
Chapter 14. Data-oriented programming
This chapter covers
- Code as code, and data as data
- Data as data
- Data as code
- Code as data
- Code as data as code
Of primary importance to functional programming languages, and Clojure is no exception, is the relationship between an application’s data elements and the code manipulating it. Some programming languages, in support of their paradigms, view the code/data relationship differently. In this chapter, we’ll talk about the data/code split in some modern languages and the way effective Clojure programs are constructed to blur that line. We’ll discuss how elevating data to the level of information can enable interesting simulation and testing solutions by being explicit about data in terms of time. We’ll touch on some representations of data and dig into the power achieved by having code that is data. But to start, we’ll talk about data on its own terms.
14.1. Code as code, and data as data
In a typical application, perhaps created in Java, the way we think of data is summarized in the following table:
|
Product ID |
Product name |
Supplier ID |
Price |
Unit sales |
Total |
|---|---|---|---|---|---|
| 0 | Pumpkin spice | 0 | 0.99 | 400,000 | 396,000.00 |
| 1 | Dung spice | 1 | 1.99 | null | null |
Another way of viewing this same data is at the level of the definition language used to describe it. For the purpose of illustration, we’ll use a rectangle definition language (RDL) that is a variant of SQL:[1]
1 We ran and tested our SQL code on the SQL Fiddle site at http://sqlfiddle.com.
create table COFFEE (COF_ID int NOT NULL AUTO_INCREMENT, COF_NAME varchar(64) NOT NULL, SUP_ID int NOT NULL, PRICE numeric(10,2) NOT NULL, UNIT_SALES integer, TOTAL numeric(10,2), PRIMARY KEY (COF_ID), FOREIGN KEY (SUP_ID) REFERENCES SUPPLIERS (SUP_ID));
Compared to the earlier table, the definition language used to describe our data is far more opaque. For those of you accustomed to viewing SQL, the definition may appear clear (regardless of your opinion on its structure). But we hope you agree that the definition is a step removed from the purity of the table-based layout. We can tolerate a conceptual gap between data and its schema because their purposes are related, yet different. What about accessing the data via query? A simple example is as follows:
select COF_NAME from COFFEE where COFFEE.UNIT_SALES is NULL; --> COF_NAME --> -------- --> Dung spice
This query deals in the language of the rectangle and is fairly straightforward in its intent: find all product names without a sale. But as we’ll explore in the next section, the distance between data and the way we access it in a language like Java is widened further.
14.1.1. A strict line betwixt
To access the data discussed so far in Java, the following snippet suffices:
// ... some details elided
public static void viewTable(Connection con) throws SQLException {
Statement stmt = null;
String query = "select COF_NAME, SUP_ID, " +
"PRICE, UNIT_SALES, TOTAL from " +
"COFFEE_DB.COFFEE";
try {
stmt = con.createStatement();
ResultSet rs = stmt.executeQuery(query);
while (rs.next()) {
String coffeeName = rs.getString("COF_NAME");
int supplierID = rs.getInt("SUP_ID");
float price = rs.getFloat("PRICE");
int sales = rs.getInt("UNIT_SALES");
float total = rs.getFloat("TOTAL");
doPrint(coffeeName, supplierID, price, sales, total);
}
} catch (SQLException e ) {
JDBCTutorialUtilities.printSQLException(e);
} finally {
if (stmt != null) { stmt.close(); }
}
}
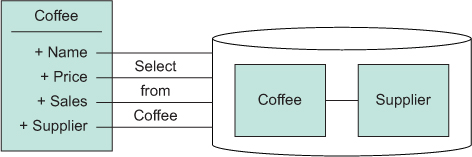
Where did the data go? It’s certainly in there, as shown by the creation of variables like coffeeName and price; but the data and its method of access in Java are obfuscated by the baggage required for query construction, database connection, data unwrapping, and exception handling. If the data is likened to a meal, then this approach to access is a recipe or even a menu for data access. Data manipulation in Java via this obfuscation sadly mistakes the menu for the meal.[2] In fact, the obfuscation works to draw a severe line between the data in question and the code used to access it, as illustrated in figure 14.1.
2 With apologies to Alan Watts for our use of the menu analogy.
Figure 14.1. Accessing rectangular data in Java is often a chore, highlighting the vast differences in the data model and the code to access it.

