
13
High Availability and Disaster Recovery
As an aspiring network professional, one of the core roles and responsibilities is to always ensure the network services and resources are always available and accessible to the users on the network. Within large organizations, many users depend on the availability of the network infrastructure to provide the availability of various network services and resources that are essential for ensuring the business is operating continuously.
In this chapter, you will explore various techniques that are commonly implemented by IT professionals to ensure their systems and networks are always up and running to provide the necessary services and resources for their users. You will dive into both high availability and various disaster recovery concepts and gain a solid understanding of how various technologies are used to ensure fault tolerance while providing maximum uptime for resources.
In this chapter, we will cover the following topics:
- High availability concepts
- Disaster recovery concepts
Let’s dive in!
High availability concepts
High availability (HA) is simply the ability of a system or a network to continuously operate without failure. For instance, network professionals implement various techniques and technologies into their network infrastructure to ensure it can continue operating without failing over a very long time. For instance, imagine if a switch or a router were to fail within a company; what will be the impact and how many users will be affected? What if the router was connecting the organization’s internal network to the internet service provider (ISP) network? All the users within the organization will be affected and if the company was depending on resources or services that are hosted on a cloud provider’s data center, those cloud resources will be inaccessible.
A common strategy for setting up HA within an organization is to implement fault tolerance in the form of redundancy in hardware components on devices and network infrastructure. For instance, imagine if a critical server within the company has one network adapter that allows network connectivity between the server and the clients. If the network adapter on the server were to fail, none of the users on the network will be able to access the resources hosted on the server. However, implementing two or more network adapters and connecting each network adapter from the server to two different switches provides redundancy in network connectivity between the server and the physical network.
When implementing HA techniques within a network, IT professionals must be familiar with the following key terminology:
- Mean Time To Repair (MTTR): This is the time required/needed to resolve an issue. For instance, if an IT professional spends a total of 60 hours per year repairing a server during an unplanned maintenance window and the server was repaired 8 times during that same year, then MTTR = Total repair time/number of repair = 60/8 = 7.5 hours.
- Mean Time Between Failure (MTBF): This is the predicted time between the outages of a system. For instance, if a critical server operates for 8,745 hours per year and experienced 10 failures within the same year, then MTBF = Total uptime/number of failures = 8745/10 = 874.5 hours.
- Recovery Time Objective (RTO): This is the goal of getting the system up and running back to a specific service level after an outage has occurred.
- Recovery Point Objective (RPO): This is determined by how data loss is considered to be acceptable or how far back the data goes to bring the system back online.
To become a professional within the networking industry, it’s essential to have a solid understanding of the importance that HA plays within organizations and the various techniques that are used to provide network availability to users. In the following sub-sections, you will explore common HA techniques and discover their benefits.
Diverse paths
In today’s world, many organizations are using services from cloud computing providers to help reduce the cost of maintaining their own IT infrastructure. Whenever an organization such as your employer is considering a cloud provider or a data center, it’s important to consider the type of connectivity between your organization and the data center, and the number of connections needed. While some organizations will choose to have a single ISP to provide connectivity between your company and the data center, it’s important to consider the possibility of an outage that may occur within your ISP’s network. If ISP services are unavailable, your organization will not be able to access your resources that are hosted within the remote data center.
The following diagram shows an organization with a single connectivity path to the data center facility:
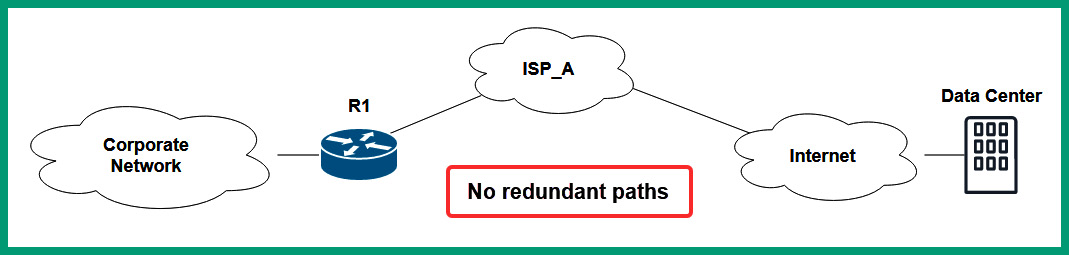
Figure 13.1 – No redundancy
As shown in the preceding diagram, if the router between the organization’s corporate network and the internet goes down, users and client devices will not be able to access the resources on the internet.
