
CHAPTER 4
Authentication and Access Control
In this chapter, you will learn:
• The difference between authentication and authorization
• Authentication types
• Authentication protocols
• Access control techniques
Authentication, authorization, and access control are layers of security controls to protect systems on your network, because at some point your users will want to make use of the systems and to do so, they need to verify they are legitimate users. All of these concepts are fundamental to providing your users with the ability to provide that verification so they can make use of the services that the systems offer. That’s ultimately the name of the game. As information security professionals, we should not prevent users from being able to function or even make it harder for them to do their jobs. Providing strong authentication is important, but only if it doesn’t drive users to find ways around that strong authentication by doing things like writing down passwords. As with everything in life, there needs to be a balance.
All of these concepts apply regardless of the type of system you are implementing and trying to protect. This can be a login to a desktop operating system or a remote login over Secure Shell (SSH) to a command-line environment. It can also be logging in to a virtual private network (VPN) or Gmail or Facebook. Web services all have authentication needs, and based on the frequent news reports about different accounts that have been cracked and broken into, there are still issues with fundamentally providing strong authentication that not only protects the systems but also protects the users and all of their data, including their credentials.
Beyond authentication is ensuring that each user gets access to the right resources and only those resources. This is what authorization is all about. Authentication is only the first step unless you intend for everyone to have the same rights and privileges all across the board, but that’s not very realistic. In conjunction with that idea is the principle of least privilege, which should be followed to keep systems and resources better protected.
Certain protocols are responsible for authentication, access control, and ensuring that users get authorized to the right resources. Two such protocols are RADIUS and TACACS, which can be employed in a wide variety of situations, including being used for dialup users (perhaps for remote, out-of-band administrative access) and for providing access to network equipment and networks in general.
Authentication
Authentication is the act of proving you are who you say you are. You have credentials that you use to perform the act of authentication, and those credentials may come in various forms.
There are four potential factors of authentication:
• Something you are This factor is inherent, meaning it’s a part of who you are. This is commonly called biometrics.
• Something you know This factor typically would be a password or personal identification number (PIN).
• Something you have Commonly, your smartphone or cell phone might be the something you have. When you enable two-factor authentication on your banking website, for example, you may get a message sent to your phone. This message, which includes a value you provide back to the system you are trying to authenticate against, is sent to a preconfigured number, demonstrating that you are the authorized user.
• Somewhere you are This factor is based on your location. You may have noticed that when you connect to your Google account or your Facebook account from a new location, you get an e-mail or a text message indicating that there was a connection attempt from a location that hadn’t been noted before. This is because these sites know where you commonly connect from, via IP address or geolocation.
Imagine that you are crossing the border into Canada. You will be asked for your passport, which has your name and picture. Your name tells the border patrol agent who you are, and your picture assures them that you are who you say you are. This is reasonably straightforward. Passports are valid for ten years. However, consider how much you may change in ten years, and how difficult it would be to ensure that you really are who you say you are ten years after your picture was taken and you’ve aged ten years. During that time, you may have gained or lost significant amounts of weight, your hair may have turned gray, or you might have had cosmetic surgery to make alterations to your nose or lips. Such changes increase the challenge of performing authentication based on your passport. Beyond that, there is the question of the eyesight and facial recognition capabilities of the agent examining you and your passport. Also, the amount of light in your car and in the sky above the agent, which ensures a good look at both your face and your passport, comes into play. I’m reminded of a scene from the 1985 movie Gotcha where Anthony Edwards’ character is crossing the East German border but doesn’t want to be recognized, so the punk band he is traveling with paint him up with a lot of makeup.

EXAM TIP It’s important to know the difference between authentication and authorization. Although they are related, they are very different concepts.
Given all of that, it’s a wonder that travel happens at all with so many variables involved in the simple act of authentication. Fortunately, there are far fewer variables in computer-based authentication, but that doesn’t make it any less challenging to find the right way to handle identity and proving you are who you say you are.
Figure 4-1 shows a partial log of users who have been authenticated on a Linux system on my network. Having this level of detail is a form of accounting, which is coming up later in more detail. This includes log information about cases where a user was authorized to perform a specific task. We will discuss authorization later in this chapter.

Figure 4-1 An Auth log from a Linux system
Credentials
Credentials are things you present in order to demonstrate that you are who you say you are. The credentials most commonly used in computing are a username and a password. These, however, are very weak credentials. Passwords can be easily guessed, particularly in this age of high-powered computers. Additional types of credentials are parts of your body in the case of biometrics, an access token, or a smart card. Combinations of these credentials can be used to perform authentication. When you use multiple methods of performing authentication, you are performing multifactor authentication. Not surprisingly, this is considered a best practice in implementing authentication. Single-factor authentication runs the risk of being compromised easily, particularly since single-factor authentication is typically a password.
Figure 4-2 shows a request from a Windows Server 2016 system for credentials. In this case, it’s the login screen, and the figure shows an attempt to log in as the user Administrator on the system. Administrator is one half of the credentials being requested; the password is the other half. You’ll see in the image that the user has filled in. Commonly, the user should have to enter the username rather than have it presented. An attacker, who could get access to this screen, including the possibility of a Remote Desktop Connection, would have half of the information they need. With the username already presented, the only piece that needs to be guessed is the password.

Figure 4-2 The Windows login screen
Passwords
A password is a secret word or phrase that is provided during the process of authentication. It is commonly paired with a username, although in some instances a password is all that is required to log in to some devices. There is a challenge with passwords, however. The best passwords are long and complex, with a variety of upper- and lowercase letters as well as numbers and symbols. The reason for this is mathematical. Let’s take an eight-character password that just uses upper- or lowercase letters. There are 52 possible upper- or lowercase letters, so an eight-character password has 52 × 52 × 52 × 52 × 52 × 52 × 52 × 52 possible variations. This is simply because each position has 52 possibilities and there are eight positions, so you multiply the number of possibilities in position 1 by the number of possibilities in position 2, and so on. The total number of possible passwords in that situation is thus 53,459,728,531,456. While that may be a really large number, adding an additional position multiplies the potential outcomes by 52, and that’s just if you only use letters. When you add in numbers, you get 62 potential values in each position, and thus 62^8 for an eight-character password. As you can see, adding additional positions and additional possible characters increases the number of possible outcomes.
Exercise 4-1: Password Values
How many potential passwords are there if you use a 16-character password/passphrase with all of the letters, both upper- and lowercase, as well as numbers and just the symbols that are above the numbers?
The problem is that humans just aren’t typically capable of memorizing complex passwords with random letters, numbers, and symbols. This can lead to bad behaviors like writing down passwords on a piece of paper and leaving it someplace where it can be referred to when logging in. This really defeats the point of having complex passwords to begin with if they can be found written down. As a result, you dramatically reduce the number of potential passwords by limiting passwords to words or names that are more easily remembered. Thus, we move from potentially billions, trillions, or more passwords to something in the range of thousands. This makes guessing the password a lot easier. In some cases, you can convert letters to either numbers or symbols in order to increase the complexity of the password, but those conversions aren’t typically challenging, and it ends up not really increasing the complexity. For example, using the word password for your password is, of course, a very bad idea. Changing the password to P455w0rd does a simple conversion from letters to numbers that look similar, but that strategy is pretty well known by attackers. If you change the letters to numbers or symbols that aren’t reminiscent of the original letter, you run the risk of forgetting the conversions you did, which puts you back in the same boat with the long, random password—something that can’t be remembered.
Often, people make it a lot easier to simply guess passwords by using ones that are easy to remember. Password123, the name of a significant other or child, and adding birthdates or anniversaries onto common words or names are all examples of typical strategies that people use in order to help them remember their password while still trying to ensure that it’s complex enough to pass whatever rules an organization may have for a password policy.
Password policies also sometimes make remembering passwords too difficult. Requiring that passwords be highly complex can make it difficult for users to come up with a password, which may make them resort to using a dictionary word as a starting point and just adding enough numbers, symbols, and uppercase letters to pass the policy check. When you add in password rotation, particularly with fast cycles, you quickly run into a situation where average users may be forced to write down the passwords somewhere. There are challenges to cycling passwords every 60 or 90 days, too, especially when you don’t allow for a reasonable level of reuse. Again, we run into the limitation where the human brain just doesn’t really work that way. The brain is very associative by nature and strong passwords are non-associative and shouldn’t be associative.
