
12
Organizational Documents and Policies
As an aspiring network professional, it’s essential to understand the business processes and operations of an organization, as it will help you to align the IT objectives with the business goals better. Sometimes, non-technical procedures require the resources of the technical staff to complete, such as implementing a change within the IT services and resources to enhance the productivity of employees. Additionally, there are many non-technical plans and procedures that all technical staff need to know, such as security policies, recovery from disasters and incidents, and how to create and maintain proper documentation for systems and networks within the organization.
During this chapter, you will understand the importance of various types of plans and procedures that are commonly implemented and enforced within many organizations to ensure there are fewer risks to the business processes, and how to recover from a cyber-attack. Furthermore, you will explore various security policies that are used by security professionals to improve the security posture of systems and networks, and common types of documentation that must be maintained within any organization by IT professionals.
In this chapter, we will cover the following topics:
- Plans and procedures
- Hardening and security policies
- Common documentation
- Common agreements
Let’s dive in!
Plans and procedures
Each organization usually has its own plans and procedures, which are commonly well-documented to ensure each employee has access to the most up-to-date form of documentation whenever needed. Plans and procedures are created to ensure each employee follows a standard set of rules or guidelines that are used to achieve a common goal or meet an objective. If each employee used their own unique method of completing the same task, only some of the employees would be able to achieve the objective, while others may not. Additionally, there may be employees who can complete the same task faster than others, while some may take quite some time.
Therefore, creating a standard set of plans and procedures that are shared with employees helps ensure each person can follow the same set of guidelines to complete a task and achieve the same goals. These plans and procedures are usually tested to ensure the most efficient method to achieve a specific goal. However, it’s important to understand that as an organization grows and the IT team implements new technologies within the company to support the demand of users, plans and procedures need to be updated to ensure employees are aware of the most efficient methods of meeting an objective.
During this section, you will be exposed to common plans and procedures such as change management, incident response, disaster recovery, business continuity, and the need for standard operating procedures.
Change management
Change management simply focuses on ensuring that a change is beneficial to the organization and that it’s applied as efficiently and effectively as possible while ensuring users are affected as little as possible during and after the change being made. Before a technical or non-technical change is implemented within an organization, the change has to go through an entire life cycle to ensure all the procedures are thoroughly followed by the people who are implementing the change – such that, the change has to be approved by the Change Management Board. They read carefully and determine whether the procedures are efficient, that those who are going to perform the change have the right set of skills and qualifications, that the impact of the change is minimal, and there’s a contingency plan to roll back the change if the implementation does not go as planned and standby staff to assist if the primary staff are unable to continue or roll back the change.
To put it simply, changes have to be carefully evaluated to determine what is being changed and how it is going to affect the users within the organization. For instance, imagine the IT staff members upgraded the version of the Microsoft Office suite of applications that are installed on everyone’s computer over one weekend within a company. Tech-savvy users will be able to adapt to the new user interface quickly and continue working – however, users who are not tech-savvy may find difficulties in adapting to the newer user interface and performing tasks using the various applications without prior training. For the users who are affected, productivity decreases and some tasks will take longer to complete until everyone can adapt to the change.
What if the IT staff members created training videos and various step-by-step documentation that was user-friendly and distributed them to employees before making the change? This would help all the employees to gain a better experience in transitioning from the older user interface to the new interface while helping the users to understand what has changed. Additionally, the IT staff can roll out the change in phases, such as one organizational department at a time, to monitor and gather the user experience, which could be used to help improve how to implement the change in the future within additional organizational departments.
The following are the typical phases of change management:
- Request – Requesting to implement a change in the organization
- Evaluate – Determining whether the change is needed to improve the business process
- Authorize – Gaining authorization from the change advisory board before making the change
- Implement – Performing the change within the organization (on the part of the change owner, the person who is performing the change)
- Documentation – Documenting everything about the change for future reference
During a change, things may not always go quite as planned. Having a rollback or remediation plan helps IT professionals to reverse the change in the case of some unforeseen problem with the change. For instance, imagine you’re performing a change to upgrade the operating system on a core switch within your network. During the upgrade process, something didn’t go quite as planned – the switch seems to be frozen and no longer responds to any commands you’re sending to the switch. If a rollback or remediation plan was not created before starting the change, you will spend a lot of time troubleshooting and restoring the switch to a working state.