Having multiple/diverse paths between your organization and the data center is an important factor to consider when implementing HA concepts. Multiple/diverse paths focus on ensuring an organization has more than one available path to and from a data center or the internet. Hence, if one ISP connection goes down, the redundant ISP connection will be enabled and allow the organization to continue accessing the resources within the data center.
The following diagram shows redundant ISPs providing connectivity:
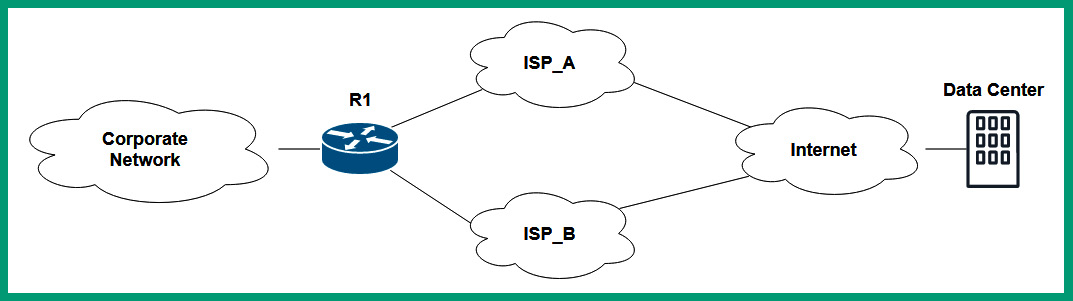
Figure 13.2 – Redundant ISP connections
Since data centers are hosting resources, servers, and devices for many customers, the data center also needs redundancy internet connections from various ISPs within the region. For instance, imagine if a data center had only one internet connection that is used to provide internet connectivity between the data center and the world. If this single connection were to be disrupted and becomes unavailable, the resources within the data center would be inaccessible to many users and organizations. Therefore, even data centers need redundancy connections from multiple ISPs to ensure their resources are available to users and organizations.
Since data centers use multiple ISPs for redundant internet connection, additional hardware such as networking and specialized devices are needed; network devices need to be configured with advanced routing protocols that can quickly route packets between a source and destination. Furthermore, the routing protocols that are used within the data center should be able to detect network changes and reconverge quickly. Using multiple ISPs for a data center provides greater redundancy, ensuring access to the data center resources is always available when needed.
Infrastructure redundancy
Any network designed around the concepts of stability and reliability must incorporate a large amount of fault tolerance. Fault tolerance refers to the ability of a system to continue to operate normally, despite the failure of one or more of its constituent parts. Fault tolerance is closely related to both the concept of HA, which is the ability of a system to operate properly and continuously for an extended period, and the concept of a single point of failure, which refers to any one component or entity in a system whose failure can affect the operation of the entire system.
Network professionals often purchase particular components and implement several types of configurations to design highly available fault-tolerant systems. One commonly implemented configuration is load balancing. Load balancing is a configuration technique that aims to disseminate workloads among all of the available resources. This technique is commonly implemented in servers. Incoming traffic from clients is initially directed at the load balancer, which then utilizes its preconfigured balancing algorithm to determine which of its backend servers will receive the traffic.
Common load balancing/scheduling algorithms include round-robin (a simple algorithm where requests are sequentially distributed to servers as they arrive), weighted round-robin (as with round-robin, but servers are assigned different weightings, and the ones with higher weightings receive larger shares of incoming requests), and least connection (servers with smaller numbers of client connections are preferred over saturated servers).
