
Case Study 7 Information Organization and Access of Enron Emails to Help Investigation
Dan Zaratsian
Murali Pagolu
Goutam Chakraborty
Step-by-Step Software Instruction with Settings/Properties
Introduction
Across industries, text analytics is opening the door for new, innovative ways to understand behavior, motives, interests, and trends buried within rich textual data. In most instances, this type of data is most advantageous when it is paired with structured data, such as demographic or transactional data, to enhance your view of the customer or party of interest. Text analytics is used across industries and can be applied to a variety of data. This data may consist of survey responses, call center notes, emails or chat messages, social media, news posts, forums, blogs, a document collection, warranty claims, and many more. This is why it is critical for an organization to take advantage of text analytics tools to extract relevant, insightful information from this type of data.
In the world of fraud and criminal activity, investigators benefit from having as much as information as they can in order to solve the puzzle. But there are really two fundamental problems with this. First, they only have so much time in the day to review the information, so having the right tools to analyze and sort through the volumes of data in the least amount of time is essential. Second, most of this information is in the form of documents, emails, and other textual formats.
The Enron Corporation was an American energy, commodities, and services company based in Houston, Texas. In 2001, it filed for bankruptcy. Before Enron’s, bankruptcy filing, Enron employed approximately 20,000 staff. It was one of the world’s leading electricity, natural gas, communications, and pulp and paper companies, with claimed revenues of nearly $101 billion in 2000. Later, it was discovered that many of Enron’s recorded assets and profits were inflated, or even wholly fraudulent and nonexistent. For example, in 1999, Enron promised to pay back a Merrill Lynch investment with interest in order to show a profit on its books. Debts and losses were placed in offshore accounts that were not included in the firm’s financial statements. More sophisticated and mysterious financial transactions between Enron and related companies were used to take unprofitable entities off the company’s financial records. These “offshore” entities were limited partnerships between Enron and LJM Cayman LP and LJM2 Co-Investment LP, created to buy Enron’s poorly performing stocks to improve its financial statements. These two partnerships received funding of approximately $390 million from a group of investors. Enron created entities it called “Raptors” and transferred more than $1.2 billion in assets into Raptor accounts, including millions of shares of Enron common stock, long-term rights to purchase millions more shares, plus $150 million of Enron notes payable. It capitalized the Raptors and booked the notes payable issued as assets on its balance sheet while increasing the shareholders’ equity for the same amount.
Objective
Understanding the actions and motives of fraudsters is a vital part of predicting (and preventing) fraudulent activity. To gain an advantage, you must incorporate analytics within your investigative process. The goal of analytics is to turn data into actionable information. Unfortunately, most data is unstructured, making it more challenging to analyze than traditional structured data (such as demographic or transactional data). SAS Text Analytics processes large volumes of text and provides useful analytics to support investigations. The objective of this case study is to demonstrate how SAS Text Analytics can be leveraged to extract meaningful information from textual data and to identify patterns and trends across thousands of Enron email correspondences.
Data Description
The Enron email data, used in this case study, is publicly released as part of FERC’s Western Energy Markets investigation and has been converted to industry standard formats by EDRM. The original data set consists of 1,227,255 emails with 493,384 attachments covering 151 custodians. The email is provided in Microsoft PST, IETF MIME, and EDRM XML formats. This data was downloaded from http://www.edrm.net/resources/data-sets/edrm-enron-email-data-set-v2 in an XML format.
