
17
Assistive Technologies for Visual, Hearing, and Speech Impairments: Machine Learning and Deep Learning Solutions
Shahira K. C.*, Sruthi C. J. and Lijiya A.
Department of Computer Science and Engineering, National Institute of Technology Calicut, Kozhikode, India
Abstract
Recent advancements in technology have helped researchers in computer vision (CV) to provide useful and reliable services to improve the quality of life in various aspects. These include some of the significant applications like factory automation, self-driving cars, surveillance, healthcare, assistive technology (AT), human-computer interaction, remote sensing, and agriculture. Tremendous improvement in processing power led the way toward the successful machine learning and deep learning techniques, which, in turn, made otherwise impossible CV applications to come true. AT takes a special place due to its social commitment. AT is any service, software, or product that assists a person with a disability or elderly to improve the quality of their life. Diverse AT techniques available these days makes it out of scope for a single chapter, and hence, this chapter summarizes AT fabricated for people with vision, hearing, and verbal impairment.
Keywords: Assistive technology, visual impairment, hearing and speech impairment, machine learning, deep learning
17.1 Introduction
Among all the disabilities, blindness or visual impairment is the most limiting one. Age-related muscular degeneration or diabetics is one of the primary causes of vision loss. Hence, the necessity for assisting the increasing number of visually impaired people is indispensable. Haptic and aural modalities have a significant role in perception by the visually impaired and congenitally blind people. In earlier days, they depended mostly on braille. Later, screen readers like VoiceOver and JAWS help along to access the digital media. These adaptive technologies are attributed to the breakthrough in computer vision (CV) and deep learning (DL). With the promising results in image and video processing by these DL models, research in AT is beneficiary, which is not limited to: wearable technology (wearables), object detection, navigation, scene description, visual question answering, education, and also improving daily and social life. The recent trends in AT focus on making the printed media accessible and social life more manageable. We categorize the various approaches in AT for the VIP as the traditional based and the CV based and discuss the essential techniques used in each of these approaches. Effective use of the algorithms mimicking human visual system in AT and with proper training on these assistive devices, we can make their life better and easier.
Different from vision impairment, people with verbal and hearing impairment face difficulty in communication, owning to this, they feel isolated and dependent always. Assistive devices for speech and hearing is broadly categorized into assistive listening devices (ALDs), augmentative and alternative communication (AAC) devices, and alerting devices. Advancements in CV, DL, and machine learning (ML) approach had benefited improvements in AAC and alerting device developments in a significant way. People with verbal impairment communicate through sign language, which is a blend of hand gestures, facial countenance, and body stance. Recognizing this mode of communication is hard for the verbal community. An automated two-way translator that translates the verbal language to sign language and sign language to verbal language can help to reduce this communication barrier to a certain extent. Many research in this direction has tried to solve these issues. The whole chapter describes various ML, and DL-based CV techniques that are attributed to the assistive technologies (ATs) for vision, hearing, and verbal impairment.
17.2 Visual Impairment
Among all the disabilities, the most excruciating one is blindness or visual impairment. In 2020, two billion people around the globe suffer from severe or moderate vision impairments, according to WHO. Diabetics, age-related muscular degeneration, cataract, and glaucoma are the main reasons causing vision impairment in adults, while its congenital in children. Through touch and voice input and output devices, blind people learn about the world. There are haptic devices and voice recognition systems, which make use of these senses. With proper training on the new assistive devices, they can live independently like any other sighted person. There are many supporting devices developed to help the blind or low vision people. A survey on the current list of supporting devices and softwares is given in [46]. For the blind, we can explore the AT by categorizing it into conventional approaches and CV-based approaches with a more focus on DL.
17.2.1 Conventional Assistive Technology for the VIP
Many research works are available in the assistive aids for the VIP. ATs1 can be “high tech” and “low tech” from canes and lever door knobs to voice recognition software and augmentative communication devices (speech generating devices). The AT which were in use without making use of the CV-based approaches are categorized as conventional approaches. In conventional approaches, these ATs supporting the VIP can be classified as wayfinding and reading. These conventional methods are enhanced in the future with DL to solve the challenges in navigation and reading.
17.2.1.1 Way Finding
In way finding, the movement of the blind people, both indoor and outdoor are discussed. The primary aim of navigational aids is to detect obstacles in the path. These obstacles can be a gutter in the road, pit holes, a hanging branch or any suspended obstacles. Indoor, it can be any wall or furniture or stairs. The daily movement of the visually impaired people, both indoor and outdoor, should ensure their safety. Any navigation aid should be able to detect the following:
- • Obstacles in the field of vision as similar to the human eye.
- • Find the obstacles not only in the ground upto certain height, but also find any objects along his/her height.
- • To find the distance from the blind user to the obstacle and this result should be imparted to the user in fraction of time to avoid collisions.
- • Perception and avoidance of obstacles in the immediate proximity at a faster rate than at a longer distance.
- • Precise depth estimation to these objects.
In earlier days, the blind navigation was supported by canes and dogs or a volunteer. The traditional canes give the result on physical contact with the obstacles, but the obstacles above the feet are missed out. The challenges faced by these give rise to white canes supported by sensors, to get informed about the obstacles at a distance and at the height of the user. A widely used AT by the visually impaired people is white canes because of the ease of use and low cost. Later, improvements were added to these traditional walking sticks by adding sensors to it. The type of sensors includes ultrasonic sensors, infrared, RGBD, or LiDAR. A comparison between a few sensors used in an Electronic Travel Aid (ETA) is given in Table 17.1 [16]. An ETA is a device that gathers information from the environment and transmits it to the visually impaired user to allow independent movement. It takes in input from a sensor and an imaging device. It combines the result from these environmental inputs, and it imparts the output information as vibration or voice output. Few challenges faced by these travel aids are the following:
- • Most of the ETA’s are prototypes.
- • Heavy and bulky.
- • Unidentified or missed the hanging obstacles.
- • The sensors need to be fixed without changing direction and height to ensure good obstacle avoidance accuracy [9]. But this is not possible in case of the devices, where the user change direction randomly.
- • Some of the prototypes were tested on blind folded candidates. Testing should be on blind users as the cognitive ability of these two categories varies.
- • To perceive the surrounding as a blind user wishes, obstacle avoidance alone is not sufficient. He might be interested in the various objects or signboards or text in a scene.
