
Chapter 7 Content Management
Comparison of Statistical versus Rule-Based Categorizers
Determining Category Membership
SEQUENCE and PREDICATE_RULE Definitions
Automatic Generation of Categorization Rules Using SAS Text Miner
Differences between Text Clustering and Content Categorization
Introduction
In Chapter 2, we discussed how to extract content from a variety of data sources such as websites, blogs, feeds, local files, etc. In this chapter, we focus on how to organize and manage the data that we collect based on its content. Why is content management so important? Suppose that hundreds of paper documents or files are scattered across your desk. You have encountered a task that requires you to refer to a particular document, and you have absolutely no clue where that document is located in the heap. It means that you have to manually sift through all of the documents to find what you need. If you had chosen to organize all of your files in separate folders and labeled them accordingly, you could have saved a lot of time searching. The same goes for digital documents stored on your laptop or PC. You are always better off creating a folder structure that makes logical sense to you for storing your documents. This process is also called document classification. Document classification is often synonymously referred to as text classification or content categorization, indicating that we consider only the textual data in document content to perform classification. Objects such as images, graphics, or charts are ignored.
Many of us classify documents at our workplace. We typically maintain a manageable number of folders (less than 100), and the total number of documents generally does not exceed more than a few thousand. Assuming that you are the only person accessing your machine, this should be fairly easy to manage. Extend this case to a large enterprise where the total number of documents is a few hundreds of thousands or even in the millions. How about a folder structure with more than a hundred folders and subfolders? What if there were an incremental flow of new documents added to the shared repository each day? In a typical enterprise, there are many knowledge workers contributing to the development of shared document repositories at any given time. This compounds the problem of managing and organizing document content in those repositories. At this point, you would want to automate the process of document classification. Organizing documents on this scale requires a lot of thought, planning, and work. It might appear to be a simple task that you can do all by yourself, which might be true if you are the only person benefiting from it. However, in reality, many users need to benefit from this preclassified repository. As a result, the logical arrangement of the folder structure should be both meaningful and intuitive. This is the reason document classification has grown from being a simple administrative task to an amalgamation of both art and science.
In the context of document classification, the folder structure is called taxonomy and the folders and subfolders are called categories and subcategories, respectively. In large enterprises, it is not efficient to navigate back and forth through a huge folder structure to find documents of interest. It is worth mentioning that you can choose not to create a physical folder structure to organize your documents. All of your documents can be stored in one single storage location on a server. Instead of moving documents to folders, you can opt to simply tag all of your documents with the information of the categories and subcategories to which they belong. These tags form the documents’ metadata, and they are useful in the document search and retrieval process. The process of tagging documents is technically termed in literature as content tagging or document tagging.
If documents are stored in your company’s repository for your employees, but they are unable to find them, it can derail the progress of your workforce. Research studies show that the cost at an employee’s workforce of searching for a document and not finding it, in addition to the time and effort involved in creating a new document, add up to approximately 12 million United States dollars per 1,000 employees on average each year. Sometimes, the cost of not being able to find information can prove catastrophic. In a real-world example, a large pharmaceutical company failed to find a patent filed by a competitor that was related to a similar drug that it envisioned to develop. As a result, five years of precious time and money went straight into the gutter!
Applications
Organizations are increasingly showing interest in using text classification techniques for many business applications. Many media firms deploy document classification techniques to automatically categorize online news articles into various topics such as politics, business, science, sports, entertainment, etc. Spam filtering, automatic classification, and routing e-mails are well-known applications of text classification. Some websites monitor their users for the content that they are reading. These websites provide automatic suggestions with links to similar or related content. Many universities set up their online digital libraries and use abstracts or descriptions of articles, journals, and e-books to classify them into one or more categories. Automatic authorship attribution and identification of a document’s genre are some other classic cases of document classification techniques put into practice. In market research, open-ended responses or comments on a customer survey are automatically assigned predefined survey codes for a qualitative study of data using text classification algorithms. An interesting but complex problem, automatic essay grading revealed how text classification programs can be developed to score student-written essays as closely as human graders. Needless to say, scientific advances in machine learning, natural language processing, and statistical techniques laid strong foundations for the evolution of sophisticated text classification methods.
Content Categorization
Document classification (or content categorization as we refer to it for the remainder of this chapter) can be performed using SAS Content Categorization Studio. This tool offers two features, categorization and concept extraction, which are covered in great detail in this chapter. Content categorization (as the name implies) helps classify documents into a set of known subject areas or categories. Concept extraction helps extract important pieces of information from the documents called concepts. A concept can be the name of a person, place, organization, or event. A much more sophisticated feature, known as contextual extraction, is available if you obtain the Enterprise version of SAS Content Categorization Studio or install SAS Contextual Extraction Studio with SAS Content Categorization Studio. This feature incorporates the combined power of categories and concepts to extract complex factual information. The name of the president of a country, the date on which an article was published, etc., are examples of complex facts. The distinguishing features of contextual extraction compared to concept extraction are discussed later in this chapter. Throughout this chapter, we discuss the features and functionalities of SAS Content Categorization Studio based on version 12.1. Screenshots of features are subject to slight changes in later versions.
In Chapter 4, we showed you how standard entities such as date, currency, address, etc., can be extracted using SAS Text Miner. However, SAS Text Miner cannot extract custom entities and complex facts from documents. For example, Display 7.1 shows a SAS Global Forum paper abstract in which SAS Add-In for Microsoft Office (a complex fact) represents the name of a SAS software product. To extract the names of software products used in the paper abstracts, you must write concept definition rules to find patterns in the documents with SAS as the prefix. In Display 7.1, the terms highlighted in red (intelligence and dashboard) are closely related to the field of Business Intelligence. As a result, they are helpful in the content categorization process.
Before working in SAS Content Categorization Studio, the subject matter expert familiar with the document content should define the taxonomy structure and categories/sub-categories into which the documents can be classified. A well designed taxonomy will help the end-users to easily narrow down to the specific folder in which they are likely to find a document of their interest. SAS Content Categorization Studio helps to easily build such taxonomies to organize information (content categorization) and identify facts (concept extraction). For these purposes, SAS Content Categorization Studio uses several natural language processing and advanced linguistic techniques. In SAS Content Categorization Studio, you can develop rules for categories and concepts simultaneously, but in separate branches within the taxonomy.
Display 7.1: Screenshot of a SAS Global Forum Paper Abstract