This case study was performed using the following SAS software:
• SAS® Enterprise Miner
• SAS® Text Miner
• SAS® Enterprise Content Categorization
• SAS® Crawler (SAS Information Retrieval Studio)
Step-by-Step Software Instruction with Settings/Properties
Step 1: Information Retrieval and Parsing
As described above, we chose to download the files in XML format from the website http://edrm.net/. The XML file looked something like this:

Our first objective is to convert the XML files into a structured format (a SAS data set) by parsing out the individual fields such as body, title, id, msgdate, from, and to. We chose to use SAS® Information Retrieval Studio to crawl the XML file directory and parse the XML using the built-in “parse_xml” post-processor. Below are step-by-step instructions and screenshots that help to clarify this process:
1. Launch the SAS® Information Retrieval Studio and create a new project. Name it ‘Enron’.
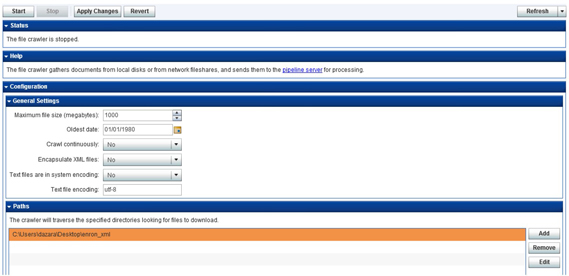
2. Go to ‘File Crawler’ and change the ‘General Settings’ to reflect the properties as shown in Display C7.1. Under the “Paths” section, provide the complete path of the folder which contains the XML files you downloaded. Under the “Paths to Exclude’ tab, add ‘XML’ as the filename extension you wish to exclude from file crawling. Click ‘Apply Changes’ to save settings.
Display C7.1: Settings for File Crawler in SAS® Information Retrieval Studio
3. Go to ‘Pipeline Server’ and add the document processor – ‘parse_xml’ from the list of available document processors using the default settings.
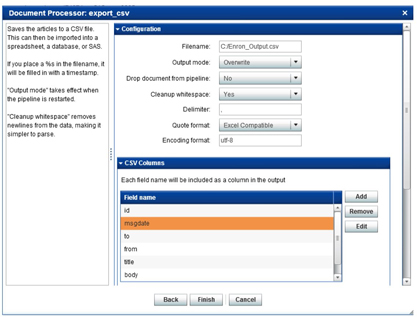
4. Add the ‘export_csv’ document processor and make the changes as shown in Display C7.2. Ensure all the fields: id, msgdate, to, from, title and body are included in the columns for output. Click on ‘Apply Changes’ to save the settings.
Display C7.2: Settings for ‘export_csv’ document processor
5. Go to the ‘File Crawler’ and click on ‘Start’ to kick start the file crawling, extract the contents of XML files, and export the data into structured columns of a CSV file.
6. Rename the fields ‘id’ to ‘_document_’, ‘msgdate’ to ‘date’, ‘to’ to ‘recipients’, ‘from’ to ‘sender,’ and ‘title’ to ‘subject’.
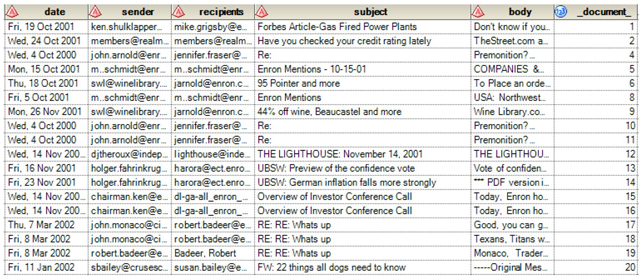
7. You can then use the ‘Import Data’ task in SAS® Enterprise Guide to import the data in the output CSV file. The output SAS data set will look like the below (Display C7.3).
Display C7.3: Snapshot of the Enron emails data imported from output CSV file
Note: For this case study, we are only providing you with a small sample since the original data is very large (~210 GB).
Step 2: Data Exploration and Analysis
1. Launch SAS® Enterprise Miner, create a new project, and name it ‘TM_Demo’. Alternatively, you can also open the project “Enron_TM” that we have provided. This is available in the folder Case Studies ▸ Case Study 7 in the data provided with this book.
2. Register the SAS data set that we have provided to you (ENRON_SAMPLE.sas7bdat). This data set is also available in the folder Case Studies ▸ Case Study 7 in the data provided with this book. Ensure that the variable ‘body’ is in ‘Text’ role, ‘_document_’ in ‘ID’ role and the rest of variables are rejected.
