
Chapter 13. Case study 2: SIREn
Searching semistructured documents with SIREn
Contributed by RENAUD DELBRU, NICKOLAI TOUPIKOV, MICHELLE CATASTA, ROBERT FULLER, and GIOVANNI TUMMARELLO
In this case study, the crew from the Digital Enterprise Research Institute (DERI; http://www.deri.ie) describes how they created the Semantic Information Retrieval Engine (SIREn) using Lucene. SIREn (which is open source and available at http://siren.sindice.com) searches the semantic web, also known as Web 3.0 or the “Web of Data,” which is a quickly growing collection of semistructured documents available from web pages adopting the Resource Description Framework (RDF)[1] standard. With RDF, pages publicly available on the web encode structural relationships between arbitrary entities and objects via predicates. Although the standard has been defined for some time, it’s only recently that websites have begun adopting it in earnest.
1 See http://en.wikipedia.org/wiki/Resource_Description_Framework.
A publicly accessible demonstration of SIREn is running at http://sindice.com, covering more than 50 million crawled structured documents, resulting in over 1 billion entity, predicate, and object triples. SIREn is a powerful alternative to the more common RDF triplestores, typically backed by relational databases and thus often limited when it comes to full-text search.
One of the challenges when indexing RDF is the fact that there’s no fixed schema: anyone can create new terms in their descriptions. This raises important challenges. As you’ll see, SIREn first attempted to use a simplistic mapping of RDF subject, predicate, object triples to documents, where each predicate was a new field. But this led to performance challenges, because the number of fields is unbounded. To solve this, payloads (covered in section 6.5) were used to efficiently encode the tuple information, and the resulting architecture provides a highly scalable schema free RDF search.
SIREn perhaps sets the record for making use of Lucene’s customization APIs: it has created a number of Lucene extensions, including tokenizers (TupleTokenizer), token filters (URINormalisationFilter, SirenPayloadFilter), analyzers (TupleAnalzyer, SPARQLQueryAnalyzer), queries (CellQuery, TupleQuery), and its own query parser to handle SPARQL RDF queries (a standard query language for RDF content, defined by the W3C (World Wide Web Consortium). SIREn’s analysis chain is a good example of using a token’s type to record custom information per token, which is then consumed downstream by another token filter to create the right payloads. SIREn even includes integration with Solr. Such a componentized approach gives SIREn its open architecture, allowing developers to choose components to create their semantic web search application. Advanced stuff ahead!
13.1. Introducing SIREn
Although the specifications for RDF and Microformats[2] have been out for quite some time now, it’s only in the last few years that many websites have begun to make use of them, thus effectively starting the Web of Data. Sites such as LinkedIn, Eventful, Digg, Last.fm, and others are using these specifications to share pieces of information that can be automatically reused by other websites or by smart clients. As an example, you can visit a Last.fm concert page[3] and automatically import the event in its calendar if an appropriate Microformats browser plug-in is used.
At DERI, we’re developing the Sindice.com search engine. The goal of this project is to provide a search engine for the Web of Data. The challenge is that such an engine is expected not only to answer textual queries but also structured queries—that is, queries that use the structure of the data. To make things a bit more complex, the RDF specifications allow people to freely create new terms to use in their descriptions, making it effectively a schema-free indexing and structured answering problem.
Traditionally, querying graph-structured data has been done using ad hoc solutions, called triplestores, typically based on a database management system (DBMS) back-end. For Sindice, we needed something much more scalable than DBMSs and with the desirable features of the typical web search engines: top documents matching a query, real-time updates, full-text search, and distributed indexes.
Lucene has long offered these capabilities, but as you’ll see in the next section, its native capabilities aren’t intended for large semistructured document collections with different schemas. For this reason we developed SIREn, a Lucene extension to overcome these shortcomings and efficiently index and query RDF, as well as any textual document with an arbitrary number of metadata fields. Among other things, we developed custom tokenizers, token filters, queries, and scorers.
SIREn is today in use not only in Sindice.com but also within enterprise data integration projects where it serves as a large-scale schema-free semantic search engine to query across large volumes of documents and database records.