The entire process of taxonomy generation and deployment in real time is shown in Display 7.2.
Display 7.2: High-Level Process Flow Diagram for Using SAS Content Categorization Studio and SAS Content Categorization Server
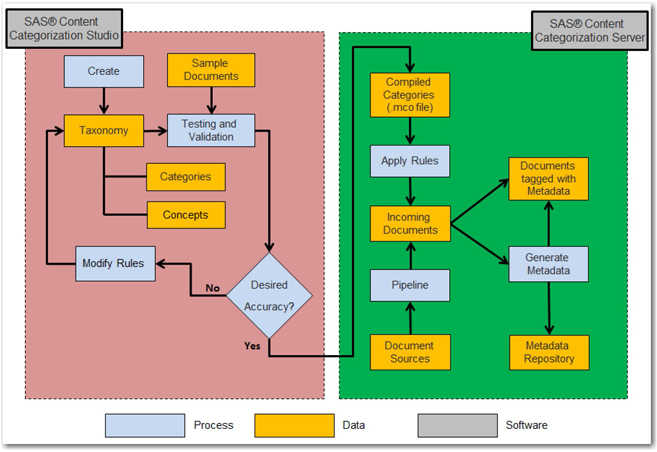
The developed taxonomy can be tested against a set of sample documents preclassified by category to verify the accuracy of classification. Taxonomy can be modified and tested again iteratively until the appropriate accuracy is achieved. Model accuracy is generally assessed by the means of two measures, recall and precision. In a given category, recall indicates the percentage of documents that are correctly classified. Precision indicates the percentage of documents that are correctly classified out of all of the documents classified in the current category. However, these two measures often affect one another, making it difficult to assess model performance. A third measure, traditionally known as F-measure (or F-score), can be used to test model accuracy. F-measure is the harmonic mean of precision and recall. It can be calculated using the following formula:
F-measure = 2 * (p * r)/(p + r) (Equation 7.1)
In this formula, p and r are the precision and recall measures of the model. The value of an F-measure ranges between 0 and 1. A higher value of the F-measure indicates a better classification model.
For the purpose of testing category and concept rules, you should collect a significant number of documents (around 10 to 20) representing each category in the taxonomy. It is important to include documents that shouldn’t match a category. This helps the taxonomist to efficiently write rules so that documents belonging to one category are less likely to be assigned to another category. For example, documents containing the word “plant” in the context of industrial equipment shouldn’t be matched with the term “neem plant,” which is a botanical term.
Once the taxonomy is finalized, you can generate the compiled files representing the rules of the categories (.mco) and concepts (.concepts). These files can be used in SAS Content Categorization Server to automatically apply rules to documents feeding from various data sources in real time. The output of this process is metadata information, such as document category and the facts found in the document. SAS Content Categorization Studio supports approximately 30 international languages and many document formats such as HTML, HTM, plain text, XML, RTF, SGML, and XLS. SAS Content Categorization Studio does not support PDF documents or the Microsoft Word format. Hence, you need to convert them to plain text documents using SAS Document Conversion. SAS Content Categorization Studio does not recognize SAS data sets as a data source (unlike SAS Text Miner). Hence, you should use raw documents in recognizable file formats to train and test the models built using SAS Content Categorization Studio.
Types of Taxonomy
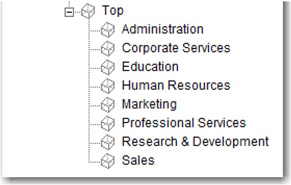
Taxonomy can be simple or complex and flat or hierarchical in its structure. In a flat taxonomy, all categories are at the same level in the taxonomy and there are no children or subcategories for any category. For example, the taxonomy in Display 7.3 represents the structure of various departments within a typical firm. All categories appear at the same level, and there are no dependencies—it is a flat taxonomy. In the project, you need to add a language such as English, and then enable a categorizer to start building the taxonomy.
Display 7.3: Example of a Flat Taxonomy
If one or more categories in the taxonomy contains a child or subcategory, it is a hierarchical taxonomy. The child categories can have children, leading to a nested category structure. Display 7.4 shows a partial screenshot of a sample hierarchical taxonomy in which the parent-child relationship between categories and their subcategories can be clearly understood.
Display 7.4: Example of a Hierarchical Taxonomy
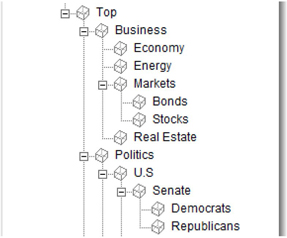
The categories Business and Politics are at the same level, and they have children or subcategories. The category U.S is the child of its parent Politics, Senate is the child of its parent U.S, and both Democrats and Republicans are children of their parent Senate.
Categorization
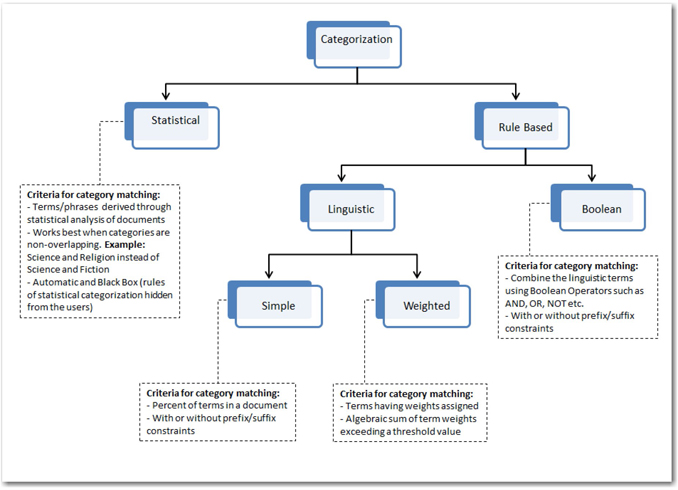
Categorization is the process in which documents are assigned to pre-identified categories or topic areas. Although the primary objective of the categorization process is to identify the topic area to which a document pertains, it is important to prevent classifying documents to incorrect categories. There are several methods of performing content categorization in SAS Content Categorization Studio. Display 7.5 shows these methods and how they differ from each other. Each method has its own pros and cons compared to the other methods.
Display 7.5: Hierarchy of Categorization Methods in SAS Content Categorization Studio
Training and Testing
Before diving deep into the details of these individual methods, you should understand what are training and testing documents. If you are using a set of documents to train or build the model, the documents are called the training set. If you are using a set of documents to test an already developed or built model, the documents are called the testing set. Both training and testing document sets are required for developing statistical models in SAS Content Categorization Studio. You should organize these documents in separate folder structures reflecting the hierarchy of the taxonomy. If you do not have the folder structures already created, you can create them automatically. To do this, provide the physical path for the testing directory and training directory on the Data tab. (See Display 7.6.) Click Propagate with the Create Folders option checked in the Propagate Options. Physical folders reflecting the hierarchy of the taxonomy are created on the storage drive. You can place the relevant documents in the appropriate folders for training or testing.
Display 7.6: Testing and Training Paths for a Category
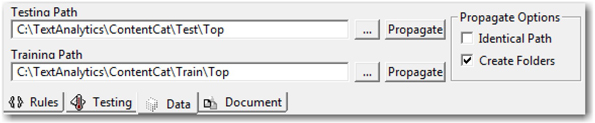
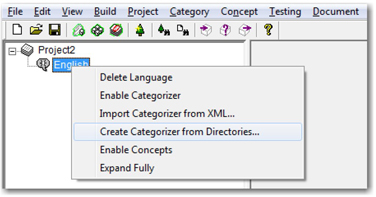
Rule-based categorizers do not require training documents, so you can skip setting the training path. If you like to place documents from all categories and subcategories in only one folder, then check Identical Path in Propagate Options. Conversely, you can create a taxonomy using an existing folder structure on your physical drive. Right-click English, and select Create Categorizer from Directories.
Display 7.7: Defining a Categorizer from an Existing Folder Structure
Statistical Categorizer
A statistical categorizer helps users automatically build a model for categorization without having to write any rules. It requires a set of documents pre-identified for each category in the taxonomy to train the model. When training the model for a particular category, documents from all categories in the taxonomy are considered for analysis. A statistical categorizer tries to find uniquely identifiable terms that describe a category while making sure they do not match any other categories. As a result, any changes made to the training documents in any category impact the rules for other categories also. In this case, you need to rebuild the model. Once the model is trained, you can test it on other document to verify its accuracy. The underlying rules of a statistical categorizer cannot be viewed. This is why it is also called a black box model. The statistical categorizer performs well when the number of categories is limited and the categories are significantly different from each other with regard to their content. For example, if the categories are sports, media, events, and entertainment, the statistical categorizer might not be efficient in categorizing documents precisely. The biggest advantage of a statistical model is that it is the easiest to develop, requiring just a set of well-collected training documents. However, due to the difficulty of matching concepts on the basis of a statistical measure, it is difficult to achieve a high level of accuracy, which is a major drawback for the statistical categorizer.
Here is a brief demonstration on how to build a statistical categorizer-based model. For the statistical categorizer, you need a training set of documents to build the model. For this purpose, we have extracted 466 SAS Global Forum paper abstracts published in the past three years from five different sections. Stats (Statistics and Data Analysis), DataMining (Data Mining and Predictive Modeling), Reports (Reporting and Information Visualization), BusInt (Business Intelligence), and SysArch (Systems Architecture) are the five section categories representing the 466 paper abstracts. These abstracts are split into Test and Train groups. Each group folder contains subfolders representing the five section-based categories and respective paper abstracts in raw files. SAS Content Categorization Studio requires input textual comments in .xml or .txt format. If you have your textual data as a SAS data set, you need to create a unique .xml or .txt file for each textual comment in your data set. Refer to the section “Appendix” in this chapter for SAS code that creates each observation in the SAS data set as a separate text file.
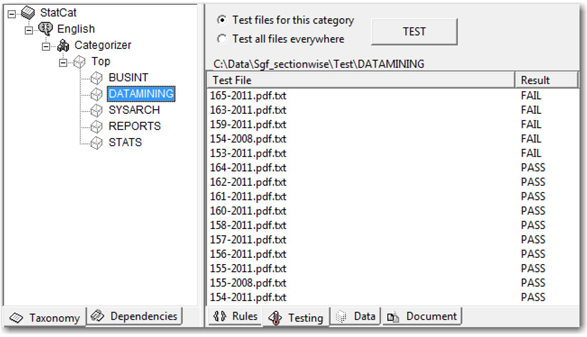
Create a new project in SAS Content Categorization Studio, enable the statistical categorizer, and create these five categories with the same names. Click the Top node in the categorizer, set the Training Path on the Data tab, and point it to the Train folder. Deselect any Propagate Options, and click Propagate next to Training Path. Now, the training paths of all categories automatically point to the specific folders containing the paper abstracts in text files. Similarly, set the Testing Path in the Top node, and propagate the testing paths to all of the categories. After both the testing and training paths are set up, select Build ▸ Build Statistical Categorizer to build the statistical model. After the successful completion of the build, you will see the Build Successful window. Select the DATAMINING category, and click the Testing tab to see all of the files available to test the statistical model. Click Test to see which documents have failed and which have passed the test.
Display 7.8: Test Results for DataMining Category in the Statistical Categorizer
Automatic Rule Generation
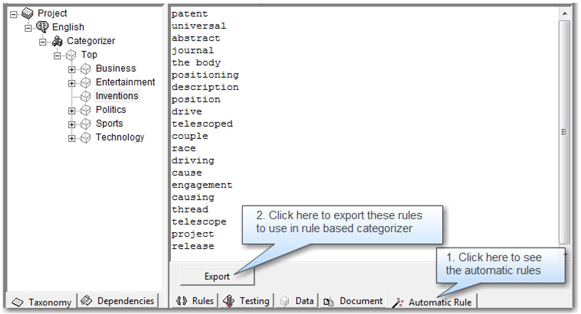
Automatic rule generation is a powerful feature offered in SAS Content Categorization Studio to automatically generate a list of terms that describe a category based on a training set of documents. The rules derived using this process are called “unqualified linguistic rules.” This process helps as a precursor to rule-based categorization. You can export the automatic rules generated into a rule-based categorizer, and then modify them for each category. For example, suppose that you have a need to automatically generate rules for the category Inventions. Place all of the documents related to this category in a single folder on your system, and specify the path to that folder as the Training Path on the Data tab for the Inventions category. Once the training path is set, click Generate Rules Automatically in the Category menu. Display 7.9 shows the two steps involved in this process.
Display 7.9: Automatic Rule Generation in SAS Content Categorization Studio

