
Case Study 9 Evaluating Health Provider Service Performance Using Textual Responses
Gary Gaeth
Satish Garla
Goutam Chakraborty
Introduction
The service industry has always relied on customer feedback for improving day-to-day business operations. Customer feedback is collected through surveys sent to the customer via mail, telephone and email. A survey can be used to collect different types of information. Typically a large portion of a survey contains closed-ended questions. When collecting service feedback, these questions expect customers to rate their experience on a scale, for example a Likert-scale. In addition, a small portion of the survey questionnaire is devoted for open-ended questions where a customer is allowed to write about things not included in the survey. Until the last decade these textual comments, commonly referred as unstructured data, was considered junk that was eating away storage space. With the growth of text analytics technology, companies have realized the value of textual responses. Companies across industries are successfully answering various business questions using text analytics applications like information retrieval, trend analysis, sentiment analysis, etc.
Sentiment analysis is used to classify a document as either positive, negative, or neutral based on the valence of the writer’s opinion in the text. In many situations a single textual comment such as a product review cannot be classified as purely positive or purely negative. A reviewer might be talking about two different features of a product where he expresses satisfaction with one of the features and is disappointed with another. Extracting sentiment at the sentence level would require sophisticated tools like SAS® Sentiment Analysis Studio. However in the presence of data with pre-classified sentiment at the document level, a model can be developed that can be used to understand reasons for positive and negative sentiment and score new comments for sentiment without manual intervention. The Text Rule Builder node in SAS® Text Miner can be used to develop rules that identify the reasons for sentiment in the text. These rules can be used as a starting point for further sentiment analysis using SAS Sentiment Analysis Studio or for content categorization.
In this case study we explore patient response collected via a survey by one of the largest university hospitals in USA. For privacy concerns the name of the hospital in the text is changed to “UCARE”. Names of places, persons and other entities are also anonymized in the data. The response to the question ‘What was your overall experience with the service’ is analyzed using SAS® Text Miner. The textual responses analyzed in this study are related to one of the hospital departments and were collected during a specific time period. Each response was manually classified as positive, negative, or neutral by experts. Whenever a comment had both a positive and negative sentiment, it was rated as neutral. This classification will be used as the target variable for training a model that can be used to classify new survey data. The Text rule builder node in SAS® Text Miner extracts rules from text that can further be used in SAS® Content Categorization Studio.
The data used in this case study cannot be provided with this book due to confidentiality reasons. However by following below steps you can analyze textual feedback where the comments are pre-classified into categories such as positive, negative and neutral.
