
2
Zonotic Diseases Detection Using Ensemble Machine Learning Algorithms
Bhargavi K.
Department of Computer Science and Engineering, Siddaganga Institute of Technology, Tumakuru, India
Abstract
Zonotic diseases are a kind of infectious disease which spreads from animals to humans; the disease usually spreads from infectious agents like virus, prion and bacteria. The identification and controlling the spread of zonotic disease is challenging due to several issues which includes no proper symptoms, signs of zoonoses are very similar, improper vaccination of animals, and poor knowledge among people about animal health. Ensemble machine learning uses multiple machine learning algorithms, to arrive at better performance, compared to individual/stand-alone machine learning algorithms. Some of the potential ensemble learning algorithms like Bayes optimal classifier, bootstrap aggregating (bagging), boosting, Bayesian model averaging, Bayesian model combination, bucket of models, and stacking are helpful in identifying zonotic diseases. Hence, in this chapter, the application of potential ensemble machine learning algorithms in identifying zonotic diseases is discussed with their architecture, advantages, and applications. The efficiency achieved by the considered ensemble machine learning techniques is compared toward the performance metrics, i.e., throughput, execution time, response time, error rate, and learning rate. From the analysis, it is observed that the efficiency achieved by Bayesian model combination, stacking, and Bayesian model combination are high in identifying of the zonotic diseases.
Keywords: Zonotic disease, ensemble machine learning, Bayes optimal classifier, bagging, boosting, Bayesian model averaging, Bayesian model combination, stacking
2.1 Introduction
Zonotic diseases are a kind of infectious disease which spreads from animals to human beings; the disease usually spreads from infectious agents like virus, prion, virus, and bacteria. The human being who gets affected first will, in turn, spread that disease to other human beings likewise the chain of disease builds. The zonotic disease gets transferred in two different mode of transmission, one is direct transmission in which disease get transferred from animal to human being, and the other is intermediate transmission in which the disease get transferred via intermediate species that carry the disease pathogen. The emergence of zonotic diseases usually happens in large regional, global, political, economic, national, and social forces levels. There are eight most common zonotic diseases which spread from animal to humans on a wider geographical area which include zonotic influenza, salmonellosis, West Nile virus, plague, corona viruses, rabies, brucellosis, and lyme disease. Early identification of such infectious disease is very much necessary which can be done using ensemble machine learning techniques [1, 2].
The identification and controlling of spread of zonotic disease is challenging due to several issues which includes no proper symptoms, signs of zoonoses are very much similar, improper vaccination of animals, poor knowledge among the peoples about animal health, costly to control the world wide spread of the disease, not likely to change the habits of people, prioritization of symptoms of disease is difficult, lack of proper clothing, sudden raise in morbidity of the humans, consumption of spoiled or contaminated food, inability to control the spread of zonotic microorganisms, reemerging of zonotic diseases at regular time intervals, difficult to form coordinated remedial policies, violation of international law to control the disease, transaction cost to arrive at disease control agreements is high, surveillance of disease at national and international level is difficult, unable to trace the initial symptoms of influenza virus, wide spread nature of severe acute respiratory syndromes, inability to provide sufficient resources, climate change also influences on the spread of the disease, difficult to prioritize the zonotic diseases, increasing trend in the spread of disease from animals to humans, and continuous and close contact between the humans and animals [3, 4].
Ensemble machine learning uses multiple machine learning algorithms, to arrive at better performance, compared to individual/stand-alone machine learning algorithms [5, 6]. Some of the potential ensemble learning algorithms like Bayes optimal classifier, bootstrap aggregating (bagging), boosting, Bayesian model averaging (BMA), Bayesian model combination, bucket of models, stacking, and remote sensing. Some of the advantages offered by ensemble machine learning compared to traditional machine learning are as follows: better accuracy is achieved in prediction, scalability if the solution is high as it can handle multiple nodes very well, combines multiple hypothesis to maximize the quality of the output, provides sustainable solution by operating in an incremental manner, efficiently uses the previous knowledge to produce diverse model-based solutions, avoids overfitting problem through sufficient training, models generated are good as they mimics the human like behavior, complex disease spreading traces can be analyzed using combined machine learning models, misclassification of samples is less due to enough training models, not sensitive toward outliers, cross-validation of output data samples increases performance, stability of the chosen hypothesis is high, measurable performance in initial data collection is high, will not converge to local optimal solutions, exhibits non-hierarchical and overlapping behaviors, several open source tools are available for practical implementation of the models, and so on [7–9].