Table 17.1 Comparison of sensors for obstacle detection in ETA inspired from [16].
| Ultrasound | LiDAR | RADAR | Vision sensors | |
| Range | Short | Short Medium | Medium-Long | Short Medium |
| Accuracy | Good | Good | Good | High |
| Number of obstacles detected | Low | High | Medium | Medium |
| Effect of sunlight | No effect | Strong | No effect | Strong |
| Effect of rain | Yes | Yes | Yes | Yes |
| Night Operation | Yes | Yes | Yes | No |
| Cost | Low | High | Medium | Medium |
Figure 17.1 illustrates an object detection and avoidance architecture that can be integrated into several wearable devices. The information from the sensors are incorporated into white canes and “n” number of variants of the white canes are available in the market today. Ultra canes based on ultrasound, laser canes based on a laser beam, and sonar based on ultrasound are few of them. However, many of them do not meet the precise specification needed by an ETA for a VIP [20]. The navigation can be made better and reliable by incorporating sensors along with the DL models as discussed in Section 17.2.2. The DL included new versions of the walking assistants with object detection modules evolved as smart canes.
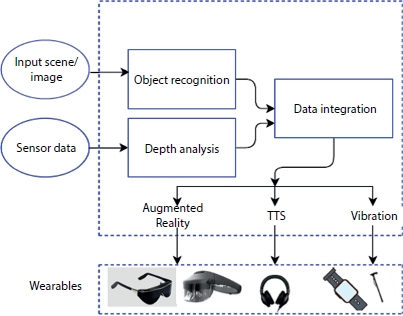
Figure 17.1 An architecture of simple obstacle detection and avoidance framework that can be integrated with different wearables.
17.2.1.2 Reading Assistance
The AT here includes those software and hardware which help the VIP to read, write, or understand the contents in a printed media or the digital media. The braille made a way to access the knowledge by the people who cannot see. These are raised dots which are read by touch. Braille is a tactile system for the blind found in 1820. Slate and stylus is a method of writing braille by hand, so the blind get the feeling of how each letter looks like. The blind people perceive the document information through audio or by touch or a volunteer reading out or by recorded voices. Adaptive technology like screen readers, Siri, and other voice-recognition software emerge with time. A screen reader is a software that uses a text-to-speech (TTS) engine to translate the textual contents of the computer screen to either speech output or a refreshable braille display. The speech synthesis technology was not initially aimed at blind users, but further advancements in this area contributed to screen reader technology. Using this, they can read documents, send an email, and use social media sites. However, unfortunately, they cannot identify the graphical contents of the page. Later, these image contents are provided as descriptions in the form of alternate text (alt-text), which can be read out by a screen reader. People prefer braille display in cases they are left with confusions in the speech so that they can feel and understand the text. All these advancements are attributed to a breakthrough in CV and DL. The recent trends in AT focus on making the printed media accessible and social life more comfortable. The refreshable braille displays also utilize the tactile perception. This has a raised set of pins that get adjusted as the user adjusts the cursor on the screen. The American Foundation for Blind gives a set of refreshable braille. In cases when a blind user is confused with the output from a screen reader, this is used. Screen reading software like JAWS and Voiceover are used to read the digital contents. The information about the figures on a web page is communicated by using the image descriptions which are produced in the real time using DL models as discussed in Sections 17.2.2.2 and 17.2.2.3. These image descriptions are represented as alt-text for the screen reader to readout.
This section focuses primarily on the categorization of AT as wayfinding related and AT related to reading. The traditional methods like cane evolved into smart canes and reading AT evolved into screen readers and mobile apps from braille. It is possible to extend the promising findings of the DL models to different ATs. The following section addresses applying various DL models to specific ATs to help the blind people.
17.2.2 The Significance of Computer Vision and Deep Learning in AT of VIP
Computer or robotic vision focuses on how camera and sensor vision can be accomplished. If a camera can be made to see and recognize objects, then the same can be applied for enhancing the visual ability of a visually challenged. Haptic and aural modalities have a major role in perception by the Visually impaired and congenitally blind people. In earlier days, they depended mostly on braille; later, screen readers help to access the digital media and improve their social life. Navigation requires scene understanding and estimation of obstacle distance in the real time. Object detection gives the best accuracy using DL methods like YOLO [38], SSD [17], and FasterRCNN [39]. The CV methods that are well accepted in the AT research for improving the reading assitance, mobility and travel includes object recognition and obstacle avoidance, scene understanding, document image understanding, visual question answering, and more. All these CV methods in AT are reciprocally related to each other.
17.2.2.1 Navigational Aids
The traveling is easy for a VIP today with the advancements in technology. The wayfinding in Section 17.2.1.1 discusses the asssitive techonologies in navigational aids and the ETA in use. Most of the ETA in support of them are costly and some apps working real time require network connectivity. ETAs have sensor inputs which can be any one or a combination of the sensors discussed in Section 17.2.1.1. Choose the sensor based on various attributes like cost, range, or other factors. Use the sensors to calculate the depth to the obstacles. There are sensors providing depth information, but are expensive. The RGB-D cameras are less costly compered to them, and they provide the per pixel depth information along with the color information. Microsoft Kinect2 widely attained popularity because of its cost and the depth resolution and its invariant to illumination changes. Kinect have a RGB camera along with an infrared sensor to find the depth. The computational cost of the RGB-D images is high. The future of navigation research for AT is trying to incorporate the proximity sensors in the mobile phone. Integrate with the transfer learning of a DL model for object detection in a smartphone. The information about the objects in the scene can be readout. The text in natural scenes can also be given as audio output. This can be handy, unlike the earlier prototypes and also affordable.
When a visually impaired person is traveling, he should be informed with the obstacles in the near vicinity at a faster rate to prevent the collision. The object detection deals with finding any obstacles in the path and the obstacle avoidance deals with giving an alert or feedback to the user.
One of the most challenging problems in CV is obstacle detection, and it has gained popularity because of its wide application in scene analysis, activity recognition, content-based image retrieval and pedestrian detection, lane tracking, and more. Object detection determines where objects are present in a given image, i.e., object localization together with which category each object belongs to (object classification). The object detection models consist of region selection, feature extraction and classification. The conventional methods used handcrafted features for classification. The traditional methods required separate modules for feature extraction, while the DL models have the advantage of end to end learning. The traditional methods failed to give better detection results when the image is affected by occlusion, shadows, or illumination changes. Identifying different categories of objects in the same image was difficult. Promising results toward this came with DL which could even classify multiple overlapping objects in different backgrounds. Convolutional Neural Networks (CNN) is a breakthrough in this, which works like human vision [18]. ImageNet Large-Scale Visual Recognition Challenge (ILSVRC)3 conducted annually to find the top-performing models. Few of the CNNs are LeNet-5 [28], AlexNet [24], ResNet [50], and Inception [49]. There are different models which use Deep CNNs like R-CNN, Fast R-CNN, Faster R-CNN, and Yolo. These models can follow the following approaches:
- • Region proposal–based approach
- • Single-shot–based approach.
