
CHAPTER 9
Risk Management
In this chapter, you will learn:
• Critical controls
• Security policy
• IT risk management
Risk management encompasses an enormous amount of what we do as security professionals. Actually, risk management comes with just the act of living your life. Every day you make decisions based on evaluating risk, whether it’s deciding if the milk for your cereal has spoiled or determining if you can make it through the traffic light before it changes and a car comes through from another direction. Whereas many people have to make some level of risk assessment in their jobs on a daily basis, a security professional spends his or her life engaged in constant risk assessment in order to determine what they can or should be doing to manage risk. In general, people don’t logically or rationally evaluate risk, as demonstrated by several studies by Amos Tversky and Daniel Kahneman. An organization’s information security risk management must be based on sound and repeatable practices; otherwise, the organization is making poorly informed decisions.
Risk management can become a very complicated activity, and it is a critical part of an entire life cycle of security program management. Many factors feed into a risk assessment, including a variety of regulations that may apply to your organization. There is a difference between doing a risk assessment based on business requirements and the vision and strategy of the business and just focusing on compliance with regulations. A business solely focused on compliance isn’t factoring the larger picture of risk associated with information assets and resources.

NOTE Risk is often misunderstood. When people say risk, they often mean chance or sometimes threat. Risk and chance are not synonymous. Probability is only one aspect of risk.
Once you have performed your risk assessment activities, you can then go about doing all the work of writing policies and implementing processes and procedures to handle incidents. One component of a risk assessment should always be the possibility of a disaster, whether it’s a natural disaster or a manmade one. Knowing how to effectively respond in a situation that is unfolding very quickly can help control the situation and ensure that your organization has a better shot at getting back on its feet quickly and efficiently. Having clearly defined processes in this area will remove a lot of the uncertainty in an unplanned event or situation.
Regulatory and Compliance
One risk that needs to be taken into consideration is that of complying with regulations that may impact your business. If you don’t comply with regulations, you could be assessed fines or you may potentially lose customers. Of course, the regulations are also there to protect you and your customers or clients, so ensuring that you are in compliance is generally a good idea anyway, but it’s also true that not being in compliance with industry guidance or regulations can be damaging to your business. Said another way, it’s clear that there are risks that these regulations and guidelines are attempting to protect against, but there is also a risk in not complying. Depending on it activities, an organization may need to comply with multiple regulations and standards. Here are some widely applicable regulations you may be familiar with:
• SOX The Sarbanes-Oxley Act of 2002 was passed to protect investors from egregious accounting irregularities like those seen in the early 2000s (Enron’s, for example). The act is considerable in scope, consisting of 11 titles. While it primarily concerns both financial and auditing accountability, it also involves records and recordkeeping, and how public companies behave.
• PCI DSS The Payment Card Industry Data Security Standard is a set of requirements regulating how credit card data is used, stored, and transmitted. The PCI is an organization of payment card companies like Visa, MasterCard, and American Express. The industry organization expects everyone who handles their cards and card data to be in compliance with these standards. The standards surround secure networking, protecting cardholder information, performing vulnerability management, and implementing strong access control mechanisms, among other measures. The current version as of this writing is 3.2.1, and it’s expected that all organizations who handle card data be in compliance and that all assessments be done against version 3.2.1. An assessment is a check to make sure all of the controls outlined in the standards are in place.
• HIPAA The Health Insurance Portability and Accountability Act was passed into law in 1996 and, among other things, required the establishment of national standards to protect electronic health care transactions and records. HIPAA defines protected health information (PHI) and specifies how that information needs to be protected.
• FISMA The Federal Information Security Management Act was passed in 2002 and requires federal agencies to develop, document, and implement information security policies, practices, and infrastructure to protect the information the agency is responsible for. This act was amended by the Cybersecurity Act of 2012. FISMA 2014 provided an update to FISMA itself.
• GLBA The Gramm-Leach-Bliley Act was passed in 1999 and is named for the three legislators who co-sponsored the legislation: Sen. Phil Gramm, Rep. Jim Leach, and Rep. Thomas Bliley. Among many other things, the act required financial institutions to develop safeguards to protect information provided by, and belonging to, their clients. It also required that these financial institutions perform a risk analysis on every department that handles the non-public information of their clients.
• FFIEC The Federal Financial Institutions Examination Council is responsible for developing principles and standards for the examination of financial institutions in accordance with the Federal Institutions Regulatory and Interest Rate Control Act (FIRIRCA) of 1978, as well as the Federal Institutions Reform, Recovery, and Enforcement Act of 1989.
• GDPR The General Data Protection Regulation was passed in 2016 but implemented in 2018. Even though it was passed by the European Union (EU), it impacts companies around the world because any company who may have customers who live in the EU has to comply with the GDPR. It provides regulations for protecting information of consumers that may be stored or handled by a data processor or a data controller.
GDPR is starting to have impact outside of Europe. Most of the regulations and compliance requirements mentioned above are US-based. GDPR is not, though there are some states like California that are developing their own privacy laws. While every country in the world has their own judicial system and ways of applying laws and punishments, there are two common legal systems: common law and civil law. Common law is based on precedents set through legal rulings by judges or courts, and is founded upon the idea that it is unfair to apply different standards to different cases. Civil law, on the other hand, is based on statutes that have been passed by legislative bodies, or on regulations that have been issued by the executive branch. Both types of legal systems can have an impact on your organization’s operations and risk assessment.

EXAM TIP Common law and civil law are the two most prevalent legal systems in the world.
In addition to the laws and regulations that might impact your organization’s business policies, there are other laws you should be aware of. A number of countries have laws that cover the business use of computers. One of these is the Computer Fraud and Abuse Act of 1986, which was amended several times, including in 1996 by the National Information Infrastructure Act, and in 2002 by the USA PATRIOT Act. These laws protect against the unauthorized use of a computer—meaning, the use of a computer without the permission to do so. It’s also illegal to perform acts using a computer that may cause damage to another computer system. This includes the creation and use of worms and viruses.
The Digital Millennium Copyright Act (DMCA) was created to protect against copyright violations in digital media like music or video. The DMCA was passed in 1998 as part of the implementation of two treaties by the World Intellectual Property Organization (WIPO). In it, the DMCA prohibits removing the copyright protection from digital works. Online service providers can be effectively exempt from this law, assuming they comply with a set of requirements such as blocking access to or removing material that infringes on copyrights.
NOTE A Russian programmer named Dmitry Sklyarov wrote a program for ElcomSoft that purportedly circumvented the copyright protections in Adobe’s e-book format. Sklyarov was in Las Vegas in 2001 to give a presentation to the Def Con security convention. When he attempted to leave, he was arrested and detained by the FBI. A jury trial later found ElcomSoft not guilty of the four charges filed against them under the DMCA. This case highlights some of the challenges of copyright law on the global Internet. Sklyarov was just an employee of a company developing software that wasn’t illegal in the country it was developed in. While Adobe initially supported Sklyarov’s arrest, they later called for his release after a meeting with the Electronic Frontier Foundation. The U.S. Department of Justice, however, declined to drop charges against Sklyarov.
While the United States and other countries have a number of laws relating to computers and security, perhaps the strictest laws are found in Germany. In 2007, Section 202c of the Strafgesetzbuch (German for penal code) took effect, outlawing the preparation of an act of data espionage or data interception. This has been highly controversial because it effectively makes it illegal to be in possession of a number of critical tools for a networking professional as well as security professionals. You may be able to argue against the possession of hacking tools involved in performing penetration tests, but preventing networking professionals from accessing tools like tcpdump or Wireshark, which are both data interception tools, makes performing their jobs much harder.
Not only different countries but also different states and localities might have their own sets of laws and regulations regarding what is illegal use of a computer or telecommunications gear. Because of this, it’s worth doing due diligence to see what laws and regulations may impact your organization to ensure that your policies cover whatever the laws and regulations may require of your organization, including the possibility that you may be required to provide information to a government entity should a breach of security occur.
Risk Management
Before we go any further, we should talk about what risk actually is, even though it seems like a fairly straightforward concept. Risk is the degree to which something may be negatively impacted by an event or circumstance that may happen. You can think of risk as the intersection between probability and loss. You can’t have risk without loss but loss on its own is just loss. You need to be able to determine a probability of an event incurring that loss. You may hear different terms when people discuss risk. One of them is impact, which is the same as loss, though it encompasses a broader range than just monetary loss, though loss isn’t only about monetary issues anyway. The other is likelihood, which is the same as probability. These terms may be interchangeable when you see risk assessments and see the two dimensions of risk described.