One tactic, in addition to a password policy, for ensuring the strength of users’ passwords is to regularly run password-cracking checks against the password database. This is certainly something an attacker would likely do. Passwords are not commonly stored in plaintext anywhere since this would defeat trying to use strong passwords to begin with. If they were stored in plaintext, an attacker would only need to gain access to the system where the passwords are kept and read the file or files. As a result, there needs to be a way to protect the passwords in case the password files are actually discovered. One common way of doing that is to perform a cryptographic hash on each password. A cryptographic hash is a one-way function that generates a value that appears unrelated to the input. There is no way to run a cryptographic hash through an algorithm to reverse the process and get the plaintext password back, so this would seem to do a really good job of protecting the password.

NOTE One of the hash functions that has been very popular is based on the Data Encryption Standard (DES) algorithm. DES was specified as the encryption standard in the 1970s.
In addition to protecting password files by performing cryptographic functions like a hash on the password, the permissions on the file or files are typically set so that only the highest level of user can look at the results. You might think that hashing the passwords would be enough, given that the hash is one-way and can’t be undone. The reason for this is that even with a one-way hash algorithm to protect the passwords themselves, there are ways of obtaining the password from the hash.
Password Cracking
Password cracking is the method by which passwords are taken from the place in which they are stored, typically having been hashed or otherwise encrypted, and obtaining the cleartext password. This is commonly done by simply performing the hash or encryption process against a list of possible passwords and comparing the output to the stored password. If the result matches, the password has been discovered. This can take time and computational power, particularly if there is a long list of potential passwords. Using a list of potential passwords and computing the hash or encrypted password from the plaintext is called a dictionary attack. Generating passwords using a specific set of criteria (e.g., a–z, A–Z, 0–9), computing the encrypted or hashed password, and then comparing the result to the stored password is called brute-forcing.
One way of limiting the processing time is to pre-compute all of the hashes ahead of time rather than when trying to crack the password. This means you are only computing the hashes of a dictionary or wordlist once and then comparing the stored password against the pre-computed hash value. This approach of using rainbow tables is a tradeoff of computing power versus storage space. Rainbow tables take up more disk space than just a wordlist because you are storing the pre-computed hash as well as the plaintext.
A number of password cracking utilities are available. One of the most popular is John the Ripper, an open-source utility that runs on Unix-based and Windows operating systems. John supports passwords that have been hashed using the Unix crypt function, which commonly uses DES as the algorithm to hash the password. John also supports passwords that have been stored in LAN Manager (LM) format, as well as passwords hashed with the Secure Hash Algorithm (SHA). This covers the majority of operating systems that are available. John can, and has been extended to, support even more password formats. This gives it a lot of flexibility.
Figure 4-3 shows the help feedback provided by John, indicating the number of options that are available in the course of a run. In addition to the command-line options, John also supports configuration files that can be used to provide information on how John should run.
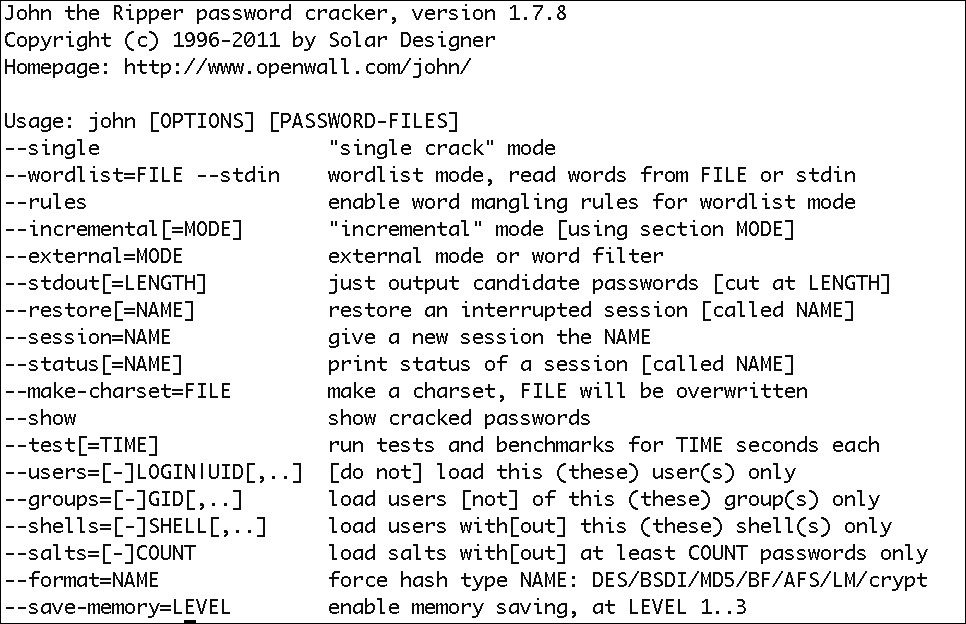
Figure 4-3 John command-line options
NOTE In order to get the list of users and passwords from a Windows system, you can use the pwdump command. This will provide you with data that you can feed John to crack Windows passwords.
Another password-cracking utility that has been very popular is L0phtCrack. L0phtCrack was written by Mudge, a member of the hacker group L0pht. It was designed to test password strength and also recover lost passwords. L0phtCrack uses a combination of strategies, much like John does. L0phtCrack uses dictionary, brute-force, and rainbow tables attacks against the Windows password database. Unlike John, however, L0phtCrack is commercial software and has been through a few owners, in part due to mergers and acquisitions.
Figure 4-4 shows the L0phtCrack wizard that starts up when you launch L0phtCrack. The wizard guides you through how you want to import passwords, how you want to try to crack them, and then how you want the results reported on. Of course, you can cancel out of the wizard and just use L0phtCrack without it. Figure 4-5 shows the main window of L0phtCrack, including the Statistics pane on the right-hand side that provides a status on the number of passwords cracked and how many passwords have been attempted. You can also see the passwords that are being attempted as they go by.

Figure 4-4 The L0phtCrack wizard

Figure 4-5 The L0phtCrack main window
NOTE Mudge (Peiter Zatko) formerly worked at BBN, the company responsible for building the ARPANET, and then went to DARPA, the defense analog of ARPA. Mudge once famously announced, with other members of L0pht, that they could shut down the Internet in 30 minutes.
LAN Manager Passwords
Windows originally took their password management from OS/2, which was the operating system developed by Microsoft in conjunction with IBM. OS/2 called their networking components LAN Manager, and the password storage was referred to as LAN Manager (LM). There were a number of problems with the LAN Manager passwords, however. The first problem was that LM passwords were not case-sensitive. All passwords were converted to uppercase before the hash was generated. This immediately removed 26 characters from the possible characters in each position. You could always assume that any letter in the password was uppercase. Additionally, while the passwords had a maximum length of 14 characters, they were padded with NULL bytes (a value of 0) if the actual password was less than 14 characters. Finally, the password was broken into two seven-character chunks, a hash was computed on each chunk, and then the two hashes were put back together. If a password was only seven characters, the second half of the hash would always have the same value because it would be based on a hash of NULL bytes. A hash will always yield the same result through a hashing algorithm. If it didn’t, it wouldn’t be of much value to something like an authentication process since you wouldn’t be able to compare a stored value against a computed value because the computed value would be different every time.
If you had a password that was less than eight characters, which is possible without a password policy, the value of the second part of your hash would be 0xAAD3B435B51404EE. When you saw this value in the second half of the hash, you could be assured you were looking for a short password, which significantly reduced the number of potential passwords on top of the already reduced number because all passwords would be uppercase after being converted.
All of these processing strategies led to very weak passwords. Microsoft called their implementation of LAN Manager NT LAN Manager (NTLM). Microsoft continued to use LM hashes for authentication until the release of NT4.0 Service Pack (SP) 4 in October of 1998. At that time, Microsoft released NTLM version 2 to remediate the flaws in the original NTLM implementation that led to easily cracked passwords.
Prior to the release of SP4, Microsoft attempted to protect their password database with Syskey. Syskey was introduced as an optional feature in NT 4.0 SP3. Syskey encrypted the password database in an attempt to protect against offline password cracking. Offline password cracking is where you take the static password database and run password crackers against all of the hashes, trying to determine what the plaintext password is.