As an aspiring IT professional, it is important to always remember that not everyone sees what you see, and therefore cannot adapt as quickly to change. The change has to be evaluated to determine what is being changed and how it is going to affect the users within the organization. Change management helps reduce the downtime of the network and resources while reducing the risks within an organization. Additionally, the change that’s going to be made must be beneficial to the organization while ensuring the change does not create additional issues for the company and its resources.
Incident response plans
The field of cybersecurity is quite an amazing and in-demand industry around the world. Each day, we discover new security vulnerabilities within systems, and cybersecurity professionals are working continuously to implement security controls and countermeasures to mitigate the risks of being compromised by a threat actor such as a hacker. While there are a vast number of job roles within the cybersecurity industry, incident responders are in high demand. Incident response professionals are responsible for containing a threat and recovering from a cyber-attack that affects an organization. Overall, the incident response team are the cybersecurity professionals who help an organization prevent and recover from a real-world cyber-attack.
However, all organizations need an incident response plan, which is a set of procedures and tools that are commonly used by the cybersecurity team to efficiently identify, contain, and recover from cyber-attacks and threats. The incident response plan is designed to help organizations quickly adapt to the ever-changing security landscape of new emerging threats and quickly respond using a uniform, systematic approach to any threat of a cyber-attack.
It’s important to document and keep track of all the incidents that occur within an organization. Keeping proper documentation can help a professional to determine whether a similar incident has occurred in the past and if so, what actions were taken. When documenting an incident, it’s important to include as many details as possible in the description, record the time and date, location, persons involved, actions taken to resolve the issue, and lessons learned. Keeping track of incidents can help security professionals to look for any patterns of similar incidents in past records.
When an incident occurs, the right people must be involved to help resolve the issues. The organization may have a dedicated incident response team that is trained in resolving security incidents. The IT security management team or IT technical staff may also be involved in remediating the security incident. If a person within the technical team is unable to resolve the issue, the incident should be escalated to someone senior with more expertise in security.
Some companies will have a Cyber-Incident Response Team (CIRT), which is responsible for monitoring and resolving all security incidents within the organization. The CIRT is made up of professionals who are trained and qualified in various security incident response techniques. Most importantly, the CIRT is focused on incident response, analysis, and reporting.
Designing an incident response plan is all well and good but the plan needs to be tested regularly. The plan should be tested a few times per year. The testing of the plan should be scheduled. The plan should be tested before an actual security incident occurs. It’s important to document the outcome after testing the plan. Look for any areas that need improvement and test again. Continuous testing helps cybersecurity professionals be better prepared in the event of a real cyber-attack or threat – frequent testing also helps improve the incident response plan to be more effective at handling incidents within the organization.
According to the NIST SP 800-61 Rev. 2 documentation in the Computer Security Incident Handling Guide, the following are the phases of incident handling:
- Preparation
- Detection and analysis
- Containment, eradication, and recovery
- Post-incident activity and analysis
The following diagram shows the NIST incident response and handling model:
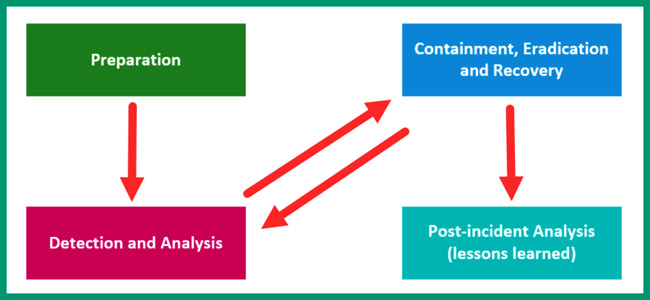
Figure 12.1 – The incident handling process
Over the next few subsections, you will gain better insights into the roles and responsibilities of each phase within the incident response phases.
Important note
The NIST SP 800-61 Rev. 2 documentation in the Computer Security Incident Handling Guide can be found at https://csrc.nist.gov/publications/detail/sp/800-61/rev-2/final.
Preparation
The preparation phase focuses on gathering a list of all the assets within the organization. An asset is simply anything that has value to the company; assets can be tangible, intangible, or people. Tangible assets are any physical objects that are valuable such as networking devices and servers. Intangible assets are digital objects that do not have a physical form such as data, license keys for applications, organization policies and procedures, business processes, and intellectual property.
