
CHAPTER 13
Incident Response
In this chapter, you will learn:
• Incident response policies and plans
• Response management
• Legal requirements
• Essential communications
There is a sentiment that has been variously attributed to different people that says there are two types of companies: those who realize they have suffered a data breach, and those who don’t yet know they have suffered a data breach. The gist of the sentiment is that every company has suffered (or will suffer) a data breach. It has also been suggested that breached companies can be categorized further into two types: those who won’t be breached again, and those who will be breached again. All of this is to suggest that being able to address these breach attempts is very important because they are inevitable. You can think about how you handle this as falling into the categories prevent, detect, response, and recover. Incident response is not only about the response, since you at least need to be able to detect something before you can respond to it. Waiting for either the Federal Bureau of Investigations (FBI) or a security-focused reporter to let you know you’ve been breached is not the best of ideas. In the end, response is as much about planning as it is about actually responding.
Incident response is also not purely a technical activity. There is so much more to it than just doing the investigation. A large-scale incident will impact significant sections of the company. This would include the system and network teams as well as management, legal staff, the corporate communications team, and potentially human resources. Today, there are so many laws and regulations, specifically with regard to breach notification, that the legal team needs to be involved to ensure the response proceeds in a manner that will protect the business against fines and other punishments.
Understanding how the attacker works can help with incident response because you’ll understand where the attacker is in their process. This can help you to better scope the investigation. If they are very early in, you may not need to worry yet about tracking any data leaving your organization. Each of the attack stages will have evidence that will point to what the attacker has been doing. There are a couple of different ways to map the attack. Each has its benefits, though ultimately which one you choose may depend on the organization you are in and how you think about the world when it comes to attacks. The first mapping technique is the cyber kill chain, and the second is the attack lifecycle. We will cover the stages of each of these.
Part of every investigation will include collecting data, analyzing it, and then storing it. It’s important to understand how to collect and store data in a way that makes clear it hasn’t been tampered with. In some cases, what you are collecting may have to be presented as evidence in court, and it won’t hold up as admissible evidence if it’s not demonstrably free from alteration. This applies to both the collection and storage. It’s not just the disk data you’ll be collecting, either. You’ll have to be concerned with such ephemeral data as process listings, network connections, and other essential pieces of information that may exist for a very short period of time.
As an incident may be related to business operations, you need to consider the legal implications of the incident. This is for the sake of not only potential prosecution of an attacker but, perhaps more importantly, ensuring that the business does not get fined for improperly handling customer data. Legal implications includes potential disclosure of what has happened. Disclosing that a breach has occurred is where a good communications team comes in. The communications team can help notify customers as well as handle any necessary communication with the press and regulatory agencies.
Mapping the Attack
As previously mentioned, there are currently two well-known ways of thinking about how attackers come after your systems and networks: the cyber kill chain and the attack lifecycle. This is not to say there are no other ways of thinking about these attacks. It’s also not to say that all attacks happen using these patterns. You may have heard the term advanced persistent threat (APT). APT attackers will commonly use methods that easily map to either the attack lifecycle or the cyber kill chain, so it’s very helpful to know more about these two frameworks. This is important from the standpoint of incident response because knowing where the attacker is in their attack will help you understand both the urgency with which you need to respond and where you should focus your attention. Knowing how to determine what the attacker has done and what they are in the process of doing will help you scope your investigation and overall response.
A kill chain is a military term that is used to describe an attack and how it is put together. The idea behind a kill chain is to follow the progression of an attack from identification all the way through destruction of the target. It may also take into account a follow-up to ensure that the target has been destroyed. Lockheed Martin took the idea of the military’s kill chain and applied it to cybersecurity. What they ended up with is commonly referred to as the cyber kill chain. It describes the methods used by attackers to gain unauthorized access to computers in order to gain an advantage, whether it’s building a base of operations or achieving something more directly financial. The cyber kill chain steps are shown in Figure 13-1.

Figure 13-1 Cyber kill chain diagram
The first phase is reconnaissance. This is where the attacker identifies a target and learns what they can about the target. Reconnaissance is not necessarily performing network reconnaissance or enumeration. It’s perhaps finding an organization that has resources the attacker wants, such as intellectual property or financial resources. Reconnaissance also likely involves finding people—names and e-mail addresses—as potential targets for social engineering attacks. The second phase is weaponization. This is where the attacker identifies a means of gaining access, which may be malware that could be used as a Trojan to provide the attacker remote access to the system under attack. Some may consider weaponization the development of a zero-day exploit, which doesn’t take into account the reality of how attacks happen today. Delivery, the third phase, is where the attacker sends the malware to the victim, where (the attacker hopes) it gets executed and gives the attacker remote access to the target’s system. The execution and giving remote access falls under exploitation and installation. The objective here would be to ensure the access is persistent even beyond logouts and reboots. The attacker’s expectation with the cyber kill chain is that the installation will result in a form of remote access to either the attacker or a network of command and control systems.
Another way of mapping out an attack is to use the attack lifecycle. This is a model that was developed after countless investigations of APT groups by Mandiant, a company widely recognized as a leader in the incident response space. You can see the trajectory of the attack in Figure 13-2. One difference between the attack lifecycle and the cyber kill chain is the attack lifecycle recognizes the persistent nature of the attacker. It’s not a one-and-done incident. The attacker gains access to the environment and, rather than being satisfied with the initial access, continues to look for ways to become further entrenched within the organization.

Figure 13-2 Attack lifecycle
The attack lifecycle doesn’t assume malware as the cyber kill chain seems to. It rather generically labels initial recon and initial compromise as the first two stages. One reason for this is that, from a real-world perspective, not all attacks use malware. In some cases, the initial compromise may be the compromise of credentials using a phishing attack. Once in the environment, the attacker works to establish a foothold. This could be through the use of persistence mechanisms to ensure they continue to have access through reboots. This may include installing software that connects back to a system designed to receive these connections. This would allow either a single user or a whole command and control network to maintain access to this system.
Once the attacker has access, the cycle starts. First, if they don’t have administrator-level privileges, they escalate privileges to get them. Then, they perform internal recon, move laterally within the network, and maintain presence (persistence) on the newly acquired systems. Along the way, there would typically be a credential harvest, since that may allow for more systems to be infiltrated. There is no reason to use exploits or malware when simply logging in as an authorized user is possible.
