web page can contain links to many other pages, where each page, again, is linked to hundreds of other pages. These links can belong to the same website domain or to a different website. For example, you can see that the page www.allanalytics.com has links to other pages in the domain and links to a resource page on the www.sas.com website as shown in Display 3.19.
Display 3.19: Home Page of the www.allanalytics.com Website
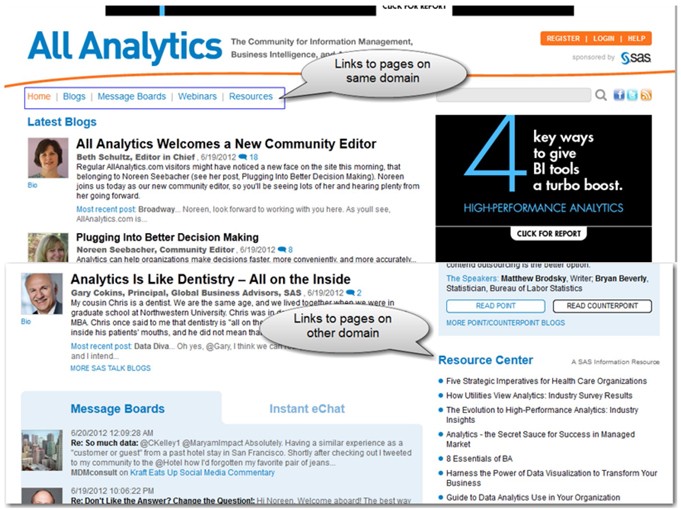
A value of 1 for the Depth property would extract all of the files linked to from the initial page. Hence, the web pages for the links on the home page of the allanalytics.com site, such as Blogs, Message Boards, Webinars, and Resource Center, are extracted. If you leave this property value set to its default (i.e., 2), the web pages of the links available in Blogs, Message Boards, Webinars, Resources, and Resource Center are also extracted. In this way, you can control the level up to which you want to extract web pages. You need to be cautious when using this property. As you increase the depth, the number of pages extracted grows exponentially.
Most of the time, you want to restrict your analysis only to web pages from one particular domain or website. For example, when analyzing the allanalytics.com web page, you do not want to extract web pages from other domains such as www.sas.com using the links that are contained in the allanalytics.com web pages. The property setting Domain is used to control this behavior. A value of Restricted prevents the crawler from processing documents outside the domain of the initial web page. If this is not a concern in your study, then leave this property value set to Unrestricted. User Name and Password properties are used when the URL input refers to a secured website and requires a user name and password to access the content on that domain.
After the Text Import node run is complete, the Results window generates the same types of plots as seen in the previous section. You can look in the Destination and Source folders for the files that are downloaded from the web and for the text files that were filtered from these downloaded files. The downloaded files are named File1, File2, File3, and so on. With the current settings, it took 20 minutes to download around 1,800 web pages. This completely depends on the website that you are downloading from and the value set for the Depth property.
Display 3.20 shows a sample of the data set that is created by the Text Import node. You can browse the data using the Exported Data property from the Properties panel. The Text field shows a text snippet with the first 1000 characters from the downloaded web page. The URL column lists the source URL of the web page. This list shows that all of the pages are downloaded from the same domain, www.allanalytics.com.
Display 3.20: Sample Output of the Data Set Created from Web Crawling

The exported data is used by the successor nodes, primarily the Text Parsing node, for processing and use in the text mining process. Chapter 4 discusses in detail the functionality of the Text Parsing node.