The main goal of applying ensemble machine learning algorithms in identifying the zonotic diseases are as follows: decreases the level of bagging and bias and improves the zonotic disease detection accuracy with minimum iteration of training, automatic identification of diseases, use of base learners make it suitable to medical domain, easy to identify the spread of disease at early stage itself, identifies the feature vector which yields maximum information gain, easy training of hyper parameters, treatment cost is minimum, adequate coverage happens to large set of medical problems, reoccurrence of the medical problems can be identified early, high correlation between machine learning models leads to efficient output, training and execution time is less, scalability of the ensemble models is high, offers aggregated benefits of several models, non-linear decision-making ability is high, provides sustainable solutions to chronic diseases, automatic tuning of internal parameters increases the convergence rate, reusing rate of the clinical trials gets reduced, early intervention prevents spread of disease, capable to record and store high-dimensional clinical dataset, recognition of neurological diseases is easy, misclassification of medical images with poor image quality is reduced, combines the aggregated power of multiple machine learning models, and so on [10, 11].
2.2 Bayes Optimal Classifier
Bayes optimal classifier is a popular machine learning model used for the purpose of prediction. This technique is based on Bayes theorem which is principled by Bayes theorem and closely related to maximum posteriori algorithm. The classifier operates by finding the hypothesis which has maximum probability of occurrence. The probable prediction is carried out by the classifier using probabilistic model which finds the most probable prediction using the training and testing data instances.
The basic conditional probability equation predicts one outcome given another outcome, consider A and B are two probable outcomes the probability of occurrence of event using the equation P(A|B) = (P(B|A)*P(A))/P(B). The probabilistic frameworks used for prediction purpose are broadly classified into two types one is maximum posteriori, and the other is maximum likelihood estimation. The important objective of these two types of probabilistic framework is that they locate most promising hypothesis in the given training data sample. Some of the zonotic diseases which can be identified and treated well using Bayes optimal classifier are Anthrax, Brucellosis, Q fever, scrub typhus, plague, tuberculosis, leptospirosis, rabies, hepatitis, nipah virus, avian influenza, and so on [12, 13]. A high-level representation of Bayes optimal classifier is shown in Figure 2.1. In the hyperplane of available datasets, the Bayes classifier performs the multiple category classification operation to draw soft boundary among the available datasets and make separate classifications. It is observed that, with maximum iteration of training and overtime, the accuracy of the Bayes optimal classifier keeps improving.
Some of the advantages of advantages of Bayes optimal classifier which makes it suitable for tracking and solving the zonotic diseases are as follows: ease of implementation, high accuracy is achieved over less training data, capable of handling both discrete and non-discrete data samples, scalable to any number of data samples, operates at very speed, suitable for real-time predictions, achieves better results compared to traditional classifiers, not much sensitive to outliers, ease generalization, achieves high computational accuracy, works well on linear/nonlinear separable data samples, interpretation of the results is easy, easily mines the complex relationship between input and output data samples, provides global optimal solutions, and so on [14].
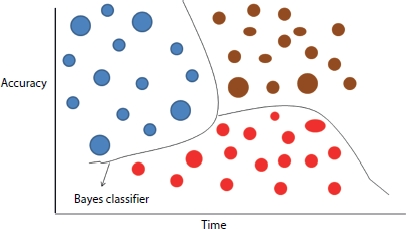
Figure 2.1 A high-level representation of Bayes optimal classifier.
2.3 Bootstrap Aggregating (Bagging)
Bootstrap aggregating is popularly referred as bagging is a machine learning–based ensemble technique which improves the accuracy of the algorithm and is used mostly for classification or aggregation purposes. The main purpose of bagging is that it avoids overfitting problem by properly generalizing the existing data samples. Consider any standard input dataset from which new training datasets are generated by sampling the data samples uniformly with replacement. By considering the replacements, some of the observations are repeated in the form of the unique data samples using regression or voting mechanisms. The bagging technique is composed of artificial neural networks and regression tree, which are used to improve the unstable procedures. For any given application, the selection between bagging and boosting depends on the availability of the data. The variance incurred is reduced by combining bootstrap and bagging [15, 16].