Rule terms and phrases that might describe this category are derived based on the statistical analysis of the training documents. (See Display 7.10.) These rule terms and phrases can be exported as rules in the first step to build a rule-based categorizer. Generally, automatically generated rules do not work well if they are used in the rule-based categorizer without any changes. Add a qualifier, assign weights, or use Boolean operators to refine the rules and build a better performing model.
By default, the automatic rule generation feature uses the frequent phrase extraction algorithm to derive the most frequent words or phrases in the training documents. You can change the option to use the maximum entropy classifiers algorithm, which generates words or phrases that are most meaningful for the selected category and are different from the other categories. Select Project ▸ Settings, and click the Rule Generation tab to change the algorithm. Using this feature, you can either generate weighted linguistic rules or Boolean rules automatically. This feature is efficient when you have training documents for all other categories or subcategories within the taxonomy.
Display 7.10: Example Showing Terms Derived by the Automatic Rule Generation Feature
Rule-Based Categorizer
A rule-based categorizer enables you to write your own rules for each category or subcategory in the taxonomy. Unlike the statistical categorizer, you can control the rules for each category individually independent of other categories. In fact, you can start writing rules for a category without the need for training documents. However, you need to have sample documents for each category in the taxonomy for testing the rule-based categorizer. As shown in Display 7.5, there are fundamentally two types of rule-based methods, linguistic and Boolean.
Linguistic
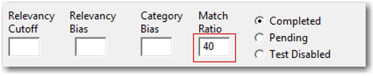
In the linguistic approach, rules use terms (word or phrases) that might uniquely represent a category in the taxonomy. In a simple linguistic method, a document is assigned to a category when a certain percentage of the rules is found in the document. For example, consider the category Inventions in Display 7.10, which contains 20 linguistic rules. If you set 40% as the matching criteria percentage, then a document is assigned to this category only when at least eight of the 20 rules are found in that document. This threshold percentage for linguistic rules is called the Match Ratio, and it can be set for each category individually on the Data tab (s shown in Display 7.11). By default, the match ratio for any category is 10%. A higher percentage might make the rules very rigid in assigning a document to a category. A lower percentage indicates that the rules are too liberal, which can cause a document to be assigned to more than one category. It is important to find an optimal value through thorough testing.
Display 7.11: Setting for Match Ratio on the Data Tab of a Category
Rule terms can be modified using qualifiers. A qualifier is a special symbol that, when syntactically applied to a linguistic rule, performs a specific function (most of which is related to natural language processing). For example, a linguistic rule named “position,” when suffixed with a qualifier @V and changed to position@V, expands the term “position” to include all of its verb forms in the category rules. Thus, the following terms are included as part of the rules automatically generated during the execution of the classification algorithm:
position
positioned
positioning
positions
In a weighted linguistic approach, rules are assigned different weights. A document is assigned to a particular category if the algebraic sum of the term weights exceeds a threshold value set for that category. You must follow a specific syntax to write these rules, and these rules cannot be mixed with either Boolean or simple linguistic rules within a category. The first line in this type of category should begin with two underscores and the keyword “THRESHOLD,” followed by a comma and a threshold value.
__THRESHOLD,value
Also, each of the following lines should have a linguistic rule and a weight separated by a comma without any spaces. For example, linguistic rules in the subcategory Football are assigned different weights. (See Display 7.12.)
Display 7.12: Example of Weighted Linguistic Rules for a Category
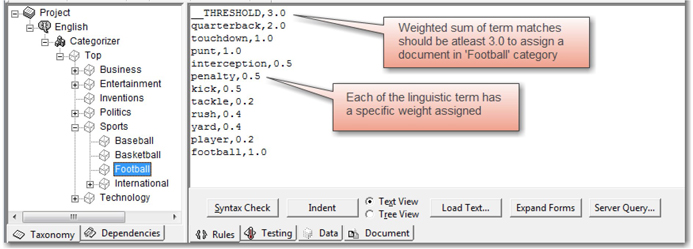
A threshold value of 3.0 is assigned for this category in the first line of the rules. The terms “quarterback,” “touchdown,” and “football” are assigned higher weights in this category because they are closely affiliated to football. “Kick,” “penalty,” “tackle,” and “yard” are assigned lower weights because these terms are not specific to football and can also be associated with another sport such as soccer. Select Build ▸ Build Rulebased Categorizer to compile the rules before testing them on sample documents. If there are any syntax errors in the rules written, the categorizer fails to compile the rules, and errors are displayed at the bottom of the window. You need to fix the errors before building the categorizer. When you test the rules against a sample document, the relevancy score for the category is calculated as follows:
Weighted Linguistic Rule Relevancy Score
In this formula, N is the number of weighted linguistic rules defined in the category, n is the frequency of occurrence for the ith rule in the document, and W is the weight of the ith rule defined in the category.
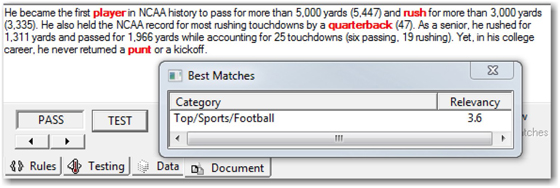
A document is assigned to this category if the calculated relevancy score is higher than the threshold value set for this category. Using the previous formula, the relevancy score is calculated for a sample text document. You can see the rule matches highlighted in red. (See Display 7.13.) The following equation shows how the relevancy score is generated for this document when tested against the Football category.
1*0.2(player) + 1*2.0(quarterback) + 1*0.4(rush) + 1*1.0 (punt) = 3.6
Display 7.13: Example Showing How the Relevancy Score Is Calculated for the Weighted Linguistic Rule-Based Category
Boolean
A Boolean rule-based categorizer enables you to join linguistic terms using Boolean operators such as AND, OR, NOT, etc. This method provides the ability to write precise rules to disambiguate between the same words that might occur in different contexts. The result of a Boolean rule expression is always either true or false, indicating whether it has found a match in the document. This method is the most powerful of all categorization techniques available in SAS Content Categorization Studio. It often yields better results compared to all other methods. Boolean rules are the hardest to develop because they require the most sophisticated human effort.
You can create symbolic links to refer to a category in the Boolean rules of another category. This mechanism proves efficient when you have a subcategory that should include the Boolean rules defined in its parent category. You can incorporate concept definitions in Boolean rules if they are defined within the same taxonomy. Similar to a linguistic rule, a Boolean rule allows for the modification of terms using qualifiers. Boolean rules are effective in finding matches in a structured document such as XML, where text data can be embedded inside tags. You can explicitly mention in the rules exactly where to look for the rule terms, such as in the body or title of the file.
Boolean rules follow a specific syntax and structure. They always start with a Boolean operator, followed by one or more arguments. You can either choose to write rules manually in the prescribed syntax or to use the point-and-click interface to add the operators and arguments without having to remember the syntax. To use the point-and-click interface, change the rules window mode from Text View to Tree View on the Rules tab. (See Display 7.14.)
Display 7.14: Text View and Tree View Options on the Rules Tab