By default, there is a fundamental disparity between Java code and the rectangle model of data modeling. But as we’ll show in the next section, there have been efforts, some with millions of person-hours behind them, to shorten the gap between the pure rectangle model of data and Java’s class-based paradigm.
14.1.2. ORMG
Perhaps it would be nice if Java allowed data rectangles to be directly expressed in terms of the language, with a transparent mapping between the two worlds. As it turns out, many[3] such tools and libraries exist to facilitate this condition; they’re typically known as object-relational mappers (ORMs). Without getting into the specifics of implementation, figure 14.2 gives a good summary of the ORM modus operandi.
3 Both authors are independently guilty of creating ORM frameworks in the past.
Figure 14.2. Via various programming magicks, an ORM provides a class-instance interface that maps to database tables on the back end for its property values.
In short, an ORM such as the popular Hibernate[4] allows a Java programmer to work in the idiom they’re familiar with—that of classes and instances—instead of the more foreign and seemingly disconnected[5] world of the database. In concrete terms, defining an ORM-able Java class in a fictional ORM for the coffee model might look like the following:
4 Hibernate, a JBoss project, is available at www.hibernate.org.
5 The authors are aware that there is a mountain of past and present research into the use and development of object databases, but for various reasons such databases haven’t caught on in the greater OO world. The late Daniel Weinreb wrote frequently on object databases at http://danweinreb.org/blog/category/objectstore.
@Entity
@Table(name="COFFEE")
public class Coffee implements Ormish {
@Id
Long id;
@Column(name="COF_NAME")
String name;
@Reference(via="SUPPLIERS")
Supplier supp;
... more elided
}
Through some compile-time bytecode hacking, the fictional ORM would write the needed database-access code and exception handling automatically, allowing the following familiar interactions:
Supplier supp = new Supplier("Quarks Coffee");
supp.save();
Coffee coff = new Coffee();
coff.setName("Pumpkin spice");
coff.setSupplier(supp);
coff.setPrice(1.99);
coff.save();
Although this certainly narrows the gap between the class-based model of Java and the underlying rectangles, the use of an ORM is deficient in a wholly different way: its model, while preserving data, lacks information.
14.1.3. Common ways to derive information from data
Hearkening back to our original data model, a fundamental problem is highlighted by the way that the price field is handled. Zeroing in on the price column for the data predicates the problem, as shown at right.
|
Product name |
Price |
|---|---|
| Pumpkin spice | 0.99 |
| Dung spice | 1.99 |
Based on this data, you can answer only a single question: what is the price of coffee X right now? But what if you wanted to know what the price was last week? That information isn’t available! This condition illustrates the difference between data and information. That is, although this model provides a mechanism for storing data[6] such as names and prices, it’s insufficient for providing information because, as we mentioned way back in section 1.4.1 (recall the runner whose leg was being erased), this type of mutable model has no notion of time. Therefore, when you see a piece of data that says “The price of pumpkin spice is 0.99,” no robust information is provided. A couple questions immediately spring to mind when looking at the data:
6 Yes, we realize this particular model can supply more information with added historical tables and foreign keys, but it’s meant to convey the general failings of place-oriented programming (PLOP).
- Has the price always been 0.99?
- What is the price unit? Dollars? Pounds? Bitcoins?[7]
7 You might also want to know about quantities, IDs, and so on, but we’re intentionally keeping things small for the sake of discussion.
This model is a common approach to relational and object-oriented data modeling in general that views data as a “place” to modify as conditions in a program’s manifest. We’ll talk further about the limitations of a place-modification data scheme presently.[8]
8 That’s not to say that PLOP is necessarily bad. As a model for data, it’s severely limited. There will always be programming domains where in-place data modification is needed for speed or abstraction (for example, many systems development problems).
14.1.4. PLOP
A place oriented programming (Hickey 2012) model is one where data representing entity state is updated in place over the data that existed previously, thus obliterating any notion of time and seriously subverting object equality. As it stands, the PLOP model is prevalent in many popular programming languages. But functional languages in general, and Clojure in particular, eschew the widespread use of PLOPing and instead advocate a purer model where values take center stage. Before we discuss the relative virtues of PLOP versus data-oriented programming (DOP), let’s recap what we’ve covered in this section.
A strict line between data and code
Many programming languages make a stark distinction between program data and the code that operates on it. That is, accessing raw data in a language like Java has an alien feel: the code is here, and the data is over there.
ORMs are a bandage over a gaping wound
Although an ORM can close the gap between the conceptual models of the relational (rectangular or table-based) and an object-oriented language like Java, its use only exacerbates a problem inherent in popular implementations. Rampant mutation as a foundational model of data representation is inherently problematic.
Place-oriented programming obliterates information
The problems of a data model built on PLOP manifest themselves in the obliteration of both time and, subsequently, information. This occurs because when data is updated in place, the previous value is lost by default, and special care is needed to maintain it. But if we instead view data as unchangeable values, as Clojure advocates, then the information problem brought about by PLOP disappears. In the next section, we’ll explore one of the facets of data-oriented programming: dealing with data on its own terms—as values.
14.2. Data as data
Data can take various roles in your applications, but more often than not it takes the role of, well, data. In other words, data is represented as an unchanging value. If you’ll recall from section 1.4.1, our definition of value is an object’s constant representative amount, magnitude, epoch, or worth. No one is surprised when we claim that the number 108 is a value; but as we’ve mentioned, Clojure’s approach of treating even composite types as values is somewhat surprising for those accustomed to the PLOP model.
In this section, we’ll discuss in detail Clojure’s value-based data support and benefits. We’ll cover the recent addition of tagged literals and their general usage and role in an extensible data notation. Before we dig into that, we’ll first discuss some of the benefits of viewing any given datum strictly as a value.
14.2.1. The benefits of value
There are numerous benefits to centering your programs around values rather than mutable places. But as we discussed in section 6.1, the immutability of values provides some abstract benefits outright:
- Reasonable —You don’t need to worry about change over time.
- Equality —Equal values are always equal, forever.
- Inexpensive —Reference sharing is cheaper than defensive copying.
- Flatness —All subcomponents of a value are also values.
- Sharing —Sharing values across threads or in a cache is stress-free.
These points are wonderful in the abstract, but it would be nice to see some tangible benefit also. In the next section, we’ll walk through a few such benefits and provide some motivating examples along the way.
Values can be reproduced
One huge advantage of Clojure values is that they are what they look like. That is, the textual form {:a 1, :b 2} is a map with two entries in it. No magic or high-wire balancing act is required to reproduce this map. It is what it looks like it is. This seems fundamental, but a similar map in Java, although close, isn’t precisely the same syntactically as it is in itself:
Map<String,Integer> stuff = new HashMap<String,Integer>() {{
put("a", 1);
put("b", 2);
}};
This is relatively compact as far as Java goes, but there is a problem: this code is code—it’s not data. The creation of the data occurs as a result of executing the code. To build a Java map requires the execution of code, whereas in Clojure a map is a literal {:a 1, :b 2} away.
Values can be reproduced and fabricated
Because a data value in Clojure is immutable, creating one occurs via straightforward data manipulation. Likewise, fabricating values is simple, as shown using Clojure’s built-in rand-int function:
(rand-int 1024) ;;=> 524 (+ (rand-int 100) (rand-int 100)) ;;=> 114
Sure, that’s pretty fun for rolling during Dungeons and Dragons games, but how much harder would it be to generate a more complex structure?[9] As it turns out, not too difficult:
9 Although it’s fun to create a random data generator in a few minutes, we advise the use of a Clojure-contrib library called clojure.data.generators that is more feature-rich and robust. It’s located at http://github.com/clojure/data.generators.
![]()
To begin, you defined a restricted sequence of characters for the generation of strings:
(defn rand-str [sz alphabet] (apply str (repeatedly sz #(rand-nth alphabet)))) (rand-str 10 ascii) ;;=> "OMCIBULTOB"
You can generate strings from your alphabet by choosing a certain number of random characters and joining them together in the end. This function also forms the basis for symbol and keyword generation:
(def rand-sym #(symbol (rand-str %1 %2))) (def rand-key #(keyword (rand-str %1 %2))) (rand-key 10 ascii) ;;=> :JRFTYTUYQA (rand-sym 10 ascii) ;;=> DDHRWLOVME
Now you can use these generators to build composite structures like vectors:
(defn rand-vec [& generators]
(into [] (map #(%) generators)))
(rand-vec #(rand-sym 5 ascii)
#(rand-key 10 ascii)
#(rand-int 1024))
;;=> [EGALM :FXTDTCMGRO 703]
And even maps:
(defn rand-map [sz kgen vgen]
(into {}
(repeatedly sz #(rand-vec kgen vgen))))
(rand-map 3 #(rand-key 5 ascii) #(rand-int 100))
;;=> {:RBBLD 94, :CQXLR 71, :LJQYL 72}
And that’s all there is to creating a useful little library of data fabricators. What does the same look like in Java?
Values facilitate testing
Extrapolating from the previous section, perhaps you can imagine how to use the random data for testing purposes. The basic unit of reproducible testing is aptly named unit testing. Unit tests are meant to determine if some base-level unit of source, usually a function, adheres to a known behavior given known input conditions. Utilizing values as input to pure functions couldn’t be easier. Take the following small example:
(assert (= [1 2 3] (conj [1 2] 3)))
This code says that the conj of a vector [1 2] and 3 is the vector [1 2 3]. The advantage of using values directly in the unit test is that a value speaks for itself. It’s clear what is being tested in this unit test. Sticking with value testing allows for easy differential checking should something go wrong. In a good unit-testing framework, failing tests should show the differences between the expected and actual values. We can show what this looks like using Clojure’s packaged tools:
(use 'clojure.data) (diff [1 2 3] [1 2 4]) ;;=> [[nil nil 3] [nil nil 4] [1 2]]
The result shows that the first item has a 3 in its last position, whereas the second has a 4; and both items have the values [1 2]. Values and their difference views are valuable for facilitating unit testing.
We’ve already shown that fabricating values is straightforward. But we can extend the idea of fabrication to the notion of generative testing. Clojure’s contrib community has a generative testing library named clojure.test.generative[10] that provides a set of tools for describing the operational bounds of functions. This mini-language of operational bounds then executes a specifications checker fed by randomly generated data adhering to the data-specification bounds for the functions under test. Take the following specification example as illustration:
10 You can find more information about clojure.test.generative at https://github.com/clojure/test.generative.
(defspec slope-rules
(fn [p1 p2] (slope :p1 p1 :p2 p2))
[^{:tag (vec long 2)} p1, ^{:tag (vec long 2)} p2]
(assert (float? %)))
This specification says that for any two vectors, each containing two long integers, the slope function returns a floating-point number.[11] The machinery behind clojure .test.generative will generate millions of random long integers and run them all against slope to ensure that at no point does the specification fail. Of course, this isn’t a full specification of slope, but a full treatment of generative testing is outside the scope of this book.[12]
11 Note that a fully conformant slope function might also return the constant Double.POSITIVE_INFINITY when given a vertical line. We intentionally avoid doing so, to focus the discussion rather than diverging into a discussion about Java numerics and the like.
12 Another emerging option in this space is simple-check by Reid Draper, available at https://github.com/reiddraper/simple-check.
Simulation testing is a technique that feeds representational actions into a system to simulate interactions, stimulate (and simulate) subsystems, and model load. If your systems are driven by data values instead of entirely by the execution of source code, then simulation testing becomes a reasonably straightforward approach to augmenting your existing testing strategies. We’ll run through an example of a simulation test in the next section, but for now we’ll continue with our discussion.