%TMFILTER Macro
The macro program that runs behind the Text Import node is %TMFILTER. Starting with SAS Text Miner 4.1, this macro is made available as a node. If you are using an earlier version of SAS Text Miner, the same operations of filtering and web crawling can be performed using this macro. It is supported in all operating systems for filtering and on Windows for web crawling. Here is the macro syntax:
%TMFILTER (DIR=path,
URL=path <,DATASET=<libref.>output-data-set <,
DEPTH=n,
DESTDIR=path,
EXT=extension1 <extension2 extension3...>,
FORCE=anything,
HOST=name | IP address,
LANGUAGE=ALL | language1 <language2 language3...>,
NORESTRICT=anything,
NUMBYTES=n,
PORT=port-number,
PASSWORD=password,
USERNAME=username>)
All of the above options are available as properties of the Text Import node, except for FORCE=, HOST=, and PORT=. The FORCE option is used to let the macro run even if the Destination directory is not empty. If no value is set for the property, the node or the macro will terminate if the Destination directory is not empty. The HOST and PORT options are necessary for the SAS Document Conversion server to function properly. The HOST property specifies the name or IP address of the machine on which to run the %TMFILTER macro. If you do not specify a value, then the macro assumes that the SAS Document Conversion server will use its own defaults. The PORT option is used to specify the number of the port on which the SAS Document Conversion server resides. It is more convenient for troubleshooting if you are using the %TMFILTER macro for importing text. For more technical information and examples of how to work with the macro, see the SAS Text Miner User Guide.
Importing XLS and XML Files into SAS Text Miner
In the previous sections, we demonstrated how you can extract data from documents with file extensions such as .pdf, .html, or .txt into SAS data the Text Import node feature in SAS Text Miner to import the data, it grabs all of the text in one row of the output SAS data set. Data is truncated from the TEXT field if its length exceeds the value provided in the Text Size property for the Text Import node. However, this is not the output that you would expect to generate. It is important to import each of the review comments as separate rows in the output data set. Hence, you can use the File Import functionality in SAS Enterprise Miner, located on the Sample tab, to import data from an Excel file. Drag and drop the node onto the Diagram workspace, and change the Import File property to point to the location of the Excel file. (See Display 3.21.) Change the Delimiter property to SP, which represents that a space character separates the columns in the Excel spreadsheet. You can use “,” as the delimiter for CSV files.
Display 3.21: File Import Node Properties Pane
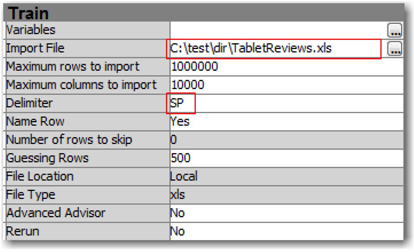
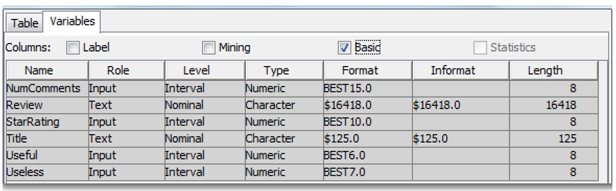
Run the File Import node to extract data from the Excel file into the SAS environment. When the Name Row property is set to Yes, SAS identifies the first row in the file as column names, and it uses the column names to name SAS variables in the output data set. The Guessing Rows property is useful to assess the data in the first n rows of the Excel file, and it estimates values for attributes such as Level, Type, Format, Informat, and Length of the SAS variables. In the Properties pane, click on the ellipsis button for Exported Data, select the Train data identified by the column Role, and click OK. The Properties window appears. Go to the Variables tab, and select the Basic check box to find all of the variables and their attributes. (See Display 3.22.)
Display 3.22: SAS Output Data Set Variables and Its Data Attributes
You can use PROC IMPORT to import data from an Excel file into a SAS data set. (See Program 3.1.) For this to work, you should have a license for SAS/ACCESS Interface to PC Files. This product enables SAS to treat an Excel spreadsheet as a database and a subset of its cells (also called a range) as a table. You can specifically point to and read a relevant worksheet in an Excel workbook. For example, the worksheet Sheet1 in TabletReviews.xls contains all of the review comments that we need. Data values in the first row of columns in the worksheet can be used to name the variables in the output data set.
