
I saw a posting in a Rails newsgroup asking for advice on the best administrative tool to use with the poster's SQL database. The majority of replies suggested that with the development of migrations a Rails developer should keep away from SQL. This newsgroup thread seems to reflect the views of a number of Rails developers. The more I develop Rails applications, the more I am confident that this view is
mistaken. A developer who ignores SQL is tying one hand behind their back. SQL databases form the core of almost all Rails applications, and not using the free extra resources that SQL can provide, seems daft to me.
Migration is a splendid system that simplifies database table creation and modification. Migrations add order, structure, and ease to table development. However, creating tables is only a small part of what a SQL database engine can do. SQL tools provide a very efficient system to process, combine, and compare data. What is more, the SQL tools are installed when you install the database, so they are a free resource waiting to be used.
However, there is also the argument that ActiveRecord is already leveraging SQL within each Rails application, and usually makes a very good job of generating SQL calls from executing Rails code. This is a sound argument. So, if this is true, where is the need to create and use custom SQL code? The simple answer is, when standard Rails code and the resulting ActiveRecord generated SQL takes too long to process the data; or SQL offers a way to summarize, compare, or combine data in a simpler manner than what can be done within Ruby and Rails.
In my experience, ActiveRecord generated SQL works well when retrieving and processing data from one or two tables. When you start wanting to combine data from three or more tables, processing the data purely within Rails and ActiveRecord generated SQL can take many seconds. In these circumstances, a custom SQL call can greatly improve the performance.
A second area where an understanding of SQL is useful, is when you need to apply grouping to a data set. ActiveRecord supports grouping, however, it is not as simple as it might first appear. In my experience, it is often easiest to create the required grouping statement in SQL and then reverse engineer it back into an ActiveRecord find statement.
A detailed guide to SQL is beyond the scope of this book. So instead, I will describe here a couple of examples that show how a knowledge of SQL can help to create better, or at least faster, Rails applications.
In building a project management application, I needed to process data that was held within a daughter object that was itself a daughter object. That is, each project was represented by a project object. Each project had a number of daughter objects called tasks. Each Task could also have daughter objects called budget.
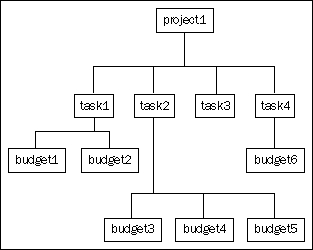
Within the model definition, for each model class, I was able to specify the relationship. So, a project has_many tasks, and a task has_many budgets. Also, budgets belong_to task, and tasks belong_to project.
I could also use :through option to create a project has_many budgets relationship in the Project model:
has_many :budgets, :though :tasks
And improve performance of retrieving Budget information when iterating through a project’s tasks by using an :include option in the definition of the has_many tasks statement:
has_many :tasks, :include => :budgets
However, in my main project reporting tool, I needed to be able to output the final project budget value. This was not a simple task. If a task had three budgets, the final budget was not the sum of all the three budgets, but rather the value of the last budget. Also, I needed to be able to assign a budget to a task, but set a flag to prevent that budget from being used when calculating the total project budget.
So, to get the project budget, I needed to sum the last budget item in each task that had a flag set for it to be included in the project budget. I created a task method called final_project_budget that returned the value of a relevant budget object, if one existed. I was then able to use Project.tasks to return a collection of tasks assigned to the project and then iterate through them to calculate the sum of the values returned by the final_project_budget method.
The process worked fine. It accurately returned the correct figure each time. The code was fairly simple and therefore easy to modify and maintain. The problem was that the resulting report took eight seconds to render for one project. This was not apparent initially, when each project only had a couple of tasks, but as tasks were added the application slowed.
The main problem was that each-and-every retrieval of a budget data from a task involved a separate SQL call to the database. So, one SQL call would return the list of tasks relating to a project, and then a further SQL call would be called on each task to get the budget information. Then some processing in Ruby added the budgets together and returned the correct number.
My solution was to create a single SQL call that gathered and processed all the information in one go. This is the SQL statement used:
SELECT SUM([value]) as total_budget FROM [Data_Warehouse].[dbo].[budgets] budget INNER JOIN ( SELECT MAX([target_on]) as date , [task_id] FROM [Data_Warehouse].[dbo].[budgets] WHERE [project_id] = 147 AND [part_of_parent] = 1 GROUP BY [task_id] ) AS last_target_on ON last_target_on.date = budget.target_on AND last_target_on.task_id = budget.task_id
This is Transact SQL used on a MS SQL database, and therefore the syntax may not be correct for other databases. However, it is not the code itself that is important, but the fact that a single SQL call could be created that did all the processing required.