1. Create a new project in SAS® Enterprise Miner and create a data source for the UCARE data.
2. Select the roles for the variables as shown in the Display C9.1.
Display C9.1 Variables list window in data source creation
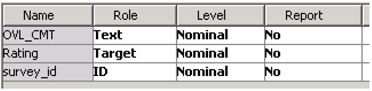
3. The variable OVL_CMT has the textual response and the variable rating has the values positive, negative, or neutral.
4. Create a diagram and drag the UCARE data set to the diagram workspace.
5. Connect a data partition node and the set the partitions to 70:30:0 as shown in Display C9.2.
Display C9.2 Data partition node property panel
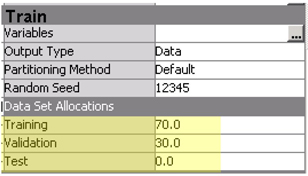
6. Connect a text parsing node to the data partition node and change the settings as below:
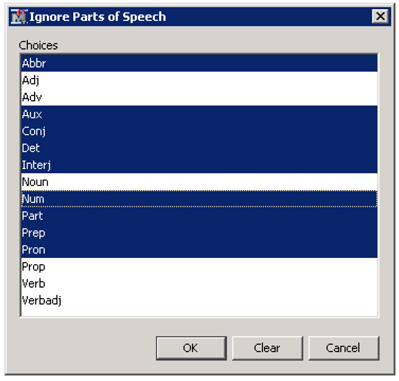
a. Parts of Speech: Select as shown in Display C9.3 and click OK
Display C9.3 Ignore parts of speech window
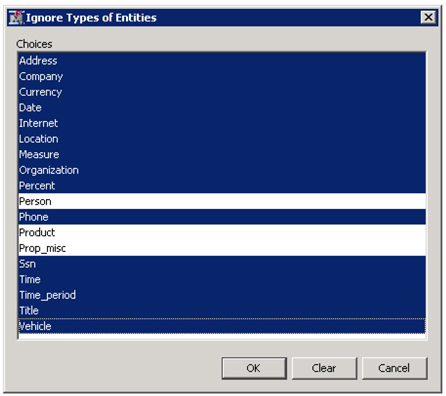
b. Ignore Types of Entities: Select all except Person, Product and Prop_Misc as shown in Display C9.4 and click OK.
Display C9.4 Ignore types of entities window
7. Run the text parsing node and click on the results after the completion of the run.
8. Sort the Terms table in the results window by clicking the keep column twice to view the terms with keep status ‘Yes’ as shown in Display C9.5.
Display C9.5 Terms table from text parsing results window
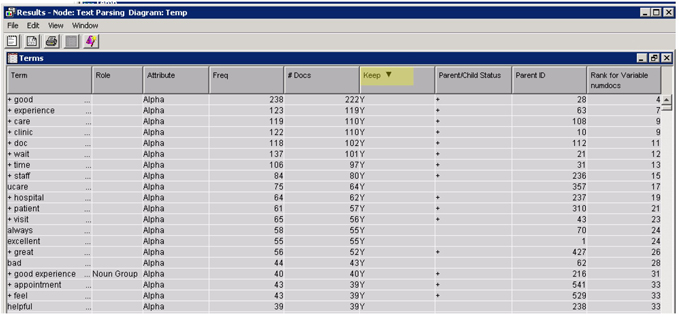
The terms retained in the analysis are reasonable without a lot of noisy terms. However, the list can be improved by identifying synonyms such as “doc” and “doctor”, “hospital” and “ucare”, etc.
9. Connect a text filter node to the text parsing node and change the settings as shown in Display C9.6.
Display C9.6 Text filter node train properties panel
Since you have a target variable, the Mutual Information term weighting technique can be used to derive meaningful weights to the terms.
10. Run the text filter node.
11. After completion of the run, click on the ellipsis next to filter viewer in the property panel.
This is the step where an analyst spends significant amount of time processing the terms. Primary tasks performed at this stage are excluding irrelevant terms and creating custom synonyms. It is difficult to list all the operations performed at this stage. The following steps discuss few of those tasks and you are provided with a custom synonym list for use. You might see a difference in the results which is due to the difference in the terms dropped or kept.
12. In the Terms table, sort the KEEP column by kept terms. Select the terms “ucare” and “hospital”, then right-click and select Treat as synonyms as shown in Display C9.7. In most of the comments ucare is referred to as hospital by patients. However, there could be instances when the hospital is used to refer to other hospitals. This is usually the choice left to the analyst to create such synonyms. Also, by reading through the list you will see short forms of terms such as ‘appt’ for appointment and ‘doc’ for doctor. You can treat all these terms as synonyms.
Display C9.7 Terms table in interactive filter viewer of the text filter node
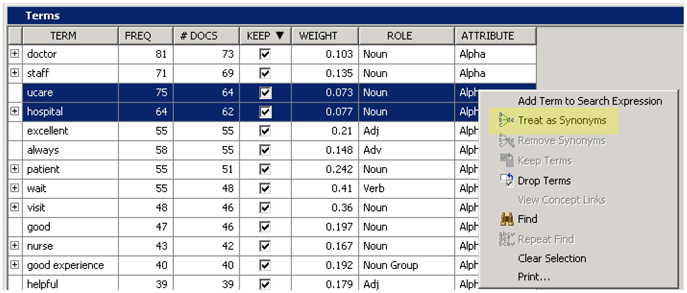
You can work through the whole list yourself or you can start with some of the synonyms you already created in other projects.