Bagging and boosting operations are considered as two most powerful tools in ensemble machine learning. The bagging operation is used concurrently with the decision tree which increases the stability of the model by reducing the variance and also improves the accuracy of the model by minimizing the error rate. The aggregation of set of predictions made by the ensemble models happens to produce best prediction as the output. While doing bootstrapping the prominent sample is taken out using the replacement mechanism in which the selection of new variables is dependent on the previous random selections. The practical application of this technique is dependent on the base learning algorithm which is chosen first and on top of which the bagging of pool of decision trees happen. Some of the zonotic diseases which can be identified and treated well using bootstrap aggregating are zonotic influenza, salmonellosis, West Nile virus, plague, rabies, Lyme disease, brucellosis, and so on [17]. A high-level representation of bootstrap is shown in Figure 2.2. It begins with the training dataset, which is distributed among the multiple bootstrap sampling units. Each of the bootstrap sampling unit operates on the training subset of data upon which the learning algorithm performs the learning operation and generates the classification output. The aggregated sum of each of the classifier is generated as the output.

Figure 2.2 A high-level representation of Bootstrap aggregating.
Some of the advantages offered by bootstrap in diagnosing the zonotic diseases are as follows: the aggregated power of several weak learners over runs the performance of strong learner, the variance incurred gets reduced as it efficiently handles overfitting problem, no loss of precision during interoperability, computationally not expensive due to proper management of resources, computation of over confidence bias becomes easier, equal weights are assigned to models which increases the performance, misclassification of samples is less, very much robust to the effect of the outliers and noise, the models can be easily paralyzed, achieves high accuracy through incremental development of the model, stabilizes the unstable methods, easier from implementation point of view, provision for unbiased estimate of test errors, easily overcomes the pitfalls of individuals machine learning models, and so on.
2.4 Bayesian Model Averaging (BMA)
It is one of the popularly referred ensemble machine learning model which applies Bayesian inference to solve the issues related to the selection of problem statement, performing the combined estimation, and produces the results using any of the straight model with less prediction accuracy. Several coherent models are available in BMA which are capable of handling the uncertainty available in the large datasets. The steps followed while implemented the MBA model is managing the summation, computation of integral values for MBA, using linear regression for predictions, and transformation purposes [18, 19].
Basically, BMA is an extended form of Bayesian inference which performs mathematical modeling of uncertainty using prior distribution by obtaining the posterior probability using Bayes theorem. For implementing the BMA, first prior distribution of each of the models in the ensemble network needs to be specified then evidence needs to be found for each of the model. Suppose the existing models are represented by Ml, where the value of l varies from 1 to k which basically represent the set of probability distributions. The probability distribution computes likelihood function L(Y|θl, Ml), where θl stands for parameter which are model specific dependent parameter. According to the Bayes theorem, the value for posterior probability is computed as follows [20]. A high-level representation of BMA is shown in Figure 2.3. Bayesian model representation begins with the data set which is distributed among multiple data subsets. Each subset of data is fed as input to the learner then average operation is performed finally compared with the average threshold and tested using permutation threshold to generate the Bayesian model as output.
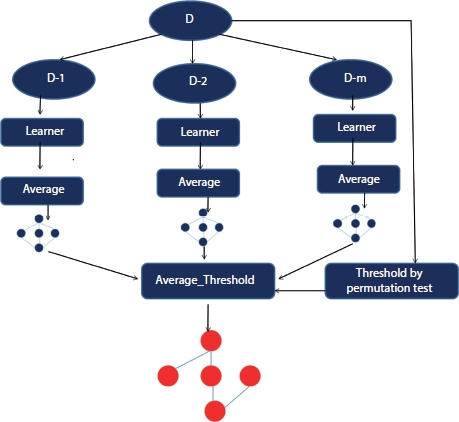
Figure 2.3 A high-level representation of Bayesian model averaging (BMA).