As mentioned at the beginning of this chapter, we encounter risk on a daily basis and make decisions based on that, often without even realizing it. When we step out of the house and take a walk down the street, there is a risk we could get hit by a car. Going outside incurs a risk, over the longer term, of skin cancer. Risk management is how you define the risk and what you do to protect yourself from it. In the case of going outside, you may put on a hat or wear sunscreen to protect yourself. That mitigates the risk of sun exposure, though it doesn’t completely remove it. However, by putting the hat or sunscreen on, you have managed the risk to a degree.
Managing risk seems like it should be a simple job. You see a risk and either you take action to remove that risk or you take action to reduce it and accept the residual risk. You might even accept the entire risk without any mitigation. Sounds pretty easy, right? With limited resources, how do you determine how to prioritize which risks to mitigate and how to mitigate them? Also, how do you manage the limited resources you have to mitigate those risks? Many things need to be taken into consideration when engaging in a risk management activity. Before you can do much in the way of writing policies or implementing a security program, you should always go through a risk identification activity to determine how you will manage risks. Otherwise, you are just shooting blindly, hoping what you do reduces the risks.
Governance is an important concept in risk management. At some point, someone is responsible for an organization, whether it’s the owner, the executive management, or the board of directors. Governance is a set of actions taken by those responsible for the business to provide strategic direction and ensure that what the business does falls in that strategic direction to make sure business goals are met. The business owner also must manage risk in order to protect the business and make sure the business’s resources are used appropriately. Providing strong risk management across the organization demonstrates effective management by those responsible for the business. Governance is not something that should be hands-off or entirely delegated. Only those responsible for the organization can set the strategic direction and know what risks are of most concern to the business. Without the goals and strategic direction provided by the business owner, it’s very difficult to succeed at managing risk.
In larger organizations, especially ones that are publicly traded companies, governance is the responsibility of the executives of the company and the board of directors. They should be providing strategic guidance that should be implemented throughout the organization.
The National Institute of Standards and Technology (NIST) has publications available that outline what risk management is and how to assess risk. According to NIST, processes involved in risk management include framing risk, assessing risk, monitoring risk, and responding to risk. Each of those can feed into the other, which creates a continuous cycle of managing risk for an organization. A number of activities can cause risk to an organization, from simply hiring people to determining where a business should be located and the potential for natural disasters there, not to mention changes to processes within your organization, the applications installed, operating systems in use, the way your building is constructed, and many other issues that create risk. An example of a cycle of risk management can be seen in Figure 9-1, which is from NIST Special Publication (SP) 800-30 Rev. 1, Guide for Conducting Risk Assessments.

Figure 9-1 The risk management cycle
NIST has several publications related to risk and risk management. The following are two others you should consider reviewing:
• Draft SP 800-37 Rev. 2, Risk Management Framework for Information Systems and Organizations NIST’s RMF addresses not only risk and the risk management cycle, but also important security controls that could be used to manage risk.
• Draft SP 800-37 Rev. 2, Risk Management Framework for Information Systems and Organizations Describes the application of the NIST RMF for federal systems. This does not mean, though, that you have to be working with federal systems in order to make use of this document. If you are unfamiliar with risk management and applying a framework, this would be a good document to review.
The various steps in a risk management process or strategy are often tightly coupled. Notice in Figure 9-1 that inside the triangle outlining the simple process is a piece called “Frame.” Framing a risk is identifying it and assessing its impact and likelihood. This allows you to fully understand what the risk is, as well as its priority. Framing a risk can also identify ways of mitigating it and the costs associated with mitigation. Once you have a cost determination, you can start to determine whether it’s worth it to you to even look at mitigating the risk or whether you should just leave it alone and accept it the way it is. Some risks cost more to mitigate than the costs that may be incurred if they were triggered. Once you have performed an assessment and framed the risks, you can determine how you are going to control them. The control should be monitored and reviewed regularly to ensure nothing has changed—either the level of risk has increased or the control needs to be adjusted based on new information. This review loops back up to assessment since changes to systems or processes may introduce new risk that can be identified during the control review.
Risk often can’t be completely removed or mitigated, which is why we have controls to monitor the risk and ensure that it doesn’t rise to an unacceptable level. Sometimes, though, you just have to accept the risk the way it is. For example, suppose you want to offer a new web service to your customers. You already have web services you are offering, so you have accepted the risk of opening ports 80 and 443 through your firewall. You are using a standard OS image, so the risk to the underlying system is the same as what you already have in place. The difference between this application and the other applications you are offering is that this is written using the Java platform and a particular framework your developers have only limited familiarity with. Although you have experienced Java developers, the framework they are using for this particular service is reasonably new. Nevertheless, it still offers the best path to delivering the service on time and within budget. Without the framework, you will need more time and potentially more money in order to get the service written. You decide to deploy a web application firewall in front of this new service in order to mitigate as much risk to the application as you can. Even then, there may be new attacks against Java or this framework that the firewall can’t control. Since this is a big opportunity for your company, management decides to simply accept the risk that the application creates.
According to the International Organization for Standardization (ISO), a risk management process should have the following characteristics:
• It should create value.
• It should be an integral part of the organization’s processes.
• It should be part of the decision-making process.
• It should explicitly address uncertainty and assumptions.
• It should be systemic and structured.
• It should be based on the best available information.
• It should be tailorable.
• It should take human factors into account.
• It should be transparent and inclusive.
• It should be dynamic, iterative and responsive to change.
• It should be capable of continual improvement and enhancement.
• It should be reassessed either continually or periodically.
As you can see from that list, ISO strongly hints at a life cycle for risk management where the process constantly cycles around, and is deeply ingrained in, the business processes and decisions of an organization. This is the best way to ensure that issues are addressed from a holistic standpoint where risk and security are factored into decisions, or at least risks are identified. Building a risk management life cycle into your business processes can help you make plans and decisions that will improve your security and yet have less impact on your system over the long run.
A risk management process requires information about the risks. We’ll talk about how to assess these risks later in this chapter, but before that, let’s touch on some pieces of information that are critical to have. Pulling all of this information together is called risk modeling because you are creating a picture of what the risk looks like, how it may unfold, and the impact it will have if it does. First, you need to have an idea of the threat or vulnerability you are looking at. A threat is something with the potential to negatively impact an organization and its resources, whether physical, financial, or human. A vulnerability is a weakness in a system. The system includes any processes and procedures used to manage and control that system.
Once you have the threat or vulnerability identified, there are two pieces of information you need. The first is the impact that the threat or vulnerability would have on your organization if it were triggered and caused a significant incident. This could be a material impact, but it could also be something less tangible. One example, though there are several very similar to it, is the attack on the PlayStation Network where usernames and passwords were compromised after a group breached the infrastructure. This may not have had a specific material impact on Sony, although they should probably have spent some time and money working to better secure their infrastructure, but it did have a reputational impact on them. Whether this translated into a loss of customers and revenue is much harder to determine.
The last piece of information necessary is the probability or likelihood of a vulnerability being exploited. This piece of information will provide some weight to your analysis and reveal the possible scope of an event’s impact. You may have a threat with a possibly significant impact to your organization but a very low likelihood of occurrence. The lower likelihood may reduce the priority of mitigating that threat. Perhaps there is a risk that your founder and CEO may be shot and killed in the building. This is a possible threat, and the impact could be very high, but with the likelihood of its occurrence hopefully being very low, you may choose not to spend any money on protections like a full-time bodyguard for your CEO.
There is generally a level of uncertainty when it comes to managing risk, often because there is a limit to the amount of information you can have. In the preceding example, you can’t predict what your CEO may say and thus offend the wrong group of people, causing them to overreact. This is a fairly ridiculous example, but it does highlight the point that there is information you just don’t know and circumstances you just can’t predict. You may also have dependencies you missed, which can cause a ripple effect if something happens to one of those dependencies. Uncertainty can also come from a lack of knowledge about the threats that exist. Ultimately, some amount of uncertainty will remain in any risk assessment.