Values facilitate debugging
Like most world-weary programmers, we’ve created our share of systems that dump out mountains of log data in hopes of helping to debug errors that might occur at runtime. In a PLOP-centric system, it’s often difficult to get a handle on the state of a system at any given point of failure. But in a value-centric system, a well-placed log statement may make all the difference. Imagine you have a function in your system of the following form:
(defn filter-rising [segments]
(clojure.set/select
(fn [{:keys [p1 p2]}]
(> 0
(/ (- (p2 0) (p1 0))
(- (p2 1) (p1 1)))))
segments))
You can use this function to (presumably) pull out line segments in a set with a rising slope, like so:
(filter-rising #{{:p1 [0 0] :p2 [1 1]}
{:p1 [4 15] :p2 [3 21]}})
;;=> #{{:p1 [4 15], :p2 [3 21]}}
But when the system runs, the line segments drawn have a downward-sloping descent. Fortunately, in the universe where you’ve placed log statements perfectly, you have a snapshot of the full set of line segments. You can use that set directly by feeding it textually into the filter-rising function for debugging purposes, finding that the vector indexes were reversed.[13] There was no need to set up a brittle system state to find this problem. Instead, the values in play were logged and used as is to debug the problem at hand.[14]
13 The division line should be (/ (- (p2 1) (p1 1)) (- (p2 0) (p1 0))))) instead.
14 Although if you were simulation testing and/or using pre- and postconditions, you probably would have caught the problem before now.
Values are language independent
The final benefit of programming with values is the idea that values transcend programming languages. Think of all the systems on the internet connected by a stream of JSON packets flowing back and forth. JSON is by nature a pure data structure composed of maps, arrays, strings, numbers, and the constants, true, false, and null. This ubiquity and simplicity of JSON’s primitives facilitates the current explosion in polyglot systems.
But these basic primitives, although basic as can be, are insufficient for modeling some types of data. For example, a mathematical set of data where there are no repeated elements can be simulated via a JSON array and strict API convention. In the chaotic world of the net, though, there are seldom guarantees that the sender believes in mathematical sets, thus potentially wreaking havoc on your server.
It would be nice if JSON had sets as a primitive data type instead of foisting the guarantees of set-ness onto the receiver. Do you see where this is leading? Clojure has a set type, and its literal data structures are compact, semantic, and easy to describe and therefore parse. Why can’t we use Clojure data literals instead of JSON? As it turns out, we can, and many Clojure applications do that very thing.
Both JSON and Clojure share a subset of similar data elements, including array-likes (vectors in Clojure), maps, strings, floats, truthiness, and nullity. But Clojure literal data provides a richer superset, including the following:
- More data types —These include characters, lists, sets, larger precision numbers, symbols, and keywords.
- Namespacing —Symbols and keywords allow prefixes.
- Nonstring keys —Any of Clojure’s types can serve as map keys.
- Extensibility —Clojure provides a way to extend the reader to accept userdefined data literals. A simple example is that in JSON, a date is encoded as a string, with the knowledge that it’s in fact a date encoded out of band or via some sort of project-specific convention. In Clojure, a date literal is encoded via the tagged-literal capability and read by the proper tag reader.
Clojure programmers already use Clojure data over the wire because of these advantages. Others can as well—see the section “Extensible Data Notation (EDN).”
In the next two sections, we’ll talk about using and extending Clojure’s core data literals via a recently added feature: tagged literals.
14.2.2. Tagged literals
In Clojure 1.4, a capability was added that provides a way to programmatically extend the reader. The syntax of the readable forms allowed via this new functionality looks like the following:
#a-ns/tag some-legal-clojure-form
For example, Clojure now includes numerous tagged literals, including universally unique identifiers (UUIDs) and a time-instance form that can be used as follows:
#inst "1969-08-18" ;;=> #inst "1969-08-18T00:00:00.000-00:00"
The instance literal starts with a # followed by the tag inst and ends with a legal Clojure string "1969-08-18". We used a simplified date in the string, but the instance reader allows a richer time specification adhering to the RFC-3339[15] time-stamp specification.
15 You can find the murderous details at www.ietf.org/rfc/rfc3339.txt.
Generic syntax, deferred type
An interesting facet of this new capability is that the thing generated by the inst tag parser is specific to the host (JVM, JavaScript, and so on) of the Clojure implementation. That is, for Clojure, the type is by default a java.util.Date instance, whereas in ClojureScript it’s an instance of the built-in Date type. The implication of this fact is important: using the same tagged syntactic form, the precise runtime types are left up to the language reading the form.
Extensible Data Notation (EDN)
Although JSON has an advantage in that it’s a minimal data-exchange format directly representable as JavaScript, it’s a bit too spartan. That is, there are classes of data types and usages that can’t be easily represented in JSON but that nonetheless are legitimate for the purposes of exchange.
In addition, JSON is a fixed format and doesn’t support extensibility of the base literal types as XML does. With the addition of the tagged-literal feature, Clojure also allows extension of its literal notation. An informal standardization effort is underway to formalize the use of Clojure data literals and its tagged extensions as Extensible Data Notation (EDN, pronounced “Eden”).
Defining new tagged-data source-code literals
Imagine that you wanted to create a data literal of the form #unit/length [1 :km] that provided a way to describe a unit of measure corresponding to length. The value of the syntactic tag #unit/length would be a numeric value relative to some base unit. The benefit of a literal form for such a thing is that the literal itself is self-explanatory (as the redundancy of the previous sentence shows).
You may recall from chapter 7 that we showed a way to recursively define units of measure using a map, and likewise derive their values in terms of a base unit. As it turns out, you can use the derivation function convert directly to implement the #unit/length tag parser. The problem, of course, is that tag-reader functions expect one argument, but convert takes two. This is an easy fix because you can use partial to define a new function as shown in the following listing.
Listing 14.1. Function to read distance units
(in-ns 'joy.unit)
(def distance-reader
(partial convert
{:m 1
:km 1000,
:cm 1/100,
:mm [1/10 :cm]}))
But before you can start using distance-reader, you need to tell Clojure to use the function whenever it encounters the #unit/length tag. To do that, you need only create a file called data_readers.clj at the root of your classpath (for example, in our-project-directory/src/) with a simple map of symbol to symbol, like so:
{unit/length joy.unit/distance-reader}
The data_readers.clj map keys define the literal tags, and their associated values name a fully qualified var containing a function that will receive the tagged data packet to parse. The type of the return value of the data parser is relative to the use case in general, but in this example it will be a number.
With the data_readers.clj file properly populated, you can start a REPL and test the results:
#unit/length [1 :km] ;;=> 1000
If you’ll recall, the length parser used meters as its base unit, so the value of the tagged type is legitimate. You can also manipulate the data readers used to read Clojure types at runtime by dynamically binding a var named *data-readers* with a map in the same shape as you’ve created. To set this up, define a new reader called time-reader:
(in-ns 'joy.unit)
(def time-reader
(partial convert
{:sec 1
:min 60,
:hr [60 :min],
:day [24 :hr]}))
You use the time-reader function as a data reader dynamically as follows:
(binding [*data-readers* {'unit/time #'joy.units/time-reader}]
(read-string "#unit/time [1 :min 30 :sec]"))
;;=> 90
And indeed, 1 minute and 30 seconds is 90 seconds.
One important feature added before the 1.5 release was the inclusion of a *default-data-reader-fn* var accessible to user code. This var, when bound to a function, serves as a catch-all for literal tags that don’t have any associated readers. Observe the following:
(binding [*default-data-reader-fn* #(-> {:tag %1 :payload %2})]
(read-string "#nope [:doesnt-exist]"))
;;=> {:tag nope, :payload [:doesnt-exist]}
*default-data-reader-fn* is useful when you encounter tags in a source file that you’re not prepared to handle. But as a general-purpose data-exchange mechanism, the use of *data-readers*, *default-data-reader-fn*, read-string, and the data_readers.clj file are less than ideal. The reason is that these mechanisms work at the level of the Clojure language-read mechanism. Therefore, using them to handle data from untrusted sources (from an HTTP POST, perhaps) opens up Clojure’s privileged runtime mechanisms to potential exploitation—via arbitrary constructor execution, for example. Therefore, the use of *data-readers*, *default-data-reader-fn*, and read-string is not recommended for processing data from untrusted sources. Instead, we highly recommend you use the utilities in the clojure.edn namespace for handling Clojure data sources, as we’ll discuss next.
Handling Clojure’s EDN data using clojure.edn
The potential of using Clojure data literals, or EDN, as an extensible data-exchange format is extremely promising. Many Clojure programmers already use the EDN data formats as wire-transfer formats for things such as web-service data exchange in addition to general-purpose formats for configuration files and the like. But until version 1.5, we were forced to use privileged built-in mechanisms like read-string to process data. Fortunately, the version 1.5 release included a new namespace clojure.edn that provides the safe EDN data-read functions clojure.edn/read and clojure.edn/read-string. Recall that in our discussion of tagged literals, we mentioned that Clojure has a built-in UUID form that looks like this:
#uuid "dae78a90-d491-11e2-8b8b-0800200c9a66"
The UUID tagged literal resolves to a relevant UUID type in either Clojure or ClojureScript, but for the former you can expect the following type resolution:
(class #uuid "dae78a90-d491-11e2-8b8b-0800200c9a66") ;;=> java.util.UUID
We won’t go into the details of why and where you might wish to use a UUID, but we can show you how to use clojure.edn/read-string to read one:
(require '[clojure.edn :as edn]) (edn/read-string "#uuid "dae78a90-d491-11e2-8b8b-0800200c9a66"") ;;=> #uuid "dae78a90-d491-11e2-8b8b-0800200c9a66"
This example requires the clojure.edn namespace and uses its version of read-string to process a UUID tagged literal. Of course, EDN readers work on other Clojure forms:
(edn/read-string "42")
;;=> 42
(edn/read-string "{:a 42, "b" 36, [:c] 9}")
;;=> {:a 42, "b" 36, [:c] 9}
But you’ll run into issues if you try to process a tagged literal that you’ve defined yourself:
(edn/read-string "#unit/time [1 :min 30 :sec]") ;; java.lang.RuntimeException: No reader function for tag unit/time
The “limitation” is that the clojure.edn functions, by design, make no assumptions about how to parse an unknown tag and require that you tell them how to handle tags in place. Therefore, the clojure.edn/read-string function accepts an options map that lets you specify the tag readers to use on the string processed:
(def T {'unit/time #'joy.units/time-reader})
(edn/read-string {:readers T} "#unit/time [1 :min 30 :sec]")
;;=> 90
As shown, the options map T passed into clojure.edn/read-string specifies the :readers to use on the input string. You can also specify a default reader function using the :default mapping:
(edn/read-string {:readers T, :default vector} "#what/the :huh?")
;;=> [what/the :huh?]
We can’t emphasize enough that for processing untrusted EDN data, we highly recommend you use the utilities in the clojure.edn namespace. We think you’ll enjoy using Clojure at every level of your architecture, including as the data format passing between its components.
14.3. Data as code
Sure, you say, data is data. There’s nothing terribly groundbreaking in that statement, right? Perhaps so, but as it stands, many programming languages seem to get data wrong. Fortunately, a respectable trend is taking root in the way applications and services are constructed: the data-programmable engine. In this section, we’ll talk about the ways data can be viewed as programming elements and the implications of that view on how we can develop more robust systems.
14.3.1. The data-programmable engine
Imagine a generic model of computation representing some sort of behavior called an Engine. The Engine might take some data as input, perform some action, and then perhaps return some more data. A block model of the Engine looks like figure 14.3.
Figure 14.3. Many programs can be viewed as an Engine of computation, taking an input and performing some action.

