
At some point you have to decide whether you’re going to be a politician or an engineer. You cannot be both. To be a politician is to champion perception over reality. To be an engineer is to make perception subservient to reality. They are opposites. You can’t do both simultaneously. | ||
| --H. W. Kenton | ||
One of the best features of .NET is the automatic memory management provided by the Common Language Runtime, reference types, and the Garbage Collector. C# hides most of its memory management, which makes life a lot easier for developers. In almost all situations, this censorship from the nitty gritty details of memory management is a good thing, though the need does arise when low-level access to memory is needed.
Memory in C++ is accessed and managed through the use of pointers. C# supports the concept of pointers, but only when absolutely necessary. The use of pointers in C# is discouraged, though there are a few rare situations that require them.
These situations are:
When dealing with existing structures on disk, or when you need direct access to memory.
When using Platform Invoke or Advanced COM that involve structures with pointers in them.
When there is a strong need for performance-critical code, such as applications that require enhanced performance to make things as “real time” as possible.
Pointers in C# should not be used except for the three situations listed above. Only use pointers when absolutely necessary.
Before continuing on, it is important to list the advantages and disadvantages of using C# pointers.
The advantages are:
Enhanced performance and increased flexibility. You can use a pointer to access and manipulate data in the most efficient way.
There have obviously been a large number of Windows and third-party libraries that were developed prior to the .NET platform. Some functions may require that pointers be passed as parameters. Though this can be accomplished with
DLLImportandSystem.IntPtr, it can often be cleaner to do it with pointers if you are already using them. Pointers offer extensive compatibility with legacy components.Some situations require that you track memory addresses, in which case a pointer is the only way to accomplish this.
The disadvantages are:
Using pointers in C# increases the complexity of the language syntax. While CC++ developers are accustomed to it, C# developers may struggle a bit with the rarely used concepts.
Pointers are much harder to use, and even harder to use safely, than using reference types. It is quite easy to overwrite other variables, cause stack overflows, and access areas of memory that do not contain valid data, and in some cases, you can even overwrite process data for the .NET runtime. Doing so will result in a fatal application crash, defeating the purpose of using managed code for robust fault tolerance in the first place.
Now that I have successfully scared you away from using pointers in C#, it is time to continue on into the implementation and usage details.
The concept of pointers is well known and loved by C++ developers, but developers accustomed to other languages may find the idea and syntax difficult to grasp at times. Because of this, it is important to briefly discuss pointer notation, though only scratching the surface of a complex topic. If you are new to using pointers, it is recommended that you do further reading before attempting to use them in your code.
What is a pointer? A pointer is a variable that holds the memory address of another type. In C#, pointers are implicitly declared using the dereferencer symbol (*). After declaring the pointer variable, prefixing the variable with a dereferencer symbol will allow you to refer to the type located at the memory location held by the pointer; this is commonly known as dereferencing a pointer.
For example, the following code creates an integer with a pointer to it (intPtr) and uses integer assignment to set its value to 27.
int* intPtr = 27;
Later on, should you wish to change the integer value, you can use the following code to set the value to 15.
*intPtr = 15;
Caution
It is very important that you prefix the variable with the dereferencer symbol when trying to work with the data.
Consider the following code:
intPtr = 56;
The intent was to set the integer value to 56, but in actuality the pointer will now point to the start of the four bytes at memory location 56 (which could be anything).
Another symbol that is essential when working with pointers is the address operator (&) (in the context of pointer notation). Prefixing a variable with this operator will return the memory address of the variable.
The following code declares an integer and creates a pointer that points to the location of the integer in memory.
int myNumber = 42; int* myNumberPtr; myNumberPtr = &myNumber;
At this time, we have a pointer (myNumberPtr) that points at the memory location of an integer (myNumber) in memory.
The following code can now be used to set the value of myNumber to 13 through the pointer myNumberPtr.
*myNumberPtr = 13;
Note
*myNumberPtr can be read as “the integer located at the memory value address held by myNumberPtr.”
Finally, pointers can also be declared for structs.