The following diagram shows the concept of a load balancer on the network:
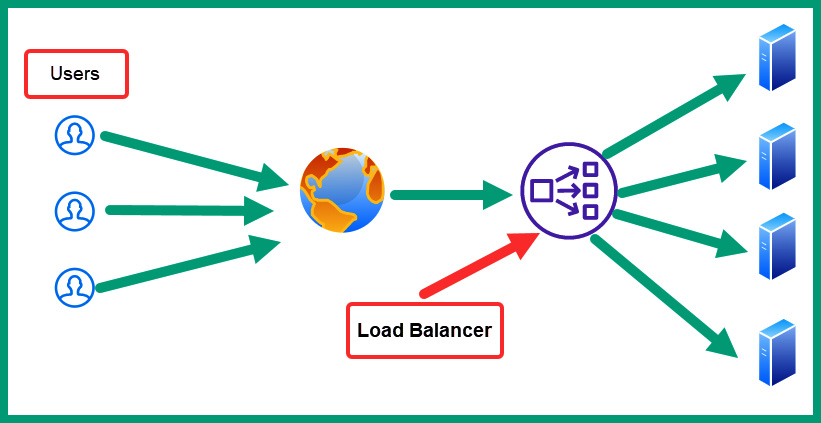
Figure 13.3 – Load balancer
As shown in the preceding diagram, this introduces the concept of clustering, which is another technique commonly used to provide high availability. Clustering refers to the aggregation of several nodes into a group, such that the group of nodes behaves as though it were a single node. For instance, the preceding diagram illustrates a server cluster, where each server delivers content to clients in the same manner as a single server would. Clustering adds a degree of fault tolerance to a system, so long as the cluster is configured correctly. For example, a cluster can be configured such that, even if a single node in the cluster fails, the other nodes continue to provide the overall function of the cluster, with the other nodes simply absorbing the increased workload.
Another technique commonly used to provide fault tolerance is network interface card (NIC) teaming. NIC teaming refers to a technique in which several NICs on a server are combined into a group to provide higher capacity or improved fault tolerance to the server. When configured to provide increased fault tolerance, NIC teaming balances traffic across all of the NICs and links in the group, allowing traffic to continue flowing if any of the individual NICs in the group fails.
This concept of combining several links into one highly available link can also be implemented on network equipment (such as switches) through the concept of port aggregation. Port aggregation allows several physical ports on devices to be combined into one logical port on the device. This process can be performed through particular protocols on devices such as the link aggregation control protocol (LACP).
Active-active versus active-passive configurations
The concept of active-passive configurations allows network professionals to install and configure two devices of the same type and function on the network, allowing only one device to operate at a time. If one of the two devices fails on the network, the secondary device can take over and become the new primary device. Within the active-passive configuration, there’s always constant communication between both devices as they are configured as a pair.
The following diagram shows an example of an active-passive scenario:
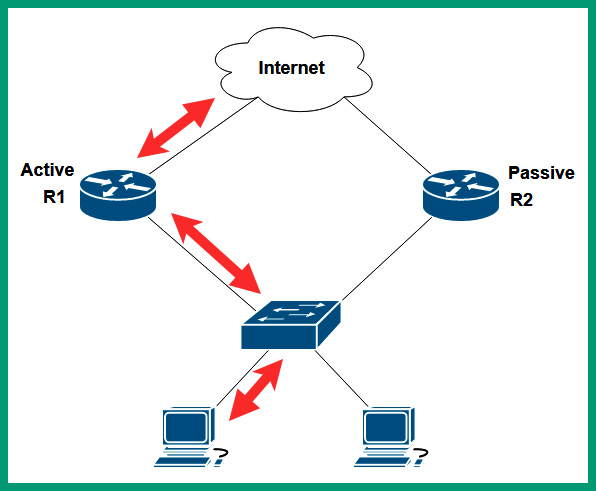
Figure 13.4 – Active-passive routers
As shown in the preceding diagram, two routers have been configured to operate in an active-passive mode, where R1 is configured to operate as the primary router for forwarding packets between the internet and the internal network and R2 becomes the standby router. While these two routers are online, they both exchange keep-alive messages with each other. If R2 does not receive the keep-alive messages from R1 after a specific time, R2 will automatically assume the role of the primary router for forwarding packets to and from the internet for the internal clients.
Network professionals commonly configure various types of devices in an active-passive state. Some of these devices are switches, routers, firewalls, and even servers on a network. The configurations and real-time session information between devices in an active-passive state need to be constantly synchronized with each other as failover may happen at any time within an organization.
In an active-active state, two devices of the same type are configured and operating at the same time. This type of configuration is usually more complex to design and operate compared to the active-passive configuration. Since both devices are active and forwarding traffic at the same time, the packet can flow in many different directions.
