
Throughout this chapter, we have been building our application up, based on the data structure developed in Chapter 2. We have put in place the whole of the model layer for the application, including the necessary validation code and associations between models. We have also assured ourselves that the model is stable, by building some tests to confirm its behavior.
But there are a couple of areas we have neglected so far:
- How can this work be shared with other members of the team (via the Subversion repository)?
- How can we get a list of Outlook contacts into the database?
The remainder of this chapter covers these topics.
We've done quite a bit of coding in this chapter, but so far we're the only developers who can see it. It's high time we committed what we've written to the Subversion repository.
If you're using Eclipse, you may have been wondering what the question marks on the file and directory icons mean:
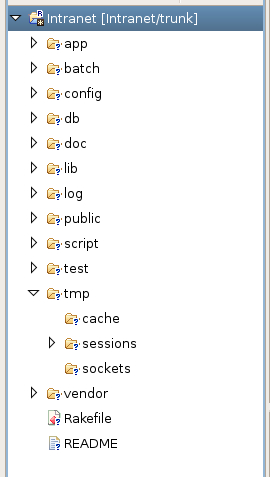
The question marks highlight the directories and files which the Subversion repository doesn't know about yet. These are the files we need to commit.
Before we leap in, it's worth taking some time to decide whether we need all of the highlighted files. Some of the files in the application are temporary, and don't need to be included. The next section describes how to exclude these files from the repository.
As well as the source code, our application directory contains several temporary files in the following directories:
- db: If you dump your database structure, it is stored in a file called
schema.rbinside this directory. As this file can be reconstructed dynamically, it is a good idea to exclude it from the repository. - log: Contains log data (in
*.logfiles) for individual Rails environments. When you run your applications using Mongrel (see Chapter 2), the log file for Mongrel is also stored here. - tmp/cache: If you use view caching (see section on view caching) to improve your application's performance, cache fragments will be stored here.
- tmp/sessions: If you followed the brief introduction to the scaffold in the section: The Scaffold, and accessed your application via a web browser, there may be several session files stored in this directory, prefixed with
ruby_sess. These files store session data for connected clients, and can occasionally be orphaned when sessions end (e.g. the user closes their browser). By the way, provided no clients are connected, you can just delete these files. - tmp/sockets: In some configurations (mainly, if running Rails applications under FastCGI), socket files will be stored here.
- tmp/pids: When running Rails under Mongrel, the process ID (PID) files identifying the server processes will be stored here.
Ideally, we want to exclude all temporary files from the Subversion repository: they are only applicable to the machine which created them. Any missing files will be created as soon as the application runs on a different machine, so there is no harm in excluding them. Other bonuses are that checking out an application is faster (no big log files); and that potentially sensitive information (e.g. debugging information in development.log) is not included when the application is distributed.
Subversion provides a facility for setting filename patterns which should be ignored (i.e. not committed to the repository and only stored in the working copy). This is done by setting a Subversion property called svn:ignore on each directory which contains temporary files. This property is a newline-separated list of filename patterns; any files with matching names are ignored and excluded from commits.
Files can be added to svn:ignore using the svn command line tool (have a look at svn help propedit); however, Eclipse provides a simple wrapper around this functionality, so we'll use that instead:
- Right-click on the directory containing the files we want to ignore (see the list above):
tmp/sessions, for example. - Select Team | Set Property...
- In the Set an svn property dialog box, select svn:ignore from the Property name drop-down box. Ensure the Enter a text property radio button is ticked, and enter
ruby_sess.*in the text area (a pattern which matches the temporary Ruby session files we want to ignore—you can use an asterisk character as a wild-card). The completed dialog box should look like this: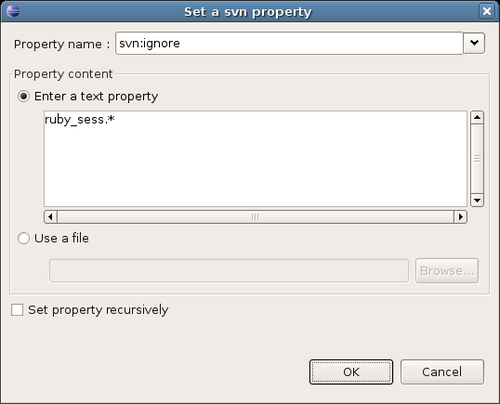
- Click OK.
The svn:ignore property is now set on the tmp/sessions directory. If at any time you want to edit or delete properties, right-click on the directory again and select Team | Show Properties from the context menu.
Following the same steps, set the following svn:ignore properties on the other locations:
db:set toschema.rb.log:set to*(ignore everything in this directory).tmp/cache:set to*.tmp/sessions:set to*.tmp/sockets:set to*.tmp/pids:set to*.
Finally, commit the code to repository, follow these steps.
- Right click on the project name (Intranet, in our case).
