
10
Predictive Analysis of Online Television Videos Using Machine Learning Algorithms
Rebecca Jeyavadhanam B.1, Ramalingam V.V.2*, Sugumaran V.3 and Rajkumar D.4
1Department of Computer Applications, Faculty of Science and Humanities, SRMIST, Kattankulathur, India
2Department of Computer Science and Engineering, College of Engineering and Technology, SRMIST, Kattankulathur, India
3SMBS, VIT Chennai Campus, Chennai, India
4Department of BCA, Faculty of Science and Humanities, SRMIST, Ramapuram, India
Abstract
In recent years, intelligent machine systems promote different disciplines and facilitate reasonable solutions in various domains. Machine learning offers higher-level services for organizations to build customized solutions. Machine learning algorithms are widely integrated with image, video analytics, and evolving technologies such as augmented and virtual reality. The advanced machine learning approach plays an essential key role in handling the huge volume of time-dependent data and modeling automatic detection systems. The data grows exponentially with varying sizes, formats, and complexity. Machine learning algorithms are developed to extract meaningful information from huge and complex datasets. Machine learning algorithms or models improve their efficiency by the training process. This chapter commences with machine learning fundamentals and focuses on the most prominent machine learning process of data collection, feature extraction, feature selection, and building model. The significance and functions of each method on the live streaming television video dataset are discussed. We addressed the dimensionality reduction and machine learning incremental learning process (online). Finally, we summarized the performance assessment of decision tree, J48 graft, LMT tree, REP tree, best first (BF), and random forest algorithms based on their classification performance to build a predictive model for automatic identification of advertisement videos.
Keywords: Machine intelligent, machine learning, prediction, dimensionality reduction, feature extraction, feature selection, decision tree
10.1 Introduction
There is a need to develop customized and cognitive solutions in various fields in a service-driven generation. Cognitive solutions where the system could listen, respond, and recognize things and learning from the interactions. Machine learning is a subdivision of artificial intelligence (AI) in which we need efficient algorithms to process and analyze the huge volume of data. It aims to extract meaningful information such as features or patterns from a huge volume of data. There is a critical step to derive meaningful information as the feature which helps as the intelligent learning agent. Feature extraction is where would give the attention to extracting the useful data. Feature selections are the optimal subset of input variables to the learning algorithms. In other words, dimensionality reduction is necessary to choose the best performing features from the larger dataset. Significantly, it improves the performance of the learning algorithms. Choosing suitable algorithms and techniques on the training data gives a better prediction model. Training is the iterative process to reach the correct prediction goal and evaluate its performance using F1 score, precision, and recall. Evaluation of a model is a measure of success rate. If the evaluation process gets successful, then the next step is to proceed with the parameter tuning, where we can regularize the mode, scaling up, and tuning parameters. Prediction is the final process to consider the model to be ready for real-time applications. A well-built and executed machine learning model can improve the decision-making process for the respective domains. As an outcome, human resource is unbound from the encumbrance of processing the information and decisions. Brezeal et al. discussed a detailed survey for automatic video classification techniques and low level features. The statistical approach has been explained and helps the reader to enhance their works [1]. Qi et al. illustrated the SVM classifier and its classification performance on news stories [2]. Many research works have concentrated on television videos. CBIR (content-based image retrieval) framework for categorical-based searching has been proposed using machine learning methods for image pre-filtering, similarity matching with statistical distance measures and relevance feedback schemes. This approach has performed better than the traditional and it captures the variation of attributes in semantic categories. This system can be used as a front-end search application for medical images [3]. A combined fuzzy learning approach for a relevant feedback-based CBIR system for image search is proposed using both short term technique [fuzzy support vector machine (FSVM)] and long-term learning technique (novel semantic clustering technique). The results have shown the best retrieval accuracy compared to all its equivalent alternate methods and it occupies less space, increased scalability to larger databases [4]. A generic framework for analyzing large scale diverse sports videos with three different video analyses incoherent and sequential order is proposed [5]. Encouraging results of about 82.16% in genre categorization using KNN classifier, 82.86% using supervised SVM and 68.13% using unsupervised PLSA for average classification accuracy, and 92.31 by unsupervised PLSA and 93.08% by supervised SVM for structure prediction are achieved. Performance evaluation of various classifiers is reported and the decision tree algorithm (C4.5) finds good attributes to categorize video genre [6]. A study on pilot behaviors and their mood-based TV programmer classification has illustrated broadly. The video