During the preparation phase, network and security professionals must create a baseline of their network and system’s performance when everything is working under normal conditions. These baselines help cybersecurity and networking professionals to determine what is considered to be a normal traffic flow between the assets within the network. Furthermore, it is important to develop a communication plan that outlines who should be contacted if a security incident should occur within the organization and a plan of action for each possible security incident that can occur.
Detection and analysis
During the detection and analysis phase, the incident response team must be well-trained to identify a security event efficiently and quickly when it occurs on a system or the network of the organization. Events are generated all the time on a network and cybersecurity professionals need to investigate each event to determine whether it’s an incident or not. An event is simply any action or transaction that occurs on a system or network, such as a user logging into a system, or a client device establishing a connection to a server. An incident is a security event that indicates a system or network has been compromised due to a cyber-attack or a threat. Hence, cybersecurity professionals need to keep a close eye on distinguishing between events versus incidents within their network.
Furthermore, it’s important to collect as much information as possible on the security event or incident to improve the analysis phase, such as determining whether a threat exists in the system or not. Additionally, if a threat exists, try to determine how the threat has entered the system and network of the organization. Using security appliances to actively monitor systems and networks improves threat identification as they occur in real time.
Containment, eradication, and recovery
When a security incident occurs within an organization, the incident (or threat) must be contained as quickly as possible to prevent it from spreading and causing damage to other systems on the network. The goal of the containment phase is to simply stop a threat such as malware spreading to other systems on the network or a hacker from compromising additional machines.
Once the threat is contained, the eradication phase is initialized to remove the threat from any compromised or infected systems on the network. The eradication phase ensures systems are thoroughly disinfected to ensure there are no longer any infections present on any system within the organization. However, during the eradication phase, the incident response team will need to revisit the detection and analysis phase to verify that there are absolutely no more traces of the threat on any of the systems within the organization.
Once all traces of the threat are eliminated, then the recovery process begins, which focuses on restoring systems to an acceptable working state in terms of their operating systems, applications, and data. The recovery phase also includes performing data recovery from backups, replacing compromised systems, and re-installing the host operating systems and applications.
Post-incident analysis
After an incident is resolved, it’s important to use the opportunity to learn from the experience of the cyber-attack or threat. The lessons learned will help improve the incident response plan and its effectiveness, and the efficiency and preparedness of the incident response team for future security events and incidents.
The business continuity plan
The Business Continuity Plan (BCP) is a set of guidelines that is used to help restore the organization’s services and business functions whenever a disaster has occurred. A Business Impact Analysis (BIA) is used to help professionals to identify the most critical business processes, procedures, and resources that are needed to ensure the organization can continue to operate and function. The BIA contains a systematic method that also helps professionals to determine the potential effects of disruption on critical business processes and operations within a company. Additionally, it’s essential to determine the availability that is needed by those business processes and resources that may be affected.
Many organizations use various metrics to measure the availability of their systems, such as assigning a percentage value to their uptime and downtime on an annual basis. For instance, many cloud service providers advertise their availability in terms of 99.999% annually. More 9s appended to the end of the percentage value simply indicates that more uptime is guaranteed by the service provider.
When developing a business continuity plan, it’s important to consider the following factors:
- Exercises (tabletop) – When planning for business continuity, it’s important to perform regular exercises to ensure everyone is prepared. These exercises can cost a lot of money and be very time-consuming. However, a tabletop exercise allows an organization to reduce costs and time by simply discussing a simulated disaster. In a tabletop exercise, people do not physically participate but rather discuss what happens at the reached stage of the plan.
- After-action reports – After completing a disaster recovery exercise, an after-action report is required. This report may contain the details of each step of the methodology and any explanations of the procedures. Make sure that you cover the details of everything that worked smoothly and anything that did not work as expected.
- Failover – Having a failover site is important; if a disaster occurs, you already have an alternative site and plans in place for migrating your systems. Ensure all data is fully replicated or synchronized between the organization and the failover site.
- Alternative business practices – During a disaster, things may not always go as planned. It’s important to alternate between different methods of achieving the same task. This technique is useful in the case that the network or devices such as printers are not available to print a receipt for a customer. It’s important to ensure proper documentation is kept for all the primary and alternative business processes before a disaster occurs.
Having explored the importance of business continuity planning, next, you will explore disaster recovery planning and how it plays a vital role within organizations.