Some of the advantages offered by BMA in diagnosing the zonotic diseases are as follows: capable of performing multi-variable selection, generates overconfident inferences, the number of selected features are less, easily scalable to any number of classes, posterior probability efficiency is high, deployment of the model is easier, correct estimation of uncertainty, suitable to handle complex applications, proper accounting of the model, combines estimation and predictions, flexible with prior distribution, uses mean candidate placement model, performs multi-linear operation, suitable of handling the heterogeneous resources, provides transparent interpretation of the large amount of data, error reduction happens exponentially, the variance incurred in prediction is less, flexibility achieved in parameter inference is less, prediction about model prediction is less, high-speed compilation happens, generated high valued output, combines efficiency achieved by several learner and average models, very much robust against the effect caused by misspecification of input attributes, model specification is highly dynamic, and so on.
2.5 Bayesian Classifier Combination (BCC)
Bayesian classifier combination (BCC) considers k different types of classifiers and produces the combined output. The motivation behind the innovation of this classifier is will capture the exhaustive possibilities about all forms of data, and ease of computation of marginal likelihood relationships. This classifier will not assume that the existing classifiers are true rather it is assumed to be probabilistic which mimics the behavior of the human experts. The BCC classifier uses different confusion matrices employed over the different data points for classification purpose. If the data points are hard, then the BCC uses their own confusion matrix; else, the posterior confusion matrix will be made use. The classifier identifies the relationship between the output of the model and the unknown data labels. The probabilistic models are not required; they share information about sending or receiving the information about the training data [21, 22].
The BCC model the parameters which includes ![]() hyperparameters
hyperparameters ![]() . Based on the values of the prior posterior probability distribution of random variables with observed label classes, the independence posterior density id computed as follows:
. Based on the values of the prior posterior probability distribution of random variables with observed label classes, the independence posterior density id computed as follows:
The inferences drawn are based on the unknown random variables, i.e., P, π, t, V, and α which are collected using Gibbs and rejection sampling methodology. A high-level representation of BCC is shown in Figure 2.4. First parameters of BCC model, hyperparameters, and posterior probabilities are summed to generate final prediction as output.
Some of the advantages offered by BCC in diagnosing the zonotic diseases are as follows: performs probabilistic prediction, isolates the outliers which causes noise, efficient handling of missing values, robust handling of irrelevant attributes, side effects caused by dependency relationships can be prevented, easier in terms of implementation, ease modeling of dependency relationships among the random variables, learns collectively from labeled and unlabeled input data samples, ease feature selection, lazy learning, training time is less, eliminates unstable estimation, high knowledge is attained in terms of systems variable dependencies, high accuracy achieved in interpretation of the results, confusion matrix–based processing of data, low level of computational complexity, easily operates with less computational resources, requires less amount of training data, capable enough to handle the uncertainty in the data parameters, can learn from both labeled and unlabeled data samples, precise selection of the attributes which yields maximum information gain, eliminates the redundant values, lower number of tunning parameters, less memory requirement, highly flexible classification of data, and so on [23].

Figure 2.4 A high-level representation of Bayesian classifier combination (BCC).
2.6 Bucket of Models
The bucket of models is one of the popular ensemble machine learning techniques used to choose the best algorithm for solving any computational intensive problems. The performance achieved by bucket of models is good compared to average of all ensemble machine learning models. One of the common strategies used to select the best model for prediction is through cross-validation. During cross-validation, all examples available in the training will be used to train the model and the best model which fits the problem will be chosen. One of the popular generalization approaches for cross-validation selection is gating. In order to implement the gating, the perceptron model will be used which assigns weight to the prediction product by each model available in the bucket. When the large number of models in the bucket is applied over a larger set of problems, the model for which the training time is more can be discarded. Landmark-based learning is a kind of bucket-based model which trains only fast algorithms present in the bucket and based on the prediction generated by fast algorithms will be used to determine the accuracy of slow algorithms in the bucket [24]. A high-level representation of bucket of models is shown in Figure 2.5. The data store maintains the repository of information, which is fed as input to each of the base learners. Each of the base learners generates their own prediction as output which is fed as input to the metalearner. Finally, the metalearner does summation of each of the predictions to generate final prediction as output.