clips were labeled as happy, serious, and exciting for mood classification. Since it is a pilot study, a small dataset was used. Mel-Frequency Cepstral Coefficients (MFCCs) were used on audio, and phase correlation was used on video for feature classification and it produced an average of 75% to 100% accuracy on 3-minute clips when using two mood axes and 70% to 76% accuracy when all three mood axes were used [7]. A new algorithm for incremental feature learning in restricted Boltzmann machines is proposed to reduce the model complexity in computer vision problems as hidden layer incremented. There are two tasks defined as determining the incrimination necessity of neurons and the second, to compute the added attributes for increment. The results have shown that this approach has incremental RBM archives comparable reconstruction and classification errors than its non-comparable RBMs [8]. A video classification method is proposed to classify videos into different categories. This method aims at generic classification, namely, specific video classifier and generic video classifier, and it exploits motor information and cross-correlation measure for classification. Experiments were conducted on four popular video genres: cartoon, sports, commercial, and news, which yielded a good classification accuracy of 94.5% [9]. High-resolution video frame is a great challenge to process and discriminate their attributes. A learning-based technique has been used to enhance the super resolution of video frames exploit Artificial Neural Network (ANN). The method has been developed based on the edge properties and the spatial and temporal information has properly been utilized [10]. The simulation results show improvement in average PSNR and perceptual quality of the super-resolved frame. A finger joint detection method to measure modified total sharp (MTS) using SVM is proposed for the early detection of Rheumatoid Arthritis (RA), which increased by 30,000 patients annually. The experiments performed on 45 RA patients showed its early detection with an accuracy of 81.4% [11]. Content-based automatic video genre classification system exploits low-level audio and visual features and combines them with cognitive structural information. In web videos, the meta-information is also used for classification and this method is runs on YouTube videos. An accuracy of 99.2% on RAI dataset and 94.5% on Quareo 2010 evaluation dataset under TV programs and 89.7% on YouTube videos is measured [12]. A dataset DEAP (Database for Emotion Analysis using Physiological Signals) has developed a 3D emotional model. EEG signals were used to extract the features for their experimental study [13]. The authors discussed a systematic, comprehensive review and the advantage of neural networks. Image and video compression is done in three ways: excellent adaptability and leveraging samples from the far distance and texture and feature representation [14]. New objectives are used to evaluate the performance of the techniques [15]. Low level visual features were used to analyze the satellite images due to the different colors and textural variations. A multimodal feature learning mechanism based on deep networks for video classification is proposed through two-stage learning frameworks using intra-modal and inter-modal semantics. Compared to other deep and shallow models, experimental results show improvements in our approach in video classification accuracy [16]. A rule-based video classification method is suitable for online and offline study which helps in various video genre. Rule-based method is the better approach to classify the basket clips with increased accuracy [17]. The labeling problem is a significant one to consider in the classification approach. A semi-supervised learning technique has been used in vehicle classification and fused with an unsupervised graph which combines multiple feature representations under different distance measures [18]. The affinity between instances becomes more reliable, facilitating the vehicle type label propagation from labeled instances to their unlabeled ones when tested on BIT vehicle dataset. Classification of various video summarization techniques used to compress video files is carried out. A comparison chart of various techniques adopted in video summarization is discussed, and the usage of techniques adopted along with its dataset applied strengths, and weaknesses is presented [19]. Suggestions on how can use network techniques like CNN and RNN for video summarization is also suggested. A new method temporalspace-smooth warping (TSSW) is proposed to solve low temporal coherence in synthesized videos during its editing process [20]. This method produces a result with advantages like robustness to temporal coherence and preserves the temporal coherence and spatial smoothness, and effortless video editing options make this method a practically preferred method for video editing. A novel graph-based SSL framework structure sensitive anisotropic manifold ranking (SSAniMR) is proposed by studying the connections between graph-based SSL and PDE-based diffusion [21]. Experiments conducted on the TRECVID dataset have demonstrated that this framework outperforms the existing graph-based methods and is effective for semantic video annotation. In this work, the effective features of the furniture style. A three-way classification strategy is used to compare handcrafted classification and learning-based classification. Machine learning techniques like SVM and CNN are used for training and learning. According to the experimental results, the combinations of both handcrafted classification and learning-based classification can achieve state-of-the-art performance in labeling and detecting furniture’s style [22, 23].
