
Chapter 2 Information Extraction Using SAS Crawler
Introduction to Information Extraction and Organization
SAS Information Retrieval Studio Interface
Web Crawling: Real-World Applications and Examples
Understanding Core Component Servers
Component Servers of SAS Search and Indexing
Introduction to Information Extraction and Organization
In a little less than two decades, we have witnessed how the Internet has evolved and become an integral part of a common man’s life. The emergence of many e-commerce websites and social media channels has quickly turned the web into a breeding powerhouse of massive data, mostly unstructured in nature. In a scientific study conducted in 2011, the IDC estimated that the digital world produced 1.8 zettabytes (equivalent to 1.8 trillion gigabytes) of information in that year alone. It is approximated that the amount of data will multiply at least 50 times by the year 2020. This figure applies not just to content on the web, but also to data in documents and files stored locally on PCs and servers across the globe. This irrepressible explosion of data poses quite a challenge for organizations that like to tap into even a portion of this data and transform it into a format suitable for text analytics. Advanced scientific methods such as NLP greatly help organizations in the process of discovering useful nuggets of information hidden within a gazillion bytes of data.
As a first step, organizations should be able to separate useful information (signal) from vast piles of unstructured data (noise). This process can be termed “information extraction.” It should not be confused with the science of information retrieval. Information retrieval is an umbrella term that covers many advanced concepts and techniques such as page ranking, document clustering, etc., which are much broader than information extraction. In this chapter, we discuss how SAS proprietary software can be used to extract unstructured data stored on the web or in file storage systems in a systematic and efficient manner. The extracted data can be parsed, transformed, and even exported to other SAS tools, which can consume this information, analyze, and then produce useful results.
SAS Crawler
Businesses can have multiple needs with textual data. Although text mining serves as a generic process to explore textual data, it is not necessarily the only need. For example, a product firm might require extracting its user reviews and understanding the sentiment of its products or brands in the market. An online media company might choose to categorize its document base into various predefined themes to help its users easily navigate and locate relevant articles or files based on their topics of interest. Some organizations might like to gather information, build an index, and facilitate a search interface for their office staff to access the content in an efficient manner. With such diverse needs, almost all organizations face challenges in managing such large volumes of text data.
To gather and manage such massive volumes of data in a systematic fashion, you need sophisticated tools capable of extracting text data from almost any data source or data format. SAS offers exclusive web crawlers capable of performing directed crawls on the web, files, and even feeds to grab relevant content and store it in raw files. These raw files can be used by other SAS Text Analytics products such as SAS Text Miner for analysis.
SAS Search and Indexing
SAS Search and Indexing helps you choose and then create either a simple or advanced index to efficiently handle user-submitted search queries to retrieve relevant information. Queries are submitted against these prebuilt indexes to return the most relevant matching documents. SAS provides additional components, which are used to parse, categorize, and export the crawled documents to other SAS applications. These components form the heart of the entire IR framework.
SAS Information Retrieval Studio Interface
SAS web, file, and feed crawlers, SAS Search and Indexing, and other supporting components are all integrated on a single framework—SAS Information Retrieval Studio. SAS Information Retrieval Studio is a graphical user interface in which you can configure, control, and monitor the end-to-end information extraction process. The high-level architecture diagram of SAS Information Retrieval Studio provides a general overview of all of the components and how they interact with each other. (See Display 2.1.) Throughout this chapter, we discuss various components of the SAS Information Retrieval Studio interface based on version 12.1. Screenshots referring to these components are subject to slight changes in later versions.
Display 2.1: Simple Architectural Diagram of the SAS Information Retrieval Studio Graphical Framework
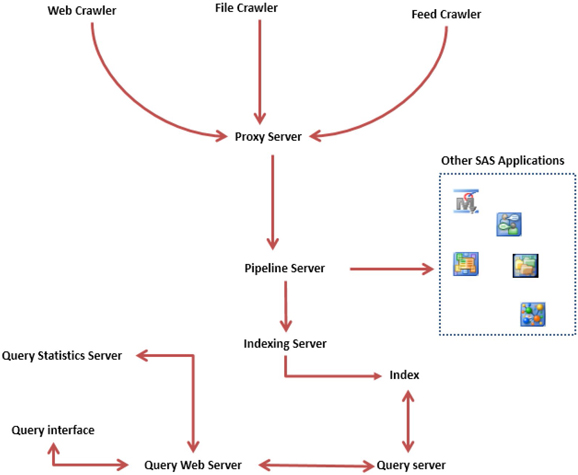
Components of SAS Crawler
Web Crawler – Extracts text from web pages on the Internet or on intranet sites.
File Crawler – Extracts text from files or documents stored locally on PCs, shared network drives, etc.
Feed Crawler – Extracts text from web feed formats such as RSS or Atom.
Core Components of the SAS Information Retrieval Studio Interface
Proxy Server – Controls the flow of documents pushed by the web or file and feed crawlers to the pipeline server. Functions like a pressure valve to maintain a steady movement of files fed by crawlers into the pipeline server.
Pipeline Server – Documents the flow into the pipeline server from the proxy server. The pipeline server performs actions such as parsing, modifying fields, analyzing content, etc., on the documents. It then passes them to either the indexing server or another SAS application. This is arguably the most important component of the SAS IR framework. It works like the heart for a human body. The main function of the heart is to purify and pump oxygenated blood to various parts of the body. Similarly, a pipeline server helps cleanse, parse, convert, extract, and pass meaningful content to various SAS applications for further processing.
Components of SAS Search and Indexing
Indexing Server – Builds an index of documents to help with searching them using the query server.
Query Server – Helps with searching the documents based on the index built using the indexing server.
Query Web Server – Hosts the query interface to help users search documents interactively.
Query Statistics Server – Monitor user search queries through the query web server.
Virtual Indexing Server* – Distributes documents across a set of multiple index segments and maintains them as if they are all under one single large index.
Virtual Query Serveri – Distributes the influx of user-submitted queries to several back-end query servers.
Other Important Components
SAS Markup Matcher Server – Helps you create custom templates to target specific sections of HTML web pages or XML files and to extract only the wanted content. For example, you can do a simple web crawl to extract the contents of articles posted on a blog site. However, web pages on blogs generally contain links to other sites, articles, advertisements, banners, and comments sections. As a result, you might end up retrieving additional unwanted content during the web crawl. The SAS Markup Matcher helps you control what you need to extract.