There are a couple of different ways to manage risk, which we’ll cover later in the chapter. The first is quantitative risk management, which takes into account the numbers associated. The other is qualitative risk management, which is more subjective and takes the quality of something into consideration.
Cost-Benefit Analysis
As it turns out, there is some math that can help with the risk management process. A cost-benefit analysis (CBA) can be used, with the idea in mind that “there ain’t no such thing as a free lunch” (TANSTAAFL). Everything costs something, even if that cost is time. A CBA helps us weigh the costs against the benefits and thus make better decisions. In addition to helping determine whether a particular decision is wise, when you get a value out of a CBA, you can weigh that against alternatives to determine whether one is quantitatively better than another. From this, you create a standard against which to base your decisions.
NOTE Jules Dupuit was a French economist credited with devising the cost-benefit analysis in a paper in 1848. He also supervised the construction of the Paris sewer system.
One of the challenges is determining how to effectively measure all of the inputs in the analysis. The idea of a CBA is to provide some concrete information from which to make a decision. If all of the information you have is something like “customers will be impacted” or “it will take a lot of time to do this,” then you don’t have real data to create an accurate analysis from. Getting accurate information to create the CBA can be challenging, but in the long run you end up with a much more informed decision. Rather than simply saying that customers will be impacted, for example, you would need to determine in what ways they might be impacted, and whether customers will leave and go to your competitors. The amount of time it will take to develop a solution to an issue should also be measured in terms of the cost in man-hours. This should be done using a rough estimate of the amount of time it would take, multiplied by an average hourly cost for labor. Everything, with a little bit of work, can have a value.
After the genesis of the CBA idea in 1848, it eventually became U.S. government policy to perform a CBA before undertaking any work. In the early 1900s, a number of projects went through a CBA before getting underway, including the idea of damming the Colorado River in Nevada to create a reservoir and generate power. Hoover Dam, shown in Figure 9-2 during its construction, cost $49 million in 1930s dollars, which was a considerable amount of money, but it was determined that the benefits of building the dam far outweighed the cost of construction.

Figure 9-2 The Hoover Dam under construction
Values can change over time, and so time needs to be taken into consideration also. There is the time value of money. A dollar invested today will likely be worth more than a dollar in five years’ time. This is one of the factors that had to be taken into consideration by those planning the construction of the Hoover Dam. It took five years to build and the cost of a dollar in the initial days of the project would be worth more (theoretically) when the dam was completed. This has to be factored into calculations, because if the dollar was invested or simply left to sit, its value would rise in comparison to its value at the inception of the project, and you would have gained money. Does the benefit of implementing the project outweigh not only the initial cost, but also the cost of the money that could have been made during the time of the project? Granted, most projects an enterprise embarks on don’t take nearly as long as building the Hoover Dam, but the value of money over time should still be calculated. The future value can be calculated as follows: FV = PV / (1 + i)n, where FV is the future value, PV is the present value, i is the interest rate to compound the value over a number of periods, and n is the number of periods over which to perform the calculation.
Exercise 9-1: The Future Value of Money
You are presently considering a project that will cost $10M up front and take two years to complete. The interest rate is 0.25 percent per month. What will be the future value of that money when the project is complete?
Of course, the values you assign to the costs and benefits will likely be estimates since you can’t be certain of changes that may happen before the plan is implemented. As a result, a CBA is only as accurate as the estimates used to feed it. The more experience you have with particular projects, the better you can make estimates, because you will have actual data and experience from which to draw up your estimates.
Quantitative Risk Assessment
Quantitative risk assessment factors in only numbers that can be used to provide some specific context to an event. Quantitative assessment feeds nicely into a cost-benefit analysis because you have specific numbers that you can input into your CBA. Some other calculations that may be used in a quantitative risk assessment are single loss expectancy (SLE), which is a weighted value of how much monetary loss there would be in the case of an asset being impacted by a threat and subsequently lost. SLE is calculated by multiplying the value of the asset (AV) by the exposure factor (EF). The exposure factor is the percentage of the asset that may be lost in case of an event.
NOTE The exposure factor is often a subjective value, possibly based on uncertain data.
Once you have a single loss expectancy, you can calculate the annualized loss expectancy (ALE). This is calculated simply by multiplying the SLE by the annual rate of occurrence (ARO), which is expressed as the number of times a year an event is expected to occur. If you have an SLE of $10,000, meaning you expect to lose $10,000 each time a particular event happens—for example, losing power to your facility (after deciding not to install a generator)—and you expect this to happen four times a year, the annualized loss expectancy is $40,000. This is how much you expect to lose each year to power outages.
Using the quantitative approach, you would also calculate the return on investment (ROI). This can be done by assessing the costs and the gain. The ROI is calculated as follows: ROI = (gain – expenditure) / expenditure × 100 percent. Once you have the ROI for any set of investment opportunities, you can determine which investment makes the most financial sense. When you are performing a quantitative risk assessment, you would calculate the ROI on the various options you have available to you and then determine which one makes the most sense financially. A decision based on this doesn’t factor in the event’s severity or likelihood, only the ROI.
EXAM TIP Quantitative risk management takes only return on investment into account to determine what risks to prioritize. ROI is calculated as (gain – expenditure) / expenditure × 100 percent.
Qualitative Risk Assessment
Qualitative risk assessment is more about how you feel about the risk than it is about the factual data associated with decisions. This is unlike a quantitative risk assessment where only hard numbers are taken into consideration. A qualitative risk assessment may use data that isn’t very hard because some factors are very difficult to measure and put a specific number to. A qualitative risk assessment takes into account the fact that there is a lot of uncertainty in doing risk assessments. While there are a lot of hard figures that can be used, there are a lot of soft numbers as well that go into calculating costs.
One of those figures that is hard to calculate is the cost in terms of human resources. Obviously, if people are spending a lot of overtime responding to a particular event and they are getting paid for that overtime, it is much easier to track the cost of that. The reality is that you are paying for your people to show up to work regardless of whether they are tackling the impact from a threat materializing or not. If they are working on the response to a threat, they are not doing other work, so there is some cost associated with putting off their other work. Can you easily calculate that? Perhaps, but more often than not, figuring the amount of loss in terms of time is a fuzzy calculation. This is where qualitative risk assessments can provide value. You may not have a specific number you can easily point to from calculations derived from hard data, but you may have a sense of how much it costs you in lost productivity in day-to-day matters because people were pulled off-task to work on an incident response.
A qualitative risk assessment may be used in combination with a quantitative approach because they are not mutually exclusive. There are places where you will have a lot of data that can be used, and other cases where you will only have words like low, medium, and high to determine things like impact or likelihood. You may not have a specific dollar value you can cite, but you know it will be high impact because of the amount of man-hours required to resolve the issue. Similarly, you may not be able to put a hard dollar value on the customer impact, but you may have a sense it will be a medium impact. Some people will say that reputational concerns fit in here, though it’s not clear whether those are realistic when it comes to impact and loss. Numerous studies have shown there is very little damage to large brands, especially over time. Consumers often either don’t understand what happened or assume that it happens to everyone and don’t penalize the companies with reduced commerce.
Risk Management Strategies
An important risk management concept to consider is risk appetite. Risk management can be somewhat subjective. Different organizations may approach the same risk in different ways. This is because they have different appetites for risk. Some organizations are willing to make the bet that an incident that would incur loss to the organization won’t occur. Some organizations may also calculate loss differently than others. For example, one organization may think that a significant data breach could cause a lot of damage to their reputation, resulting in a loss of customers, while another organization may either not consider reputational damage or determine they won’t lose customers even if a data breach were to happen. Every organization needs to understand what their risk appetite or risk tolerance is.
Once you have identified the risks and performed your assessments to determine priorities, you have several options. The first one is simply to avoid the risk altogether. You could avoid a risk by not engaging in the activity that might cause it. Not all activities or projects need to be done, and if there is significant risk, you may simply choose not to do them. This can be very effective, but it’s not always practical because an activity or project probably wasn’t proposed unless it was determined to be necessary or at least desirable.
If you choose to go forward, your next strategy may be to reduce the risk. This can take many forms. An example of a common risk reduction strategy is to install sprinkler systems in your facility. The threat is fire. The impact is the destruction of critical information, systems, and resources, as well as the potential danger to people. While the likelihood of a fire may commonly be low in most instances, it is still a very significant threat that needs to be addressed. Sprinkler systems reduce the risk by limiting the damage the fire can cause. They will, however, create their own damage, and so other fire suppression means may be more desirable in some circumstances.