This chapter is intended to provide the fundamental concepts of machine learning techniques for readers who are primarily familiar with image processing and machine learning. We described elaborately the feature extraction, feature selection, and classification techniques. Also, the performance evaluation of various classifiers is presented in the following sections.
10.1.1 Overview of Video Analytics
In image and video processing technology, video analytics has become used to process digital video signals to achieve many security goals and provide robust solutions in various domains. Video analytics technology has scaled with advances in machine learning, AI, multi-lingual speech recognition, and rules-based decision engines. Prescriptive analytics is mostly required in real time. YouTube and television videos contain rich content information. In contemporary applications, image or video plays a critical role in low and high resolution and bandwidth communication. High resolutions are required at the user end display system. In surveillance video, television videos, medical images, and satellite images have significantly gained the focuses on high resolutions. Resolutions greatly influence in the viewing experience and better quality. Video resolution mainly depends on the number of pixels in a frame. Pixels combine RGB values as the smallest unit, making a picture in a video frame. Possibly, the more pixels of the images present, the better clarity of the image. Therefore, to process the live streaming television videos, spatial information of the current frame and the next frame’s temporal information must be considered. In television, the broadcast videos are in different genres such as news, music, sports, cartoon, movie, and commercials are supposed to build the model. Generally, the video contains scenes, shots, and frames, respectively. Figure 10.1 shows the hierarchical representation of the videos.
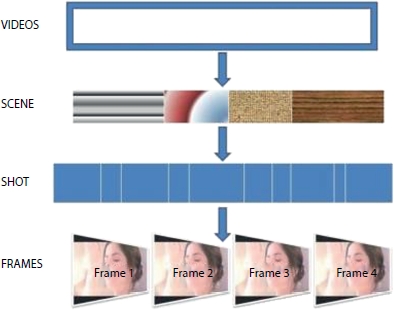
Figure 10.1 Hierarchical video representation.
10.1.2 Machine Learning Algorithms
To examine the consistency of various machine learning algorithms, we used the five other television video genre. Predictive accuracy criteria estimate the efficiency of the classifiers. Various machine learning algorithms such as C4.5, J48 graft, logistic model tree (LMT), random tree, best fit (BF) tree, reduced error pruning (REP) tree, and random forest (RF) are evaluated similarly on same attributes consistently. Each algorithm is illustrated below.
10.1.2.1 Decision Tree C4.5
Presentation of decision tree J48 has been assessed and contrasted and different calculations. Grouping calculations consistently discover standard rules to speak to the information and arranged to groups. DT is a famous and straight forward structure that utilizes a “partition and overcome” strategy to separate a non-predictable dynamic cycle into an assortment of basic choices. The decision tree system is straightforward and, in this manner, giving an interpretable arrangement. Given an information base D = {t1, t2, …, tn} where ti = {ti1, ti2, …, tih} and the information base composition contains the qualities {A1, A2, A3, …, Ah}. It is additionally given a bunch of classes C = {1, …, m}.
A decision tree computational model related to D that has the accompanying properties:
- • Each interior hub is named with a quality, simulated intelligence.
- • Each bend is named with a predicate that can be applied to the parent’s quality.
- • Each leaf hub is marked with a class, Cj.
Given a bunch of classes C = {1, …, m}with an equivalent likelihood of the event, the entropy is-p1log2p1–p2log2p2…-pmlog2pm where pi is the likelihood of even to fI. A property with the most minimal entropy is chosen as part of the standards for the tree. It is utilized to advance the forecast and grouping exactness of the calculation by limiting over-fitting problem.
10.1.2.2 J48 Graft
J48 graft is an efficient technique suggested to escalation the prospect to classify the objects exactly. J48 graft algorithm creates a single tree which aids in reducing the prediction error. J48 grafting algorithm is inherently generated from J48 tree algorithm. The main advantage of J48 graft is used to increase the probability of correctly predicted attributes. The grafting system is an inductive method and inserts nodules to trees to decrease prediction errors. The J48 grafting algorithm gives a good prediction accuracy on selected attributes of the training process.