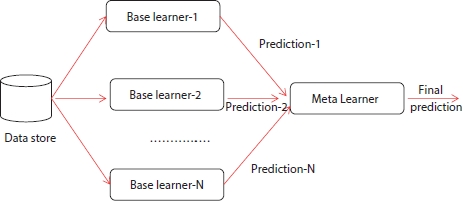
Figure 2.5 A high-level representation of bucket of models.
One of the best suitable approaches for cross-validation among multiple models in ensemble learning is bake off contest, the pseudo-code of which is given below.
Pseudo-code: Bucket of models
For each of the ensemble model present in the bucket do
Repeat constant number of times
Divide the training set into parts, i.e., training set and test set randomly
Train the ensemble model with training set
Test the ensemble model with test set
Choose the ensemble model that yields maximum average score value
Some of the advantages offered by bucket of models in diagnosing the zonotic diseases are as follows: high quality prediction, provides unified view of the data, negotiation of local patterns, less sensitive to outliers, stability of the model is high, slower model gets benefited from faster models, parallelized automation of tasks, learning rate is good on large data samples, payload functionality will be hidden from end users, robustness of the model is high, error generation rate is less, able to handle the random fluctuations in the input data samples, length of the bucket is kept medium, easier extraction of features from large data samples, prediction happens by extracting the data from deep web, linear weighted average model is used, tendency of forming suboptimal solutions is blocked, and so on [25, 26].
2.7 Stacking
Stacking is also referred as super learning or stacked regression which trains the meta-learners by combining the results generated by multiple base learners. Stacking is one form of ensemble learning technique which is used to combine the predictions generated by multiple machine learning models. The stacking mechanism is used to solve regression or classification problems. The typical architecture of stacking involves two to three models which are often called as level-0 model and level-1 model. The level-0 model fit on the training data and the predictions generated by it gets compiled. The level-1 model learns how to combine the predictions generated by the predictions obtained from several other models. The simplest approach followed to prepare the training data is k-fold cross- validations of level-0 models. The implementation of stacking is easier and training and maintenance of the data is also easier. The super learner algorithm works in three steps first is to setup the ensemble, train the ensemble which is setup, and after sufficient training test for the new test data samples [27, 28].
The generalization approach in stacking splits the existing data into two parts one is training dataset and another is testing dataset. The base model is divided into K-NN base models, the base model will be fitted into K–1 parts which leads to the prediction of the Kth part. The base model will further fit into the whole training dataset to compute the performance over the testing samples. The process gets repeated on the other base models which include support vector machine, decision tree, and neural network to make predictions over the test models [29]. A high-level representation of stacking is shown in Figure 2.6. Multiple models are considered in parallel, and training data is fed as input to each of the model. Every model generated the predictions and summation of each of the predictions is fed as input to generalizer. Finally, generalizer generates final predictions based on the summation of the predictions generated by each of the model.
Some of the advantages offered by stacking in diagnosing the zonotic diseases are as follows: easily parallelized, easily solves regression problems, simple linear stack approach, lot more efficient, early detection of local patterns, lower execution time, produces high quality output, chances of misclassification is less, increased predictive accuracy, effect of outliers is zero, less memory usage, less computational complexity, capable of handling big data streams, works in an incremental manner, classification of new data samples is easy, used to solve multiple classification problems, approach is better than classical ensemble method, suitable to solve computation intensive applications, generalization of sentiment behind analysis is easy, able to solve nonlinear problems, robust toward large search space, training period is less, capable of handling noisy training data, collaborative filtering helps in removal of noisy elements from training data, suitable to solve multi-classification problems, less number of hyperparameters are involved in training, evolves naturally from new test samples, very less data is required for training, and so on.
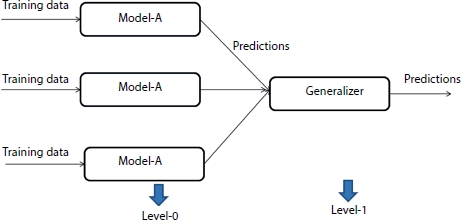
Figure 2.6 A high-level representation of stacking.