- Select Team | Commit from the context menu. You should see this dialog box:
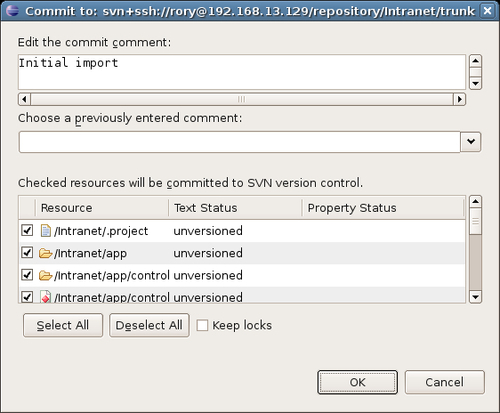
- Enter a suitable comment in the Edit the commit comment text area; click on the Select All button to select all resources for commit to the repository.
- Click OK. Eclipse will whirr away, committing the code to the repository. Once it is finished, you should see this in the resource view:
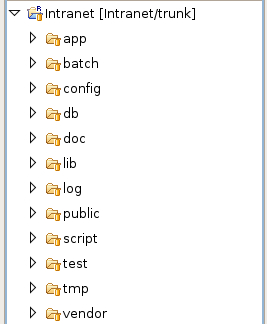
- Note that the yellow "barrels" on the files and directories indicate that they have been successfully added to the repository, and that they are in sync with it.
Each time you modify anything inside the project, Eclipse highlights the changed file with a white asterisk on a black background; it will also highlight any directories which contain a modified file, however deep the file is in the directory structure, with the same icon. You can right-click on the project or on the changed file(s) and select Team | Commit to commit the changes to the repository.
If you create new files, you will need to add them in to version control: simply right-click on the file and select Team | Add to Version Control.
Note
Try to use helpful comments each time you commit changes to the repository. Ideally, you should outline the reasoning behind the change, rather than explain the mechanics of what has changed. The repository can be queried to discover which parts of the code have changed; but it can't be queried for why the change occurred. For example, a comment like the fillowing:
"Added national insurance numbers for people."
This is more useful than:
"Added ni attribute to Person."
The original impetus behind the Intranet application was to make Mary's address book available to everyone working at Acme. So far, we have deconstructed Mary's Outlook address book export file, built a database from it, and developed a set of Rails models to wrap that database. The next step is to get the data, which was exported from Outlook, and process it with a script to insert records into the Intranet database. Rather than doing this manually, we are going to use the power of Ruby, coupled with ActiveRecord, to do the import for us.
Microsoft Outlook provides an export facility for contact data (File | Import and Export). The Acme team exports to a spreadsheet initially, as this makes it easier to do the initial data analysis. We won't dwell on the export process, as it is self-explanatory and fairly trivial: the Outlook documentation provides some good guidance on how to do this.
From the spreadsheet, they produce a tab-separated flat-file database, contacts.tsv. Here's a fragment of the file:
The first line of the file contains the field names; each subsequent line represents a single contact from Outlook, with tabs between the field values.
One issue which is immediately apparent is that some of the fields in the Outlook export file have new line characters in them. This is a problem, as the new line character is also used to delineate individual records (one record per line). The first fix is a manual one, therefore: removing any new line characters within field values. The result is this (record 3 for Frank Monk is the only one affected):

Note
This might be impractical for thousands of records: in such cases, the alternative would be to do more parsing of the raw text files to clear out anomalies. For example, the first pass might count tab characters, and combine multiple lines with too-few tabs into a single line with the correct number of tabs.
The next step is mapping the columns in the text file onto tables and fields in the database.
The script will have to break up each row of the text file into multiple instances of our models: a Person instance, a Company instance, an Address instance for the person's home address and an Address instance for the person's work address. To do this, the columns in the text file must be mapped onto the models in the Intranet application and attributes of those models. The table below describes how the Acme team decides to do this mapping. As two addresses are constructed for each line in the text file, the company Address instance is marked as Address(c), and the personal Address instance as Address(p).