13. Copy the synonym data set to the library that you created for this project.
14. In the text parsing node property panel, click on the ellipsis next to Synonyms.
15. Click on Import, then click on the library that you create for the project
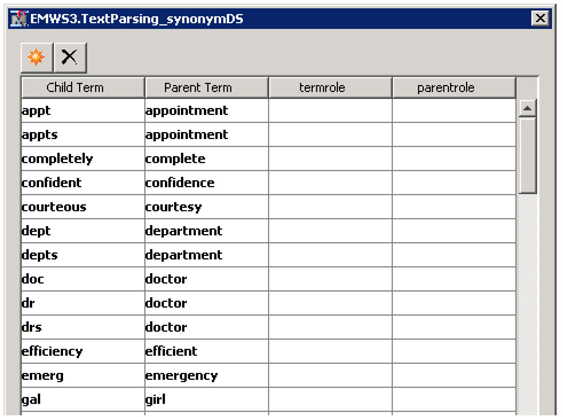
16. Select the data set “Syn” and click OK.
17. You will see all the synonyms imported into the custom synonyms window as shown in Display C9.8.
Display C9.8 Custom synonyms pop-up window
18. Connect a text rule builder to the text filter node as shown in Display C9.9 and rename the node to “TRB – Default”.
Display C9.9 Text mining diagram process flow

19. Leave the properties of the rule builder node to default values. All the three properties, generalization error, purity of rules and, exhaustiveness have a default value of Medium.
In the results window (See Display C9.10), you will find typical data mining model fit statistics since this is similar to a structured model with a target variable.
Display C9.10 Text rule builder node results window
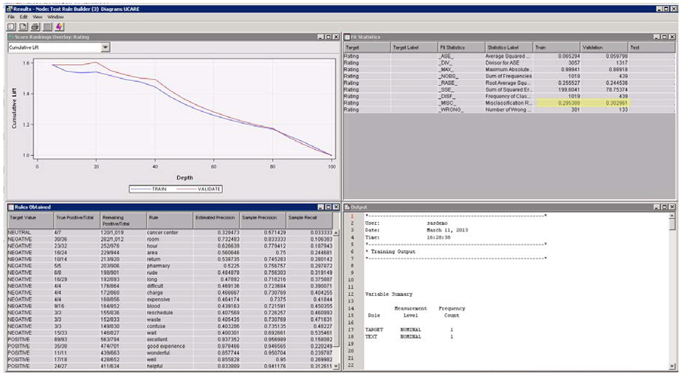
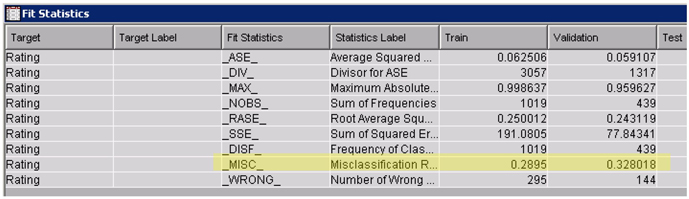
From the fit statistics table, you will find that the model misclassification rate in training and validation data is 29% and 30%, respectively. With a three-level target variable, the misclassification rate around 30% may sound reasonable. Other important results of the text rule builder node are the rules extracted from text. The rules are nothing but key terms that were identified to be significantly associated with a particular level of target variable. These rules are listed in the ‘Rules Obtained’ table. You will see terms hour, room, pharmacy, rude, etc. being identified as rules for the target level negative. In this data, all the rules are made of single terms. Rules could also be conjunctions of terms and their negations. The order of rules listed in the table is very important. The second rule in the table is extracted using the documents that were not satisfied with the first rule. Similarly the third rule is extracted using documents that were not covered by the first two rules. On a scoring data set, the rules are applied in the same order.