2.8 Efficiency Analysis
The efficiency achieved by the considered ensemble machine learning techniques, i.e., Bayes optimal classifier, bagging, boosting, BMA, bucket of models, and tacking, is compared toward the performance metrics, i.e., accuracy, throughput, execution time, response time, error rate, and learning rate [30]. From the analysis, it is observed that the efficiency achieved by Bayesian model combination, stacking, and Bayesian model combination are high compared to other ensemble models considered for identification of zonotic diseases.
| Technique | Accuracy | Throughput | Execution time | Response time | Error rate | Learning rate |
| Bayes optimal classifier | Low | Low | High | Medium | Medium | Low |
| Bagging | Low | Medium | Medium | High | Low | Low |
| Boosting | Low | Medium | High | High | High | Low |
| Bayesian model averaging | High | High | Medium | Medium | Low | Low |
| Bayesian model combination | High | High | Low | Low | Low | High |
| Bucket of models | Low | Low | High | Medium | Medium | Low |
| Stacking | High | High | Low | Low | low | Medium |
2.9 Conclusion
This chapter provides introduction to zonotic diseases, symptoms, challenges, and causes. Ensemble machine learning uses multiple machine learning algorithms to identify the zonotic diseases in early stage itself. Detailed analysis of some of the potential ensemble machine learning algorithms, i.e., Bayes optimal classifier, bootstrap aggregating (bagging), boosting, BMA, Bayesian model combination, bucket of models, and stacking are discussed with respective architecture, advantages, and application areas. From the analysis, it is observed that the efficiency achieved by Bayesian model combination, stacking, and Bayesian model combination are high compared to other ensemble models considered for identification of zonotic diseases.
References
1. Allen, T., Murray, K.A., Zambrana-Torrelio, C., Morse, S.S., Rondinini, C., Di Marco, M., Daszak, P., Global hotspots and correlates of emerging zoo-notic diseases. Nat. Commun., 8, 1, 1–10, 2017.
2. Han, B.A., Schmidt, J.P., Bowden, S.E., Drake, J.M., Rodent reservoirs of future zoonotic diseases. Proc. Natl. Acad. Sci., 112, 22, 7039–7044, 2015.
3. Salata, C., Calistri, A., Parolin, C., Palu, G., Coronaviruses: a paradigm of new emerging zoonotic diseases. Pathog. Dis., 77, 9, ftaa006, 2019.
4. Mills, J.N., Gage, K.L., Khan, A.S., Potential influence of climate change on vector-borne and zoonotic diseases: a review and proposed research plan. Environ. Health Perspect., 118, 11, 1507–1514, 2010.
5. Ardabili, S., Mosavi, A., Várkonyi-Kóczy, A.R., Advances in machine learning modeling reviewing hybrid and ensemble methods, in: International Conference on Global Research and Education, 2019, September, Springer, Cham, pp. 215–227.
6. Gao, X., Shan, C., Hu, C., Niu, Z., Liu, Z., An adaptive ensemble machine learning model for intrusion detection. IEEE Access, 7, 82512–82521, 2019.
7. Yacchirema, D., de Puga, J.S., Palau, C., Esteve, M., Fall detection system for elderly people using IoT and ensemble machine learning algorithm. Pers. Ubiquitous Comput., 23, 5–6, 801–817, 2019.
8. Zewdie, G.K., Lary, D.J., Levetin, E., Garuma, G.F., Applying deep neural networks and ensemble machine learning methods to forecast airborne ambrosia pollen. Int. J. Environ. Res. Public Health, 16, 11, 1992, 2019.
9. Dang, Y., A Comparative Study of Bagging and Boosting of Supervised and Unsupervised Classifiers For Outliers Detection (Doctoral dissertation), Wright State University, Dayton, Ohio, United States, 2017.
10. Wiens, J. and Shenoy, E.S., Machine learning for healthcare: on the verge of a major shift in healthcare epidemiology. Clin. Infect. Dis., 66, 1, 149–153, 2018.
11. Bollig, N., Clarke, L., Elsmo, E., Craven, M., Machine learning for syndromic surveillance using veterinary necropsy reports. PLoS One, 15, 2, e0228105, 2020.
12. Shen, X., Zhang, J., Zhang, X., Meng, J., Ke, C., Sea ice classification using Cryosat-2 altimeter data by optimal classifier–feature assembly. IEEE Geosci. Remote Sens. Lett., 14, 11, 1948–1952, 2017.