10.1.2.3 Logistic Model Tree
A LMT comprises of a typical choice with strategic relapse capacities at the leaves. The LMT covers a tree like structure consisting of many internal or non-terminal bunch of nodes and end hubs. The LMT calculation formulates a tree with double and multi-class marked factors, like “numeric” and “missing abilities”. LMT is a mix of acceptance trees and calculated relapse. LMT utilizes cost-unpredictability trimming. Execution capability is slower in nature when compared with other techniques.
10.1.2.4 Best First Tree
In BF decision tree calculation, the tree grows by choosing the hub, which boosts the contamination decrease all the current hubs to part. In this calculation, the contamination could be estimated by the Gini index as well as information gain. BF trees are developed in a separation vanquish technique like the standard profundity first DT. The important guidelines for building the BF tree is as follows:
- • Select a characteristic to put at the root hub and make a few branches for this trait dependent on certain measures.
- • Split preparing occasions into sub group, one branch inherited from root hub.
- • The building measure proceeds until all hubs are unadulterated or a particular value of extensions is arrived.
10.1.2.5 Reduced Error Pruning Tree
REP tree is the easiest and reasonable strategy in choice tree pruning. It is a quick choice tree student, which constructs a choice or a relapse tree utilizing data pick up as the parting basis and prunes it and using decreased blunder pruning. Utilizing REP calculation, the tree crossing has performed from base to top and afterward checks for each interior hub and supplants it with most of the time class with the most worry about the tree exactness, which should not diminish. This method will proceed until any further pruning reduces the proficiency.
10.1.2.6 Random Forest
RF tree is an effective calculation for building a tree with K irregular highlights at every hub. The irregular tree is a tree drawn indiscriminately from a bunch of potential trees. Irregular trees can be created effectively, and the blend of huge arrangements of arbitrary trees prompts precise models. Irregular tree models have been widely evolved in AI to fabricate a reasonable and solid video order model.
10.2 Proposed Framework
Detection of the unique video is a popular yet challenging task in learning and intelligence, including various internet, YouTube, and television videos. Commercial monitoring systems brought a ground-breaking revolution in the internet, television, and smart-phones. Commercial videos are a good idea which spreads and communicates quickly to the targeted customers. However, the television video system faces two challenges nowadays: on the one hand, the growing number of television viewers and, on the other hand, increasing the advertisement channels. Hence, there is a great demand on smart remote sensing enabled device to facilitate happy timing for the homemakers and working peoples. It also provides a beneficial strategy for business sectors to promote their products in the competitive world. Hence, it is essential to identify a particular video genre for all kinds of multimedia applications. However, few observations have been noticed to carry out in the proposed work. Identifying a common feature among various videos, differentiating a particular video genre from others and identifying the commercial videos from the non-commercial videos are significant challenges. This chapter gives a concise and insightful analysis of commercial videos using a machine learning approach. Finding the unique features from the commercial frames can be utilized to classify accurately using spatial and temporal techniques. Temporal consistency gives valuable clues to derive most prominent features from the video-frames. Spatial information of the video frames provides the visual contents, giving a better prediction using machine learning techniques. In this chapter, there are two orthogonal views of features extraction techniques using spatial-temporal information: selection of best performing features and the classification results analysis are described elaborately to understand the importance of machine learning techniques in a better way. This chapter aims to help the researchers learn more and understand the machine learning and AI concepts aids of video classification developed model as depicted in Figure 10.2. We elaborately discussed the feature extraction techniques, feature selection process, and the machine learning classification methodology.
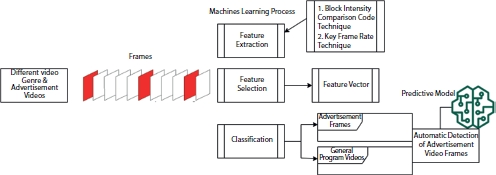
Figure 10.2 Overall architecture of the proposed framework.
10.2.1 Data Collection
The quality of data defines the accuracy of the model. Pre-processing is an essential step to removing the duplicates, handling the missing values, normalization, and data type conversion.
However, the collection dataset of the real-time video is an excellent challenging task to extract useful information. Data are extracted from five different video genres like news, music, sports, movie, and commercial videos in this framework. The dataset is categorized into two levels: advertisement videos and it is labeled as ADD class and other videos are labeled as NADD class. All commercial videos are taken in the ADD category and news, music, sports, and movie videos come under NADD category. We have extracted 20,000 individual frames for extracting the spatial and temporal features for ADD and NADD categories, respectively. The proposed algorithm extracted the frames at a rate of 25 FPS. Among 20,000 frames, 8,000 were taken for the test data. In a large scale dataset, robustness and efficiency are the most important concern in machine learning models.