The rules table includes valuable statistics for each rule which indicate rule generalizability. Consider the rule, “rude” (See Display C9.11). The “Remaining Positive/Total” column has a value 198/901. This value indicates that the rule is extracted using 901 documents which are not covered by any of the previous rules in the table and among these documents there are 198 documents with level Negative. The “True positive/Total” column has a value 6/8 for this rule. This means, of the 901 documents, there are 8 documents that had the term “rude” and 6 of these documents have the target as “Negative.” Using these values, you can derive precision and recall statistics. Precision measures the fraction of predicted documents that are true positives, and recall measures the fraction of actual documents that are true positives. Both these statistics use the results of the rules in the table up to the current rule.
Display C9.11 Rules obtained from text rule builder with default settings
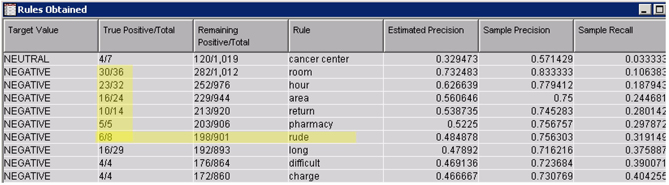
For the rule, “rude”,
Precision: True Positives/ Total Predicted = (30+23+16+10+5+6)/119=0.756303
Recall: True Positive/ Total Actual: 90/282 = 0.319149
The estimated precision value indicates the expected precision of this rule in the hand-out data set using the setting for generalization error property. It is always advised to play with property settings and explore multiple sets of results. The properties generalization error and exhaustiveness control model over train, while the purity of rules lets you choose between few high-purity rules vs. many low-purity rules.
20. Connect another text rule builder node to text filter node and change the settings as shown in Display C9.12.
Display C9.12 Text rule builder node train property panel
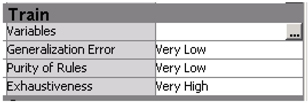
This selection of settings will work well when your objective is to explore the training data set without worrying about model performance on hold-out data. Selecting low on the generalization error and exhaustiveness properties will over train the model (fits very well in the training data). And selecting low on the purity of rules will extract rules that handle most terms and could generate very long rules.
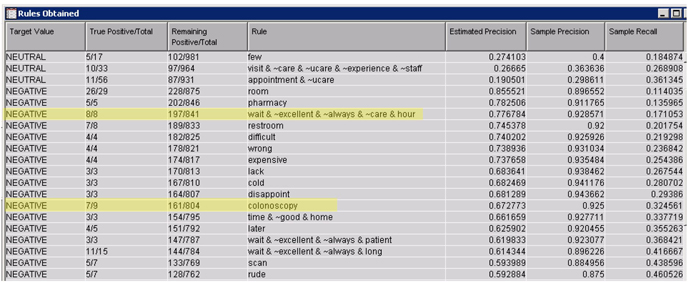
21. After completion of the run, open the results window of the text rule builder node and view the results The fit statistics table shows improvement in the misclassification rate in the training data set with misclassification at 27.38%. However, the misclassification rate in the validation data set is 37.13%. This is clearly due to model over-training. The rules obtained table shows more rules compared to the rules extracted with default settings. For Target Value of negative, you will find one of the rules as “wait & ~excellent & ~always & ~care & hour” as shown in Display C9.13. Clearly, patients are unhappy with the wait times. Comments that do not have the terms ‘excellent, always, care’, but have the terms ‘wait’ and ‘hour’ contain negative sentiment. Similarly, you can change the settings to other values and explore your results for more insights.
Display C9.13 Rules obtained from the text rule builder with modified settings
The list of rules extracted provides excellent insights on the key service aspects of the hospital that are influencing patient experience. From the two rule builder node results, you can clearly see that the patients seem to have negative experiences with restroom, rescheduling, pharmacy, etc. And they are happy with the care, staff, overall experience, etc.