13.2. SIREn’s benefits
The Web of Data is composed of RDF statements. Specifically, an RDF statement is a triple consisting of a subject, a predicate, and an object, and asserts that a subject has a property (the predicate) with some value (the object). A subject, or entity, has a reference that has the form of an URI (such as http://renaud.delbru.fr/rdf/foaf#me). There are two kinds of statements:
- An attribute statement, A(e, v), where A is an attribute (foaf:name), e is an entity reference, and v is a literal (such as an integer, string, or date)
- A relation statement, R(e1, e2), where R is a relation (foaf:knows), and e1 and e2 are entity references
Those RDF statements intrinsically form a giant graph of interlinked entities (people, products, events, etc.). For example, figures 13.1 and 13.2 show a small RDF data set and how it can be split into three entities: renaud, giovanni, and DERI. Each entity graph forms a star composed of the incoming and outgoing relations of an entity node. Oval nodes represent entity references and rectangular ones represent literals. For space consideration, URIs have been replaced by their local names. In N-Triples syntax, URIs are enclosed in angle brackets (< and >), literals are written using double quotes, and a dot signifies the end of a triple. The following is a snippet of the N-Triples[4] syntax of the entity graph renaud:
4 N-Triples: http://www.w3.org/2001/sw/RDFCore/ntriples/
Figure 13.1. A visual representation of an RDF graph. The RDF graph is split (dashed lines) into three entities identified by the nodes renaud, giovanni, and DERI.
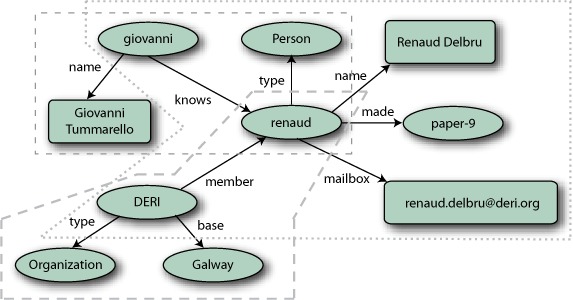
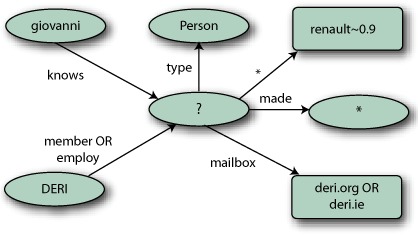
Figure 13.2. Star-shaped query matching the entity renaud, where ? is the bound variable and * a wildcard
http://renaud.delbru.fr/rdf/foaf#me<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
SIREn follows an entity-centric view; its main purpose is to index and retrieve entities. To search and locate an entity on the Web of Data, SIREn offers the ability to ask star-shaped queries such as the one in figure 13.2. You could argue that Lucene already has the possibility to create such star-shaped queries as the document fields need not follow a fixed schema (see section 2.1.2). For example, each entity can be converted into a Lucene document, where each distinct predicate is a dynamic field and objects are values indexed into that field. Following this approach, a Lucene document will contain as many dynamic fields as the entity has predicates. But the use of dynamic fields isn’t suitable when dealing with semistructured information, as we’ll explain in a moment, and a new data model like the one we proposed is necessary.
The web provides access to large data sources of all kinds. Some of these data sources contain raw data where the structure exists but has to be extracted. Some contain data that has structure but isn’t as rigid and regular as data found in a database system. Data that’s neither raw nor strictly typed is called semistructured data. Semistructured data can also arise when integrating several structured data sources because it’s to be expected that the data sources won’t follow the same schemas and the same conventions for their values.
SIREn is intended for indexing and querying large amounts of semistructured data. The use of SIREn is appropriate when
- You have data with a large schema or multiple schemas
- You have a rapidly evolving schema
- The type of data elements is eclectic
SIREn lets you efficiently perform complex structured queries (when the program or user is aware of the schema) as well as unstructured queries, such as simple keyword searches. Moreover, even in the case of unstructured queries, SIREn will be able to “respect” the data structure during the query processing to avoid false positive matches, as we’ll explain in the next section.
13.2.1. Searching across all fields
With semistructured documents, the data schema is generally unknown and the number of different fields in the data collection can be large. Sometimes, we aren’t able to know which field to use when searching. In that case, we can execute the search in every field.