Region proposal–based methods: Region proposal–based methods are concerned with generating and extracting bounding boxes around the object of interest. It is followed by a feature extractor which is usually a CNN that can extract the features from each proposed regions. A classifier at the end classifies these features into known classes. RCNN, Fast R-CNN, and Faster R-CNN are examples which uses this approach.
In case of RCNN, region proposal is based on selective search, the feature extraction is based on AlexNet, and the final classification is using a linear SVM. In Fast RCNN [17], input is a set of region proposals from which feature is extracted by a pretrained VGG16 model. A region of interest (ROI) pooling layer extracts features specific to a candidate region. Output of this CNN is given to a softmax for class prediction and also to a linear SVM for producing output for the bounding box. But this was slow process as a set of candidate region proposal needed to be proposed with each input image. Faster RCNN [39] reached the pinnacle of models in detecting the objects, by adding a CNN for proposing region and the type of object to consider along with the already existing Fast RCNN.
Single-shot–based methods: It is a single neural network which is trained end to end and predicts bounding boxes and class labels for each bounding box directly. This could process 45–155 frames per second, varying based on their versions. Yolo [38], YoloV2 [60], Fast Yolo [37], and SSD [31] are examples which uses this approach.
These DL models using CNN can be applied to problems in AT in different ways. Either we can build own model which includes training a neural network with custom dataset or do fine-tuning of the network in which we can change the hyperparameters of the model till we get a minimum error, or do transfer learning.
Transfer learning is an approach in which a model developed for one task is reused as the starting point for a model on a second task. The models trained on a different dataset and the weights are saved for future use. These weights can be used for object detection or scene description. For instance, Yolov2 [60] is developed for chinese traffic sign detection. Here, the weight vector obtained after training Yolov2 is used to classify the objects in a different dataset. Choose the models which give better accuracy in real time. An architecture of simple obstacle detection and avoidance framework that can be integrated with different wearables inspired from [41]. This gives an instance where, the result can be given as augmented reality or zoomed version of the input image or video, in case of low vision users. The voice output can be given through any wearables like headset or handsfree or smartphone. The vibration alerts can be given through watch or cane. Thus, by integrating the input from the depth sensors and camera, the object recognition improves the navigation. The smartphones are widely used for navigation and is discussed in Section 17.2.2.4.
17.2.2.2 Scene Understanding
The goal of scene understanding is to make the machines able to see like humans. Scene understanding is perceiving and analysing an environment in real time. This involves object detection and recognition integrated with the help of sensors. A scene can be a man made scene or natural scene. A scene may have different objects in various environments and different contexts. Understanding the context of the scene, identifying the objects in it and providing accurate visual information is its purpose. Visual attention contributes to scene understanding. Attention networks [56] allow to focus on some areas of the network and the visual attention is very important in locating some objects of the scene. Road scene segmentation is crucial for driving assistance. In 2020, authors in [12] introduced a fast and accurate segmentation using DL models for high and low resolution images. Apart from all these, DL has paved the way for mobile applications which can detect the objects in real time. “Tap tap see” is one among them which identifies the objects present in the input picture. The user has to click a picture; the processing happens in the cloud and gives him the voice output. Color ID Free is another app which is used to find the objects of matching color.
The scene understanding systems can analyze the images to understand the variations in the environment and identify the objects in it and interpret in human understandable form [27]. It is influenced by cognitive vision. It have applications in autonomous driving and robotic vision. The same algorithms can be customized for assisting the vision of blind people.
17.2.2.3 Reading Assistance
Visually impaired students learn to read and write with braille, with the help of a trained teacher. They can access web content or a computer with refreshable braille connected to the computer. Screen reading software allows them to read the contents on the web by converting it into speech by a TTS or through refreshable braille. They perceive the images through tactile graphics of maps, graphs and pictures. Text extraction by applications using OCR makes both the digital documents and print media easily accessible. Text localization and extraction from images helps them in different walks of life, including few listed below.
- • Locate the text in natural scenes in scene understanding.
- • They can access the audiobooks.
- • Smartphone-based cabs that can scan the document and read out the text.
- • Identify the traffic signboard, text in a catalogue, assist shopping, or read a restaurant menu card.
Smartphones provide quick and easy access to information. There are many android and iOS applications for reading assistance. SeeingAI4 is an app by Microsoft which helps them to read the bar code of products, identify currency and also describe a scene in front of him/her. The wearable finger reader [45] (in Table 17.2) helps to read the document with the help of a minicamera in it. When compared to mobile applications, this finger-based approach helps a blind user to to understand the spatial layout of a document better and provide control over speed and rereading.
Table 17.2 A comparison between few wearables.
| Wearables | Sensors | Assistance | Features | Demerits | Wear On |
| MyEyes2.06, 2020 | 12 MP camera | Robotic vision | Text, bank notes, face detection | Costly | Finger like camera mounted to glasses |
| Sunu7 [6], 2020 | Sonar | Obstacle avoidance | Haptic guide light weight | Costly | Wrist band |
| Maptic [54], 2018 | Vision sensor in chest | Obstacles in the field of vision | App process and give feedback to phone | Use GPS, Network connection required | Neck or wrist |
| Horus8, 2016 | Camera | Virtual assistant | Read text, face recognition, object detection | Still in prototype stage | Headset |
| FingerReader [48], 2015 | Opticon, mini camera | Reading assistance | Printed text to voice | Camera do not auto focus, hard to adjust for different finger lengths | Finger |
17.2.2.4 Wearables
The wearables for the blind can be used in different parts of the body. The mode of perception by the VIP is aural or haptics. An overview of wearable devices used by the blind people is given in [57]. They can be placed at the fingertips, wrist, tongue, ears, hands, chest, and abdomen. Figure 17.2 gives an example of a wearable glasses with sensors to understand the scene. The input information is processed using a bulky device in the backpack and the output provided as refreshable braille is felt with the fingertips. Today, the output can provided as image descriptions with the help of a TTS converters via ear pluggins. The wearable can play a very important role in education also. This is an era of intelligent assistants and intersection of them with the AT is proving
Several prototypes and wearables use sensors and give vibrational feedback or audio output. But most of them are bulky in nature and heavy. Some are in the form of head eyeglasses, heavy head sets, chest mounted devices, etc. Dakopoulos et al. [14] give a detailed description of these prototypes with their pros and cons. These device prototypes pass the testing, but usability by a person is very low. The cognitive ability of the user should be considered at the design stage. The user should be involved right from the design to its implementation. The work [61, 62] enlists the underlying parameters that need to be considered when developing tools or devices for any activity especially for the mobility of the visually impaired. The wearables uses a camera or sensors to acquire the real world information. The processing can be done in cloud or the device and provides output as vibration or audio.