Another example of a common risk reduction strategy is to perform testing on software being developed in-house. The threat is not only to the company’s reputation for releasing poor quality software, but also potentially to its customers, who can incur a liability to the company in the way of lawsuits and reduced sales. Because of this, you would want to ensure that the software you develop for customers, either for their use or purchase, has been tested so as to remove as many bugs as possible.
You might also choose to share a risk with another party. This may be done by contracting with an insurance company to insure your company against loss or damage as a result of a particular threat occurring. This is sometimes called risk transference, but in reality you haven’t transferred the risk since you are still being impacted by it. You are simply getting someone else to help you with a particular risk. When you outsource or migrate data or services to a cloud-computing provider, you are also sharing risk. You are removing some of the direct risk to you and your organization and sharing it with the outsourcing or service provider. That doesn’t entirely remove the risk to your organization. If you are using a service provider and they are storing a lot of information about your customers and they get breached, you are still responsible to your customers, although your service provider shares the responsibility with you.
On the other end of this spectrum is acceptance. You can simply choose to accept a risk as it is. This may be a result of determining that the cost of reducing the risk is too high compared to the cost of it actualizing. Risk acceptance is an understanding of the impact of a threat being actualized and the decision to take on that risk. Risk acceptance shouldn’t be confused, however, with a lack of understanding of a risk. If management doesn’t completely understand a risk because it hasn’t been documented or explained well enough and chooses to go forward anyway, that’s not the same as risk acceptance, because they haven’t truly accepted the risk.
NOTE Similar to saying that not knowing a law isn’t a defense against breaking it, not understanding the actual costs and impact of a threat being actualized and then choosing to go forward isn’t the same as risk acceptance. In order to accept a risk, you must understand what that risk is. It is up to security professionals to clearly communicate the risk to management so that informed decisions can be made.
Security Policies
A security policy is a document indicating the intentions of an organization regarding the security and integrity of its systems and resources. A security policy is essential to a well-thought-out approach to the security of an organization, because it documents the way the organization wants to approach security. It not only specifies the approach to appropriate ways of using computer systems but may also specify deterrents or punishments for inappropriate uses. Most importantly, a security policy, as with any policy, is a statement of management’s commitment to the specifics of the policy. Policies within an organization must be provided top-down, with the full support of an organization’s leadership. Without that, the policy has no chance of being followed because it’s not backed by management and the business, and is instead just some ideas some group wrote down. There are a number of policies that may be relevant to an organization, all of them falling under the heading of security policies. Some of those policies may fall under the following categories:
• Access control An access control policy may specify physical security aspects of how people gain access to a facility. For example, this policy may specify the use of biometrics or badge access, and determine how badges are handed out. An access control policy may also specify information about usernames and passwords in order to provide users with access to the network and its resources. It may put in place additional measures like smartcards or token access to systems.
• Incident response Companies are increasingly concerned with how to respond to incidents. This means they need to identify who is responsible for responding to and managing incidents. The incident response policy should identify responsible parties and also which organizations are responsible parties in the case of an incident.
• Business continuity/disaster recovery Organizations must address how to remain operational if something catastrophic were to happen. This could be something related to a breach that causes outages or it could be something kinetic like a hurricane, flood, or other natural disaster. A business continuity/disaster recovery policy provides guidance for how critical business functions need to be handled to ensure the organization remains operational.
• Information protection This policy specifies who should get access to sensitive information. It should also determine how sensitive information should be stored and transmitted. While you should always be thinking about the ramifications of what this policy stipulates, much of it may be dictated by regulations or industry guidelines. PCI DSS, for example, specifies how organizations should handle sensitive information like credit card data, and these guidelines will provide a lot of detail as to what this policy may look like for that type of information.
• Remote access policy A remote access policy determines who may have access to your network and computer systems remotely. Whereas this used to specify dial-up access, currently it’s more likely to address virtual private network (VPN) access or possibly access to a virtual desktop infrastructure (VDI). This policy may designate the types of users who can get remote access, as well as the hours during which they are allowed access. There may also be details about the types of systems that can get access. While you may be allowed to use your home computer, there may be requirements for a personal firewall and anti-virus program before you can gain access to the internal network.
• Acceptable use policy An acceptable use policy indicates the types of activities considered permissible on the company network. It may also specify the types of activities that are not acceptable.
• User account policy A user account policy specifies who can have a user account on systems, and classifies the different types of systems and the requirements that must be met to get a user account. For example, depending on the type of data your organization has stored on a system, the user account policy may have a citizenship requirement. A user account policy also specifies whether shared or role-based accounts are acceptable. The policy may also cite password requirements, including aging and complexity requirements. A user account policy may also specify background checks to ensure access to a network.
• Network security policy A network security policy might be a very complex document specifying rules on how to access the network, including the types of systems that are permitted and the prerequisites for a system being attached to the network, like anti-virus software and updated patching. It may also outline data access rules, as well as information flow and classification. It might specify the details surrounding web browsing, including what is acceptable and what is not, and whether browsing will be filtered or not filtered.
NOTE Background checks are common when hiring employees, but circumstances can change, and while an employee may have had a clean background when hired, over time they might have become too much of a risk to continue being given access to sensitive information. As a result, revisiting background checks on a periodic basis may not be a bad idea.
These are just some of the policies that may fall into an organization’s policy library. The policy library may be extensive and very detailed, or it may be small and very high level, depending on the needs of the organization. Not all organizations have the personnel in place to create and manage a large library, nor do all organizations actually need a large library of policies. There aren’t specific rules surrounding these policies that everyone has to follow, though certainly there are regulations that will suggest the need for particular policies. The important thing to keep in mind is that the policy is how the organization defines its approach to security. Without a policy, processes and procedures in use within an organization don’t have any guidance, and as a result, they may end up conflicting with one another. Of course, this can happen even when there are policies, if an organization isn’t good about communicating the existence of those policies and the need to adhere to them.
When you are ready to start pulling your policies together into something coherent, you may use a policy framework. A policy framework will provide an overarching set of standards and requirements for creating new policies, as well as present an organizational structure for pulling all of your policies together. Your policy framework may have a set of core principles that you use to not only define the remainder of the policies you will be developing, but also to guide how the policies you create will be structured and written.
Data at Rest
A lot of attention is focused on securing data in transit. As a result, data at rest is often overlooked. Data at rest is simply data that is sitting on a disk somewhere not being used. While some types of sensitive data are often treated appropriately, like passwords and encrypted data, that’s not always the case. Often, access control mechanisms are used to protect data at rest, assuming that this restricts who has access to data. The problem with relying on access control is that once a user has access to data, they can copy it or manipulate it in a number of ways. There have been a large number of cases over the past few decades where data has gone missing because it was stored on a laptop or some external media. The laptop or media was lost or stolen, causing a major cleanup effort. An online search will turn up a number of news stories. One story is about an incident in 2013 where a laptop was lost with data on it. While this event happened outside the United States, there have been a large number of instances here where data was copied to a laptop and then the laptop was taken out of the facility, only to be lost or stolen.
This is a case where policies are inadequate, even in instances where the policy covers the issue. User education of the policy and appropriate practices is critical in protecting data. The easiest way to incur a data breach is to have a user take data out of the facility where it is no longer under the care and administration of your IT and security teams. One of the problems is that it has become ridiculously easy to move data around without any way of tracking it. Figure 9-3 shows a USB stick capable of storing 4GB of data on it. This is equivalent to roughly six CDs or about one single-sided DVD. You can easily and cheaply find USB sticks that are capable of storing 16 times that and yet are the same size as the one in the figure. This particular USB stick is roughly the length of an average man’s finger, from the tip to the second knuckle, and not much wider. You can also find storage devices that have more capacity and that are significantly smaller. It has been suggested that Edward Snowden used devices like this to remove data from the NSA. Without technical controls to prevent the use of the USB ports on your system, there is little to prevent this sort of thing from happening. In cases where someone is okay with explicitly violating a policy or even accidentally violating a policy, there should be a technical control to prevent this or to at least detect it so it can be addressed.