The code uses the SQL SUM function to add up the values assigned to a number of budget entries. Most of the work is carried out with a JOIN to a second SELECT statement. This second statement finds only the latest budgets assigned to each task, and that have the part_of_parent flag set (it is this flag that determines whether a budget is to be included in the project budget). This JOIN, therefore, ensures that only the correct last budgets for each task are passed to the initial SUM([value]) statement.
It was then a case of replacing 147, (the id for a particular project), with code that would insert the current project's ID, using the SQL statement with a find_by_sql call, and then processing the result to output the solution as required.
def total_budget
sql = "SELECT SUM([value]) as total_budget
FROM [HL_Data_Warehouse].[dbo].[budgets] budget
INNER JOIN (
SELECT MAX([target_on]) as date
, [task_id]
FROM [HL_Data_Warehouse].[dbo].[budgets]
WHERE [project_id] = #{self.id} AND [part_of_parent] = 1
GROUP BY [task_id]
) AS last_target_on
ON last_target_on.date = budget.target_on
AND last_target_on.task_id = budget.task_id"
budget = Budget.find_by_sql(sql)
return budget[0].total_budget
end
This method was added to the Project model. Then, for a Project object called project, the application could call project.total_budget to return the total budget.
As a result of this modification, the page that had taken eight seconds to load now took eight tenths of a second to load; ten times faster to load than before the modification.
There is a better technique to using find_by_sql for the total_budget method. The above example, while useful in that it shows a real world example of how an application was improved by adding some SQL magic, is also problematic. The issue is that it has forced the results of the SQL call into a collection of budget objects. This does not cause an error, but it would be neater if the objects returned using the SQL query formed a simple array of hashes whose properties were defined solely by the data returned from the database and did not inherit any of the properties from the parent model.
The solution is to use the parent’s connection to the database, and then use one of two connection methods to return the data in a more suitable set of object. The options are:
connection.select_all(sql) #returns data in an array of hashes where each hash corresponds to a data row. connection.select_one(sql) #returns a single hash containing the first row of data from the sql call
Therefore, a better version of the total_budget method using the connection object, would be as follows:
def total_budget
sql = "SELECT SUM([value]) as total_budget
FROM [HL_Data_Warehouse].[dbo].[budgets] budget
INNER JOIN (
SELECT MAX([target_on]) as date
, [task_id]
FROM [HL_Data_Warehouse].[dbo].[budgets]
WHERE [project_id] = #{self.id} AND [part_of_parent] = 1
GROUP BY [task_id]
) AS last_target_on
ON last_target_on.date = budget.target_on
AND last_target_on.task_id = budget.task_id"
budget = connection.select_one(sql)
return budget.total_budget
end
GROUP BY is a very useful SQL option that can be used to quickly generate summary reports. It can be used via an ActiveRecord find method using the : group option. However, its use is not as simple as it might appear from the Rails api pages. Consider this example:
We have an application that stores data on the contents of boxes of fruit. It contains a single MySQL table:
|
ID |
fruit |
quantity |
source |
|---|---|---|---|
|
1 |
Orange |
50 |
Jaffa |
|
2 |
Apple |
110 |
UK |
|
3 |
Orange |
30 |
Jaffa |
|
4 |
Apple |
60 |
UK |
|
5 |
Orange |
90 |
Spain |
|
6 |
Pear |
40 |
UK |
|
7 |
Orange |
110 |
Spain |
|
8 |
Orange |
110 |
Spain |
|
9 |
Apple |
50 |
Belgium |
|
10 |
Apple |
20 |
France |
|
11 |
Pear |
110 |
UK |
We want a summary report that details how many of each type of fruits you have in all the boxes. We can use GROUP BY to do this. However, it is not as simple as the following:
report = Boxes.find(:all, :group => 'fruit')
This would generate the following:
|
ID |
fruit |
quantity |
source |
|---|---|---|---|
|
2 |
Apple |
110 |
UK |
|
1 |
Orange |
50 |
Jaffa |
|
6 |
Pear |
40 |
UK |
This has not provided a summary, but rather has simply pulled out the first entry for each type of fruit.
So, what is missing?
Let us start by looking at the SQL that generated the group data:
SELECT * FROM boxes b GROUP BY fruit
The problem is that by using the short-hand * in the SELECT part of the statement, the job of selecting what is to be returned has been handed over to SQL. As the example above demonstrates, SQL's best effort will usually not give us the desired result. Instead, we must specify, which fields are to be included in the output. However, the following would generate an error:
SELECT fruit, quantity FROM boxes b GROUP BY fruit
We also need to specify an aggregate function for each field that is not being grouped. Here are some of the commonly used aggregate functions:
- AVG—Average value for those in the field.
- COUNT—Number of items in the group.