If you’ve been paying attention, this figure could be used numerous times throughout this book, including in the introduction to functional programming. When we view functions as models for a computation Engine, the idea of data as code begins to reveal itself, as shown in the modified image in figure 14.4.
Figure 14.4. The data-programmable model is composed of an Engine taking a specification, performing some actions, and eventually returning or materializing a result.

In the next section, we’ll cover a few well-known examples of data-programmable engines, including one of our own design.
14.3.2. Examples of data-programmable engines
The data-programmable engine isn’t a new concept. In fact, if you look deeply enough, you’ll find that systems built this way have existed since the dawn of computation. In an attempt to give a flavor of how this model might benefit you, we’ll start by discussing a few well-known engines before you create one of your own.
Ant
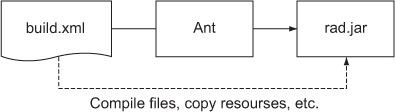
One famous example of the data-programmable engine model is the famous Ant system, used for building Java source projects. Ant as a data-programmable engine is shown in figure 14.5. The specification for Ant is[16] an XML document containing build, maintenance, and testing directives in a form that Ant is able to interpret.
16 In the early days of Ant history, the XML files were fairly limited and straightforward in their effects. But as Java projects go, Ant became much more complex, allowing all sorts of wild directives including XML-ified conditionals!
Figure 14.5. The Ant engine: Ant takes a build specification and returns a build artifact.
An easy example of a specification is as follows:
<project name="EngineSummer" basedir="." default="compile">
<property name="src" value="src"/>
<property name="output" value="classes"/>
<target name="compile" depends="create">
<javac destdir="${output}">
<src path="${src}"/>
<classpath refid="java"/>
</javac>
</target>
</project>
This XML snippet tells the Ant engine to compile all the sources in the src directory into the output destination. Bear in mind that this is a naive script, but we think the intent is clear. One advantage you’ll find when using data this way is that the input data is declarative in form.
Clojure
It behooves us in covering data-programmable engines to mention the quintessential example, the Lisp compiler. Because this is a book about Lisp, we’ll talk a bit about Clojure’s compiler. Viewing the compiler as an Engine fits the model we’ve outlined throughout this section, as shown in figure 14.6.
Figure 14.6. The Lisp compiler as the ultimate computation engine. The Clojure compiler is a data-programmable engine taking Clojure data as input and returning Clojure data as a result.