Finally, the last stage is to complete the mission. This, again, though, is not a stopping point. It’s just another stage. It means the objective of the attacker is executed. This may include exfiltrating sensitive data (personal information, intellectual property, etc.) from the target systems to a location managed by the attacker. This attack likely would not be a one-and-done scenario since data is always being generated and updated. New projects get started and generate new documentation and details. More people get hired, so there is more personally identifiable information (PII) to take out of the network.
Keep in mind that APT organizations are funded and staffed. The adversary has an objective and they will do what it takes to obtain that objective. In some cases, it may be stealing intellectual property either to sell or to use for businesses that are nation-state sponsored. In some cases, an APT is organized crime looking to make some money. Either way, these are not ad hoc attack groups or so-called script kiddies, which is one reason why the activities can be mapped. These are people who are doing a job and trying to do it as efficiently as they can because they are being paid to do so. One good example of an APT as a business is APT38. While it’s expected that the APT38 group is backed by the North Korean regime, the group’s objective is financial. They steal money from organizations using a number of techniques. Their actions are not random. They are specific and predictable, with an objective of financial benefit to the attacker.
Preparation
Preparation may be the most important element of incident response. It may not be very exciting, perhaps, but without preparation, there will be a whole lot of excitement. You’ll be responding constantly if you are not prepared. The first thing you need to do is understand what an incident is. I’ll give you a broad definition to help you get started, but keep in mind that each organization may have some specific needs that alter the definition of incident, or at least each organization may have different examples of an incident that relate to how they do business. For purposes of our discussion, an incident is any event that has the potential to incur an adverse reaction within an organization. Narrowing this slightly, an incident is any event that is a violation of security policy. An event is any observable action that deviates from the normal course of business. Essentially, an event is an anomaly. A system spontaneously reboots, for instance. That’s an event. Whether that reboot has an adverse impact on the business would depend on the system in question.

NOTE One important activity of any security operations team is to filter out the false positives. A false positive is an event that was identified that was not actually anomalous. It could also be an event that was identified as an incident, meaning it was thought to have an adverse impact on the business. A false negative is also troublesome, but much harder to identify because it’s a case where nothing was identified but something bad actually happened. A false negative would need to be addressed post-incident to ensure detections are in place for it going forward.
According to the National Institute of Standards and Technology (NIST), there are five essential functions to an information security program. You can see these five functions as they are typically represented in Figure 13-3. When you are preparing your organization for incident response and handling, you should keep all of these functions in mind. First is identify. If you are not putting resources into protecting the right parts of your environment, you are asking for incidents to happen that will need to be responded to. It’s important to keep some things in mind while you are working on the protect function. Some form of threat intelligence is useful here, especially when it comes to understanding who your adversaries are and how they are most likely to attack you. If you throw up a bunch of firewalls, choking network traffic, when in fact the adversaries are attacking your organization’s users through e-mail and web-based attacks, you’ve missed the boat. Intelligence will help you identify so you can effectively protect.

Figure 13-3 Five essential information security functions
Next, is the detect function. This means placing monitoring elements into the environment so you have visibility into all aspects, from servers to network infrastructure down to desktops. Without detection capabilities, you will have no idea when to respond to an incident. You won’t know what an incident is and may not even see events when they happen. Of course, detection leads into the response function. This is what we are dealing with in this chapter. But, as already mentioned, it’s a far broader concept than just sending all the forensics guys in to figure out what happened. The forensics guys can’t do anything without data, which is why we are covering the whole scope of incident response activities.
Finally, you need to recover. This not only means restoring business operations to normal so the lights can stay on. It also means following up to ensure you have “nailed up boards over the holes” to keep the bad guys out. There are not currently clear statistics regarding reinfection rates but be assured the bad guys get back in. Often, too often considering, they get back in the very same way they got in the first time around. The reason is that businesses may be too intent on getting everything restored without taking the time to understand what happened so that they can stop it from happening again. The appropriate follow-up may take the form of root cause analysis (RCA) or an after-action review (AAR). These are semi-formal to formal affairs that seek to understand what happened in order to take back lessons learned from the incident and apply those lessons. Without applying the lessons, you’ll be getting right back on the merry-go-round with the same attacker, in a very short space of time.
NOTE It’s sometimes hard to get the appropriate perspective on an incident right after cleanup has happened. It is important, though. Taking adequate notes during the course of the incident may help a lot in getting through an after-action report. That way, you aren’t spending time trying to remember the order of events. You may also have identified the root cause and lessons during the course of the investigation. They just need to be implemented using a plan, with identified stakeholders following up to ensure the work gets done.
Intelligence
Threat intelligence is important. However, many organizations do not have the depth of experience with attackers or the resources to go digging for information to have adequate threat intelligence. Companies are often focused on getting the business operational again when an incident occurs. They can’t take the time to really identify who the threat actor is and fully understand all the tactics, techniques, and procedures (TTPs) the threat actor used. For this reason, relying on external sources for intelligence makes sense, not only to help inform the overall information security program, but also to understand who your adversaries are and how they operate so that you can make sure you have the right protections in place as well as the right set of detections. Again, this is a place where you should keep in mind the five essential functions of information security so you are developing strategies for each to address what you know to be the threats you face.
While there are commercial companies that will provide you with intelligence that has gone through collection, analysis, correlation, and presentation, there are other sources as well that you can take advantage of without spending money. For a start, there are Information Sharing and Analysis Centers (ISACs). These organizations were originally created in 1998 as a result of a presidential directive in the United States recognizing the potential cyber threats to critical infrastructure. There are a number of ISACs targeted at specific business verticals. If you are in the automotive or real estate industries, for instance, there are ISACs that provide threat intelligence for you. As of this writing, there are 20 ISACs, mostly targeted at specific industries, and most of them have been around for at least a decade, according to the National Council of ISACs (www.nationalisacs.org). There is also an ISAC for governmental organizations called the Multi-State ISAC, focused on state, local, tribal, and territorial governments.