The structure of Boolean rules facilitates the conditional matching of words or phrases. Rules can be defined to match categories with the occurrence of a term in the presence or absence of one or more terms. There are several types of Boolean operators available in SAS Content Categorization Studio. The biggest advantage of Boolean rule-based categorization is disambiguation. The same word can mean different things when applied in different contexts. For example, consider the word “poker.” Poker is a well-known card game in which each player places bets, claiming to hold high-ranking cards. However, “poker” could mean a metal rod used to stir a fire in a fireplace. Linguistic rules are not capable of handling this scenario. Boolean rules can help you disambiguate the contexts when these types of words appear in documents. To distinguish between the two contexts, you can write Boolean rules in the categorizer to look for closely related words in the proximity of the word “poker” as a game. (See Display 7.15.)
Display 7.15: Example of a Boolean Rule-Based Category
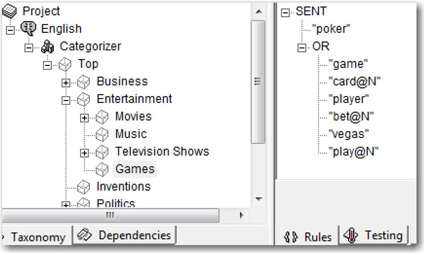
This rule indicates a category match if the word “poker” appears in the same sentence with at least one of the following words: “game,” “card,” “cards,” “player,” “bet,” “bets,” “Vegas,” “play,” or “plays.” The qualifying suffix @N indicates noun stemming. Hence, all noun forms of the qualified word are included in the rule. Click Expand forms on the Rules tab, and select Text View to see the completely resolved rule.
(SENT,“poker”,(OR,“game”,(OR,“card”,“cards”),“player”,(OR,“bet”,“bets”),“vegas”,(OR,“play”,“plays”)))
Comparison of Statistical versus Rule-Based Categorizers
Now that you have a better understanding of statistical and rule-based categorizers, let’s review the distinguishing features between these two methods. Table 7.1 lists the important differences between these methods at a high level to help you understand which method to use if you need to develop a categorization model at your workplace.
Table 7.1: Differences between Statistical and Rule-Based Categorizers
| Statistical Categorizer | Rule-Based Categorizer |
| • Fast and easy to develop. | • Demands significant amount of time and human effort to build. |
| • Requires a set of training documents to build model and a set of testing documents for validating model performance. | • No need for training documents. However, a sample set of documents for each category helps validate the rules. |
| • Often less accurate. | • Usually yields higher model accuracy compared to statistical models. |
| • Hard to interpret because you cannot view the underlying rules of a statistical model. | • Rules are available and easy to interpret. |
| • Works well when document content is very similar within a category and vastly different between categories. | • Boolean rules can help disambiguate contexts in places where the same concept term with different meanings can appear in the document. This approach makes the categorization process efficient in handling categories that might contain overlapping content. |
| • Cannot develop models for categories separately as you add them to the taxonomy. The statistical categorizer uses all documents in the training set of all categories simultaneously when building a model. | • Can develop models for each category separately, independent of other categories. |
Determining Category Membership
Earlier in this chapter, we discussed how match ratio plays an important role in assigning categories to documents based on linguistic rules. There could be a scenario where a document might be qualified for more than one category based on the match ratio. In this case, the best matching category is determined using another criterion, relevancy type. There are three choices of relevancy type in SAS Content Categorization Studio: operator-based (default), frequency-based, and zone-based.
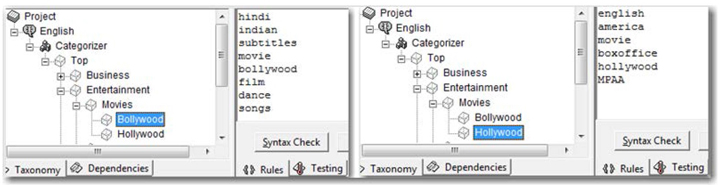
A frequency-based relevancy type is based on the number of rule matches in the document. The category for which the document gets the highest score is the best match. For example, consider two linguistic rule-based subcategories. They are Bollywood (eight terms and a match ratio of 25%) and Hollywood (six terms and a match ratio of 50%) in the category Movies (as shown in Display 7.16). The minimum number of terms required for a match to Bollywood is 2 (25% * 8), and 3 (50% * 6) for Hollywood. If a document surpasses the minimum number for both of these categories, the relevancy score helps in breaking the tie to determine which category needs to be assigned to the document.
Display 7.16: Examples of Simple Linguistic Rule-Based Categories
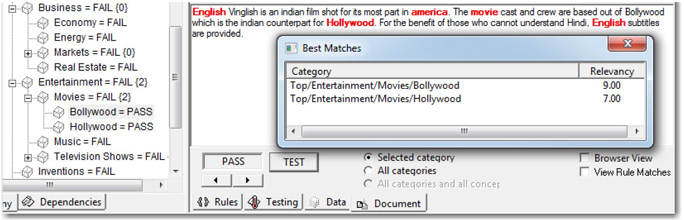
A sample movie review passed the test for both of these categories based on the match ratio. (See Display 7.17.) However, it is assigned to the category Bollywood based on the relevancy score. It is important to choose the frequency-based relevancy type by selecting Project ▸ Settings for this to work.
Display 7.17: Example Showing Role of Match Ratio in Assigning a Category
For the zone-based relevancy type, the entire document is divided into three equal segments. A document is scanned for any rule matches in all three segments. If the first segment has a match with any of the category rules, it gets a high weight. If a match occurs in the third segment, it gets a low weight. The rationale behind this approach is that whenever rule terms representing a category are found in the beginning sentences of a document, the probability that the document actually belongs to the category is high. If the rule terms are found in the last part of the document, there is a very low chance that the document belongs to the category. In this case, the rule terms might have occurred in the document in reference to some other document or in a different context altogether. This relevancy type might not be the most suitable for all types of data, but it generally works well for categorizing journals, news articles, etc.
The operator-based relevancy type boosts the weight of Boolean rules that have greater coverage of the document content. Although the operator-based relevancy type is most suitable for Boolean rules, it also works for linguistic rules. There are a few other factors such as relevancy cutoff, relevancy bias, and category bias that can influence relevancy calculations. Relevancy cutoff is the minimum threshold that the relevancy score must meet in order for a document to be matched against a category. This cutoff can be specified for all categories in the project settings or specifically for each category separately on the Data tab. By default, its value is 0. If a document passes for a match based on the match ratio, but fails to meet the relevancy cutoff, it is branded as conditionally passed. Relevancy bias helps in boosting the relevancy of one category over other categories in the case where the occurrence of certain terms in a document can provide enough credibility to unequivocally decide its category membership. The default value for relevancy bias is 1. Similarly, category bias boosts the relevancy of one or more categories of an entire taxonomy to help in the information retrieval process to return the most relevant information. The primary difference between relevancy bias and category bias is that the former relies on the key terms of a category, and the latter gives more credibility to the categories of a particular taxonomy compared to the categories of other taxonomies.
New Relevancy = (Relevancy Score * Relevancy Bias) + (Default Category Bias * Category Bias)
The default category bias in the project settings is 0. Hence, if you want to use category bias for categories to influence the relevancy score, you need to ensure that the default category bias in the project settings is changed to a nonzero value.
Concept Extraction
Concept extraction involves the process of identifying and extracting valuable bits of information (or concepts) from text document collections. Concepts can be interesting pieces of information such as the names of entities. Commonly known entities of interest are people, places, events, organizations, etc. Similar to categories, concepts are defined in SAS Content Categorization Studio in a taxonomy structure that can be either flat (concepts only) or hierarchical (concepts and subconcepts). Concept definitions in SAS Content Categorization Studio can be broadly classified into two types: classifier and grammar.
Classifiers
Classifiers are either literal strings or regular expressions. A literal string is a word or phrase representing the name of an entity. Classifier definitions should contain a match string followed by a mandatory comma. It can have a return string after the comma as follows: below.
match_string_literal,<return_string>
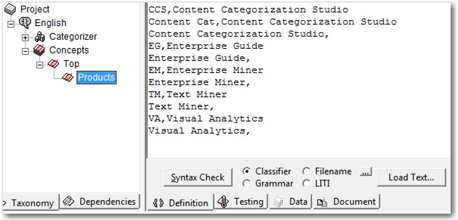
For example, a concept is defined with a series of literals indicating some key SAS products. (See Display 7.18.) A few of these classifier definitions do not have return strings. Classifier concept definitions work only when you select Classifier on the Definition tab.
Display 7.18: Example of Classifier Concept Definition
When tested against a sample text file containing information about some of these products, three classifier definitions are detected and highlighted in red (as shown in Display 7.19). Two of the matched strings, “enterprise miner” and “eg,” are not exactly defined in the same case in the concept definition. Matching is possible only when you select Case Insensitive Matching on the Data tab for this concept. You can choose to make this the default option for the entire project. In that case, this setting applies to all concepts defined in this taxonomy. The compiled concepts binary file can be used in SAS Content Categorization Server to retrieve the return strings in the results when a match is found in the documents.
Display 7.19: Example Showing Concept Matching with Case Insensitive Matching

You can use the built-in disambiguation operators within the concept definitions to match concepts identified in a suitable context of interest. __TGIF is the disambiguation operator that returns a match only if the Boolean rule followed by this operator is true. __TGUNLESS works exactly the opposite way. It returns a match only if the Boolean rule followed by this operator is false. The syntax structure is in the following format:
match_string_literal,X:{Y}:<return_string>
In this format, X is either __TGIF or __TGUNLESS and Y is any Boolean rule in the syntax required by SAS Content Categorization Studio.
For example, you can disambiguate between the terms poker game and poker tool in the concept definition for the classifier concept Game. (See Display 7.20.) Boolean rules can include terms such as card, game, play, and deck to co-occur with poker in the document to return a match.
Display 7.20: Example Showing Use of Disambiguation Operator in Classifier Concept