SAS Document Conversion Server – Document Conversion is an essential component of the IR process. It provides a means to convert documents in various file formats into individual TXT files. Documents in formats such as HTML, PDF, PPT, MS Word, etc., need to be normalized and converted to a common format that is understood by other SAS applications and the indexing server. This step is crucial in situations where a file crawl or a web crawl can potentially retrieve documents in one or more of these formats.
Web Crawler
A web crawler is a software program that traverses pages on the World Wide Web and leverages the embedded linkage structure through which web pages are interconnected. Web crawlers require a web page link to begin crawling (also known as a seed page or entry point).
A typical web crawler starts parsing a seed page and scans for links in the seed page that point to other web pages. The newly found pages are again searched, parsed, and scanned for links that point to other web pages. This process continues recursively until all links referenced in this way are searched and all links are collected. While parsing these web pages for links, the web crawler grabs the actual content from them and stores it as document files. These files are often passed to other programs that work in conjunction with web crawlers to build indexes based on the document files. These indexes are helpful in retrieving the information based on search queries entered by users. Parsing generally involves cleaning up HTML and other tags scattered across the source code of the crawled web pages. Display 2.2 shows how a typical web crawler works. In this scenario, the seed page references two hypertext links (Link 1 and Link 2). Each link points to web pages that refer to other links (for example, Page 1 refers to Links 3, 4, and 5, and Page 2 refers to Links 6 and 7).
Display 2.2: A Typical Web Crawler Traversing through Web Pages
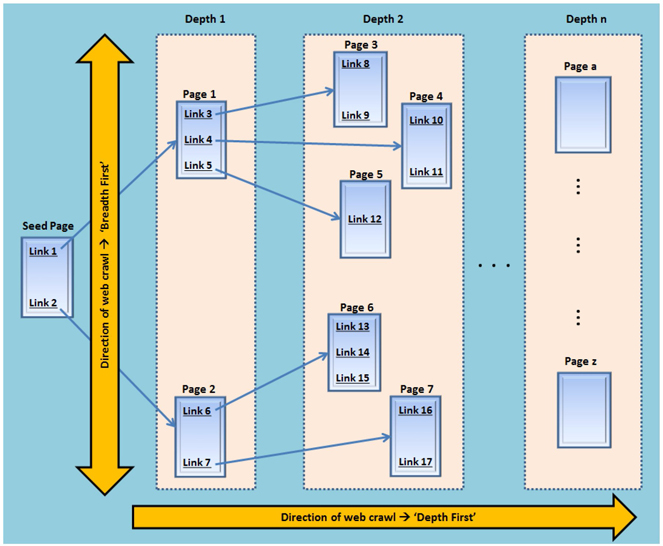
Link and Page: A link is nothing but a URL that acts as a pointer to a web page. When you click on a link, it retrieves the associated content from the web and displays it as a web page in a browser. Throughout this chapter, link n represents a reference to the web page n.
Child Page: All web pages that are linked to the seed page directly or indirectly through the linkage structure are considered child pages. In this example, any of the links shown in Display 2.2 can be reached by traversing through the links starting from the seed page. They are all child pages in this example.
Modes of Crawl: Primarily, there are two modes that represent the two different directions in which a web crawler can be guided to move through the linked list of web pages and to retrieve content.
Breadth First
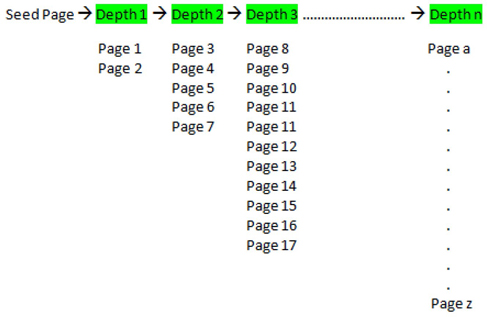
The breadth first direction guides the web crawler to search through all of the child pages at Depth 1 referenced by the seed page first. Then, it searches through all of the child pages at Depth 2 referenced by the pages in Depth 1. This process repeats until all of the child pages related to the seed page are completely crawled. In Display 2.2, in the breadth first mode, pages are searched starting with the Seed Page, Depth 1 (Pages 1 and 2), Depth 2 (Pages 3 through 7), and so on, crawling through all links at each depth before proceeding to the links at the next depth. Display 2.3 shows the web crawl path in breadth first mode for this current example.
Display 2.3: Traversing Path of a Web Crawler in Breadth First Mode
Depth First
The depth first option guides the crawler to select one link first, and then completely go through all of the child links following it, until the end. Once all of child links within this link are completely crawled, the control goes back to the next link, and follows all of its child links. In the current example, the depth first mode of crawl follows the path starting from Seed Page, Link 1 (Depth 1), Links 3 through 5 (Depth 2), Links 8 through 12 (Depth 3), and so on, until all of the child links for Link 1 are completely crawled. (See Display 2.4.) Once done, the control goes back to Link 2, and then recursively goes through its child links. As the depth of the crawling increases, the number of links to crawl exponentially increases regardless of the mode of crawling. Starting with version 12.1, the depth first option is not available in SAS Information Retrieval Studio and breadth first is used as the default method.
Display 2.4: Traversing Path of a Web Crawler in Depth First Mode
![]()
Though web crawlers are also known by several other names such as spiders, robots, worms, etc., implying they move physically, they neither execute nor migrate from one physical location to another. Unlike other categories of software programs such as viruses, crawlers do not spread across networks, but reside and run on one machine. A web crawler does nothing but automatically follow links, send page requests, and fetch required information hosted on machines over the Internet through a standard HTTP protocol.
SAS Web Crawler has many configurable settings and features that are covered in great detail in SAS Information Retrieval Studio: Administration Guide. We discuss some of the key features when we walk you through a step-by-step demonstration on how to conduct web crawling toward the end of this chapter.
Web Crawling: Real-World Applications and Examples
There are many real-world applications of using a web crawler. Almost all search engines such as Google, Bing, etc., use web crawlers to gather documents for building large indexes. Whenever a user submits a query to these search engines, the indexes are used to locate web pages with related information, and they are returned as a result of the search query. McCallum et al. used crawlers and built portals that were repositories of indexed research papers related to computer science. Site maps in a graphical layout can be developed by initiating a web crawl from the seed page going in the breadth first mode, and then connecting the related pages visually.