Figure 17.2 A prototype of a wearable system with image to tactile rendering from [57].
The bulky prototypes and the depth sensors that are costly increases the demand for a handy, less expensive device. Also, the increasing number of visually impaired people every year amplifies the need for a cost-effective device. The heart of the future navigational aids for the VIP lies in a smartphone. The smartphone can be used to integrate the traditional methods with CV to produce better solutions. The smartphone can act as an input and output device. The necessary steps are acquisition, processing, and output.
Acquisition: The inbuilt camera for sensing the environment. The input can be an image or a video.
Processing: The input can be processed locally in the device or on a remote server with the higher computing power. The remote device takes care of the input test data from the device. It needs to be pre-processed. The processing devices have the DL or the object detection models trained with good accuracy. Now, the input image or video is tested for the presence of objects or text or any obstacles. Processing can be done locally on the acquisition device also. DL models trained with large training set save their weights. This pre-trained weights which are trained on some other data said can be used for other task; this is transfer learning. Transfer learning of these models saves time for the time fine-tuning. The lightweight DL networks require the computational power of a smartphone.
Output: The output after processing can be the descriptions of the object or the distance provided as audio by TTS synthesis.
These wearables like a smart watch, smart glasses, or smart rings are light weight. The intelligent voice assistants like Siri by Apple, Google Assistant, or Amazon Echo are making lives easier. These virtual assistants provide easy web access by not typing in keyboard. They enable easy interaction with the wearable devices. Table 17.2 includes few wearables that helps to identify the text, currency, and face recognition. They are designed to meet specific needs of the VIP. Olli5, designed by local motors with IBM Watson is an autonomous vehicle to meet the transportation of people with different needs. Audio cues and haptic sensors help the blind users to find seats. They can book a ride using Olli app. This uses augmented reality to use sign languages to support the deaf users. The following sections discuss the various AT supporting the deaf people.
17.3 Verbal and Hearing Impairment
Verbal and hearing problems are another form of impairment faced by humans for decades. Partial or full verbal or hearing loss creates difficulty in communication with the verbal society. Numerous techniques have evolved to reduce the communication barrier, but the fact is that nothing was entirely successful. People suffering from verbal, hearing and language disorder faces different levels of communication problems. Some people have complete hearing loss, whereas some have partial hearing loss. Similarly, some people can hear properly, but they may be vocally disabled to communicate with society. AT is an equipment or a collection of devices that help a person with a disability to overcome their difficulty and live more comfortably. In the case of verbal, hearing, and language disorder, AT is anything which helps a person to communicate with society. A variety of assistive devices are being used to overcome the communication barrier and are mainly categorized into: ALDs, alerting devices, and AAC devices.
17.3.1 Assistive Listening Devices
Hearing loss can be partial or complete. This happens when the human hearing instrument is not sufficient to fulfil the auditory requirements of the person. ALD is amplification equipment for improving the hearing ability. The sound that we perceive is affected by numerous unwanted sound sources called noise, and this creates a problem for hard of hearing person to correctly understand the speech. ALD aims to separate noise from speech and increase speech-to-noise ratio. Significant factors that decrease the intelligibility of a speech signal are [22]:
- • Distance: As the distance of the person from the sound source increases speech-to-noise ratio decreases, and the speech becomes less intelligible.
- • Noise: Affect of different background noises over the speech signal diminishes its intelligibility.
- • Reverberation: This is a phenomenon where a sound signal undergoes multiple reflections and persist for a long time even after its source have stopped emitting it. This diminishes the clarity of speech and thus decreases intelligibility.
ALD differs from simple hearing aids or cochlear implant, but it can be an additional module attached to these devices for better hearing in outdoor or in a specific environment. ALD ranges from a simple electronic microscope amplifier unit to more sophisticated broadcasting systems and hence are used in public places like church, theaters, and auditoriums, also for personal uses to listen to telephone and television, and for small group activities. Some of the ALDs available these days are induction loop system, FM systems, telecoils, infrared systems, personalized amplification equipment and many more [33]. Each of these mentioned ALDs are designed for specific environments and purposes but all work with the same objective to discard the adverse effects of distance, background noises, and reverberation and to provide a clear and uninterrupted speech signal to the listener. Working and contexts of each of these systems are complex and out of scope for this chapter.
17.3.2 Alerting Devices
Alerting devices, as the name suggests, alert the concerned person to audio stimuli. Hard of hearing person finds it difficult to hear or sometimes even miss out certain necessary audio signals like a doorbell, fire alarm, phone rings, alarms, barking, news alerts, and baby crying. In such cases, alternative attention seeking methods like vibrations, flashing lights or strobes, and loud horns may help. Visual or tactile means are the most effective techniques in case of hard of hearing people. Erin discusses the needs and effectiveness of strobes and tactile in different scenarios [7]. The effectiveness of strobes decreases if the person is sleeping or if he is away from it or based on the lighting in the background. Tactile, on the other hand, depends on what kind of vibrating instruments are being used. Some of the tactile instruments include bed shakers that are connected to alarms to notify the person in sleep, vibration alerts in phones, many vibrating wearable with displays showing the cause of vibration and even number of alerts are possible on smartphone applications. Some of the most commonly used alerting devices or systems are smoke alarm signalers, telephone signalers, doorbell signalers, wake up alarms, and baby signalers.
17.3.3 Augmentative and Alternative Communication Devices
Speech and audio communication can be replaced with other alternative modes of communication like speech to text, picture board, touchscreen, and many more. This becomes extremely helpful for people with complete hearing loss or for people who cannot talk. Some of the popularly used AAC are as follows [58]:
Telecommunications Device for the Deaf (TDD): The communication through telecommunication devices for a speech-impaired person is made possible by a TTS and speech to text conversion with the help of a third party. A person with the impairment communicate the message through text, the intermediate third party, or translator reads the message at the other end. The person at the other end conveys the message vocally which is converted to text by the third party and sent back to the user.