Program 3.1: SAS Code to Import Data from an Excel File
PROC IMPORT
/* Library and name of the data set in which the output is stored */
OUT=work.TabletReviews
/* Physical path of the input file to read data */
DATAFILE=“C: estdirTabletReviews.xls”
/* Data source identifier specifying the type of data to import */
DBMS = XLS
/* Overwrite SAS output data set, if it already exists */
REPLACE;
/* Name of the worksheet containing the data to import */
SHEET = ‘Sheet1’;
/* Data values in first row used to name variables in SAS data set */
GETNAMES=YES;
RUN;
If you run this code, you will find that the SAS data set TabletReviews has been created in your Work library with all of the review comments stored as individual rows. This is a very quick and efficient approach to import text data from an Excel file. You can import data from an Excel file using the SAS Import Wizard in SAS Enterprise Guide without writing any SAS code.
Data is often stored in XML files. XML stands for Extensible Markup Language. XML files are typically composed of tags and values. An XML file can either have a simple or complex structure, which mainly depends on how the tag hierarchies are defined. For example, a sample XML file, SAS_Books_Sample.xml, contains information about some of the SAS Press books. (See Display 3.23.) You can see information specific to each book enclosed in relevant tags. Tag book id appears as the parent tag under which all other tags (author, title, publisher, and price) are formatted in the same level. This is a classic example of a very simple XML file structure that many websites typically follow.
Display 3.23: Sample XML File with Information about SAS Press Books

XML files can be read programmatically by SAS by reading the tags and feeding their values to columns in a SAS data set. However, this process is not very efficient, and you need to write a customized program if the structure of the XML file changes. SAS XML Mapper is an easy-to-use tool exclusively developed for the purpose of mapping XML tags and their values directly to columns and rows in a SAS data set. You can download it from http://support.sas.com for free. Using this tool, XML files of almost any complex structure can be parsed.
Start SAS XML Mapper, and select File ▸ Open to locate the XML file to be used for generating the XML map. Select the XML file named SAS_Books_Sample.xml, and click Open to load the file into SAS XML Mapper. Right-click on the root tag book, and click AutoMap this branch to move all of the tags into the map. (See Display 3.24.) Select File ▸ Save XMLMap As, and save the map as SASBooks.map. You can click the Table View tab in the bottom half of the screen to see how various tags and values are transformed into rows and columns.
Display 3.24: SAS XML Mapper Using SAS_Books_Sample.xml
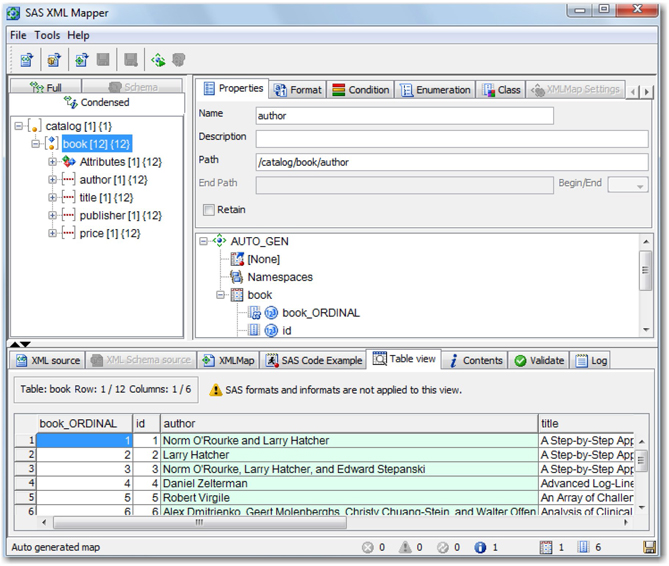
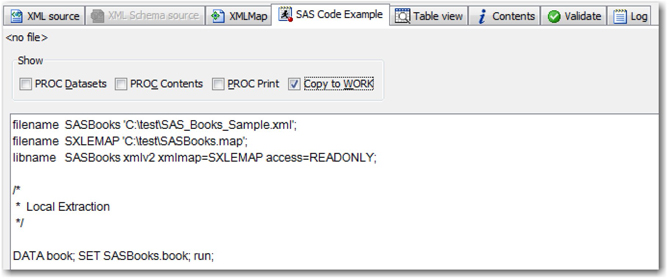
You can use this map to import data from the XML file through the XML LIBNAME engine. You can directly copy the program from the SAS Code Example tab to import data from the XML file. Uncheck all boxes except Copy to WORK to retain the code required for this purpose. (See Display 3.25.) Copy and run this code in Base SAS to generate the SAS output data set in the Work library. If you would like to create the output data set in a permanent library, replace the data set name book in the DATA step with Lib.book, where Lib is the name of permanent library.