Lieberman et al. developed a browsing agent, which monitors the real-time browsing patterns of users, understands which links the user is spending time with, and tries to suggest more links that might be suitable for the user’s interests and needs.
The most prominent application of web crawling adapted by many companies in the contemporary business world is to crawl the competitors’ websites to collect information about their new products, future plans, investment strategies, etc. In the field of biomedical studies, researchers are often required to access huge volumes of literary content about genes. They deploy web crawling to gather gene-related information from various sources on the web. On a downside, a popular but rather litigious application of using web crawling is to extract the e-mail addresses of individuals from various websites and spam their inboxes with phishing e- mails. Through phishing, hackers can gain access to individual passwords, credit card information, or personally identifiable data.
File Crawler
A file crawler searches through the files or documents located physically on local disk storage or on a shared network. It then downloads these files to send them to the pipeline server for processing. The file crawler can grab content contained in document types such as PDF, HTML, Microsoft Word, XML, text files, etc. A document conversion process can be used to convert the data from these formats into raw text files. Remember to select Yes for the Encapsulate XML Files option if you are crawling HTML or XML files and to include a markup_matcher document processor in the pipeline server for normalizing the text in the files.
Feed Crawler
A feed crawler gathers information like news updates, weather updates, press releases, blog entries, etc., that are distributed on web feeds. It can gather either full text or a summary of the information. A feed crawler always pulls data from the web links found within the feeds, whereas a web crawler typically grabs content off standard web pages. Feeds are generally embedded as hyperlinks within web pages and sometimes users can confuse them with web pages. In the following subsections, we attempt to explain a feed, commonly used feed types in the industry, and a way to identify or distinguish them from web pages.
What Is a Feed?
A feed can be technically described as a mechanism to publish frequently updated information about websites. Feeds (also termed web feeds) are simply formatted documents on the web (often built in an XML file format) containing web links redirecting to the information sources that are added frequently at regular time periods. A software program called a feed reader (also called an aggregator) is required to read and pull information from these web feeds whenever they are updated with new information. A user can subscribe to a feed and monitor its updates from a web browser. Many browsers such as Internet Explorer and Google Chrome have built-in feed readers, which check the user-registered feeds for new posts and avoids the task of manually visiting all of the interested sites for information. SAS Feed Crawler in SAS Information Retrieval Studio performs the job of a feed reader and can be configured based on the user needs.
Types of Feeds
Primarily, there are two types of feeds based on their format and structure—RSS and Atom. RSS stands for RDF Site Summary and is nicknamed Really Simple Syndication. The SAS Information Retrieval Studio feed reader is capable of reading content from both RSS and Atom feeds. Feeds can be classified depending on the content. Full content and summary only are the two major categories of feeds. Full content (as the name implies) refers to feeds that contain all of the information that is needed. Summary-only feeds contain only a short summary of the actual content. You need to click on the link within the feed and navigate to the original web page where full information is available.
How to Identify Feeds?
Generally, feeds are found in the websites with an icon (![]() ) next to the URL pointing to them. Remember, feeds are not web pages. Exercise caution and check whether the URL that you provide in the tab is, indeed, a feed URL or a web page. For example, the web page http://www.sas.com/rss provides a comprehensive list of all SAS RSS feeds and their links. (See Display 2.5.)
) next to the URL pointing to them. Remember, feeds are not web pages. Exercise caution and check whether the URL that you provide in the tab is, indeed, a feed URL or a web page. For example, the web page http://www.sas.com/rss provides a comprehensive list of all SAS RSS feeds and their links. (See Display 2.5.)
Display 2.5: Partial Screen Capture of SAS RSS Feeds Web Page
Once you click on a link (for example, Media coverage), you can see the actual feed. This is a summary-only feed, and the links found here actually refer to the web pages of external media sites. You can click on a link to navigate to the web page that contains the full content of the news article. (See Display 2.6.)
Display 2.6: Partial Screen Capture of the SAS Media Coverage Feed

Understanding Core Component Servers
Now that you understand how the web, file, and feed crawlers can work independently to fetch data from various sources, look at the core component servers and their functionalities.
Proxy Server
The proxy server acts as an intermediary layer between the crawlers and the pipeline server. It receives documents from the crawlers and sends them to the pipeline server. The component proxy server that we are referencing should not be confused with the more traditional web proxy server. A web proxy server serves as a cache of web pages to help quickly retrieve the web content when a client residing locally requests a web page. The proxy server in SAS Information Retrieval Studio fundamentally serves two purposes:
a. Enables you to pause the flow of documents to the pipeline server. When paused, the incoming documents from the crawlers are queued until the proxy server is resumed. This is useful in situations where the pipeline server or other downstream servers require ad hoc changes (or maintenance work) without having to pause or stop the crawlers.
b. Facilitates the creation of multiple pipeline servers to which copies of documents coming in from the crawlers can be sent. Each of these servers runs simultaneously on different machines and provides support as a backup mechanism in case of emergencies such as hardware failure.
Pipeline Server
The pipeline server is a critical component in SAS Information Retrieval Studio used to perform actions on the incoming documents from the proxy server based on your needs. These actions can be defined by document processors. Document processors form the core components of the pipeline server and solve one or both of the following purposes:
a. Process documents into an appropriate form that is ready to be used by other SAS applications such as SAS Text Miner (to analyze trends) or SAS Sentiment Analysis Workbench (to analyze sentiment).
b. Send processed documents to another component of SAS Information Retrieval Studio such as an indexer to build indexes for these documents for information search and retrieval.
Document Processors
A document processor can be defined as a functional module designed to operate on documents to achieve the right result. The document processor can be used to execute simple text normalization tasks such as parsing documents, removing unwanted tags (for example, markup tags in HTML documents), modifying fields, exporting data in a different format (for example, exporting TXT file as CSV file), converting documents (for example, PDF to TXT), etc. Document processors can be used to perform tasks involving advanced semantic analysis such as content categorization, concept or factual extraction, etc. All of these tasks and a few more can be accomplished using the available set of prebuilt document processors provided with SAS Information Retrieval Studio. If the tasks involved are more complex, users can build their own custom processors.