10.2.2 Feature Extraction
In a typical feature extraction process, the low-level features are extracted from the spatial information and high-level features are generated from the temporal information. Here, we used the Block Intensity Comparison Code (BICC) to mine the spatial relevance objects. Key Frame Rate (KFR) technique has been used to generate high-level visual features to obtain the ADD and NADD frames’ likeness and variance. The experiment was conducted to identify the best promising block size such as 2 × 2, 3 × 3, 4 × 4, 5 × 5, 6 × 6, 7 × 7, 8 × 8, 9 × 9, and 10 × 10 [23]. Block size 8 × 8 has selected as the promising block size, and then, the BICC feature extraction technique has applied to generate the feature vector to carry out the experimental procedures. Next, the KFR feature extraction technique was used to extract the high-level feature to differentiate the ADD and NADD frames.
To increase the classification efficiency, accuracy, and effectiveness, we applied machine learning techniques and incorporated the feature extraction techniques such as BICC and KFR to produce a better predictive model to identify the commercial videos from another video genre. A brief description of the two advanced feature extraction techniques is discussed below to grab the machine learning process’ insightfulness of feature extraction techniques.
10.2.2.1 Block Intensity Comparison Code
Application of block pattern yields the proof of changes between the present frame and the adjacent frame. In each block of the frame, the average is calculated and compared with all other blocks. BICC feature vector has generated using the different phases are as follows.
Phase 1: Apply various blocking patterns on the frames.
Phase 2: Choosing the prominent block size.
Phase 3: Computing the average intensity value for each block.
Phase 4: Comparison of average values.
Phase 5: Constructing a feature vector.
Algorithm Implementation:
Step 1: Divide the Image (M) into K × K blocks, whereas K = 2 to 10; M/K × N/K.
Step 2: Block Size: 8 × 8 and Image Size: 320 × 240. Find Average Intensity of each block.
Step 3: Construction of Feature Dataset: Y = [((i – 1) * M) + 1: ((i * M), (j – 1)*N) + 1):(j * N)],
Step 4: Iterate step 2 and step 3.
Step 5: Assume the Feature Set = V = {f1, f2, …, fn}.
Blocking pattern of BICC technique is shown in Figure 10.3. BICC feature extraction technique is significant proof for the images’ static and dynamic properties and improvises the learning and intelligent process.

Figure 10.3 Blocking pattern.
10.2.2.2 Key Frame Rate
To calculate the frame rate of the online streaming television videos, it is essential to choose the key frame for various applications like video searching, retrieval, efficient browsing, content-based retrieval, and query-based search and classification. KFR feature extraction technique reduces the flaws in high-level semantic features and low-level features. From the literature study, most of the research works focused only on two methods to choose the key frames from the sequence of video images, such as uniform key frame collection and random key frame selection. However, rapid changes are occurring more in all commercial videos than in other videos. Therefore, the variations that might be occurred two selected key frames at a specific interlude is supposed to be dissimilar in the advertisement video frames (ADD Frame) than the other frames (NADD frames). In the proposed work, we have considered the key frames in the three different equal intervals of frames like 8, 12, and 16, as shown in Figure 10.4. The motion acceleration of the frames can calculate frame rate. Furthermore, KFR feature gives a progressive incline nearly in all multimedia applications. Different phases are carried out to generate the feature vector using the KFR feature extraction technique.
Phase 1: Shot segmentation: Input video shots are processed and segmented.
Phase 2: Key frames are collected in the equal interval of frames.
Phase 3: Divided the key frames into sixteen macro blocks to calculate frame rate.
Phase 4: Construct the feature vector.

Figure 10.4 Key frame extraction.
Algorithm Implementation:
Step 1: Let us consider the Video frames X = {F1, F2, F3, …, Fn} Step 2: Key Frames Set X1 = {KF i:j; where j = 8, 12 and 16}
Step 3: Select key frames and compute average K= {k1, k2, k3, …, kn}
Step 4: Assume T is a threshold value.
- Apply the condition:
- If T ≥ average intensity;
- ADD frames
- Else
- NADD frames.