Another resource for threat intelligence that is available at no cost is the United States Computer Emergency Readiness Team (US-CERT). This organization was created in 2000 as the Federal Computer Incident Response Center (FedCIRC) but in 2003 was renamed and moved elsewhere within the government. US-CERT is now part of the National Cybersecurity and Communications Integration Center (NCCIC). US-CERT provides a lot of resources and updates about vulnerabilities and threats at their website: www.us-cert.gov.
NOTE The first computer emergency response team was created in 1988 at Carnegie-Mellon University in response to the so-called Morris Worm that took down a substantial portion of the Internet. The global network at that time was primarily mini computers and mainframes rather than the enormous collection of PC-based devices that it is today. The CERT Division of the Software Engineering Institute at Carnegie Mellon still exists as a point of coordination and is also a good resource for threat intelligence.
Threat intelligence should be used to inform the organization’s overall risk program, meaning information gathered from any intelligence sources should be fed into a risk assessment. This will help to identify what the actual risk (potential for loss or damage in percentage and monetary impact) to the organization is. Once the risk has been assessed, the organization can decide how to handle the risk. This often includes applying resources to mitigate the risk, but it could also be to take an action like transferring the risk through the use of something like cyber insurance. Along with the risk, the threat should be identified, meaning what is the mechanism or entity that may be used to exploit a vulnerability to violate policy or otherwise obtain unauthorized access to a computer system or the information of an organization.
Many threat intelligence programs can provide a feed that can be used within a security information and event manager (SIEM). This outside information can be used in conjunction with the organization’s internal monitoring and logging information to relate what is happening in the outside world to events happening within the organization.
One important point about threat intelligence is attribution. For example, Mandiant names different groups who are responsible for attacking organizations and users. The names Mandiant uses are commonly referenced by the media and across other security vendors. Any advanced persistent threat is given a name APT followed by a number. As an example, APT1, the first named group, is a handful of actors in the Chinese military. As previously mentioned, APT38 is a group that is backed by the North Korean regime. These are not the only named groups, however. In addition to APTs are FINs, which are financially motivated attackers. FIN7, for instance, is not tied to a specific country, though they appear to be Russian-speaking, based on a long period of time observing and cleaning up after them. This is an organization that regularly steals credit card information from restaurants, hotels, and retail establishments. If you have had your own credit card information stolen from a business in one of these sectors, FIN7 may have been behind it.
The purpose of naming these organizations isn’t simply to know who your attacker is. Far more importantly, identifying the adversary means identifying their TTPs. Once you know who you are dealing with, you can narrow the focus of your investigations since you know that, for instance, they are going after credit card information and not intellectual property. This may take a significant number of systems out of the equation when looking for the potential for theft. It also tells you how they do business. They may use a particular piece of malware, for instance, so you can make sure your anti-virus is up to date with signatures for that piece of malware. FIN7 often uses the Trojan Carberp, for instance. You can see the control panel for Carberp in Figure 13-4. Identifying this software in your environment tells you who you are dealing with, potentially, which can increase the speed of the investigation.
Figure 13-4 Carberp Trojan admin panel
Any advantage you can get to help you identify your adversary faster potentially enables you to get to a resolution faster. This means getting your business fully operational again. Ultimately, this should be one of the overall goals of any incident response.
Policy and Plans
The start of any incident response should begin with a policy. This is a set of high-level statements by the organization. These statements define the intention of the organization when it comes to incident response. This includes the goals and objectives of the incident response as well as a definition of roles and responsibilities. After all, responding to an incident isn’t just sending in the technicians and forensic investigators to find out what happened and clean it up. The organization will want to know what the overall impact from the incident is, which may include estimating the monetary value of any data that has been taken out of the organization. Once details like this are known, many other people in the organization are going to be involved.
A policy typically includes sections like scope, purpose, definitions, and responsibilities and then a series of policy statements. Depending on how the organization’s governance and document library is set up, the policy may be very detailed, including procedures. However, policies usually lead to standards that are more specific than the policy, providing some guidance around how to implement the policy statements to ensure the policy is adhered to. Below the policy is the procedure, which would be ground-level guidance for step by step how the standards should be implemented and maintained. A policy generally should not need to be updated very regularly since it should be general enough to be able to encompass any number of technologies and processes that may be used by technicians and analysts.
In some cases, below the policy your organization may have an incident response plan (IRP). The IRP should be detailed and comprehensive, providing guidance on not only how to respond to an incident but also how to ensure events are correctly identified as incidents. Beyond that, the IRP should provide guidance for assigning priorities to the incident. This would typically be based on business needs. Any incident will likely pass through many phases over the course of an investigation. All of the work performed in response to an incident should be documented in a case management or ticketing system. When you are filling in details of the incident for the ticket, you may want to assign categories to identify what the disposition of the incident is at any point in time. The NCCIC uses Table 13-1 to define categories that are to be used for federal agencies. You may find there is some value in using these categories as a starting point.