We’ll talk more about Clojure’s compiler as a programmable device in section 14.5, but for now we’ll wrap up by exploring a synthesized example: a simple event-sourced engine.
14.3.3. Case study: simple event sourcing
Event sourcing is an interesting architectural model that defines system state solely in terms of system events (Fowler 2005). For example, imagine a system that models a baseball player’s statistical achievements. One way to model such a system is to store a table of the player’s statistics, such as how many times he’s batted and the number of hits:
|
At-bats |
Hits |
Average |
|---|---|---|
| 5 | 2 | 0.400 |
But an equally good model, and one that has interesting properties, is an event-sourced model. In an event-sourced model, the state is derived from a sequence (a strict sequence isn’t always required) of events pertaining to the domain in question. In the case of the baseball player, an example is shown in table 14.1.
Table 14.1. Baseball events
|
Event number |
Result |
|---|---|
| 1 | :out |
| 2 | :hit |
| 3 | :out |
| 4 | :hit |
| 5 | :out |
At the end of the events, the state of the player in question is exactly the same: five at-bats with two hits. But with event sourcing, it’s derived from the events themselves.
Events as data
Before we explore the implementation of a simple event sourcing engine, we’ll take a moment to make a point that should ring true based on the trajectory of this chapter. As we mentioned in section 14.2, recent advances in system design have taken advantage of a client-server model exchanging data in a regular format (such as JSON). But we can extend this idea further by exchanging event data between disparate, polyglot systems (written in different programming languages). Although the codebases can take any form in such systems, their behaviors are driven via events toward a common goal (see figure 14.7).
Figure 14.7. Integrating polyglot systems using events as data

Systems built this way are made possible by observing that the events forming the unit of currency in an event-sourced model are themselves data! This is a powerful idea (did you notice the exclamation mark?) because if your events are data, then they can be persisted in a database and served in a straightforward way to re-create a system’s state at any time in the future. This is the model that we’ll sketch.
A simple event-sourced model
The example event-sourced model starts with a snapshot of some state. In the case of the baseball world, it’s a map like the following:
{:ab 5
:h 2
:avg 0.400}
This is similar to a data table except that this state is never directly modified, but instead is derived from events, which themselves are maps:
{:result :hit}
To get from an event or a sequence[17] of events requires a few auxiliary functions. First is a function called valid? that checks the form of an event.
17 For the sake of simplicity, we’ve decided to ignore explicit sequence values in the event maps. But if you take this path, you may need them.
Listing 14.2. Checking the form of an event
(ns joy.event-sourcing)
(defn valid? [event]
(boolean (:result event)))
(valid? {})
;;=> false
(valid? {:result 42})
;;=> true
Next you need an effect function that takes a state and event and applies the event to the state in the proper way.
Listing 14.3. Event-sourcing function that affects state

Running effect through a few tests validates your thinking:
(effect {} {:result :hit})
;;=> {:ab 1 :h 1 :avg 1.0}
(effect {:ab 599 :h 180}
{:result :out})
;;=> {:ab 600 :h 180 :avg 0.3}
It would be nice to use the valid? function before applying an event to your state, so define a new function that uses it:
Listing 14.4. Function that applies an effect only when the event is valid
(defn apply-effect [state event]
(if (valid? event)
(effect state event)
state))
You can test apply-effect in place like so:
(apply-effect {:ab 600 :h 180 :avg 0.3}
{:result :hit})
;;=> {:ab 601, :h 181, :avg 0.3011647254575707}
Finally, you can define another function effect-all that takes a state and a sequence of events and returns a final state.
Listing 14.5. Event-sourcing, mass-effect function
(def effect-all #(reduce apply-effect %1 %2))
Again, you can test effect-all in isolation:
(effect-all {:ab 0, :h 0}
[{:result :hit}
{:result :out}
{:result :hit}
{:result :out}])
;;=> {:ab 4, :h 2, :avg 0.5}
Taking effect-all for a spin proves the model:

You can now feed these 100 random events into the effect-all function to see what happens:
(effect-all {} events)
;;=> {:ab 100 :h 32 :avg 0.32}
What you have at the end of the call to effect-all is a snapshot of the state at the time of the hundredth event. Rewinding is as simple as applying only a subset of the events:
(effect-all {} (take 50 events))
;;=> {:ab 50 :h 14 :avg 0.28}
The events can be sliced and diced in any conceivable way to garner information about the states at any given moment along the event stream. In addition, you can change the way states are saved to gather a historical timeline:
(def fx-timeline #(reductions apply-effect %1 %2))
(fx-timeline {} (take 3 events))
;;=> ({}
; {:ab 1, :h 0, :avg 0.0}
; {:ab 2, :h 0, :avg 0.0}
; {:ab 3, :h 1, :avg 0.3333333})
You could use fx-timeline to infer trends, build histograms, and many other useful actions. With an event-sourced model, the possibilities are seemingly endless.
Simulation testing
Throughout this chapter, we’ve highlighted ways that building programs around values facilitates certain ways of constructing solutions. One particularly interesting technique that arises from data orientation is the idea of simulation testing. As we hinted earlier, simulation testing is the act of feeding actions, represented as data, into a system or library to simulate interactions, stimulate subsystems, and model load. In this section, we’ll run through an example library used to process a simple model of baseball ability and generate possible statistical sets. The first part of the library, shown in the following listing, sets up the data model for ability representation.
Listing 14.6. Data model for representing baseball player abilities

The baseball library is built on a simple ability model: a ratio of player’s ability over total possible ability. You store the set of abilities as a set of maps so you can access the data in a way similar to how you might access a relational data store, but with an abstract lookup function.[18]
18 If you wanted to, you could create a data-source abstraction based on protocols that would include a lookup function. Because that isn’t the focus of this section, we leave this as an exercise for you.
Listing 14.7. lookup function
(lookup PLAYERS "Nick")
;;=> {:ability 8/25, :player "Nick"}
There’s nothing stunning about the lookup function, but it serves nicely as a cornerstone of an update function.
Listing 14.8. Applying a baseball result event to a database

The update-stats function takes a database value[19] and an event (:hit or :miss) and returns a new database with the updated player statistics:
19 Clojure favors values over mutable places, including at the database layer. Viewing the database as a value resulting from a function application is an extremely powerful paradigm (Hickey 2012).
(update-stats PLAYERS {:player "Nick", :result :hit})
;;=> #{{:ability 19/100, :player "Ryan"}
;; {:ability 8/25, :player "Nick", :h 1, :avg 1.0, :ab 1}
;; {:ability 13/50, :player "Matt"}}
As shown, when given a single event denoting a :hit by Nick, the database value returned shows the updated player stats for a single at-bat. You can make this more like a database write by creating another function named commit-event that assumes it gets a ref and updates its value using update-stats.
Listing 14.9. Transactionally applying result events to a data store
(defn commit-event [db event]
(dosync (alter db update-stats event)))
(commit-event (ref PLAYERS) {:player "Nick", :result :hit})
//=> #<Ref@658ba666: #{...}>
This is all fine and good, but we still haven’t shown the tenets of simulation testing. To move toward that discussion, let’s create a way to generate random at-bat events.
Listing 14.10. Generating a random baseball event based on player ability

As shown, rand-event takes advantage of the strength of values to build random at-bat events. Specifically, using the ability components, you build a proper event map based on the probability of either a :hit or :miss occurring.[20] Now that you have a way to create a single random event, it would be nice to create a function to build many random events.
20 We intentionally simplified the baseball ability model so as not to distract from the main point, but we can’t help but hope that Bill James never reads this section.
Listing 14.11. Generating a number of random baseball events

We decided to limit the rand-events function to accept a count of events that it creates. We could have written it to return an infinite seq of events but saw no reason to do so at the moment. In general, when creating APIs, if you’re unsure about the capabilities a given function should have, it’s a good idea to start with the most limited ability. It’s always easier to widen a function’s capabilities than to restrict them after creation. Regardless, you can see the rand-events function in action:
(rand-events 3 {:player "Nick", :ability 32/100})
;;=> ({:player "Nick", :result :out}
;; {:player "Nick", :result :hit}
;; {:player "Nick", :result :out})
Now that you have the event-generation component in place, it’s high time we explained a little about the kernel of a simulation-testing framework.[21] The domain of this library is, by design, amenable to simulation testing. That is, the players and the results of their abilities map nicely onto the notion of autonomous actors operating asynchronously within and on a system or library. Therefore, you can implement each player as a unique agent that stores its total event stream. The function that creates a unique agent per player is shown next.
21 The framework described in this section is motivated by the vastly superior Simulant library, located at https://github.com/Datomic/simulant. We highly recommend that you use that library rather than the one shown here.
Listing 14.12. Creating or retrieving a unique agent for a given player name

agent-for-player is a bit subtle, so we’ll explain it in depth. First, the function that takes a player name and returns a new agent instance
is memoized ![]() . This technique allows you to use the player name as an index to a table of agents without having to explicitly manage and
look up agents in a table. Clojure’s memoization machinery manages that entire process for you. Next, the agent that’s created
. This technique allows you to use the player name as an index to a table of agents without having to explicitly manage and
look up agents in a table. Clojure’s memoization machinery manages that entire process for you. Next, the agent that’s created
![]() is given a fairly dumb error handler
is given a fairly dumb error handler ![]() and put into failure mode on creation
and put into failure mode on creation ![]() . Although we don’t anticipate errors in this section, we felt it worth showing this neat memoization pattern, because we’ve
found it useful on occasion.
. Although we don’t anticipate errors in this section, we felt it worth showing this neat memoization pattern, because we’ve
found it useful on occasion.
The next function in the simulation-testing framework takes a “database” (that is, a ref) and an event and updates the contained players stats. It returns the agent that will perform the update.
Listing 14.13. Feeding an event into the data store and player event store

On its own, the feed function isn’t terribly interesting. Instead, a more useful function is one that operates on a sequence of events.
Listing 14.14. Feeding all events into a data store and player event stores