- MAX—Maximum value in group. If used on a MySQL varchar field, it returns the last value in an alphabetical order.
- MIN—Minimum value in group. If used on a MySQL varchar field, it returns the first value in an alphabetical order.
- SUM—adds together the values held in the field.
The field fruit is being grouped, so it can stay as it is in the SQL statement. An aggregate function needs to be applied to the quantity field, as this field is not being grouped. That is, there will be a number of quantity values in each group, but only one fruit value. So, all we need to tell SQL is, which quantity value should be returned for a group; the fruit value is automatically returned.
SELECT fruit, sum(quantity) AS 'total_quantity' FROM boxes b GROUP BY fruit
This will produce the desired result:
|
fruit |
total_quantity |
|---|---|
|
Apple |
240 |
|
Orange |
390 |
|
Pear |
150 |
Notice that AS was needed to specify a meaningful name for the quantity output.
To generate the desired result set in Rails, the following code can be used.
report = Boxes.find(:all, :select => "fruit, sum(quantity) AS 'total_quantity'", :group => 'fruit')
By using the select option in the find statement, the output was controlled and the desired results obtained.
It is also possible to group on multiple fields. For example:
SELECT fruit, source, sum(quantity) as 'quantity', count(*) as 'boxes' FROM boxes b GROUP BY fruit, source
This will produce a report showing how many fruits there are from each source and in how many boxes:
|
fruit |
source |
quantity |
boxes |
|---|---|---|---|
|
Apple |
France |
20 |
1 |
|
Apple |
Belgium |
50 |
1 |
|
Apple |
UK |
170 |
2 |
|
Orange |
Jaffa |
80 |
2 |
|
Orange |
Spain |
310 |
3 |
|
Pear |
UK |
150 |
2 |
From this, we can see there are three boxes of Spanish oranges containing 310 fruits in total. The Rails code would look like this:
report = Boxes.find(:all, :select => "fruit, source, sum(quantity) AS 'total_quantity', count(*) as 'boxes'" :group => 'fruit, source')
Aggregate functions need to be used carefully. Consider how you would find the source of the boxes with the least fruit of each type. Your first stab at a solution may be:
SELECT fruit, MIN(quantity) AS 'quantity', MIN(source) AS 'source' FROM boxes GROUP BY fruit
This would return the record set below, which at first glance looks correct:
|
fruit |
quantity |
source |
|---|---|---|
|
Apple |
20 |
Belgium |
|
Orange |
30 |
Jaffa |
|
Pear |
40 |
UK |
However, the source of the box with the least apples is France and not Belgium. In fact, it is only by chance that the other two records match the correct result. MIN (source) has returned the first source in alphabetical order—not the source that matches the minimum quantity.
To get the correct result, we first need to find the minimum quantities for each fruit and then use that data to pull out the records that match that information. The following code does that:
SELECT b.fruit, b.quantity, b.source FROM boxes b JOIN (SELECT fruit, MIN(quantity) AS 'quantity' FROM boxes GROUP BY fruit ) AS s ON b.fruit = s.fruit AND b.quantity = s.quantity
The result is shown below.
|
fruit |
quantity |
source |
|---|---|---|
|
Orange |
30 |
Jaffa |
|
Pear |
40 |
UK |
|
Apple |
20 |
France |
ActiveRecord's find method has a: joins option and can be used to construct this query. A: from option is also needed so that an alias of 'b' can be specified for the boxes table. However, the resulting code is more complex than the original SQL code:
report = Boxes.find(:all, :select => 'b.fruit, b.quantity, b.source' :from => 'boxes b' :join => "(SELECT fruit, MIN(quantity) AS 'quantity' FROM boxes GROUP BY fruit ) AS s ON b.fruit = s.fruit AND b.quantity = s.quantity)"
Personally, I would use a find_by_sql method as it would be easier to maintain:
sql = "SELECT b.fruit, b.quantity, b.source FROM boxes b JOIN (SELECT fruit, MIN(quantity) AS 'quantity' FROM boxes GROUP BY fruit ) AS s ON b.fruit = s.fruit AND b.quantity = s.quantity" report = Boxes.find_by_sql(sql)
Knowledge of SQL makes it easier to get the most of the: group option in ActiveRecord's finds method and also makes it easier to extend further SQL's GROUP BY options.
Note
A little SELECT goes a long way
In both of these examples, refining the SQL SELECT statement sent to the database greatly improved the efficiency with which Rails was able to obtain the data required for the application. Mastering this one, SQL command can provide many dividends. SELECT statements simply read data and therefore do not alter the data in the database. Therefore, you can safely experiment with them to find the statement that achieves what you need. Time spent mastering this SQL command will give you a simple way to improve the performance of Rails applications.