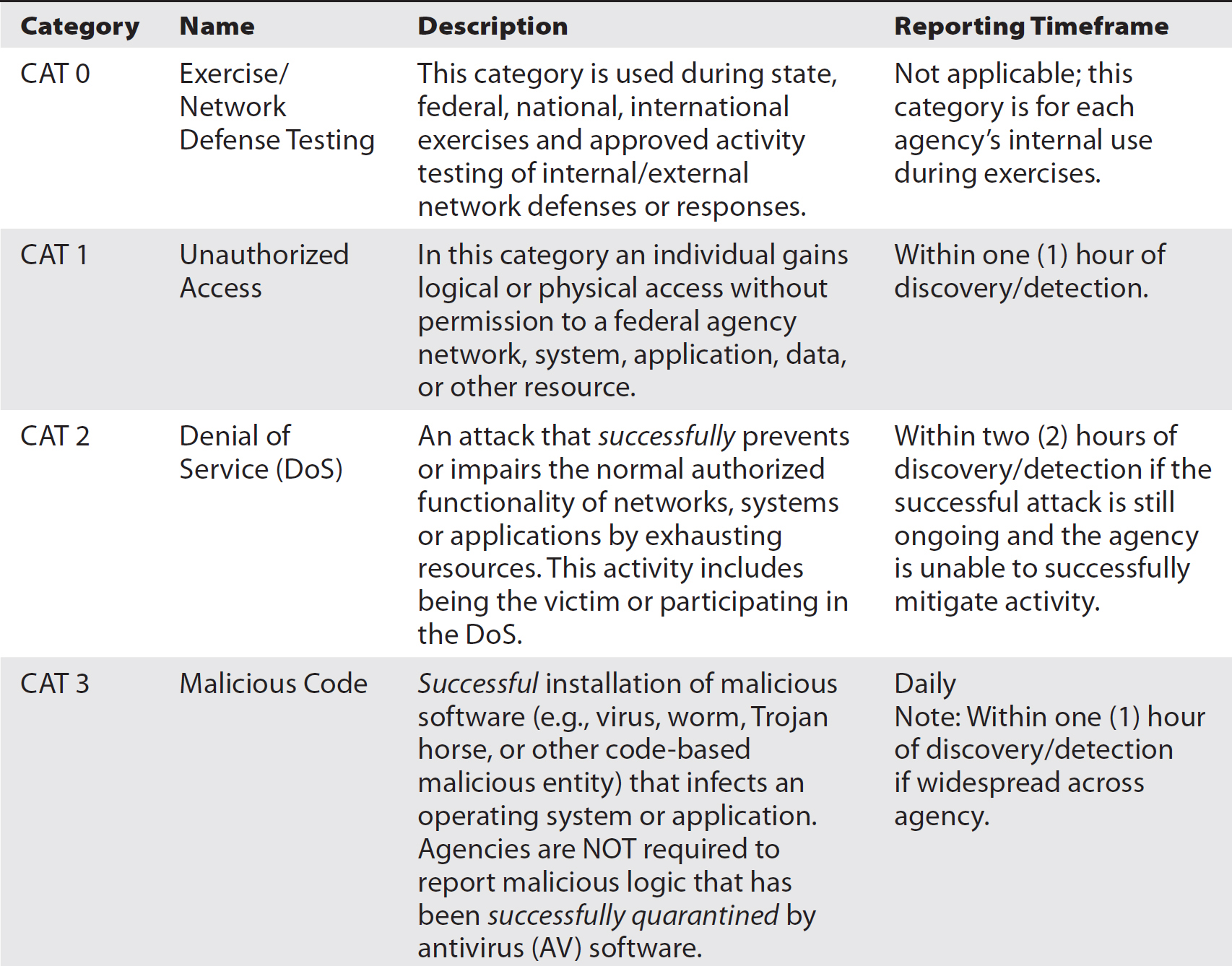

Table 13-1 Incident Response Categories
In order to identify the priority, which should determine how quickly issues are addressed and also how quickly other parties like executive management and legal staff are brought in, NIST suggests using the functional impact to the business, the information impact, and the recoverability. This guidance is available in NIST Special Publication 800-61 Rev. 2 (r2), Computer Security Incident Handling Guide. Table 13-2 shows NIST’s definitions for the functional impact based on whether the business is able to remain operational and to what extent.

Table 13-2 NIST Functional Impact Categories
NIST SP 800-61r2 also provides guidance for the information impact. This has to do with whether data has been removed from the organization and what sort of data has been removed. These categories are shown in Table 13-3. These categories are not mutually exclusive, meaning you may have an incident that impacts multiple categories here. This is different from the functional impact, which considers functions across the organization.

Table 13-3 NIST Information Impact Categories
Finally, NIST SP 800-61r2 suggests determining priority of an incident based on recoverability from that incident. This categorization, shown in Table 13-4, will help to determine resources necessary to respond to the incident. It also talks about the predictability of the incident. Additionally, recoverability is not about survivability of the incident. It’s more about containing the incident within the boundaries of the organization. An incident that is not considered recoverable, for example, is one where data has already left the company and is available publicly.

Table 13-4 NIST Recoverability Effort Categories
The IRP should also contain an escalation path along with thresholds. Once a security operations analyst identifies an event that is worth noting, how quickly does that event get investigated by a more senior member of staff? Who is that senior member of staff? How quickly does that happen? All of these items should be addressed. As part of the escalation, the IRP should include clear delineations for roles and responsibilities. This ensures that essential tasks are addressed, without a duplication of effort.
As you are developing your IRP, you should consider reviewing either the cyber kill chain or the attack lifecycle. After all, your response may be different if you identify an event during the initial reconnaissance phase than it would be much further down the line when data is being exfiltrated. What are the actions you would take depending on the phase you were in? How does the phase you are in within the attack lifecycle change your priority, if it does?
Also, consider the incident response lifecycle, as defined by NIST SP 800-61r2. You can see NIST’s representation in Figure 13-5. Preparation is important, as noted earlier. How are you preparing for an incident? Do you have all the tools you need? Is your staff trained and prepared? Has your plan been tested? These are all elements to consider as part of your IRP in the preparation phase. How are you detecting events and assessing them? Do you have a formal security operations center (SOC)? What are the roles of the SOC in your organization? When it comes to containment and remediation, have you thought about what it means to contain systems? Do you pull the plug or leave systems up for further analysis? Does the attack phase factor into that decision? Do you have a process or technology in place to isolate infected systems from the rest of the network so no further infection takes place while you are conducting your investigation? You may have a virtual local area network (VLAN) you can connect a system to, which may not tip off the attacker while you further assess their activities.