Documents fed into the pipeline server go through at least one document processor before they are sent to other SAS applications or pushed to the indexing server. When more than one processor is required to act on the documents, you should exercise caution to ensure that the processors are in the proper order to obtain the right results. For example, a web crawler might gather HTML pages and send them to the pipeline server via the proxy server. First, these pages should be parsed using an appropriate document processor such as parse_html or heuristic_parse_html before exporting them to another SAS application. Adding processors in the wrong order might yield wrong results or stop the pipeline server in some cases. Each document passes through the pipeline server in a field-value pair format. A document can have many fields such as filename, body, ID, URL, etc. These fields form the metadata of the document, and actual content is assigned to the values for each of these fields. These fields can be configured for a prebuilt document processor when added to the pipeline server based on the requirements of users. Many prebuilt document processors are readily available with SAS Information Retrieval Studio to use in the pipeline server. Some of these processors are described in this section.
document_converter: Converts documents in sophisticated file formats such as PDF and MS Word into plain text documents using the SAS Document Conversion server.
extract_abstract: Creates an abstract extracting the first 25 to 50 words from the body of the incoming document. Useful to create summaries of scientific journals, technical papers, etc., where generally the abstract or introduction is placed at the beginning of the document.
heuristic_parse_html: Heuristically determines which sections of an HTML page can be ignored and which sections should be used to parse and extract the main content.
export_to_files: Creates a copy of the incoming documents into separate files. Files are named using a hash function, which converts the character strings in a document into values that are useful in indexing and searching.
Component Servers of SAS Search and Indexing
SAS Search and Indexing components fit into the overall architecture of the SAS Information Retrieval Studio framework.
Indexing Server
Index (as the term suggests) is similar to the index provided at the end of a book. The index in a book acts as a quick reference of all of the terms and points to the specific pages of the book in which they are found. Similarly, an index built in SAS Information Retrieval Studio is based on the data in the incoming documents from the pipeline server and the index helps quickly retrieve documents in which terms entered in the search query are found. This component in SAS Information Retrieval Studio helps build an index of the incoming documents to help in the information search and retrieval process. You might opt out of indexing if the documents collected using the crawlers are immediately sent to other SAS applications.
A document in the indexing server is in the field-value pair format. When documents in the pipeline server start flowing into the indexing server, fields are populated by matching similarly named fields. Though all the three crawlers might run simultaneously, passing documents to the indexing server via the pipeline server, it is possible to build only one index at a time. However, you can build indexes on various fields of the document. You might assign various predesigned functionalities to these fields to ensure that they are included in the search and query process. Choosing a specific functionality for a field controls the limitations for the types of queries that you can perform.
Another component in SAS Information Retrieval Studio, the query server, assists in returning the relevant information by executing user queries on indexed documents. You might perform customized searches via a user search interface that runs on a query web server. You might perform searches using either a term or a combination of terms. An intuitive search is possible if you assign the required fields with the functionality label. By default, English is the language used in building indexes. Regardless of the language selection, documents in any language are indexed; though, indexes are optimized for the language selected.
You should pay careful attention when building indexes because they are impacted by other components. Here are some of the caveats to consider whenever the indexing server is functional:
• The same documents are gathered by the crawlers when they are started, stopped, and restarted. Thus, duplicate documents might flow into the indexing server via the pipeline server. Each document indexed by the indexing server must have a unique identification field (ID), such as the URL of a web page. If two documents with the same ID are pushed to the indexing server, the document that comes in last overwrites the document that came in first, ensuring that only one copy of a unique document resides in the index.
• Whenever document processors in the pipeline server are modified when the indexing server is running, be sure to click Apply Changes located in the top pane.
• When configuration properties of the indexing server are modified, it does not change the existing index, but it does affect only the next index built. You can perform either of the two following options to remedy this situation:
∘ Delete the current index to allow the indexing server to build a new index with the modified properties whenever the crawlers are restarted.
∘ Click Apply Changes while the indexing server is still running. This deletes the current index and restarts the indexing server to build a new index.
Query Server
A query server takes the search query issued by the user, runs it against the document index previously built using the indexing server, and returns the matching documents as search results back to the user. You can execute these search queries using a query API in a custom-built program and pass the search queries to the query server. You also have the option to perform these searches and review returned results in an interactive query interface. This web application runs on another component of SAS Information Retrieval Studio called the query web server. Another component of SAS Information Retrieval Studio called the query statistics server can be used to monitor, measure, and analyze query metrics periodically such as the frequency of searches and hit rate. By default, the query server is running behind the scenes all the time. Unlike other components of SAS Information Retrieval Studio, there are no configurable settings on this server that a user can modify.
Query Web Server
The query web server lets you configure how the search results returned to the user should be displayed in the query interface. It helps you specify how documents should be matched against the search queries and sort results. It enables you to format labels, matched documents, and the theme of the search interface.
There are primarily two types of searches possible on the indexed documents in SAS Information Retrieval Studio:
Simple Search: In this format, you can specify the terms in a search query. They are used to look up in the index of documents and to return results in which they occur. Operators such as a plus (+) sign and a minus (-) sign can be used to either include or exclude a word or phrase in the search query. For example, a query like +sas -analytics submits a search on the index to return documents containing the term ‘sas’ but not when the term ‘analytics’ appears in the document.
Advanced Search: You can use the fields and search terms together in the query expression. It enables you to use Boolean, positional, and counting operators in combination with the search words or phrases. This method improves the quality of search by narrowing down to return the most relevant results. In this case, only those fields marked with a functionality of Search when building the index can be used. For example, a query like (AND, _body:”SAS”, _title:”analytics”) searches for the term ‘SAS’ in the body and ‘analytics’ in the title of the document. ‘AND’ is a Boolean operator whereas _body and _title are the markers for body and title fields of the document, respectively.
Query Statistics Server
This component can be used to analyze the patterns of user queries sent to the query server. The query statistics server helps you monitor the topmost submitted user queries by frequency. It also monitors which matches have been found in the indexed document repository. It lets you monitor monthly, daily, and hourly query rates.