The following diagram shows routers operating in an active-active state:
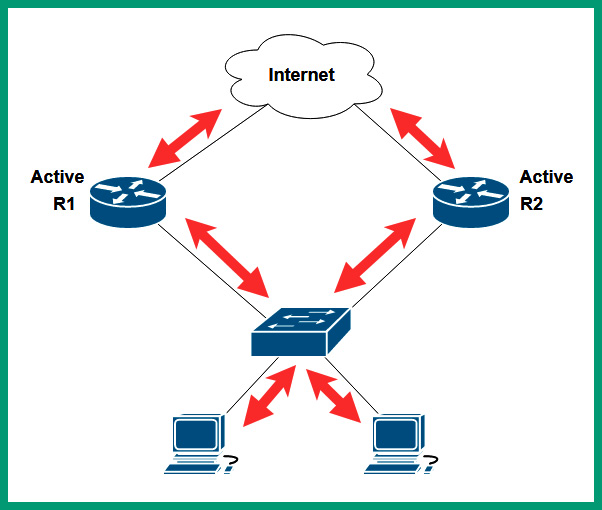
Figure 13.5 – Active-active routers
As shown in the preceding diagram, R1 and R2 are both operating in an active-active state. Therefore, traffic from one computer may take the outbound path through R1 to access the internet, and returning traffic may not take the same path but use the path through R2 and back to the computer.
The following diagram shows how data can flow in different directions:
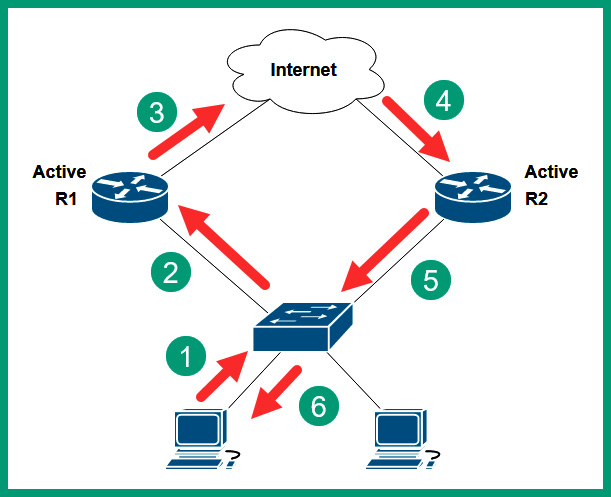
Figure 13.6 – Different paths
When operating in an active-active state, network professionals need to closely monitor and even control the flow of packets between their source and destination. Hence, network professionals need a solid understanding of the devices and technologies that are involved in forwarding traffic.
First hop redundancy
Typically, on a network, there will be a default gateway such as a router that is configured to forward packets to remote and foreign networks, such as public networks on the internet. Without a default gateway, clients and servers will not be able to exchange messages with devices that are beyond their subnet or local network. As a network professional, it’s essential to ensure the default gateway is available and operating as expected.
The following diagram shows a network with a single default gateway:
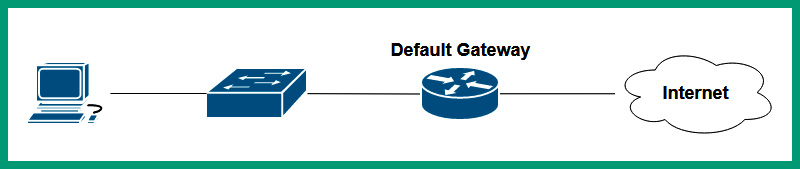
Figure 13.7 – Single default gateway
As shown in the preceding diagram, the computer has only one default gateway to the internet. If the default gateway becomes unavailable due to a failure or another cause, the clients on the internal network will lose connectivity to the internet. Around the world, many organizations depend on internet connectivity for various resources, such as accessing resources on a cloud provider’s data center, communicating with external parties, research, and so on. Imagine if an organization has only one default gateway and it goes offline – what will be the impact on the users within the company?
Within the networking industry, there are various first-hop redundancy protocols (FHRPs) that allow network professionals to configure two routers of the same type to operate in an active-active or active-passive role, which helps provide redundancy for the default gateway. Routers that are using an FHRP share a virtual IP address and a virtual media access control (MAC) address. The virtual IP and virtual MAC address are assigned to the active router that is responsible for forwarding packets. In the event the active router is no longer available, the virtual IP and MAC address is reassigned to the standby router, which will now assume the role of the new active router on the network.