Motion information can be considered through the sequential manner of the frame arrangements in the video. Hence, we utilized this KFR feature for insightful component extraction dependent on machine learning strategy.
10.3 Feature Selection
A machine learning technique plays a critical role in building a model with the dataset for automation anywhere. In a well-defined dataset, all the variables are participating in a useful way. The redundant variables’ presence always reduces the efficiency of the model and it might reduce the accuracy of the classifier. Moreover, involving more variables increases the complexity and decreases the capacity of the model. Therefore, feature selection identifies the best performing input variables in building the predictive model. Microscopic analysis of every variable in the dataset is not feasible for larger datasets. It is important to diminish the number of variables that cause a great impact on the computational cost of a model and increase the model’s performance. However, dimensionality reduction is a sensible method when dealing with a huge volume of high dimensional data. Dimensionality techniques would handle the space and time complexity effectively. In this work, we employed C4.5 algorithm for the feature selection process. Using BICC feature with 8 × 8 block size, 64 features were extracted and pruned after, 19 features are selected as best features (h1, h5, h8, h10, h15, h20, h27, h31, h39, h42, h47, h50, h52, h54, h55, h56, h57, h58, and h61) out of 64 features. The rest of the features were ignored sensibly.
In KFR technique, the experiments were carried out with the ratio of 1:4, 1:8, and 1:12 from each shot. Further, the frames weredividedinto16 macro blocks, which reduces of the temporal redundancy. However, the well-performing feature were identified as feature1 (f1), feature2 (f2), feature3 (f3) up to feature16 (f16) and 12 features selected as best attributes. We compared the two key frames concerning the ratio of 1:12 and, if the average is greater than the threshold value, the frame rate is high and it means that the frame belongs to ADD and it is lesser than the threshold value, it is NADD frames.
10.4 Classification
In this section, the classification performance of various machine learning algorithms and experimental breakthroughs are discussed elaborately in section 2.4. Owing to the prediction of ADD and NADD frames, the given datasets are split into 80% of training dataset and 20% for testing dataset. The algorithms’ classification accuracy is compared with their predictive accuracy, robustness, and scalability and interpretability criteria. Finally, decision treeJ48, J48 graft, LMT, RF, and REP tree classifiers are applied along with AI to predict whether the input frame is ADD frames or NADD frames. Table 10.1 shows the classifiers classification accuracy using BICC and KFR features, and it gives evidence to prove that RF with their “k” values achieved 99.50% of classification accuracy.
The most important factors are training and testing, which affect the success rate of machine learning. The quality of the built model depends on an efficient training process. Figure 10.5 shows the proposed developed model and the dataset divided into two parts for the training and testing process. The training and testing sets are considered in the ratio 0f 60% to 40% for the proposed model development. However, iteration of the training process could increase the success rate of the classifiers performance and the process flow is shown in Figure 10.5.
Table 10.1 Classifiers vs. classification accuracy.
| Classifiers | Variable parameters |
Classification accuracy (%) | |
| BICC Feature | KFR | ||
| Decision Tree J48 | Minimum Number of Objects | 83.69 | 60.94 |
| J48 Graft | Minimum Number of Objects | 83.69 | 62.08 |
| LMT | Minimum Number of Instances | 91.34 | 71.01 |
| Best First (BF Tree) | Minimum Number of Objects | 83.51 | 62.28 |
| REP Tree | Minimum Total Weight of Instances | 80.64 | 59.11 |
| Random Forest | K values | 99.50 | 71.9 |
10.5 Online Incremental Learning
Incremental and online machine learning attracts more attention with respect to learning real-time data streams, in disparity with conventional assumptions of the available data set. Though various approaches exist, it is unclear to choose the suitable one for specific work. Instant or online-based incremental learning is that the model could learn each attribute as it receives. Traditional machine learning techniques access the data concurrently fail to meet the actual requirements to handle the huge volume of complete data set within the stipulated time. It leads more unprocessed accumulated data. Moreover, the existing approaches do not integrate and update new incremental information into the existing built models instead it reconstructs new-fangled models from the mark. It is a time-consuming process as well as potentially outmoded. Hence, there is a need for a paradigm change to sequential data processing for the video streaming system to overcome this state of concerns.

Figure 10.5 Training and testing process.