13. Dalton, L.A. and Dougherty, E.R., Optimal classifiers with minimum expected error within a Bayesian framework—Part II: properties and performance analysis. Pattern Recognit., 46, 5, 1288–1300, 2013.
14. Boughorbel, S., Jarray, F., El-Anbari, M., Optimal classifier for imbalanced data using Matthews Correlation Coefficient metric. PLoS One, 12, 6, e0177678, 2017.
15. Hassan, A.R., Siuly, S., Zhang, Y., Epileptic seizure detection in EEG signals using tunable-Q factor wavelet transform and bootstrap aggregating. Comput. Methods Programs Biomed., 137, 247–259, 2016.
16. Hassan, A.R. and Bhuiyan, M.I.H., Computer-aided sleep staging using complete ensemble empirical mode decomposition with adaptive noise and bootstrap aggregating. Biomed. Signal Process. Control, 24, 1–10, 2016.
17. Pino-Mejías, R., Jiménez-Gamero, M.D., Cubiles-de-la-Vega, M.D., Pascual-Acosta, A., Reduced bootstrap aggregating of learning algorithms. Pattern Recognit. Lett., 29, 3, 265–271, 2008.
18. Hinne, M., Gronau, Q.F., van den Bergh, D., Wagenmakers, E.J., A conceptual introduction to Bayesian model averaging. Adv. Methods Pract. Psychol. Sci., 3, 2, 200–215, 2020.
19. Ji, L., Zhi, X., Zhu, S., Fraedrich, K., Probabilistic precipitation forecasting over East Asia using Bayesian model averaging. Weather Forecasting, 34, 2, 377–392, 2019.
20. Liu, Z. and Merwade, V., Separation and prioritization of uncertainty sources in a raster based flood inundation model using hierarchical Bayesian model averaging. J. Hydrol., 578, 124100, 2019.
21. Isupova, O., Li, Y., Kuzin, D., Roberts, S.J., Willis, K., Reece, S., Computer Science, Mathematics, BCCNet: Bayesian classifier combination neural network. arXiv preprint arXiv:1811.12258, 8, 1–5, 2018.
22. Yang, J., Wang, J., Tay, W.P., Using social network information in community-based Bayesian truth discovery. IEEE Trans. Signal Inf. Process. Networks, 5, 3, 525–537, 2019.
23. Yang, J., Wang, J., Tay, W.P., IEEE Transactions on Signal and Information Processing over Networks, Using Social Network Information in Bayesian Truth Discovery. arXiv preprint arXiv:1806.02954, 5, 525–537, 2018.
24. Dadhich, S., Sandin, F., Bodin, U., Andersson, U., Martinsson, T., Field test of neural-network based automatic bucket-filling algorithm for wheel-loaders. Autom. Constr., 97, 1–12, 2019.
25. Leguizamón, S., Jahanbakhsh, E., Alimirzazadeh, S., Maertens, A., Avellan, F., Multiscale simulation of the hydroabrasive erosion of a Pelton bucket: Bridging scales to improve the accuracy. Int. J. Turbomach. Propuls. Power, 4, 2, 9, 2019.
26. Lora, J.M., Tokano, T., d’Ollone, J.V., Lebonnois, S., Lorenz, R.D., A model intercomparison of Titan’s climate and low-latitude environment. Icarus, 333, 113–126, 2019.
27. Chen, J., Yin, J., Zang, L., Zhang, T., Zhao, M., Stacking machine learning model for estimating hourly PM2. 5 in China based on Himawari 8 aerosol optical depth data. Sci. Total Environ., 697, 134021, 2019.
28. Dou, J., Yunus, A.P., Bui, D.T., Merghadi, A., Sahana, M., Zhu, Z., Pham, B.T., Improved landslide assessment using support vector machine with bagging, boosting, and stacking ensemble machine learning framework in a mountainous watershed, Japan. Landslides, 17, 3, 641–658, 2020.
29. Singh, S.K., Bejagam, K.K., An, Y., Deshmukh, S.A., Machine-learning based stacked ensemble model for accurate analysis of molecular dynamics simulations. J. Phys. Chem. A, 123, 24, 5190–5198, 2019.
Email: [email protected]