
In this chapter, we will be taking a much closer look at the real subject of this book, that is, learning Neo4j—the world's leading graph database. In this chapter, we will be going through and familiarizing ourselves with the database management system so that we can start using it in the following chapters with real-world models and use cases.
We will discuss the following topics in this chapter:
- Key concepts and characteristics of Neo4j
- Neo4j's sweet spot use cases
- Neo4j's licensing model
- Installing Neo4j
- Using Neo4j in the cloud
Let's start with the first topic straightaway.
Before we dive into the details of Neo4j, let's take a look at some of the key characteristics of Neo4j specifically as a graph database management system. Hopefully, this will immediately point out and help you get to grips with some of the key strengths as well.
Like many open source projects and many open source NoSQL database management systems, Neo4j too came into existence for very specific reasons. Scratching the itch, as this is sometimes called. Grassroots developers who want to solve a problem and are struggling to do so with traditional technology stacks, decide to take a radical, new-found approach. That's what the Neo4j founders did early on in the 21st century—they built something to solve a problem for a particular media company in order to better manage media assets.
In the early days, Neo4j was not a full-on graph database management system—it was more like a graph library that people could use in their code to deal with connected data structures in an easier way. It was sitting on top of traditional, MySQL (and other) relational database management systems and was much more focused on creating a graph abstraction layer for developers than anything else. Clearly, this was not enough. After a while, the open source project took a radical decision to move away from the MySQL infrastructure and to build a graph store from the ground up. The key thing here is from the ground up. The entire infrastructure, including low-level components such as the binary file layout of the graph database store files, is optimized for dealing with graph data. This is important in many ways, as it will be the basis for many of the speed and other improvements that Neo4j will display versus other database management systems.
We don't need to understand the details of this file structure for the basis of this book—but suffice to say that it is a native, graph-oriented storage format that is tuned for this particular workload. That, dear reader, makes a big difference.
Neo4j prides itself in being an ACID-compliant database. To explain this further, it's probably useful to go back to what ACID really means. Basically, the acronym is one of the oldest summaries of four goals that many database management systems strive for, and they are shown in the following figure:
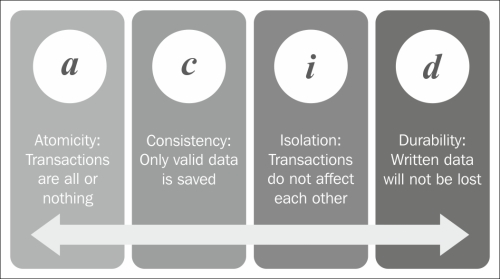
- Atomicity: This means that changes in the database must follow an all or nothing rule. Transactions are said to be "atomic" if one part of the transaction fails, then the consequence would be that the entire transaction is rolled back.
- Consistency: This means that only consistent or "valid" data will be allowed to be entered into the database. In relational terminology, this often means that the schema of the database has to be applied and maintained at all times. The main consistency requirement in Neo4j is actually that the graph relationships must have a start and an end node. Relationships cannot be dangling. Aside from this, however, the consistency rules in Neo4j will obviously be much looser, as Neo4j implements the concept of an "optional" schema.
Note
The optional schema of Neo4j is really interesting: the idea being that it is actually incredibly useful to have a schema-free database when you are still at the beginning of your development cycles. As you are refining your knowledge about the domain and its requirements, your data model will just grow with you—free of any requirements to pre-impose a schema on your iterations. However, as you move closer to production, schema—and therefore consistency—can be really useful. At that point, system administrators and business owners alike will want to have more checks and balances around data quality, and the C in ACID will become more important. Neo4j fully supports both approaches, which is tremendously useful in today's agile development methodologies.
- Isolation: This requires that multiple transactions that are executed in parallel on the same database instance would not impact each other. The transactions need to take their due course, irrespective of what is happening in the system at the same time. One of the important ways that this is used is in the example where one transaction is writing to the database and another is reading from it. In an isolated database, the read transaction cannot know about the write that is occurring "next to" it until the transaction of the write operation is complete and fully committed. As long as the write operation is not committed, the read operation will have to work with the "old" data.