EXAM TIP In order to get the password database from a Windows system using Syskey, you can use the pwdump utility. The results can then be fed into a password cracking utility like John.
Token-Based Authentication
Token-based authentication may make use of a physical token that provides an authentication value. The token is “something you have” and is typically used in conjunction with “something you know,” like a personal identification number (PIN). It’s possible to get software-based tokens that work like a hardware token. One of the great advantages to token-based authentication is that it commonly uses one-time passwords. The token generates a value that, employed in conjunction with the PIN, can be used to authenticate a user. Once the authentication value has been used, it can’t be used again and the value provided by the token will refresh after a specific period of time.
Hardware tokens can come in several forms, and mobile devices such as cell phones can sometimes be used to perform the token function. Some tokens require being attached to the computer the user is trying to authenticate to. This could be done using a USB dongle that plugs into the computer using a well-known and widely used system interface. This is very similar to the dongle that has long been used by software vendors to ensure that the person using a piece of software is actually the owner. When you purchase some pieces of software, you get a hardware dongle. The software won’t run without the dongle attached. The idea is that while you can make as many copies of the software as you like and distribute them, they won’t be any good without the dongle, which is significantly harder to copy and distribute.
One method of implementing a token function is using a synchronized token and server. The token’s values are synchronized with a server that is used to check the values when the user wants to be authenticated. The PIN would be checked to ensure it’s the one provided by the user when the token was first initialized. Then the token value is checked to ensure that the user is in possession of the token.
Figure 4-6 is a picture of an RSA SecurID token. Notice that the display has a number in it. The number changes every 60 seconds and is synchronized with a server. The number, in combination with a PIN, is the one-time password that would be used to authenticate a user.

Figure 4-6 An RSA SecurID token
Tokens can also be used for physical authentication to ensure that someone has the ability to access something, like entry to a building. A badge can be used in place of a key since keys can be lost or copied. A badge containing information about the holder is much harder to copy and can also be imprinted with the picture of the user, which provides additional authentication, ensuring that the holder of the badge is the right person. These types of tokens are also used in electronic payment solutions. You will sometimes see a place to wave your credit card instead of swiping it.
Tokens are not foolproof, however. If the PIN can be determined either by shoulder-surfing (looking over the shoulder of a user) or guessing, then the token can be used to authenticate as the user of the token. This form of two-factor authentication is still considered better than simply using usernames and passwords, because a password can be guessed, and while a PIN can also be guessed, you need to have physical access to the token in order to make use of it.
NOTE Some financial institutions are using two-factor authentication that employs tokens to authenticate their customers to web-based portals.
RSA Security is one of the leading vendors when it comes to token-based authentication. Their SecurID product comes in a wide variety of forms and is often used for one-time password authentication in enterprises. RSA was breached in 2011 and one of the major concerns, in light of the fact that RSA admitted that information relating to their SecurID products had gotten out, was that information that would have allowed token codes to be predicted may have gotten out. This breach and the possible issues that may have resulted from it really highlight the challenges of strong authentication. It’s very difficult to develop an invulnerable means of authentication.
Biometrics
One of the great things about biometrics is all of the movies that have made use of biometrics to one degree or another, typically demonstrating ways of bypassing biometric systems. Seen in everything from Sneakers (where they splice a tape together to get past a voice print recognizer) to Demolition Man (where Wesley Snipes uses an eyeball from a dead body to get past a retinal scanner), biometrics is the “something you are” part of authentication. Something you are can entail a number of aspects of your physical being, including your voice, your face, or portions of your hand or eye.
Biometrics work because we are generally physically unique in many ways, and these unique qualities can be used to identify us. Biometric systems are not infallible, however. There are a lot of different reasons why biometric systems can fail, which can sometimes make them weak authenticators. Some important metrics are associated with biometrics. The first is the false acceptance rate (FAR). Obviously, the FAR is a very important statistic because it means that sometimes biometric systems can be mistaken and thus allow someone access to a resource who shouldn’t have access to it.
EXAM TIP Lowering the false acceptance rate (FAR) is a critical aspect of maintaining a biometric system.
Another important metric is the false rejection rate (FRR), which is the probability that someone who should have access is instead rejected by the biometric system. This is another statistic that takes careful monitoring to ensure that appropriate users get access to systems they should get access to. Tuning the biometric system and providing it with additional data points can reduce the FRR.
The Android phone software provides a way of authenticating users with facial recognition. When you hold your phone up to your face, as long as you have configured facial recognition as a means of authentication, your phone will recognize you and allow you access. Apple introduced Face ID in 2017, providing similar functionality to what Android already had. However, because of the FRR, there is a backup authentication mechanism on both types of devices because sometimes both Android’s facial recognition and Apple’s Face ID fail, which would lead to the user being unable to use their phone if it were the only means of identification/authentication. It’s this sort of problem that can lead to challenges with the implementation of biometrics.
Biometric systems should have mechanisms to ensure that they can’t be fooled by a photo of a fingerprint or an iris. This “liveness” characteristic could be a heat sensor or, in the case of eye recognition, some amount of movement to indicate that it’s not a photo or other digital reproduction of the original.
Fingerprint Scanning
Fingerprint scanners are a very common type of biometric system. Such scanners have become so common, in fact, that many laptops have fingerprint scanners built into them as a way of authenticating users. The scanner looks at the pattern of whorls on your fingerprint because everyone has unique fingerprints. Fingerprints have long been used as a means of authenticating people. Children’s fingerprints are taken at an early age so the child can be identified in case of a catastrophic event like a kidnapping. Criminals are also identified by their fingerprints. Because fingerprints can be so reliable as a means of identification, they make good biometric identifiers. Figure 4-7 shows the tip of a finger and its pattern of whorls and ridges that provides the foundation for the identification.

Figure 4-7 The whorls of a fingertip
NOTE Fingerprints are left on surfaces that you touch as a result of the natural oils your body produces. These same oils can leave residue behind on a fingerprint scanner. Such oily residues may be used to lift fingerprints from a scanner, or they may cause problems with fingerprint identification.
There are challenges with fingerprint scanners, though. For example, with the built-in fingerprint scanner on a laptop, one finger is scanned. If you accidentally cut off that finger while woodworking, that fingerprint won’t do you any good (unless you keep the finger for scanning, a morbid idea straight out of a crime novel or movie in which the finger is intentionally removed and used to bypass a biometric system). That’s an extreme example of FRR, but there are other cases where your fingerprint may not be read accurately, leading to your fingerprint being rejected even though it really is your finger being scanned. Another challenge with fingerprint scanners is that some have been easily fooled by something as simple as a photocopy of a fingerprint.
A significant advantage of fingerprint scanners, though, is that your fingers are, assuming something catastrophic hasn’t happened, something you always have with you. A token can easily be forgotten at home or at work. Also, you can’t forget a finger like you can a password. Your finger remains static, so it’s not something you need to change out on a regular basis like a password. This is convenient and pretty reliable as a unique form of identity.
Voiceprint Analysis
A voiceprint is pretty much what it suggests. You take the idea of a fingerprint, but apply the concept to your voice. You would typically speak a particular phrase to a voiceprint system so that the resulting waveform could be compared against a stored waveform of you speaking the same phrase at the time your authentication credentials were established. This always recalls to me the movie Sneakers, where a voice was taped and then the resulting tape was spliced to construct the passphrase necessary to allow access to a facility. This is one of the risks of voiceprint as a means of authentication. Additionally, your voice can change on a regular basis depending on how well you are, your level of hydration, your level of excitation, and many other factors. The voice isn’t a constant. In addition to changes in pitch and inflection, there are changes in speed that can also factor into the difficulty of recognizing a voiceprint.
Even beyond the potential challenges in simply identifying the speaker accurately, there are the issues of ambient noise. Any noise within the environment, either at the time of initial identification or during the process of authentication, can potentially have an impact on the recognition of the sample since all noises will factor into a recorded waveform. These challenges are some of the reasons why voice recognition has a low adoption rate among biometric solutions.
NOTE It’s hard to check for liveness with a voiceprint, which is easy to manipulate using an audio recorder and some audio editing software. You can easily interface with a voiceprint system at a distance, and devices like a cell phone have the capability of playing back audio that can be easily detected by the voice recognition system.