Figure 9-3 A USB stick/drive
Even though there are numerous risks to data, there are ways to protect it when it’s at rest. The first way is to ensure that all sensitive data is encrypted. Your database should be encrypted, either at the database or table level, so if a database is copied off the drive where it is stored, it would still be encrypted and prove useless without the right keys to unlock it. Of course, not all data is stored in databases, so volume-level encryption on your hard drives is critical. Laptops today commonly have Trusted Platform Module (TPM) chips that are capable of easily enabling encryption on the entire hard drive, as well as securely storing the keys. Laptops specifically should have their hard drives encrypted to ensure that if the laptop is lost or stolen, there is no way to get access to the data on it.
As noted, USB sticks can easily store large amounts of data, so if possible, disabling access to USB ports on systems can help prevent the removal of sensitive information this way. However, USB sticks are really just part of the problem when it comes to data loss and theft. Even in the face of USB sticks, cloud storage is becoming a very easy way to copy data out of an organization for use somewhere else. While this may be done for entirely legitimate uses, there is the chance that the storage account may be breached, leading to a loss of data.
This brings us back to how to appropriately handle data at rest. Data at rest, if it is sensitive in nature (a data classification policy can help make this determination), should be encrypted and the keys protected. Having the data encrypted with the keys stored unprotected on the same system where the data is provides no additional security over having the data in plaintext on a hard drive. Ensuring that you have file, table, and database encryption on all sensitive data will help protect your sensitive information even in cases where it is copied off of your network onto another device. In cases of rogue or malicious actors that have access to the keys, you may have a hard time protecting against data loss or theft. This is where periodic background checks and appropriate monitoring and auditing will help.
There are several ways you can protect your data at rest, depending on the operating system you have. Microsoft includes an Encrypting File System (EFS) in Windows NT–based versions of Windows. This allows users to encrypt individual files or folders without encrypting the entire volume. BitLocker, however, provides volume-level encryption and is available on versions of ultimate and enterprise Windows since Windows Vista. BitLocker not only provides volume encryption but also makes use of the Trusted Platform Module (TPM) chip on systems to store keys. BitLocker can also be configured to store recovery keys within the Active Directory to allow for data retrieval when keys are lost or an employee with the information has left the organization. Other operating systems provide the means to encrypt volumes. With Mac OS, you can use FileVault. Linux supports Linux Unified Key Setup (LUKS), which can be used to create encrypted volumes. There are also third-party solutions like TrueCrypt or BestCrypt that can be used to provide encryption. You can also use PGP/GPG to encrypt individual files.
NOTE Data in motion is another important concept and one that is covered in regulations such as PCI DSS. Sensitive data should be encrypted using strong encryption while it is in motion. This is because the data could be intercepted by an attacker, even if it is only transiting networks within an organization. Anytime data passes out of a system onto a network, it should be considered to be available to be compromised.
Contingency Plans
A contingency plan is a way of handling unexpected events, and is critical in ensuring that business operations continue. Disaster recovery is an example of when a contingency plan is needed. A business continuity plan (BCP), on the other hand, is a bit more general than a disaster recovery plan since it has to ensure that business operations are restored to 100 percent efficiency. This may not mean that a business remains fully operational during an event, but a BCP should establish goals and steps to work toward resuming full operations. A BCP must take into account events other than disasters.
EXAM TIP A business continuity plan must not only define how an organization will restore 100 percent of its operations, but give it the ability to continue to meet defined goals.
Disaster Recovery
Disaster recovery planning is intended to address not only how you would keep the business going as best as possible in the case of a disaster, whether natural or manmade, but also how to fully restore operations. There are many details to consider when developing a disaster recovery plan, but typically three different sets of controls should be in place:
• Preventive controls Designed to ensure that something bad doesn’t happen.
• Detective controls Designed to identify when something bad does happen.
• Corrective controls Designed to assist in recovery efforts after disaster strikes.
When developing a disaster recovery plan, an assessment of the most important systems and data is critical since you’ll have to prioritize what to restore first. Saying “everything is important” isn’t helpful because it doesn’t enable you to determine where to start getting everything back up and running. Of course, in some cases, you may be able to simply move your operations to other facilities using standby or replication. That’s one way to ensure that you continue to stay open for business. Other strategies to consider are
• Backups Backups to tape or other external media that can be sent off-site are critical in ensuring you can get your systems back up and running. However, you may also consider local backups to external disks to have something you can run the systems from quickly in case you haven’t lost all operations locally.
• Replication Some systems may be replicated to other locations. This replication may be periodic or live depending on the needs your data has and how often it changes. Replication allows you to switch over to another system in case of failure in your primary location.
• Backup facilities You will likely need a place to run your operations out of if your facility is significantly impacted.
• Local mirrors This might be done via RAID to ensure a catastrophic loss of data doesn’t happen.
• Surge protectors These can help protect your systems against catastrophic failure.
• Uninterruptible power supply (UPS) A UPS can give you the opportunity to shut down your systems gracefully and transfer control to another system or location in the event of a power outage.
• Generator Should a power outage occur, a generator can help keep your systems operational for a period of time.
• Cloud facilities Cloud computing providers may allow you to quickly migrate your operations to their facilities and also provide you with the ability to store backups.
• Standby You may have hot or warm standby systems ready to take over operations. A hot standby is always ready with the most up-to-date data and applications. A warm standby may need something done to it, such as updating it with the most up-to-date data, before it is ready to fully take over operations. The system may be in place with all of the applications up and running; it just needs a backup restored to make it fully operational.
Assessing your priorities should offer some guidance on what strategies to use for your system. This is definitely not a one-size-fits-all activity. Not all of your systems will require replication or hot standbys. Doing a risk assessment to determine which systems are the most critical to your business should give you answers about which strategy to use for each system. Once you have your strategies in place, you should document them, as well as the processes for service restoration, as part of your disaster recovery plan.
Incident Handling
In addition to many other areas of computer security, NIST provides guidance on how to handle incidents. Before we go further, we need to talk briefly about what an incident is and the distinctions between an incident and an event. An event is an occurrence of something that can be seen through monitoring or observance on your network, either in the network itself or on one of the systems within the network. An event is neither good nor bad but simply something that happens. There are, however, adverse or negative events. Whereas events are just things that happen, an incident is a violation of a security policy or perhaps the threat that a violation is imminent.
Typically, an organization will have a policy for incident response that provides specific guidance as to what constitutes an incident, and the severity level of different incidents. Most importantly, as with any policy, it provides a statement of the commitment of management in how to categorize and handle incidents. Every organization has different needs and requirements when it comes to handling incidents, but generally an incident response policy includes a statement of intent and commitment on the part of management, as well as the purpose and scope of the policy. Additionally, it should define key terms, and possibly define roles and responsibilities during an incident response. This may include an outline of what an incident response team would look like, selected from roles within the organization. Also, the policy would specify how to measure success or failure.
Once you have the policy in place, indicating the intent, purpose, and scope of how your organization views incidents and wants to handle them, you can move on to the specifics of the plan. The plan should include the mission, senior management approval, details on how the incident response (IR) team should communicate with the rest of the organization, including providing regular reports to management about the progress, and metrics for determining the progress of the IR team in responding to the incident. Communication is a very important role for the team, and there may be requirements to communicate with external organizations in addition to providing updates internally. Figure 9-4 shows some of the different people and organizations the team may be responsible for communicating with when responding to an incident. This set of groups and people will typically vary from incident to incident, but the IR team will always be the communications hub, as shown in Figure 9-4. Since the IR team is handling the incident, they are the ones who know the current status and specifics about what is being done and what else needs to be done.