3. Create a new diagram and name it ‘Enron Analysis’. Drag the registered SAS data set into the diagram.
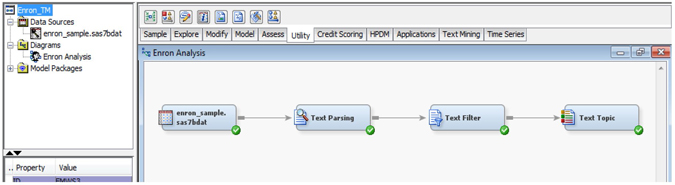
4. Connect the ‘Text Parsing’, ‘Text Filter’, and ‘Text Topic’ nodes in series as shown in the Display C7.4.
Display C7.4: Text mining process flow for ‘Enron Analysis’
5. Click ‘Text Parsing’ node and change the following settings in the property pane.
a. Find Entities – Standard
b. Ignore Types of Entities – Company, Currency, Date, Person Address, Internet, Phone, and SSN
6. Click ‘Text Filter’ node and change the property ‘Check Spelling’ to ‘Yes’.
7. Click ‘Text Topic’ node, right click, and select ‘Run’ to execute the text mining process flow.
8. Once the process flow is run successfully, right click and open the text parsing node results. You will find that all of the terms in the email content are parsed. They are either kept or dropped from the terms list based on the default stop list and property settings such as ignore types of entities, attributes, and parts of speech. From this list, you can find lot of terms and phrases which you can use in building taxonomy for the classification of Enron emails.
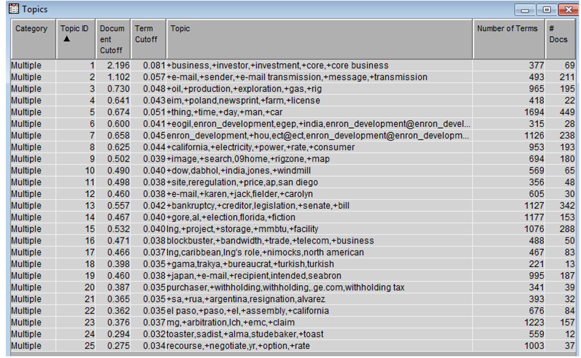
9. Click on the Text Topic node and verify the results by looking at the multi-term text topics generated from the Enron sample data set (Display C7.5). You can make sense of these topics by looking at the terms describing each of the individual topics. For example, Topic 14 is about the Al Gore election, #16 is about trading telecommunications stock, #3 is about oil production, and #11 is tied to California electricity, which are all part of the Enron scandal. These terms can be used to build the categories/sub-categories that will capture the e-mails related to those topics.
Display C7.5: Text Topics emerged from mining the Enron sample data set
Step 3: Building Taxonomy (Categories and Concepts)
1. In this step, you can start building the taxonomy in SAS® Enterprise Content Categorization for the purpose of classifying the Enron email content into various categories and subcategories.
2. For this purpose, you may either choose to use an industry standard taxonomy such as IPTC and modify it to ensure it is customized for this particular case. This process is lot easier than building it from the scratch.