Real-Time Text (RTT): This mode of communication is very similar to TDD but is more transparent; it does not involve any third party in between. All the communications are entirely done through text messages. This differs from the conventional text messaging with a fact that it allows each user to see what the other is typing in real time like the face-to-face conversation in terms of reaction time.
Videophones: The videophone is a telecommunication device produced explicitly for people with hearing or verbal impairments. The device has a large screen in order to use it in hands-free mode while performing sign language. A videophone is necessary at both ends if both of the end-users are using sign language for communication. In the other case, an interpreter or translator translates the sign language to speech and speech to sign language during the conversation.
17.3.3.1 Sign Language Recognition
Hearing- and speech-impaired people use sign language for communication. Majority of the population cannot interpret sign language, and this hinders the social interactions of these people. They find it challenging to communicate with verbally speaking world, making it difficult for them to attain education, job, and many other basic requirements. In order to communicate with society, they need a translator. A manual translator can convert any complicated gesture sequence to speech with all the emotional modulations required for it, but it reduces the privacy of the speakers involved in the conversation. A non-manual or machine translator guarantees the privacy factor, but research is still going on to develop a complete sign language recognition system which can perform with the same accuracy as that of a human translator. The significant challenges involved in the sign language recognition system are follows:
- • Sign language is very diverse; it differs from geography to geography and even differs within a region.
- • Sign language involves single hand gestures, double hand gestures, facial expression, and body posture, which makes it complicated to incorporate on to a machine.
- • Sign language conversation contains static and dynamic gestures performed in a sequence and hence finding the starting and ending of each gesture in the sequence become complicated.
- • Interclass similarity and intraclass differences of gestures are common among sign language gestures.
- • Gesturing differ from person to person based on body nature, posture, contexts, etc., making it a more challenging problem.
- • Occlusion: While performing the gesture, one hand can occlude the other making it hard for the system to recognize.
Despite all these challenges, researchers are all over the world are working hard for developing an optimal sign language recognition system. Several solutions have been suggested till date but search for better one is still going on. There are many methods suggested by experts for this purpose in literature; these methods can be classified broadly into sensor-based methods and vision-based methods.
Sensor-Based Methods: These methods make use of sensors and sensor-enabled gloves to collect gesture related data. The sensors include accelerometers (ACCs), flexion (or bend) sensors, proximity sensors, and abduction sensors. The sensors are used to measure the abduction in between the fingers, finger bend angle, wrist and palm orientation, and hand movement. Values measured by the sensors provide accurate results with fewer computations. Hardware components of the sensor-based method are divided into input unit, processing unit, and output unit. The input unit deals with acquiring the data or the sensors readings and pass it to the processing unit. Some of the commonly used sensors and their uses include:
- • Flex sensor: Measures finger curvature based on the resistive carbon element correlated to the bend radius.
- • Light-dependent resistor (LDR): LDR changes its resistance according to the light falling on it. Amount of light received by LDR changes as the finger takes the possible bends giving different voltage values at different positions.
- • Tactile sensor: It is a force-sensitive sensor that calculates the amount of force on the finger, by which it shows whether the finger is curved or straight.
- • Hall effect magnetic sensor (HEMS): Sensors are placed on the fingertips, and a magnet is placed on the palm area with the south pole facing the top. When the magnet and sensors come closer, it generates electric output depending on the degree of closeness.
- • Accelerometers: These sensors have a dual purpose as it can determine finger shapes, and it can capture the movement and orientation of the wrist.
- • Gyroscope: This sensor measures the angular velocity and the speed with which an object spin along the axis.
- • Inertial measurement unit (IMU): This unit is a combination of magnetometer, accelerometer, and a gyroscope, which can collect information with a greater degree of freedom regarding the motion and orientation of the hands.
The processing unit performs the required gesture processing to recognize the sign and to transfer the result to the output port. It collects and processes the data from the input unit using a microcontroller. Microcontrollers are of many types and differ in performance based on architecture, memory, and read-write capabilities. Some of the commonly used microcontrollers in glove-based methods are ATmega microcontroller, MSP430G2553 microcontroller, Arduino Uno board, and Odroid XU4 minicomputer [4]. Output unit as the name suggests displays the classified gestures name on computer monitor, liquid-crystal display (LCD), smartphone, or through the speaker. It also serves as a user interface and hence is an essential factor for achieving the best performance among the sign language recognition devices. Apart from the hardware components in the sensor-based methods, softwares also play a vital role in improving the system outputs. Softwares mainly come into play for the classification to recognize gestures. One of the most typical methods is to use statistical template matching, which finds the closest match of acquired sensor reading values with pre-determined training samples. ML methods like artificial neural network (ANN), support vector machines (SVM), and hidden Markov models (HMMs) are also used in literature for better classification of the obtained sensor readings in the area of gesture recognition [4]. Figure 17.3 shows the image of a DG5-V hand glove developed for Arabic sign language recognition using flex sensors and accelerometers [40]. Researchers all over the world had contributed different sensor-based methods with different combinations of sensor technologies, but the fact is that none of them covers an extensive vocabulary and the cost of many of these devices is also high based on the microcontrollers and sensors used in them. The person using it also has the burden of carrying the device whereever they travel. Table 17.3 shows some of the sensor-based methods from literature.