Disaster recovery plans
Disaster recovery planning focuses on ensuring an organization is well prepared and equipped to recover from any possible disaster that may be a risk to the company, its resources, and assets. It’s essential to create a dedicated team of professionals for performing and handling disaster recovery for the organization – additionally, proper documentation of the company’s infrastructure should always be up-to-date to help professionals during times of need. When developing a disaster recovery plan, the organization should perform continuous training and testing of the plan to ensure everyone understands their roles and responsibilities during an actual disaster.
Important note
The NIST SP 800-34 Rev. 1 documentation in the Contingency Planning Guide for Federal Information Systems can be found at https://csrc.nist.gov/publications/detail/sp/800-34/rev-1/final.
The following are key terms in disaster recovery planning:
- Recovery Time Objective (RTO) – The RTO is simply the maximum amount of time that a system or resource can be unavailable before there is an unacceptable impact on other systems' resources, business processes, and critical functions of an organization
- Recovery Point Objective (RPO) – The RPO is simply the point in time before the disruption or outage of a system to which the business processes or data can be recovered or restored after the outage has occurred
Additionally, when creating a disaster recovery plan, it’s essential that you clearly identify both the internal and external teams that are responsible for assisting the organization in restoring services and critical business functions to an acceptable level, enabling the organization to resume its operations. Furthermore, having proper documentation of key assets of the organization helps disaster recovery professionals to reduce the time to restore business operations. Hence, professionals should ensure that network configurations, both hardware and software details, and vendors are properly documented, and all documentation should be up-to-date at all times.
Furthermore, it’s important to identify the recovery and failover sites and the redundancy hardware components that will be needed in the event of a disaster. If this information is unknown before a disaster, the time to restore an organization’s business operations will be lengthy due to inefficiency and the unavailability of important information. Keep in mind that the disaster recovery plan is designed to be proactive, allowing professionals to be prepared to handle and respond to various types of disasters that may affect the organization.
Lastly, continuous training and testing of the disaster recovery plans ensure each person understands their role and responsibilities during a real disaster. Additionally, continuous testing allows professionals to identify gaps or procedures that need to be updated and improved. Furthermore, IT professionals test their failover processes often to ensure the process is working as expected. Any issues discovered during the testing phase are documented and updated to improve the plan.
The system life cycle
The system life cycle is used to define the life span of a system or technology that is supported by a vendor before the device or product becomes obsolete. If an organization continues to use end-of-life systems on its networks, it increases the security risks to the organization. End of life simply means that the vendor of the product is no longer providing any support, updates, and patches to resolve any software bugs and security vulnerabilities. Without these updates and patches, any newly discovered security vulnerabilities on the system will not be rectified and the risk of the system being compromised due to a cyber-attack or threat increases.
Important note
The system life cycle affects both software and hardware components.
The following are the phases of a system life cycle:
- Procurement – Focuses on planning, negotiating, and acquiring a product or system from a vendor.
- Deployment – Focuses on the implementation (installation) and integration of systems into the organization.
- Management – Focuses on supervision such as keeping track of the hardware or software products while monitoring them to ensure they’re performing as expected. Additionally, supporting the product or system to ensure it continues to operate and perform as needed.
- Decommission and disposal – Focuses on replacing devices that are no longer functioning or supported by the vendor, preserving systems to continue providing the resources and services needed, and retiring systems that are end-of-life.
Understanding the importance of the system life cycle of systems within an organization reduces the security risks associated with using outdated devices and applications. While many organizations do not update their internal technologies such as devices and applications, they are left vulnerable to cyber-attacks and the failure of systems as a result.
Standard operating procedures
Standard operating procedures are simply step-by-step guidelines or instructions for performing a common task within an organization. These guidelines are designed to improve the efficiency of performing a task or action by an employee and are sometimes required for compliance with various regulatory standards within an industry. Furthermore, using standard operating procedures within an organization helps reduces the likelihood of either failures or miscommunication, as the guidelines are standardized within the company for each person to follow to achieve a given task.
Overall, the standard operating procedures contain the details about the organization’s daily business processes and operations, while outlining the methods, techniques, and sequences used to complete a given task or objective. Organizations should have procedures for everything within the business, therefore ensuring each employee understands how to achieve the task using the guidelines. It’s important to ensure that the standard operating procedures are clearly defined and well documented so that they are easy to understand and follow by anyone who reads them.