The only way to search multiple fields at the same time in Lucene is to use the wildcard * pattern for the field element (WildcardQuery is covered in section 3.4.7). Internally, Lucene will expand the query by concatenating all the fields to each query terms. As a consequence, this will generally cause the number of query terms to increase significantly. A common workaround is to copy all other fields to a catchall search field. This solution can be convenient in certain cases, but it duplicates the information in the index and therefore increases the index size. Also, information structure is lost, because all values are concatenated inside one field.
13.2.2. A single efficient lexicon
Because data schemas are free, many identical terms can appear in different fields. Lucene maintains one lexicon per field by concatenating the field name with the term. If the same term appears in multiple fields, it will be stored in multiple lexicons. As SIREn primarily uses a single field, it has a single large lexicon and avoids term duplication in the dictionary.
13.2.3. Flexible fields
The data schema is generally unknown, and it’s common to have many name variations for the same field. In SIREn, a field is a term as any other element of the data collection and can thus be normalized before indexing. In addition, this enables full-text search (Boolean operator, fuzzy operator, spelling suggestions, etc.) on a field name. For example, on the Web of Data, we generally don’t know the exact terms (such as URIs) used as predicates when searching entities. By tokenizing and normalizing the predicate URI—for example, http://purl.org/dc/elements/1.1/author—we can search for all the predicates from one or more schemas containing the term author.
13.2.4. Efficient handling of multivalued fields
In Lucene, multivalued fields are handled by concatenating values together before indexing (see section 2.4.7). As a consequence, if two string values Mark James Smith and John Christopher Davis are indexed in a field author, the query author:"James AND Christopher" looking for an author called “James Christopher” will return a false positive. In SIREn, values in a multivalued property remain independent in the index and each one can be searched either separately or together.
13.3. Indexing entities with SIREn
To understand how SIREn indexes entities, you need to understand the following:
- The data model and how it’s implemented on top of the Lucene framework
- The Lucene document schema that will index and store an entity
- How data is prepared before indexing
Let’s take a look at each concept.
13.3.1. Data model
Given an entity, a way to represent its RDF description is to use two tables, each one having a tuple per RDF triple: in one table (outgoing relationships), the tuple key is the subject s (entity), the first cell is the predicate p (property), and the second one is the object o (value). In the second table (incoming relationships), the order is reversed; the key is the object o, and the second cell is the subject s. A generalized version of this accounting for multivalued predicates (such as multiple statements having the same s and p but different o) can be seen as two tuple tables composed by p and n values. This is shown in table 13.1. In SIREn, there’s no limit on the number of cells and null values are free.
Table 13.1. Representation of an entity tuple table
|
Outgoing relations |
|||||
|---|---|---|---|---|---|
|
Subject |
Predicate |
Object 1 |
Object 2 |
Object n |
|
| id1 | rdf:type | Person | Student | ... | Thing |
| id1 | foaf:name | Renaud Delbru | R. Delbru | ... | |
| id1 | foaf:mailbox | [email protected] | ... | ||
| id1 | foaf:made | paper-9 | paper-12 | ... | paper-n |
| ... | ... | ||||
| Incoming relations | |||||
| Object | Predicate | Subject 1 | Subject 2 | Subject n | |
| id1 | foaf:knows | giovanni | nickolai | ... | |
| id1 | foaf:member | DERI | ø | ... | |
| ... | ... | ||||
Each cell can be searched independently or together as one unit using full-text search operations such as Boolean, proximity, or fuzzy operators. By combining multiple cells, you can query a tuple pattern to retrieve a list of entity identifiers. It’s also possible to combine tuples to query an entity description. The tuples listed in section 13.2 provide an example of combining query operators to match the entity described in table 13.1.
13.3.2. Implementation issues
Let’s now explore how the structural information associated with a term can be transposed into Lucene. The data model is similar to the path-based model described in Proceedings of International Symposium on Digital Media Information Base, November 1997.[5] In this model, each term occurrence is associated with the following information: entity, tuple, cell, and position.