- Durability: This basically means that committed transactions cannot just disappear and be lost. Persisted storage and transaction commit logs that are forced to be written to disk—even when the actual data structures have not been updated yet—ensure this quality in most database systems and also in Neo4j.
The summary of all this is probably that Neo4j, really, has been designed from the ground up to be a true multipurpose database-style solution. It shares many of the qualities of a traditional relational database management system that we know today—it just uses a radically different data model that is well suited for densely connected use cases.
The mentioned characteristics help with systems where you really need to be returning data from the database management system in an online system environment. This means that the queries that you want to ask the database management system would need to be answered in the timespan between a web request and a web response. In other words, in milliseconds—not seconds, let alone minutes.
This characteristic is not required of every database management system. Many systems actually only need to reply to requests that are first fired off and then require an answer many hours later. In the world of relational database systems, we call these analytical systems. We refer to the difference between the two types of systems as the difference between Online Transaction Processing (OLTP) and Online Analytical Processing (OLAP). There's a significant difference between the two—from a conceptual as well as from a technical perspective. So let's compare the two in the following table:
|
Online Transaction Processing (Operational System) |
Online Analytical Processing (Analytical System, also known as the data warehouse) | |
|---|---|---|
|
Source of data |
Operational data; OLTPs are the original source of the data |
Consolidation data; OLAP data comes from the various OLTP databases |
|
Purpose of data |
To control and run fundamental business tasks |
To help with planning, problem solving, and decision support |
|
What the data provides |
Reveals a snapshot of ongoing business processes |
Multidimensional views of various kinds of business activities |
|
Inserts and updates |
Short and fast inserts and updates initiated by end users |
Periodic long-running batch jobs refresh the data |
|
Queries |
Relatively standardized and simple queries returning relatively few records |
Often complex queries involving aggregations |
|
Processing speed |
Typically very fast |
Depends on the amount of data involved; batch data refreshes and complex queries may take many hours |
|
Space requirements |
Can be relatively small if historical data is archived |
Larger due to the existence of aggregation structures and history data; requires more indexes than OLTP |
|
Database design |
Highly normalized with many tables |
Typically de-normalized with fewer tables; use of star and/or snowflake schemas |
|
Backup and recovery |
Backs up religiously; operational data is critical to run the business, data loss is likely to entail significant monetary loss and legal liability |
Instead of regular backups, some environments may consider simply reloading the OLTP data as a recovery method |
At the time of writing this, Neo4j is clearly in the OLTP side of the database ecosystem. That does not mean that you cannot do any analytical tasks with Neo4j. In fact, some analytical tasks in the relational world are far more efficiently run on a graph database (see the sweet spot query section that follows later), but it is not optimized for it. Typical Neo4j implementation recommendations would also suggest that you put aside a separate Neo4j instance for these analytical workloads so that it would not impact your production OLTP queries. In the future, Neo Technology plans to make further enhancements to Neo4j that make it even more suited for OLAP tasks.
In order to deal with the OLTP workload, Neo4j obviously needs to be able to support critical scalability, high availability, and fault-tolerance requirements. Creating clusters of database server instances that work together to achieve the goals stated before typically solves this problem. Neo4j's Enterprise Edition, therefore, features a clustering solution that has been proven to support even the most challenging workloads.
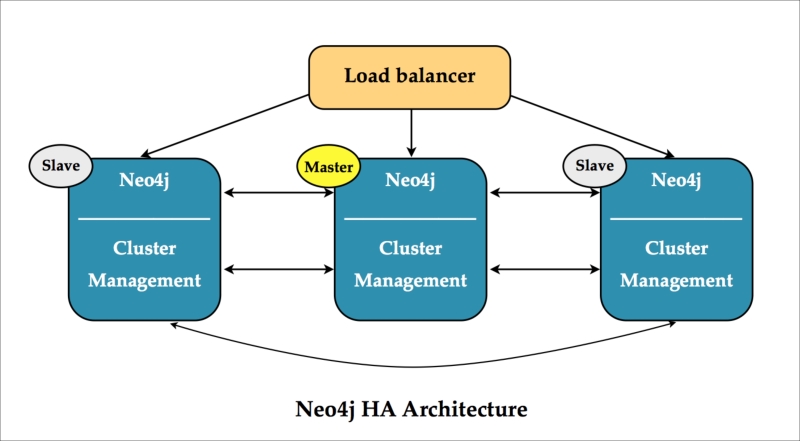
Neo4j high availability architecture
As you can see from the preceding diagram, the Neo4j clustering solution is a master-slave clustering solution. In a particular cluster, each server instance of the cluster will perform the following steps:
- Hold the entire dataset of the database. All servers hold the same data and therefore can respond to all query requests.