Challenges of Incremental Learning Algorithms:
- 1. Incremental learning algorithms are limited in run time and model complexity.
- 2. Long term leaning with a device and restricted resources.
- 3. Adaptation of model without retraining process.
- 4. Conservation of earlier assimilated knowledge and without any impact of catastrophic failure.
- 5. Limited number of training attributes is allowed to be upheld.
Here, few algorithms are recommended for the online incremental learning process in the perspective of concept gist as given below:
- • Incremental Support Vector Machine (ISVM)
- • LASVM is an online approximate SVM
- • Online Random Forest (ORF)
- • Incremental Learning Vector Quantization (ILVQ)
- • Learn++ (LPPCART)
- • Incremental Extreme Learning Machine (IELM)
- • Naive Bayes (NBGauss)
- • Stochastic Gradient Descent (SGDLin)
The evaluation process of these algorithm allows the interpretation of various aspects concerning to the algorithmic performance and provide deeper insight.
10.6 Results and Discussion
In this experimental analysis, we investigated the arrangements of spatial and temporal information of advertisement videos and Non-advertisement videos for recognizable ADD frames and NADD frames aided with AI concepts. Optimization and tuning of the parameters were executed and run on the Waikato environment–Weka tool and all other windows operating systems applications. The classifiers’ performance is estimated, and the video frames are analyzed in terms of F1 score, precision, and recall sores. Results and outputs of the video frames are analyzed and shown in Table 10.2.
Referring to Table 10.3, the predicted number of frames is shown in the confusion matrix. The confusion matrix is used to explore the performance of the classifiers based on the prediction like True Positive (TP), False Positive (FP), True Negative (TN), and False Positive (FN). From the confusion matrix given, one can understand that there commended RF classifier correctly predicted 9,515 ADD frames and the rest of 485 frames are misclassified as NADD frames. However, these frames belong to ADD frames. Similarly, RF correctly classified 8,902 NADD frames and 1,098 frames are misclassified as ADD frames. The predicted resultant video frames of ADD and NADD frames are shown in Figures 10.6 and 10.7.
Table 10.2 Performance metrics of the recommended classifier.
| TP rate | FP rate | Precision | Recall | F- Measures | ROC area | Class |
| 0.951 | 0.10 | 0.896 | 0.951 | 0.922 | 0.95 | ADD |
| 0.88 | 0.048 | 0.983 | 0.88 | 0.917 | 0.95 | NADD |
| 0.920 | 0.078 | 0.921 | 0.920 | 0.920 | 0.95 | Weight Avg. |
Table 10.3 Confusion matrix.
| Class | ADD | NADD |
| ADD | 9,514 | 486 |
| NADD | 1,097 | 8,903 |

Figure 10.6 Predicted output frames from advertisement videos.

Figure 10.7 Predicted output frames from non-advertisement videos.
10.7 Conclusion
The importance is given for plausible experiment methodology to analyze online television streaming videos to classify commercial videos using a machine learning approach. Machine learning is imperative to classify the video genre and identify the advertisement videos from other videos like news, music, sports, and movie videos for the proposed work. The finding of this work is mainly utilized for quick access and various multimedia applications. Experiment results are based on the fusion of machine learning and AI. The recommended model for classification of the advertisement video frames is proficient with an accuracy of 99.50%. Recall score with the precision score is verified with advertisement frames. Hopefully, the present findings and verified methodology help the researchers better understand machine learning techniques for versatile approaches. Hence, the machine learning model is the best tool and achieves better decisions with minimum effort. The study will extend the investigation on various methods to get the optimal classification performance. Probable future directions in online incremental algorithms are appropriate for learning new information instantly enabling devices to adapt the environments.
References
1. Brezeale, D. and Cook, D.J., Automatic video classification: A survey of the literature. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev., 38, 3, 416–430, 2008.
2. Qi, W., Gu, L., Jiang, H., Chen, X.R., Zhang, H.J., Integrating visual, audio and text analysis for news video. IEEE Int. Conf. Image Process., 3, 520–523, 2000.
3. Rahman, M.M., Bhattacharya, P., Desai, B.C., A framework for medical image retrieval using machine learning and statistical similarity matching techniques with relevance feedback. IEEE Trans. Inf. Technol. Biomed. Publ. IEEE Eng. Med. Biol. Soc., 11, 1, 58–69, Jan. 2007.