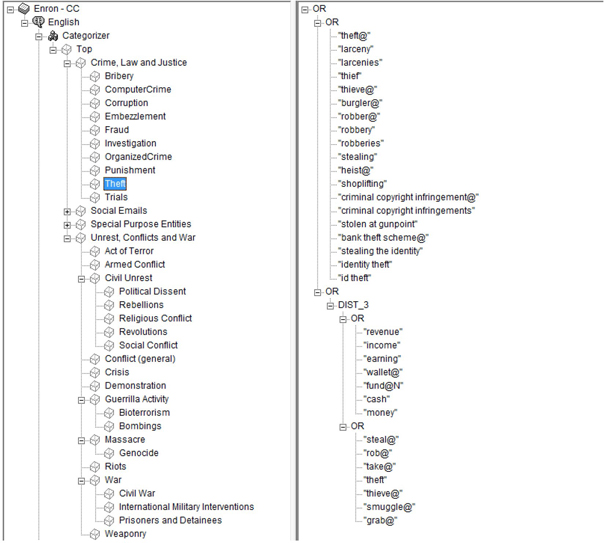
3. For learning purposes, you can open the “Enron_CC” content categorization project we have provided to you. This is available in the folder Case Studies ▸ Case Study 7 in the data provided with this book. As you look at the taxonomy and the categories/sub-categories we have built for this case study, you will find that a lot of terms defining the categories/sub-categories are pre-existing from the IPTC taxonomy (See Display C7.6). However, you can leverage the features such as text parsing and text topic extraction in SAS® Text Miner to enhance the terms list which will efficiently categorize Enron e-mails.
Display C7.6: Taxonomy created for classifying Enron e-mails into categories
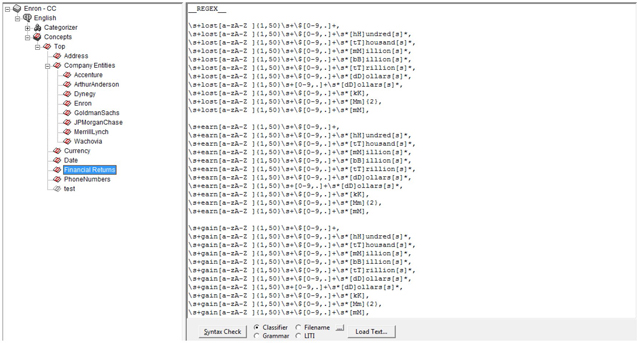
4. Similarly, you can write rules in ECC to capture simple classifier concepts such as the names of companies that can help your investigation. You can also write complex definitions to capture facts that are related to financial gains or losses involved in the scandal. You can rely on regular expression-based concept definitions for this purpose as shown in Display C7.7.
Display C7.7: Concepts created to capture facts using regular expressions
Step 4: Indexing and Search
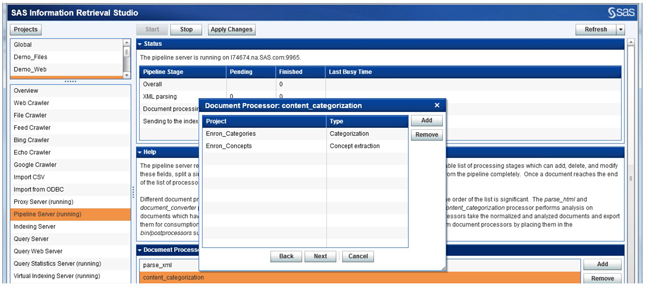
1. As a next step, you can include the content categorization project (categories & concepts) that you have built as a post processor in SAS® Information Retrieval Studio (Display C7.8). You need to use the “content_categorization” document processor from the list of available processors. This will facilitate facetted search and navigation through the matched concepts or categories found in the e-mail content.
Display C7.8: Add the “content_categorization” document processor to enhance searching
2. Upload the compiled categorization and concepts files to the SAS Content Categorization Server using the “Upload Concepts” & “Upload Categories” options available in the “Build” tab of SAS® Enterprise Content Categorization Studio.
3. Update the .desc file located in the installation path under the descriptors folder (Example: C:Program FilesTeragramTeragram Catcon Serverdescriptors) and specify the path to the uploaded project files on the server under the models folder. Also, give meaningful names such as “Enron_Categories” and “Enron_concepts” to uniquely identify these projects.
4. Restart the SAS® Content Categorization Server to make sure all the changes that you have made to the descriptor files are reflected and that the projects are available as document processors in the SAS® Information Retrieval Studio.