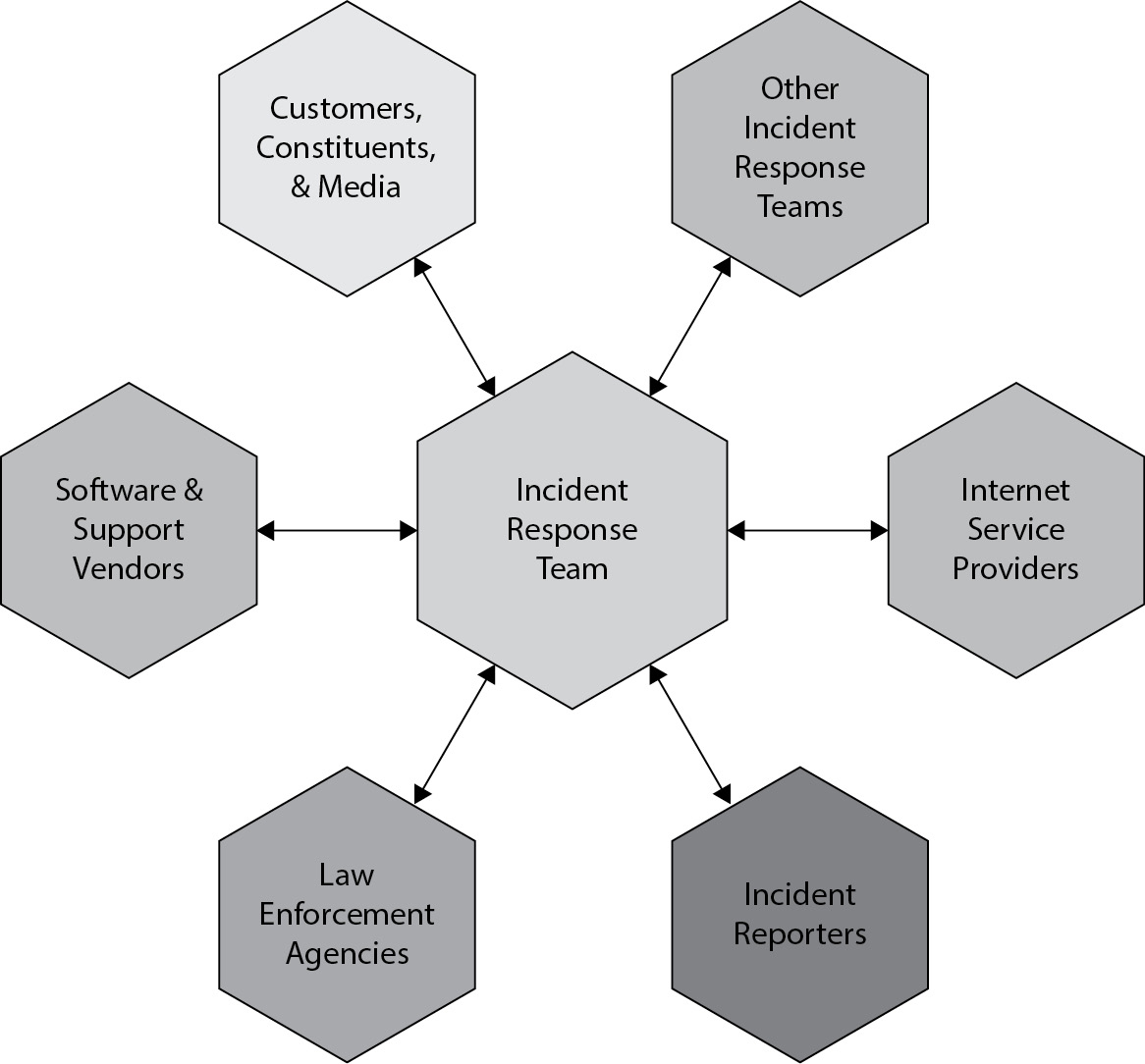
Figure 9-4 Communication with other organizations
Depending on the nature of the incident and the regulations or laws that may be applicable, you may want to, or be required to, communicate with law enforcement. A large-scale attack on your organization’s network requires communication with your Internet service provider. This not only is a necessity but is also highly desirable since the ISP can help mitigate the threat. Coordination with other teams can be very beneficial, including computer emergency response teams (CERTs) like US-CERT. While not always necessary and often undesirable, there will be times when you may have to communicate with the media as well. This should be done carefully to avoid compromising internal details about the response and the organization.
Rolling out from the plan, you may have specific sets of procedures that should be followed. Your IR plan may be very specific with regard to how to handle incidents that are well defined, or it could be generic in order to accommodate an incident that is difficult to foresee. These procedures should be well documented. As always, a solid set of documentation is helpful to avoid confusion, delay, and mistakes in the course of an incident response when the incident itself may be causing much confusion and stress.
Whether you have a set of specific response guidelines or a more generic approach to incident response, several steps should be followed when responding to an incident. The first is preparation. In developing a policy and related procedures, you have started down this path. You will want to have contact lists for IR team members, as well as on-call information for other groups within the organization that may need to be contacted in the midst of a response. You may also want to cite where a central point of coordination will be—something like a war room—as well as communication procedures and protocols.
Beyond developing a structure for how the response should be handled, how to communicate with the team, and how the team will communicate with others, documentation about the network, systems, applications, and expected traffic flows will be very helpful in providing the team with details on what to expect. This will save a considerable amount of time and prevent the team from having to quickly learn how to sift out and isolate the abnormal events from the normal ones.
Preventing incidents from happening is also highly desirable. While you may spend a lot of time developing policies and plans, you don’t really want to have to call the IR team to have them handle an incident unless it’s absolutely necessary. Once you have a violation that’s created an incident, you have something bad happening, but it’s much easier to simply keep that bad thing from happening to begin with. You can go a long way toward preventing incidents by performing risk assessments to determine threats that can be removed or mitigated. Once you have the risks identified, you can then implement appropriate and effective network and host security measures like firewalls, system hardening, intrusion detection, or virtual private networks. Additionally, malware protection like anti-virus and web proxies will be very helpful in preventing malware incidents. While all these technical measures are good, users need to be educated and trained in their appropriate and acceptable use, as well as in security awareness.
NOTE As shown clearly in the Mandiant report “APT1: Exposing One of China’s Cyber Espionage Units” describing the advanced persistent threats identified in a large number of U.S. corporations, the easiest way into an organization is by exploiting the human element by sending e-mail to employees and either directing them to infected websites or simply attaching malware to the message itself.
Detection can involve the use of intrusion detection systems, as well as extensive logging on systems and network elements. Firewalls may also provide detection capabilities. Having all of this data isn’t enough, however, since there needs to be some way of alerting someone to act on the information generated. This requires that someone be paying attention to alerts, either by watching screens or by having the systems generate e-mail or text alerts to operators who would then investigate the alert. Once the alert is generated, it should be analyzed to determine that it’s legitimate, and the scope and severity of the incident should be assessed. In addition to infrastructure monitoring, user education and awareness is also helpful. Users should be trained to identify and report unusual behavior on their systems that may be related to an incident. This may be an alert from their anti-virus installation or it could be unusual sluggishness in their system. It may also be aberrant behavior like applications refusing to launch or unusual windows popping up.
System and network profiling can help with analysis, but this should be done ahead of time to have a baseline to compare the current state against. You may also want to have a log retention policy. Having historical logs can be very helpful once an incident has been reported in order to go back and try to determine a starting point for the incident. Log data can also be helpful in tracking an incident in case it has been migrating from system to system. With a lot of log data from a number of different systems, you may want to have a system that is capable of correlating all that data. A security information and event management (SIEM) system can help with this by taking in log data from several different systems and performing an automated analysis of it.
A couple of other items that are very useful, but that may be overlooked, are to keep all clocks synchronized and to make use of a knowledge base. Clock drift will throw off details around a timeline of events, making things harder to track. While a second or two isn’t a very big deal, several minutes or more of clock drift can make it much harder to put together a sequence of events necessary in understanding what happened and what might happen next. A knowledge base can be very helpful in providing details about the system and network, as well as the details of previous incidents. Having an internal knowledge base can be important in speeding the resolution of the incident.
Once the incident is identified and prioritized, it needs to be contained and eradicated. There may be a lot of details here, depending on the nature of the incident. Some incidents may need to be handled differently because law enforcement may want evidence collected for use in a potential prosecution. You may also need to document the extent of the damage for both law enforcement and the company’s insurance. In the process of eradication, understanding the scope is important to ensure you have completely removed the cause of the incident. The scope would be obtained during the analysis, but you may find that you will get more information from trying to remove the cause of the incident. You should also be prepared to follow up on new information and leads, perhaps pointing to a larger problem than previously thought.
Finally, you should conduct a post-incident analysis, including documenting lessons learned. While lessons learned can be very valuable, they need to translate into process improvement to be effective. Simply documenting lessons learned and then letting the document sit for some future review isn’t very helpful. The outcome from a post-incident analysis should be details about how to improve processes and procedures in order to prevent similar incidents in the future.