If a standard operating procedure is not clearly defined or written, the reader may have difficulties understanding how to perform the task and will take longer to complete the action. As a result, this can lead to inefficiency within the organization and affect business operations.
Having completed this section, you have learned about various plans and procedures that are commonly implemented within many organizations around the world. Furthermore, you have learned about their roles and responsibilities, and how they help organizations to improve their performance and operations.
Next, let’s take a deep dive into discovering various security policies that are used to improve the security posture of devices and systems on a network.
Hardening and security policies
Network professionals mostly focus on designing, configuring, maintaining, and troubleshooting network-related issues within an organization. However, it’s important for the next generation of network professionals to understand the role of various security policies that are used to help prevent malicious activities on a system and network by employees of the company.
Over the next few subsections, you will explore various hardening techniques and security policies that are commonly used to help improve the security posture of companies.
Password policies
Password policies are created by system administrators and security professionals with the intent of ensuring that any user who wants to create or update a password on a system or device meets the requirements for creating a complex password. Many systems and devices are protected with a username and password combination that can easily be compromised by a skilled cybersecurity professional or seasoned hacker. For instance, imagine if users within the organization set a simple and easy-to-remember password for their user accounts within the company. If a threat actor were to gain access to the network, the hacker would be able to perform an online password attack with the intent to discover the valid user credentials of any user on the network with a weak password.
Password policies usually contain the following rules and guidelines:
- Do not use the same password on multiple systems, devices, or user accounts.
- Ensure the password contains uppercase, lowercase, special characters, symbols, and numbers to increase its complexity.
- Ensure the password has a minimum length of eight characters or more.
- Create a policy to ensure a user is unable to reuse an older password on a system.
- Create a policy to ensure passwords are frequently changed every 30 to 60 days.
- Create a lockout policy to prevent access to a user account if there are continuous failed login attempts within a specific duration of time. For instance, three failed attempts within 60 seconds is an indication of a possible attempt of an account takeover.
- Ensure users understand how to recover their user accounts if their passwords are forgotten.
The idea of creating complex passwords on systems reduces the likelihood of a hacker being able to compromise the user account and gain access to the system. However, creating a unique complex password for each system can make them quite challenging to remember. Using password manager applications helps people to generate unique, complex passwords and store them. If you’re using a password manager application, ensure you set a complex password for it and use Two-Factor Authentication (2FA) to prevent a threat actor from gaining unauthorized access to your passwords within the password manager.
Acceptable use policy
The Acceptable Use Policy (AUP) is very common within many organizations and educational institutions, containing the guidelines, rules of conduct, and constraints that an employee or a user must agree to before they are granted access to a system or network. For instance, without an AUP within an organization, employees will be unrestricted in their actions on company-owned equipment such as computers and smartphones. If an employee is unaware of the dos and don’ts within an organization, the employee can use the company-owned systems to access websites and resources that are not safe for work and websites that create an unproductive workforce.
Tip
If you’re interested in obtaining a template of an AUP and the additional common security policies, please see the following link: https://www.sans.org/information-security-policy/.
During the onboarding process of an employee, the human resource department usually ensures the new employee thoroughly reads and signs the AUP documentation as an indication of accepting the terms and conditions of using the systems and company resources. Additionally, the AUP ensures each policy uses the company’s systems and resources to benefit and improve the organization’s business processes.
Bring your own device policies
Bring Your Own Device (BYOD) is a policy that allows the employees within an organization to use their personally-owned devices such as smartphones, tablets, and laptops for work-related activities in the company. This allows the employee to use their personal devices for accessing their corporate email accounts, performing daily work-related tasks, and accessing the organization’s network, services, and resources.
While it may be convenient for employees to use their personal devices, this concept imposes greater security risks to the organization. Since these devices are not company-owned, they are not managed by the IT team of the company – hence, the IT team is unable to monitor the security posture of these personal devices. For instance, if an employee has a smartphone with an outdated operating system, that smartphone will be vulnerable to many new cyber-attacks and threats. If the smartphone contains malware that’s unknown to the device owner and it’s connected to the organization’s network, the malware can infect and compromise other systems within the corporate network.
Overall, organizations that implement BYOD policies ensure their network is closely monitored for any suspicious activities and there are cybersecurity solutions that are implemented to profile each connected device to ensure they meet the minimum security requirements before they are permitted access to the network resources.