Regular Expressions
Regular expressions are used when you know the possible patterns in which you might be able to find the concepts. Examples could be phone number, SSN, website address, e-mail address, etc. The rule-writing syntax is similar to the regular expressions that you write in any scripting language such as Perl, Java, or C#. If you are not familiar with regular expressions, refer to a good online guide such as http://www.regular-expressions.info/reference.html. You can find detailed notes on how to write regular expressions in the SAS Content Categorization Studio 12.1: User’s Guide.
Concept definitions using regular expressions should have the keyword __REGEX__ in its first line for the compiler to understand. Here are some example regular expressions to match several formats of a date concept that you commonly see in documents. You can use the special character # at the beginning of a line to indicate it is a comment, not a rule.
__REGEX__
# Example: January 10, 2004,
Januarys*[0-9,]*s*20[0-1]{1}[0-9]{1},
# Example: Jan. 10, 2004,
Jan[.]*s+[0-9,]*s*20[0-1]{1}[0-9]{1},
# Example: 10, Jan 2004,
[0-9,]*s*Jan[a-zA-Z]*s*20[0-1]{1}[0-9]{1},
# Example: Jan. 09,
Jan[.]*s+[0-9]*[0-9][,]*s*,
# Example: Jan. 9th, 2004,
Jan[.]*s*[0-9]+[ndrhst]{2}[,.]*s*20[0-1]{1}[0-9]{1},
# Example: January. 9th, 2004,
January[.]*s*[0-9]+[ndrhst]{2}[,.]*s*20[0-1]{1}[0-9]{1},
# Example: 01-10-2009,
[0-1]{0,1}[0-2]{1}-[0-3]{0,1}[0-9]{1}-[1-2]{1}[0-9]{1}[0-9]{1}[0-9]{1},
[0-1]{0,1}[0-2]{1}/[0-3]{0,1}[0-9]{1}/[1-2]{1}[0-9]{1}[0-9]{1}[0-9]{1},
[0-3]{0,1}[0-9]{1}-[0-1]{0,1}[0-2]{1}-[1-2]{1}[0-9]{1}[0-9]{1}[0-9]{1},
[0-3]{0,1}[0-9]{1}/[0-1]{0,1}[0-2]{1}/[1-2]{1}[0-9]{1}[0-9]{1}[0-9]{1},
# Example: yyyy-mm-dd,
20[0-1]{1}[0-9]{1}-[01]{0,1}[0-9]{2}-[0123]{0,1}[0-9]{1},
20[0-1]{1}[0-9]{1}-[0123]{0,1}[0-9]{2}-[01]{0,1}[0-9]{1},
20[0-1]{1}[0-9]{1}/[01]{0,1}[0-9]{2}/[0123]{0,1}[0-9]{1},
20[0-1]{1}[0-9]{1}/[0123]{0,1}[0-9]{2}/[01]{0,1}[0-9]{1},
# Example: in 2009,
ins*20[0-1]{1}[0-9]{1},
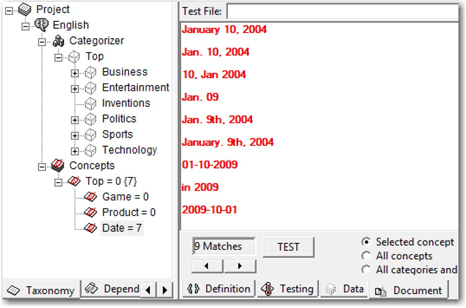
Once you compile these concepts, test the rules to verify whether there were any logical mistakes that you made when writing the rules. If the rules are precise, matches found during the testing process are highlighted in red. (See Display 7.21.) It is highly recommended that you include a wide range of concept formats in the test document section and thoroughly test them. By doing this, over a period of time, you can end up with a very good compilation of rules that cover most formats of a concept.
Display 7.21: Example Showing Test Results of Concepts Written Using Regular Expressions
Grammar
Using grammar concept definitions, you can specify parts of speech or use wildcard search rules to match any term. Select Grammar on the Definitions tab to write grammar concept definitions. The wildcard search symbols #w and #cap identify any words and words that begin with an uppercase letter, respectively. For example, some SAS products such as SAS Enterprise Guide, SAS Enterprise Miner, etc., can be identified by writing a match rule like the following:
#ROOT=*SASConcept
*SASConcept=SAS #cap #cap
All grammar rules should have the format #ROOT=*<ConceptName> in its first line. Part-of-speech tags can be used to capture words or phrases used with a specific sequence in a sentence. For example, the following concept definition is capable of identifying a match when the sentence contains a phrase such as “exceptionally brilliant” or “charmingly intelligent” that follows the specific sequence of an adverb followed by an adjective (:A):
#ROOT=*Concept1
*Concept1 = :Adv :A
Symbol :Adv represents an adverb and :A an adjective. Similarly, :digit represents a numeric value between 0 and 9. :Det represents a noun-modifying determinant such as “the,” “a,” or “an.” :PN represents a proper noun, and so on. There are many symbols to use in concept definitions depending on the requirement. For a complete list of part-of-speech tags or match symbols, see the SAS Content Categorization Studio 12.1: User’s Guide.
Contextual Extraction
Contextual extraction, also known as a LITI (Language Interpretation/Text Interpretation) definition, offers many advanced linguistic capabilities that are not available with concept extraction methods. It offers many more features combining the power of categorization and concept extraction to extract complex facts. Contextual extraction capabilities are available to use only if you have SAS Contextual Extraction Studio licensed and installed with SAS Content Categorization Studio. It is always better to use a LITI definition instead of a regular concept definition when you have SAS Contextual Extraction Studio. You can start writing LITI definitions after you select LITI on the Definitions tab. There are many types of LITI definitions and each of them offers a variety of capabilities.
CLASSIFIER Definition
The CLASSIFIER definition is similar to the classifier concept definition that we discussed earlier. It identifies word or phrase matches in a document. LITI definitions provide additional features such as coreferencing, XML field-specific matching, and exporting matches to other concepts. The basic structure of a CLASSIFIER LITI definition is CLASSIFIER:match_string_literal<,return_string>. (See Display 7.22.)
Display 7.22: Example of a LITI Classifier Definition
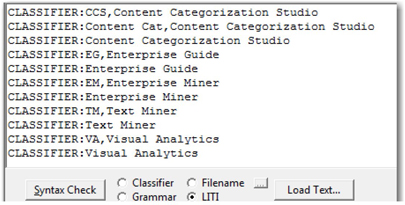
Each definition should be prefixed with CLASSIFIER: to indicate that it is a classifier LITI rule. Both the comma and the return string are optional in a LITI classifier definition. If the document is an XML file, you can specify the exact fields in the file to limit matching. Specify the fields by selecting Project ▸ Settings on the Misc tab (as shown in Display 7.23). In this case, matching is limited to the Body and Title fields of the XML document by default. XML tags Author and Date are ignored from matching.
Display 7.23: Project Settings to Ignore Specific Fields in an XML File

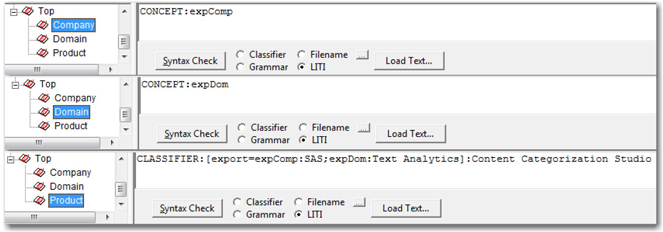
If you are looking for matches to the string literal “SAS” in the Body field of the XML file, the LITI classifier definition looks similar to CLASSIFIER:_body:SAS,SAS Institute. “SAS Institute” is the return string when a match for “SAS” is found. Similar to the classifier concept definition, the return string information is useful only when the compiled LITI file (.li file) is applied to documents using SAS Content Categorization Server. The export function is useful for exporting matches to other concepts when matches are found for the classifier string defined in the concept in which the export rule is defined. For example, you can export “Text Analytics” and “SAS” to two concepts, “Domain” and “Company” respectively, only after you find a match in the document for “Content Categorization Studio.” As a first step, define the concepts “Domain” and “Company” with CONCEPT: expDom and CONCEPT: expComp, respectively. Both expDom and expComp are the acronyms for the Domain and Company concepts, respectively, that are used to export matches from other rules when the export function is defined. Define a new concept named Product to export the concept matches for Company and Product (as shown in Display 7.24).
Display 7.24: Example Showing LITI Classifier Definition Using the Export Function
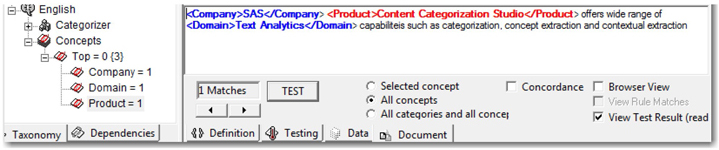
When the match string Content Categorization Studio is found in the document, the other matches, SAS and Text Analytics are exported to the Company and Domain concepts, respectively. (See Display 7.25.) Using this method, you can export more than one concept. Matches highlighted in red belong to the category Product. Matches highlighted in blue are exported to the two other concepts Company and Domain based on the export function used in the LITI classifier definition.
Display 7.25: Results of LITI Classifier Definition Used with Export Function
LITI classifier definitions enable you to coreference terms within a document. For example, terms such as He and him in a document might be referring to a single person. In this case, you can write a LITI definition such as CLASSIFIER:[coref=He,him]:Barack Obama. When tested on a document containing these terms, all of the three matches were returned when Barack Obama was found as a match (as shown in Display 7.26).
Display 7.26: Example Showing LITI Classifier Definition Using Coreferencing Operator