The following diagram shows two routers that are using FHRP:
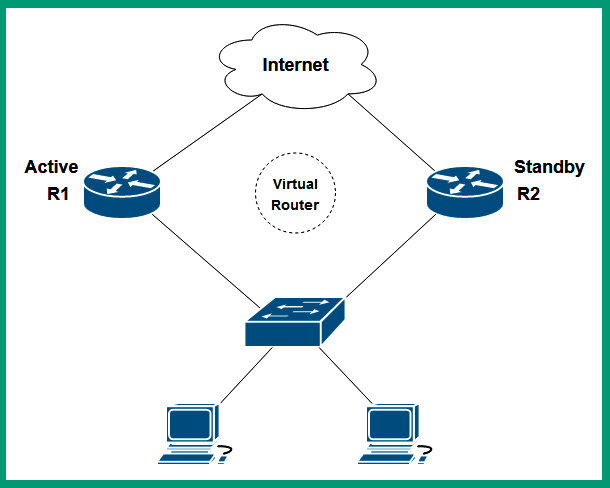
Figure 13.8 – First-hop redundancy
As shown in the preceding diagram, two routers have been configured with first-hop redundancy, which allows them to create a virtual router that has the role of the default gateway. The virtual router has a virtual IP address and a virtual MAC address that is shared with the clients on the networks. However, one of the physical routers such as R1 will be an active router, while R2 will be the standby router. If the active router, R1, goes offline, the failover will occur automatically and R2 will become the new active router. Additionally, since the virtual IP and virtual MAC address are shared between both R1 and R2, the clients will experience a minor interruption in network connectivity during the failover process.
Since clients, servers, and networked devices are provided the virtual IP and virtual MAC address of the virtual router, whenever the active router such as R1 goes offline and the failover occurs, there is no need to inform the clients on the network as the virtual IP and virtual MAC address are assigned to the new active router, R2, on the network.
The following are FHRPs that are commonly used within the industry:
- Virtual Router Redundancy Protocol (VRRP)
- Hot Standby Router Protocol (HSRP)
- Gateway Load Balancing Protocol (GLBP)
VRRP is a common vendor-neutral first-hop redundancy protocol that allows network professionals to create a group of physical routers with the intent to create a virtual router on a network. Using VRRPv2 allows many routers to become part of the VRRP group, which enables them to share the virtual IP address as the default gateway address for the network. When using VRRP, the master is the router that is currently operating as the default gateway on the network, while the backup is the other router that will take the role of the master if the master router is no longer available.
HSRP is a Cisco-proprietary first-hop redundancy protocol that allows network professionals to group two Cisco routers into a group/cluster to create a virtual router to act as the default gateway for the network. The virtual router will have a virtual IP and virtual MAC address that will be provided to all clients, services, and networked devices on the network. When working HSRP, the active router is the router that is currently forwarding packets and is operating as the default gateway, while the standby router will take the role of the new active router if the actual active router is offline.
GLBP is another Cisco-proprietary first-hop redundancy protocol that allows load balancing between multiple routers that are within the GLBP group/cluster. This first-hop redundancy protocol allows network professionals to load-balance both inbound and outbound traffic while gaining the benefits of implementing first-hop redundancy on their network. GLBP uses the same active and standby router concept as HSRP.
Having completed this section, you have learned about various concepts that are commonly implemented by network professionals to provide high availability of their network services and resources. In the next section, you will explore various disaster recovery concepts that allow organizations to continue operating and recovering from a disaster.
Disaster recovery concepts
A disaster can occur at any time and without warning, and many organizations can be greatly impacted when a disaster happens. The impact of a disaster can affect the ability of an organization to continue operating, whether short-term or long-term. Hence, companies implement various disaster recovery plans and strategies to help recover whenever a real disaster occurs.
In the next few sub-sections, you will discover common practices that organizations use to help them recover when disasters do occur.
Recovery sites
In the event of a critical disaster at an organization’s primary business location, it may be necessary for the company to move all of its staff to a backup location to ensure business continuity. These backup locations, also known as recovery sites, can be categorized into one of four groups, depending on how they are equipped, and the resources that are available at each site:
- Hot site: A hot site is a complete mirror image of an organization’s primary location. It contains all of the equipment and data required for the staff to begin working again with little to no downtime. Hot sites contain the latest backups of data and configurations of equipment.
- Warm site: A warm site contains all of the physical infrastructures of the primary location, but requires staff to restore backups and configurations manually, meaning that recovery times are longer than with a hot site.
- Cold site: A cold site is a backup site that simply reserves space for the enterprise. Infrastructure must be transferred to this site and backups must be restored. Although cold sites require the longest time to restore business functions, they also have the lowest costs associated with them.