Remote access policies
The remote access policy simply defines the methods and techniques that allow an employee to securely connect and access the resources on an organization’s network. Many organizations implement remote access configurations on their networking devices and security appliance to allow their IT team to conveniently access systems and devices over a network. However, when implementing remote access services on a device, it’s important to always secure methods and protocols to provide data security between the client and server.
The following are common network protocols and techniques that allow remote access:
- Secure Shell (SSH)
- Remote Desktop Protocol (RDP)
- Virtual Network Computing (VNC)
- A Virtual Private Network (VPN)
Whether you’re using SSH or a remote access VPN to securely access the networking devices and security appliances within your organization, the remote access policy should define the authorized users, their privileges, the preferred remote access protocol, acceptable usages, the VPN concentrator, and client configurations. Without remote access policies within organizations, a user may attempt to take advantage of their privileges that access a networking or security device.
Onboarding and off-boarding policies
The onboarding process is usually conducted whenever an organization hires a new employee. This process is important to ensure the employee is well trained in the business processes and operations, tasks, and security policies that are involved within their new role and the organization. Furthermore, when an employee leaves an organization, the off-boarding process must be effective. The off-boarding process focuses on ensuring the user accounts for the resigned employee are disabled rather than deleted, passwords for systems are changed, and any company-owned devices and equipment are returned.
Imagine if an organization never disabled user accounts or changed the passwords on their systems – the ex-employee could share that confidential information with hackers who could use those secrets to gain physical access to the building and remote access to systems.
The onboarding and off-boarding policies are simply the guidelines and rules that are used by the human resources department to help a new employee join the organization and to separate the employee from the company when the employee leaves.
Security policies
Security policies are simply documentation that explains how an organization plans to protect and secure its assets from cyber-attacks and threats. These documents are frequently updated to ensure the organization is adapting to the changes in the security landscape, as new and emerging threats surface very often.
The head of information security within an organization is usually the responsible person who will be tasked with developing various security policies that are designed to protect the organization’s assets. An information security professional must understand the need for data protection, privacy, and security of all assets (whether tangible, intangible, or people). Furthermore, it’s essential to understand the various risks that are associated with each type of security vulnerability that exists within the organization. Lastly, an information security professional also needs to consider both internal and external threats, as many professionals focus more on securing their systems from external threats, while leaving their internal systems and network unprotected.
Data loss prevention
Data Loss Prevention (DLP) includes features within many cybersecurity solutions such as firewall appliances, email solutions, and Endpoint Detection and Response (EDR) applications. DLP focuses on preventing anyone within the organization from exfiltrating sensitive and confidential data. DLP solutions help organizations to monitor for any potential data breaches where, if an employee or a threat actor is attempting to remove data from the company’s systems and network, the DLP solution can detect and prevent the security incident in real time.
Upon completing this section, you have now learned about the various types of hardening and security policies that are commonly used within organizations. In the next section, you will learn about the common but important types of documentation that are needed as a network professional.
Common documentation
Each organization usually has a set of common documentation that helps network professionals to better understand the network design when planning for future upgrades, maintenance, and troubleshooting issues.
The following are common types of documentation for network professionals:
- Physical network diagrams – The physical network diagram contains a flood plan of the building or office space and shows how each networking device is interconnected and its location. Additionally, you can find a rack diagram that includes a server rack and all its interconnected servers, and network racks, showing all the networking devices and security appliances. Furthermore, physical network diagrams show the Intermediate Distribution Frame (IDF) and the Main Distribution Frame (MDF), which indicate how and where the physical network connections are terminated within the company.
- Logical network diagrams – This type of diagram shows the packet flow throughout a network within an organization by illustrating how devices are interconnected and able to communicate with each other. The logical network diagram contains information such as IP schemes, networking devices and types, network protocols, and gateways to the internet.
- Wiring diagrams – A wiring diagram shows how the physical connections and layout of networking cables are made throughout the organization. They help network professionals to better understand the physical connections between devices and how they are interconnected.