- Comply with a master-slave consistency scheme. This means that, in case of potential conflicting data in the database, the Master server instance will decide what would be right data to keep and persist. If at some point, the cluster would lose its master, the remaining cluster member instances would run a master election algorithm (in Neo4j's case, based on Paxos) that allows them to quickly choose a new master.
- The server should be optimized to deal with a particular subset of the queries that hit the cluster. For example, the load balancer would be configured in such a way that specific types of queries (for example, write queries versus read queries, queries for a specific region/continent, and queries from a specific application) would be directed to a specific cluster member. The advantage of doing so is that this will allow Neo4j to optimize its caching content and use a concept that we sometimes refer to as a "sharded cache". This means that the cluster members may in fact be holding the same dataset in their database store files, but in memory, in the cache, they will hold very different parts of the graph. Similar to any database management system, queries served up from a cache will be much faster. So, we want to try and optimize the cluster for this. If by some twist of fate the queries don't end up on the right instance, then that does not mean that the application will stop functioning. It will just not respond from cache, and therefore respond a bit slower.
Neo4j's clustering solution allows you to provide the following features:
This covers 99 percent of all use cases—the references of Neo Technology speak for itself.
One of the defining features of the Neo4j graph database product today is its wonderful query language, called Cypher. Cypher is a declarative, pattern-matching query language that makes graph database management systems understandable and workable for any database user—even the less technical ones.
The key characteristic of Cypher is, in my opinion, that it is a declarative language, opposed to other imperative query languages that have existed for quite some time. Why is this so important? Here are your answers:
- Declarative languages allow you to state what you're looking for, declare the pattern that you would like to see retrieved, and then let the database worry about how to go about retrieving that data.
In an imperative (query) language, you would have to tell the database specifically what to do to get to the data and retrieve it.
- Declarative languages separate the concern of stating the problem, from solving it. This allows greater readability of the queries that you write, which is important as people tend to read their database queries more often than they write them. This piece of your software will therefore become more readable and shareable with others, and long term maintenance of that easy-to-read query becomes so much easier.
- Declarative languages will allow the database to use the information that it holds about the nature and structure of the data to answer your question more efficiently. Essentially, it allows query optimizations that you would never have known of or thought about in an imperative approach. Therefore, declarative languages can be faster—at least over time as the optimization algorithms mature.
- Declarative languages are great for adhoc querying of your database, without you having to write complex software routines to do so.
Part of the reason why I feel that Cypher is such an important part of Neo4j is that we know that declarative languages, especially in the database management systems world, are critical to mass adoption. Most application developers do not want to be worrying about the nitty gritty of how to best interact with their data. They want to focus on the business logic and the data should just be there when I want it, as I want it. This is exactly how relational database systems evolved in the seventies (refer to Chapter 2, Graph Databases – Overview). It is highly likely that we will be seeing a similar evolution in the graph database management system space. Cypher, therefore, is in a unique position and makes it so much easier to work with the database. It is already an incredible tool today, and it will only become better.
Like with many software engineering tools, Neo4j too has its sweet spot use cases—specific types of uses that the tool really shines and adds a lot of value to your process. Many tools can do many things and so can Neo4j, but only a few things can be done really well by a certain tool. We have addressed some of this already in the previous chapter. However, to summarize specifically for the Neo4j software package, I believe that there are two particular types of cases—featuring two specific types of database queries—where the tool really excels.
We discussed in the previous chapter how relational database management systems suffer from significant drawbacks, as they have to deal with more and more complex data models. Asking these kinds of questions of a relational database requires the database engine to calculate the Cartesian product of the full indices on the tables involved in the query. That computation can take a very long time on larger datasets, or if more than two tables are involved.