5 R. Sacks-Davis, T. Dao, J. A. Thom, and J. Zobel. Indexing documents for queries on structure, content and attributes. In Proceedings of International Symposium on Digital Media Information Base (DMIB), pages 236–245. World Scientific, November 1997.
The content of a cell can be any kind of information (text, URI, integer, date, etc.) and is itself decomposed into a sequence of terms. These terms are indexed, similarly to a classical Lucene index, along with their position. In addition, we assign a cell identifier (cid) to each term occurrence. The cid is derived from the cell index in the tuple. For example, a term that occurs in the first cell will be labeled with cid=0. The tuple can be addressed using an internal identifier (tid) for each tuple within an entity. We assign to each entity a unique identifier (eid), which is in fact the internal document identifier assigned by Lucene.
The index format has been implemented using the Lucene payload feature (described in section 6.5). Each term payload contains the tuple and cell identifier. Therefore, a Lucene posting holds a sequence of term occurrences, in the following format:
Term -> <eid, freq, TermPositions^freq>^tef TermPositions -> <pos, Payload> Payload -> <tid, cid>
The tef parameter is simply the number of entity descriptions that contains the term, and it’s similar to the term document frequency in a normal document index. Those identifiers are stored efficiently using variable-byte encoding because they’re generally small. In average, storing this information requires only 2 bytes per term.
13.3.3. Index schema
We designed a generic set of fields for Lucene documents that hold entities. The Lucene document schema is described in table 13.2. Some of the fields, such as subject, context, and content, are necessary for implementing the SIREn index. The field subject indexes and stores the subject (the resource identifier of the entity), whereas context indexes the provenance (URL) of the entity. Those fields are returned as search results but can also be used for restricting a query to a specific entity or context. The content field holds the tuple table—that is, the RDF statements describing the entity.
Table 13.2. The Lucene document schema used for the Sindice use case
|
Field name |
Description |
|---|---|
| subject | URI of the entity (subject element of the statement). |
| context | URI of the data set containing the entity (context element of the statement). |
| content | The list of tuples describing the entity. This field is using the SIREn data format presented earlier. |
| ontology | List of ontologies used in the entity description. |
| domain | The domain where the entity is published. |
| data-source | The source of the data: crawled, dumped, or pinged. |
| format | The original format of the data: RDF, RDFa, Microformats, etc. |
We chose the other fields for implementing additional features for the Sindice use case, such as query filter operators and faceted browsing. It’s then possible to filter search results by ontology, domain, data source, or format.
13.3.4. Data preparation before indexing
Lucene documents are sent to the index server. The document is analyzed before indexing. We created our own Lucene analyzer for fields containing tuples. The field content, of type tuple, has a special syntax derived from the N-Triples syntax:
http://www.w3.org/1999/02/22-rdf-syntax-ns#type
URIs are enclosed in angle brackets, literals are written using double quotes, blank nodes are written as _:nodeID, and a dot signifies the end of a tuple.
A TupleTokenizer, a grammar-based tokenizer generated with JFlex, breaks text using the tuple syntax into tokens. It generates tokens of different types, such as uri, bnode, and literal for the elements of a tuple, but also cell_delimiter and tuple_delimiter to inform the TupleAnalyzer downstream of the ending of a tuple element or tuple (section 4.2.4 describes the token’s type attribute). The TupleTokenizer embeds a Lucene analyzer for analysis of the literal tokens. Whenever a literal token is created, it’s sent to this second analyzer in order to tokenize the literals. This offers the flexibility of reusing Lucene components for analyzing the textual information of the literals.
The TupleAnalyzer defines the TokenFilters that are applied to the output of the TupleTokenizer. We created two special filters for the SIREn extension: the URINormalisationFilter and the SirenPayloadFilter. Other original Lucene filters are used, such as StopWordFilter and LowerCaseFilter.
The URINormalisationFilter normalizes URIs by removing trailing slashes and by breaking down a URI into subwords and generating multiple variations; for example:
"http://xmlns.com/foaf/0.1/name" ->
(position:token)
0:"http"
1:"xmlns.com",
2:"foaf",
3:"0.1",
4:"name",
5:"http://xmlns.com/foaf/0.1/name"
These variations are useful for enabling full-text search on a URI. It’s then possible to write queries like name, foaf AND name or http://xmlns.com/foaf/0.1/.