Display 3.25: SAS XML Mapper Showing SAS Code Generated Automatically
In the second maintenance release for SAS 9.3, the AUTOMAP option became available with the XMLV2 LIBNAME engine. This feature enables you to create default XMLMap files in SAS without the need for SAS XML Mapper. AUTOMAP= option accepts either REPLACE or REUSE as its value. If you use REPLACE, an XMLMap file with the same name is overwritten with the new file if it exists in the same location. The REUSE value uses the XMLMap file with the same name if already exists, otherwise, a new file is created. Using the sample XML file we used in the previous example SAS_Books_Sample.xml, you just need to run the following code to create the SAS data set automatically using the XMLV2 LIBNAME engine and the AUTOMAP option. The FILENAME option creates a temporary location for XMLMap file tempMap in this example.
Program 3.2: SAS Code to Use XMLV2 LIBNAME Engine with the AUTOMAP Option
libname out ‘C: est’;
filename SASBooks ‘C: estSAS_Books_Sample.xml’;
filename tempMap temp;
libname SASBooks xmlv2 xmlfileref=out xmlmap=tempMap automap=replace;
data out.book; set SASBooks.book; run;
For a moment, let’s move away from local files to websites where the information of interest is often found in news articles, blogs, user reviews, social media conversation, etc. Many websites storing massive volumes of unstructured data usually allow external applications to connect and access its data by means of an API (application programming interface). Social media giants Twitter and Facebook are the most popular websites offering APIs for data exchange. You can send your requests to these APIs and retrieve unstructured data that you can use in various text analytics applications, such as analyzing social media trends, topic discovery, and sentiment analysis.
Generally, you need custom-built SAS programs capable of querying APIs and parsing the returned responses in various formats. The most commonly used API response formats are Atom, XML, RSS, and JSON (JavaScript Object Notation). Data consumers face challenges to keep up with the ever-changing structures and formats of API responses. For example, Twitter, in its current version (API v1.1), offers support only in JSON format, and has deprecated old formats such as XML, Atom, and RSS. Fortunately, the SAS user community has been contributing and sharing conference papers, blogs, and articles and providing SAS programs to deal with most of the formats. In their paper, Badisa, Mandati, and Chakraborty (2013) discussed a SAS macro that they developed to extract movie reviews from a website and return data in JSON format. You need an API key and the name of a movie to execute this macro. It predominantly uses SAS Perl regular expression functions to meaningfully parse the returned responses and to store the reviews of that movie in a SAS data set.
In 9.4, SAS provides a new procedure, PROC JSON. The JSON procedure helps you export a SAS data set into an external file in JSON format. Here is sample code to generate an external file in JSON format based on the content in the SASBooks SAS data set that was created in the previous section using the XMLV2 LIBNAME engine.
Program 3.3: SAS Code to Export a SAS Data Set into an External File in JSON Format
proc json out=“C: estBooksOut.json” pretty nosastags;
export out.book;
run;
The PRETTY option makes the output data easy to read, and the NOSASTAGS option suppresses metadata supplied by SAS. This helps keep it in a format similar to web service formats. Here is the sample output generated in the JSON format:
[
{
“book_ORDINAL”: 1,
“id”: 1,
“author”: “Norm O’Rourke and Larry Hatcher”,
“title”: “A Step-by-Step Approach to Using SAS for Factor Analysis and Structural Equation Modeling, Second Edition”,
“publisher”: “SAS Institute”,
“price”: 74.95
},
{
“book_ORDINAL”: 2,
“id”: 2,
“author”: “Larry Hatcher”,
“title”: “A Step-by-Step Approach to Using SAS for Factor Analysis and Structural Equation Modeling”,
“publisher”: “SAS Institute”,
“price”: 89.95
},
{
“book_ORDINAL”: 3,
“id”: 3,
“author”: “Norm O’Rourke, Larry Hatcher, and Edward Stepanski”,
“title”: “A Step-by-Step Approach to Using SAS for Univariate and Multivariate Statistics, Second Edition”,
“publisher”: “SAS Institute”,
“price”: 89.95
},
]
Managing Text Using SAS Character Functions
Many projects might require preprocessing textual data before any text mining is performed.