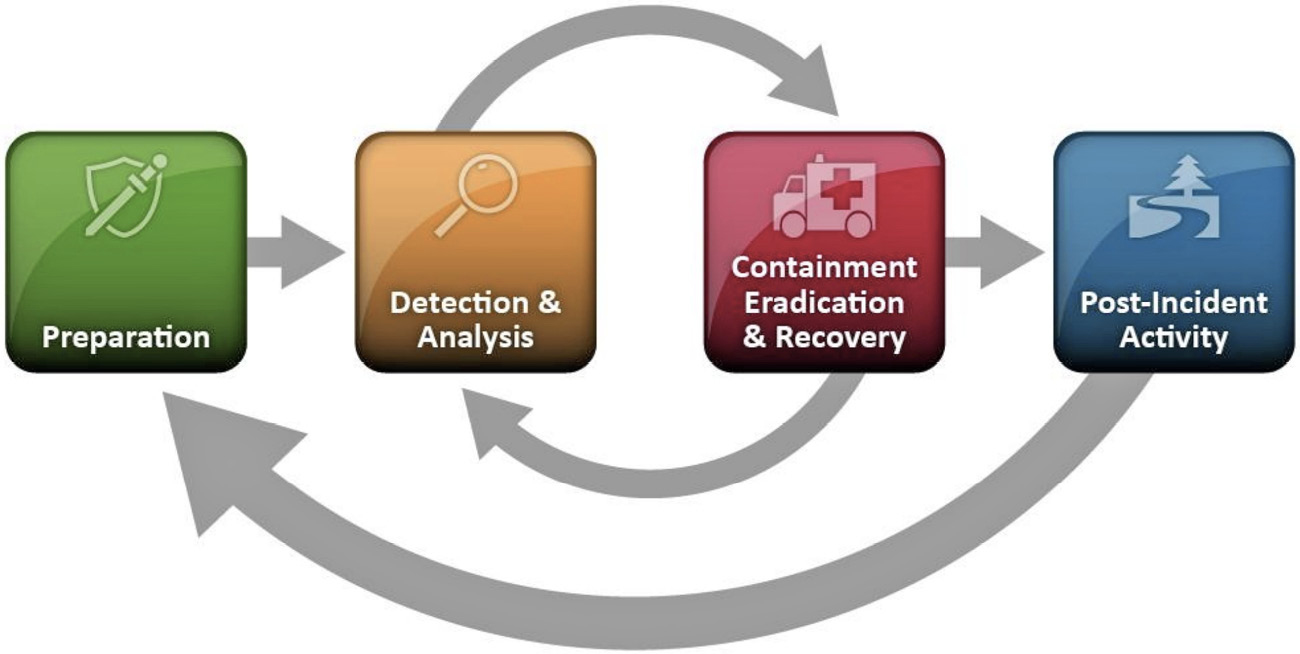
Figure 13-5 NIST incident response lifecycle
NOTE Testing an incident response plan is essential. This can be done through a variety of means, including a tabletop exercise, which presents a scenario to the team/organization and expects them to demonstrate their ability to respond given the plan in place.
Finally, formalize your post-incident process. Make sure you have forms and procedures for how to handle an after-action review. What do you want to get out of this activity? Make sure the expected outcomes are identified and documented in your IRP. Address who is involved in the review and who the results should go to.
NOTE For further details on how to handle incidents and develop your IRP, make sure to check out the NIST publications, several of which address information security, including the incident response process, which is documented in SP 800-61r2.
Computer Security Incident Response Team
Under the definition of roles and responsibilities within the IRP should be the composition of the Computer Security Incident Response Team (CSIRT). Your organization may use a different name for this team, such as Incident Response Team, Emergency Response Team, or some other name that makes sense to your organization. No matter what you call it, though, you should take some time to consider who should be on the CSIRT. This team is responsible for coordination and communication. This is not necessarily the team who is doing the hands-on work. In fact, if your organization is large enough, it’s probably better that it not be the people who are doing the hands-on work, so that the CSIRT can focus on incident response.
You should also consider whether your organization has the staff to be able to handle incident response internally or needs to partially or completely outsource it. If you are going to outsource your incident response, make sure you have that agreement in place well ahead of when you need it. This will help establish your procedures and give you adequate time (hopefully) to get familiar with the third party and vice versa. Many incident response companies offer a retainer service where you pre-pay for some number of hours in exchange for being able to call them and get immediate response when something bad happens. If you have staff in house, you may also be able to, or need to, augment that staff with an outside resource. If you are completely outsourcing or even augmenting, you may need just a minimal CSIRT internally with the coordination happening at your provider.
If you are going to handle your incidents in-house, or even if you are going to partially outsource, you need to make sure you have thought through a few considerations. First, is the CSIRT expected to be available 24/7? How are you going to handle backups in the case of vacations or other personnel outages? Being a member of the CSIRT can be very stressful, so ensuring that you are addressing morale, especially during the course of the investigation and response, can be essential. Don’t assume your people can work 18-hour days for a week or more straight. They will burn out and miss something that may be essential to a successful response.
When it comes to staffing your CSIRT, the first thing you need to do is name an incident response lead (IRL). Even if your teams and people are distributed, having a single incident response lead is essential. All decisions and communications would go through this incident response lead (or whatever you choose to call the role; some organizations use terms like incident commander). You should also make sure you have identified a deputy or backup for the IRL. This is important not only in case the IRL is on vacation or otherwise unavailable when an incident happens, but also if the IRL becomes unavailable in the middle of the incident.
It’s important to keep in mind that major incidents will be weeks (if not months) long and you will need to make sure you provide sufficient rest periods for your CSIRT team so they are not working all the time. Your IRL and backup IRL will need to be in constant communication so that there is no ramp-up time required if the ball needs to be handed from one to the other.
Many organizations will expect that the incident will be managed by one of the legal team. There are a couple of reasons for this. The first is the essential sensitivity of the response activities. You may be dealing with illegal activities by the attacker, in which case your organization may need to engage law enforcement. A lawyer should know when that threshold has been hit. Additionally, companies don’t want these activities to be widely known or even casually discoverable after the fact. If a lawyer is involved and all communication and activity run through the legal team, that communication becomes covered under attorney-client privilege. This protects the contents of the investigation in the case of legal action initiated by outside parties later on.
Your organization may choose to have a member of management on the incident response team. This provides “top cover” for the response team, meaning someone from management can interface with other relevant management staff so they are informed as needed. Again, this sort of communication should be cleared by the legal team. Additionally, the response team would have management support for their actions. In some cases, difficult decisions need to be made when responding to an incident, and it is critical to have relevant management staff available to make those decisions.
Finally, and certainly not the least important, is CSIRT representation from the technical staff. You don’t want to include everyone who is involved in the incident response activities. After all, the CSIRT should be about coordination and communication. However, the technical staff does need to be identified ahead of time. Even if they aren’t part of the CSIRT, you will want to know who you have available to handle the technical response and investigation. This is where understanding the capabilities of your staff is essential, and making sure the identified staffers know they have been identified and what they are expected to do. This will be necessary in order to potentially determine additional training they may need to undergo to be prepared when an incident happens.