- Cloud site: A cloud site is simply a recovery site that is established within a cloud provider’s data center and provides enough resources for the recovery process. Using a cloud site ensures there’s no separate facility to manage as the physical maintenance is handled by the service provider. Although the cost can be a flat fee, it can vary based on the usage of resources within the cloud provider’s data center. Keep in mind that the data and applications within a company’s primary location still need to be moved to the cloud site.
In addition to choosing backup/recovery sites, network professionals must also choose which method of data backup they wish to employ. Three of the main methods are as follows:
- Full backup: All data in every file server for a backup is preserved every time a backup cycle is performed. This method allows data to be restored quickly since every backup contains all of the data required for restoration (requiring only one restoration to be performed). However, this method also requires the most time to perform and requires the most space on backup media.
- Incremental backup: A backup that records only the files that have been added or changed since the last backup. A full backup is performed first; then, incremental backups record the changes that occur after that initial full backup. Therefore, incremental backups require much less space and time to restore as they only record the changes that have occurred since the last backup (either incremental or full). However, they also require much more time to restore, requiring first the restoration of the last full backup, then the restoration of all subsequent incremental backups.
- Differential backup: This backup method provides a compromise between full and incremental backups. With this method, a full backup is performed initially. Then, on each subsequent backup cycle, a differential backup is run, recording the changes that have been made since the last full backup. In this way, restoration is quicker than with an incremental backup, requiring only the full backup and the last differential backup. This method also requires less space and time than continuous full backups.
It is also important to be familiar with snapshots when working with hypervisors and virtual machines. Snapshots record the state of a system at a particular instance in time. They do not back up (copy) the data within the system, but merely record how the data is organized within the system at the instant it is taken. Since they do not replicate data, snapshots are commonly used for recording different versions of a system. However, this lack of replication also means that they are not full backup solutions by themselves. Therefore, it is important to utilize other backup solutions in tandem with snapshots.
Facilities and infrastructure support
Organizations invest in various support systems to ensure their facilities and infrastructure are always up and running to provide the necessary resources to support their business, functions, and processes. Without electricity, electronic devices such as computers, servers, networking devices, security appliances, and physical security systems will not be operational.
An uninterruptible power supply (UPS) is an external unit that provides short-term backup power to a device. The UPS contains an internal, changeable battery that stores electrical current. A computer, server, or networking device receives power from the UPS while it is connected to the power outlet.
The following are common types of UPS:
- Offline/standby: This type of UPS is often seen within homes and small offices. They provide instant power to connected devices whenever a power outage occurs. Furthermore, when the UPS detects it’s no longer receiving electrical power from the power outlet, it will automatically switch to the backup battery mode to supply short-term power to any connected devices.
- Line-interactive: This type of UPS provides additional protection against low and high voltage and power surges from the utility company.
- Online/double conversion: This type of UPS always provides electrical power from its inverter to any connected devices. This method allows no delays when an actual power outage occurs.
Some UPS devices support additional features such as auto shutdown, which sends a signal to a connected device such as a computer to automatically power off during a power outage. Additionally, many UPSs support phone line suppression to prevent any noise or irregularity in electrical signals on the phone lines.
On a server rack, IT professionals install a power distribution unit (PDU), which simply provides multiple power outlets to many servers on the same rack. The PDU is commonly used by IT professionals to both monitor and control the power capacity that’s being provided and consumed by each server. IT professionals use common network protocols such as Simple Network Management Protocol (SNMP) to gather statistics and perform changes to the PDU over a TCP/IP network.
Medium-size to large organizations and data centers usually have one or more generators to provide long-term backup power to their facilities and infrastructure. The power can be unavailable for a very long time during a disaster and the organization may have critical servers and networking devices that need to be available to provide resources for the business. Using one or more generators can provide electrical power to an entire building for a long time. Unlike a UPS, which contains a backup battery to store power, a generator runs on fuel and may take a few minutes to get up and running to provide power to the building, so a UPS may be needed in the meantime.
A heating, ventilation, and air conditioning (HVAC) system is commonly implemented within data centers and organizations that provide temperature, humidity, and airflow control for a building. This type of system is usually integrated with the fire suppression system of the organization; if a fire occurs within a building, there will be a lot of toxic smoke that is harmful to humans. Therefore, the HVAC and fire suppression system needs to work together to control and extinguish the fire. Additionally, a computer system usually manages the equipment and components that are responsible for the cooling and heating decisions that are made for the workspaces and data centers.