SAS programmers or analysts might have to validate text, replace text, and extract a substring from a string. These operations can be performed using powerful SAS character functions like SCAN, INDEX, SUBSTR, etc., and simple DATA step programs. Although SAS character functions are valuable for data cleaning, they might not be very efficient when the text is too long.
Many projects involving textual data require disguising a piece of text or a set of words because of confidentiality reasons or simply to make the data look clean. A typical example is eliminating or disguising all swear words in the text that are commonly found when dealing with data from social media websites. TRANWRD, TRANSLATE, and TRANSTRN functions can be appropriately applied to perform this task. Functions like COMPBL, COMPRESS, and SUBSTR can be extensively used to eliminate the noise from the text. Consider a data set that has the following Tweets about a general store:
1. #Valuemart clearing off shelf space for $599 #HP #TouchPad? http://pulsen.wk/1QQL7_:)
2. Value-mart has a Blu-ray Value Bundle #Deal Choice of 2 #Movies for $15 Pick 2 from a list of 48. RT
3. VALUE MART Coupons- Get Your Name In For The $1000 Gift Card We Will Be Giving Away At The End Of The Month **DEAL**
The following DATA step with SAS character functions replaces all occurrences of the word “ValueMart” or its variants, eliminates double spaces, and eliminates special characters like * . : , and ) from the text.
Program 3.4: SAS Code with Examples Using TRANWRD, COMPBL, and COMPRESS Functions
data valuemart1;
set valuemart;
/*Compresses successive blanks to a single blank*/
text = compbl(text);
/*Replace ‘Valuemart’ with ‘Store’ */
text = tranwrd(text, ‘Valuemart’,‘Store’);
/*Replace ‘Value-mart’ with ‘Store’ */
text = tranwrd(text, ‘Value-mart’,‘Store’);
/*Replace ‘VALUE MART’ with ‘Store’ */
text = tranwrd(text, ‘VALUE MART’,‘Store’);
/*Remove specified characters in the second argument from text */
text = compress(text, ‘#*:()&@!-?+’);
run;
The DATA step transforms the three Tweets in the following example:
Store clearing off shelf space for $599 HP TouchPad http//pulsen.wk/1QQL7
Store has a Bluray Value Bundle Deal Choice of 2 Movies for $15 Pick 2 from a list of 48. RT
Store Coupons Get Your Name In For The $1000 Gift Card We Will Be Giving Away At The End Of The Month DEAL
Character functions can significantly improve the quality of the textual data. There are various other functions available in SAS that can be wisely applied for manipulating textual data. In the previous example, we had to write three different TRANWRD statements to replace the three variants of the string “Valuemart.” In the next section, you learn how to accomplish this task with just one statement by defining patterns using Perl regular expressions.
Managing Text Using Perl Regular Expressions
SAS character functions lack flexibility and tend to be not very effective with dynamic text. In situations like these, regular expressions and routines give the programmer the power to define, locate, and extract patterns from highly unstructured text easily. They can make a complicated string manipulation task look very simple by combining most of the steps, if not all, into one expression.
SAS provides two types of regular expressions for pattern-matching: SAS regular expressions (the RX functions) and Perl regular expressions (the PRX functions). Regular expressions are popularly used to easily process large amounts of textual data. These expressions help in defining patterns that can be searched and extracted in a character string. Regular expressions are nothing but a string of standard characters and special characters, called metacharacters, which tell the program what types of patterns to find in the text. It is strongly suggested to comment any regular expression that you write because it is highly possible that it will be very difficult to interpret the ones that you wrote yourself.