As with fingerprint analysis, however, voiceprint analysis has the advantage of being something you can’t leave home without, except in the case of extreme illness, in which case you may well be better off staying home anyway. The one factor that may require memorization is the passphrase, unless it’s something you are prompted for by the authentication mechanism.
Eye Scanning
Two components of your eye can be scanned because they are considered unique. One is the iris and the other is the retina. The iris is the colored part of your eye that controls the diameter of the pupil to allow either more or less light in so you can see in both dark and bright situations. The retina is on the inner surface of the eye and is the portion responsible for sensing the light coming in through the pupil. The iris has similar characteristics to a fingerprint. It has a high degree of variability, leading to something close to uniqueness, so it can be used to determine whether someone is who they say they are. Additionally, the iris is something determined before birth that is carried with you throughout your life. The static nature of the iris makes it a good prospect for an identification marker. Figure 4-8 is a photo of an eye, with the blue iris surrounding the black pupil in the center. If you look closely at the photo, you may be able to see the unique pattern of white and gray squiggly lines running from the outer portion of the iris to the inner portion. This is the pattern, along with the coloration, that makes the iris unique for the purposes of identification.

Figure 4-8 An iris
Iris scanners can fail because a dilated or constricted pupil, resulting from differences in the amount of light available in different circumstances, can deform the iris, making it difficult to match against the known signature. In Figure 4-8, notice that the pupil is actually dilated. When the pupil either dilates to let more light enter the eye or constricts to keep too much light out, it changes the size of the iris and the pattern of the lines in the iris. To accurately perform an iris scan, the eye must be in very close proximity to the scanner and the person cannot move while the scan is in progress; otherwise, they run the risk of causing a false rejection because the scan won’t match. Without additional mechanisms to ensure the liveness of the subject, an iris scanner can be fooled by a very high-quality digital image of the subject’s iris. This can expose an iris scanner to a very high false acceptance rate.
In the case of the retina, the complex patterns of capillaries form the basis of the biometric identification. The patterns are complex enough that they can be considered unique among individuals. The pattern is also so unique that there are very low error rates both on the false acceptance and false rejection side. The challenge, though, is that eye abnormalities like cataracts and astigmatism can cause problems with accurate identification.
NOTE Retina scanning has been known for decades. In fact, Batman: The Movie from 1966 made reference to the complex pattern of capillaries in the retina and how they could be used to identify someone.
A challenge to both iris scanning and retinal scanning is the positioning of the sensor. If you position the sensor in such a way that tall people don’t have to bend down too far to present their eye for scanning, you will make it too tall for shorter people to reach it. One way or another, unless you have a scanner that can be repositioned, or multiple scanners for different sets of heights, you are going to inconvenience users.
Hand Scanning
Hand scanners rely on the way your hand is shaped, using its geometry to determine whether it’s a match. They make measurements of length, width, and other factors to help identify your hand. While hand scanners have been around for several decades and have been a very popular form of performing computerized biometrics for access purposes, they are not very accurate because hand geometry isn’t very unique to any particular individual.
Hand scanning, or hand geometry scanners, can be used very effectively, however, with other forms of authentication like a card scanner. The presence of the card (“something you have”) along with your hand (“something you are”) can be a very effective two-factor authentication mechanism.
RADIUS
Remote Authentication Dial-In User Service (RADIUS) is a way of performing authentication across a network. This offers a centralized approach in a situation where you have a large number of network devices requiring the same user base as in a provider of dialup network access from back in the day when accessing networks and the Internet over analog modems was a common thing. RADIUS originated in 1991 as a way of providing authentication for access servers. In the time since then, RADIUS servers have been deployed to handle a wide variety of authentication needs. Since RADIUS is a standard protocol, it can be used as a front end or proxy for other authentication mechanisms, including other RADIUS servers.
NOTE While RADIUS was developed in 1991 by the Livingston Corporation in response to a request for information (RFI) by Merit Network, maintenance and additional development of the protocol was taken over by the Internet Engineering Task Force, making it an Internet-wide standard.
RADIUS uses the User Datagram Protocol (UDP) for a transport protocol to send authentication requests and responses between the client and the server. A centralized server responsible for authentication is convenient and allows users to roam anywhere within the network and still make use of the same authentication credentials. In addition to authentication, RADIUS also offers authorization and accounting services. Both of these will be discussed later in this chapter.
Because of the generic nature of the protocol and architecture, RADIUS can be used to allow access to the Internet over a dialup modem or a DSL modem; it can be used to grant access to a wireless network; and it might be used to authenticate users in a virtual private network (VPN) solution. It has a wide variety of applications. Also, because it is a standard, it can be used as a glue protocol in between two different solutions. As noted earlier, a RADIUS server can behave as a proxy between a client and another authentication or authorization server. This may be a case where the network infrastructure makes use of a central RADIUS server that offloads requests for authentication to other servers based on the realm that the request references.
Clients belong to realms, which are ways of organizing users into specific groups. Each realm may have its own server. One example of this situation may be a case where one provider has the network infrastructure for a DSL network, but the customer-facing side is handled by resellers. Rather than allowing each reseller to make changes to a central database of users, which could be potentially problematic and may end up allowing poaching of users or accidental deletion, the network provider offers a RADIUS server where each DSL client authenticates, providing realm information as part of the request. This would allow the network provider’s RADIUS server to offload the actual authentication and authorization to a reseller’s RADIUS server. The network provider is proxying the authentication request on behalf of the reseller.
EXAM TIP RADIUS uses UDP port 1812 for authentication and UDP port 1813 for accounting.
RADIUS does offer some security to the authentication process. While some authentication protocols transmit their credentials in cleartext, expecting that the connection to the authentication server will be either direct or at least private, RADIUS uses a shared secret in conjunction with a Message Digest 5 (MD5) hash to transmit the credentials. This prevents unauthorized users from performing packet sniffing on the connection and easily extracting user credentials. In this case, getting the user credentials is far more challenging than simply trying to brute force a password since almost nothing about the communication may be known in advance. Even without an encrypted link to transmit the RADIUS traffic over, this is a large hurdle to obtaining user credentials. However, if all you are looking for is access to the network, you may be able to transmit captured hashes in response to an authentication challenge and gain access.
While RADIUS is still in widespread use, a replacement protocol, Diameter, has been proposed. Diameter is widely used in the mobile space as well as in other voice-related networks like Voice over IP (VoIP). One of the hurdles to implementing Diameter is simply support for the protocol in the networking equipment that is currently making use of RADIUS.
NOTE You may have caught the fact that Diameter = 2 × RADIUS. Just another little joke among us Internet engineers.
TACACS/TACACS+
Terminal Access Controller Access-Control System (TACACS) is an authentication protocol that provides the ability for a remote access server (e.g., terminal server, dialup access server, and so on) to determine if a user can be authenticated based on the credentials provided. TACACS was developed in the early 1980s and has since mostly been replaced by the use of TACACS+ and RADIUS. TACACS, historically, used UDP for transport and operated on port 49. TACACS is a fairly simple and straightforward protocol, with a client sending a username and password to a TACACS server and getting either an accept or deny response back to the request. This request could be either a login or an authentication request. Cisco Systems eventually updated TACACS to a proprietary protocol they called XTACACS.
NOTE TACACS was developed by engineers at BBN Technologies, the company responsible for building the ARPANET, and BBN continued to work on developing and maintaining it over the years.
TACACS+ is considered an improvement on TACACS and XTACACS and was developed by Cisco Systems as a replacement protocol for the earlier two protocols. While the name is similar, it takes leaps forward because it is effectively its own protocol and is not backward compatible with the older protocols. A draft of the protocol was submitted to the IETF in 1997, though it never became an RFC or an IETF standard. In spite of that, TACACS+ is commonly used, particularly in networks with Cisco routers or switches in order to provide authentication services. Since Cisco has long been the predominant vendor for routing equipment to network service providers, TACACS+ has been implemented across the Internet in various degrees.
According to the TACACS+ draft, TACACS+ differs from TACACS by providing separate processes for authentication, authorization, and accounting, all of which can exist on separate servers. TACACS+ also uses TCP for reliable delivery, whereas the original TACACS protocol used UDP, as noted earlier. TACACS+ does listen to TCP port 49, which is the port previously assigned to TACACS in both the UDP and TCP protocols.