This listing is fairly straightforward. That is, it loops over a sequence of events and feeds each into the database and agent event vector. You can see feed-all operate over a sequence of 100 random events as follows:
(let [db (ref PLAYERS)]
(feed-all db (rand-events 100 {:player "Nick", :ability 32/100}))
db)
;;=> #<Ref@321881a2: #{{:ability 19/100, :player "Ryan"}
;; {:ability 13/50, :player "Matt"}
;; {:player "Nick", :h 27, :avg 0.27, :ab 100,...}}
The 100 random events for Nick appear to have been applied to the ref database. If you run this code yourself, you may occasionally see an :ab count slightly less than 100. This happens because agents are dispatched in a thread pool (as we talked about in section 11.2), and by the time the function returns its ref, all agents may not have been dispatched. We’ll handle this inconsistency later, but for now you can check the agent events vector manually to see if it looks sane:
(count @(agent-for-player "Nick")) ;;=> 100
The agent for Nick has 100 stored events, which is exactly what you expected. You can also use the effect-all function created earlier in this chapter to see if the stats match your expectations:
(es/effect-all {} @(agent-for-player "Nick"))
;;=> {:ab 100, :h 27, :avg 0.27}
This multisource verification of behavior is where simulation testing can shine. Coupled with the proliferation of data-oriented programming, verification of a simulation test can be a matter of data comparisons. Even in the face of stochastic processes, simulation testing can work to exercise a system along expected usage patterns.
The final function in this discussion of simulation testing is a driver named simulate, shown in the next listing.
Listing 14.15. Simulation driver

The simulate function is a fairly standard driver routine with a few points worth noting. First, all the messages are generated for every
player and interleaved into a single event stream ![]() . You do this to gain a modicum of parallelization among different agents that are fed events serially
. You do this to gain a modicum of parallelization among different agents that are fed events serially ![]() . As hinted at earlier, you use the await function
. As hinted at earlier, you use the await function ![]() to ensure that every agent has run its course before returning a snapshot of the resulting database value. If you were returning
the database reference, this use of await probably wouldn’t be necessary. Here’s simulate in action:
to ensure that every agent has run its course before returning a snapshot of the resulting database value. If you were returning
the database reference, this use of await probably wouldn’t be necessary. Here’s simulate in action:
(simulate 2 PLAYERS)
;;=> #{{:ability 8/25, :player "Nick", :h 2, :avg 1.0, :ab 2}
;; {:ability 19/100, :player "Ryan", :h 1, :avg 0.5, :ab 2}
;; {:ability 13/50, :player "Matt", :h 0, :avg 0.0, :ab 2}}
As a start, we asked simulate to run through only two events per player, and the database snapshot seems reasonable on return. Running simulate again with a higher event count should work similarly:
(simulate 400 PLAYERS)
;;=> #{{:ability 13/50, :player "Matt", :h 95, :avg 0.2375, :ab 400}
;; {:ability 8/25, :player "Nick", :h 138, :avg 0.345, :ab 400}
;; {:ability 19/100, :player "Ryan", :h 66, :avg 0.165, :ab 400}}
As before, you can use the effect-all function to process the raw event stream for a given player to see if it matches up with the database snapshots returned thus far:
(es/effect-all {} @(agent-for-player "Nick"))
;;=> {:ab 402, :h 140, :avg 0.3482587064676617}
And indeed, the small simulation of two events, plus the results of the large simulation results for 400 events, sum to the amount given by the raw event stream! Simulation testing is facilitated by data orientation and data collection on multiple facets of the same simulation executions. By collecting multiple sources of event data—the aggregate in the database and the raw event stream—you can derive one from the other to ensure that they match, even in the face of stochastic processes. This is powerful stuff.
Essential state and derived state
One particularly sharp (as the double-edged sword goes) aspect of the event-sourcing model is the differentiation between essential and derived state. The essential state is the state created from direct mappings in the event model, namely :ab (from the event count) and :h (from the :result type). The derived state is the data that exists only in code, derived from specific rules and conditions therein. In the baseball model, the :avg state element is derived from the mathematical relation between two essential elements.
By virtue of storing the events, you can easily make changes to live systems. That is, if a system’s state is the product of the event stream, then you should be able to re-create it at any time by re-running the events into a fresh system (Fowler 2011). But if the code generating the derived state changes in the interim, re-running the events may not result in the expected state. Using a language like Clojure that is built with data processing in mind helps to soften the pain of deep code changes affecting the generation of derived state.
Likewise, complications may arise if the form of the events in the system changes from one version to another. That you’ve used maps as the basis for your events provides agility in alleviating this particular complication; see section 5.6 for a deeper discussion of this matter. Providing the ability to rewind and fast-forward a system is extremely powerful, but it’s not without caveats.
By implementing an event-sourcing model, you can apply the data-programmable engine paradigm to state calculation. This is a powerful approach to constructing software, and we’ve only scratched the surface of its benefits. Alas, we now need to take a few pages to discuss the decidedly Lispian notion of code as data.
14.4. Code as data as code
In this final section of our exploration into data-oriented programming, we come full circle and explore the possibilities of viewing Clojure itself as the ultimate data-programmable engine. We’ll tie up the loose ends on a codebase to convert units of measure, and we’ll explore an approach to create domain-specific languages by viewing a practical domain specification as data and metaprogramming it into submission.
In most members of the Lisp family, the code syntax is a data representation, and Clojure is no different. Some interesting metaprogramming techniques come directly from this capability, as we’ll show next.
14.4.1. Hart’s discovery and homoiconicity
In October 1963, Timothy Hart, one of the original creators of Lisp, released a memo entitled “MACRO Definitions for LISP” (Hart 1963). In the memo, he discussed the observation that special operators called macros could operate on a data structure representing Lisp code, transforming it into another data structure prior to final evaluation. This was an elegant solution and an important conceptual leap in the development of Lisp. Most modern Lisps have a different mechanism for handling macros, but the general principle discovered by Hart holds true.
14.4.2. Clojure code is data
As you already discovered in chapter 8, Clojure code is composed of data elements. This condition of Lisp is known as homoiconicity, and it’s nicely summarized in figure 14.8.
Figure 14.8. Clojure code is a data structure that Clojure can manipulate.