Managing the Response
When an incident happens, there are really two aspects to consider. The first is how management is going to handle the incident. This involves legal elements as well as communications elements. The second, which we have so far not addressed very much, is the technical aspect. This requires management, just as the other aspects we have been talking about. First, you need to make sure your organization has the right staff in place. Not every organization can afford to have a fully staffed, 24/7 SOC that can watch for alerts, perform triage, and have multiple tiers of analysts and engineers to hand tickets off to. In some cases, the “SOC” is literally a one-person shop where detection and response has to be done by the same person. Depending on the scale of the incident, this may be adequate. After all, not every incident is going to be a multisystem infection with data exfiltration. Some incidents will be as minor as a notification from a user that they received a phishing e-mail that they may have clicked but didn’t go further. This requires investigation but not a large response.
The first thing you need is a case management system. A case management system can improve the efficiency of your response. This doesn’t mean you need to have commercial software with all the bells and whistles, especially if you are not with a big organization. There are some open source solutions, such as Request Tracker (RT), which also has a commercial option and additional plugins that can configure it specifically for incident response. (You can find RT at https://bestpractical.com/request-tracker.) The case management software provides a place for you to centralize notes and any hand-offs from one person or team to another. These notes and details can be (and should be) saved for later reference, which may be useful if a similar incident arises later on. You can refer to how you responded the first time for hints on how to do it the next time. This archive is even more useful if someone who wasn’t involved in responding to the first incident is called on to handle the similar incident the second time around. There is now essentially a cheat sheet. More importantly, these notes provide guide posts that can be used during an after-action review.
There are other aspects of managing the investigation, though, that are important. Some of these are legal in nature. When you are performing an investigation, you should consider whether your findings may need to be used as evidence in a court case, should there be a trial of the attacker. Any time there is evidence involved that could be brought before a court, there are considerations for how to collect the evidence and also for how to handle it once it is collected.
Forensic Teams
Many organizations do not have a dedicated forensic team. This may not be an issue, depending on the size and needs of the organization. It is important, though, that anyone tasked with performing forensic analysis be trained in proper evidence handling. In many cases, the person or team who is doing an organization’s system and network administration may be knowledgeable enough about the devices under their control to know how to look for different details related to the investigation. An experienced system administrator may know how to identify instances of persistence on a system, for instance, which would allow the attacker to maintain access over long periods of time, across logouts and reboots. They may also be aware of how to identify compromised system binaries, and maybe even processes that have had malicious code injected into them.
Fortunately, there are a lot of tools that are available for forensic teams to make use of, even if the teams aren’t as familiar with popular commercial tools like FTK, EnCase, or BlackLight. For a start, on the Windows side, the Sysinternals tools are really useful for collecting details from a running system. This includes process information, network connections, and even hidden files in alternate data streams. There are dozens of tools in the Sysinternals collection, offered for free from Microsoft. Additionally, on the Linux side, you can use entire distributions like SIFT or Kali Linux. Kali is oriented toward security testing in general but includes a fairly complete collection of forensic tools. The SIFT workstation is maintained by SANS as a Linux-based distribution designed specifically for forensic investigations.
Collecting Data
There are going to be multiple sources of data you will need to collect, especially in a broad investigation. For a start, if you are fortunate, you are using a SIEM that is aggregating all your log data. Your logs are going to be essential in performing a complete incident response, since they will provide historical data for you. It may be rare that you catch an initial encounter, which means that in most incident-response scenarios there will have been activities that happened before the event that you detected. Being able to go back days, weeks, or months is going to be essential to getting a comprehensive picture. This means you will need to be able to collect log data from either a SIEM or some log aggregation tool. Ideally, a SIEM or something similar would be used, since it may provide you better searching and data retrieval tool than just a log collection utility. A SIEM may be able to help guide you in your search. Unless you are a highly experienced investigator, that help may be essential to you.
Disk-Based Evidence
When it comes to collecting disk-based evidence, you have a choice of multiple tools. A very simple approach is to use a bootable USB stick with a small Linux distribution to get a disk image. You can use a built-in tool like dd, which is a disk dump utility that performs a bit-for-bit copy of one disk to either another disk or an image file. If you were to use a forensics-oriented implementation of dd like dcfldd, you could not only collect the image of the disk but also generate a cryptographic hash at the same time. In the following code you can see the use of dcfldd to grab a copy of a disk. The device being imaged is /dev/sdb, which is the second SCSI/SATA-based disk on the system. The primary disk would be /dev/sda. This is a very small disk, only 120Mb. The cryptographic hash has been generated using the Secure Hash Algorithm using 256 bits of hash value. This hash value can be used to compare against subsequent file hashes to ensure nothing has been changed.

NOTE When you are collecting disk-based evidence, it’s important to have a write blocker in place. This is either software or hardware that prevents the disk being acquired from being written to during the acquisition. This is essential for appropriate evidence collection and handling.
If you are uncomfortable with the use of the command line or Linux, you can also use Windows. For example, FTK Imager is a Windows-based program that you can use to capture disk images. One of the challenges of using software like this that needs to be installed, though, is that you are altering the disk you want to capture, unless you have the disk installed as a secondary disk. This would require removing the disk from the original system and either adding it as a secondary disk to your workstation or putting it into an external case to image from there. By using the FTK Imager, shown in Figure 13-6 selecting a source drive, you can not only create the disk image but also generate an evidence item that could later be used in FTK proper for analysis.

Figure 13-6 Selecting a disk in FTK Imager
Once you have selected the source drive, you will be able to look at a dump of all the bytes on the drive in hexadecimal representation. We use hexadecimal representation for data like this because most of it won’t translate nicely to printable ASCII characters since the vast majority of the data is not human-readable strings. A pair of hexadecimal digits is what is needed to represent a byte. This is shorter than the possible length in decimal, which would be three numeric positions. In order to actually get a dump of the disk, you need to right-click the disk, as seen in Figure 13-7, and select Export Disk Image. This will let you select the type of image you want. This may be a raw image or it may be an evidence-based format like E01 or the Advanced Forensics Format (AFF).