Vision-Based Methods: Vision-based methods use visual sensors like a camera to capture the input data. Cameras nowadays are ubiquitous device and are even present in mobile phones. This reduces the dependency of the user over different sensor devices while performing the gestures. Mostly all sign language recognition systems consist of four main modules: (1) data acquisition, (2) pre-processing, (3) feature extraction, and (4) classification. Data acquisition deals with acquiring the videos or images required for running the system. This module specifies the camera specification, the required distance between the camera and the signer, background, or outfit requirement, if any. The pre-processing module deals with the removal of unnecessary distortions, finding and segmenting the region of interest and preparing the preprocessed data for feature extraction phase, so that feature extraction is done in an unbiased manner. Some of the popularly used noise removal techniques include low-pass box filter for smoothing, median filter for salt and pepper noise, and the bilateral filter, which is a non-linear, noise-reducing, edge-preserving, and smoothing filter. Face and the two palm regions are the region of interest for any sign language recognition system. Viola-Jones face detection method [59] is the widely used solution for detecting face in an image or frame. Pre-trained TensorFlow human detection model [51] is used to find the human in the frame. Skin color segmentation [8] is the widely used hand segmentation method in the literature. Feature extraction module plays a vital role in the entire SLR system as the accuracy of the recognition process depend completely over the extracted features. Feature vectors are those vectors which can efficiently represent an image or a frame. Palm position, orientation, shape, fingertips, edges, depth, and movements are some among the crucial features considered in SLR. These features are extracted using various methods like histogram of oriented gradients (HOG) [21], Zernike moments [8], histogram of edge frequency [29], scale invariant feature transform (SIFT) [35], Fourier descriptor [2], 3-D motionlets [23], and other techniques. The last or final stage of an SLR system is the classification or recognition. ML and DL methods come into the picture in this stage. The classification has two phases: training and testing. In the training phase, features extracted are used to train the model using ML or DL algorithms, and in the testing phase, new images or videos are classified using the trained model. SVMs [8, 25, 29, 34, 55], neural network [3], and HMM [52] are the most commonly used ML models and Convolution Neural Network (CNN) [10, 48], Long short-term memory (LSTM) [30], and Recurrent Neural Network (RNN) [10]. Despite research all over the world, a complete solution covering the vocabulary of a particular sign language with acceptable accuracy is not ready. Methods proposed by researchers till date are limited to a minimal vocabulary, and hence, the scope of research in this area is high. Table 17.4 shows some of the vision-based methods from literature.

Figure 17.3 DG5-V hand glove developed for Arabic sign language recognition [40].
Table 17.3 Sensor based methods from literature.
| Sensors | Sign language | Gestures | Ref. |
| Accelerometer and IMU sensors | American | Gestures for A- Z and 0-9 | [1] |
| 5-Flex sensors | American | 4 Common gestures | [36] |
| Flex and Accelerometer sensors | Indian | 8 Common gestures | [32] |
| Flex, Accelerometer, and Tactile sensors | American | Gestures for A-H | [42] |
| Contact and multiple flex sensors | Australian | 120 Common static gestures | [5] |
| Flex sensors and 3-D accelerometer | Arabic | 40 Sentences from 80 Words | [53] |
| Flex sensors and gyroscope | American | 3 Common gestures | [15] |
| Accelerometer, Bend and hall effect sensors with | - | Gestures for 0-9 | [13] |
| Flex and Accelerometer sensors | American | Gestures for A-Z | [11] |
Table 17.4 Vision based approaches.
| Techniques used | Language | Gestures recognized | Ref. |
| 3-Dimentional position trajectory with adaptive matching | Indian | 20 Common actions | [26] |
| 3-Dimensional motionlets with adaptive kernal matching | Indian | 500 Common gestures | [23] |
| DWT(Discrete wavelet transforn) with HMM | Indian | 10 Sentences | [52] |
| Skin-color segmentation, fingertip detection, zernike moment, and SVM | American | 4 Dynamic gestures and 24 static alphabets | [25] |
| Fingertip and palm position, PCA, optical flow, CRF | American | 9 Alphabets | [19] |
| SIFT (Scale Invariant Feature Transform) with key point extraction | Indian | 26 Alphabets | [35] |
| Skin color segmentation, Fourier descriptor, distance transform, neural network | Indian | 26 Alphabets and 0-9 Digits | [3] |
| Direct pixel value, hierarchical centroid, neural network | Indian | Digits 0-9 | [44] |
| SMO (Sequential Minimal Optimization) with Zernike moments, | Indian | 5 Alphabets | [43] |
| Zernike moment, SVM | American | 24 Alphabets | [34] |
| Histogram of edge frequency, SVM | Indian | 26 Alphabets | [29] |
| Eigen value weighted Euclidean distance | Indian | 24 Static alphabets | [47] |
| Skin color segmentation, Zernike moment, SVM | Indian | 24 Static Alphabets and 10 dynamic words | [8] |
| B-spline approximation and SVM | Indian | 29 signs (A-Z and 0-5) | [55] |
| LSTM | Chinese | 100 Isolated common words | [30] |
| Skin color segmentation and CNN | Indian | 24 Static Alphabets | [48] |
17.3.4 Significance of Machine Learning and Deep Learning in Assistive Communication Technology
ML and DL models can identify patterns from a large amount of data. The real-world problem is always very complex and multidimensional, and ML and DL models have always proved their excellence in solving these problems in various domains. Assistive communication technologies make use of self-learning and continuous improvement properties of these models, which ensures the best results compared with the traditional methods. Different from ML models, DL models even do not require feature engineering, as these models find the best features based on the provided training data. The significance of ML and DL models is evident from the extensive use of SVM, HMM, neural network, CNN, LSTM, and other models in almost all the vison-based methods. These models are even used in AAC devices, alerting devices, and sensor-based devices for automation.
17.4 Conclusion and Future Scope
The most commonly encountered sensory impairments are vision and hearing problem. We discuss the various ATs in support of these categories of people. For the visual impairment, we classify the available AT as conventional and the DL-based ones. The earlier AT available was only in navigation and reading assistance. The challenges faced by the traditional methods is resolved with the DL-based approaches. With the promising results in CV by DL models, object detection and navigation, scene description, and textual and graphical readers and wearables are beneficial. In the case of hearing and verbal impairment, we classify the available AT as ALDs, alerting devices, and AAC devices. We discuss some of the popularly used AT devices in these categories and also the significance of ML and DL models in assistive communication technology.
New developments in technologies had improved the quality of AT to a greater extend. Improvements in various sensors, cameras, and algorithms to process the data collected from these devices in lesser time can even improve the situations. Dealing with 3D data efficiently in real time can be an excellent solution for many ATs. The solutions presented throughout the chapter are still under research for further improvements hoping that even a small change can improve a person’s life to the extent that we can even imagine.
References
1. Abhishek, K.S., Qubeley, L.C.F., Ho, D., Glove-based hand gesture recognition sign language translator using capacitive touch sensor, in: 2016 IEEE International Conference on Electron Devices and Solid-State Circuits (EDSSC), IEEE, pp. 334–337, 2016.
2. Adithya, V., Vinod, P.R., Gopalakrishnan, U., Artificial neural network based method for Indian sign language recognition, in: Information & Communication Technologies (ICT), 2013 IEEE Conference on, IEEE, pp. 1080–1085, 2013.
3. Adithya, V., Vinod, P.R., Gopalakrishnan, U., Artificial neural network based method for Indian sign language recognition, in: 2013 IEEE Conference on Information & Communication Technologies, IEEE, pp. 1080–1085, 2013.