Graph database management systems do not suffer from these problems. The join operations are effectively precalculated and explicitly persisted in the database based on the relationships that connect nodes together. Therefore, joining data becomes as simple as hopping from one node to another—effectively as simple as following a pointer. These complex questions that are so difficult to ask in a relational world are extremely simple, efficient, and fast in a graph structure.
Many users of Neo4j use the graph structure of their data to find out whether there are useful paths between different nodes on the network. Useful in this phrase is probably the operative word; they are looking for specific paths on the network to:
- See whether the path actually exists. Are there any connections between two data elements, and if so what does that connectivity look like?
- Look for the optimal path. Which path between two things has the lowest "cost?"
- Look for the variability of the path if a certain component of the path changes. What happens to the path if the properties of a node or relationship change?
Both of these sweet spot use cases share a couple of important characteristics:
- They are "graph local" and they have one or more fixed starting point(s), or "anchor", in the graph from where the graph database engine can start traversing out
- They are performed "in the clickstream", and therefore performed on near-real-time data
Let's now switch to another key element of Neo4j's success as a graph database management system: the fact that it is an open source solution.
One of the key things that we have seen happening in Enterprise information technology, is the true and massive adoption of open source technologies for many of its business-critical applications. This has been an evolution that has lasted a decade at least, starting with peripheral systems such as web servers (in the days when web servers were still considered to be serving static web pages), but gradually evolving to mission critical operating systems, content management applications, CRM systems and databases such as Neo4j.
There are many interesting aspects to open source software, but some of the most often quoted are listed as follows:
- Lower chance of vendor lock-in: Since the code is readily available, the user of the software could also read the code themselves and potentially understand how to work with it (and extend it, or fix it, or audit it, and so on) independently of the vendor.
- Better security: As the code is undergoing public scrutiny and because there is no way for a developer to implement "security through obscurity" (for example by using a proprietary algorithm that no one knows and would have to reverse engineer), open source software systems should be intrinsically more secure.
- Easier support and troubleshooting: As both the vendor and the customer have access to the source code, it should be easier to exchange detailed, debug-level information about the running system and make it easier to pinpoint problems.
- More innovation through extensibility: By exposing source code, many people left and right will start playing with the software—even without the original author knowing that this is going on. This typically causes these "community contributors" to solve problems that they encounter with the product, in their specific use case, and it leads to faster innovation and extensibility of the solution.
- Supporting (fundamental and applied) research: Open source solutions—even the ones equipped with enterprise commercial features such as Neo4j—usually allow researchers to use the software for free. Most researchers also published their work as open source code. So, it's a two-way street.
- Cheaper: open source software tends to use "fair" licensing models. You only need to pay if you derive value from the software and are not able to contribute your code. This not only allows cheaper evaluation of the software in the start of the process—hopefully avoiding unused shelfware—but also allows enterprises to start with limited investments and grow gradually as the use expands.
I believe that all is true for Neo4j. Let's look at the different parameter axes that determine the license model. Three parameters are important, which are explained in the following sections.
Neo4j offers different feature sets for different editions of the graph database management system:
- Community Edition: This is the basic, fully functional, high-performance graph database.
- Enterprise Edition: This adds a number of typical Enterprise features to the Community Edition: clustering (for high availability and load balancing), advanced monitoring, advanced caching, and online backups. Neo Technology has a number of additional features lined up on the Enterprise Edition roadmap.
Most users of Neo4j start off with the Community Edition, but then deploy into production on the Enterprise Edition.
Different support channels exist for Neo4j's different editions:
- The Community Edition offers "community support". This means that you are welcome to ask questions and seek support on the public forums (Google group, Stack Overflow, Twitter, and other channels). However, note the following points:
- The responses will always need to be publicized (cannot be private)
- The response will not be guaranteed or timed
Neo Technology does sponsor a significant team of top-notch engineers to help the community users, but at the end of the day, this formula does have its limitations.
- The Enterprise Edition offers a professional grade support team that is available 24/7, follows the sun, and has different prioritization levels with guaranteed response times. At the time of writing this, Neo Technology also offers direct access to its engineers that write the product so that customers can literally get first-hand information and help from the people that build Neo4j themselves.