Figure 13-7 Export disk image
Memory Captures
Disk evidence is not all you will be dealing with. You may also need to acquire a memory dump. You may need to dump the whole of your system memory or just dump the memory of a process. Some of the Sysinternals tools will help you with investigating memory for a specific process, but if you need to dump the entirety of system memory, you will need additional help. This can be challenging since it’s generally not a good idea for programs to be able to directly access memory without going through an application programming interface. Once direct access to memory has been enabled, there is the possibility of overwriting system memory. This would be bad for multiple reasons, but this is why there aren’t a lot of programs around that do this sort of work. As an example, there used to be different ways to grab Linux system memory, but over the last few years these techniques have become unusable as the Linux kernel has prevented the techniques they use.
One tool you can use on Windows (and there are only a handful) is Memoryze. This is a utility developed by Mandiant as part of their incident response suite and is freely available from www.fireeye.com (under Resources | Free Software Downloads). It can be used as a standalone tool to grab memory dumps. Because it uses configuration files to capture the memory, you wouldn’t just run Memoryze on its own. It’s a command-line program and it comes with batch files that will set it up to grab what you are looking for. Figure 13-8 shows a run of Memoryze to capture the system memory from a Windows desktop. Since system memory is highly protected, you need to run it from a command prompt that has Administrative privileges.

Figure 13-8 Collecting a memory dump using Memoryze
Using Central Data Collection
So far, we’ve been talking about performing the data collection on individual machines. In a large organization this is simply impractical. You can use centralized methods to collect data, though. There are commercial products that will perform this work, such as Carbon Black, but there is also an open source product that can be used. Google Rapid Response (GRR) uses a server/agent model, just like other similar commercial products. You install the agent on the system you want to collect data from and you initiate the collection from the server. Using this approach, you can hunt for infections using GRR. Figure 13-9 shows one of the hunt requests. This is a generic hunt that can be used to query the endpoints. There are multiple other queries that can be generated from the GRR console to help identify potential infected systems on your network.

Figure 13-9 Hunting with GRR
A tool like GRR puts the control into a centralized location, but it does require that agents be installed on all endpoints that will need to be queried. While GRR is supported by Google, it is much less mature than other tools that are available for the same purpose. This is a good option, though, if you don’t have the resources for a commercial tool, because you can use GRR to identify potential issues within the devices in your environment.
Evidence Handling
As noted earlier, evidence handling is an important consideration. For a start, you need to make sure you are collecting all evidence in a way that can be demonstrated not to have been tampered with. You can do this using cryptographic hashes. Previously, the standard cryptographic hash was Message Digest 5 (MD5). While this is still useful as a hashing algorithm to generate unique values identifying data, it’s better practice to use SHA-1 or, even better, SHA-256. SHA-1, SHA-256, and SHA-512 all have a larger space to generate these values in. SHA-1 generates a 160-bit value, while SHA-256 generates a 256-bit value, and so on. These larger values reduce the possibility of collisions, which are cases where two different pieces of data generate the same hash value. If you can have two different data sources that result in the same hash value, this fact could create doubt as to the validity of the original data presented.
Beyond ensuring that no data has been tampered with using cryptographic hashes, it’s important to document when evidence has been passed from one entity to another. This is called a chain of custody, and any time a piece of evidence such as a disk image is transferred from one person or organization to another person or organization, that transfer must be documented in the chain of custody, including a description of the evidence, the means of transfer, the names of the parties, and the date and time of the transfer. The chain of custody document must also be secured, meaning it is stored in a place where only authorized people can get to it.
Speaking of ensuring things are secured, evidence should also be secured so no one can get at it unless they are authorized and the access has been documented. This might be done through the use of encrypted, access-controlled storage, for instance. In the case where you have physical evidence, this should be put into a safe that can only be accessed by authorized investigators. Any time physical evidence is removed from the safe, it should be documented. Even if the person removing it is the same person who put it in the safe last, every access to the evidence should be documented. A complete paper trail of all evidence handling is essential.
Communications
Incident response has many communication aspects that are important to consider. The first is the communication to management and the rest of the organization. Regular updates on the status of the investigation should be provided. This should be documented in the IRP so expectations are clear. Technical staff should be reporting to the CSIRT, which should then be keeping executive management informed. Time frames for all reporting should be clear and documented. Even formats for reporting should be provided as part of the IRP. This ensures all the relevant details are provided in the regular status updates.
In addition to communication about status, there is also communication between investigators. In the case of a wide-spread incident, all system functions should be considered compromised, from the servers to the desktops to the network itself. As a result, normal communications channels should be considered suspect. It’s best for these communications channels to be encrypted to begin with, but in the case of a significant investigation, plans for out-of-band communications should be developed. This should include phone communications, for instance. The organization should plan to have teleconferencing solutions in place. However, these solutions should not make use of the enterprise network. If the phone system is Voice over IP (VoIP), the company phones should also not be used since that traffic could be intercepted.
When it comes to data exfiltration and information compromise, there are likely reporting requirements. If the corporate communications staff does not understand how to handle sensitive communications like breach notifications, a third-party public relations firm should be used. As with the case of an incident response company, this is the sort of relationship that pays to have established ahead of time.
Legal Implications
There are multiple laws that require notification in the case of data loss or theft. Most states have their own notification laws. Other laws that impact companies are Europe’s General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA). Each of these laws has stringent requirements for protecting consumers’ data. If an organization’s consumer data gets stolen or compromised, each law has requirements for notifying the consumers. This is just one reason why having legal staff involved in incident response is important. The legal team should have an understanding of these laws’ requirements. They can provide guidance as to how the response should proceed with the relevant laws in mind. They can also provide guidance to executive management.
In some cases, consumers or other parties may initiate litigation against a company or organization, claiming damages resulting from an incident. Therefore, having the lawyers involved early on can be beneficial. For a start, with the lawyers involved, communications can go through them and remain confidential. This means the actions of the incident response team, as related to what goes through the legal team, remain confidential and potentially exempt from any discovery that may come as part of a lawsuit against the organization.
Chapter Review
Incident response is a complicated business for many reasons. One reason is that attacks are complicated. Attackers are often interested in gaining access to systems and retaining access over a long period of time. For this reason, they are referred to as advanced persistent threats (APTs).