4. Ahmed, M.A. et al., A review on systems-based sensory gloves for sign language recognition state of the art between 2007 and 2017. Sensors, 18, 7, 2208, 2018.
5. Ahmed, S.F., Ali, S.M.B., Saqib Munawwar Qureshi, Sh, Electronic speaking glove for speechless patients, a tongue to a dumb, in: 2010 IEEE Conference on Sustainable Utilization and Development in Engineering and Technology, IEEE, pp. 56–60, 2010.
6. Alabi, A.O. and Mutula, S.M., Digital inclusion for visually impaired students through assistive technologies in academic libraries, in: Library Hi Tech News, University of Maryland, College Park, 2020.
7. Ashley, E.M., Waking effectiveness of emergency alerting devices for the hearing able, hard of hearing, and deaf populations. PhD thesis, 2007.
8. Athira, P.K., Sruthi, C.J., Lijiya, A., A signer independent sign language recognition with co-articulation elimination from live videos: an indian scenario. J. King Saud Univ.-Comput. Inf. Sci., 2019. https://www.semanticscholar.org/paper/A-Signer-Independent-Sign-Language-Recognition-with-Athira-Sruthi/f9071918498da2ce65984f3a32935e3d4683611e
9. Bai, J. et al., Smart guiding glasses for visually impaired people in indoor environment. IEEE Trans. Consum. Electron., 63, 3, 258–266, 2017.
10. Bantupalli, K. and Xie, Y., American sign language recognition using deep learning and computer vision, in: 2018 IEEE International Conference on Big Data (Big Data), IEEE, pp. 4896–4899, 2018.
11. Cabrera, M.E. et al., Glove-based gesture recognition system, in: Adaptive Mobile Robotics, 5 Toh Tuck Link, Singapore pp. 747–753, World Scientific, 2012.
12. Chen, P.-R. et al., DSNet: An efficient CNN for road scene segmentation. APSIPA Trans. Signal Inf. Process., 9, 424–432 2020.
13. Chouhan, T. et al., Smart glove with gesture recognition ability for the hearing and speech impaired, in: 2014 IEEE Global Humanitarian Technology Conference-South Asia Satellite (GHTC-SAS), IEEE, pp. 105–110, 2014.
14. Dakopoulos, D. and Bourbakis, N.G., Wearable obstacle avoidance electronic travel aids for blind: A survey. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.), 40, 25–35, IEEE. 2009.
15. Das, A. et al., Smart glove for sign language communications, in: 2016 International Conference on Accessibility to Digital World (ICADW), IEEE, pp. 27–31, 2016.
16. Di Mattia, V. et al., Electromagnetic technology for a new class of electronic travel aids supporting the autonomous mobility of visually impaired people, in: Visually Impaired: Assistive Technologies, Challenges and Coping Strategies, Nova Science Publisher, Inc., Basel, Switzerland, 2016.
17. Girshick, R., Fast r-cnn, in: Proceedings of the IEEE international conference on computer vision, pp. 1440–1448, 2015.
18. Heaton, J., Goodfellow, I., Bengio, Y., Courville, A., Deep learning. Genet Program Evolvable Machines, The MIT press, 305–307, 2013. https://doi.org/10.1007/s10710-017-9314-z.
19. Hussain, I., Talukdar, A.K., Sarma, K.K., Hand gesture recognition system with real-time palm tracking, in: 2014 Annual IEEE India Conference (INDICON), IEEE, pp. 1–6, 2014.
20. Jeong, G.-Y. and Yu, K.-H., Multi-section sensing and vibrotactile perception for walking guide of visually impaired person. Sensors, 16, 7, 1070, 2016.
21. Joshi, G., Singh, S., Vig, R., Taguchi-TOPSIS based HOG parameter selection for complex background sign language recognition. J. Visual Commun. Image Represent., 71, 102834, 2020.
22. Kim, J.S. and Kim, C.H., A review of assistive listening device and digital wireless technology for hearing instruments. Korean J. Audiol., 18, 3, 105, 2014.
23. Kishore, P.V.V. et al., Motionlets matching with adaptive kernels for 3-D Indian sign language recognition. IEEE Sens. J., 18, 8, 3327–3337, 2018.
24. Krizhevsky, A., Sutskever, I., Hinton, G.E., ImageNet Classification with Deep Convolutional Neural Networks, in: Advances in Neural Information Processing Systems 25, F. Pereira, et al., Lake Tahoe, Nevada, United States (Eds.), pp. 1097–1105, Curran Associates, Inc., 2012, http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf.
25. Kumar, A., Thankachan, K., Dominic, M.M., Sign language recognition, in: 2016 3rd International Conference on Recent Advances in Information Technology (RAIT), IEEE, pp. 422–428, 2016.
26. Anil Kumar, D. et al., Indian sign language recognition using graph matching on 3D motion captured signs. Multimed. Tools Appl., 77, 24, 32063–32091, 2018.
27. Li, L., Socher, R., Fei-Fei, L., Towards total scene understanding: Classification, annotation and segmentation in an automatic framework, in: 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 2036–2043, 2009, doi: 10.1109/CVPR.2009.5206718.
28. LeCun, Y. et al., LeNet-5, convolutional neural networks. In: URL: http://yann.lecun.com/exdb/lenet. 20, 5, 14, 2015. http://yann.lecun.com/exdb/lenet/ accessed on 2020/12/09
29. Lilha, H. and Shivmurthy, D., Evaluation of features for automated transcription of dual-handed sign language alphabets, in: 2011 International Conference on Image Information Processing, IEEE, pp. 1–5, 2011.
30. Liu, T., Zhou, W., Li, H., Sign language recognition with long short-term memory, in: 2016 IEEE international conference on image processing (ICIP), IEEE, pp. 2871–2875, 2016.
31. Liu, W. et al., Ssd: Single shot multibox detector, in: European conference on computer vision, Springer, pp. 21–37, 2016.
32. Lokhande, P., Prajapati, R., Pansare, S., Data gloves for sign language recognition system. Int. J. Comput. Appl., 975, 8887, 2015.
33. NIH(NIDCD), Assistive Devices for People with Hearing, Voice, Speech, or Language Disorders, https://www.nidcd.nih.gov/health/assistive-devices-people-hearing-voice-speech-or-language-disorders. Accessed: 2020-12-09.
34. Otiniano-Rodrıguez, K.C., Cámara-Chávez, G., Menotti, D., Hu and Zernike moments for sign language recognition, in: Proceedings of international conference on image processing, computer vision, and pattern recognition, pp. 1–5, 2012.