EXAM TIP TACACS is an older protocol, specified in RFC 927, while TACACS+ is the newer protocol, and includes authorization and access control in addition to the original authentication process. Both protocols use port 49, but TACACS is UDP, while TACACS+ is TCP.
TACACS+ messages may be encrypted, which is an upgrade in security over the older protocol. TACACS+ can carry authentication protocols such as the Password Authentication Protocol (PAP), the Challenge-Handshake Authentication Protocol (CHAP), and Microsoft’s version of CHAP, MS-CHAP. PAP allows for the transmission of cleartext username and password while CHAP and MS-CHAP use an MD5 hash of the credentials and a challenge in place of the cleartext credentials. This protects the user’s information during transmission of the authentication request.
Web-Based Authentication
So much of our lives takes place on the Web today. Whether it’s social interaction via Facebook or Twitter or our financial life at our bank or broker, many people conduct a large portion of their lives online. The original technologies that made the Web possible didn’t really have authentication in mind when they were developed. Because of this, we have had to implement authentication mechanisms into websites. This has provided some challenges, and these challenges have several potential solutions.
There are different authentication solutions for web applications, and some of them provide better security than others. The first is basic authentication, which allows the web server and client to negotiate the authentication. Digest authentication also has the server and client managing the authentication. Forms-based authentication is handled within the web application itself, relying on the logic of the web program to take care of authentication.
Basic Authentication
Basic authentication is handled within the context of the interaction between the web server and the client and is part of the Hypertext Transfer Protocol (HTTP). Authentication is handled within standard HTTP headers. When a client browses to a page requiring authentication, as specified by a mechanism on the server such as an access file within the server directory where the content is, the server generates a WWW-Authenticate header. The WWW-Authenticate header will be within the context of an error status like 401 Unauthorized, indicating that the client needs to be authenticated in order to gain access to the requested resource or page. The WWW-Authenticate header contains the realm that the user will authenticate against. The client then creates an authentication request by concatenating the user and password and inserting a colon (:) in between them. If the username were ric and the password were P4ssw0rd, for example, the authentication request would be ric:P4ssw0rd. Before transmitting this value to the server, however, the string is Base64 encoded. The following header would then be sent back to the server: Authorization: Basic cmljOlA0c3N3MHJk==, where cmljOlA0c3N3MHJk is the value of the username:password string after being Base64 encoded. Figure 4-9 provides an example of HTTP headers including the basic authentication request from a 401 Unauthorized message.
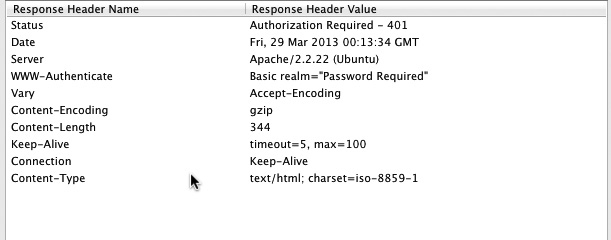
Figure 4-9 HTTP headers from a basic authentication request
When the server receives the Authorization header, it decodes the username:password string and then compares the username and password against values stored on the server to determine if the user can be authenticated. The problem with this mechanism, of course, is that it’s not any better than sending the credentials in plaintext since Base64 decoders are easy to come by and the Authentication header indicates very clearly that the authentication value has just been Base64 encoded and not otherwise encrypted or protected. Because of this limitation, the use of basic authentication is not recommended in any case other than very limited situations on private networks or where the data is otherwise forced to be encrypted.
Digest Authentication
Digest authentication also uses the HTTP protocol headers to pass the required information, but the information is better protected. In the case of a digest authentication, a server would reply with an error status like 401 Unauthorized, indicating that the user has to be authenticated in order to visit the page being requested. Additionally, the server provides a realm to authenticate against, just like in basic authentication. In the case of digest authentication, however, the server provides a nonce, which is just a random value generated by the server. This nonce is used to prevent replay attacks against the server, since every authentication request should include a different, random value for the nonce. When the client replies, it replies with a single hash value that has been generated from two separate hashes and the nonce. The first hash is generated from a concatenation of the username, the realm, and the password. The second hash is generated from the method (e.g., GET or POST) as well as the page requested, which is known as the request URI (Uniform Resource Identifier). Finally, the third hash is generated by concatenating the first hash, the nonce, and the second hash and then computing a cryptographic hash value from that string. Figure 4-10 shows headers from a 401 Unauthorized message, including the nonce.

Figure 4-10 HTTP headers from a digest authentication request
Figure 4-11 shows a dialog box indicating that the user needs to be authorized before getting access to the requested page. Once the user enters values into the username and password fields, the request is sent to the server with an Authorization header. When the server receives the Authorization header, it will include the username, the realm, the nonce, the URI, and the response, which is the third hash value. The server will also generate a hash in the same manner as the client did and compare the value it gets to the response value sent in by the client. If the values match, the user is authenticated and the requested resource is presented to the user. Otherwise, the user is not authenticated and an error response is sent back to the user.

Figure 4-11 A dialog box requesting authentication
While the username is passed in the clear, the password is not. The username must be passed to the server in order for the server to know what user to look up and generate a hash value for. Without that data, the server would have to compute a value for all the users in the list of authorized users and that would just delay the response in addition to generating an unnecessary load on the server. Since the server generates a random nonce for each request, you can’t have a list of pre-computed hashes sitting around to compare a response to. The response must be computed each time since it contains the randomly generated nonce.
Since the username is passed in the clear as part of the HTTP headers, this can provide an attacker with a list of usernames if the attacker can listen to the communication with the server over a long period of time. Because this is a potential risk, any time there are users being authenticated, it’s a good idea to ensure the messages are being encrypted between the server and the client.
Forms-Based Authentication
Unlike basic and digest authentication, forms-based authentication doesn’t make use of the HTTP headers to pass authentication information back and forth. This doesn’t mean that HTTP headers aren’t used at all, however. Since HTTP is a stateless protocol, meaning every request to a server is considered standalone with no concept of connection state, most web applications need a way to ensure that users remain authenticated across multiple requests to the server rather than having to authenticate each request that gets made. Because of this state requirement, it was necessary to develop a way of tracking that state, and so cookies were created as a way of maintaining information across multiple requests or sessions between a client and a server. The cookies are maintained on the user’s computer and managed by the browser.
The authentication itself, as well as the means of passing the authentication credentials to the server, is entirely up to the application. It is called forms-based authentication because, rather than having the browser itself handle it by popping up a login dialog box, the web page has a form embedded in it requesting a username and password or other forms of credentials. Once the credentials have been collected, it’s up to the web page and the underlying application code to determine if credentials are sent in a GET or a POST request, if they are encrypted or hashed in any way, and if they are sent as part of a query string within the URL or are sent as parameters with the headers. Figure 4-12 shows an example of how a forms-based authentication page would be handled in PHP. You can see the script pulling the values out of the form and then rendering them into a SQL query. The results of the query and whether it’s successful will determine whether the login succeeds. There is a potential issue with the statement checking whether the query resulted in a success since it never verifies that the username in the result matches the username in the query. This could potentially open the door to a SQL injection attack, which would allow unauthorized access.