Perl is a powerful text processing language widely popular amongst programmers. In this chapter, we briefly discuss how Perl regular expressions can be used for effectively preprocessing the data. A modified version of Perl regular expressions is implemented in SAS via a set of functions called PRX functions. Only Perl regular expressions are available in SAS, not the entire Perl language. You do not need to be an advanced SAS programmer to write Perl regular expressions. Basic knowledge of DATA step programming is sufficient. The examples discussed in the following sections can be easily modified to meet your requirements.
Using Perl Regular Expressions to Match Exact Text in a Document
The simplest use of Perl regular expressions is to locate a piece of text or a pattern in a textual document. You can write a regular expression to check whether a document contains text in the form (XXX) XXX – XXXX, indicating a phone number. Here, Xs are digits. You can use a Perl regular expression to search for specific characters and other classes of characters (digits, letters, non-digits, etc.).
Perl helps in defining and extracting custom patterns in text, and SAS Text Miner contains a built-in functionality to extract common types of text like phone number, address, and SSN, and entities like names of people, places, companies, etc., during text parsing. A more advanced type of entity extraction can be done by defining concepts in text using SAS Content Categorization Studio. We discuss these topics in Chapter 7.
Consider the corpus of web pages downloaded from the allanalytics.com website in the previous section. From the entire corpus, if you want to consider only those articles that talk about big data, you can use a Perl regular expression to filter the articles that you need.
Here is a simple DATA step that can meet this requirement:
Program 3.5: SAS Code Showing Usage of PRXPARSE and PRXMATCH Functions in a SAS DATA Step
data bigdata;
set work.allanalytics;
if _N_=1 then pattern= PRXPARSE (“/big data /”);
retain pattern;
Locate =PRXMATCH(pattern,text);
if locate;
drop pattern locate;
run;
Log:
NOTE: There were 1788 observations read from the data set WORK.ALLANALYTICS.
NOTE: The data set WORK.BIGDATA has 140 observations and 15 variables.
NOTE: DATA statement used (Total process time):
real time 0.25 seconds
cpu time 0.17 seconds
In the program, we create the data set allanalytics from the web pages available in the WORK library. The PRXPARSE function is used to create a regular expression. Because you want to use the pattern for each observation in the data set, the pattern has to be available for each iteration of the DATA step. Instead of compiling it for each observation, you can execute the statement with PRXPARSE only once, and then use the RETAIN statement with _N_ to make it available for each iteration. The PRXPARSE function returns a code that is a sequential number generated by SAS whenever a regular expression is compiled. The PRXMATCH function is used to return the first position of the string “big data” in the given text. A value of 0 is returned when no match is found. The PRXMATCH function takes two arguments: the return code from PRXPARSE and the string to be searched.
The string “big data” might be represented in the articles in multiple forms: big data, Big Data, big-data, BIG DATA, etc. You can include all of these different forms of the string “big data” in the regular expression using a | (OR) condition as shown:
pattern= PRXPARSE(“/big data | big-data | Big Data | BIG DATA /”);
The search can be made more compact and complex to include other possible forms of the string “big data” by writing it the following way:
pattern= PRXPARSE(“/[Bb]ig( |-)?[Dd]ata /i”);
Log:
NOTE: There were 1788 observations read from the data set WORK.ALLANALYTICS.
NOTE: The data set WORK.BIGDATA has 989 observations and 15 variables.
NOTE: DATA statement used (Total process time):
real time 0.10 seconds
cpu time 0.04 seconds
This pattern will match the strings “big data,” “Big Data,” “BIG DATA,” “big-data,” “Big-Data,” “bigdata,” “BigData,” “BIGDATA,” and “BIG-DATA.” In the log, there are more documents filtered because the new regular expression contains more forms of the search word. In this regular expression, the letters “[Bb]ig” match either Big or big. Similarly, the expression in parenthesis ( |- ) is used to search for a space or a hyphen after the letters “[Bb]ig.” To include the words “BIGDATA” or “bigdata” (no space or hyphen between the two words) in the search, we use the ? metacharacter, which matches the previous sub-expression zero or one time. The letter “i” after the last slash is used to match all types of cases (small, upper, and proper case) of the string.