Consider the following struct definition and code:
struct CartesianCoord
{
public int x;
public int y;
public int z;
}
CartesianCoord coord = new CartesianCoord();
CartesianCoord* coordPtr = &coord;You can now use the pointer coordPtr to access public fields of coord.
This can be done with the following code:
(*coordPtr).y;
Or the following equivalent code, which uses the indirection operator:
coordPtr->y;
Caution
C++ developers are used to declaring statements like the following to save typing:
int* int1, int2;
Those developers would assume that int1 is a pointer to an integer, and int2 is just an integer. C# handles this statement differently, as the pointer declaration is on the type, not the variable. In this example, both int1 and int2 are pointers to integers.
C# code executes in either a safe or unsafe context. Safe is the default, but any use of pointers requires that an unsafe context be used. The unsafe keyword is used to denote an unsafe context. Unsafe code is still managed by the Common Language Runtime, just like safe code, the only difference being that programmers can use pointers to manipulate memory directly. Unsafe code runs outside of the automatic memory management capabilities provided by the garbage collector, though the Common Language Runtime is always aware of the code. The unsafe keyword is an enhancement to make unsafe code a little bit safer. Code executing in an unsafe context is not verified to be safe, so the code must be fully trusted in order to execute the unsafe code. Unsafe code cannot be executed in an untrusted environment like the Internet.
The unsafe keyword can be applied on methods, properties, constructors (exception static), and extenders. Running code in an unsafe context is much more efficient than using references because the garbage collector and an extra layer are bypassed to decrease overhead. Unsafe code also increases performance by getting rid of array bounds checking (though you are now responsible for it).
Aside from placing code within an unsafe construct, you must also configure the compiler to allow unsafe code to be used. This can be done through the property pages for the project or by using the /unsafe switch flag with csc.exe.
The following code shows how to properly use the unsafe keyword in a couple of ways.
public void unsafe MyMethod(int* arg)
{
// Use arg parameter here
}
public void MyMethod(int arg)
{
unsafe
{
fixed (int* argPtr = arg)
{
// Use argPtr parameter here
}
}
}The automatic memory management provided by the Garbage Collector runs in a background thread, so you can never tell when memory will be assigned to a new data location. This can create a serious problem when dealing with pointers, because the pointers will not update their addresses when the memory changes, resulting in pointers that point at incorrect or invalid memory blocks.
C# supports the fixed statement, which is used to signal that a particular variable should not be touched by the garbage collector. This is known as memory pinning, which means that the specified memory is pinned to a particular location, and that you are guaranteed that the location will remain constant until the code exits the fixed statement.
The fixed statement has similar syntax to the using statement. The following code shows the fixed statement being used.
byte[] data = new byte[10000];
unsafe
{
fixed (byte* dataPtr = data)
{
// Code using dataPtr here
}
}Some situations require that you have two fixed variables that use each other. This is perfectly acceptable by nesting fixed statements. The following code shows this being done.
byte[] data1 = new byte[10000];
byte[] data2 = new byte[5000];
unsafe
{
fixed (byte* data1Ptr = data1)
{
fixed (byte* data2Ptr = data2)
{
// Code using data1Ptr and data2Ptr here
}
}
}Another keyword that is relevant to unsafe pointer usage is the unchecked keyword. Specifying unchecked allows you to suppress overflow-checking for integral-type arithmetic operations and conversions. If an expression produces a value that is outside the range of the destination data type, then the result is truncated. For example, trying to evaluate the following code will set myNumber equal to -1014837864.
unchecked
{
int myNumber = (int)3181555928472; // Evaluates to -1014837864
}The unchecked keyword causes the compiler to ignore the fact that the value is too large for the integer data type. Had the unchecked keyword not been specified, then the compiler would have thrown compile time errors because the sizes are known and the values are constant. Otherwise, an OverflowException would have been thrown at runtime.
You can also use the unchecked keyword as an operator, as in the following example.
public int AddNumbers(int left, int right)
{
return unchecked(left + right);
}Running code, especially numeric-intensive calculations, within an unchecked block can boost the overall speed and performance of the executing code. You have to be careful to watch your data type sizes though.