Clojure (and most Lisp) code is a data structure that Clojure can manipulate. If a Clojure program is a data structure, then the code can be transformed by Clojure prior to execution. This, of course, is the condition that gives Clojure macros their power.
We won’t reiterate the fundamental dictums of macrology that we covered in chapter 8. But it bears noting that the Clojure compiler is essentially the ultimate data-programmable engine. In effect, it’s a meta-data-programmable engine. In the next section, we’ll go a bit further down this meta rabbit hole and see what comes out.
14.4.3. Putting parentheses around the specification
Many applications deal in measurements of differing units. For example, it’s widely known that the United States works almost exclusively in English units of measure, whereas most of the rest of the planet works in SI, or metric units. To convert[22] from one to the other isn’t an arduous task and can be handled easily with a set of functions of this general form:
22 There is a spectacular general-purpose JVM language named Frink that excels at conversions of many different units. We highly advocate exploring Frink at your next available opportunity: http://futureboy.homeip.net/frinkdocs/.
(defn meters->feet [m] (* m 3.28083989501312)) (defn meters->miles [m] (* m 0.000621)) (meters->feet 1609.344) ;;=> 5279.9999999999945 (meters->miles 1609.344) ;;=> 0.999402624
This approach certainly works if only a few functions define the extent of your conversion needs. But if your applications are like ours, then you probably need to convert to and from differing units of measure of many different magnitudes. You may need to convert back and forth between units of time, dimension, orientation, and a host of others. Therefore, it would be nice to be able to write a specification of unit conversions (Hoyte 2008) as a Clojure DSL and use its results as a low-level layer for high-layer application specifics. This is precisely the nature of Lisp development in general: each level in an application provides the primitive abstractions for the levels above it.
In this section, you’ll create a small specification and then convert it into a Clojure DSL using a technique that Rainer Joswig (Joswig 2005) called “putting parentheses around the specification.”
An ideal representation for a unit-conversion specification language would be simple:
The base unit of distance is the meter. There are 1,000 meters in a kilometer. There are 100 centimeters in a meter. There are 10 millimeters in a centimeter. There are 3.28083 feet in a meter. And finally, there are 5,280 feet in a mile.
Of course, to make sense of free text is a huge task in any language, so it would behoove us to change it so it’s easier to reason about programmatically but not so much that it’s cumbersome for someone attempting to describe unit conversions. As a first pass, let’s try to group the most obvious parts using some Clojure syntactical elements:
(Our base unit of distance is the :meter [There are 1000 :meters in a :kilometer] [There are 100 :centimeters in a :meter] [There are 10 :millimeters in a :centimeter] [There are 3.28083 :feet in a :meter] [There are 5280 :feet in a :mile])
This specification is starting to look a little like Clojure code, but it would still be difficult to parse into a usable form. Likewise, it would be difficult for the person writing the specification to use the correct terms, avoid spelling mistakes, properly punctuate, and so on. This form is still not useful. It would be ideal if we could make this into a form that was recognizable to both Clojure and a conversion expert. Let’s try one more time:
(define unit of distance
{:m 1,
:km 1000,
:cm 1/100,
:mm [1/10 of a :cm],
:ft 0.3048,
:mile [is 5280 :ft]})
This almost looks like the units map from chapter 7, except for a few minor details. We’ll eventually zero in on a specification that matches the form expected by the convert function from chapter 7, but there is a more pressing matter at hand. That is, although you can use the convert function directly, it assumes a well-formed unit conversion map. This is problematic for use in a DSL because the details of covert will leak out to users in the form of nasty exceptions or errors. Instead, let’s create a driver function that checks input values and reports more sensible errors.
Listing 14.16. Driving the calculation of compositional units of measure
(in-ns 'joy.units)
(defn relative-units [context unit]
(if-let [spec (get context unit)]
(if (vector? spec)
(convert context spec)
spec)
(throw (RuntimeException. (str "Undefined unit " unit)))))
The function relative-units uses the same unit-conversion map form as convert but does an existential check and error report on problematic input:
(relative-units {:m 1, :cm 1/100, :mm [1/10 :cm]} :m)
;;=> 1
(relative-units {:m 1, :cm 1/100, :mm [1/10 :cm]} :mm)
;;=> 1/1000
(relative-units {:m 1, :cm 1/100, :mm [1/10 :cm]} :ramsden-chain)
;; RuntimeException Undefined unit :ramsden-chain
We decided to avoid the natural language phrase “in a” because English isn’t good for a DSL. Natural language often lacks the precision of a simple yet regular form. Having said that, let’s now create a macro to interpret a unit specification:
(defunits-of distance :m :km 1000 :cm 1/100 :mm [1/10 :cm] :ft 0.3048 :mile [5280 :ft])
This is a simplification of the original verbal form of the conversion specification, but this final form is more conducive to parsing without appreciably sacrificing readability. The implementation of the defunits-of macro is presented in the next listing.
Listing 14.17. defunits-of macro

The macro defunits-of is different from any macro you’ve seen thus far, but it’s typical for macros that expand into another macro definition. In this book, you’ve yet to see a macro that builds another macro and uses multiple levels of nested syntax-quotes. You won’t likely see macros of this complexity often; but this example uses nested syntax-quotes in order to feed structures from the inner to the outer layers of the nested macros, processing each fully before proceeding. At this point you can run a call to defunits-of with the simplified metric-to-English units conversion specification, to define a new macro named unit-of-distance:
(unit-of-distance 1 :m) ;;=> 1 (unit-of-distance 1 :mm) ;;=> 1/1000 (unit-of-distance 1 :ft) ;;=> 0.3048 (unit-of-distance 1 :mile) ;;=> 1609.344
Perfect! Everything is relative to the base unit :m, just as you would like (read as “How many meters are in a _”). The generated macro unit-of-distance allows you to work in your given system of measures relative to a standard system without loss of precision or the need for a bevy of awkward conversion functions. To calculate the distance a home-run hit by the Orioles’ Matt Wieters travels in Canada requires a simple call to (unit-of-distance 441 :ft). The expansion of the distance specification given as (defunits-of distance :m ...) looks like this:
(defmacro unit-of-distance [G__43 G__44]
(* G__43
(case G__44
:mile 1609.344
:km 1000
:cm 1/100
:m 1
:mm 1/1000
:ft 0.3048)))
That is, the defunits-of macro is an interpreter of the unit-conversion DSL that generates another macro unit-of-distance that performs a straightforward lookup of relative unit values. Amazingly, the expansion given by (macroexpand '(unit-of-distance 1 :cm)) is that of a simple multiplication (* 1 1/100). This is an awe-inspiring revelation. We’ve fused the notions of compilation and evaluation by writing a relative units of measure mini-language that is interpreted into a simple multiplication at compile time!
This is nothing new, of course; Lisp programmers have known about this technique for decades, but it never ceases to amaze us. There is one downside to this implementation: it allows for circular conversion specifications (for example, seconds defined in terms of minutes, which are then defined in terms of seconds), but this can be identified and handled in relative-units if you’re so inclined.
14.5. Summary
This chapter has been a whirlwind tour of data-oriented programming. Clojure is particularly adept at data manipulation and handling values, and it should motivate you to find ways to make all your programs data-centric. Whether it’s viewing data as data or viewing data as the code for a programmable engine like Ant or Overtone, Clojure is agile enough to handle varying program architecture models.
Likewise, an idea prevalent in functional programming—state manipulation as the result of pure functions—maps nicely onto a promising architecture pattern called event sourcing. Finally, we couldn’t help showing you that by viewing Clojure and its compiler as programmable engines, you can, via macros, reach infinitely deep into the dark recesses of the metaprogramming vortex.
In the next chapter, we’ll put our feet firmly on the ground again and deal with important techniques and approaches to squeezing maximum performance from Clojure and ClojureScript.