4. Barrett, S., Chang, R., Qi, X., A fuzzy combined learning approach to content-based image retrieval, in: 2009 IEEE International Conference on Multimedia and Expo, pp. 838–841, 2009.
5. Zhang, N. et al., A generic approach for systematic analysis of sports videos. ACM Trans. Intell. Syst. Technol., 3, 3, 1–33, 2012.
6. Jeyavadhanam, R., Mohan, S., Ramalingam, V.V., Sugumaran, V., Performance Comparison of Various Decision Tree Algorithms for Classification of Advertisement and Non Advertisement Videos. Indian J. Sci. Technol.,9, 1–10, Dec. 2016.
7. Eggink, J., Allen, P., Bland, D., A pilot study for mood-based classification of TV programmes. Proc. ACM Symp. Appl. Comput, pp. 918–922, 2012.
8. Yu, J., Gwak, J., Lee, S., Jeon, M., An incremental learning approach for restricted boltzmann machines. ICCAIS 2015 - 4th Int. Conf. Control. Autom. Inf. Sci., pp. 113–117, 2015.
9. Kandasamy, K. and Subash, C., Automatic Video Genre Classification. Int. J. Eng. Res. Tech. (IJERT), 2, 5, 94–100, 2014.
10. Cheng, M.H., Hwang, K.S., Jeng, J.H., Lin, N.W., Classification-based video super-resolution using artificial neural networks. Signal Process., 93, 9, 2612– 2625, 2013.
11. Morita, K., Tashita, A., Nii, M., Kobashi, S., Computer-aided diagnosis system for Rheumatoid Arthritis using machine learning, in: 2017 International Conference on Machine Learning and Cybernetics (ICMLC), vol. 2, pp. 357– 360, 2017.
12. Liu, Y., Feng, X., Zhou, Z., Multimodal video classification with stacked contractive autoencoders. Signal Process., 120, 761–766, 2016.
13. Dabas, H., Sethi, C., Dua, C., Dalawat, M., Sethia, D., Emotion classification using EEG signals. ACM Int. Conf. Proceeding Ser., pp. 380–384, 2018.
14. Ma, S., Zhang, X., Jia, C., Zhao, Z., Wang, S., Wang, S., Image and Video Compression with Neural Networks: A Review. IEEE Trans. Circuits Syst. Video Technol., 30, 6, 1683–1698, 2020.
15. Asokan, A. and Anitha, J., Machine Learning based Image Processing Techniques for Satellite Image Analysis -A Survey. Proc. Int. Conf. Mach. Learn. Big Data, Cloud Parallel Comput. Trends, Prespectives Prospect. Com. 2019, pp. 119–124, 2019.
16. Zhou, W., Vellaikal, A., Kuo, C.C.J., Rule-based video classification system for basketball video indexing. Proc. 2000 ACM Workshops Multimed., 213– 216, 2000.
17. Sun, M., Hao, S., Liu, G., Semi-supervised vehicle classification via fusing affinity matrices. Signal Process., 149, 118–123, 2018.
18. Basavarajaiah, M. and Sharma, P., Survey of compressed domain video summarization techniques. ACM Comput. Surv.,52, 6, 1–29, 2019.
19. Li, X., Liu, T., Deng, J., Tao, D., Video face editing using temporal-spatial-smooth warping. ACM Trans. Intell. Syst. Technol., 7, 3, 1–29, 2016.
20. Tang, J., Qi, G.J., Wang, M., Hua, X.S., Video semantic analysis based on structure-sensitive anisotropic manifold ranking. Signal Process., 89, 12, 2313–2323, 2009.
21. Hu, Z. et al., Visual classification of furniture styles. ACM Trans. Intell. Syst. Technol., 8, 5, 1–20, 2017.
22. Ramalingam, V.V. and Mohan, S., Prosthetic Arm Control with Statistical Features of EEG signals using K-star Algorithm. J. Appl. Sci., 16, 4, 138–145, 2016.
23. Vadhanam, B.R.J., Mohan, S., Sugumaran, V., Ramalingam, V.V., Exploiting BICC Features for Classification of Advertisement Videos Using RIDOR Algorithm, in: 2016 International Conference on Micro-Electronics and Telecommunication Engineering (ICMETE), pp. 247–252, 2016.
- *Corresponding author: [email protected]