|
Field exported from Outlook |
Maps to model/attribute |
Notes |
|---|---|---|
|
Title |
Person/title |
- |
|
First Name |
Person/first_name |
Required. |
|
Last Name |
Person/last_name |
Required. |
|
Company |
Company/name |
- |
|
Job Title |
Person/job_title |
- |
|
Business Street 1 |
Address(c)/street_1 |
- |
|
Business Street 2 |
Address(c)/street_2 |
- |
|
Business Street 3 |
Address(c)/street_3 |
- |
|
Business City |
Address(c)/city |
- |
|
Business State |
Address(c)/county |
- |
|
Business Postal Code |
Address(c)/post_code |
- |
|
Home Street |
Address(p)/street_1 |
- |
|
Home Street 2 |
Address(p)/street_2 |
- |
|
Home Street 3 |
Address(p)/street_3 |
- |
|
Home City |
Address(p)/city |
- |
|
Home State |
Address(p)/county |
- |
|
Home Postal Code |
Address(p)/post_code |
- |
|
Business Fax |
Company/fax |
- |
|
Business Phone |
Company/telephone |
If a value is provided for this field and for Company Main Phone, this field is ignored |
|
Company Main Phone |
Company/telephone |
If a value is provided for this field and for Business Phone, this field is used |
|
Home Phone |
Person/telephone |
- |
|
Mobile Phone |
Person/mobile_phone |
- |
|
Birthday |
Person/date_of_birth |
DD/MM/YY |
|
E-mail Address |
Person/email |
Required. |
|
Gender |
Person/gender |
"male" or "female"; if not set, "male" is assumed |
|
Keywords |
Person/keywords |
- |
|
Notes |
Person/notes |
- |
|
Web Page |
Company/website |
- |
Any other fields in the text file are ignored.
Another aspect of adding lines from the text file is doing it in the correct order. The associations we defined earlier in this chapter (see the section Associations Between Models) indicate that we should add records to the database in this order:
- Personal address
- Company address
- Company (referencing the company address just added as the value for the
address_idfield) - Person (referencing the company just added as the value for the
company_idfield, and the personal address just added as the value for theaddress_idfield)
We also need to consider the validation rules we defined earlier (see the section Validation). These may prevent some of the data in the Outlook export file from being added to the database: for example, if a person has no email address, his record is invalid according to our validation rules, which requires first_name, last_name, and email to contain values. The approach taken by Acme to deal with this is as follows:
- Write the script so that it highlights errors as they occur, e.g. print the line of the import file where the error occurs and show the validation errors thrown.
- Run the script with the initial text file.
- Fix problems with the text file as they are highlighted during the import. For example, if an address cannot be saved because of a missing post code, determine the post code for that address; if a person cannot be saved because their email address is missing, ring them up and find out the their email address.
- Roll the database back to a blank slate.
- Re-run the script.
- Re-iterate steps 2 to 5 until the script returns no unexpected or unwanted errors.
This approach wouldn't work in situations where the import is to be run periodically with no human intervention. In situations like this, the only approach may be to relax the validation rules to allow broken data into the system. In the case of Acme, where they are planning to do a one-off import, they can afford to be picky, and make sure the data is clean before it is inserted into the database.
Once Acme has cleaned their data as far as possible, and decided a process for further purifying the data as they go, they are ready to start coding. Acme stores the script in db/import inside their Rails application; they call it import_from_outlook.rb. Rather than go through the whole script line-by-line, we'll have a look at a pseudo-code overview of the script over the next two pages. The full code for the script is available from the book's code repository.
# Script for importing Outlook address data into Intranet. # Where data is retrieved from columns in the import file, the mapping # described in the section Mapping a Text File to Database Tables is used # to work out, which column it goes into in the database # Each time a save fails, show an error message and the line number # in the file where the error occurred. # Run this script through script/runner open contacts.tsv file (tab-separated contacts file exported from Outlook) read in the first line (which contains the column headings) split the first line around the tab character " " into array raw_field_names data processingscript, codingcreate a hash which maps the field name onto its index position in the array; this makes it easier to reference fields within the subsequent lines by field name, rather than position for each remaining line: split around tab character into an array of values # parse out company address get company street_1 and post_code if there is an existing address with the same street_1 and post_code: use that for the company address else: parse out the remaining address fields to create a new address save new address use it for the company address end # parse out personal address get personal street_1 and post_code if there is an existing address with the same street_1 and post_code: use that for the personal address else: parse out the remaining address fields to create a new address save new address use it as the personal address end # company get the company name field if there is an existing company with that name: use that company as the person's company else: parse out the remaining company fields to fill out the company details associate the company with the company address extracted earlier save new company end # person parse out the person fields to create a new person (using the mapping) associate with personal address associate with company save new person end # no more lines in file
One of the most important tips in this script is how to load the Rails environment to make the database available without having to run the application in a server setting. Rails makes this simple: you just need to run the script/runner script that is included with your application, passing it the location of the script file, e.g.
$ ruby script/runner db/import/import_from_outlook.rb
Once the script is ready, the Acme developers tests it repeatedly against the data exported from Mary's Outlook address book, until they are happy it is as error free as possible. This is made possible by their migrations, which enable them to start each test run from a blank slate by running the following commands from the command line (inside RAILS_ROOT):
$ rake db:migrate VERSION=0 $ rake db:migrate $ ruby script/runner db/import/import_from_outlook.rb ...
Here is a tangible example of the benefits of migrations: the Acme developers can repeat the cycle of destroying the database, rebuilding it, then inserting the data as many times as they need to, until they have ironed out any problems with the import file.