SAS Markup Matcher Server
SAS Markup Matcher is a component provided within the SAS Information Retrieval Studio framework to help you create custom templates for accessing and extracting specific portions of an XML or HTML document. SAS Markup Matcher enables you to specify rules so that whenever an XML or HTML file is sent to it, it can create a new document and fields to add to that document. Once you define a matcher, you can upload it to the SAS Markup Matcher Server and add it to the pipeline server as a document processor. It applies the matcher rules to incoming documents. The output document generated by the SAS Markup Matcher can be either indexed or exported in XML or CSV file format. These output documents can be fed into other SAS applications such as SAS Text Miner, SAS Content Categorization, and SAS Sentiment Analysis to conduct further analysis as required. It is important to remember that the fields that are newly created by SAS Matchup Marker should be listed in the indexing server if you need to build indexes on those fields. In the later sections of this chapter, we demonstrate a simple scenario explaining how to use SAS Markup Matcher. We use this tool to define the rules required to perform guided search and information extraction from HTML web pages.
In the following sections, we demonstrate how you can leverage SAS Information Retrieval Studio to extract, parse, index, and search content in typical use case scenarios.
Scenario 1: Use SAS Web Crawler to extract, parse, and index content from a website and use simple searches to retrieve information.
1. Launch SAS Information Retrieval Studio on your web browser.
2. Click Projects in the top pane to open the Manage Projects window. Click New, and enter a name for the project, for example, SASCrawl. Click OK to create a new project. The newly created project appears in the list. Click Close.
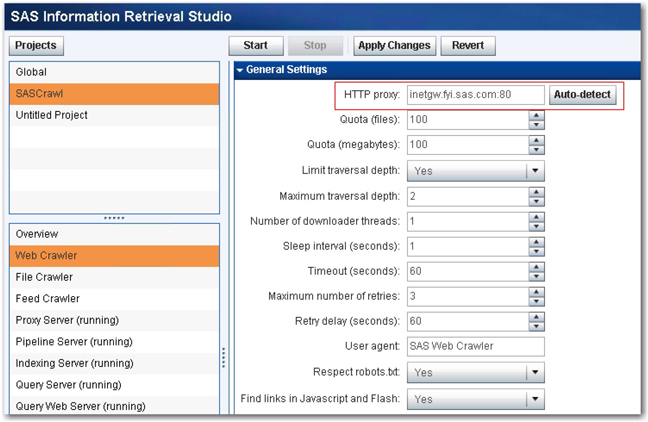
3. Select the newly created project, and click Web Crawler. Populate the fields for General Settings as shown. (See Display 2.7.) As highlighted in the display, you need to specify the HTTP proxy server to use for crawling. You can click Auto-detect to automatically show you the proxy server available in your environment.
Display 2.7: General Settings for SAS Web Crawler
4. In the Entry Points pane, click Add to open the Add Entry Point window. Enter the URL http://www.sas.com, and change the default value for Quota (files) to 100, and click OK. You see the entry point for crawling defined as shown in Display 2.8.
Display 2.8: Entry Points in SAS Web Crawler

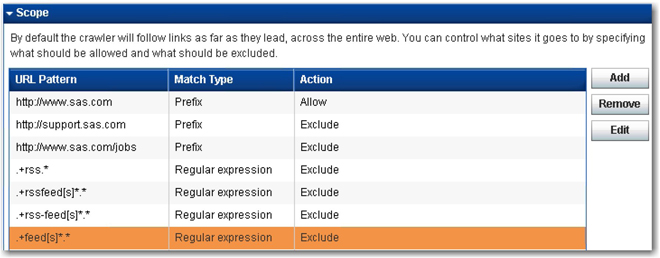
5. By default, the same URL is added to the scope. However, you can modify the scope of the web crawl to exclude certain links in the website. For example, you can choose to exclude support.sas.com, the SAS job portal, and RSS feeds from crawling. Click Add, and enter the URL patterns, match types, and action as shown in Display 2.9. Leave all other settings with their defaults in SAS Web Crawler. Click Apply Changes to make sure that all of the changes that you made are applied to the SAS Web Crawler.
Display 2.9: Configuration for Managing the Scope in SAS Web Crawler
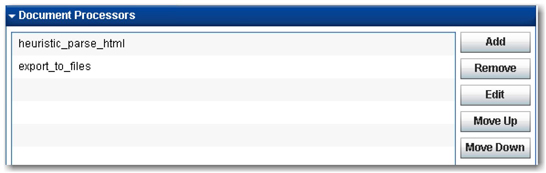
6. Click Pipeline Server from the left pane. Add some document processors to process the documents coming from SAS Web Crawler through the proxy server. Click Add, and select heuristic_parse_html from the list of available document processors. Click Next. Accept the default settings, and click Finish to add it to the queue.
7. Click Add, and select export-to-files from the list, and then click Next. Change the Export format to Plain Text, and the click Finish, leaving all others with default settings. You should have the two document processors added to the queue. (See Display 2.10.) Click Apply Changes to ensure that the changes that you made are applied to the server.
Display 2.10: Document Processors Added to the Pipeline Server
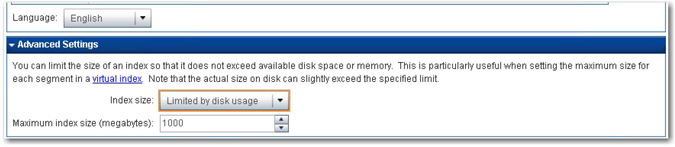
8. Click Indexing Server, and change the language to English under General Settings in Configuration. Expand the Advanced Settings, and select Limited by disk usage for Index size. Enter 1000 for Maximum index size (megabytes) to limit the size of the index and potentially avoid any disk space or memory errors. (See Display 2.11.) Click Apply Changes to restart the indexing server and allow the changes that you made to take effect.
Display 2.11: Language and Index Size Options in the Indexing Server
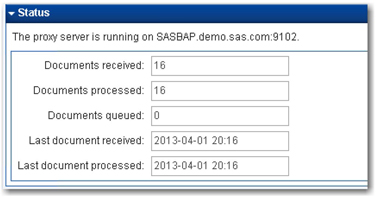
9. Leave all other options with default settings. Go back to the SAS Web Crawler. Click Start to start the SAS Web Crawler. You should notice the word “running” displayed next to the SAS Web Crawler indicating that web crawling is in progress. Click Proxy Server, and you should see that the documents are being pumped into the proxy server by the SAS Web Crawler. Simultaneously, documents are transferred to the next stage (i.e., to the pipeline server). (See Display 2.12.)