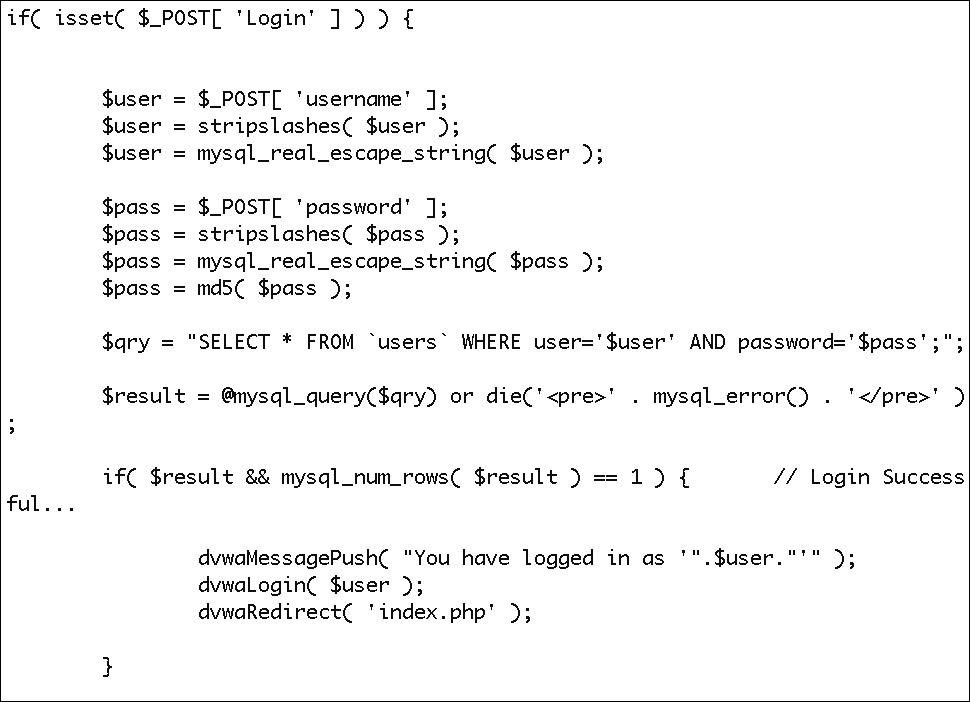
Figure 4-12 Forms-based login in PHP
NOTE Input validation is one of the biggest challenges for web developers in particular since a lack of input validation is often the cause of cross-site scripting (XSS), SQL injection, and command injection attacks.
Typically, forms-based authentication would make use of a database to store the authentication credentials, though that’s certainly not a requirement. Using a database to store credentials, however, does lead to the risk of other attacks against the web infrastructure, such as SQL injections where the internals of the database may be used to gain unauthorized access or, perhaps worse, expose sensitive data from the database. Flaws in the program logic cause this vulnerability. This would be different from the other types of web-based authentication that don’t rely on program logic and don’t provide direct access to the data the application is storing.
Multifactor Authentication
Multifactor authentication is where multiple authentication mechanisms are used to grant access to a user. You may have seen this when interacting with your bank’s website. Financial institutions, perhaps not surprisingly, have been some of the first to adopt stronger authentication mechanisms. In the case of your bank, you may have been asked to log in with a password and then asked a personal question that you would have established when you enrolled for access to the web interface. These are two instances of the “something you know” factor. Truly multifactor is when you are using two different factors, so you may be sent a message to your phone to take in the something you have factor. When you access your bank account through their automated-teller machine (ATM), you use two different factors—something you have (your bank card) and something you know (PIN).
Using a token and a PIN is two-factor—something you have and something you know. Adding biometrics to that using something like a fingerprint scanner will give you three-factor. In the case of the Android facial recognition backstopped by either a PIN or some other authentication mechanism, we are not talking about multifactor authentication. Multifactor is using multiple factors in the same authentication attempt. When one authentication attempt fails and you try another one, that’s two different attempts at single-factor authentication and not multifactor.
Authorization
While authentication is proving that you are who you say you are, authorization is ensuring that you have the appropriate rights and permissions to access a particular resource. Authorization is tied inextricably with authentication, since in order to authorize someone to perform a particular action, you should first ensure they are who they say they are. Authorization is a process that commonly follows authentication. Once your credentials have been validated, the system can determine whether you have authorization to get access to the resource you have requested. Authorization can be very fine-grained. You may have perfectly acceptable credentials that you present to a login function, but you just don’t have the rights to make use of a system in a particular way. As an example, you may be authenticated and authorized to log in to a system when you are sitting directly in front of it, but while your credentials are the same, you may not be authorized to log in remotely to the very same system. I may authorize you to read one file on my system but not authorize you to read another file. You may be able to write to one of those files but only read from another one without being able to write to it.
You may have noticed in the earlier discussion of the authentication protocols, such as RADIUS and TACACS+, that authorization was part of the discussion. Again, this is because we like to segment our infrastructure and our data. Just because you have valid credentials to log in to a system or network doesn’t mean you get complete access to and control over all aspects of a system or a network.
Principle of Least Privilege
In information security, there is a principle of least privilege that states you should only be allowed to access exactly what you need in order to perform your job functions. You shouldn’t get access to anything above what you need since that comes with the risk that you may make use of the excessive privilege in a way that may compromise resources in some way. Your credentials may also be used to gain access to those excess privileges in a malicious way, should someone else get your credentials. Least privilege is a good principle to live by to best protect systems and other resources.
EXAM TIP The Unix/Linux utility sudo is an example of the principle of least privilege because you have to be authenticated and authorized to perform higher-level functions using sudo than those granted to your user. sudo will determine what specific functions you are permitted to perform, but only when run through the sudo command.
While this principle has been used to varying degrees on Unix-like operating systems for years, it’s a more recent development on Windows systems. It’s easier for developers to simply expect to have system privileges in the services they may be developing than to specifically determine the privileges they need and have a user created with those specific privileges so the service can run in the restricted context of that user. Many system services operate with system privileges when they may not need to. Additionally, starting with Windows Vista, Microsoft implemented User Account Control (UAC), which required users to run in a context of least privilege. If additional privileges were required for a specific application, the screen would change and the user would be prompted about this elevation of privileges.
The challenge with this approach is that it could be turned off easily, meaning you would no longer be required to accept the risk that comes with elevated privileges. This is similar to simply logging on with full administrative privileges, which was the case previously with Windows operating systems, and is the case with Unix-like operating systems that allow someone to log in directly to root. In a Unix-like operating system like Linux, root is the administrative user. When someone logs in directly to the administrator account, no matter what the operating system, the principle of least privilege is violated and opens the door to potential damage to the system.
Accounting
Accounting is all the paperwork associated with system and user management. It keeps track of who has logged in, for how long, what they have accessed, and so on. This typically takes the form of logs on the system, from which you can derive a lot of information. Accounting provides the ability to determine who did what and when they did it. This is helpful in the case of attacks against a system or in the case of a misconfiguration of a resource. The logs will provide details about when the misconfiguration may have taken place and who may have done it. Obviously, the who depends on how authentication is done, since weak authentication can be broken and allow malicious users access to systems they shouldn’t have access to because they have stolen the credentials of a legitimate user.

TIP Phone systems, including VoIP systems and cell phone networks, use accounting to determine usage and billing. You may see this accounting detail on your billing statement. These are often called call detail records.
Accounting is also useful for providing details to enable billing for resources by tracking usage. You may also want to have details of system and resource utilization for trending and analysis. In addition, keeping track of capacity to determine when resources may need to be augmented, upgraded, or replaced is a good idea.
Figure 4-13 shows a list of the last users to log in to a Linux system. This list is generated from the wtmp log that is stored on Unix-like operating systems. This list of users helps narrow down who was logged in to a particular system at a particular time and from when. You can see in the third column where the user has logged in from. This is the hostname that the login originated from over the network.

Figure 4-13 The last users to log in
EXAM TIP The utmp and wtmp files store the login information on Unix-like operating systems.
Access Control
Access control is tied up with all of the other concepts we’ve discussed so far—authentication, authorization, and accounting. Without knowing who is attempting to access a resource or what their permissions are, we can’t make determinations about whether that access is allowed or not. Access control is about the whole process of determining what you have the rights and privileges to do on a system once you have been authenticated. Access control, in this sense, is very similar to authorization except that there are specific types of access control that different systems implement. Those different types of access control are Discretionary Access Control, Mandatory Access Control, Role-Based Access Control, and Attribute-Based Access Control.
Discretionary Access Control
Discretionary Access Control (DAC) allows the users to have the discretion to set access control rules on objects that they own. There is no overriding policy that sets the rules on what the controls on access should be. This is why it’s called discretionary, because access controls can be set at the discretion of the user and not by the will of the security policies that govern the organization. This sounds good on the face of it. Surely the users should have the ability to determine who can get access to their files and data?
EXAM TIP Windows Access Control Lists is an example of Discretionary Access Control, as is using the User, Group, and World permissions set in Unix-derived operating systems.