The class SirenPayloadFilter (shown in listing 13.1) assigns the structural information to each token and encodes them into the token payload. Note that the token filter uses the version 2.4 tokenizer APIs (for example, the next() method), which have been removed in Lucene as of version 3.0. Payloads are covered in section 6.5.
Listing 13.1. How SirenPayloadFilter processes the token stream
public class SirenPayloadFilter extends TokenFilter {
protected int tuple, tupleElement = 0;
@Override
public Token next(final Token result) throws IOException {
if ((result = input.next(result)) == null) return result;
if (result.type().equals("<TUPLE_DELIMITER>")) {
tuple++; tupleElement = 0;
}
else if (result.type().equals("<CELL_DELIMITER>"))
tupleElement++;
else
result.setPayload(new SirenPayload(tupleID, cellID));
return result;
}
}
13.4. Searching entities with SIREn
Next we’ll present a set of query operators, implemented into SIREn, for performing operations on the content and structure of the tuple table. Those query components are the building blocks for writing search queries for data sets and entities.
13.4.1. Searching content
SIREn includes primitive query operators that access the content of a tuple table. These query operators provide basic operations, such as term lookups (TermQuery, PhraseQuery) or more advanced functionality such as fuzzy or prefix operators. They can then be combined with higher-level operators such as Boolean operators (intersection, union, difference), proximity operators (phrase, near, before, after, etc.), or SIREn operators (cell, tuple).
These operators reproduce the same strategy as the original Lucene operators with the small difference that, during query processing, their scorers read tuple information from the payload and use them to filter out irrelevant matches. For example, the TermScorer scores a term and provides an iterator over the entity, tuple, cell, and position (eid, tid, cid, pos) of the term. In fact, all the SIREn Scorers implement the interface SirenIdIterator (shown in listing 13.2), which provides methods to skip entities, tuples, or cells during the iteration.
Listing 13.2. Interface of SirenIdIterator

For operators performing a conjunction of multiple terms such as PhraseQuery, we use the following merge-join algorithm:
- We retrieve the postings list of each term.
- We walk through the postings lists simultaneously.
- At each step, we compare the entity, tuple, and cell identifiers.
- If a mismatch occurs, we discard the current entry.
- If they are the same, the scorer performs the usual strategy of checking if each query term has valid positions (for example, adjacent positions). In case of a match, the scorer returns eid, tid, cid as results (which will be used by higher query components such as CellQuery) and advances the pointers to the next position in each postings list.
13.4.2. Restricting search within a cell
The CellQuery allows us to combine the primitive query components such as TermQuery or PhraseQuery with Boolean operations. The interface is similar to Lucene BooleanQuery but offers the ability to add multiple clauses using the addClause (PrimitiveSirenQuery c, Occur o) method.
The CellScorer scores a Boolean combination of primitive queries matching within a cell. The ConjunctionScorer, DisjunctionScorer, and ReqExclScorer implement the scoring mechanism of a conjunction, disjunction, or exclusion of terms inside a cell. They walk through the iterators of the scorers and perform joins using eid, tid, and cid, keeping only matches that occur inside a same cell. A CellScorer provides an iterator over the entities, tuples, and cells (eid, tid, cid) matching the query so that higher query components such as TupleQuery can filter matches per tuple.
A CellQuery provides an interface called CellQuery.setConstraint (int index), and, to add a cell index constraint cid=index. For example, imagine the cell index of a predicate is always 0. All matches that don’t have a cid equal to 0 are discarded. The index constraint isn’t hard, and can be represented as an interval using CellQuery.setConstraint (int start, int end) in order to search multiple cells where cid falls between start and end.
13.4.3. Combining cells into tuples
A CellQuery allows us to express a search over the content of a cell. Multiple cell query components can be combined to form a “tuple query” using the TupleQuery component. A tuple query retrieves tuples matching a Boolean combination of the cell queries. The TupleQuery provides a similar interface to BooleanQuery with the ability to add multiple clauses using the addClause(CellQuery c, Occur o) method.