Display 2.12: Status Windows Showing Number of Documents Received and Processed by the Proxy Server
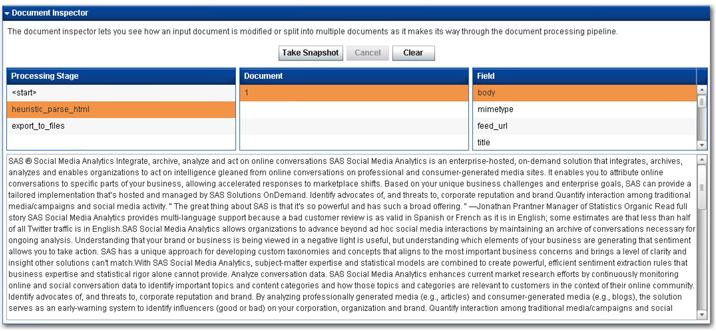
10. Go to the Pipeline Server, and click on heuristic_parse_html in the document processors. Click Take Snapshot under Document Inspector to check how the document content is modified at any given stage. Select heuristic_parse_html in Processing Stage, 1 in Document, and body in Field to view a snapshot of the parsed content from a web page at that point in time. (See Display 2.13.)
Display 2.13: Status Window Showing Number of Documents Received and Processed by the Proxy Server
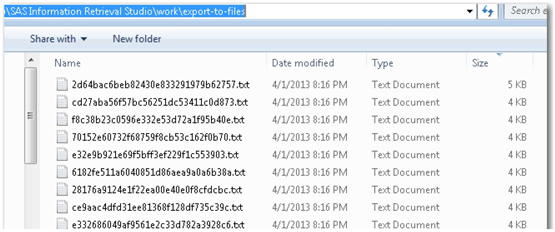
11. Because you have also used the export_to_files document processor in the pipeline server, each of the extracted and parsed documents are exported to the default location of workexport-to-files in the SAS Information Retrieval Studio installation path. You can navigate to that location on your machine and find those documents as raw text files. (See Display 2.14.) These files contain the body of web pages crawled after the heuristic_parse_html document processor has removed the unwanted HTML tags. These files can be used by other SAS applications such as SAS Text Miner for further analysis as required.
Display 2.14: Status Window Showing Number of Documents Received and Processed by the Proxy Server
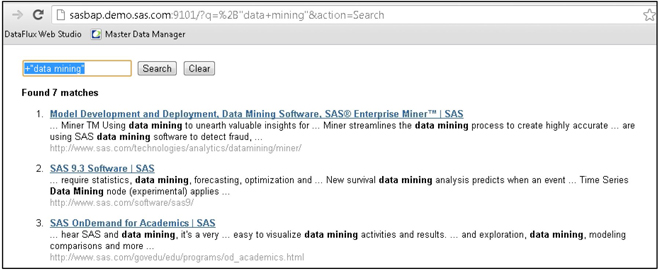
12. Launch the query web server on your browser. Go to the query web server and click on the URL provided in the Status window. You can also launch it by navigating to the SAS Information Retrieval Studio folder in your Start menu. Select Start ▸ All Programs ▸ SAS Information Retrieval Studio ▸ Query Interface. By default, the query web server enables you to do simple searches. If you search using the keyword “data mining” and using the inclusion operator (+), it returns all documents that have the term “data mining” in them. (See Display 2.15.)
Display 2.15: Partial Screen Capture of the Query Interface Displaying Search Results
13. In this scenario, you learned how content from web pages can be crawled, parsed, indexed, and searched within the SAS Information Retrieval Studio framework. This scenario is very simple and easy to follow. Often, you might require only specific contents of a website. In the next scenario, you will see a demonstration of how to accomplish this using custom templates.
Scenario 2: Use SAS Markup Matcher to extract, parse, and index content from specific fields of an HTML web page and export the content to CSV or XML file(s).
1. Click Global under Projects, and then click Markup Matcher Server. You should see the SAS Markup Matcher Server in running status. If not, start the server. Click Auto-detect under General Settings in Configuration, and select the HTTP proxy server available in your environment.
2. Click the URL provided in the Status window to launch the SAS Markup Matcher Server in a separate window on the browser.
3. In this example, you can use the web page http://www.allanalytics.com/archives.asp?blogs=yes, from which you can easily extract content from specific sections of the page into separate fields in a document. www.allanalytics.com is an online community sponsored by SAS for topics such as analytics, information management, and business intelligence. Users of this website post articles, blogs, and other resources related to any of these topics in general.
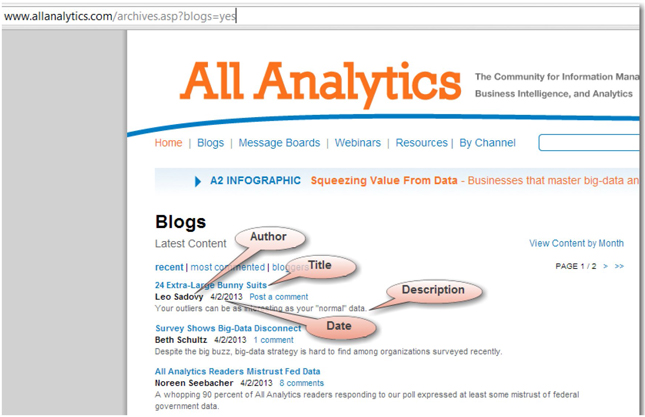
4. For this demonstration, you can simply use the blogs section of the website. See Display 2.16, which shows the blog archives from the website ordered by recent to oldest. As you can see, there are many blogs posted by various authors on different topics. Each topic has a title, name of the author, date on which it was published, and a brief description of what that article is all about. If you intend to perform web crawling on this web page similar to how you did in scenario 1, you will capture all of the content in a single document. However, all of these blog posts are different from one another. Hence, it makes sense to create a single document for each post, and then store the information in separate fields. You can create an XML file with tag elements representing the title, author, date, and description of the blog posts.
Display 2.16: Partial Screen Capture of www.allanalytics.com Web Page Listing Latest Blogs
5. In SAS Markup Matcher, select Testing ▸ Download Test Document to open a window. In that window, enter the URL http://www.allanalytics.com/archives.asp?blogs=yes as the address, and click OK. You will see that the HTML code of this web page is opened in the Test Document pane.
6. Click Edit ▸ Add Document Creation Rule to create a new document creation rule for the content that you are looking to extract from this web page. This creates a new document in the Rules folder in the Matcher pane. Enter the name “AllAnalyticsBlogs” in the Document Creation Rule pane. For this scenario, the XPath expression of the document rule is very important because it decides how many documents can be extracted.