You can use the keyword stackalloc to allocate a block of memory on the stack. This only works with value types, and the memory is not subject to garbage collection, so it does not have to be pinned. The lifetime of the memory block is limited to the scope of the executing method; stackalloc is only valid in local variable initializers.
Note
Stackalloc is very similar to the _alloca method in the C runtime library. Stackalloc depends on the use of pointers, so you can only use it within an unsafe context.
The memory is only allocated by stackalloc, so initialization is up to you. One common usage for stackalloc in terms of performance is when dealing with arrays. The .NET platform provides excellent mechanisms for dealing with arrays, but the data are still objects instantiated from System.Array and stored on the heap, so all the related overhead is incurred when dealing with them.
You can allocate enough memory to store 10 integers with the following code.
int* intArray = stackalloc int[10];
There are a couple of ways to access the array members.
You can use *(intArray + i), where i is the index of the array element to access.
*(intArray + 0) = 123; *(intArray + 1) = 456; *(intArray + 2) = 789;
You can also use intArray[i] to access the array elements.
intArray[0] = 123; intArray[1] = 456; intArray[2] = 789;
Normally, when you access a member outside of the array bounds, an out of bounds exception will be thrown. When using stackalloc, however, you are accessing an address located somewhere on the stack. Writing to an incorrect address could corrupt a variable, or even return an address from a method currently being executed.
For example:
int* intArray = stackalloc int[5];
intArray[7] = 123; // This means that (intArray + 7 * sizeof(int)) had
// a value of 123 assigned to it.Just as in CC++, you can use the sizeof operator to determine the number of bytes occupied of the given data type. You must do so within an unsafe context.
The following code can be executed to print out a list of data type sizes for handy reference. As of .NET 2.0, it is optional to use the sizeof operator within an unsafe context.
unsafe
{
Console.WriteLine("sbyte: {0}", sizeof(sbyte));
Console.WriteLine("byte: {0}", sizeof(byte));
Console.WriteLine("short: {0}", sizeof(short));
Console.WriteLine("ushort: {0}", sizeof(ushort));
Console.WriteLine("int: {0}", sizeof(int));
Console.WriteLine("uint: {0}", sizeof(uint));
Console.WriteLine("long: {0}", sizeof(long));
Console.WriteLine("ulong: {0}", sizeof(ulong));
Console.WriteLine("char: {0}", sizeof(char));
Console.WriteLine("float: {0}", sizeof(float));
Console.WriteLine("double: {0}", sizeof(double));
Console.WriteLine("decimal: {0}", sizeof(decimal));
Console.WriteLine("bool: {0}", sizeof(bool));
}Executing the above code will print out the following:
sbyte: 1 byte: 1 short: 2 ushort: 2 int: 4 uint: 4 long: 8 ulong: 8 char: 2 float: 4 double: 8 decimal: 16 bool: 1
You may be wondering why char prints a size of 2. This is because System.Char (char) is a Unicode type (two bytes), and sizeof returns the size of the data types allocated by the CLR. There is another method to get the size of data types after marshaling has occurred. System.Runtime.InteropServices.Marshal.SizeOf() returns the size of a data type when converted to an unmanaged representation. Using Marshal.SizeOf(char) will return one byte since at this point the char has been converted to a one-byte ANSI character.
You can also get the size of a struct that contains value types. The following code shows this.
public struct SimpleStruct
{
public char firstChar;
public char secondChar;
public int myInteger;
}Evaluating sizeof(SimpleStruct) will return 10 bytes with padding, and Marshal.SizeOf(SimpleStruct) will return 6 bytes.
The following example shows how to loop through an array and assign values to each array element. This example also profiles the elapsed time between using checked and unchecked arithmetic.