The TupleScorer scores a Boolean combination of cells, and provides an iterator over the entities and tuples (eid, tid) matching the query. It’s based on the CellConjunctionScorer, CellDisjunctionScorer, and CellReqExclScorer to score a conjunction, disjunction, or exclusion of cells inside a tuple. Each walks through the iterators of the underlying scorers (CellScorer) and perform joins over entities and tuples.
13.4.4. Querying an entity description
TupleQuery, CellQuery, and TermQuery can be combined using Lucene’s BooleanQuery, allowing you to express rich queries for matching entities. The scoring is done by Lucene’s BooleanScorer because each of the SIREn scorers complies with the Lucene Scorer class. Listing 13.3 shows how to build a query using the previously described operators. The query example will retrieve all entities related to DERI and that have a property labeled name or fullname with a value of Renaud Delbru.
Listing 13.3. Creation of an entity description query

13.5. Integrating SIREn in Solr
Solr is an enterprise search server based on Lucene, developed within the same Apache Lucene top-level project as Lucene. It provides many useful features, such as faceted search, caching, replication, and distribution over shards. In this section we’ll show you how easy it is to plug a new Lucene component into the Solr framework, and how Sindice is able to benefit from all features provided by Solr.
To connect SIREn to the Solr framework, we had to assign the TupleAnalyzer to the tuple field type in the Solr schema file, as shown in listing 13.4. We also created a parser for the SPARQL, the recommended RDF query language by the W3C.[6]
The first component of the query parser is the SPARQLQueryAnalyzer that processes the input SPARQL query into a stream of tokens. The second component is the SPARQLParser, which extends the Solr.QParser that invokes the SPARQLQueryAnalyzer, parses the stream of tokens, and builds the corresponding SIREn query.
To make the SPARQLParser available to the Solr front end, we created a SPARQLParserPlugin class that extends Solr.QParserPlugin and a modification of the Solr config file to register the plug-in; see listing 13.4.
Listing 13.4. Integration of SIREn through Solr schema.xml
<fieldType name="tuple" class="solr.TextField">
<analyzer type="index"
class="org.sindice.solr.plugins.analysis.TupleAnalyzer"
words="stopwords.txt"/>
<analyzer type="query"
class="org.sindice.solr.plugins.analysis.SPARQLQueryAnalyzer"
words="stopwords.txt"/>
</fieldType>
...
<fields>
<field name="content" type="tuple" indexed="true" stored="false"/>
... Other field definition ...
</fields>
13.6. Benchmark
We performed the following benchmark using synthetic datasets of RDF entities on a commodity server.[7] We varied the number of distinct predicates (fields) of these data sets between 8 and 128. To generate the values in one field (a field is generally multivalued), we used a dictionary of 90,000 terms. We averaged the query time reported in this benchmark over 500 query executions. Each query contains two keywords randomly selected from the dictionary.
7 8 GB of RAM, two-quad core Intel processors running at 2.23 GHz, 7200 RPM SATA disks, Linux 2.6.24-19, Java Version 1.6.0.06
Table 13.3 shows that SIREn keeps a concise dictionary (the term dictionary is represented by two files per segment, the main file (*.tis) and the index file (*.tii)) whereas Lucene dictionary size increases linearly with the number of fields. With 128 fields, the size of the SIREn dictionary is 1.6 MB, whereas the size of the Lucene dictionary is 113 MB. In this case, SIREn is much more memory-efficient and lets us keep a larger part of the dictionary in memory. The file containing the posting lists (that is, the *.frq file that contains the lists of documents for each term, along with the frequency of the term in each document) is smaller using SIREn. Lucene has a different posting list for each term in each field; therefore, Lucene is creating more posting lists than SIREn, and this causes storage overhead. But the file that contains the positional information (*.prx), which contains the lists of positions that each term occurs at within documents along with the payload associated with the current term position, becomes five times bigger than the Lucene one. This is due to the overhead of storing the structural information (tuple and cell identifier) in the payload, but the impact of this is limited because this file isn’t usually kept in memory. The overall SIREn index size is below twice the size of Lucene index. Appendix B describes Lucene’s index file format.