7. Click Edit ▸ Add Field Creation Rule four times to create four fields for this document. Once you select each field in the Matcher pane, you will see the corresponding Field Creation Rule pane. Enter the names “Title,” “Author,” “Date,” and “Description” for these four fields, respectively.
8. Define the XPath expressions for these four fields using the HTML code of the web page that you imported into SAS Markup Matcher as a test document. To do this, you need to locate the first occurrence of the first blog title on the web page. From Display 2.16, you can see that 24 Extra-Large Bunny Suits is the first title listed on the page. Click Edit ▸ Find, and enter the following search term in the pop-up window—24 Extra-Large Bunny Suits. Click Next. It will take you to the section of the HTML page where this title appears for the first time.
9. Follow these steps for each of the four fields to create the XPath expressions:
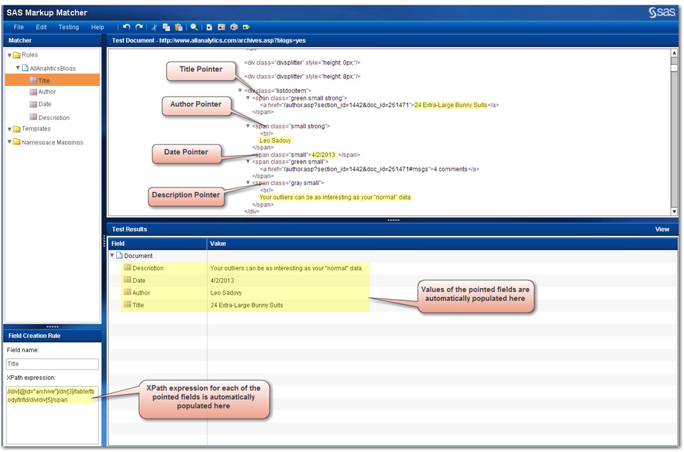
a. Move your pointer and highlight the specific HTML tag that contains the content. In this case, you need to click on the <span portion of the tag that encapsulates the content. (See Display 2.17.)
b. The XPath expression in the Field Creation Rule pane for that field should be populated automatically. (See Display 2.17.) If it is not automatically populated, then you must have either clicked on a wrong tag or a wrong field in the Test Document pane.
c. The value of the field in the Test Results pane should be automatically populated. (See Display 2.17.)
Display 2.17: Partial Screen Capture of www.allanalytics.com Web Page Listing Latest Blogs
10. By now, you should have created the XPath expressions for all the fields and verified that they are populating the test results accurately. Click File → Save Matcher to save the matcher that you have created.
11. Click File → Publish Matchers, and then click Upload to upload this matcher. Enter a new matcher name such as “AllAnalytics,” and click OK to finish uploading the matcher. The uploaded SAS Markup Matcher should be available within the markup_matcher document processor in the pipeline server.
12. Go back to the SAS Information Retrieval Studio interface, and click Projects. Create a new project named “AllAnalyticsCrawl.” Click the SAS Web Crawler, and change the following under General Settings, keeping the default values for everything else:
a. HTTP proxy: Use Auto-detect to find a proxy server that is local to your environment.
b. Quota (files): 100
c. Quota (megabytes): 100
d. Limit traversal depth: Yes
e. Maximum traversal depth: 2
f. Number of downloader threads: 1
g. Sleep interval (seconds): 1
h. Timeout (seconds): 60
i. Maximum number of retries: 3
j. Retry delay (seconds): 60
k. Find links in Javascript and Flash: Yes
13. Enter the URL http://www.allanalytics.com/archives.asp?blogs=yes as the entry point, and add the same URL in the Scope with a Match Type of Prefix and an Action of Allow. Change Quota (files) to 100 in the Entry Points section. Click Apply Changes to make sure the settings that you changed are saved for the web crawler.
14. Go to the pipeline server, and click Add to open the list of available document processors. From this list, select markup_matcher, and click Next. Provide the name of the matcher that you saved previously (AllAnalytics) in this window, and click Finish. You will see the markup_matcher document processor added to the pipeline server.
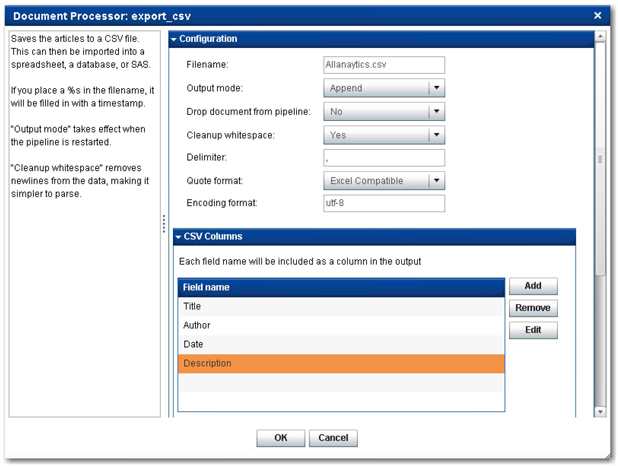
15. Now that you have the markup_matcher processor in place to extract only the relevant fields from the web pages, add another document processor, export_csv, to the pipeline server. In the Document Processor: export_csv window, make the following changes as shown in Display 2.18:
a. Filename: Allanalytics.csv
b. Drop document from pipeline
c. Edit the field names under CSV Columns to ensure that only the following fields are listed: Title, Author, Date, and Description. Click Finish.
16. Add another document processor, export_to_files, to the pipeline server. Under Configuration, make the following changes:
a. Document XML root tag: blogs
b. Drop document from pipeline: Yes
c. Add the following field names in the Included Fields pane to ensure that only these fields are listed: Title, Author, Date, and Description. Click Finish.
17. You should now have markup_matcher, export_csv, and export_to_files listed as document processors in the pipeline server (in that order). Click Apply Changes.
Display 2.18: export_csv Document Processor Configuration Window
18. The markup_matcher document processor parses the content on the web and extracts only the four specific fields that you defined in the matcher AllAnalytics. Both export_csv and export_to_files document processors should create the CSV and XML files with those four fields.