There are a couple of different ways to map attacks. The first is the cyber kill chain, developed by Lockheed Martin with the military kill chain in mind. The stages of the cyber kill chain are reconnaissance, weaponization, delivery, exploitation, installation, command & control, and actions on objectives. The second is the attack lifecycle. This is a way of mapping attacks that was created by Mandiant as a result of many years of investigating APT attacks. The stages of the attack lifecycle are initial reconnaissance, initial compromise, establish foothold, escalate privileges, internal recon, move laterally, maintain presence, and complete mission. The attack lifecycle takes into account the common practice of these attackers of staying in the environment, compromising additional systems, and obtaining additional credentials.
Preparation is important for incident response. Intelligence is important for preparing for incident response. It can be used to inform the protection against and detection of events, which may become incidents. Organizations can buy threat intelligence but they can also use Information Sharing and Analysis Centers (ISACs), which are specific to industries, including telecommunications, utilities, and automotive businesses. This information should also be used to inform the incident response policy and plan. The policy is a set of high-level expectations of the organization when it comes to incident response. The plan is more detailed and should be comprehensive in its guidance to the organization so anyone coming on board as a new hire should be able to look at the plan and understand how incident response is handled within the organization.
Part of the plan covers how the Computer Security Incident Response Team (CSIRT) is staffed. The plan should also include how the forensic team should be staffed and operated. Organizations may not be able to fully staff a complete forensic team, which may mean they need to make do with what staff they already have. This may be systems and network administrators. This staff should be trained in appropriate evidence handling processes, including demonstrating that evidence has not been tampered with through the use of something like a cryptographic hash. MD5, SHA-1, SHA-256, and SHA-512 might be used for cryptographic hashes to demonstrate that evidence has not been tampered with. Additionally, chain of custody documentation is essential to demonstrate who has had access to evidence and what they have done with it. Incident response plans should be tested regularly to ensure the plan is up to date and all staff understand how the plan operates.
Privacy laws like those in California and Europe have created requirements for legal teams to be involved in incident response to ensure the requirements of these laws are followed. Additionally, legal teams can help ensure communication is confidential and protected by attorney-client privilege. These privacy laws also typically require notification of anyone who may be impacted by a data breach. This can require the use of either a communications staff or an external public relations firm who has experience with these sorts of communications with consumers.
Questions
1. If you need to use a tool to both gather disk-based evidence and generate a cryptographic hash, what would you be most likely to use?
A. dcfldd
B. dd
C. Memoryze
D. Fmem
2. What is the document that demonstrates who has had access to evidence and when?
A. Evidence form
B. Data collection document
C. Chain of custody
D. Legal signoff
3. What organization could you turn to for threat intelligence if you didn’t want to pay for a commercial service?
A. FIRST
B. ISACA
C. NECCDC
D. ISAC
4. Why would you use a centralized data capture program?
A. To avoid having to physically touch every system
B. To save space
C. Better acceptance of resulting evidence
D. Centralized hashes all data
5. How is an incident different from an event?
A. An incident is any observable change, whereas an event has the potential to cause damage.
B. Incidents have a higher probability of causing damage.
C. Events might be false positives.
D. An event is an observable change, whereas an incident has the potential to cause damage.
6. What is the purpose of an incident response policy?
A. To provide details for incident responders to follow
B. To identify risks to the environment
C. To provide high-level guidance from the business
D. To suppress fires
7. Why would you use a cryptographic hash?
A. To uniquely identify evidence
B. To classify incidents
C. To differentiate memory from disk captures
D. To encrypt evidence
8. What set of tools provided by Microsoft could you make use of to acquire evidence from systems?
A. Winternals
B. Forensic Analyzer
C. Sysinternals
D. GRR
9. What is the possible problem with using MD5 as a cryptographic hash?
A. Encryption algorithm is known
B. Collisions
C. Outlawed
D. Doesn’t work on all digital evidence
10. What is the privacy law in Europe known as?
A. CCPA
B. EUPA
C. GDPR
D. DPRE
Answers
1. A. Only dcfldd could get a disk image and also generate a cryptographic hash. dd is used to acquire a disk image, but it doesn’t have the ability to generate a cryptographic hash. You would need to use an additional tool for that. Memoryze is used to acquire memory captures. Fmem was once used for memory captures on Linux.
2. C. A chain of custody document is used to document every time a piece of evidence has been handled, who it has been handled by, and the purpose of handling the evidence. None of the other answers is a real thing, at least not in this context.
3. D. An Information Sharing and Analysis Center (ISAC) can be used for information sharing. These are industry-specific groups. ISACA is another organization that provides information security certifications. NECCDC is a cyber-defense competition in New England. FIRST has a number of meanings, including a robotics organization for students.
4. A. Central data collection programs make it easier to collect data since you don’t have to physically touch every system. They rely on agent installs on the endpoints to collect the data remotely. They don’t save space, and the resulting evidence is no more acceptable than that collected manually from endpoints. Also, you can perform cryptographic hashes on any digital evidence collected.
5. D. An event is any observable change to an environment that is different from what is expected. An incident, though, is an event that has the potential to cause damage.
6. C. A policy is a high-level statement of intentions from the business owners to clearly identify expectations. A plan would provide more details. A risk assessment program would identify risks. It is not used to suppress fires.
7. A. A cryptographic hash generates a long value that is used to uniquely identify data. It is not used to classify incidents. A hash, while cryptographic, is not used to encrypt anything. It also isn’t used to differentiate memory captures from disk captures.
8. C. Microsoft offers Windows Sysinternals as a collection of tools that are highly useful for forensic professionals to collect information about processes, network connections, and multiple other system details. Previously, the collection of tools was called Winternals, but the group developing them was not part of Microsoft at that time. GRR is Google Rapid Response, and Forensic Analyzer isn’t a Microsoft product.
9. B. Collision is the term for when a cryptographic hashing algorithm generates the same value for two different data sources. The algorithm for MD5 is known, but MD5 doesn’t do any encryption. It has not been outlawed, and it will work on all digital evidence.
10. C. GDPR is the General Data Protection Regulation, the European law that addresses data breaches and other privacy violations. CCPA is California’s privacy law. The other two don’t exist, as least not as privacy laws.