The support program for Neo4j is typically something that is most needed at the beginning of the process (as that is when the development teams have most questions about the new technology that they are using), but it is often only sought at the end of a development cycle.
For the slightly more complicated bit, Neo Technology has chosen very specific licensing terms for Neo4j, which may seem a tad complicated but actually really supports the following goals:
- Promoting open source software
- Promoting community development of Neo4j
- Assuring the long-term viability of the Neo4j project by providing for a revenue stream.
This is achieved in the following ways:
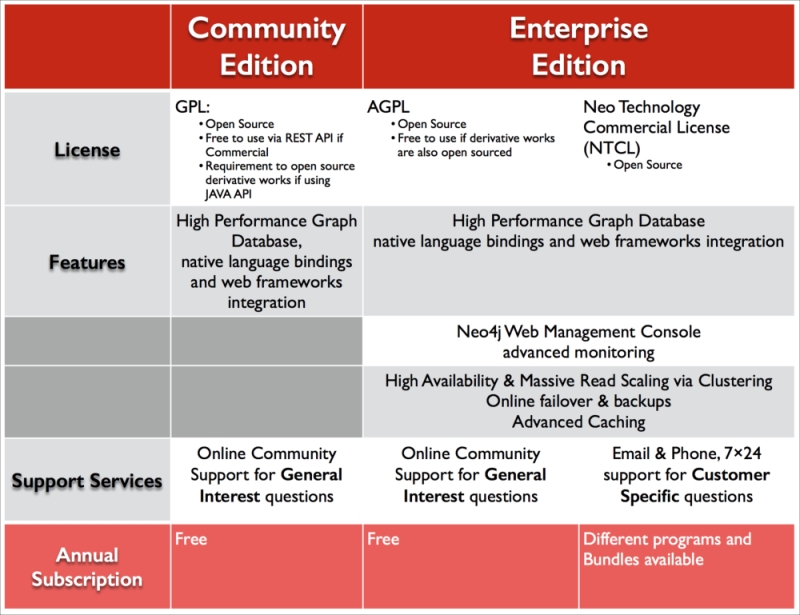
- The Community Edition uses the GNU Public License Version 3 (GPLv3) as its licensing terms. This means that you may copy, distribute, and modify the software as long as you track changes/dates of in source files and keep modifications under GPL. You can distribute your application using a GPL library commercially, but you must also provide the source code. It is therefore a very viral license and requires you to open source your code—but only if your code directly interfaces with the Neo4j code through the Java API. If you are using the REST API, then there are little or no contamination effects and you can just use Neo4j at will.
- The Enterprise Edition uses a so-called dual license model. This means that users of the Neo4j Enterprise Edition can choose one of two options:
- Either they adhere to the Affero GNU Public License Version 3 (AGPLv3), which is sometimes also referred to as the "GPL for the web".
Note
The AGPL license differs from the other GNU licenses in that it was built for network software. Similar conditions apply as to the GPL; however, it is even more "viral" in the sense that it requires you to open source your code not only when you link your code on the same machine (through Neo4j's Java API), but also if you interface with Neo4j over the network (through Neo4j's REST API). So, this means that if you use Neo4j's Enterprise Edition for free, you have to open source your code.
- Get a Neo Technology Commercial License (NTCL). This license is a typical commercial subscription license agreement, which gives you the right to use Neo4j Enterprise Edition for a certain period of time, on a certain number of machines/instances.
- Either they adhere to the Affero GNU Public License Version 3 (AGPLv3), which is sometimes also referred to as the "GPL for the web".
All of the mentioned points are summarized in the following figure:
An overview of the Neo4j license
As indicated in the preceding figure, Neo Technology offers a number of different annual commercial subscription options, depending on the number of instances that you will deploy, the type of company you are (startup, mid-sized corporation, or large corporation), the legal contract requirements of the agreement, and the support contract. For more information on the specifics of these bundles—which change regularly—you can contact <[email protected]>.
With that, we have wrapped up this section and will now proceed to getting our hands dirty with Neo4j on the different platforms available.