However, there are terms that need to be further investigated for understanding the key service aspects. For example, just the term “colonoscopy”, shown in Display C9.13, that shows up as a rule in the results for negative rules does not provide sufficient information on what is going wrong with colonoscopy procedures. The text filter node can help in searching for documents that contain the term ”colonoscopy”. Looking at these documents can help in understanding the negative issues with this procedure.
22. Open the Interactive Filter viewer of the text filter node.
23. In the search box available in the top section of the report type ‘>#colonoscopy’ and click apply as shown in Display C9.14.
Display C9.14 Search box of interactive filter viewer

24. While searching for documents, including the symbols ‘>#’ before the term will retrieve documents that that include the term or any of the synonyms that have been assigned to the term.
25. Right-click on the results and click ‘toggle full-text’ to view the full text
The results show that negative issues with colonoscopy are related to staff at registration, delay in sending results and wait time. Similarly, other rules from the rule-builder node can be further explored using the search feature in text filter node.
26. In the diagram, from the properties panel of the rule builder node with modified settings, click on the ellipsis next to Content Categorization code.
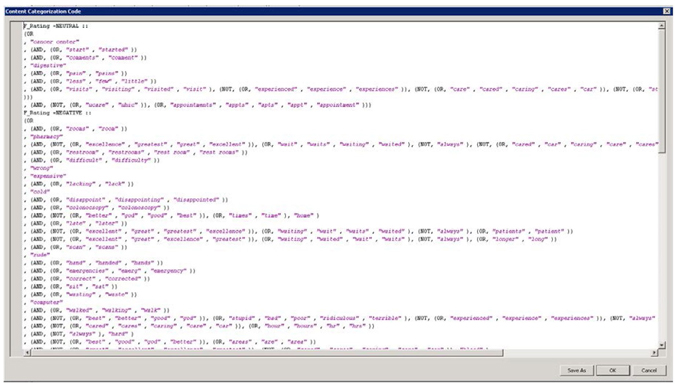
Here you will find the code that can be used with SAS® Content Categorization Studio. This code lists all the rules as Boolean rules with the synonyms and stemmed terms embedded in the rules as shown in Display C9.15. You can both save the code or copy and paste it in SAS® Content Categorization Studio. Refer to Case Study 2, “Automatic Detection of Section Membership for SAS Conference Paper Abstract Submissions” for a detailed demonstration on the utility of SAS® Content Categorization Studio in enhancing the performance of a classification model built using the text rule builder node.
Display C9.15 Boolean rules generated by the text rule builder node
The other very useful feature of the rule-builder node is the active-learning functionality. In cases where humans are involved in rating textual comments, there is very high likelihood of wrongly classifying a comment either purely due to manual error or misinterpretation of the comment by the expert. A similar situation is commonly observed when using product reviews by users for sentiment analysis. In supervised sentiment analysis a product review’s numeric rating is used to classify the sentiment of the comment. For example, consider the review for a newly launched video game as shown in Display C9.16. The reviewer seems to have more negatives than positives. However, he tends to give 4 stars for the product. The rating might have been influenced by his love for an earlier version of the game. Considering a rating above 4 as positive will be misleading. This will result in the extraction of wrong rules. Mistakes such as this can be corrected using the change target feature of the text rule builder node.
Display C9.16 Sample video game review

27. Click the ellipsis button next to Change Target Values property of the rule builder node with default settings.
The change target value table lists only wrongly classified comments. Often you will find that some comments should have been rated as negative, but were actually rated as positive by experts. Those types of mistakes can now be modified by changing the value in the last column to NEGATIVE from POSITIVE.
After correcting few target values and rerunning the node, the misclassification rates are changed as shown in Display C9.17. The change has improved the misclassification rate in training data slightly but made it poorer in the validation data set. Slight changes in the target variable can bring in significant changes in the results.