SANS also provides guidance on incident handling, which is similar to the NIST guidelines. SANS outlines the steps as follows:
• Preparation Preparation involves creating policies and procedures defining how incidents are to be handled. You should also establish relationships with law enforcement, human resources, legal counsel, and system administrators, since they will be helpful in responding to the incident effectively. In addition, you should have a response kit prepared, including a response laptop, networking hardware like cables and switches, a call list of important numbers, evidence bags, and data storage like CDs/DVDs or USB sticks. You’ll also want to create an incident response team, perform threat modeling to determine the types of incidents you may need to respond to, and then practice your responses in order to be better prepared when an incident does happen.
• Identification In order to respond to an incident, you need to determine whether you actually have an incident or not. An event is something that can be observed within your network or organization. An incident is a negative or adverse event. Your determination of whether you have an incident is based on your policies defining an incident, as well as all of the facts that you can gather. Different people may have different opinions. Make your own judgment based on the facts rather than someone else’s opinion.
• Containment You will want to ensure that the incident doesn’t impact other systems. This may involve removing systems from the network if they are affected by malware intent on contaminating the remainder of the network. Once you have isolated the incident and kept it from spreading, make sure to gather any evidence needed for legal processing. Evidence may include the state of the running system, the contents of RAM, and any disks and information about running processes. There are specific rules regarding evidence collection, including maintaining a chain of custody. The chain of custody is a document indicating a comprehensive list of who has handled a particular piece of evidence, when it was entrusted to them, and what was done with it. In addition, evidence must be secured and not tampered with. If forensic analysis is necessary, it should be performed on a copy of the evidence and not on the evidence itself, if at all possible. This will maintain the veracity of the evidence.
• Eradication This stage is where you remove the cause of the incident, like finding the malware and getting rid of it. You should also perform an analysis to determine the source of the incident in order to know how to protect against it in the future.
• Recovery Once the source of the incident has been eradicated, the system can be put back into production.
• Lessons learned The lessons learned stage is perhaps the most important since it’s where you ensure you are implementing policy and process changes to help protect against this type of incident in the future. Your lessons learned can be informed by the results of the analysis done during the eradication stage.
EXAM TIP Steps in responding to incidents include preparation, identification, containment, eradication, recovery, and lessons learned.
Many organizations today have developed Computer Security Incident Response Teams (CSIRTs) to provide oversight and coordination when an incident occurs. Incidents may commonly begin as an event within the security operations center (SOC), which would do some triage and investigation to determine whether it can be ignored or whether it should be elevated to the level of an incident, which would need to be handled with a full investigation, including containment and eradication. Organizations will have different escalation paths, depending on the organizational structure.
The Legal Impact of Incidents
Incidents may require the involvement of law enforcement. Even if it’s not immediately obvious that law enforcement is necessary, you may want to involve them down the road. Because of this, you will want to follow appropriate evidence handling procedures from the very beginning to ensure that everything you do, and everything you collect, can be used in the case of a criminal proceeding. During the course of incident handling, you will acquire a lot of information regarding the incident, the people involved, and systems involved, including any information gathered from the systems. You may want an incident tracking database in which to store all of this information, because the more detailed the information, the better your case will be in legal proceedings.
Any information gathered must be secured against tampering, and only those directly involved in incident handling should have access to the incident database. This will limit the chances that the data can be manipulated in an inappropriate manner. A secure incident response database will provide a timeline of events that can be used in the case of prosecution.
Digital evidence is tricky because it is so easily manipulated. One way to ensure that you are presenting the original data is to make use of a cryptographic hash, providing a signature of what the data looks like. Once you have a signature and it has been verified by the evidence handler, you will need to record a chain of custody for all of the evidence, including the signatures for the digital evidence. The signature and the chain of custody together can provide evidence that what is being presented in court is the original information, or at least an accurate facsimile of it. Without securing the evidence and providing a chain of custody, anything you gather won’t be of value if you end up with a court case.
Information Warfare
The term information warfare has evolved over time. Information warfare can involve collecting information from an adversary, or perhaps providing misinformation to an adversary. It can also be more aggressive, including jamming signals to prevent information dissemination, or it can involve attacks against adversaries. A number of examples of this sort of information warfare have appeared in the past decade, including the release of Stuxnet and Duqu against efforts in Iran to generate nuclear capabilities, believed to be related to the development of nuclear weapons. This was a military action that involved nations, though there are certainly many cases of information warfare related to corporate activities as well. There have been many reports related to the Chinese initiating attacks against corporations around the world, collecting intellectual property and other corporate information thought to be used to improve businesses in China.
Information warfare is becoming far more of a threat to business than in the past, in part because of the use of computers to engage in these activities. Where previously you may have needed to get human elements involved, all you need now is a computer and someone with some skill in computer-related attacks like social engineering and malware. Hardening your systems and networks against attack is helpful, as is constant monitoring through an intrusion detection system (IDS) or SIEM system, but ultimately, the social avenue is proving to be the easiest way into organizations. This can be done through targeted e-mail messages that result in a system being compromised with malware. Once the malware is on a system, it can provide a way of remotely controlling the system and extracting any information that system and user has access to. Some organizations have had many terabytes of information extracted from their networks.
An awareness of these activities is certainly helpful in order to understand what the threat really is. Primarily, though, understand that this is a coordinated effort by determined actors, regardless of the source of the attacks. These are not random attacks by the cyber-equivalent of juvenile delinquents (“script kiddies”) trying to cause trouble. These are targeted, specific attacks. The determination should be the primary cause for concern because, unlike a door-rattling exercise, these types of attacks may continue until success is achieved by infiltrating your organization. The best defense against these types of attacks is vigilance.
You can also use disinformation as a way of practicing information warfare. The less accurate information your adversary receives, the less effective they can be. You may disseminate fake information either about what resources you have or about data you have available. We talked about honeypots in Chapter 5. These can be a terrific way of practicing disinformation. First, it’s not a real system. It’s a system that is posing as a real system that acts as both a lure and an information gathering point. You lure your attacker in by letting them think it’s an easy target, one that they can either gather information from or use as a jumping-off point to other systems in your network. Second, you may place false data on the system. You can do this with either something concrete like financial statements or engineering documents, or perhaps false data like SSH keys to systems that don’t exist.
This type of strategy could also be considered psychological warfare, which can be another important tactic. In the case of a honeypot, you eventually create doubt in the mind of your attacker about any system they attack on your network or any information they gather. You can also reduce the credibility of your attacker if they later pass off the information to someone or resell it, and it’s found out to be false. This strategy of doubt and turning adversaries against one another can be very helpful. It’s not going to take down an entire network of people stealing information, but spreading the seeds of uncertainty may help slow attacks down or simply frustrate attackers enough that they consider it a better use of their time to find another target somewhere else.
Defense, as noted earlier, is always critical in information warfare, but with the rise in attacks and with various nations’ involvement being known publicly, it’s possible that responding to attacks with other attacks may become a common strategy. It has long been considered unethical and potentially illegal to respond in kind to an attack or an infiltration. Attacks from all sides may become more commonplace before we achieve a cyber peace, so at least understanding the basics of attacking with social engineering and malware, covered in other places in this book, will be helpful. Those seem to be common attack methods at the moment, though denial-of-service attacks are also pretty common, and malware may require exploiting a vulnerability to succeed.
OPSEC
Operations security (OPSEC) is about protecting small pieces of information that could be pieced together to view the operations of an organization. While this is primarily a military concept, it applies well to information security as a whole. This may include restricting how e-mail is used, or an analysis of social networking activities that may divulge internal details of how an organization operates. This information may be useful to an adversary. While details of an organization, particularly one that is a public corporation, will have to be public, not all details need to be so, and protecting those details as much as possible is what OPSEC is about.
There are a lot of details about how an organization operates internally that can be discovered through careful searching and analysis. For example, if a company advertises a need for a network engineer with F5 and Juniper experience, an adversary knows or can guess that the company uses Juniper and F5 networking equipment. Job advertisements can be very lucrative sources of information about how an organization operates. Recruiting Windows administrators tells an adversary that your infrastructure is at least partially Windows-based. Indicating that the job applicant should have experience with Internet Information Services (IIS) provides details about the web server in use, thus narrowing the types of attacks that will work. This can substantially shorten the duration of an attack before it’s successful. There are a number of other repositories of information, including the systems themselves. Also, the Domain Name System (DNS) and domain name registries can provide details about internal contacts within an organization. Public organizations are also required to file documents with the Securities and Exchange Commission (SEC). This is done using the Electronic Data Gathering, Analysis, and Retrieval (EDGAR) system.