Table 13.3. Comparison of size (in kb) of the main index files (synthetic data set with 128 fields)
|
Approach |
TermInfoIndex (.tii) |
TermInfoFile (.tis) |
FreqFile (.frq) |
ProxFile(.prx) |
Total |
|---|---|---|---|---|---|
| Lucene | 1627 | 113956 | 1179180 | 509815 | 1804578 |
| SIREn | 38 | 3520 | 769798 | 2697581 | 3470937 |
| SIREn/Lucene | 2% | 3% | 65% | 529% | 192% |
In tables 13.4 and 13.5, we can see that either for conjunction and disjunction Lucene performance decreases with the number of fields. To answer queries across a number of fields, Lucene expands the query by concatenating each field name to each keyword. For example, for a query with two keywords over 64 fields, the Lucene MultiFieldQueryParser (covered in section 5.4) will expand the query to 2 x 64 = 128 query terms. In SIREn, there’s no query expansion. The worst case will be 2 (keyword terms) + 64 (field terms) = 66 query terms—and only 2 if search is performed across all fields (that is, when a field wildcard is used because no field terms have to be intersected with the keyword terms).
Table 13.4. Query time (in ms) for conjunction of two keywords across all fields (wildcard for field names)
|
Approach |
8 fields |
16 fields |
32 fields |
64 fields |
128 fields |
|---|---|---|---|---|---|
| Lucene | 100 | 356 | 659 | 1191 | 2548 |
| SIREn | 72 | 79 | 75 | 76 | 91 |
Table 13.5. Query time (in ms) for disjunction of two keywords across all fields (wildcard for field names)
|
Approach |
8 fields |
16 fields |
32 fields |
64 fields |
128 fields |
|---|---|---|---|---|---|
| Lucene | 85 | 144 | 287 | 599 | 1357 |
| SIREn | 45 | 59 | 62 | 74 | 109 |
Similar performance for the field wildcard case could’ve been achieved with Lucene by using a catchall field, where all the values are concatenated together. In this case, doing so would duplicate information another time in the index (and in the dictionary), induce false positives, and be of no use when only a subset of fields has to be searched.
Table 13.6 reports the execution time of keywords search over one, two, or three randomly selected required terms in a BooleanQuery on the synthetic data set of 64 fields. SIREn performs slightly worse than Lucene when search is restricted to one field. The reason is that SIREn intersects three posting lists (the posting list of the field and the posting lists of each keyword) whereas Lucene intersects only two (the posting list of each keyword). But when keyword search is performed over two or three fields, SIREn takes the advantage. The performance is similar in all the other cases, using disjunction or exclusion instead of conjunction. After profiling Lucene during query execution, we observed that 25 percent of the time is spent reading the dictionary (more precisely in the method SegmentTermEnum.next()).
Table 13.6. Query time (in ms) for keyword search in one, two, or three randomly selected fields
|
Approach |
Q-1F |
Q-2F |
Q-3F |
|---|---|---|---|
| Lucene | 50 | 56 | 82 |
| SIREn | 77 | 53 | 58 |
13.7. Summary
In this chapter, you learned about SIREn, a Lucene “extension” for efficient querying of large amounts of schema-free semistructured data. We say “extension” because SIREn is more like a whole purpose-built application running on top of Lucene with a set of custom Lucene components—Analyzers, Tokenizers, TokenFilters, and so on. SIREn enables Lucene and Solr to handle information directly coming from the “Web of Data,” but can also be useful in enterprise data integration projects. The principal advantages that SIREn brings are as follows:
- It enables efficient search across a large number of fields.
- It is memory efficient with respect to the lexicon size.
- It enables flexible field names indexing (tokenized, wildcards, fuzzy matching on field names).
- It handles multivalued fields in an accurate way.
But when you expect to have data with a relatively small and fixed schema or when field values are distinct across fields, direct Lucene is a better choice; it will produce a smaller index and the query processing will be generally faster. In fact, SIREn isn’t meant to replace Lucene features but to complement them. You can use Lucene fields for fixed and frequent properties in the data collection and use SIREn for the other properties or for to perform fast multifield queries.
SIREn is in use in the Sindice search engine, which currently indexes more than 50 million structured documents (for a total of 1 billion triples) and can serve thousands of queries per minutes on a commodity server machine.