35. Patil, S.B. and Sinha, G.R., Distinctive feature extraction for Indian Sign Language (ISL) gesture using scale invariant feature Transform (SIFT). J. Inst. Eng. (India): Ser. B, 98, 1, 19–26, 2017.
36. Praveen, N., Karanth, N., Megha, M.S., Sign language interpreter using a smart glove, in: 2014 International Conference on Advances in Electronics Computers and Communications, IEEE, pp. 1–5, 2014.
37. Redmon, J. and Farhadi, A., YOLOv3: An Incremental Improvement. In: arXiv, 1804.02767,2018.
38. Redmon, J. et al., You Only Look Once: Unified, Real-Time Object Detection, in: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.
39. Ren, S. et al., Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell., 39, 6, 1137–1149, June 2017.
40. Sadek, M.I., Mikhael, M.N., Mansour, H.A., A new approach for designing a smart glove for Arabic Sign Language Recognition system based on the statistical analysis of the Sign Language, in: 2017 34th National Radio Science Conference (NRSC), IEEE, pp. 380–388, 2017.
41. Shahira, K.C., Tripathy, S., Lijiya, A., Obstacle Detection, Depth Estimation And Warning System For Visually Impaired People, in: TENCON 2019-2019 IEEE Region 10 Conference (TENCON), IEEE, pp. 863–868, 2019.
42. Sharma, D., Verma, D., Khetarpal, P., LabVIEW based Sign Language Trainer cum portable display unit for the speech impaired, in: 2015 Annual IEEE India Conference (INDICON), IEEE, pp. 1–6, 2015.
43. Sharma, K., Joshi, G., Dutta, M., Analysis of shape and orientation recognition capability of complex Zernike moments for signed gestures, in: 2015 2nd International Conference on Signal Processing and Integrated Networks (SPIN), IEEE, pp. 730–735, 2015.
44. Sharma, M., Pal, R., Sahoo, A.K., Indian Sign Language Recognition Using Neural Networks and KNN Classifiers. ARPN J. Eng. Appl. Sci., 9, 8, 1255– 1259, 2014.
45. Shilkrot, R. et al., FingerReader: a wearable device to explore printed text on the go, in: Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, pp. 2363–2372, 2015.
46. Singh, B. and Kapoor, M., A Survey of Current Aids for Visually Impaired Persons, in: 2018 3rd International Conference On Internet of Things: Smart Innovation and Usages (IoT-SIU), IEEE, pp. 1–5, 2018.
47. Singha, J. and Das, K., Indian sign language recognition using eigen value weighted euclidean distance based classification technique. In: arXiv preprint arXiv:1303.0634, 2013.
48. Sruthi, C.J. and Lijiya, A., Signet: A deep learning based indian sign language recognition system, in: 2019 International Conference on Communication and Signal Processing (ICCSP), IEEE, pp. 0596–0600, 2019.
49. Szegedy, C. et al., Rethinking the inception architecture for computer vision, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2818–2826, 2016.
50. Targ, S., Almeida, D., Lyman, K., Resnet in resnet: Generalizing residual architectures. In: arXiv preprint arXiv:1603.08029, 2016.
51. Tensorow Detection Model Zoo. https://medium.com/@madhawavidanapa-thirana/real-time-human-detection-in-computer-vision-part-2-c7eda27115c6. Accessed: 2020-12-09.
52. Tripathi, K., Baranwal, N., Nandi, G.C., Continuous dynamic Indian Sign Language gesture recognition with invariant backgrounds, in: 2015 International Conference on Advances in Computing, Communications and Informatics (ICACCI), IEEE, pp. 2211–2216, 2015.
53. Tubaiz, N., Shanableh, T., Assaleh, K., Glove-based continuous Arabic sign language recognition in user-dependent mode. IEEE Trans. Hum.-Mach. Syst., 45, 4, 526–533, 2015.
54. Tucker, E., Maptic is a wearable navigation system for the visually impaired, Dezeen, London, Retrieved October 10 (2017), 65–84, 2019, 2018.
55. Geetha, U.C. and Manjusha, M., A Vision Based Recognition of Indian Sign Language Alphabets and Numerals Using B-Spline Approximation. Int. J. Comput. Sci. Eng. (IJCSE), 4, 3, 406, 2012.
56. Vaswani, A. et al., Attention is all you need, in: Advances in neural information processing systems, vol. 30, pp. 5998–6008, 2017.
57. Velázquez, R., Wearable assistive devices for the blind, in: Wearable and autonomous biomedical devices and systems for smart environment, pp. 331– 349, Springer, Berlin, Heidelberg, 2010.
58. verizon, Assistive Technologies for the Deaf and Hard of Hearing, https://www.verizon.com/info/technology/assistive-listening-devices/. Accessed: 2020- 12-09.
59. Yun, L. and Peng, Z., An Automatic Hand Gesture Recognition System Based on Viola-Jones Method and SVMs, in: Second International Workshop on Computer Science and Engineering, pp. 72–77, 2009.
60. Zhang, J. et al., A real-time chinese traffic sign detection algorithm based on modified YOLOv2. Algorithms, 10, 4, 127, 2017.
61. Isaksson, J., Jansson, T., Nilsson, J., Desire of use: A hierarchical decomposition of activities and its application on mobility of by blind and low-vision individual. IEEE Trans. Neual Syst. Rehab. Eng.,25, 5, 1146–1156, 2020.
62. Law, Effie L.-C., Roto, V., Hassenzahl, M., Vermeeren, A.POS, Kort, J., Understanding, scoping and defining user experience: a survey approach, in: Proceedings of the SIGCHI conference on human factors in computing systems, pp. 719–728, Boston, MA, USA, 2009.
- *Corresponding author: [email protected]
- 1 https://guides.library.illinois.edu/c.php?g=613892ssssssssp=4265891
- 2 http://alumni.cs.ucr.edu/klitomis/files/RGBD-intro.pdf
- 3 http://www.image-net.org/challenges/LSVRC/
- 4 https://www.microsoft.com/en-us/ai/seeing-ai
- 5 https://www.ibm.com/blogs/internet-of-things/olli-ai/
- 6 https://www.orcam.com/en/myeye2/
- 7 https://shop.sunu.com/default.aspx?ref=landingssssssga=2.9462641.590209563.1608186286-1650292166.1608186286
- 8 https://assistivetechnologyblog.com/2016/03/horus-wearable-personal-assistant-for.html