Using Perl Regular Expressions to Replace Exact Text
In many situations, the business application demands to anonymize certain words in your text before you use it in text mining. Perl regular expressions are of great help in performing text substitutions. The Perl substitution function, which is in a PRXPARSE function, looks like this:
PRXPARSE(“s/ pattern to find / text to substitute /”);
You need to specify the substitution operator s before the first slash in the regular expression. In the previous example, if you want to replace different forms of the string “big data” with the string “Big Data,” you can do it using PRXPARSE and PRXCHANGE functions. You can anonymize all of these words with a different keyword if required. Here is the DATA step for completing this task:
Program 3.6: SAS Code Showing Usage of PRXPARSE and PRXCHANGE Functions in a SAS DATA Step
data bigdata;
set bigdata;
if _N_=1 then pattern= PRXPARSE(” s/[Bb]ig( |-)?[Dd]ata / Big Data /i”);
retain pattern;
call PRXCHANGE (pattern, -1, text);
drop pattern;
run;
The PRXCHANGE function is used to substitute one string for another. The function takes the return code from PRXPARSE as the first argument. The second argument is used to indicate the number of times to search for and replace a string. A value of -1 replaces all matches. The third argument is the string to be replaced. We have explained only the required arguments of the function in this example. For more information about this function, see the online SAS Help.
The substitution approach can be heavily used for cleaning the data. If you can define the pattern of noise in the data to the best extent possible, you can create regular expressions and replace the matches with a blank space. This helps in generating cleaner data for further text mining.
Using Perl Regular Expressions to Extract Text between Two Keywords
The ability to define patterns and locate those patterns in text using regular expressions makes the Perl language very powerful in handling textual data. Organizations have ample textual data at their disposal. We have the computer power to use all textual data for text mining. Remember that textual data is first transformed into numbers before any traditional data mining tasks are performed. The more text used for text mining, the more complex the processing. Instead, in many situations, it is sufficient to use a piece or part of a document for performing text mining.
For example, consider you want to analyze conference papers to understand the trend of topics represented in various conferences. Considering the entire paper in your analysis will likely add a lot of noise because an entire paper can include tables, images, references, SAS programs, etc., which are problematic and might not add much value in text mining for topic extraction. The abstract of a paper is the most appropriate text because it captures the detailed objective of a paper and does not contain extraneous items. A typical conference paper has the following layout:
Display 3.26: Typical Layout of a Conference Paper

We define two regular expressions that give the positions of the keywords ABSTRACT and INTRODUCTION in the conference paper. The text between the two positions (that represents the abstract portion of the paper) is extracted for text mining. However, not all authors will follow the same layout. For this example, we assume we are dealing with papers that strictly follow the above layout. This problem is dealt with in detail in Case Study 1. The DATA step program that can solve this requirement is shown in Program 3.7:
Program 3.7: SAS Code Showing Usage of PRXPARSE and PRXMATCH Functions to Extract a Portion of Text
data abstracts;
length text $ 3000;
set work.sasgf;
if _N_=1 then do;
pattern1 = PRXPARSE (“/Abstract/i”);
pattern2 = PRXPARSE (“/Introduction/i”);
end;
retain pattern1 pattern2;
position1=PRXMATCH (pattern1, text);
position2=PRXMATCH (pattern2, text);
if position1 gt 0 AND (position2-position1) gt 0
then text= SUBSTR(text,position1+9,position2-position1-9);
else text= SUBSTR(text,150,2850);
drop pattern1 pattern2 position1 position2;
run;
After locating the positions of the keywords using the PRXMATCH function, a SUBSTR function is used to fetch the text between the two positions. In the case that you do not find a match for the two keywords, we extract text with a length of 2,850 characters after the first 150 characters, assuming that the first 150 characters represent the title and author details, which are unnecessary for the study. Display 3.27 shows sample results of abstracts extracted using the above code.