Regular Expressions
Regular expressions in LITI definitions are similar to those used in classifier concept definitions. The syntax slightly differs in a LITI definition with the keyword “REGEX:” prefixed for each regular expression written on every line. In LITI, regular expressions are used for pattern matching after the document is broken into individual tokens or terms. Hence, a pattern embedded within another term is not returned as a match in a LITI definition. In a classifier concept definition, regular expressions work in the document before terms are tokenized. Hence, any embedded patterns are returned as a possible match.
Example: REGEX: d+lbs
Match Example: I weigh 185lbs approximately.
Non-Match Example: You should be 185lbsor more.
In the case of a non-match, you can see that 185lbs is embedded inside the token 185lbsor. This is a match if the classifier concept definition is used instead of a LITI definition.
CONCEPT Definition
A CONCEPT definition in LITI provides the combined capabilities of classifier and grammar concept extraction features. The CONCEPT definition enables you to reference concepts within other concepts and provide priorities in the case of overlapping concept matches. Overlapping matches are possible when the terms or phrases in a document are matched with definitions in more than one concept. For example, “Columbus” could be a reference to Christopher Columbus, the European explorer and navigator who sailed to America in the fifteenth century. However, it could also be a reference to one of the many cities in the United States with the same name (for example, Columbus in the state of Ohio). There can be scenarios where references to both Columbus, the city, and Columbus, the person, can coexist in a single document. In this case, you might need to give priority to guide concept matches whenever there is an overlap. To deal with this case, you can create concepts like the following:
PERSON
CLASSIFIER:[coref=he,His]:Columbus
CONCEPT:PRIORITY=20:Christopher Columbus
CONCEPT:PRIORITY=20:Columbus's :V
CONCEPT:PRIORITY=20:Columbus's :Npl
CITY
CONCEPT:States StateShrt
CONCEPT:PRIORITY=20:Columbus, StateShrt
CONCEPT:PRIORITY=20:city of Columbus
CONCEPT:PRIORITY=20:Columbus city
CONCEPT:PRIORITY=20:Columbus in States
CONCEPT:PRIORITY=20:Columbus, States
States
CLASSIFIER:Ohio
CLASSIFIER:Georgia
CLASSIFIER:Arizona
CLASSIFIER:Mississippi
CLASSIFIER:Montana
CLASSIFIER:Michigan
CLASSIFIER:Kansas
CLASSIFIER:Kentucky
CLASSIFIER:Indiana
CLASSIFIER:Illinois
StateShrt
CLASSIFIER:OH
CLASSIFIER:GA
CLASSIFIER:AR
CLASSIFIER:MI
CLASSIFIER:MT
CLASSIFIER:MS
CLASSIFIER:KS
CLASSIFIER:KY
CLASSIFIER:IN
CLASSIFIER:IL
LITI classifier rules States and StateShrt are defined and used as references in the CITY concept to qualify this rule for any of the listed states. Classifier concept Columbus is coreferenced to terms he and His in the PERSON concept. Part-of-speech tags for verb :V and plural noun :Npl are used to identify pattern matches in sentences referring to Columbus as a person. If Columbus is mentioned in the document as a city, higher priority is given to match it with the CITY concept. PRIORITY=20 in the concept definitions boosts the priority (default value for PRIORITY is 10) to match with the CITY concept. Display 7.27 shows how the PRIORITY option works with the concept definitions to find the best matches within a document.
Display 7.27: Example Showing Test Results for LITI Concept Definition Using the PRIORITY Option

C_CONCEPT Definition
The C_CONCEPT definition has all of the capabilities of a CONCEPT definition with the added ability to match concepts with a context and detect partial matches. The C_CONCEPT definition uses a context marker _c to identify the words or phrases indicating the context in which it should find matches. For example, if you want to highlight or match SAS in the context of the company SAS Institute Inc., but not SAS Scandinavian Airlines, you can write a C_CONCEPT rule like the following:
C_CONCEPT: _c{SAS}> Institute Inc.
The greater than symbol > after the context term returns partial matches for all occurrences of the term SAS in a document if the complete rule is found at least once in the document.
Display 7.28: Example Showing Context-Based LITI Concept Definition

CONCEPT_RULE Definition
A CONCEPT_RULE definition can be interpreted as having all of the features in the C_CONCEPT definition, plus the ability to use Boolean operators in the definition. The CONCEPT_RULE definition mandatorily requires a word or a phrase with a context marker _c and at least one Boolean operator to work. The syntax for Boolean operators is similar to what we use in the Boolean rule-based categorizer. For example, you can find matches only when certain keywords appear in the Title and Body fields of an XML document. The following simple example shows a concept rule designed to find matches only when the keywords Abstract and SAS® appear within 200 words and in the specified order. However, the context is to find cases where SAS® is followed by any word or name of the enterprise software with version number.
CONCEPT_RULE:(ORDDIST_200,”Abstract”, (OR,“_c{SAS® _cap _cap :digit}”, “_c{SAS® _w}”))
Using this rule, you can find matches where SAS software is mentioned in the abstract of a technical paper. The context marker _c helps highlight the keyword SAS® and the rest of the pattern when there is a match. SAS® programs and SAS® Enterprise Miner 6.1 are highlighted and returned as matches when found in the abstract of a paper (as shown in Display 7.29).
Display 7.29: Example Showing Usage of a LITI Concept Rule Definition

NO_BREAK Definition
The NO_BREAK definition enables you to prevent partial matches where the context is not suitable for a match. For example, you can write a definition to match the name of a person while making sure it doesn’t return a match when the same name is used to mention a landmark, place, or city. The following example shows how you can prevent a match return when the keywords Boone Pickens are followed by a noun indicating a non-match:
CLASSIFIER:Boone Pickens
NO_BREAK: _c{Boone Pickens :N}
Boone Pickens is returned as a match when detected as a person, but not when followed by the noun stadium (as shown in Display 7.30). Instead of using part-of-speech tags in the NO_BREAK definition, you can reference a CLASSIFIER LITI concept, listing all possible keywords to prevent partial matches.
Display 7.30: Example Showing Usage of NO_BREAK LITI Definition

REMOVE_ITEM
It helps to prevent a concept match when there is an overlapping match found by a match key. This requires the Boolean operator ALIGNED and a context marker to specify the concept. For example, Wall Street is a famous landmark in New York where the New York Stock Exchange and many financial giants are located. You can indicate Wall Street as one of the landmark locations in New York and avoid a match for the StreetName concept when it is found in the document. These concepts are defined as follows:
Landmark
CLASSIFIER:Wall Street
CLASSIFIER:Times Square
CLASSIFIER:Brooklyn Bridge
CLASSIFIER:Union Square
StreetName
CONCEPT: _cap Street
REMOVE_ITEM:(ALIGNED,“_c{StreetName}”, “Landmark”)
In this example, Wall Street is recognized as a Landmark instead of as a StreetName in New York. Broad Street is identified as a StreetName (as shown in Display 7.31). Though both are valid street names in New York, the REMOVE_ITEM definition enabled you to avoid this overlap and give preference to the Landmark concept when matched.
Display 7.31: Example Showing Usage of REMOVE_ITEM LITI Definition