The biggest challenge with DAC is that typical users don’t have the appropriate amount of knowledge about threats and risks to be able to make appropriate decisions about who has what level of access. Users may simply add Everyone as being able to read and write to simply not have to worry about either setting up a group and providing access to the group or adding each user individually. There are administrative challenges associated with putting access controls on every directory or file within the control of each user. This then relies on the defaults of the operating system in question to set appropriate levels of permissions. Having to set reasonable access controls on every directory or file because the defaults are unreasonable or lacking in sanity is too cumbersome to expect every user to perform those functions. This can leave the system and its data resources exposed to inappropriate or even unauthorized access.
In addition to being able to set permissions on files and folders, an owner may pass ownership permissions off to another user. Once that’s done, the other user can set permissions and the original owner no longer has that ability unless the operating system supports having multiple owners.
Figure 4-14 shows a list of permissions on a directory on a Windows 7 system. Note at the bottom of the window the different permissions that are available, from full control to read-only. This set of permissions provides very fine granularity on a Windows system, as you can see. In addition to read and write, there are also execute privileges, as well as the ability to list file contents. Directories may have slightly different needs for permissions than a file.
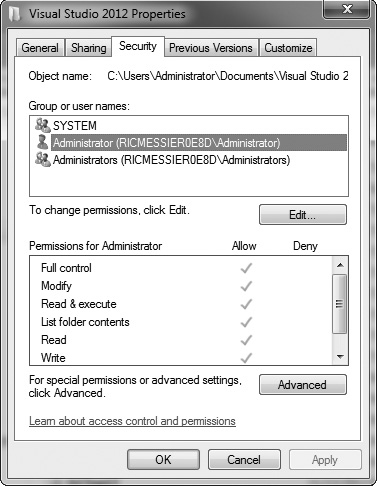
Figure 4-14 List of permissions on a directory
In a discretionary model, the users are responsible for maintaining the security of resources on the system. The entire overhead in this case rests on the user to set and maintain the correct permissions on documents they create. This is very different from Mandatory Access Control, discussed next, where the classification and security settings are far more centralized and controlled.
EXAM TIP List-Based Access Control associates a list of users and their permissions with a particular object. For example, a file would have an access control list of all of the users and groups that have access to that file, as well as the level of access they have.
Mandatory Access Control
Mandatory Access Control (MAC) is a very strict way of controlling access to resources, and it’s the type of access control typically implemented by governmental or military agencies. With MAC, access to a particular resource is determined by how that resource is categorized and classified. You would be allowed access if you had the same classification and the same category. This type of access control is based very strongly around security policy and data classification. Because it’s based around policies, it requires a lot of work on the front end to establish the policies and rules that determine levels of access.
As an example, a document may be classified Secret and belong to the Operations group. If you have Secret clearance and also belong to the Operations group, you would be able to access that particular document. If you have Secret clearance but don’t belong to the Operations group, you wouldn’t get access. Both sets of criteria have to match in order to allow a particular user to access a particular resource. It’s Mandatory Access Control because there is no way around it. The policies dictate access levels, and users have no ability to make changes, so from a user’s perspective, the access control is mandatory and can’t be altered to allow another user to access the file, even if the creator of the document would like a colleague to be able to see it.
There are challenges to Mandatory Access Control. The biggest one is the amount of overhead required to implement it. In addition to the work upfront that is required to establish rules for classification, there is the work to maintain the classification and labeling of documents. In this sort of model, you can’t have documents that don’t have labels and classifications. All documents must have labels and classifications in order to allow them to be accessed, based on the classification and categories a user falls into.
Role-Based Access Control
Role-Based Access Control (RBAC) may be the easiest access control model to figure out based solely on the name. In an RBAC deployment, users are assigned roles and rights, and permissions are assigned to those roles. You can think of these roles as groups, as they exist in both the Windows and the Unix worlds. Access privileges are not assigned to individual users in an RBAC deployment. All rights and permissions are assigned to the roles that users are then assigned to. This makes sense in an environment where users move around or leave on a regular basis. Where there is a lot of change, it can increase access creep, where users that no longer belong to a particular group may retain access if they haven’t actually left the organization as a whole. Users who have been around a long time may retain rights and privileges from several previous positions, which may not be appropriate.
With Role-Based Access Control, you have to be assigned a role and then authorized for that role, which simply means that someone with the proper authority ensures that you correctly belong to that role.
When you assign access control based on role, you can add users to individual roles and then remove users from those roles when they have moved on. It makes management of access policies much easier because you are making changes to the role rather than to a lot of individual objects. Where you are assigning individual rights, it can be difficult to find all the documents and resources that a user has access to if they remain in the organization. Obviously, if they leave the organization, their user account should be deleted, at which point all the rights and permissions they have would be removed. It’s because of the efficiency of granting and removing rights that the RBAC strategy is very often in use in larger organizations; managing rights based on the roles or groups that a user belongs to is far easier and has less overhead than doing it individually or on an ad hoc basis.
RBAC doesn’t preclude the use of MAC or DAC. You may implement RBAC and still have DAC, giving the individual users the ability to control who has access to the resources they own. In the case of MAC, you can still use RBAC by assigning individuals to roles and then ensuring that the roles meet certain criteria before access is granted to a particular resource. You can think about it as a hierarchy where RBAC sits on top of either MAC or DAC to provide access to system or network resources.
RBAC also applies to specific applications. As an example, Microsoft SQL Server, Oracle’s database management system, and PostgreSQL all provide the ability to assign rights to roles. In this case, you can provide granular access to individual tables or databases based on roles. You may have a large database where each table may have rights granted to different roles.
Attribute-Based Access Control
Attribute-Based Access Control (ABAC) requires that the user prove specific attributes. Rights are granted based on those specific attributes rather than on the identity and authentication of the user. An example of this would be allowing individuals to buy alcohol only after they have provided proof that they are at or above the legal drinking age. In the United States, individuals are required to prove that they possess the attribute of being at least 21 years old. Another example, more specific to a computer-based model, is proving that you are 18 years old in order to gain access to gambling or pornography websites. Once you have sufficiently proven that you have that specific attribute, or any other attribute required, you would be granted access to the resource in question. Another example is wanting to go on a particular ride at the fair or at an amusement park and needing to demonstrate that you are above a particular height.
TIP Attribute-Based Access Control may have legal ramifications, as in the case of alcohol or access to gambling. It’s worth knowing the legalities before implementing any ABAC system.
The challenge to this particular model is ensuring valid proof of the attribute in a timely fashion. As noted earlier, you may be required to prove that you are above a specific age before being granted access to a particular website. Often, this is done by having a user enter a birth date prior to being granted access. Facebook and Hotmail used this particular technique when they had a minimum age requirement. All you had to do was enter the right birth year and you were granted access regardless of your actual age. Really good mechanisms to prove specific attributes in a computerized, anonymous environment don’t exist currently.
Single Sign-On
Single sign-on (SSO) is a way of managing a user’s access to multiple systems and resources without requiring the user to log in for each individual system. There are several advantages to this approach. The first advantage is the obvious reduction in time spent typing in passwords. This can be a big time savings for users when they have to access a number of systems and resources during the course of the day. On top of that, different systems may have different password requirements, and those passwords may end up being different, which would require a user to have multiple passwords. When you expect a user to keep track of multiple passwords to multiple systems, each with potentially different password requirements, you again run the risk of the user needing to write those passwords down in order to be able to remember all of them.
A single sign-on solution requires a central authentication server to manage not only the authentication from a login but also the continued access based on additional authentication requests to further resources. Windows systems can use single sign-on using Active Directory and a Kerberos-based ticketing system (discussed in the next section). Any system within the Windows network would make use of the centralized authentication system to authenticate users, after which they could be authorized to access a particular resource. This might include file shares, printers, or SharePoint sites. Additionally, Internet Information Services (IIS) can make use of Windows Authentication, which is a simple way of referring to the various mechanisms that go into authenticating users on a Windows network.
A big risk that comes with single sign-on is that if an attacker can get access to a system using something like malware embedded in an e-mail message, they can gain access to all the resources on the network without ever having to authenticate again. Considering the number of applications that can and are willing to cache credentials, this particular risk may be a wash. If you have cached all of your credentials by asking the system to remember you when you gain access to a file share or a website, then any malicious user who had access to your system could still gain access to all of the systems you have access to. The only way to protect against this particular threat is to not use single sign-on and to never cache credentials. This seems unlikely to happen. The reason is people really don’t like typing passwords over and over and they don’t recognize the risk to other systems or infrastructure from caching their credentials so they don’t have to type them again.