Display 3.27: Sample Output of the Abstracts Extracted from SAS Global Forum Papers

The examples described in this section are very basic and are intended to illustrate the simple functionality of Perl regular expressions available in SAS. There are other functions like PRXPOSN, PRXNEXT, PRXPAREN, etc., which make processing unstructured data much easier and powerful. Using these functions cleverly can help you locate, extract, and replace any type of text. Whether it is extracting sales figures from annual reports, extracting ZIP codes or phone numbers from application documents, or cleaning customer comments from Internet public forums, anything can be done using Perl regular expressions. For more information about using Perl regular expressions in SAS, see http://support.sas.com or http://sascommunity.org.
Summary
In this chapter, you learned various techniques for importing textual data that exists in a wide variety of file formats: .html, .txt, .pdf, .xlsx, .xml, .doc, etc. In many situations, you might have to combine text data in these different forms for text mining purpose. SAS Enterprise Miner and SAS Text Miner have easy-to-use capabilities to import data from these files and to prepare SAS data sets. The strong web crawling functionality in SAS that is available through the Text Import node makes it easier to retrieve data available from the web. Every data importing task in SAS can be performed either via a user interface or via SAS programming. The powerful data management tools and techniques in SAS help in combining, transforming, and cleaning data. This extracted textual data can be processed before text mining analysis using SAS character functions. Although most of the text validation, extraction, and replacement tasks can be performed using these functions, more text processing capabilities are available using Perl regular expressions. All of these features empower an analyst with innumerable capabilities from data extraction, consolidation, and transformation that are generally performed before starting text mining analysis.
References
Badisa, G., Mandati, S., and Chakraborty, G. 2013. “%GetReviews: A SAS® Macro to Retrieve User Reviews in JSON Format from Review Websites and Create SAS® Datasets”. Proceedings of the SAS Global Forum 2013 Conference. SAS Institute Inc., Cary, NC. Available at: http://support.sas.com/resources/papers/proceedings13/342-2013.pdf
Cassell, D. L. 2005. “PRX Functions and Call Routines.” Proceedings of the Thirtieth Annual SAS Users Group International Conference. SAS Institute Inc., Cary, NC. Available at: www2.sas.com/proceedings/sugi30/138-30.pdf.
Cody, R. 2004. “An Introduction to Perl Regular Expressions in SAS 9.” Proceedings of the Twenty-Ninth Annual SAS Users Group International Conference. SAS Institute Inc., Cary, NC. Available at: www2.sas.com/proceedings/sugi29/265-29.pdf
Cody, R. 2004. SAS Functions by Example, 1st ed. Cary, NC: SAS Institute Inc.
Francis, L. 2010. “Text Mining Handbook.” CAS E-Forum: Publication of the Casualty Actuarial Society. Available at: http://www.casact.org/pubs/forum/10spforum/Francis_Flynn.PDF.
McGowan, K. and Lagle, B. 2011. “A Better Way to Search Text: Perl Regular Expressions in SAS.” Proceedings of the SAS Global Forum 2011 Conference. SAS Institute Inc., Cary, NC. Available at: http://support.sas.com/resources/papers/proceedings11/006-2011.pdf.
McNeill, B. 2013. “The Ins and Outs of Web-Based Data with SAS®.” Proceedings of the SAS® Global Forum 2013 Conference. SAS Institute Inc., Cary, NC. Available at: http://support.sas.com/rnd/papers/sasgf13/024-2013.pdf.
Miller, T. W. 2005. Data and Text Mining: A Business Applications Approach. Upper Saddle River, New Jersey: Pearson Prentice Hall.
Pant, G., Srinivasan, P., and Menczer, F. 2004. “Crawling the Web”. Web Dynamics: Adapting to Change in Content, Size, Topology and Use. New York: Springer-Verlag, 2004.
Text Analytics Using SAS® Text Miner. Course Notes. SAS Institute Inc., Cary, NC. Course information: https://support.sas.com/edu/schedules.html?ctry=us&id=1224.
Weiss S, Indurkhya N, Zhang T, Damerau F. 2005. Text Mining: Predictive Methods for Analyzing Unstructured Information. Springer-Verlag.
Zhang, S. 2007. “Use Perl Regular Expressions in SAS®.” Proceedings of the 20th Annual NorthEast SAS Users Group Conference. Available at: http://www.nesug.org/proceedings/nesug07/bb/bb18.pdf.