Display C9.17 Fit statistics with modified target values
28. We will now score the model on a different data set “ucare_score”. This data set only has an ID variable and a text variable.
29. Connect a score node to the rule builder node with default settings (TRB – Default)
30. Drag and drop the score data source on to the diagram and connect it to the score node as shown in Display C9.18.
Display C9.18 Partial diagram process flow with the score node and score data set
31. Run the score node.
32. After the completion of the run, click on the ellipsis button next to exported data property from the score node property panel.
33. Highlight score and click on “Browse” as shown in Display C9.19.
Display C9.19 List of exported data sets from score node
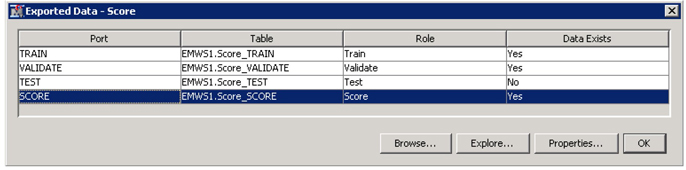
You will find the documents in the score data set scored as positive, negative, or neutral in the Into: Rating column. This way the model can be used to identify the sentiment in any data set using key rules extracted from training data set.
In the presence of a target variable, another approach to build a predictive model with textual data is by using the text topic node/text cluster node along with any typical modeling technique. Text topics from a topic node or SVDs from the text cluster node can be used as inputs to a decision tree or neural network or any modeling node. However, a text rule builder provides an added advantage of having an active-learning facility and generates Boolean rules that can be used as starting points for content categorization. In this data set, text rule builder actually outperforms basic models built using the text cluster and text topic node as shown next.
34. Attach the following nodes: Text Cluster, Text Topic (from Text Mining Tab), Metadata (from Utility Tab), Decision Tree, Regression, Decision Tree, and Neural Network (from Model Tab) as shown below to the Text Filter node (See Display C9.20).
Display C9.20 Text Mining process flow diagram
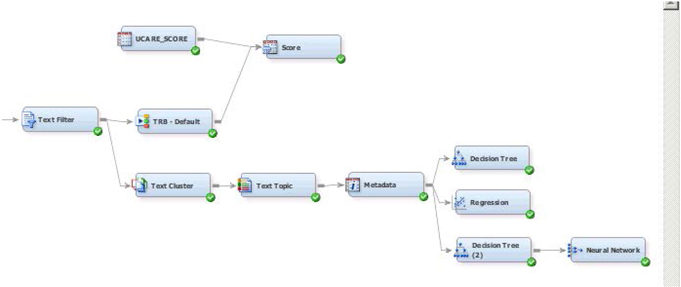
35. Make the following changes to the properties panel of each node (these changes are made based on trial-and-error with the data and using domain knowledge to get meaningful results).
a. Text Cluster: Max SVD Dimensions 25, Number of Clusters 8
b. Text Topic: Number of multi term topics 15
36. Run the flow from the Text topic node.
The Metadata node is useful in changing the roles of variables in the middle of a flow diagram. The Text Cluster and Text Topic nodes have created many different variables (such as cluster membership, topic flags etc.) that are now available as potential input variables in any predictive model.
37. In the Metadata node make following changes (click on the ellipsis button for variables under train) in the variable roles as shown in Display C9.21.