Having a fire suppression system within a data center is mandatory for fire safety and compliance. Fire suppression systems within a data center do not use water as it’s not good for large rooms with electronics such as servers. It’s quite common to use a type of inert gas and chemical agents that are usually stored within large tanks that are dispersed during an actual fire. The gases and chemical agents remove/reduce the oxygen within the affected area, suppressing the fire.
Network device backup/restore
Network professionals spend a lot of time configuring network devices within their organizations to ensure these devices forward traffic to their destinations as expected. Configuring a new router or switch for your network may take a few minutes to administer the baseline configurations for initial device provisioning. However, a network professional will administer additional configuration to the device to ensure it is forwarding traffic efficiently to the destination as expected.
As an organization expands, so does its network infrastructure to support more users, devices, services, and applications. Hence, additional device configurations are needed for the network devices within the organization to support these changes and efficiently forward packets to their destinations.
As a result, network professionals need to understand the various states of network device configurations; the following are the different device states:
- Actual: This is the present state of a device and its current configurations on the network
- Perceived: This is the state that we think the device and its configurations should be in on the network
- Desired: This is the state that we want the device and its configurations to be in on the network
As a network professional, there are many times that changes may occur on the network, such as when implementing additional servers within the server rack with a new application. Here, we would think the networking devices are capable of handling the additional traffic on the network with their current configurations. This is known as the perceived state. However, after implementing the additional servers and applications, it was realized that the networking devices have the capabilities but lack the configurations to do so; this is the actual state. As network professionals, we would want all the networking devices within the company to be configured with additional device configurations to efficiently support the new servers and applications to ensure optimal performance of the network infrastructure; this is the desired state.
Furthermore, it’s a very common practice within the IT industry to create multiple backups of each device configuration that’s on the network. When creating backups, it’s important to verify the backups are created properly and are not corrupted. Imagine if a network professional performs backups regularly and were to restore a backup configuration to a device, only to realize the backup file is corrupted. Hence, always check the integrity and verify the backup file(s) are not corrupted so that when they are needed to restore a system or device to a working state, the backups are good to go.
Having completed this section, you have learned about various disaster recovery concepts and how they can be used to help organizations restore their services and critical business functions during a disaster.
Summary
In this chapter, you learned about the importance of high availability and various techniques that network professionals use, such as creating multiple paths, implementing redundancy within the infrastructure, and using various first-hop redundancy protocols, to ensure users always have access to network resources and services when needed. Additionally, you have discovered various disaster recovery concepts, such as the need for recovery sites, support systems for both facilities and infrastructure, and creating backups of device configurations and systems.
I hope this chapter has been informative for you and is helpful in your journey toward learning networking and becoming a network professional. In the next chapter, Chapter 14, Network Security Concepts, you will learn about different types of cyber security threats and network attacks, and how to secure a wireless and wired network infrastructure using best practices and mitigation techniques.
Questions
The following is a short list of review questions to help reinforce your learning and help you identify areas that may require some improvement:
- How can network professionals implement a fault-tolerant network infrastructure within their organization?
A. Reduce the number of hubs on the network
B. Increase the number of routers
C. Implement redundancy
D. All of the above
- Which of the following best describes the goal of getting the system up and running back to a specific service level after an outage has occurred?
A. Mean time between failures
B. Recovery time objective
C. Mean time to repair
D. Recovery point objective
- Which of the following is a non-proprietary protocol that’s commonly used in a network that supports redundancy within the default gateway?
A. GLBP
B. HSRP
C. FHRP
D. VRRP
- Which of the following sites costs the least to maintain?
A. Warm site
B. Cold site
C. Cloud site
D. Hot site
- Which of the following best describes creating a backup of all the changes and new files that were created since the last full backup?
A. Differential backup
B. Full backup
C. Incremental back
D. None of the above
- Which of the following devices provides short-term backup power to a server when a power outage occurs?
A. Generator
B. PDU
C. AVR
D. UPS
Further reading
To learn more about the topics that were covered in this chapter, check out the following links:
- Disaster recovery site (DR site): https://www.techtarget.com/searchdisasterrecovery/definition/disaster-recovery-site-DR-site
- What is fault tolerance: https://www.imperva.com/learn/availability/fault-tolerance/