SEQUENCE and PREDICATE_RULE Definitions
These definitions are useful to locate and extract facts from textual data. A fact is a structured relationship between two or more concepts that is not known before analyzing documents. Concepts can be names of people, cities, locations, countries, etc. When concepts occur together in a sentence to form facts, they can be extracted using either SEQUENCE or PREDICATE_RULE definitions. SEQUENCE is useful to extract facts when the individual concepts are in a specific sequence. It requires at least two arguments to assign the returned matches based on the concepts found. For example, you can extract the names of people, their designations, and their affiliated organizations from a document without explicitly mentioning their names in the definition. Here is a list of concepts defined for this purpose:
Organizations
CLASSIFIER:SAS
CLASSIFIER:Apple
CLASSIFIER:Microsoft
CLASSIFIER:Google
Designations
CLASSIFIER:CEO
CLASSIFIER:Chief Executive Officer
CLASSIFIER:Chairman
CLASSIFIER:VP
CLASSIFIER:Vice President
CLASSIFIER:CTO
CLASSIFIER:Chief Technology Officer
Tags
CLASSIFIER:Inc.
CLASSIFIER:Incorporated
CLASSIFIER:Corporation
CLASSIFIER:Corp.
CLASSIFIER:Private Limited
CLASSIFIER:Pvt Ltd.
Executives
SEQUENCE:(a,b): _a{_cap _cap} is the _b{Designations of Organizations Tags}
SEQUENCE:(a,b): _a{_cap _cap}, _b{Designations of Organizations Tags}
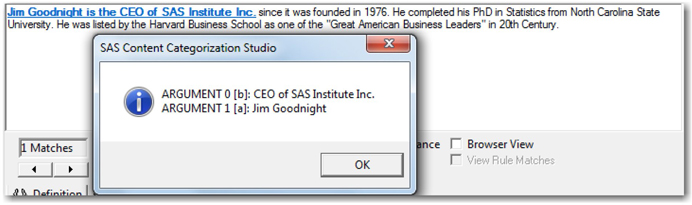
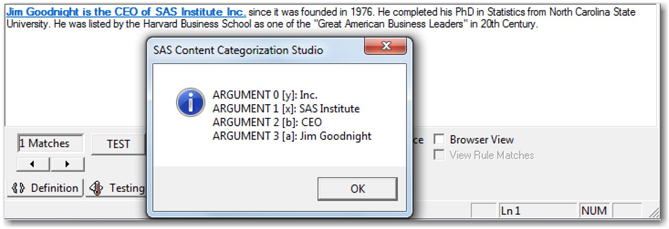
In the following example, Jim Goodnight is returned as the first argument, and CEO of SAS Institute Inc. is returned as the second argument (as shown in Display 7.32). The fact that Jim Goodnight is the CEO of SAS can be extracted from the document without any prior knowledge of the person’s name.
Display 7.32: Example Showing Usage of SEQUENCE LITI Definition
PREDICATE_RULE is much more powerful than SEQUENCE in finding facts because the order in which the concepts occur is not relevant anymore. It uses Boolean operators to find facts in the context of two or more contexts. PREDICATE_RULE avoids the hassle of writing multiple SEQUENCE definition rules to catch all of the patterns in which a fact can be found in the documents. For the same previous example, you can rewrite the definition using a PREDICATE_RULE instead of writing two SEQUENCE definitions (as shown in Display 7.33):
PREDICATE_RULE: (a,b,x,y): (SENT, “_a{_cap _cap}”, “_b{Designations}”, “_x{Organizations}”, “_y{Tags}”)
All the four arguments returned are related to each other, but there is no indication of sequence. However, PREDICATE_RULE can be written to perform a much more powerful factual extraction with the inclusion of more Boolean operators nested within each other.
Display 7.33: Example Showing Usage of PREDICATE_RULE LITI Definition
Scoring Category Rules and Concept Definitions
As you build and test a taxonomy using SAS Content Categorization Studio, it is important that the rules defining the taxonomy are applied to all documents in the organization. Category rules, concept definitions, and LITI rules are compiled to generate the binary files (.mco) concept files (.concepts), and LITI files (.li), respectively. These files can be uploaded to SAS Content Categorization Server to allow for automatic document categorization, concepts, and complex facts extraction in real time. SAS Content Categorization Server uses the SAS Document Conversion server to convert documents in other file formats such as PDF, XML, HTML, Excel, CSV, etc., to plain text files. Using the SAS Content Categorization Server Administration Web Page, you can monitor the statistics and matches for categorization rules and concept matches. This chapter mainly focuses on building models and not on the scoring process. Refer to the SAS Content Categorization Single User Servers 12.1: Administrator’s Guide for complete information about how to score documents using SAS Content Categorization Server.
Automatic Generation of Categorization Rules Using SAS Text Miner
Earlier in this chapter, we mentioned how precisely written Boolean rules in a rule-based categorizer can be very efficient in the categorization process. However, this is possible only if the analyst working on building the taxonomy has significant knowledge about the document content. It would be a great benefit for the analyst to have basic blocks for these rules for each category instead of writing them from the scratch. Starting in version 12.1, SAS Text Miner offers a new feature called the Text Rule Builder that can be used to generate Boolean rules using important terms in the data to help predict the categories. A sufficient set of documents separated by category is required in a SAS data set to train the model. To train the model, assign the role Target to the variable containing the pre-identified categories, and assign the role Text to the variable holding the content of the documents. The trained model generates Boolean expressions that represent one or more terms occurring in the presence or absence of one or more terms using the Boolean operators AND, OR, and NOT. These expressions are in the same syntax as the code used in SAS Content Categorization Studio to define categories. Thus, the rules generated by SAS Text Miner can be exported to SAS Content Categorization Studio as preliminary definitions for the Boolean rule-based categorizer. They can be subsequently modified to achieve the appropriate level of accuracy and precision. Users can choose to modify the values of the target category to be required to assist the model training process and to achieve better accuracy. The important value added by this feature is its ability to show the terms explaining the reason why a document, based on its content, falls into a category.
Let’s generate Boolean rules that are useful to understand and predict a target category for a set of documents. We are using a new SAS data set named SGFPAPERS_BYSECTION.sas7bdat, which contains 466 SAS Global Forum paper abstracts for the past three years from five randomly chosen sections. This data set is available by selecting Chapters ▸ Chapter 7 in the data provided with this book. When we discussed the statistical categorizer, we used text files for these abstracts. Continue to use the SAS Enterprise Miner project that you created in Chapter 3 or create a new project. Register the data set by creating a data source. In the Data Source Wizard, step 5, change the roles of the variables as shown in Display 7.34. Variable name contains the unique identification number of the paper, text contains the abstract of the paper, and type contains section names in short form.
Display 7.34: Roles and Levels of Variables in SAS Data Set SGFPAPERS_BYSECTION

Create a new diagram named TextBuilderDemo, and drag and drop the registered data source SGFPAPERS_BYSECTION onto the diagram. Drag, drop, and connect the Data Partition, Text Parsing, Text Filter, and Text Rule Builder nodes in sequence as shown in Display 7.35. Change the data set allocations for Training, Validation, and Testing to 70.0, 30.0, and 0.0, respectively, in the properties for the Data Partition node. Change the Term Weight option to Mutual Information in the Text Filter node Properties panel. Right-click the Text Rule Builder node, and select Run to execute the entire process flow.
Display 7.35: Text Mining Process Flow to Run Text Rule Builder Node

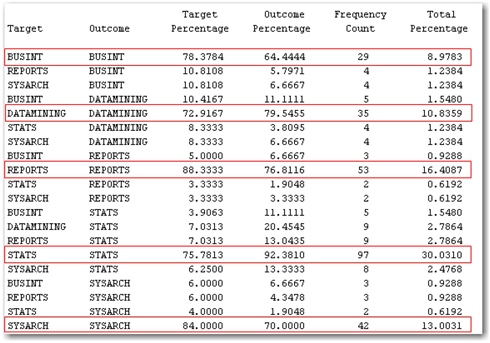
Once the entire process flow is completed, click Results to examine the output generated by the Text Rule Builder node. In the Output window, scroll down to view the distribution of predictions for all of the categories. You will see that approximately 79% of the total abstracts in the Training data set are correctly predicted by the model (as shown in Display 7.36). Similarly, about 68% are correctly classified in the Validation data set. Based on the misclassification rate, the model has performed reasonably well, although the misclassification rate increased a bit for the Validation data set compared to the Training data set.
Display 7.36: Classification Results (from Training Data Set) from Text Rule Builder Node Output
Click the ellipsis button for the content categorization code in the Text Rule Builder node Properties panel to view the rule expressions generated by the node to predict each of the five target categories (as shown in Display 7.37). You might observe that most of the terms are intuitive and make sense for the respective sections. For example, terms such as graphs, reports, and maps are more appropriate for the Reports section. Terms such as procedure and analysis make sense for the statistical analysis section. Copy the rules of each category and build a rule-based categorizer in SAS Content Categorization Studio.
Display 7.37: Partial Output from Automatic Content Categorization Code Generated by Text Rule Builder Node

Let’s go back to the SAS Content Categorization Studio project in which you built the statistical categorizer using SAS Global Forum paper abstracts. Copy the automatically generated rules from the Text Rule Builder node for each category into the respective categories in the SAS Content Categorization Studio project. Click Build ▸ Build Rule based Categorizer to build a Boolean rule-based categorization model. Select the BUSINT (Business Intelligence) category, and click the Testing tab to view the files listed for testing the model. Click Test to run the model on these files to see how many passed and how many failed. You should see two files that failed the test for this model in the BUSINT category. After carefully examining the two files that failed, you discover that they failed the test because none of the terms defining the rules for this category were present in the document. However, the presence of terms such as portlet, SAS portal, and cube in the abstracts might be good candidates to represent the category. Modify the Boolean rules for this category to accommodate the new terms (as shown in Display 7.38). Rebuild the categorizer, and then test the files again.
Display 7.38: Boolean Rules Modified in SAS Content Categorization Studio