- Site survey reports – Before implementing a wireless network solution for an organization, a site survey is required to determine the number of Access Points and their placements to ensure maximum coverage. To complete a site survey report, it’s important to understand the needs and requirements of the organization in terms of wireless technology; obtaining a floor plan or facility diagram will be very useful when determining wireless signal coverage and the Access Point placements. Furthermore, inspect the physical and network infrastructure of the building and identify the coverage area by performing an actual site survey and measuring the signal. During this time, determine potential locations where the Access Points could be implemented and document all the findings of the survey.
- Audit and assessment reports – This type of report provides a complete and detailed analysis of the network performance or network security analysis of the organization. The audit and assessment report is used to determine any issues that exist on the network and whether these issues are being resolved.
- Baseline configurations – Without capturing a baseline of systems or the network when it’s operating at an acceptable state, a network professional will not be able to tell whether the current state of their network is operating abnormally or not. Additionally, baseline configurations are a set of configurations that are applied to a system or device that is considered to be acceptable and should only be changed or modified using a change management process.
This is the common documentation that helps network professionals to ensure the healthy operation of their network infrastructure. In the next section, you will discover common organizational agreements that ensure various parties understand what is expected.
Common agreements
Organizations need to ensure the people who are using their systems, such as employees, contractors, and service providers, do not share sensitive information with external parties, and understand what is expected from them.
The following are common agreements that are used within the business world between two parties:
- Non-Disclosure Agreements (NDAs) – This type of agreement is usually given by an organization to employees, contractors, and service providers who will be working on the organization’s systems and network. The NDA is simply a legal document used to prevent anyone from disclosing sensitive and confidential information that’s discovered on the organization’s systems.
- Service-Level Agreements (SLAs) – The SLA is a common agreement that’s given by a service provider to the customer that indicates the responsibility of the service provider and its role in providing and ensuring the delivery of the service to the customer and that this service meets the acceptable level.
- A Memorandum of Understanding (MOU) – This type of agreement is sometimes written in the form of a letter that contains the intention between two parties. However, the MOU is a less formal type of agreement that’s commonly used within an organization and does not always require either party to sign.
Having completed this section, you have learned about common organizational documentation and its characteristics.
Summary
During this chapter, you have learned about the importance of performing change management to reduce the risks that are involved in implementing a change in a system, network, or organization. Additionally, you have discovered the various phases of incident response and planning and the need for incident response professionals within the industry. Furthermore, you have explored the role and function of various plans and procedures, common types of documentation, and agreements.
I hope this chapter has been informative for you and is helpful in your journey toward learning about networking and becoming a network professional. In the next chapter, Chapter 13, High Availability and Disaster Recovery, you will learn about various techniques that help network professionals to ensure their network is always up and running.
Questions
The following is a short list of review questions to help reinforce your learning and help you identify areas that require some improvement:
- Which of the following phases are responsible for removing a threat from a system?
A. Post-incident analysis
B. Detection
C. Containment
D. Eradication
- When developing a business continuity plan, which of the following helps professionals to improve the plan?
A. An after-action report
B. Failover sites
C. Alternative business practices
D. All of the above
- The maximum amount of time for which a system can be unavailable before there is an unacceptable impact on other systems within an organization is known as what?
A. The recovery point objective
B. Incident handling
C. The recovery time objective
D. Recovery
- Which phase in the system life cycle is responsible for keeping track of hardware and software products?
A. Deployment
B. Maintaining
C. Monitoring
D. Management
- Which of the following types of policies helps reduce account takeovers?
A. An acceptable use policy
B. A password policy
C. A BYOD policy
D. All of the above
- Which of the following prevents threat actors from exfiltrating data from an organization?
A. The AUP
B. DLP
C. URP
D. RDP
- Which of the following agreements prevents a contractor from disclosing sensitive information?
A. Security policies
B. An MOU
C. An SLA
D. An NDA
- Which of the following agreements is used to assure a given service to a customer?
A. An SLA
B. An MOU
C. An NDA
D. All of the above
- Which of the following policies allows employees to use their personal devices on the organization’s network to perform work-related tasks?
A. An MOU
B. BYOD
C. The AUP
D. None of the above
- Which of the following can be used to ensure each employee uses a set of guidelines to achieve the same objectives within an organization?
A. DLP
B. SOP
C. An MOU
D. The AUP
Further reading
To learn more on the subject, check out the following links:
- What is change management? – https://www.techtarget.com/searchcio/definition/change-management
- Incident management – https://www.sans.org/white-papers/1516/
- Security policy templates – https://www.sans.org/information-security-policy/