Kerberos
Kerberos came out of Project Athena at MIT. Athena was a project founded in 1983, designed to create a distributed computing environment. In addition to Kerberos, X Window System came out of the work done in Project Athena, and the project influenced the work of a lot of other protocols and applications. Kerberos is a way of performing network authentication. Kerberos will also help with a single sign-on solution because it has a central authentication server that all systems on the network can make use of to validate the credentials of any user attempting to access a resource. Figure 4-15 shows how systems interact with the Kerberos system.

Figure 4-15 A Kerberos system exchange
Kerberos uses tickets to accomplish this. When a user logs in to a system on the network, the system contacts the Kerberos Authentication Server (AS). The AS gets a Ticket Granting Ticket (TGT) from the Key Distribution Center (KDC) and sends it back to the user’s system. This TGT has been time-stamped and encrypted. The TGT is what a system uses to gain access to other systems. This only works, though, if the system the user is trying to gain access to uses the same Kerberos infrastructure. If a user wants to get access to a particular resource, the user’s system will send its request and TGT to the Ticket Granting Service (TGS), which typically lives on the same system as the KDC. After the TGS has validated the TGT and ensured that the user has access rights to the resource in question, it will issue a ticket and session keys to the user’s system, which then sends them off to the resource system along with a service request. Assuming the system hosting the resource is using all of the same Kerberos infrastructure, it should allow the resource request to proceed.
There are some downsides to using Kerberos, however. As with any centralized model, you create a single point of failure. If the Kerberos server goes down or is otherwise taken offline, no one can authenticate to anything and the network effectively becomes useless. As a result, the Kerberos server and infrastructure need to be highly available and reliable.
Also, because of the timestamps that Kerberos uses, all of the systems on the network need to use the same time source. If there is variation, users may have problems authenticating. This can be fixed by ensuring that systems sync their clocks to a Network Time Protocol (NTP) server. Assuming there isn’t too much drift on the local system clocks, this should keep everyone well within the parameters that Kerberos requires.
Another issue is that gaining access to the Kerberos server could end up giving a malicious user access to any resource they want access to. It may also allow the malicious user to impersonate any user.
These risks may be considered acceptable in light of the upside of having centralized user management and reducing the need for users to have to keep track of multiple passwords, especially since those passwords may not all be subject to the same password requirements.
Chapter Review
Access control covers three areas that are highly significant: authentication, authorization, and accounting. All three are very important in protecting systems and resources. There are a number of ways to authenticate users, though requiring a username and password combination is the most common. Another popular method is the use of tokens, such as badges or swipe cards. In addition to that, there are biometric systems that authenticate based on physical characteristics by using voiceprint, iris and retina scans, or fingerprint scans. Adding additional authentication factors, called multifactor authentication, can improve reliability of authentication, although you should ensure that you are using mechanisms that are reliable, which can sometimes be challenging with biometric factors. The different factors that you would use fall into four categories: something you have, something you know, something you are, or somewhere you are.
Beyond authentication, users may then be authorized to access particular resources. Authorization has to follow authentication so you can know who you are authorizing. Authorization may be handled by using a single sign-on solution like Kerberos. Kerberos has been implemented into Windows Active Directory. Single sign-on does have benefits, including protecting against users writing down passwords. It also has downsides, including providing a malicious user access to an entire network once they have gained access to one system, although cached credentials can offer the same risk.
Questions
1. Microsoft Windows file security permissions are an example of what?
A. MDAC
B. RBAC
C. DAC
D. ABAC
2. RSA SecurID tokens provide what?
A. Reusable passwords
B. Security
C. Usernames
D. One-time passwords
3. Kerberos tickets allow users to do what?
A. Not have to retype passwords
B. Give other users permissions on the fly
C. Get a time check
D. Change passwords
4. What is the principle of least privilege implemented in?
A. Windows Explorer
B. Apache Web server
C. The sudo utility
D. RADIUS
5. Authentication is the process of doing what?
A. Gaining access to critical resources
B. Logging information about access
C. Providing access to resources for users
D. Proving you are who you say you are
6. Your bank is letting you know they are going to implement a token-based solution for authentication. You will be sent your token and you will need to establish a PIN. What type of authentication will the bank be implementing?
A. Digest-based authentication
B. Basic authentication
C. Multifactor authentication
D. SQL authentication
7. Network devices and dialup users may be authenticated using which of the following protocols?
A. RADIUS
B. Forms-based authentication
C. Windows authentication
D. Discretionary Access Control
8. Adding an additional alphanumeric character to the required length of a password will multiply the potential passwords by how many?
A. 26
B. 32
C. 52
D. 62
9. What can John the Ripper be used for?
A. Authenticating against Windows networks
B. Cracking Windows passwords
C. Authenticating against Linux systems
D. Encoding a Windows password before transmitting over a network
10. Which of the following can be used to authenticate someone?
A. An iris pattern
B. Weight and height
C. A nose print
D. Ear size
11. What is a significant problem with the use of basic authentication for web pages?
A. It uses the MD5 hash.
B. It uses Base64.
C. It uses compression.
D. It uses SHA-1.
12. What do you use the principle of least privilege for?
A. Authentication
B. Authorization
C. Access control
D. Biometrics
13. Why would you implement accounting?
A. Verify access
B. Verify usernames
C. Verify Kerberos tickets
D. Verify forms
14. What is the biggest problem with LANMAN passwords?
A. Weak hash algorithm
B. Inadequate access control
C. Weak implementation of Kerberos
D. Seven-byte hashes
Answers
1. C. While Windows does support RBAC, Windows uses Discretionary Access Control, where the user determines who has the rights to files and folders under their control.
2. D. A SecurID token, as with other token-based authentication mechanisms, rotates an access number on a regular basis. The username has to be provided by the user. Security is a very vague word. In this case, if a token is stolen and the PIN is known, anyone can get authorized as the user of the token.
3. A. Kerberos tickets allow users to not have to re-type passwords since Kerberos is often a component of a single sign-on solution. While time is an important component of Kerberos solutions, you wouldn’t get a time check from a Kerberos token. Kerberos tickets are exchanged under the hood, so users certainly wouldn’t use a ticket to provide another user permission for access. Finally, passwords are changed using another mechanism.
4. C. While Windows Explorer and the Apache Web server may have the principle of least privilege implemented in them somewhere, and RADIUS could help implement the principle of least privilege, it’s the sudo utility that really implements it by expecting users to have to use sudo to gain additional privileges.
5. D. Authentication is about proving you are who you say you are. Authorization gives users access to resources once they have been authenticated, and accounting logs the access to resources.
6. C. Since the token is something you have and the PIN is something you know, this would be multifactor authentication. Basic authentication and digest authentication make use of the browser to request authentication credentials and then pass the credentials back either hashed or Base64 encoded. It’s not SQL authentication because you are logging in to a website, not into a database.
7. A. RADIUS is the protocol that would be used to authenticate users on network devices as well as dialup users. Forms-based authentication is used with websites, and Windows authentication is how Windows users authenticate. Discretionary Access Control isn’t an authentication protocol.
8. D. Lowercase and uppercase letters give you 52 potential characters (26 letters in both upper- and lowercase). Adding in 10 single-digit numbers gives you a total of 62 potential characters.
9. B. Among other things, John the Ripper can crack Windows passwords. It’s not a tool for authentication. It’s a tool for password cracking.
10. A. While weight and height can be used to help identify someone, an iris pattern is the only one in that list that can be used to uniquely identify and authenticate someone.
11. B. Base64 is easily decoded. There is no hashing or encryption involved.
12. C. The principle of least privilege is a way of implementing access control. By default, users are only provided access to the minimum amount of resources they need to do their jobs.
13. A. Accounting will give you details about who is doing what on your systems, and when they are doing it, enabling you to verify access in case something goes wrong.
14. D. LAN Manager broke longer passwords into seven-byte chunks. Rather than hashing the entire password, there are two hashes. If the password is not long enough to fill the entire 14 characters, the password is padded to fill out the entire 14 characters.
Exercise 4-1 Answer
There are 52 upper- and lowercase letters, and 20 numbers and symbols, so that’s 72 potential characters. If we were to just do a 16-character password, it would be 72^16. That’s 5.2 × 10^29 potential passwords.