Display C9.21 Changing Variable Roles via Metadata Node
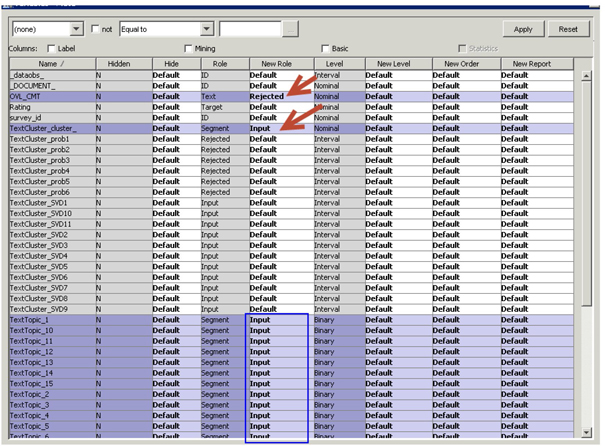
Essentially you have changed OVL_CMT to Rejected, TextCluster_cluster_ to Input (from Segment) and all TextTopic_1 to TextTopic_15 to Input (from Segment). TextTopic_1 through TextTopic_15 are binary variables with a default role of segment that needs to be changed to Input for use in the predictive models. The TextTopic_raw1 to TextTopic_raw10 contains the actual weights to derive the binary segment variables with a default weight of Input. It is up to you to either choose to use all of these variables or to use some variable selection techniques to select from these variables.
38. Make following changes in the properties panel of model nodes:
a. Decision Tree : Assessment Measure to Average Square Error
b. Regression : Selection Model to Stepwise, Selection Criterion to Validation Error
c. Decision Tree connected to Neural Network (in this case the Tree is used to select variables): Number of Surrogate Rules to 1, Method to Largest
d. Neural Network: Model Selection Criterion to Average Square Error
39. Attach a Model Comparison node (from Assess Tab) and connect all of the model nodes (Text Rule Builder, Decision Tree, Regression and Neural Network) to it as shown in Display C9.22.
Display C9.22 Comparing Multiple Models via the Model Comparison Node
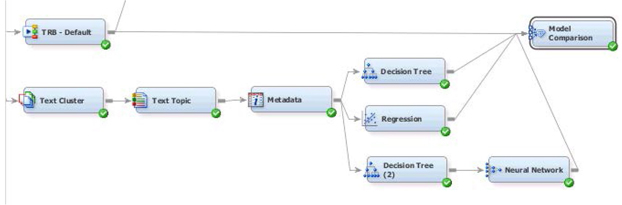
40. Change the Model Comparison Node properties panel Selection Statistic to Average Squared Error and Selection Table to Validation. The results from running the model comparison node are shown in Display C9.23.
Display C9.23 Model Comparison Results
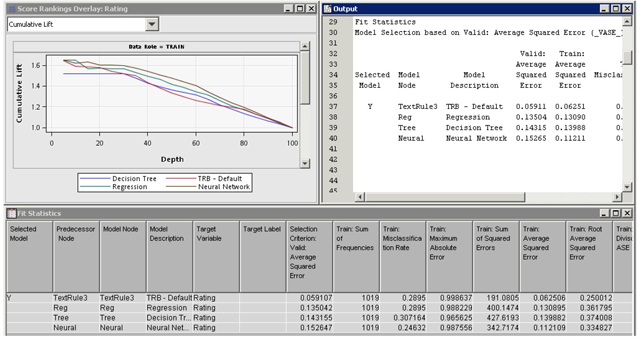
It seems that the text rule builder model has outperformed the other models using the chosen criteria for comparing models. Of course, if you change the selection criteria, the model selected might be different.
Summary
Rules identified from the Text Rule builder revealed valuable insights on reasons for positive and negative experiences with a hospital visit. These rules are easily interpretable and can serve as a starting point for a sophisticated sentiment analysis exercise. The Boolean rules can also be directly used with SAS Content Categorization Studio for further analysis. From the results it is very clear that the hospital needs to improve on rest room maintenance, rescheduling process, and waiting times. Most of the patients seemed to be satisfied with the care and consultation they received from the physician.
Mistakes by experts in rating textual comments are expected (after all they are human!) and such mistakes may seriously impact model performance. In situations such as these the active-learning functionality in the rule-builder node can be used for improving model performance. In this case study, the text rule builder with active learning adjustments seems to outperform traditional data mining models (such as decision tree, regression, and neural network) built using output from text cluster and text topic nodes.