The two files that failed earlier have now passed the test by including specific terms identifiable with the Business Intelligence category in the rules. You can use the Text Rule Builder feature in combination with SAS Content Categorization Studio to build categories with a higher classification accuracy. In general, the following steps should help you as an analyst build the taxonomy for categorization:
1. Identify and define classes or categories for the taxonomy based on your knowledge about the document content. Consult with another subject matter expert if needed.
2. Collect and organize two sets of documents (Training (50 to 100) and Testing (25 to 50)) for each category that you intend to define in the taxonomy.
3. Create a project in SAS Content Categorization Studio, and define these categories.
4. Set up the Training Path and Testing Path for all of the categories.
5. Use the Generate Rules Automatically feature to derive a primitive list of linguistic terms defining the categories.
6. Modify these linguistic terms either with qualifiers or by adding weights to create a simple linguistic categorizer or a weighted linguistic categorizer, respectively.
7. Build a statistical categorizer for all of the categories in the taxonomy using the Training set.
8. Use the Text Rule Builder feature in SAS Text Miner to automatically generate Boolean expression rules for these categories.
9. Copy the generated rules from the Text Rule Builder to SAS Content Categorization Studio for all of the categories.
10. Modify the Boolean rules copied from the Text Rule Builder node after carefully analyzing the testing documents.
11. Make changes to the match ratio, relevancy type, relevancy cutoff, category bias, relevancy bias, and default category bias as required based on the type of categorizer.
12. Thoroughly test all of the categorizers that you have built so far, and modify the rules as necessary to improve the performance.
13. Identify the best categorizer that yields high recall and precision values for classification.
14. In the case of the simple linguistic categorizer, weighted linguistic categorizer, and Boolean rule-based categorizer, you can combine the Testing and Training set of documents and use all of them for testing.
15. Repeat steps 6, 10, 11, and 12 in an iterative fashion to produce reasonably performing models.
Differences between Text Clustering and Content Categorization
In Chapter 6, we discussed how text clustering in SAS Text Miner helps in grouping documents of similar content. Although content categorization (or document classification) has a similar purpose (i.e., to organize documents of closely related content), it is not the same as text clustering. Let’s review the key distinguishing characteristics between the text clustering feature in SAS Text Miner and the content categorization methods in SAS Content Categorization Studio. The differences should help you understand which feature works best for organizing documents at your organization.
Table 7.2: Differences between Features in SAS Text Miner and SAS Content Categorization Studio
| Text Clustering (SAS Text Miner) | Content Categorization (SAS Content Categorization Studio) |
| • Unsupervised learning. | • Statistical categorizer – Supervised learning, requires corpus of documents to train model. |
| • Rule-based categorizer – Unsupervised learning, requires users to write rules and test model. | |
| • Categories not predefined. | • Categories should be predefined. |
| • Completely based on statistical techniques. | • Statistical categorizer based on statistical techniques. |
| • Rule-based categorizer based on natural language processing and advanced linguistic techniques. | |
| • Uses latent semantic analysis and singular value decomposition for dimension reduction. | • Statistical categorizer – Uses complex statistical and algebraic methods. |
| • Rule-based categorizer – Not applicable. | |
| • Cannot disambiguate between same words with distinct meanings. Example: In the sentence, “Mr. White found guilty in the trial,” White refers to the name of a person. In the sentence, “He came to the office dressed in white,” white refers to a color. Both are nouns, but they represent two different entities and shouldn’t be treated identically. |
• Natural language processing methods provide the ability to custom build rules to disambiguate based on context. Example: For the same example, you can write a Boolean rule to check whether a concept term suggesting any color (such white, red, blue, black, green, etc.) is preceded by a title (such as Mr., Ms., Mrs., etc.). If so, you can choose not to assign the Color category for the document. In this way, you can write exclusion rules to disambiguate the context. |
| • Concepts or entities are not exclusively included for context-based document clustering. You cannot conditionally force a document containing one or more entities to fall in a specific cluster. | • You can use concepts or entities in addition to category definitions to perform context-based category matching. You can choose to include concept definitions in category matching using one or more of the Boolean, context, frequency, and sequence operators available. |
Summary
In this chapter, you learned how to use SAS Content Categorization Studio to create taxonomies; define categories and subcategories; build statistical, linguistic, and rule-based categorizers; write definitions to extract concepts; write LITI rules to extract complex facts; and use the Text Rule Builder feature in SAS Text Miner to automatically generate content categorization code. Organizations can leverage SAS Content Categorization Studio to organize, catalog, and efficiently maintain their document repositories. In the next chapter, we discuss how to perform sentiment analysis on documents containing user opinions about your organization’s brand, product, or service in the market. We introduce SAS Sentiment Analysis Studio, a proprietary software product from SAS specifically designed to meet your organizational needs in conducting sentiment analysis.
Appendix
/****************************************************************************/
/** Use this macro to create .txt files from a SAS data set. **/
/** **/
/** The SAS data set should have two variables. **/
/** 1) Comment 2) Id **/
/** **/
/** The macro will create text files with each observation as a separate text file. **/
/** Each file is named with the “Id” value in the folder C:Destination. **/
/** Create a folder in C: and name it Destination. **/
/** Before running the code, set the name of your input data set to macro variable DATA,**/
/** set the text variable name to macro variable COMMENT, and set the Id variable **/
/** name to the macro variable ID. **/
/** **/
/****************************************************************************/
dm “log; clear; output; clear;”;
%let DATA= <<input-data>>;
%let COMMENT= <<text variable>>;
%let ID= <<id variable>>;
%macro createtxt(data,comment,id,numvars);
%do i=1 %to &numvars;
data _null_;
obsnum=&i;
length text $2500.;
set &data. POINT=obsnum;
file &&name&i;
text=compbl(strip(tranwrd(&comment.,'”',‘')));
put text;
STOP;
run;
%end;
%mend;
data _null_;
set &data. nobs=count;
call symput(“name”||left(_n_),” ‘C:Destination”||&id.||”.txt' “);
if _n_=1 then call symput(“numvars”, trim(left(put(count, best.))));
run;
%createtxt(&data,&comment,&id,&numvars);
References
Albright, R. 2004. “Taming Text with the SVD.” Available at: ftp://ftp.sas.com/techsup/download/EMiner/TamingTextwiththeSVD.pdf [WebCite Cache].
Antonie, M. L., & Zaiane, O. R. 2002. “Text Document Categorization by Term Association.” ICDM ’02: Proceedings of the 2002 IEEE International Conference on Data Mining. IEEE, 19-26.
IDC.2009. Hidden Costs of Information Work: A Progress Report, Doc #217936.
Jackson, P., & Moulinier, I. 2007. Natural Language Processing for Online Applications: Text Retrieval, Extraction and Categorization, Vol. 5. Philadelphia: John Benjamins Publishing.
Joachims, T. 2002. Learning to Classify Text Using Support Vector Machines: Methods, Theory, and Algorithms. Boston: Kluwer Academic Publishers.
Kaski, S., Honkela, T., Lagus, K., & Kohonen, T. 1998. “WEBSOM–Self-Organizing Maps of Document Collections.” Neurocomputing. 21(1-3): 101-117.
Mavroeidis, D., Tsatsaronis, G., Vazirgiannis, M., Theobald, M., & Weikum, G. 2005. “Word Sense Disambiguation for Exploiting Hierarchical Thesauri in Text Classification.” Knowledge Discovery in Databases: PKDD 2005. Berlin: Springer-Verlag, 181-192.
Pottenger, W. M., & Yang, T. H. 2001. “Detecting Emerging Concepts in Textual Data Mining.” Computational Information Retrieval. Philadelphia: Society for Industrial and Applied Mathematics, 89-105.
Reamy, T. 2010. Knowledge Architecture Professional Services. “Enterprise Content Categorization – The Business Strategy for a Semantic Infrastructure [White paper].” Retrieved from http://www.kapsgroup.com/presentations/ContentCategorization-Business%20Value.pdf
SAS® Content Categorization Single User Servers 12.1: Administrator’s Guide. Cary, NC: SAS Institute Inc.
SAS® Content Categorization Studio 12.1: User’s Guide. Cary, NC: SAS Institute Inc.
SAS® Enterprise Content Categorization 12.1: User’s Guide. Cary, NC: SAS Institute Inc.
Schütze, H. 1998. “Automatic Word Sense Discrimination.” Computational Linguistics. 24(1): 97-123.
Sebastiani, F. 2002. “Machine Learning in Automated Text Categorization.” ACM Computing Surveys (CSUR). 34(1): 1-47.
Yang, Y. 1999. “An Evaluation of Statistical Approaches to Text Categorization.” Information Retrieval. 1(1-2): 69-90.
Yang, Y., & Joachims, T. 2008. “Text Categorization.” Scholarpedia. 3(5): 4242.