private static void ArrayValueAssignment()
{
byte[] data = new byte[100000000];
int unsafeTime = 0;
int uncheckedTime = 0;
unsafeTime = Environment.TickCount;
unsafe
{
fixed (byte* dataPtr = data)
{
byte* dataByte = dataPtr;
for (int index = 0; index < data.Length; index++)
{
*dataByte++ = (byte)index;
// Can also do: *(dataByte + index) = (byte)index;
}
}
}
unsafeTime = Environment.TickCount - unsafeTime;
uncheckedTime = Environment.TickCount;
unsafe
{
unchecked
{
fixed (byte* dataPtr = data)
{
byte* dataByte = dataPtr;
for (int index = 0; index < data.Length; index++)
{
*dataByte++ = (byte)index;
// Can also do: *(dataByte + index) = (byte)index;
}
}
}
}
uncheckedTime = Environment.TickCount - uncheckedTime;
Console.WriteLine("Unsafe Elapsed Time: " +
unsafeTime.ToString() + " ticks");
Console.WriteLine("Unchecked Elapsed Time: " +
uncheckedTime.ToString() + " ticks");
}The following example copies the data from a source array into a destination array, serving as a replacement for Array.Copy().
static void DataBlockCopy()
{
int dataLength = 100000000;
byte[] sourceData = new byte[dataLength];
byte[] destinationData = new byte[dataLength];
for (int index = 0; index < dataLength; index++)
{
sourceData[index] = (byte)index;
}
UnsafeCopy(sourceData, 0, destinationData, 0, dataLength);
Console.WriteLine("The first 15 elements are:");
for (int index = 0; index < 15; index++)
{
Console.Write(destinationData[index] + " ");
}
Console.WriteLine("
");
}
static unsafe void UnsafeCopy(byte[] source,
int sourceIndex,
byte[] destination,
int destinationIndex,
int count)
{
Debug.Assert(source != null);
Debug.Assert(sourceIndex >= 0);
Debug.Assert(destination != null);
Debug.Assert(destinationIndex >= 0);
Debug.Assert(!(source.Length - sourceIndex < count));
Debug.Assert(!(destination.Length - destinationIndex < count));
unchecked
{
int countDiv = count / 4;
int countMod = count % 4;
fixed (byte* sourcePtr = source, destinationPtr = destination)
{
byte* sourceByte = sourcePtr;
byte* destinationByte = destinationPtr;
for (int blockIndex = 0; blockIndex < countDiv; blockIndex++)
{
*((int*)destinationByte) = *((int*)sourceByte);
destinationByte++;
sourceByte++;
}
for (int blockIndex = 0; blockIndex < countMod; blockIndex++)
{
*destinationByte = *sourceByte;
destinationByte++;
sourceByte++;
}
}
}
}The following example shows how to interact with Win32 API calls through PInvoke and unsafe pointers. There are alternatives to this approach, but this example shows how to do it with unsafe code. This example retrieves the name of the local machine.
[System.Runtime.InteropServices.DllImport("Kernel32")]
static extern unsafe bool GetComputerName(byte* lpBuffer, long* nSize);
private static void Win32APIAccess()
{
byte[] buffer = new byte[512];
long size = buffer.Length;
unsafe
{
long* sizePtr = &size;
fixed (byte* bufferPtr = buffer)
{
GetComputerName(bufferPtr, sizePtr);
}
}
byte[] nameBytes = new byte[size];
Array.Copy(buffer, 0, nameBytes, 0, size);
Console.WriteLine("Computer Name: " + Encoding.ASCII.GetString(nameBytes));
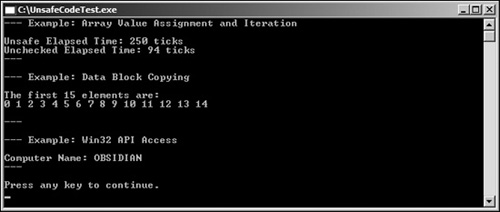
}Figure 35.1 shows all three examples after execution. Notice the speed difference between the unsafe context and the unsafe + unchecked context.
This chapter covered the usage of pointers and unsafe code within the C# language. There are only a few situations where it should be used, but pointers can solve a lot of problems when used appropriately.
It is important to keep in mind that unsafe code contexts require elevated security permissions to execute, so do not use unsafe code within applications that need to run under a least privilege account.
Lastly, only use pointers for performance gains if the gain itself is substantial. A great deal of the .NET framework has been optimized to its fullest potential, and while you may think your unsafe code implementation is faster than the built-in functionality, you cannot be certain unless you profile. Even then, if the difference between your code and the built-in functionality is pretty close, you are better off using the built-in functionality instead.