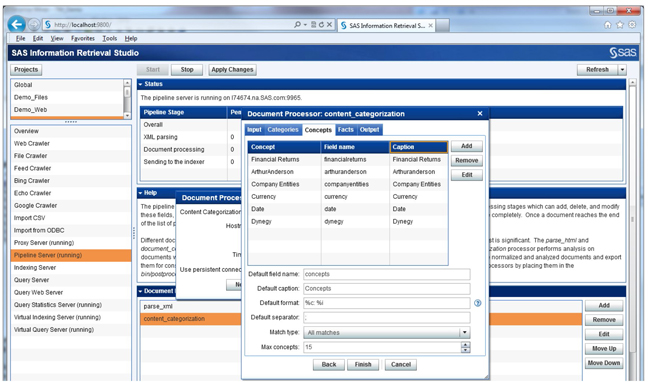
5. You can also customize your search to either include/exclude specific concepts or categories from the available list in the taxonomy you have developed. Display C7.9 shows how various tabs in the document processor wizard for “content_categorization” allow you to do this.
Display C7.9: Custom select concepts and categories to use in the search
6. After you finish adding the “categories” and “concepts” in the document processor, make sure it is placed between the “parse_xml” and “export_csv” processors that you have already created in Step 1. You can use the “Move up”/”Move Down” buttons available under the “Document Processors” pane. Click “Apply Changes” to make sure all the changes are saved.
7. Now, go back to the File Crawler and kick start the crawling again. Once the emails are indexed by the SAS indexing server, you can query the indexed Enron emails by using the SAS query interface.
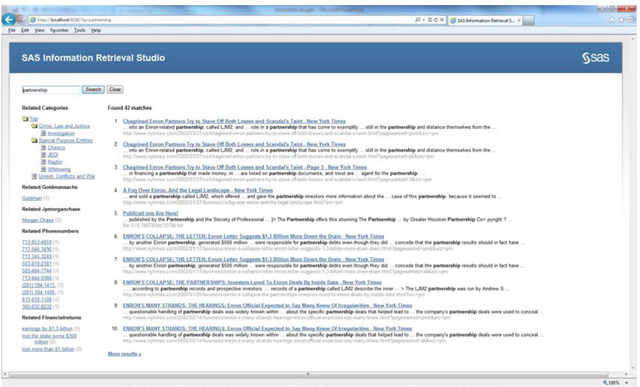
8. Launch the SAS Query interface using the link provided under the Query Web Server. You will find that the categories and concepts are available to perform facetted search on the parsed Enron emails (Display C7.10).
Display C7.10: SAS Query interface showing the search results of indexed Enron emails
Summary
Investigations and audits are typically accompanied by large volumes of text from multiple sources, and as the investigator, you face time-sensitive deadlines and an overwhelming amount of information. Perhaps one of the most time-consuming tasks is finding relevant information when you need it. SAS® Text Analytics uses natural language processing and pattern matching to facilitate timely fact extraction and data organization, giving you a holistic view of the information pertaining to your case.
SAS empowers intelligent search and advanced text analytics, supporting key functions such as:
• Multisource information retrieval and integration.
• Advanced natural language processing to parse information.
• Term stemming and misspelling identification.
• Content categorization based on statistical and linguistic rules.
• Fact and entity extraction based on part-of-speech tagging and pattern recognition.
• Document filtering.
What does this give you? Powerful tools that aid in the organization, exploration, and root-cause analysis of time-sensitive case evidence. This case study focuses on findings from analysis and information extraction of the Enron email archive. Playing the role of investigator, the goal is to extract key evidence of the Enron Corporation’s suspicious accounting practices. The Enron email archive contains more than 500,000 emails from 159 personal email accounts. The task of reading all these emails is unimaginable and impractical, not to mention how difficult it would be to identify patterns among key email accounts. SAS Text Analytics uses both statistical and linguistic technology to parse, explore and categorize the email collection.
By using the Enron emails as a test case, we have identified new opportunities for investigators who need to understand large volumes of data as integrated evidence for their cases. Digging through large volumes of information is now an advantage for investigators because they are able to use SAS® Text Analytics to understand and categorize these documents.