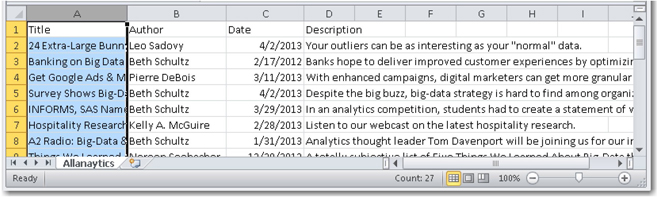
19. Go to the SAS Web Crawler, and click Start to start the web crawling process on the web pages. You should see the SAS Web Crawler in running status. Go to the proxy server and monitor the status of documents flowing through the proxy server into the pipeline server. Once the web crawler finishes, go to the SAS Information Retrieval Studio installation directory to find the AllAnalytics.csv file created with the extracted content. Open this file to see the four fields that you defined using the SAS Markup Matcher listed as different columns. Also, the values of the relevant fields are populated in the corresponding cells. (See Display 2.19.)
Display 2.19: CSV file Created by the export_csv Document Processor
20. In the workexport-to-files folder in the SAS Information Retrieval Studio installation path, you will find individual XML files created for each blog post separately. Select any one file, and open it in the XML editor to view the fields or values populated in the tag or element pairs. (See Display 2.20.)
Display 2.20: Snapshot of an XML File Created by export_to_files Document Processor
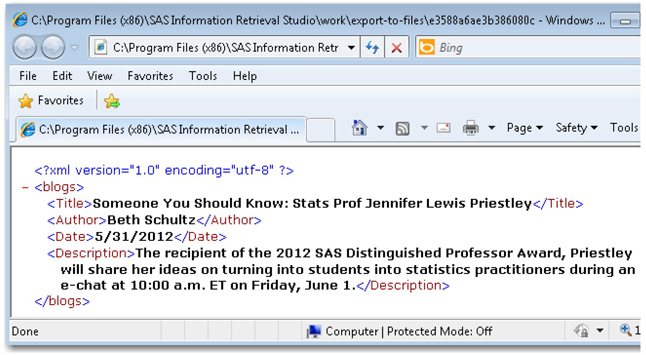
21. In Chapter 4, you will see how to easily use SAS XML Mapper or the SAS Text Miner Text Import node for mapping and exporting the fields or values in CSV or the tags or elements in XML to columns or rows in SAS data sets. Once the data is exported into a SAS data set, it can be used in SAS Text Miner for your analysis.
Note: You can view the logs for all of the server components in SAS Information Retrieval Studio with an option to highlight specific text of interest in the log data. Unless otherwise mentioned, it is important to remember that you should click Apply Changes in any server component to ensure that any changes made to the configuration settings are put into effect.
Summary
In this chapter, we showed you how to configure and use SAS Web Crawler and SAS Search and Indexing, configure some of the prebuilt document processors in the pipeline server, and build XPath expressions using SAS Markup Matcher for custom crawling. Using the integrated capabilities of these features, you can connect to any data source on the web or on your file share systems and grab content in a systematic and consistent way. In Case Study 7, we demonstrate how you can integrate content categorization and concept extraction in SAS Information Retrieval Studio to perform crawling, automatically classify documents, and extract facts or entities simultaneously. With this feature enabled, you can perform faceted searches on the indexed files and intuitively navigate through the search results. The SAS Information Retrieval Studio framework stands out as a key component to extract, parse, normalize, and manipulate data, which is a precursor to any text analysis exercise. In Chapter 3, we discuss how you can use either the file import functionality in SAS Text Miner or the %TMFILTER SAS macro to retrieve unstructured information from the web or from a local file system. These tools were primarily designed to gather data for the text mining process.
References
Blum, T., Keislar, D., Wheaton, J., and Wold, E. 1998. “Writing a Web Crawler in the Java Programming Language.” Muscle Fish LLC.
Gantz, J. and Reinsel, D. 2011. “Extracting Value from Chaos”. IDC iView, June 2011. Available at: http://www.emc.com/collateral/analyst-reports/idc-extracting-value-from-chaos-ar.pdf.
Lieberman, H., Fry, C., and Weitzman, L. 2001. “Exploring the Web with Reconnaissance Agents”. Communications of the ACM, 44(8): 69-75.
Manning, C. D., Raghavan, P., and Schutze, H. 2008. Introduction to Information Retrieval. New York, NY: Cambridge University Press.
McCallum, A. K., Nigam, K., Rennie, J., and Seymore. K. 2000. “Automating the Construction of Internet Portals with Machine Learning”. Information Retrieval. 3(2): 127-163.
Mearian, L. 2011. “World's Data Will Grow by 50X in Next Decade, IDC Study Predicts.” Computerworld, June 2011. Available at: http://www.computerworld.com/s/article/9217988/World_s_data_will_grow_by_50X_in_next_decade_IDC_study_predicts.
Mitchell, B. 2008. “UNC - Universal Naming Convention - Windows UNC.” About.com Guide: Wireless Networking. Available at: http://compnetworking.about.com/od/windowsnetworking/g/unc-name.htm.
Pant,G. and Menczer,F. 2003. “Topical Crawling for Business Intelligence”. Proceeding of 7th European Conference on Research and Advanced Technology for Digital Libraries (ECDL 2003). Trondheim, Norway, 2003.
Pant, G., Srinivasan, P., and Menczer, F. 2004. “Crawling the Web”. Web Dynamics: Adapting to Change in Content, Size, Topology and Use. New York: Springer-Verlag, 153–78.
SAS® Information Retrieval Studio, Release 12.1. Administrator’s Guide. Cary, NC: SAS Institute Inc.
SAS® Information Retrieval Studio, Release 12.1. User’s Guide. Cary, NC: SAS Institute Inc.
SAS® Information Retrieval Studio, Release 12.1. Quick Start Guide. Cary, NC: SAS Institute Inc.
Srinivasan, P., Mitchell, J., Bodenreider, O., Pant, G., and Menczer, F. 2002. “Web Crawling Agents for Retrieving Biomedical Information”. NETTAB 2002: Agents in Bioinformatics, Bologna, Italy, 2002.
i By default, the virtual indexing server and the virtual query server are not enabled. If they are turned on, they work hand in hand with back-end indexing servers and query servers to distribute the document load. Enabling these components can help improve the overall performance and optimal disk space or memory utilization of the system in cases where your crawling process can potentially retrieve documents in the range of a few petabytes or more by volume.