EXAM TIP EDGAR stores a lot of information regarding public corporations. This includes details about subsidiaries and their growth information, as well as debt information.
Ultimately, helping an adversary do its job should not be the work of you or your organization. The Operations Security Professional’s Association (OPSA) outlines a process for OPSEC, as follows:
• Identification of critical information Identifying critical information that could be of value to an adversary. Once you have identified critical information, you can proceed with the remainder of the process on that information.
• Analysis of threats Analyzing the threats in order to determine who likely adversaries may be. This is done by researching and analyzing intelligence, counterintelligence, and any other public information related to what you are trying to protect.
• Analysis of vulnerabilities This analysis focuses on anything that may potentially expose critical information to the adversary.
• Assessment of risk Once vulnerabilities have been identified, the risk from that vulnerability needs to be evaluated. Risks, once identified, can be managed and remediated.
• Application of appropriate OPSEC measures Appropriate measures should be taken to remediate the risk posed by the vulnerability.
Operations Security may come from how the military handles their engagements as much as it does from anywhere else. You can see a pamphlet about military OPSEC in Figure 9-5.

Figure 9-5 An Army pamphlet on OPSEC
Chapter Review
You may have noticed the number of instances where identification of risks is mentioned, including in the discussion of risk management, incident response, and OPSEC, just to name a few. One of the most important things you can do to help protect your organization is to perform a risk assessment and have an ongoing risk assessment strategy and process to ensure you are always up to date on the current state of risk within your organization. This will help your organization with a number of processes and decisions. Of course, how you end up performing the risk assessment will be up to you, whether it’s qualitative or quantitative or some combination of the two. In many cases, just listing the risks to the organization is an enormous improvement over the current state and is a big step in better protecting information and resources.
Having appropriate policies is helpful in ensuring that the organization has documented what it considers valuable and, perhaps more importantly, has management backing for these statements of intent. Once you have a set of policies, they can be used to guide further activities like development of processes and procedures and development of awareness training.
Risk assessments are also important when it comes to contingency planning, including preparing a disaster recovery plan. A risk assessment will help to prioritize systems that are critical to business operations so that, if they go down, efforts are immediately focused on getting them back up and running quickly. This can also manifest itself in having redundant systems or a hot standby in a separate location to replace these critical systems when needed. You should also take your critical systems into account when developing backup strategies to ensure you are not only backing up the systems but getting the backups off-site to a protected storage facility. Another consideration is having a set of local backups to work from while waiting for the backups to be recovered from the off-site facility.
Questions
1. You have determined that the SLE for one of your systems is $5000 and the ARO is 2. What is your ALE?
A. $5000
B. $10,000
C. $2500
D. $2000
2. Your organization needs to have a way to recover operations completely and also meet expectations for continued operations. What does your organization need?
A. A disaster recovery plan
B. Risk assessment
C. A business continuity plan
D. Management buy-in
3. What are Duqu and Stuxnet examples of?
A. Information warfare
B. Information assessment
C. Tactical warfare
D. Nuclear warfare
4. You have four possible strategies for mitigating a particular risk. Which of the following should you go with when using a quantitative risk assessment approach?
A. Expenditure: $100,000; Return: $95,000
B. Expenditure: $10,000; Return: $0
C. Expenditure: $250,000; Return: $275,000
D. Expenditure: $125,000; Return: $50,000
5. Which of these is not an example of where an adversary can gather useful information to use against your organization?
A. Job listings
B. SEC filings
C. Domain name registries
D. The Microsoft registry
6. What is the best way to protect data at rest?
A. Keep it moving.
B. Prevent it from moving.
C. Encrypt it.
D. Provide access controls.
7. Backups and replication are two strategies to consider for what activity?
A. Disaster recovery
B. Risk assessment
C. Information warfare
D. OPSEC
8. An effective risk management strategy can be which of these?
A. Risk assessment
B. Risk avoidance
C. Risk determination
D. Risk analysis
9. Security policies are best described as:
A. Ways to protect an organization
B. Methods of punishing those who don’t follow the policy
C. Requests for management buy-in
D. High-level statements of intent and expectation for an organization
10. In order to have data to determine whether a project makes financial sense, you would perform which of these?
A. SLE
B. ALE
C. CBA
D. ARO
11. Risk requires which two elements in order to truly be risk?
A. Chance and indecision
B. Loss and poor management
C. Loss and probability
D. Probability and chance
12. What do you call sensitive information passing over a network?
A. Data in use
B. Data at rest
C. Data under care
D. Data in motion
13. Why would you perform a risk assessment?
A. To identify risk tolerance
B. To identify areas where resources should be applied
C. To identify loss potential
D. To identify what board members should consider
14. What should security policies be driven by?
A. Risk tolerance
B. Risk avoidance
C. Annualized loss expectancy
D. Business mission and objectives
15. What would be a common role for a CSIRT within an organization?
A. Perform event triage
B. Provide oversight and coordination
C. Manage the SOC
D. Develop the computer security incident response policy
Answers
1. B. The annualized loss expectancy (ALE) is calculated by multiplying your single loss expectancy (SLE) by the annual rate of occurrence (ARO). 5000 × 2 is 10,000.
2. C. A disaster recovery plan will allow an organization to get back to full operation after a disaster, but a business continuity plan also provides details on how to ensure operations continue, based on specific targets and goals. While a risk assessment and management buy-in are helpful to have, they alone don’t achieve the stated goal.
3. A. Duqu and Stuxnet are examples of information warfare. While they are related to attacks on the nuclear industry in Iran, they are not examples of nuclear warfare themselves.
4. C. The return on investment is calculated as (gain – expenditure) / expenditure × 100 percent. While B is a very low cost, it also returns nothing. As a result, C should be the approach taken since it has a higher return on investment.
5. D. Job listings seeking IT professionals are good resources about internal systems. If names and e-mail addresses are given, SEC filings through EDGAR can provide information about public companies. Domain name registries can provide information about internal contacts within an organization. The Microsoft registry, an ambiguous term, is not one of the places to get information about a company.
6. C. Encryption is the best way to protect data at rest, just as it is for data in transmission. There are some caveats, however, including not storing the keys with the encrypted data.
7. A. Disaster recovery can be helped by having backups and having replicated systems that can be switched on to take the place of the primary system. The other answers aren’t helped by backups or replication.
8. B. Risk avoidance, while not always possible, is a good strategy for risk management.
9. D. A policy is a set of high-level statements about the intent and expectations of an organization. Policies can help protect an organization, but it’s not the best description. While there may be punishment mechanisms specified in the policy, it’s not a primary focus. While management buy-in is necessary for an effective policy, a policy is not a request.
10. C. You would perform a cost-benefit analysis (CBA) to determine whether a project makes financial sense. SLE is single loss expectancy, ALE is annualized loss expectancy, and ARO is annualized rate of occurrence.
11. C. Risk is the intersection of loss and probability. In order to identify risk to an organization, you need to be able to determine what the potential loss resulting from an incident is as well as the probability of that incident occurring. Chance is sometimes thought of as probability but probability is a more exact word.
12. D. Data in motion is data that is moving from one system to another, passing over a network. Because it’s transiting a network, it’s important to encrypt data in motion. Data in use is data that is in memory and being used by an application. Data at rest is data sitting on disk.
13. B. A risk assessment can be used to identify where resources could best be applied. When you perform a risk assessment against different assets and projects, you can rank order them based on which may incur or reduce more risk. While board members should always be aware of risk, a risk assessment does not identify what board members should be paying attention to.
14. D. Security policies for an organization should be driven by the business objectives and mission. Executives and the board should make it clear what those objectives and mission are so the security policies are aligned with those.
15. B. The Computer Security Incident Response Team (CSIRT) would provide oversight and coordination in the case that an event is determined to be an incident. The team may include members from the security operations center (SOC), but the CSIRT would commonly be separate from the SOC. Executive management should be responsible for computer security policies, though it’s possible members of the CSIRT may have input into the process.
Exercise 9-1 Answer
Future value is calculated as PV / (1 + i)n. $10,000,000 / (1 + 0.0025)24 = $9418350.51 FV.